基于改进关联规则的危险Web信息挖掘技术研究
2016-05-14黄宏本
黄宏本
摘 要: 在Web网络中承载着不同的协议和网络信道,由此产生危险信息,给网络信息空间带来安全威胁,通过对危险Web信息的准确挖掘,可净化网络空间,确保网络安全。传统方法采用模糊关联规则算法进行危险Web信息分类挖掘,在干扰背景下,模糊聚类过容易受到干扰,导致很难建立有效的关联规则,挖掘效率较低。提出一种基于改进关联规则的危险Web信息挖掘技术。在建立关联规则前,引入Takens 定理进行危险Web信息数据的相空间重构,构建Web网络的危险信息挖掘的信道模型,并对危险Web信息的信息流多源进程进行分类设计。设计自适应IIR级联滤波算法进行数据干扰滤波,运用以上方法对规则关联过程进行改进,实现危险Web信息的准确挖掘。仿真实验进行了性能验证,结果表明,采用该算法进行危险Web数据挖掘,去干扰性能较好,精度较高。
关键词: Web; 数据挖掘; 网络安全; Web 信息
中图分类号: TN911?34; TP391 文献标识码: A 文章编号: 1004?373X(2016)06?0014?04
Research on risk web information mining technology based on improved association rules
HUANG Hongben
(School of Information and Electronic Engineering, Wuzhou University, Wuzhou 543002, China)
Abstract: The security of cyber information space is threatened by the hazard information that caused by different protocols and network channels in Web network, and the cyber space is purified to ensure the network security by mining the hazard Web information accurately. The algorithm of the fuzzy association rules are used in the traditional method to excavate and classified the dangerous Web information. The fuzzy clustering is easy to be disturbed in the influence background and has low efficiency, so it is hard to establish effective association rules. Because of this, the risk Web information mining technology based on the improved association rules is proposed. Before establishing the association rules, Takens theorem is introduced to reconstruct the phase space of the hazard Web information data to establish the channel model for the hazard information mining in Web network and make classification design for the multisource progress of the risk Web information flow. An adaptive IIR cascade filtering algorithm is designed to filter the data influence, improve the progress of the association rules, and realize the accurate mining of the risk Web information. The simulation results for the performance verification show that this algorithm has advantages of good filtering interference performance and high accuracy.
Keywords: web; data mining; network security; Web information
0 引 言
Web网络是一种由不同制造商生产的计算机、网络设备和系统组成的复杂网络结构,在云计算环境的多通道平台下,Web网络是一个巨大的动态复杂网络。Web信息数据库采用多路复用的多通道输入输出信道进行数据存储和传输,然而由于云计算环境下多路复用器输入输出功能的网络具有开放性,容易受到病毒感染产生危险数据。Web网络在整个互联网体系中体现为一个异构网元,承载着不同的协议和网络信道,并通过云储存实现资源调度,随着病毒感染和入侵,危险Web信息在网络数据库中泛滥,给网络信息空间带来安全威胁,需要对危险Web信息进行实时准确挖掘,随着信息技术的不断发展和Web网络数据库的不断更新和应用,研究危险Web信息挖掘算法在网络安全和数据挖掘等领域具有重要的应用价值[1]。
在Web网络中的危险信息自相关特性较弱,挖掘难度较高,传统的挖掘方法主要有基于频谱挖掘算法和时频特征挖掘方法等。这类方法主要都是基于线性特征提取的角度进行挖掘的[2?3]。文献[4]提出一种基于博弈论的Web网络信道分配方法实现危险Web信息的挖掘,通过递阶控制调整HHT频谱的信道分配,提高挖掘性能,但是该算法采用自相关特征调度方法进行挖掘的过程中,会产生频谱偏移和失真,降低了准确性。文献[5]提出一种基于数据分类和分形特征提取的危险Web信息挖掘和检测算法,对危险信息的流量进行准确估计和预测,实现数据过滤和挖掘的目的,但该算法的实时性和收敛性不高。分析传统方法可见,传统方法采用线性特征分析方法,提高了虚警概率,然而危险Web信息通常表现为一种非线性特征,比如关联规则特征就是一种典型的非线性特征,采用非线性时间序列分析方法实现危险Web信息挖掘具有重要的研究价值和应用前景[6?10]。对此,为了克服传统方法的弊端,本文提出一种基于改进关联规则的危险Web信息挖掘技术。首先构建了Web网络的危险信息挖掘的信道模型,并设计信息流多源进程分类,进行数据干扰滤波,最后采用改进的关联规则特征提取算法,实现危险Web信息的准确挖掘,仿真实验进行了性能验证,展示了本文算法在实现危险Web信息挖掘,提高危险信息数据检测性能方面的优越性能,得出了有效性结论。
1 Web网络的危险信息挖掘的信道模型及时
间序列信号分析
1.1 构建Web网络的危险信息挖掘的信道模型
为了实现对危险Web信息的准确挖掘,建立准确的关联规则,需要首先分析Web网络的危险信息挖掘的信道模型。Web网络信息库汇聚了大量文本、图片、视频等信息数据,这些数据会让关联规则淡化;因此需要构建客户机与服务器间的数据传输通信信道模型。Web网络客户机与服务器间的数据传输通信信道中承载着不同的协议和网络信道,传输协议主要有FDMA,CDMA,TDMA等。在Web网络中,由于外部入侵的影响,会产生较多危险信息,给网络信息空间带来安全威胁和存储开销。需要建立信道模型,以保障后期规则关联的准确性,建模方法如下:
假设:Web网络信息库数据集[X=x1,x2,…,xn],[n]是Web数据集X的数目,[X]中的每个危险的Web数据特征都是一个[p]维矢量,Web数据库数据信息流[xnNn=1]含有[c]个类别,第[i]个类危险信息的数据聚类中心为[vi=vi1,vi2,…,vip]。在聚类中心,Web信息形成一个较大的数据存储通道,根据上述分析,构建Web网络的危险信息挖掘的信道模型。
首先,确定Web网络客户机与其服务器间的数据传输信息特征初始值分别是[zn]和[ωn]。可为Web通信过程中的客户机检测的Web信息时间序列[rn]的计算提供先决条件,[rn]如下所示:
[rn=h(zn)+ωnX] (1)
假设Web网络信息数据传输通信信道为连续系统,危险数据的频域目标函数表示为:
[xn=x(rn+nΔt)=h[z(rn+nΔt)]+ωn] (2)
式中:[h(·)]为Web数据挖掘模型的滑动时间窗口函数;[ωn]为测量误差。
其次,在危险数据的频域模型基础上,引入Takens定理对Web网络的危险信息数据进行相空间重构,得到危险信息挖掘的信道模型。通过引入Takens 定理,设置危险信息数据相空间[M]为[d]维的紧流形,危险数据的密度先验信息为[F]表示一特征矢量场,具有时间平移性,[h]表示在滑动时间窗口上的一个相空间重构函数,对于[Φ]:[M→R2d+1],则对Web网络信息库危险数据的空间重构得到网络的危险信息挖掘的信道模型为:
[Φ(z)=xn(h(z),h(φ1(z)),…,h(φ2d(z)))T] (3)
式中:[h(z)]分簇系统函数;[φ]为[h(z)]中[z][(∈(M))]时的检测值;[Φ(M)]表示嵌入状态矢量。通过相空间重构结构,得到了网络的危险信息挖掘的信道模型,为进行危险Web信息的挖掘提供了特征输入模型。
1.2 危险Web信息挖掘的特征分类提取
通过第1.1节得到信道模型提取所需时间序列,在进行分类,为之后的相关特征提取提供依据。在进行分类的过程中,需要对Web网络信息库的危险数据的先验信息进行滑动时间窗口重排,得到危险数据的嵌入空间时频特征为:
[z(t)=s(t)+js(t)?h(t)Φ(z)=s(t)+j-∞+∞s(u)t-udu=s(t)+jH[s(t)]] (4)
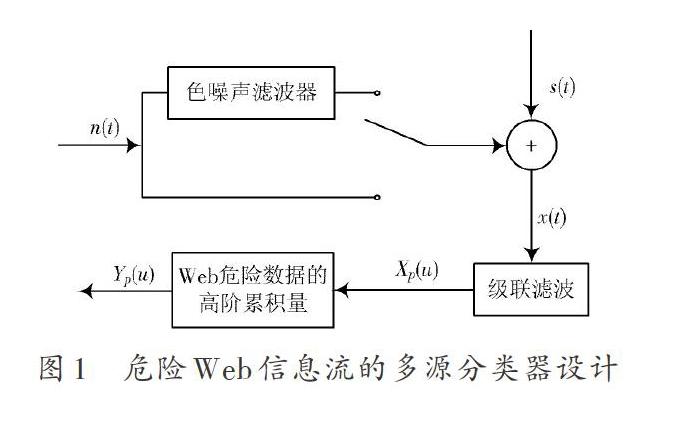
式中:[s(t)]为一组数据信息流;[u]为连续邻居集交换窗口宽度;[a(t)]为Web信息的数据特征;[z(t)]为瞬时特征,在上述构建的相空间中的信息流进行分类,则危险Web信息的多源信息流分类器的设计如图1所示。
危险Web信息流的多源分类器分类步骤如下:
(1) 对危险Web信息时间序列进行Fourier变换,得到危险信息原始数据[r(k)];
(2) 测量危险Web信息的高斯过程随机特征,进行随机化处理,得到危险Web信息替代数据[r′(k)];
(3) 采用非线性检验方法检验危险Web信息的非线性成分,生成的替代数据,在重构的[m]维状态空间中求解危险Web信息的矢量状态映射,对信息数据的时间序列生产替代数据[r′(k)],在经过Fourier逆变换完成对危险Web信息流的特征的分类,其表达式如下:
[r′(n)=r(k)r′(k)?tn] (5)
式中:[tn]为逆变换所需时间。
由此实现危险Web信息的多源信息流的分类,从而形成[m]维状态空间,矢量空间为:
[yn=(yn,yn-τ,…,yn-(m-1)τ)] (6)
式中:[m]为嵌入维数;[τ]状态空间重构的时间延迟,由此产生的危险Web信息作为一种标量时间序列,在重构的[d]维状态空间中危险Web信息的矢量状态为:
[yn+1=F(yn)] (7)
由式(7)可以看出,Web网络危险信息在矢量状态空间中[yn→yn+1]的演化反映了危险Web信息的非线性差分维数,可对时间序列进行平稳化处理,提取的相关特征更准确,而对随机时间序列可以通过统计方法研究。则Web网络危险信息的相关特征提取公式如下所示:
[Cor3=z(t)yn-xyn+1-xyn-D-xr′(n)yn-x3] (8)
式中:[yn]表示危险Web信息的非线性时间序列;[d]表示危险信息传输延迟,[D=2d],通过非线性时间序列分类方法与自相关函数法求取危险Web信息矢量空间重构的关联规则,进行提取的Web网络危险信息特征精度更高。
2 干扰信息滤波处理及实现基于关联规则特征
提取的信息挖掘算法改进
2.1 干扰信息过滤处理获取滤波器输出函数和信息梯度
在构建Web网络的危险信息挖掘的信道模型、时间序列信号分类及相关特征提取时,发现在进行危险Web数据挖掘过程中受到大量信道噪声的干扰,需要进行干扰信息过滤处理,提高信息挖掘的精度。本文采用一种自适应级联陷波算法进行干扰信息过滤处理,设计基于IIR的自适应级联过滤器进行Web干扰信息过滤设计,其Web网络危险信息的干扰信息过滤处理结构框图如图2所示。
在Web网络中的危险信息受到多个干扰信息特征的影响,传统的模糊关联规则算法进行危险信息挖掘时,不能有效去除多个已知存在干扰信息特征的危险信息,采用二阶格型IIR结构,通过下式进行迭代过滤处理:
[θ1(k+1)=θ1(k)Cor3-μRe[y(k)φ*(k)]] (9)
式中:[μ]是危险Web信息受到的干扰信息出现的频率;[θ1(k)]是控制收敛速度和精度的参数;[φ*(k)]为时间宽度;则对参数θ1(k+1)进行自适应加权,得到IIR滤波器传输函数为:
[HB(z)=(1+sinθ2)θ1(k+1)cosθ2· cosθ1(k+1)cos(θ2)z-11+sinθ1(k+1)(1+sinθ2)z-1+sin(θ2)z-2G(z)] (10)
式中:
[G(z)=1-sinθ22?1-z-21+sinθ1(k)(1+sinθ2)z-1+sin(θ2)z-2] (11)
式中:[G(z)]表示单级IIR滤波器的传递函数;[k]为级联数;[z]为时间变量。用多个固定IIP过滤器级联抑制干扰成份,然后得到去除多个已知干扰信息特征的输出函数和信息梯度值,过滤器输出函数[y(k)]和信息梯度[φ(k)]分别可以表示为:
[y(k)=s1(k)G(z)+HB(z)n1(k);φ(k)=s2(k)G(z)+HB(z)n2(k)] (12)
[s1(k)=AAHej(Ωk+θH);s2(k)=AAHBej(Ωk+θHB)] (13)
式中:[s1(k)]为危险信息的初始状态信息;[s2(k)]为危险信息第二阶状态信息;[n1(k)]和[n2(k)]为危险信息的干扰成分向量,[A]为幅值矩阵,[AHB]为求矩阵。
2.2 改进关联规则特征提取及挖掘的实现
通过上述中获取的过滤器输出函数和信息梯度对挖掘危险Web信息的关联规则进行改进。首先求出危险Web信息的自相关函数,其基本思想是考察危险数据信息的时间序列特征关联化分类[x]和[xn+τ]与平均观测量之间的自相关性,对离散化危险Web信息[x(t)]进行处理,求得自相关函数[C(τ)],其定义为:
[C(τ)=limT→∞1T-T2T2x(t)x(t+τ)dτ] (14)
式中:[τ]是危险Web信息的矢量空间的时间延迟窗口;[-T2TT2x(t)x(t+τ)]表征[t]和[t+τ]时刻危险Web信息变化关联或相似程度。
其次,在求得危险Web信息自相关函数的基础上,结合获取的滤波器输出函数和信息梯度实现关联规则特征提取及危险Web信息挖掘的改进,则其改进关联规则危险Web信息挖掘公式如下所示:
[I(τ)=-ijpij(τ)φ(k)lnC(τ)y(k)pipj] (15)
式中:[pi],[pj]表示关联规则特征空间中的任意一点;[pij(τ)]表示在危险Web信息高维矢量空间中的最近邻点;[j]为固定危险信息关联特征的采样时间间隔。由上述计算可知,提取的危险信息特征值大小之间存在一定的关联,根据这组关联性进行危险信息特征挖掘,挖掘精度较高。
3 仿真实验与结果分析
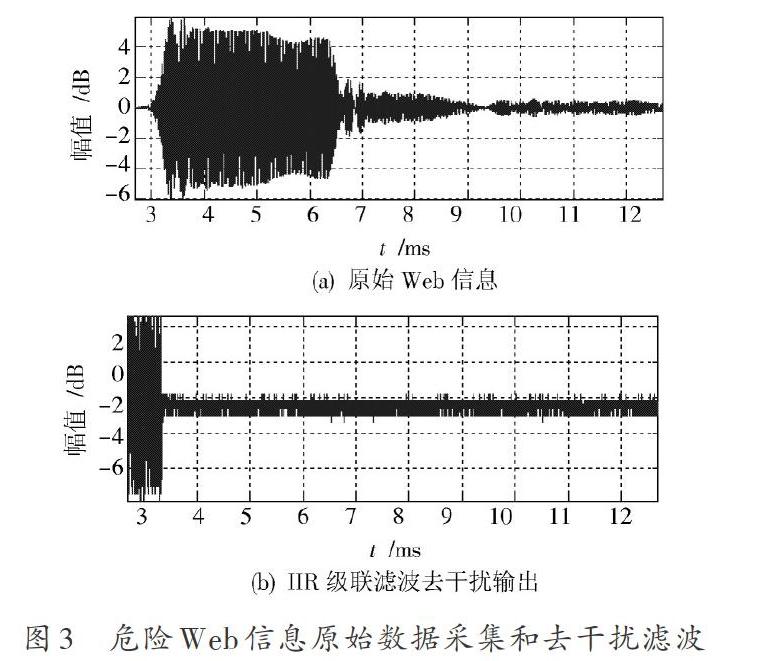
为了验证本文算法在实现危险Web信息挖掘中的性能,需要进行仿真实验。实验仿真环境为:Intel Core3?530 1 GB内存,操作系统为Windows 7,仿真软件为Matlab 7。危险信息在同一网段中传输,其中20%的危险Web信息通过网络主干进入三层交换机,Web信息传输通道的链路容量为10 Mb/s,信息传输延时5 ms。危险Web信息数据采集中,采样时间间隔为30 s,每小时为一段数据形成一组时间序列信号波形,以此为研究样本,根据上述算法和参数设计,进行危险Web信息挖掘仿真,得到原始的Web信息和采用本文设计的自适应级联滤波输出的Web信息结果如图3所示。
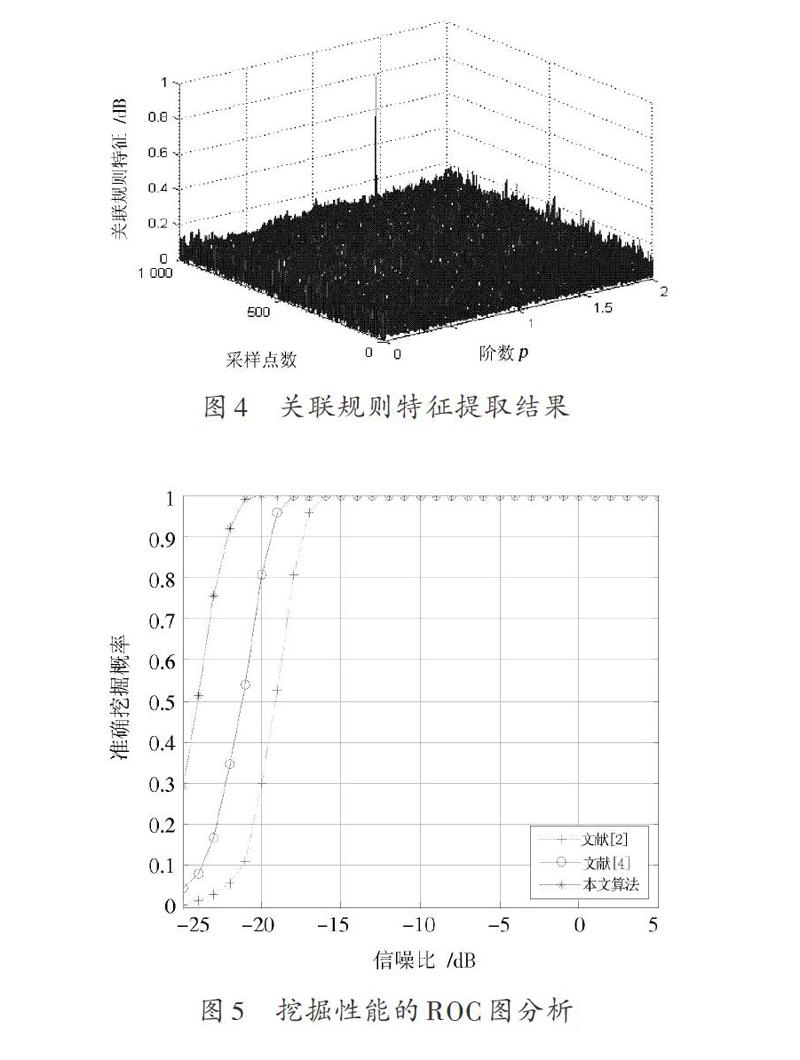
由图3可知,原始采集的危险Web信息数据受到较大的噪声信息干扰,难以有效实现危险信息挖掘,采用本文算法对危险信息进行特征提取和干扰信息滤波处理,去除多个已知干扰频率成分,提高的信息数据的纯度,以此为基础,进行关联规则特征提取,得到结果如图4所示。由图4可知,采用改进的关联规则特征提取算法,可有效实现危险Web信息的准确挖掘,特征提取准确,提高了数据挖掘的精度。为了对比不同算法性能,采用本文算法和传统算法,在不同信噪比SNR下采用200 000次蒙特卡洛实验,得到危险Web 信息挖掘的ROC图对比结果如图5所示。由图5可知,采用本文算法,有效提高了数据挖掘精度,展示了优越性。
4 结 语
本文提出了一种基于改进关联规则的危险Web信息挖掘技术。首先构建了Web网络的危险信息挖掘的信道模型,并引入Takens 定理进行危险Web信息的信息流多源进程分类设计,设计自适应IIR级联滤波算法进行数据干扰滤波,最后采用改进的关联规则特征提取算法,实现危险Web信息的准确挖掘。仿真结果表明,采用本文算法实现危险Web信息的挖掘,抗干扰性能较好,挖掘精度较高。
参考文献
[1] ZHU Q Y, YANG X F, YANG L X, et al. Optimal control of computer virus under a delayed model [J]. Applied mathematics and computation, 2012, 218(23): 11613?11619.
[2] MIORANDI D, SICARI S, PELLEGRINI F D, et al. Internet of things: vision, applications and research challenges [J]. Ad hoc networks, 2012, 10(7): 1497?1516.
[3] CHEN L, BRIAN K, AND JAMIE E. Theoretical characterization of nonlinear clipping effects in IM/DD optical OFDM systems [J]. IEEE transactions on communications, 2012, 60(8): 2304?2312.
[4] ZHOU Y, LI J X, WANG D L. Target tracking in wireless sensor networks using adaptive measurement quantization [J]. Science China information sciences, 2012, 55(4): 827?838.
[5] XU J, LI J X, XU S. Data fusion for target tracking in wireless sensor networks using quantized innovations and Kalman filtering [J]. Science China information sciences, 2012, 55(3): 530?544.
[6] 李超顺,周建中,方仍存,等.基于混沌优化的模糊聚类分析方法[J].系统仿真学报,2009,21(10):2977?2980.
[7] 汪中才,黎永碧.基于数据挖掘的入侵检测系统研究[J].科技通报,2012,28(8):150?152.
[8] 王进,阳小龙,隆克平.基于大偏差统计模型的 Http?Flood DDoS检测机制及性能分析[J].软件学报,2012,23(5):1272?1280.
[9] 郑海雁,王远方.标签集约束近似频繁模式的并行挖掘[J].计算机工程与应用,2015,51(9):135?141.
[10] 张永铮,肖军,云晓春,等.DDoS 攻击检测和控制[J].软件学报,2012,23(8):2258?2072.
