面向门诊的医患者会话病例机器翻译的研究
2016-05-04苏沙托依拉肉克艳木买买提达瓦伊德木草
苏沙·托依拉, 肉克艳木·买买提, 达瓦·伊德木草
(1.新疆大学 纺织与服装学院,新疆 乌鲁木齐 830014;2.新疆大学 新疆多语种技术重点实验室,新疆 乌鲁木齐 830014)
面向门诊的医患者会话病例机器翻译的研究
苏沙·托依拉1,肉克艳木·买买提2,达瓦·伊德木草2
(1.新疆大学 纺织与服装学院,新疆 乌鲁木齐 830014;2.新疆大学 新疆多语种技术重点实验室,新疆 乌鲁木齐 830014)
摘 要:随着国家援疆工作的深入推进,新疆乡村民族群众的求医治病条件大有改善。然而,医者与患者间的语言沟通困难问题亟待解决。目前大部分地区医院采取给患者提供民语填写表格的方法咨询患者病情,但是,该表格最终还是通过人工翻译后医生才能使用。文章利用门诊用语民汉句对语料以及机器翻译融合方法、能够给医者自动提供患者病情、病状基本正确信息的门诊支援翻译系统。该文对于支援本系统的实现以及试用情况进行分析评估。
关键词:门诊会话病历系统;民汉语言;维吾尔语;医用民汉句对语料;机器翻译.
随着我国各省对援疆工作的深入推进,新疆农村牧区医疗卫生规模以及看病求医条件大幅度改善,大部分民族群众可以在原地求医治病[1]。由于援疆医疗工作者大部分不懂当地民语、乡村民族群众汉语沟通条件有限,医者与患者的沟通成了看病求医的障碍。不少地方医院门诊使用民语填写患者病情调查表,但是,民语表格最终还是需要专业翻译人员人工翻译后医者才能使用。多语言地区这种表格的人工翻译工作量大、耗时耗力、成本高、增加患者负担。
针对民族地区医疗卫生领域所存在的上述问题,我们首先合作于医疗卫生机构,医院诊所以及医科大学专业人员,对于不同医学病科、收集高发病情,常用病名以及药物信息建立不同病科医疗卫生用语,正确度高的民汉语言(该文仅讨论维-汉语言)实例句对语料(Parallel Test, PT);其次,本系统提供给患者一个病情调查填写表格,表格上患者可以用民语自由地填写自己的病情;最后,患者录入的病情信息传输给翻译系统执行实例句对翻译或机器翻译,自动生成医者和患者双方可以阅读的民-汉文PDF文档。这个文档帮助医患者双向正确沟通。该表格医患者双方可以作为电子化病历保存再用。
1相关研究现状
目前国内对医疗卫生领域多语言翻译服务支援系统研发方面的研究报告极为稀少。先行的研究[2]中报告了实例翻译及短语统计翻译混合策略的汉-民病历文本翻译的研究结果。该研究主要是对预先录入的中文病例进行基于短语的统计机器翻译之后,通过实例短句修整机器翻译结果,从而试图提高常用机器翻译的翻译精度。通过相似量度算法获取实例短句与翻译句片断的相似片段,经调序修整后作为机器翻译最终结果。
在国外研究中,日本国宫部和池田等研究组开发了基于实例句对多语言受诊支援系统[3,4]。他们开发的系统对于预先设定好的实例句对范围内体现出有效性,却难以保障实例句对以外病情病状信息的正确翻译。
近年来面向特定领域(比如旅游业)中、使用基于实例的机器翻译是一个较热门的研究课题,翻译精度也在不断提升, 然而对于翻译精度严密的医疗卫生领域中应用方面的研究还是不多见。文章研究面向高精度领域的、基于实例句对和常用机器翻译融合方法的医院门诊支援系统。
2系统设计
2.1门诊病情调查表填写
门诊医者可以提供如图1所示患者病情调查表格,民语言患者首先点击表格语言选择栏中选取母语后,按提示信息填写自己的病情症状。为了便于说明,文章以维吾尔语拉丁字母拼写形式为例。
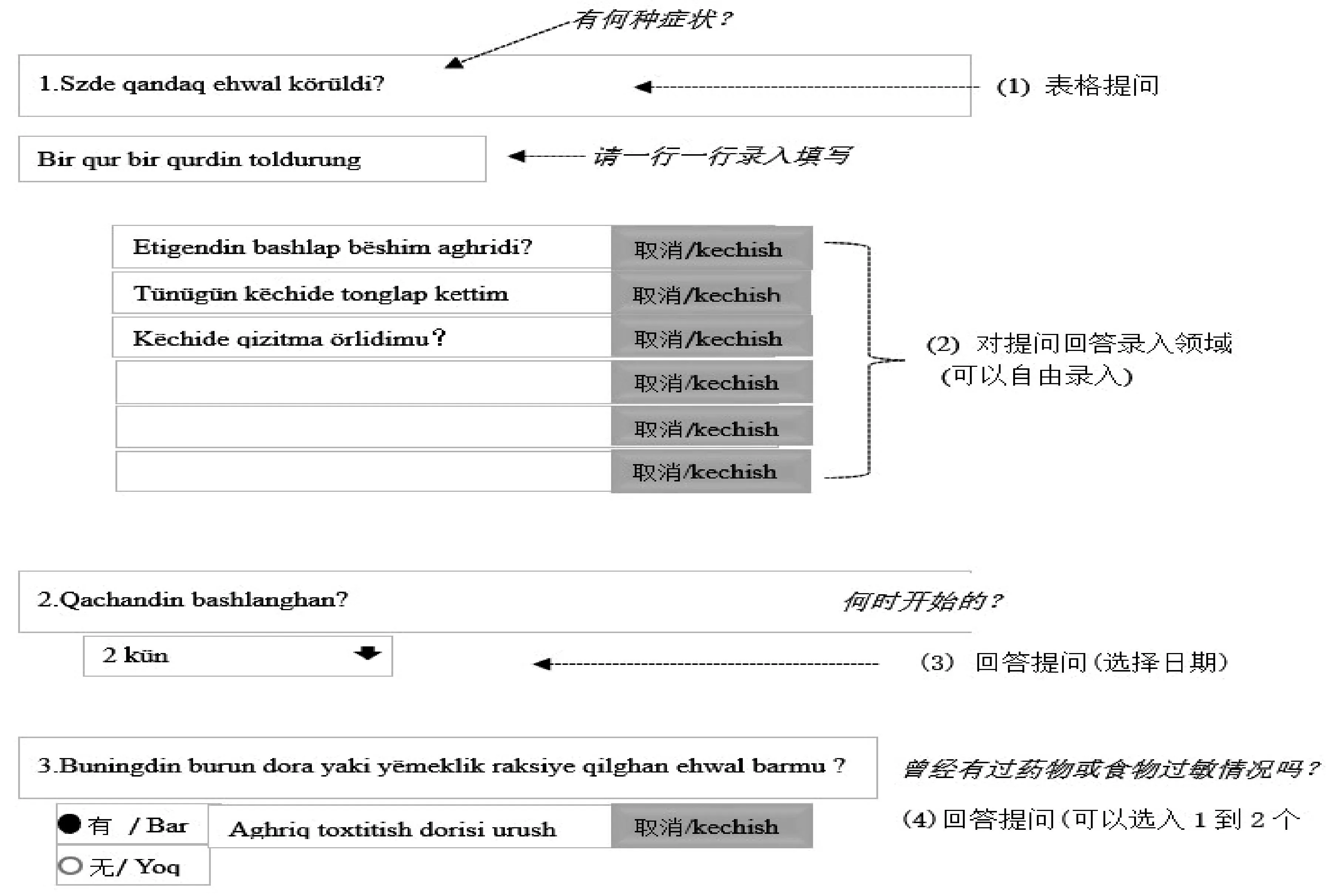
图1 调查表格录入界面
首先患者按各表栏民语提示录入回答文,如图1(1)所示,当点击图1(2)或图1(4)录入栏时系统自动显示该栏字串的机器翻译文。翻译录入界面显示如图2所示。该图2显示点击图2(1)栏时的情况。
图2显示栏中,录入到图2(2)中的字串,经实例句对检索和机器翻译后显示其结果。实例句对检索结果显示在图2(3)中,而机器翻译结果显示在图2(4)中。其中图2(3)中显的实例句对检索结果经图2(2)中字串和实例句对的N-gram(2-gram 或4gram)统计语言模型的最大似然度获取的。本系统可以提供3种匹配计算结果。如果实例句中对不存在与录入字串匹配字串,系统不显示其结果。在图2(4)中将显示机器翻译结果,由于机器翻译文常有误译情况,因此,图2(5)中用红色字串显示提示注意文,提示用户机器翻译结果可能有译误。另外,图2(4)栏中显示的机器翻译结果是把原录入字串重复多次翻译后的结果,是为了提醒用户多次确认机器翻译结果。这样患者可以多次修改原录入字串得到最满意的译文,从而提高机器翻译的正确性。机器翻译最终给出1个翻译结果,而实例句对给出3个检索文,所以本翻译系统图2可以显示4种不同译文。最后,点击图2(3)或图2(4)右边“使用”键时,原先点击的图2(1)栏中选入实例句对结果中的选文或者机器翻译结果选文,从而完成一个民汉双语病情调查表。
患者再点击 “表格生成”键,便可以获得双语门诊病情调查PDF文档并打印输出。医者可以保存患者病情表格电子版,患者可以携带打印版。

图2 翻译输出界面
2.2实例句对语料以及翻译器
本节介绍实例句对语料以及机器翻译器。本系统使用实例句对语料,这是在先行研究中研制的医疗卫生用语汉民多语言对齐语。该语料大量收集汉文医疗卫生用语句子,医学以及药物名称词汇等。在汉文句子的基础上再人工添加了维哈蒙文翻译句子。最后经过数字化及格式化处理生成语料库。该语料库包含汉维哈蒙四种语言,共收集240K(24万条)平行句子。而机器翻译软件(解码器)选用新疆大学多语言信息技术重点实验室在通用Moses软件的基础上研发的维-汉机器翻译器[5,6]。
3实验过程
下面介绍上述研发病情调查表翻译系统的实测过程。通过实验首先确认调查表的有用性、调查实例句对和机器翻译合并使用的有效性。本次实验中,先用患者在纸质表中直接填写病情与系统提供的表格中填写病情两种情况进行比较。实验过程中,首先选择理工科类学生共10人作为实验人。他们是中文和维文精通。另外选拔6名维族医学专业学生,他们对试验后的实例句对及翻译结果进行人工评估。为了使得实验过程尽量接近实际利用状态,实验表格均用民语(维文)录入。要求实验人可以录入自己体验过的不同病情,病状以及医科信息。实验过程如下:
(1)考虑到实验人和评估人隐私,实验方准备承诺书,保证保密被实验者隐私。被实验人可以不录入隐私病情;(2)要求被实验人同时填写纸质病情调查表格和系统提供表格。要求两种表格中填写病情内容一致、顺序一样;(3)考虑到被实验人对系统操作的熟悉需要时间,要求上述两种表格录入信息过程重复2次进行。表1显示本次实验;提问病情内容。
表1内容同时填写在纸质表格和系统提供表各栏中。实验时的提问全用民文(维文)进行。并设定本次实验中可以利用实例句对数为258个。

表1 调查表提问内容
3.1实验结果考查分
在表2中给出了本次实验中所用到的实例句对和机器翻译次数。

表2 实例句对和机器翻译利用次数
(单位:句子)
从表2可以看到,录入字串的80%以上是由机器翻译生成。这说明,由于检索结果可能在实例句对语料中大量存在,系统没有输出已存在的实例句对。另外,第2回利用次数多的原因是,可能因为被实验人对于实验系统的操作不习惯重复操作。表3中显示了机器翻译过程中所用句子的分类情况。

表3 机器翻译用句子
句子单位:句子;单词单位:字
从表3可以知道,机器翻译中用到的字串差不多一半以上是病名和症状名词。说明,专业术语词的使用频度较高,所以,应该考虑大幅度增加含专业术语词的实例句对数量。表3中还可以看到,“上午不小心滑倒胳膊骨折啦”等说明状态的句子出现了5次。这类句子不是医疗用语,难以作为患者常用医学用语,事先收集在实例句对中。对于这类说明状态的语句(不是专业用语),如果字数不长,在通用机器翻译器中一般可以获得较高的翻译精度。
3.2实例句对和机器翻译合并实验结果的验证
下面考查实例句对和机器翻译分别独立实施时的实验结果。
3.2.1实例句对单独实施时实验结果
根据前3.1节结果,如果系统中预先存入实例句对的数量巨大,患者录入的病情信息(字串)一句一句都可以在实例句对库中检索出,那么,这种基于实例句对的翻译结果肯定是很好的,而且翻译精度也可以保证。
但是,现实生活中不断出现新的病情,症状词汇、而且看病求医表现用语广泛,人工难以保障全面收集整理。本研究通过翻译系统来自动扩大实例句对,对每次对系统的录入,翻译来自动增加实例句对数。
3.2.2机器翻译独立实施时的实验结果
在这个试验中,首先假设机器翻译是独立实施的。采取对实例句对中所出现句子进行机器翻译,然后进行比较其结果。表4中给出本次实验一部分翻译事例。表4中原句(维文)和实例句对(中文)分别是实验中所利用的实例句对。而机器翻译(中文)列为对于原句子(维文)实施机器翻译后的翻译结果。正确性表示机器翻译结果与实例句对(中文)比较评估的结果。本次实验中一共选用了20实验句子,排除了重复句后对剩余的10个句进行考查的结果。从表4中可以看到,机器翻译结果10个句子中有4个误译句子。
另外,从表4中 ID为1的句子可以看到,虽然机器翻译的译文句子和实例句对句子的意思很接近,但是,对于该句子的提问句为有什么症状?因此,判断这种翻译结果为不正确的。
从上述考察可以肯定,如果机器翻译误译句子或者不大合理的翻译结果在实例句对中可以检索翻译,那么,提出实例句对翻译和机器翻译合并的翻译精度比仅用机器翻译,或仅用实例句对实施翻译时的翻译精度大幅度提升是可行的。
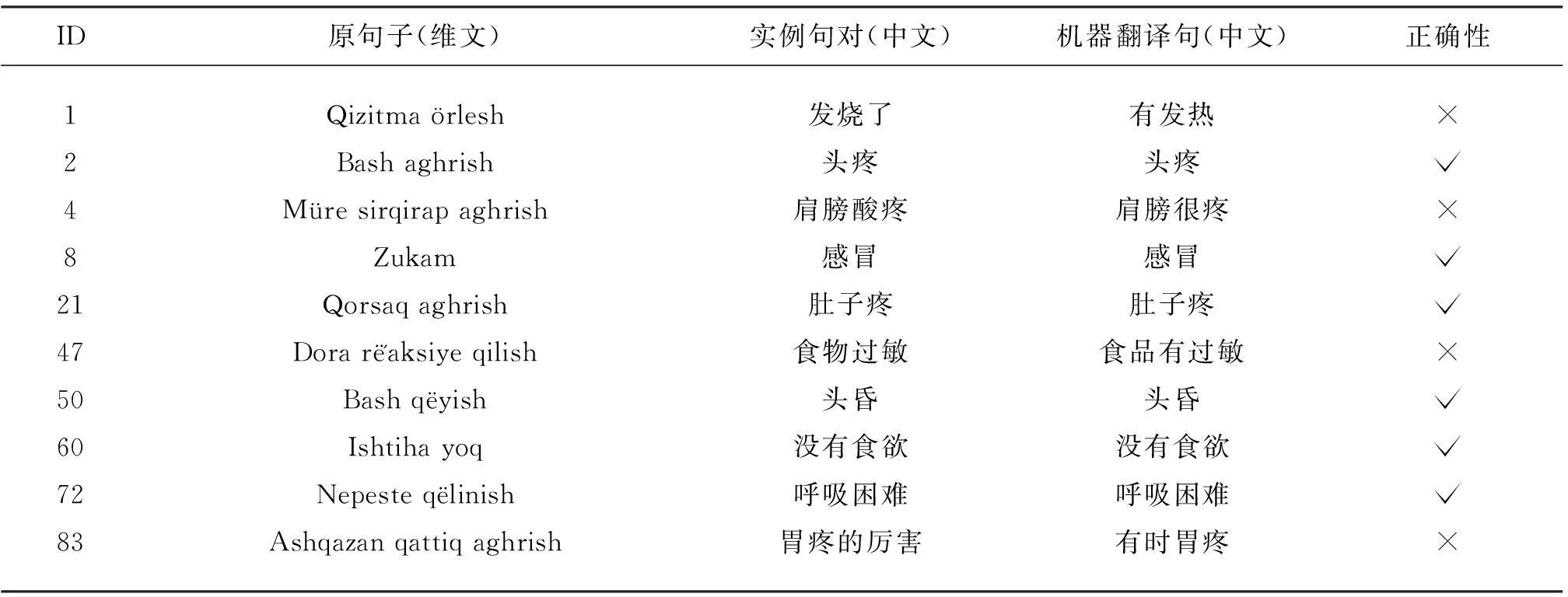
表4 在实验中使用的实例句对通过机器翻译器进行翻译的结果
4结论
文章以民族地区医疗卫生看病求医环境的改善为研究背景,讨论了门诊用语民汉语言会话翻译系统的实现过程,最终目的是开发利用汉族医者和民族患者能够正确沟通的计算机支援系统。相比于独立使用实例翻译技术,该系统可以克服人工制造巨量实例句对的工作量、而相比独立使用通用机器翻译方法,该系统借助于一定量的专业用语实例句对来克服机器翻译对专业术语常常出现的误译现象,能够提升常用机器翻译系统的完整性和正确性。该系统的开发利用有助于丝绸之路沿线多语言地区民众的看病求医,提高远程医疗事业的快速发展。进一步改善对于不会操作计算机的患者使用环境以及系统应用环境的扩展工作是我们今后研究的重点。
参考文献:
[1] 新疆维吾尔自治区人民政府, 学习宣传贯彻落实第二次中央新疆工作座谈会精神[EB/OL].http://www.xj.xinhuanet.com.
[2] 达瓦·伊德木草,等, 实例统计翻译混合策略的汉民病历翻译的研究[J].新疆大学学报(自然科学版),2015,32(1):123-128.
[3] 宫部 真衣, 吉野孝,等.外国人患者提供实例句对翻译多语言医疗门诊挂号支援系统的建设[J].日本电子情报通信学会学报,2009,192-D(6):708-718.
[4] Ikeda, T, Ando,S, Satoh,et al.T, Aoutomatic interpretation system integrating Free-style Sentence translation and Parallel text based Translation[C]. Prec.Workshop on Speech-to-speech Translation, 2002:85-92.
[5] Philipp, Koehn. Statistical Machine Translation[M]. Uk, Cambridge University,2011.
[6] 杨攀,李淼,张建. 基于短语统计翻译的汉维机器翻译系统[J].2009,29(7):2022-2025.
[7] 闵孝忠,朱林立.听诊采样仿真系统的设计与实现[J].云南师范大学学报(自然科学版),2015,35(2):62-66.
Minority and Chinese Language Translation Focus on the Outpatient Service
Susha·TUOYILA1,Roukeyanmu·MAIMAITI2,Dawa·YIDEMUCAO2
(1.CollegeofTextileandClothing,XinjiangUniversity,Urumqi,Xinijiang, 830014,China;2.KeyLaboratoryofXinjiangMulti-LanguageTechnology,Urumqi,Xinjiang, 830014,China)
Abstract:With the special service works from inner province for Xinjiang, today's medical condition has improved significantly at the rural pastoral areas of Xinjiang. However, It is more problems still that the communication between the medical works and minority patients. That is true, we can see some of services for patients using a table written by minority languages for medical works, but the table will be translated by the professional translator. To resolve this problems, we are working for developing a service system. Firstly, this system can provide a table including the main information in disease names and symptoms in different medical classification, and then translate the clicked sentences in the table by machine translation system. Finally, a PDF file is created for medial works. In this paper, we discuss the system construction and evaluation of performance in the machine translation.
Key words:Electronic medical record for medical and health; Minority and Chinese language; Language corpus of field of health; Example based and statistical machine translation
中图分类号:TP391
文献标识码:A
文章编号:1008-9659(2016)01-082-05
[作者简介]苏沙·托依拉(1984-),女,新疆伊犁人,研究生,主要从事艺术多媒体制造研究。*[通讯作者] 达瓦·伊德木草(1956-),男,新疆塔城人,教授,博士,主要从事机器翻译、语音翻译的研究。
[基金项目]国家自然科学基金(61163030,61562082)。
[收稿日期]2015-12-01
