一个基于社区相似度分析的物流网络优化算法
2016-05-14于蕾吴强
于蕾 吴强
摘 要: 随着物流网络的快速扩张,如何在异构系统中交换物品信息已经成为影响物流效率的重要因素,而社交网络与物流网络都具有异构的特征,因此将物流网的各个节点看作是社交网络的社区,利用多关系社交网络社区挖掘算法来寻找各个异构的物流网络中固有的社区结构,从而发现物流网中隐藏的规律并进行路径优化等网络行为是可行的。通过对4 000例物流数据的对比试验,得出基于相似度的社区挖掘算法在准确率、算法复杂度和效率上都优于K均值算法和回归算法。
关键词: 社区挖掘; 物流网络; 相似度分析; 优化算法
中图分类号: TN711?34 文献标识码: A 文章编号: 1004?373X(2016)06?0045?04
A logistics network optimization algorithm based on community similarity analysis
YU Lei, WU Qiang
(Xian University of Technology, Xian 710048, China)
Abstract: With the rapid expansion of logistics network, how to exchange the information of goods in heterogeneous systems has become an important factor affecting the efficiency of logistics. However, both social network and logistics network have a same heteroid feature: heterogeneity. Therefore, it is entirely feasible to find out the hidden law of logistics network and optimizing route by using the intrinsic community structure of each heteroid logistics network, which is calculated by a community mining algorithm of multi?relation social network. The contrast test result of 4000 logistics data from three different algorithms shows that the community mining algorithm based on similarity is better than K?mean algorithm and regression?based algorithm in accuracy rate, complexity and efficiency.
Keywords: community mining; logistics network; similarity analysis; optimization algorithm
目前,对于物流网络设计的研究分为三个层次:策略、战术和运作[1]。策略和战术研究主要是为供应商解决货物储备的决策问题,如仓库大小和位置、货物价格和数量以及组织一个高效、低成本的物流网络。总之,物流网络的建立和优化,需要考虑四个层次的内容:物流中的选址[2]、对客户的聚类[3]、配送区域划分[4]和车辆调度[5]。一些学者将复杂网络理论应用在物流网上,试图解决区域选址问题[4]。一些学者利用遗传算法建立染色体表达式解决车辆调度问题(Vehicle Scheduling Problem,VSP)[6?7]。
而物流网中普遍存在物流效率低、成本高、大量的异构系统不能顺畅交换数据等问题。在物流网中,如何准确获取物品信息、如何在异构系统中交换物品信息,已经成为近几年物流网络研究的热点。本文提出一种基于相似度的社区挖掘算法,将物流网的各个节点看作是社交网络(Social Networks)的社区,社区结构可能各不相同,物品是隶属于不同社区的成员(意味着,不同物流节点的信息组成是异构的)。通过社区挖掘寻找各个异构的物流网络中固有的社区结构,从而发现物流网中隐藏的规律并进行路径优化等网络行为。
1 相关工作
对物流中所涉及到的数据,建立一个适用于物流的地理社会网络,通过分析和处理,优化物流流程,提高物流效率。物流的产生和发展的原因在于没有将时间、空间以及人这三者关系结合起来,地理社会网络可以实现时间、地点与人三者关系的叠加处理[8]。因此,将地理社会网络与物流信息平台相结合,关注用户与系统、用户与用户间关系,让用户作为系统的一个节点,有效地参与并发布数据;结合地理社会网络,消除信息之间的孤立等研究具有一定的研究价值和实际意义。
1.1 物流网关系模型
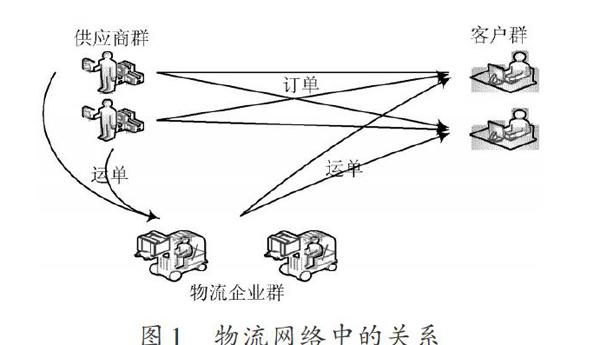
物流关系:一个物流网络可以用一张图来表示,如图1所示。供应商、客户、物流企业对应图中的节点,每个节点拥有自己的属性,包括身份,公司,车队等;边代表节点之间的关系,包括买卖关系,合作关系等。用一个无向图来表示这样的网络,Nsocial =(P,C,T),P是代表一组供应商用户的节点集合;C代表一组客户用户的节点集合;T代表物流企业,T包含于P×C的笛卡尔乘积中,是无向图中的边的集合。一条边(p1,c2)属于T,表示p1,c2这两个的关系。
对物流网络进一步抽象,用连通的无向图G=(V,E)来表示,节点集V表示物流网络中个体(既可以是供应商也可以是消费者客户)的集合,V={v_1,v_2,…,v_n},边集合E表示网络中供应商或者消费者之间的关系,E={e_1,e_2,…,e_m}。
这样,物流中的每类关系都可以对应出一个子图Gj=(Vj,Ej),j=l,2,…,k,k≥2,Vj表示该子图中供应商的集合;Ej表示子图中供应商之间关系的集合。在图G中,边E上是有标有权重的,供应商之间关系的紧密程度是通过权重来体现的,权值的计算是根据计算供应商之间的标记数目得到的。所以,在构建子图Gj=(Vj,Ej)所对应的关系矩阵Rj时,需要计算边上的权值,同样,通过计算物流网络中供应商之间的标记数,得到个体边上的权重,用如下公式进行计算:
[Rjxy=1, x和y具有相同标记0, x和y不具有相同标记]
其中[x,y∈Vj,]表示在物流子图Gj中存在的两个供应商x,y,假设x和y具有3个相同的标记,则[Rjxy]为3,是通过这种方式进行计算物流网络中所有边上的权值的。对于关系矩阵Rj,j=1,2,…,k,k≥2,通过除以物流网络中边上的最大权值作归一化处理,使得所有的边上的权重值在范围[0,1]内。因为Rj是一个对称矩阵,所以可以采用一个向量表示它。
1.2 物流网络中的社区
一个社区可以简单地定义成享有一些共同属性的一群对象的集合,这个共同属性就是对象之间的关系。例如,给出一个用户的一组选择[P={p1,p2,…,pk}],构建出相应的关系矩阵RP,关系矩阵RP是一个对称矩阵;然后,找出最能匹配选择关系向量的已有关系的线性组合,根据得到的关系组合,来挖掘符合用户需求的社区。
这些关系矩阵具有如下的属性:
频率:[f(xj)=xjn],表示社会网络中供应商[xj]在关系[Rj]中所对应的标记占关系[Rj]中的有对象对应的标记的百分比,其中[xj]表示对象[xj]在关系[Rj]中所对应的标记数;n为关系[Rj]中所有对象对应的标记总和。若[xj]在关系[Rj]所对应标记中出现的次数越多,则[f(xj)]值越大,表示[xj]在关系[Rj]中与其他个体之间的联系越紧密。
重要性:[I(xj)=Nxj],表示供应商[xj]在整个网络中的一个重要参数,式中的N表示整个物流网络中所有物流个体对应的标记总数目,[xj]表示对象[xj]在整个网络中对应的标记总数。若[xj]对应标记在整个网络中出现的次数越多,则[I(xj)] 的值就越小。
次序值:[RV(xj)=f(xj)I(xj)],由频率与重要性的定义可知,若对象[xj]所对应标记总数在社会网络中出现的次数越多,并且在某一关系中出现次数越多,则对象[xj]的次序值就越大。若以这样的[xj]作为一组选择实例,则在网络中,次序值越大的关系就更可能符合用户的需求。
综合次序值:整个网络中某关系中的次序值。[j=1kRV(xj)]表示用户选择[P={p1,p2,…,pk}],在整个网络某关系中的次序值。
1.3 基于相似度的社区挖掘算法
进行用户推荐,需要了解客户的购买行为。可以通过大量的订单的信息来了解,因为订单信息一般包含客户的编号、物品名称、数量、时间等信息;然后根据不同用户提取相关数据并调用推荐算法,最后找出1~3个供应商作为结果展现给用户。
对于两位用户,当他们在物流信息平台上购买物品,选取的物流公司相同,则认为两位用户有一定的相似性;假如两位用户同时都在物流服务平台上购买相同的物品并且选取的物流公司也相同,可以认为这两位用户在选取物流公司的相似度较高;假如两位用户同时都在物流服务平台上购买相同的物品并且选取的物流公司也相同,而且两位用户在同一个区域,认为这两位用户在选取物流公司的相似度更高。
在物流社交网络中,用户每一次下单行为可以称作一个购买兴趣点(Purchase of interest,PI)。PI库中都会记录每一个PI的供应商、物品名称、发货地、送货地、送货方式(物流公司名称),即PI=(P,N,O,D,T)。在物流过程中,经常会涉及到订单,需要对订单进行定义。这样,每一个订单都会有供应商、物品名称、发货地、送货地、物流公司名称,即Order=(ProviderName,GoodsName,Origin,Destination,LogisticsCompanyName)。n个订单可以看成[n×5] 的矩阵:
[On×5=O11O12…O15???Oi1Oi2…Oi5????On1On2…On5]
首先,给出一个连通的无向图G(V,E),|V|=M,代表物流网络中的有M个物流个体,确切地说是M个供应商;E代表个体之间的关系。并对其对应的关系向量[R1,R2,…,Rn]作标准化处理。
其次,物流社会网络中物流个体间存在着各种关系,每种关系都可以映射为一个关系图,因此一个社会网络映射出多个关系图,[G1,G2,…,Gn],并根据用户的选择信息,由次序值公式:[RV(xj)=f(xj)I(xj)]计算综合次序值[j=1kRV(xj)],然后重新排序关系,其中N表示关系的种类数目。
最后,选择次序值高于一定阈值t的关系,在此关系基础上,调用基于回归的多关系抽取算法,求出组合系数:[R=a1R1′+a2R2′+…+anRn′],其中[a1,a2,…,an]为对应关系的组合系数,得到一组关系组合[R1′,R2′…,Rn′] ,调用K?means算法,得到K个聚类,即挖掘出k个社区。
该算法伪代码如下所示:
2 实验及分析
本实验使用4 000个订单数据集进行实验,把这个数据集看作一个物流网络,供应商视为网络中的对象,供应商使用不同的物流公司配送物品视作一种关系,因为10个物流公司,则至多有10种不同关系,那么这个数据集就是一个多关系社会网络。本实验就是在其上研究供应商的内在的关系,对供应商社区进行挖掘。
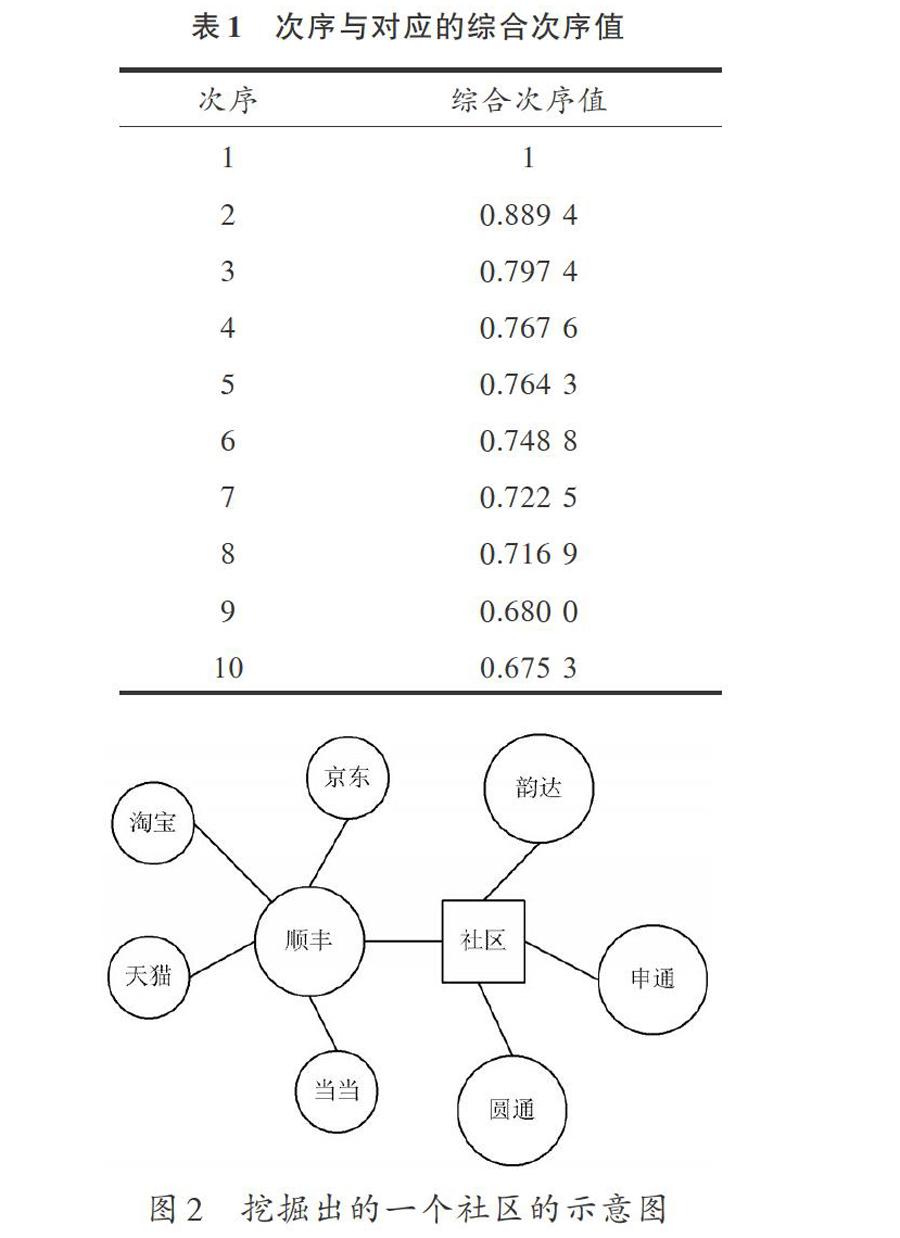
首先构建关系图,把供应商视为节点,标记数初始值为0,如果有两个供应商使用同一个物流公司配送物品,则他们的标记数加l,否则不变;然后生成关系图,每一个物流公司生成一个关系图,对每个物流公司,将数据相加获得该物流公司的供应商关系图。这种关系图反映了供应商在配送某一类物品时的相似度,相似度越高,说明他们之间的具有共同喜好的可能性越大。一般来说,如果两个供应商在某一图中边的权值较大,就说明他们有着相似或者相同的物品或物流公司,也说明他们的相似度更高。最后,对于每一个关系图,需要进行归一化权值,可以采用他们的权值除以整个网络关系图中的最大权值的方式来处理,权值结果都在区间[0,l]内。本实验选取了配送物品较多的物流公司构建了关系图。所有供应商的综合次序值的计算结果如表1所示。
当选择淘宝、京东、天猫,阈值t为10时,综合次序值对应的是表1中的第4,9,10次序;抽取的关系组合系数分别为:
[R=0.736R1′+0.265R2′+0.182R3′+0.139R4′+0.092R5′+ 0.061R6′+0.043R7′+0.021R8′+0.019R9′+0.006R10′]
由上式可以看出,当选择淘宝、京东和天猫这几个供应商和物流公司[R1′](顺丰)的关系最密切,换言之,淘宝、京东和天猫与顺丰的业务合作比较多。最终,通过聚类,得到一个社区,该社区如图2所示。
从图2中可以看出,这个社区中的供应商有一个共同的特点,那就是他们的客户主要是个人,而不是企业。他们使用的物流公司大都是一些快递公司。因为这些快递公司的费用较低,速度快等特点,淘宝是最典型的例子。进而得到一个供应商和客户的关系,该社区的供应商大多数业务是面向个人用户的。
同样的,当用户选择当当、TCL、索尼,阈值t为10时,综合次序值对应的是表1中的第1,2,3次序;抽取的关系组合系数分别为:
[R=0.636R1′+0.565R2′+0.532R3′+0.458R4′+0.394R5′+ 0.138R6′+0.119R7′+0.095R8′+0.062R9′+0.027R10′]
由上式可以看出,当选择当当、TCL和索尼这几个供应商和物流公司[R1′](顺丰)[R2′](中国外运(集团)总公司)[R3′] (EMS)[R4′] (中远国际货运有限公司)[R5′](德邦物流)的关系比较密切;最终,通过聚类,得到2个社区,如图3所示。从图3中可以看出,社区1中的供应商的共同特点是他们的客户主要是个人。他们使用的物流公司大都是一些快递公司,使用最多的是顺丰快递和EMS。此社区中的供应商大多数业务是面向个人用户的。社区2中的供应商的共同特点是他们的客户主要是企业。他们使用的物流公司大都是一些货运代理公司,如中国外运(集团)总公司、中远国际货运有限公司、德邦物流等。此社区中的供应商大多数业务是面向企业用户的。
3 结 语
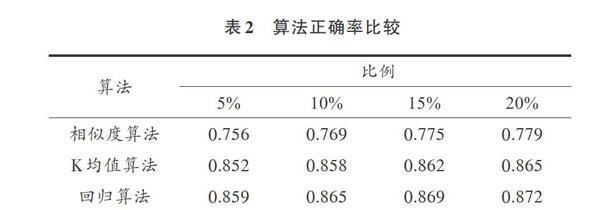
传统K均值数据挖掘算法的好处是不需要进行关系选择和抽取,但是其结果会随着选取实例比率的不同在一个而上下浮动。针对实验中的4 000个订单数据,分别使用K均值算法[9]、回归算法[10]和相似度挖掘算法在选择实例的比例为5%,10%,15%和20%下得出的挖掘正确率如表2所示。
表2 算法正确率比较
经过实验验证,在关系数恒定的情况下,相似度算法的正确率会随着用户选定实例比率的提高而提高,且明显要好于传统K均值挖掘算法,略微高于基于线性回归的多关系抽取算法。
参考文献
[1] SHANKAR L B, BASAVARAJAPPA S, CHEN J C H, et al. Location and allocation decisions for multi?echelon supply chain network: a multi?objective evolutionary approach [J]. Expert systems with applications, 2013, 40: 551?562.
[2] WANG Y, MA X L, WANG Y H, et al. Location optimization of multiple distribution centers under fuzzy environment [J]. Journal of Zhejiang University (Science A), 2012, 13(10): 782?798.
[3] MIRANDA P A, GARRIDO R A, CERONI J A. E?work based collaborative optimization approach for strategic network design problem [J]. Computer & industrial engineering, 2009, 57(1): 3?13.
[4] IYOOB I M, KUTANOGLU E. Inventory sharing in integrated network design and inventory optimization with low?demand parts [J]. European journal of operational research, 2013, 224: 497?506.
[5] CHOPRA S, MEINDL P. Supply Chain management: strategy, planning and operation [M]. 3rd ed. [S.l.]: Pearson Prentice Hall, 2007.
[6] KO H J, EVANS G W. A genetic algorithm?based heuristic for the dynamic integrated forward/reverse logistics network for 3PLs [J]. Computers & operations research, 2007, 34: 346?366.
[7] KANNAN G, SASIKUMAR P, DEVIKA K. A genetic algorithm approach for solving a closed loop supply chain model: A case of battery recycling [J]. Applied mathematical modelling, 2010, 34: 655?670.
[8] 肖智清.基于SOA的物流信息系统集成平台LESB的研究与实现[D].吉林:吉林大学,2012.
[9] GAZI V P, KAYIS E. Comparing clustering techniques for real microarray data [C]// 2012 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining. [S.l.]: IEEE, 2012: 788?791.
[10] YAN Chunlei, SHI Shumin, HUANG Heyan, et al. A method for network topic attention forecast based on feature words [C]// 2013 International Conference on Asian Language Processing. [S.l.]: IALP, 2013: 211?214.
