二分图顶点配对模型下的英汉句子对齐研究
2016-05-04严灿勋
严灿勋
(解放军外国语学院 语言工程系,河南 洛阳 471003)
二分图顶点配对模型下的英汉句子对齐研究
严灿勋
(解放军外国语学院 语言工程系,河南 洛阳 471003)
英汉平行文本句子对齐可以视为一个二分图顶点配对模型。利用完全基于英汉词典的双语句子相关性评价函数,能够对二分图的“顶点对”进行加权。该文提出的顶点配对句子对齐方法首先获取二分图全局最大权重顶点配对作为临时锚点;在此基础上,根据句子先后顺序,局部最大权重顶点配对和英汉句长比的值域范围,纠正临时锚点中的错误,补充锚点序列未覆盖的合法顶点对,同时划分句对,实现句子对齐处理。在对比实验中该句子对齐方法优于Champollion句子对齐系统。从实验对比结果和实践效果看,该句子对齐方法可行。
句子对齐;双语词典;平行文本;二分图;顶点配对;顶点对
1 引言
英汉汉英句子对齐平行语料库在英译汉和汉译英翻译训练、英语教学、英汉汉英词典编纂、英汉汉英计算机辅助翻译,以及围绕英汉汉英进行的各项自然语言处理工作中有着广泛的应用[1-2]。在进行短语、词汇对齐前一般也需要首先实现句子对齐。句子对齐平行语料是效用最大的平行语料[3]。
常见的句子对齐方法有三种: (1)基于句长的方法,有根据单词个数计算句长的[4],也有根据字符长度计算的[5]; (2)基于双语词汇互译信息的方法,词汇互译信息的获取有基于语料的[6-8],也有基于双语词典的[3]; (3)句长和双语词汇互译信息混合的方法[9-11]。当前双语句子对齐研究仍然基于上述三种方法[12-14]。
本文提出一个以二分图顶点配对为数学模型的、基于英汉词典的英汉平行语料句子对齐方法,简称顶点配对句子对齐方法。初衷是为解决各军事子领域平行语料规模小,用基于统计的句子对齐方法处理正确率低的问题。该句子对齐方法适用于各领域、各种规模英汉平行语料的句子对齐处理。下文第二节分析二分图模型和句子对齐的关系;第三节介绍二分图模型下句子对齐的相关研究;第四节详细阐述二分图顶点配对句子对齐方法;第五节介绍顶点配对句子对齐方法与Champollion句子对齐方法的对比实验;第六节总结全文并展望下一步工作。
2 二分图模型和句子对齐
2.1 句子对齐的二分图模型
句子对齐是一个以给定的双语对译平行文本为二分图,为原语和译语实现“最小对译句组”匹配的问题[15]。“最小对译句组”也称为句对或者句珠[4]。二分图又称二部图。设G=
2.2 二分图顶点配对与句子对齐的关系
图1“句子对齐的二分图模型”中任意一条边e=(Eni,Chj)所关联的两个顶点Eni和Chj分别属于两个不同的顶点子集(Eniin EN, Chjin CH)。边e=(Eni,Chj)也称为顶点对,找出合法的顶点对的过程叫顶点配对。理论上,顶点子集
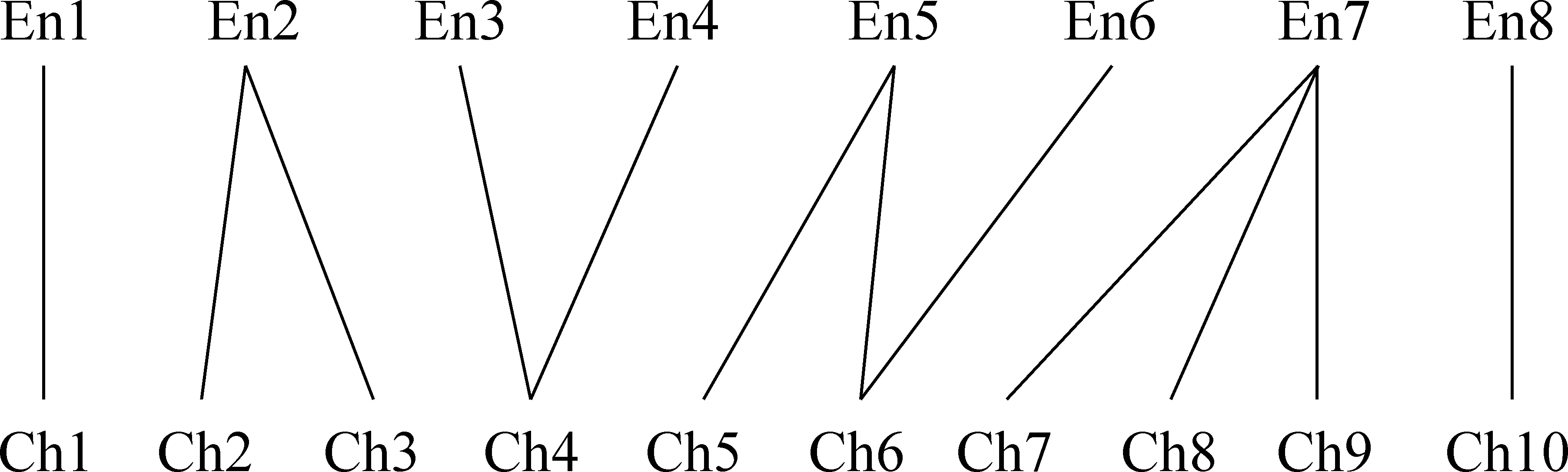
图1 句子对齐的二分图顶点配对模型
2.3 二分图匹配与句子对齐的关系
二分图匹配不同于二分图顶点配对。二分图匹配指: 如果二分图G中有边集M⊆E,且在M中任意两条边都没有公共端点,称边集M为二分图G的一个匹配。最大权重匹配就是按一定要求给E中各条边加权,存在一个M,M中的所有边的权重之和最大,这个M就是最大权重匹配[16]。句子对齐中,简单的二分图匹配提供的是1∶1类型的句对,不符合句子对齐实情,需要修正。
3 二分图模型下句子对齐相关研究
3.1 基于1∶1型句对二分图匹配的段落重组
李维刚等[17]在研究双语语料库段落重组对齐方法时利用二分图及匹配的概念对段落对齐进行了形式化描述。他们将段落重组对齐模型定义为一个二分图的“最优对齐匹配”。在寻找段落重组对齐时,句对的选取首先是根据一个基于长度的评价函数,从头向尾依次选取待对齐句子中最可能成立的1∶1型句对,选取条件是该句对的权值小于某一指定阈值;然后,再利用一个基于词典的评价函数对这样的1∶1型句对进行校验,符合词典校验的句对则成为段落重组对齐的锚点,或定位点;根据锚点实现段落重组对齐。
根据李维刚等对段落重组对齐的二分图“最优对齐匹配”模型的描述,匹配中的句对不存在一对多或交叉对应的情况,既满足二分图匹配要求,也符合段落重组对齐锚点的实际情况。以二分图匹配为模型的段落重组对齐方法在理论上和实践中均可行。
3.2 二分图最大权重匹配模型下的句子对齐
陈相、林鸿飞[18]提出以二分图最大权重匹配为模型进行句子对齐。其解决方法是: (1)以双语句子之间的相关性分值为二分图顶点之间的边加权;
(2)在基于长度的句子对齐方法基础上,利用双语中共现英语词汇、数学符号、数字及格式化表达等作为锚点,同时考虑句子在对齐文本中的位置信息,计算相关性分值; (3)根据二分图最大权重匹配获得最终对齐结果。
句子对齐与段落重组对齐不一样。句子对齐结果并非都是1∶1型的句对,对齐结果经常类似图1,有各种句对类型。陈相等考虑的句对类型仅包括传统的1∶0,0∶1,1∶1,1∶2,2∶1,2∶2六种类型。实验总体正确率92.4%, 69.8%的错误发生在非1∶1型的句对及其附近。这个统计结果在一定程度上证明,二分图最大权重匹配结果不能直接作为最终句子对齐结果,需进一步对非1∶1型句对进行甄别。
4 二分图顶点配对句子对齐方法
4.1 二分图顶点配对句子对齐方法流程
二分图顶点配对句子对齐方法整体流程如图2所示。
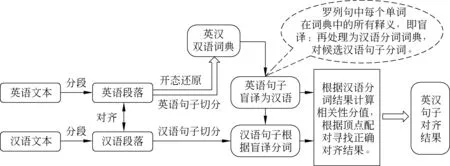
图2 二分图顶点配对句子对齐方法流程
顶点配对句子对齐方法流程中的主要步骤依次是: (1)英汉文本拆分和段落对齐; (2)英、汉句子切分; (3)英语单词形态还原; (4)根据双语词典和候选英语句子的盲译译文完成对候选汉语句子的分词; (5)利用英汉句子相关性评价函数,根据(4)的结果计算候选句对的相关性分值,为对应的二分图顶点对加权; (6)根据二分图全局范围的最大权重顶点配对结果预估临时锚点,在此基础上从系统默认的段首句对开始,结合句子顺序、英汉句长比范围和当前处理句对,重新从前向后依次评估修正每一个临时锚点,划分句对,得到最终句子对齐结果。
4.2 英汉句子相关性评价函数
本研究中英汉句子相关性评价函数仅考虑词汇互译信息。方法步骤如下: (1)将英语句子形态还原,根据词典,罗列该句每个英语单词及其原形的全部汉语词义,构成该句的盲译译文; (2)利用盲译译文中的两字和多字词语构建临时汉语分词词典,同时将盲译译文中的单个字符存入一个哈希表,再利用该汉语分词词典对候选汉语句子进行分词; (3)根据该汉语句子分词结果,结合盲译译文的单个字符哈希表,根据评价函数,计算相关性分值。
评价函数如式(1)所示。
说明:
(1) S代表候选英语句子,实际计算时先根据S得到英语句子盲译译文S′,再将S与S′合起来构成S″。T表示候选汉语句子,实际计算时T先被从S′创建的临时分词词典切分,得到T′,再参加计算,Value(S,T)是指T转换成T′后,T′中的三种类型的子字符串按一定规则与从S转换成的S″相比较所得到的相关性分值。
(2) Len(X)表示字符串X的长度。
(3) MMCh表示T′在S″中所匹配的多字汉语词语。由于T′由S″中盲译译文生成的临时分词词典进行词语切分,因此,T′中含有汉字的无空格多字符字符串(例如,“1月”)都属于MMCh多字汉语词语,分值是该字符串的长度。
(4) MSCh表示T′在S″中所匹配的单字汉语词语。单字汉语词语的识别: 先将S″的盲译译文中的单字汉语词义放到哈希表HashTemp中。比较T′与S″时,设T′中的单字汉语字符串为strTemp,如果strTemp在哈希表HashTemp中,则将其视为一个MSCh字符串,计1分,否则不计分。
(5) MCha表示T′在S″中所匹配的非汉字字符。非汉字字符对寻找正确配对贡献更大,加倍计算分值。非汉字字符通常在英语和汉语中以同一形式出现,例如,数字。正因为这个原因, S″中既有英语句子,又有其盲译译文。非汉字字符的分值计算优先。例如,对任何一个已经在S″中找到匹配的单字字符,程序先判断其是否是汉字,如果不是汉字,则计2分,如果是汉字,继续(4)中的比较。
4.3 根据顶点配对获取句子对齐结果
句子对齐结果的获取先要根据二分图全局范围内的最大权重顶点配对结果预估临时锚点,在此基础上根据多方面信息修正每一个临时锚点,划分句对,得到最终的句子对齐结果。
(1) 预估临时锚点
临时锚点的作用是通过词汇互译信息预估句子对齐二分图模型中最可能出现在句对中的边。平行文本中每对平行段落都是一个以该段落对中英语句子集
本研究按汉语句子顺序预估临时锚点。方法如下: 假设顶点对(Eni,Chj)权重为Value(Eni,Chj),针对顶点子集
En1Ch1 En2Ch2 En2Ch3 En(3|4)Ch4
En5Ch5 En6Ch6 En7Ch7 En7Ch8 En7Ch9 En8Ch10
其中En(3|4)Ch4表示En3或者En4都可能与Ch4配对,原因是图1中与其对应的原始句对是(En3,En4):Ch4。实际预估临时锚点时,哪一个顶点与Ch4配对,要视Ch4在顶点子集
(2) 修正临时锚点和划分句对
得到临时锚点序列后,接着完成下列操作: 修正临时锚点,找回未覆盖到的顶点对,划分句对。这项工作依据三条要求完成: ①句子先后顺序不能颠倒; ②预设的英汉句长比值域一般不允许逾越; ③局部最大权重顶点配对优于全局最大权重顶点配对。所谓局部最大权重顶点配对,是指为修正临时锚点或为找回未覆盖到的顶点对而在几个受限的相邻句子中获取的最大权重顶点配对。前后锚点句子顺序不对则一定有锚点错误,这时需要通过局部最大权重顶点配对重新选择最佳配对。找回未覆盖到的顶点对时,先根据句子顺序判断锚点之间是否有漏句,再根据局部最大权重顶点配对为漏句选择当前最佳配对。
英汉句长比值域用于辅助划分句对。句对划分方法: 默认每个对齐段落段首和段末的英、汉语句子分别属于该对齐段落中的第一句对和最后一个句对;句对划分从段首英、汉句子开始,一句一句依次向后,通过动态规划算法,一个句对一个句对向后划分,直到段末。根据相关统计数据,设英汉句长比的最大值是7.5,最小值是0.83。句长比值域在划分句对中的作用是: 待确定句对的句长比大于7.5则增加下一句汉语继续分析;小于0.83则增加下一句英语继续分析。
具体的句对划分主要有三种情况: ①根据对超过5 000句对的多领域英汉平行语料句子对齐结果的统计,在当前待确定句对的句长比合适,下一锚点正好是当前最大英、汉语句子序号各加1时,待确定句对是正确句对的正确率达99.853%。这个现象被作为划分句对的一条重要依据,待确定句对符合这个条件即被承认为合法句对;②在当前句对句长比合适,该句对与下一锚点间未覆盖的英语句子根据局部最大权重顶点配对应该与下一锚点的汉语句子配对时,则承认当前句对合法;③个别情况允许打破句长比值域范围: 当前待确定句对后面接连出现两个序号紧密相连的作为锚点的顶点对时,值域不再起约束作用。例如,在锚点序列片断En3Ch2 En4Ch3 En5Ch4中,如果待确定句对是En3Ch2,即使En3与Ch2的句长比超出值域,也认可En3Ch2是合法句对。这种情况在古诗英译时可能出现。
4.4 顶点配对句子对齐方法特点
顶点配对句子对齐方法有如下特点: (1)充分利用基于词汇互译信息的最大权重顶点配对结果,分两步走,实现句子对齐; (2)不限制句对类型,实践中曾以很高的正确率召回1∶5,1∶6,1∶7,1∶8,2∶2,……,2∶6,5∶2等类型的句对; (3)段落是重要的语言单位[21],该方法保留了段落标记; (4)利用英汉双语词典对汉语句子进行分词。
5 实验及结果
本实验利用公开语料对比顶点配对句子对齐方法与Champollion-1.2句子对齐系统。选择Champollion进行对比的原因是: (1)Champollion也是基于英汉词典的句子对齐方法; (2)Champollion 是当前基于英汉词典的开源句子对齐工具中较好的系统[19-20],得到了广泛认可。
5.1 语料选取
选取的语料是2009年奥巴马就职演说的全文及翻译,以及从百度文库下载的“全新版大学英语综合教程3课文原文及翻译.doc”中选取的三篇完整的课文及翻译,它们分别是第一单元的A篇、第三单元的B篇和第六单元的B篇。根据统计,后两篇是上述教材在基于大词典的顶点配对方法下出现句子对齐错误最多的课文。
5.2 语料预处理
顶点配对句子对齐方法中,英语句子以英语的句号、问号、感叹号和冒号为界,汉语句子以汉语的句号、问号、感叹号、冒号和分号为界。句子切分在段落对齐后、在预估临时锚点前自动实现。英语形态还原、汉语分词均在预估临时锚点过程中自动处理。
Champollion对语料预处理有不同的要求。Champollion中语料需要事先处理成一句占一行的格式,中间不能有空行。本实验中,Champollion的语料完全按顶点配对句子对齐方法的句子边界识别方法对英、汉文本进行句子边界识别,这样保证了本实验两种句子对齐方法中的平行语料的句子切分结果完全一致,最后的对齐结果不受句子切分结果影响。其他方面,Champollion内嵌有自己的形态还原方法,自带了第三方的汉语分词插件,在对齐过程中自动实现形态还原和汉语分词。
5.3 英汉词典的准备
(1) 大词典: 由多部电子词典合成,英语单词236 374个,汉语词义678 167个。含大量专业术语。
(2) 小词典: Champollion原型系统的词典,同时转换成顶点配对句子对齐方法所要求的双语词典格式。词典中英语单词4 885个,汉语词义41 814个。含大量常用单词及词义。
5.4 句子对齐结果
表1是本实验中的语料分别以Champollion系统和基于大词典、基于小词典的顶点配对方法实现句子对齐后的正确率、召回率和F值。相关公式如式(2)~式(4)所示。
从表1数据来看Champollion和顶点配对句子对齐方法的对齐结果: 基于大词典的顶点配对句子对齐方法的正确率、召回率和F值最高,后期需要的人工校对工作量最少;基于小词典时,顶点配对句子对齐方法比Champollion句子对齐方法略好,不过没有显著差异。但是,顶点配对句子对齐方法保留了原来的段落结构,对齐后的语料适用范围更广。
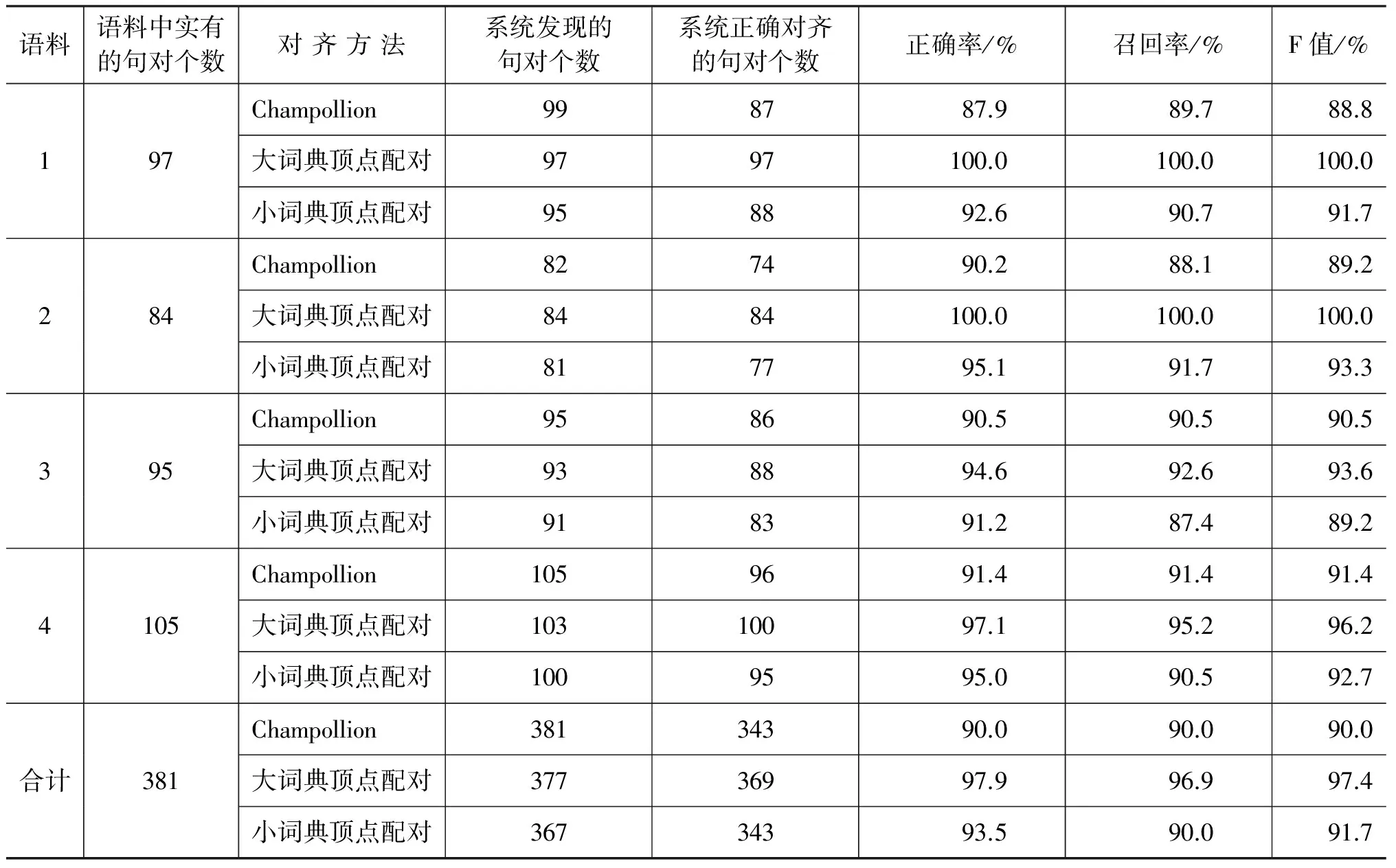
表1 Champollion和顶点配对句子对齐方法对齐结果比较
注: 语料1是2009年01月21日奥巴马就职演说全文;语料2、3和4分别是全新版大学英语综合教程3第一单元A篇、第三单元B篇和第六单元B篇的课文原文及翻译。
我们还在实践中利用基于大词典的顶点配对句子对齐方法处理了大量非公开语料。对其中一份长语料的统计是: 英语单词115 497个,句子5 257句;汉字200 108个,句子5 069句;句对4 696对;句子对齐结果中1: 1类型句对的正确率99.8%,总体正确率99.2%。
6 结论
基于双语词典的句子对齐算法有很多种。本研究以二分图顶点配对为模型,首先基于英汉词典,利用完全基于词汇互译信息的英汉句子相关性评价函数为顶点对加权,获得全局最大权重顶点配对信息,然后根据句子顺序、局部最大权重顶点配对信息和英汉句长比值域,获得英汉平行语料的句子对齐处理。从实验对比结果来看,该句子对齐方法在大容量英汉词典支持下明显优于Champollion原型系统;在词典规模与Champollion原型系统完全一致时,该句子对齐方法略优,无显著差异。该句子对齐方法是可行的。本研究在利用词汇互译信息时,仅考虑了单个英语单词对应的汉语译文信息,下一步可以针对英语词组和短语,建设英汉短语词典,研究如何在句子对齐处理中利用短语互译信息,进一步改进句子对齐算法。
[1] 孙乐, 金友兵, 杜林, 等. 平行语料库中双语术语词典的自动抽取[J], 中文信息学报, 2000, 14(6): 33-39.
[2] 李莉, 刘知远, 孙茂松. 基于中英平行专利语料的短语复述自动抽取研究[J], 中文信息学报, 2013, 27(6): 151-157.
[3] Ma, Xiaoyi. Champollion: A robust parallel text sentence aligner[C]//Proceedings of the LREC 2006: Fifth International Conference on Language Resources and Evaluation.2006: 489-492.
[4] Brown P F, Jennifer C Lai, Robert L. Mercer. Aligning Sentences in Parallel Corpora[C]//Proceedings of the 29th Annual Meeting of the Association for Computational Linguistics, Berkeley, California, 1991: 169-176.
[5] Gale W A, Church K W. A program for Aligning Sentences in Bilingual Corpora[C]//Proceedings of the 29th Annual Meeting of the Association for Computational Linguistics, Berkeley, California, 1991: 177-184.
[6] Kay M, M Roscheisen. Text-Translation Alignment[J].Computational Linguistics, 1993, 19(1): 121-142.
[7] Chen S F Aligning Sentence in Bilingual Corpora Using Lexical Information[C]//Proceedings of the 31st Annual Meeting of the Association for computational Linguistics (ACL '93),Columbus, Ohio, USA, 1993: 9-16.
[8] Moore R C. Fast and Accurate Sentence Alignment of Bilingual Corpora[C]//Proceedings of Machine Translation: From Research to Real Users, Springer, 2002: 135-144.
[9] Wu, Dekai. Aligning a Parallel English-Chinese Corpus Statistically with Lexical Criteria[C]//Proceedings of ACL 31.1994: 80-87.
[10] Tan, Chew Lim and Makoto Nagao. Automatic alignment of Japanese-Chinese bilingual texts[J].IEICE Transactions on Information and Systems, 1995, E78-D(1): 68-76.
[11] 张艳, 柏冈秀纪. 基于长度的扩展方法的汉英句子对齐[J]. 中文信息学报, 2005, 19(5): 31-36.
[12] 张亚军, 贺琛琛, 香丽芸. 限定领域的汉语-维吾尔语句子级对齐研究[J]. 软件, 2014, 35(3): 62-64.
[13] 邵健, 章成志. 从互联网上自动获取领域平行语料[J]. 现代图书情报技术, 2014, 253(12): 36-42.
[14] 刘颖, 王楠. 古汉语与现代汉语句子对齐研究[J]. 计算机应用与软件, 2013, 30(11): 127-130.
[15] Braune F, Alexander Fraser. Improved unsupervised sentence alignment for symmetrical and asymmetrical parallel corpora[C]//Proceedings of the COLING 2010: Poster Volume, Beijing, 2010: 81-89.
[16] 魏雪丽. 离散数学及其应用[M]. 北京: 机械工业出版社, 2008,4.
[17] 李维刚, 刘挺, 王震, 李生. 双语语料库段落重组对齐方法研究[C], 哈尔滨工业大学信息检索研究室论文集, 2003: 67-73.
[18] 陈相, 林鸿飞. 基于锚信息的生物医学文献双语摘要句子对齐[J]. 中文信息学报, 2009, 23(1): 58-62.
[19] Li Peng, Sun Maosong, Xue Ping. Fast-Champollion: A Fast and Robust Sentence Alignment Algorithm[C]//Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China, 2010: 710-718.
[20] 熊文新. 英汉环保领域平行语料的句对齐与再对齐[J]. 现代图书情报技术, 2013(6): 36-41.
[21] 梁茂成, 许家金. 双语语料库建设中元信息的添加和段落与句子的两级对齐[J]. 中国外语, 2012, 9(6): 37-42.
Sentence Alignment Under A Bipartite Graph Vertex Pairing Model
YAN Canxun
(Language Engineering Department, PLA Foreign Languages Institute, Luoyang, Henan 471003, China)
Pairing vertices properly in a bipartite graph can be taken as a model for the bilingual sentence alignment. The vertex pairs in the bipartite graph can be weighted with a totally bilingual-dictionary-based evaluation function which evaluates the word correspondences between an English sentence and a Chinese sentence. In our appoach, the globally-maximum-weighted vertex pairs are first chosen as temporary anchors. Then, based on the temporary anchors, the results of the locally-maximum-weighted vertex pairs and the range of the ratio of English and Chinese sentence lengths, the mistakes in the original anchor vertex pairs are corrected and the missing vertex pairs are supplemented. Meanwhile, the sentences in the bipartite graph are simultaneously grouped into minimal groups of corresponding sentences. The comparison experiments show that the vertex-pairing sentence alignment approach works better than the Champollion sentence alignment system.
sentence alignment; bilingual dictionary; parallel text; bipartite graph; vertex pairing; vertex pair

严灿勋(1971—),博士,副教授,主要研究领域为语言信息处理研究。E⁃mail:yancanxun@126.com
1003-0077(2016)05-0153-07
2015-02-13 定稿日期: 2015-04-14
中央文献对外翻译与传播协同创新中心科学研究项目(2013XT08)
TP391
A
