基于翻译模型和语言模型相融合的双语句对选择方法
2016-05-04姚建民
姚 亮,洪 宇,刘 昊,刘 乐,姚建民
(苏州大学 江苏省计算机信息处理重点实验室,江苏 苏州 215006)
基于翻译模型和语言模型相融合的双语句对选择方法
姚 亮,洪 宇,刘 昊,刘 乐,姚建民
(苏州大学 江苏省计算机信息处理重点实验室,江苏 苏州 215006)
双语句对选择方法旨在从大规模通用领域双语语料库中,自动抽取与待翻译文本领域相关性较高的句对,以缓解特定领域翻译模型训练语料不足的问题。区别于原有基于语言模型的双语句对选择方法,该文从句对生成式建模的角度出发,提出一种基于翻译模型和语言模型相融合的双语句对选择方法。该方法能够有效评价双语句对的领域相关性及互译性。实验结果显示,利用该文所提方法选择双语句对训练所得翻译系统,相比于基准系统,在测试集上性能提升3.5个BLEU值;此外,针对不同句对质量评价特征之间的权重调节问题,该文提出一种基于句对重排序的特征权重自动优化方法。基于该方法的机器翻译系统性能继续提升0.68个BLEU值。
双语句对选择;生成式建模;翻译模型;语言模型;权重调节
1 引言
面向特定领域的统计机器翻译(Statistical Machine Translation,SMT)系统依赖于充分规模且质量较好的目标领域双语语料,当训练语料和测试文本的领域分布不一致时,翻译系统的性能往往较低。原因在于,特定领域中包含较多的专业术语,但从其他领域的训练数据中无法获得这类专业术语的有效翻译知识。例如,给定待翻译句子 “Youhavetosubmityourapplicationtothewebbeforedeadline.”,如果训练数据属于教育领域,机器翻译系统很大程度上会将“application”译为“申请”;反之,若训练数据属于计算机领域,那么机器翻译系统则倾向于将“application”译为“应用程序”。另一方面,在特定领域中,句子的表述方式和语言风格也与其他领域有着巨大差异。例如,待翻译句子为: “我 感到 很热”。若训练语料来自口语领域,则机器翻译系统会倾向于译文“Ifeelsohot”;反之,若训练语料来自专业文学领域,那么机器翻译系统将倾向于译文“I’mburningup”。
针对上述机器翻译中的领域适应性问题,现有研究方法大致分为三类: 1)基于Web自动获取特定领域双语语料[1-3]; 2)基于翻译模型特征优化的机器翻译领域适应性研究[4-6]; 3)基于句对选择的机器翻译领域适应性研究[7-13]。其中,基于句对选择的机器翻译领域适应性研究方法,旨在从大规模通用领域双语语料中选择与待翻译文本领域相关性较高的句对,用以提升训练集中特定领域翻译知识的含量,或构建专属的领域双语知识库,并最终用于训练特定领域机器翻译系统。现有基于句对选择的机器翻译领域适应性研究方法,多从判别模型的角度出发,利用语言模型困惑度估计双语句对属于目标领域的概率。此类方法主要考虑句对的领域相关性,忽略了句对在目标领域的互译性。例如,如下基于语言模型方法抽取的双语句对样例: “ifismoke?”,“你 是否 介意 ?”该句对的源端和目标端句子均来自口语领域,但句对的互译质量较差,难以为训练翻译模型提供有效的翻译知识。此外,针对句对选择方法中使用的各种语言特征或统计特征,现有方法通常基于人工经验调节它们的权重。基于人工先验知识的参数调节方法,效率较低,且难以获得最优值。
针对上述研究问题,本文提出一种语言模型和翻译模型相融合的特定领域双语句对选择方法。该方法首先利用目标领域语言模型评价源语言句子的领域相关性;其次,利用领域内语料训练的翻译模型评价目标领域下双语句对的互译性,并融合二者得分获取双语句对在目标领域下的生成概率;最终,得分较高的双语句对将会被优先选择,用以扩充特定领域训练集。此外,本文进一步融合不同方向的语言模型特征或翻译模型特征,用于选择领域相关的双语句对,并提出一种基于句对重排序的特征权重自动优化方法。该方法首先标注一部分来自目标领域且互译质量较好的句对,并利用启发式搜索策略自动调节不同特征之间的权重,最终使得人工标注的双语句对在全部句对中的排序尽量靠前。实验中,利用本文方法选择双语句对训练获得的机器翻译系统,相比于基准系统,在测试集上BLEU值提升3.5个百分点。此外,利用基于句对重排序的模型权重优化方法优化权重后所得翻译系统,BLEU值进一步提升0.68个百分点。
本文章节组织如下: 第二节介绍相关工作;第三节提出面向特定领域的双语句对选择方法;第四节提出基于句对重排序的特征权重自动优化方法;第五节给出实验结果和分析;第六节总结工作并提出未来展望。
2 相关工作
基于句对选择的机器翻译领域适应性相关工作主要可分为以下两类。
1) 基于Web自动获取特定领域双语语料。Pecina等[1]提出基于聚焦爬虫自动获取特定领域双语语料的方法,该方法利用聚焦爬虫计算网页与目标领域相关性,并基于预先设定阈值对网页进行二值分类,最终在目标领域网页中抽取双语平行文本。刘昊等[2]提出一种基于全局搜索和局部分类的特定领域双语网站识别方法。该方法首先利用目标领域双语短语对构造查询,并基于搜索引擎的返回结果获取候选领域双语网站。其次,该方法融合领域性特征和双语网站结构特征,构造二元分类器,用以过滤非目标领域的候选双语网站。最终从候选双语网站中抽取双语句对。然而,Rarrick等[3]指出从Web自动获取的双语网站中抽取的双语句对的质量千差万别,利用质量较差的双语句对不但不能提升翻译性能,反而引入更多的噪声和错误。因此,利用该方法获取的特定领域双语语料仍需进一步的筛选和分类。
2) 基于双语句对选择的机器翻译领域适应性研究。该方法旨在从大规模本地平行语料库中自动抽取与测试集领域相关的句对,用以训练特定领域机器翻译系统。Lü等[7],黄瑾等[8]提出一种基于信息检索的双语句对选择方法,该方法利用测试集句子作为查询,从通用语料库中检索与测试集语料较为相关的句对。Yasuda等[9]提出基于目标领域语言模型困惑度评价并选取双语句对的方法。Moore等[10],Axelrod等[11]分别利用目标领域和通用领域语言模型计算句子的交叉熵得分,并基于交叉熵的差值选择句对。Haddow等[12]同样利用语言模型困惑度评价通用领域句对的领域相关性,并将选择的双语句对运用于翻译系统的词对齐、短语抽取以及短语打分等阶段,以评价其对翻译性能的影响。Duh等[13]继承Axelrod等[11]的方法,并利用神经网络语言模型计算交叉熵,以缓解n元文法语言模型存在的数据稀疏问题;此外,针对通用翻译系统中的双语句对选择问题,姚书杰等[14]提出一种基于句对质量和覆盖度的双语句对选择方法,该方法基于人工设定的权重融合多种特征得分评价句对质量,选择得分较高的句对,并基于N-gram覆盖度进一步过滤冗余的句对。王星等[15]提出一种基于分类的平行语料选择方法,通过少数句对特征构造差异较大的分类器,以区分双语句对的质量。上述基于双语句对选择的机器翻译领域适应性研究方法,虽然取得较好的效果,但仍存在以下不足。首先,该类方法仅考虑句对的领域相关性,但忽略句对在目标领域中的互译性。因此,利用此类方法选择的双语句对,其互译质量可能较差,从而为后续翻译模型的训练带来噪声。其次,现有研究方法中不同句对质量评价特征之间的权重依赖于人工经验调节,无法获得最佳性能。
基于此,本文提出一种翻译模型和语言模型相结合的双语句对选择方法。该方法既考虑句对与目标领域的相关性,又兼顾领域相关句对的互译质量,从而有效地提升了选择句对的质量;其次,本文进一步提出一种基于句对重排序的特征权重自动优化方法,规避了基于人工经验设定权重的句对选择结果的影响。
3 双语句对选择方法
本文从句对生成式建模的角度出发,融合目标领域语言模型和翻译模型,用以评价双语句对质量(即领域相关性和互译性)。分别提出基于翻译模型、基于翻译模型和语言模型相结合、基于双向翻译模型和语言模型的三种具体句对选择方法,用以从大规模通用领域双语语料中选择与目标领域相关的句对。
3.1 基于翻译模型的句对选择方法
翻译模型是统计机器翻译系统的核心组成部分,通常用于评价句对(或短语对)的互译概率。本文提出一种基于IBM Model 1[16]的句对质量评价方法。该方法首先利用小规模目标领域双语语料统计单词之间共现频率,用以获取IBM Model 1中的词汇翻译模型;其次,利用获得的基于词的翻译模型对大规模通用领域双语句对打分;最终,基于双语句对得分对全部句对进行排序,并从中选择排序靠前的双语句对子集。
基于上述方法,本文基于IBM Model 1评价双语句对质量,具体如式(1)、式(2)所示。
其中,P(e|f)表示利用IBM Model 1词翻译模型计算获得的源语言句子f翻译成目标语言句子e的条件概率。t(ej|fi)表示单词fi翻译成单词ej的条件概率,利用目标领域双语语料统计信息估计得到。lf和le分别表示源语言和目标语言句子长度,∈表示归一化常量,由于它不影响句对排序结果,因此此处将其赋值为1。R表示长度归一化的IBM Model 1翻译概率,用于评价通用领域句对的质量。
3.2 融合翻译模型和语言模型的句对选择方法
本文从生成式建模角度出发,估计在目标领域下双语句对的生成概率,并基于此排序和选择领域相关的双语句对。本文首先利用目标领域单语语料训练n元文法语言模型,并依据语言模型困惑度得分评价源语言句子的领域性;其次,利用目标领域双语语料统计单词之间的共现频率,用以估计IBM Model 1翻译模型参数,进而获得句对在该领域下的互译概率;最终,从生成式建模的角度出发,融合语言模型和翻译模型得分,用以评价双语句对在目标领域下的生成概率。具体如式(3)、式(4)所示。
其中,P(e|f)表示句对
3.3 融合双向翻译模型与语言模型的句对选择方法
本文3.2节提出从生成式建模角度出发,融合语言模型和翻译模型评价双语句对的质量。但是,该方法仅利用源端语言模型和源端到目标端翻译模型评价句对的质量。基于此,本文进一步利用目标端语言模型和目标端到源端翻译模型评估句对的生成概率。进而整合不同方向的领域特征,对双语句对质量进行综合评价。其次,由于面向不同语言翻译任务时(例如,英—汉或汉—英),不同方向的领域特征对句对质量评价的重要程度不同,本文为它们分别设置不同的权值。具体如式(5)所示。
(5)
其中,R表示融合不同方向领域特征评价句对质量的模型。λ1和λ2分别表示不同方向领域特征的权值,利用下文所提特征权重优化方法获得。
4 基于句对重排序的特征权重优化方法
本文提出一种基于句对重排序思想自动优化不同领域特征权重的方法,该方法核心思想如下: 首先,在目标领域训练语料中人工标注一部分领域相关性高、对齐质量较好的句对(规模为: n对),并与大规模通用领域平行句对(规模为: m对)合并;其次,利用式(5)中的双语句对选择方法对全部句对(规模为: m+n对)打分并排序;最终,通过启发式的搜索算法,寻找最优特征权重,使得人工标注质量较好的句对在全部句对中排序位置尽量靠前。
上述方法的关键是通过调节特征权重对全部句对进行重排序,使得人工标注句对的排序位置尽量靠前,因此需要定量表示不同权重下的排序结果。本文类比信息检索中相关文档的平均准确率MAP(Mean Average Precision)[17],定义人工标注句对的平均准确率,用以量化表示句对的排序结果。相关文档的平均准确率是指,检索返回结果中每篇相关文档位置上的准确率均值。平均准确率越高,相关文档的排序位置越靠前,检索性能也越好。相关文档的平均准确率定义如式(6)所示。
(6)
其中n表示相关文档总数,posi表示第i个相关文档的排序位置,ri表示前posi个排序结果中相关文档的数目。
本文首先将人工标注的双语句对类比成信息检索中的相关文档,将其他来自通用领域的双语句对类比成信息检索中的不相关文档,并利用式(6)计算人工标注句对的平均准确率。显然,人工标注句对的平均准确率越高,其排序位置越靠前。其次,利用人工标注的双语句对作为参照,通过自动调节不同方向领域特征的权重,使得人工标注句对的平均准确率不断提升,即使得它们的排序位置尽量靠前。由于人工标注句对来自于目标领域且对齐质量较好。因此,优化特征权重后的句对选择方法会倾向于选择类似的双语句对,即与目标领域比较相关同时互译性较好的双语句对。
基于上述思想,本文提出基于句对重排序的特征权重搜索算法,该算法基于人工标注句对的平均准确率,定义错误率指标err,用以评价人工标注句对的排序情况。错误率指标的定义如式(7)所示。
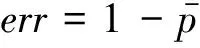
(7)
本文提出的基于句对重排序的特征权重搜索算法属于迭代算法,算法的具体描述如表1所示。

表1 基于句对重排序的特征权重搜索算法
基于上述算法,本文获取不同方向领域特征的权重,进而对通用领域的双语句对进行打分和排序,最终选择排序靠前的TopN双语句对子集用以扩充目标领域翻译系统训练集。
5 实验与结果分析
5.1 语料配置
本文实验面向口语领域翻译任务,目标领域语料采用CWMT09官方提供的旅游口语平行语料(规模为: 50k句);通用领域语料为利用Liu等[18]所提基于链接的平行网页对识别方法,在Web中自动获取所得平行语料(规模为: 16m),该语料领域分布较为混杂。所有语料配置具体如表2所示。
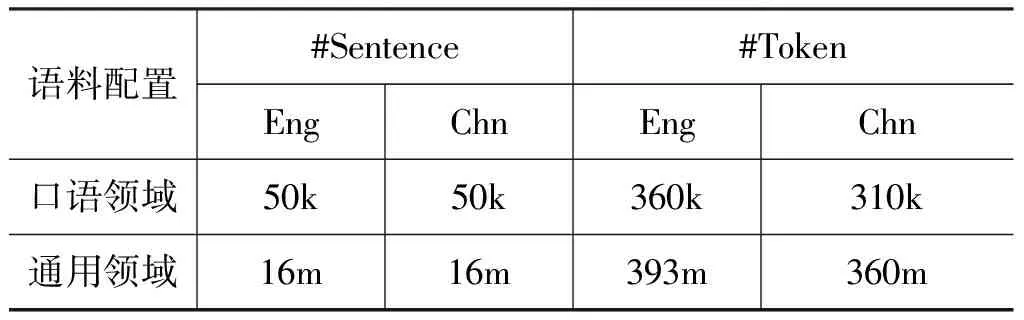
表2 语料统计信息
本文实验使用NiuTrans[19]机器翻译引擎搭建口语领域英到汉的层次短语翻译系统,系统的语料配置如下。
• 翻译模型训练语料是利用本文所提双语句对选择方法从通用领域平行语料中选择所得TopN句对子集;
• 语言模型训练语料取自本地汉语单语语料(规模为: 1 350k句);
• 翻译系统的开发集使用2005年“863”口语翻译任务的开发集,包含456英文句子和对应四个中文翻译结果;
• 翻译系统的测试集使用2004年“863”口语翻译任务的测试集,包含400个英文句子和四个中文翻译结果。
5.2 系统设置
本文实验采用NiuTrans[19]开源机器翻译系统,该系统融合GIZA++[20]工具实现双语句对词对齐,并从词对齐的平行句对中抽取层次短语翻译规则。针对双语句对选择任务,本文采用SRILM工具[21]获取目标领域4-gram语言模型,用以估计通用领域双语句对与目标领域的相关性。同时,本文借助小规模目标领域平行语料的词对齐信息,获取该领域词汇翻译概率表,用以估计特定领域下双语句对的互译概率。
本文搭建口语领域英语到汉语层次短语翻译系统,该系统基于最小错误率训练方法[22]优化翻译系统权重,并采用BLEU[23]值作为评价指标。本文设置如下八个翻译系统,以验证本文所提方法的有效性。
Baseline1: 利用通用领域16m句对训练翻译模型,所得机器翻译系统。
Baseline2: 利用CWMT口语领域约50k句对训练翻译模型,所得机器翻译系统。
Baseline3: 从通用领域中随机抽取50k句对训练翻译模型,所得机器翻译系统。
Lv_2007: 利用Lü等[7]提出的基于信息检索的句对选择方法,从通用领域句对中选择TopN句对子集训练翻译模型,所得机器翻译系统。
Duh_2013: 利用Duh等[13]方法,从通用领域句对中选择TopN句对子集训练翻译模型,所得机器翻译系统。
TM: 利用本文所提基于翻译模型的方法,从通用领域中选择TopN句对子集训练翻译模型,所得机器翻译系统。
TM_LM: 利用本文所提融合翻译模型和语言模型的方法,从通用领域中选择TopN句对子集训练翻译模型,所得机器翻译系统。
Bidirectional TM+LM: 将不同方向翻译模型和语言模型的特征权重均设为0.5,用以评价通用领域句对质量,并选择TopN句对子集训练翻译模型,所得机器翻译系统。
Tune_Bi_TM+LM: 利用本文所提特征权重优化方法调节不同方向领域特征的权重,并基于此评价通用领域句对质量,选择TopN句对子集训练翻译模型,所得机器翻译系统。
5.3 实验结果及分析
• 基线系统
本文构建的基线系统性能如表3所示。Baseline1,Baseline2,Baseline3语言模型均采用本地汉语单语语料训练(规模为: 1 350k句)。
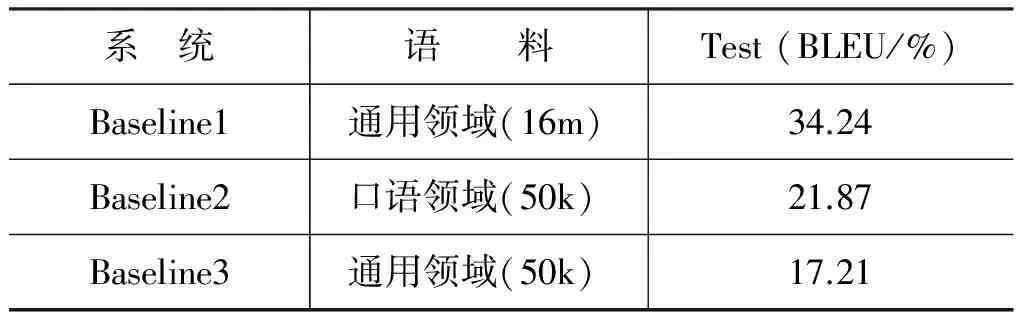
表3 Baseline系统翻译性能
实验结果表明,利用大规模通用领域平行语料训练的翻译系统(Baseline1)相比利用目标领域平行语料训练的翻译系统(Baseline2),在相同的测试集上BLEU值提升了12个百分点。原因在于,大规模通用领域平行语料覆盖更多的翻译知识和语言现象;而特定领域平行语料由于规模较小,容易发生数据稀疏问题,从而导致翻译系统的性能较低。另外,从通用领域中随机抽取与Baseline2等规模的双语句对训练所得翻译系统(Baseline3)的性能明显低于Baseline2。这一现象说明,与待翻译文本领域一致的训练语料要优于领域相对混杂的训练语料。原因在于,特定领域中存在较多的专业术语以及较为独特的语言表达方式,从其他领域的双语语料中难以有效学习这类专业用语或语言现象的翻译知识。综上所述,本文从通用领域双语语料中抽取与待翻译文本领域一致的训练语料,用以扩充目标领域翻译系统训练集,是切实可行的。
• 双语句对选择方法
实验利用本文所提特定领域双语句对选择方法,对通用领域的平行句对打分并排序,依次选取排序Top N={50k,100k,200k,400k,600k,800k,1000k}的句对子集训练目标领域机器翻译系统。系统在测试集上的实验性能如图1所示。
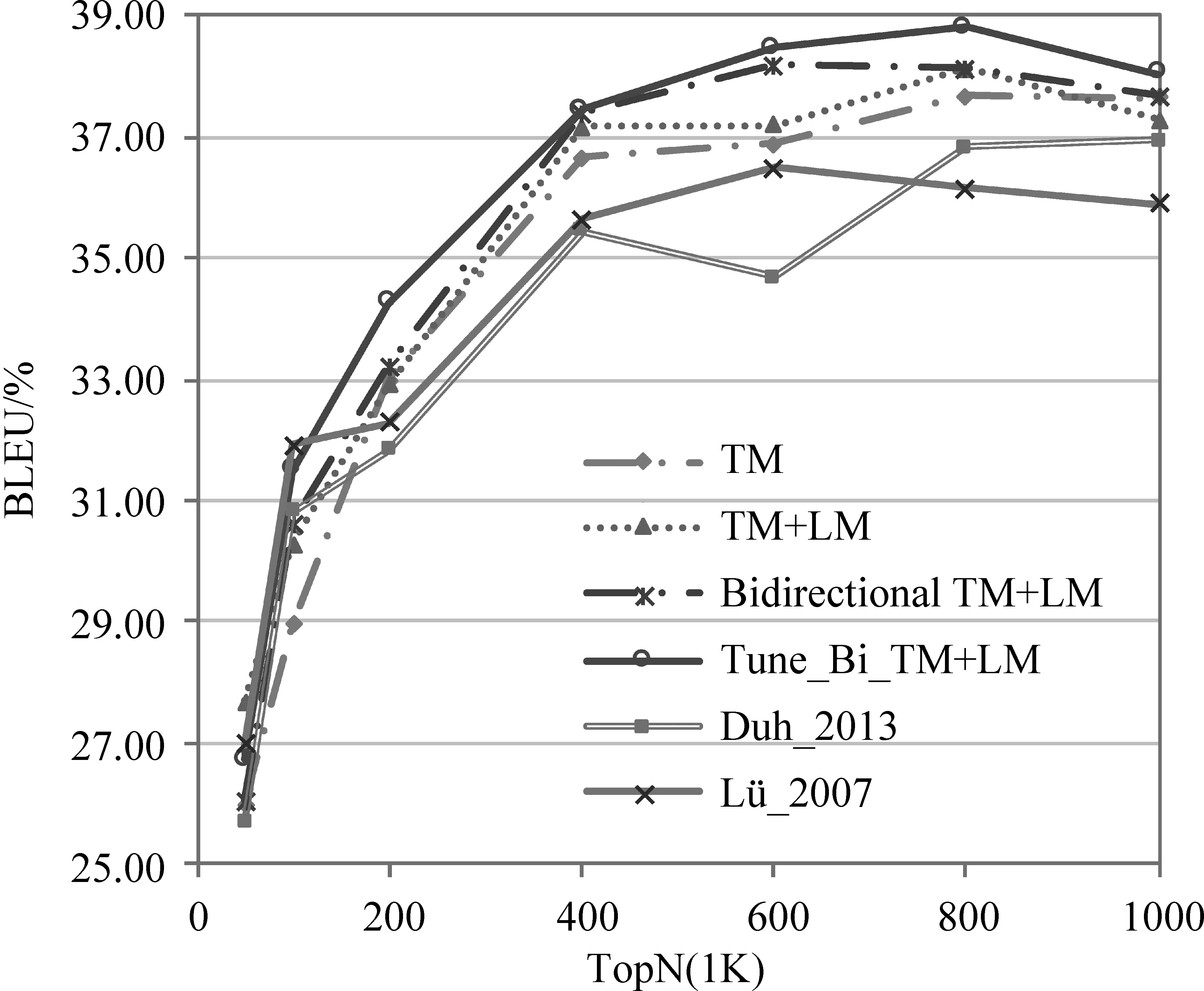
图1 机器翻译系统性能
图1为利用所提方法从通用领域选择排序TopN句对训练获得机器翻译系统的性能。其中,横坐标表示选取句对的规模(单位为: 1k),纵坐标表示训练获取机器翻译系统的BLEU值。
实验结果表明,本文提出的双语句对选择方法对改善特定领域机器翻译性能是有效的。当仅从通用领域平行语料中选择Top400k的句对子集训练机器翻译系统时,系统在测试集上的性能优于使用全部的通用领域平行语料(规模为: 16m)。这一现象说明,机器翻译系统训练语料的规模并非越大越好。原因在于,通用领域平行语料库中包含各个领域的训练数据,利用其抽取的翻译规则中可能存在较多的噪声,导致翻译系统难以有效地选取适合目标领域的翻译结果。因此训练语料规模增大时,翻译性能反而下降。此外,实验结果表明,当目标领域训练数据相对较少时,从通用领域平行语料汇总选择领域相关较高的句对有助于提升机器翻译系统的性能。
面向口语领域翻译任务时,相比使用通用领域语料训练的Baseline1系统,TM方法仅选择Top800k句对子集,但在测试集上的性能提升了3个百分点;同时,TM+LM和Bidirectional TM+LM方法的性能分别提升了3.52和3.5个百分点。相比主流的基于语言模型的句对选择方法Duh_2013,TM方法在测试集上性能提升0.87个百分点;同时,TM+LM和Birectional TM+LM方法的性能分别提升了1.32和1.3个百分点。相比基于信息检索的句对选择方法Lü_2007,TM方法在测试集上提升1.2个百分点;同时,TM+LM和Birectional TM+LM方法的性能分别提升了1.65和1.63个百分点。虽然,如图1所示,本文所提方法的在测试集上的性能并非一直优于现有方法,但本文方法在整体上有着显著的优势。这表明,融合翻译模型和语言模型的双语句对选择方法,相比现有双语句对选择方法,能有效地提升选择双语句对的质量。原因在于,通过融合翻译模型和语言模型等领域特征,本文所提方法既能保证双语句对的领域相关性,又能有效地保证选取的双语句对具有较好的互译性。此外,Birectional TM+LM方法同时兼顾了源语言句子和目标语言句子的质量。
实验结果还表明,相比Birectional TM+LM方法,优化模型权重后的Tune_Bi_TM+LM方法,在测试集上的性能进一步提升0.68个百分点,且优于本文其他方法。原因在于,利用双向翻译模型和语言模型选择双语句对,能够解决由于词汇翻译概率估计偏差导致某些质量较差的句对得分较高的问题。在合理设置不同方向权重的情况下,本文方法能够有效地减少这种错误,从而保证选择的句对质量较优,最终有利于提升翻译系统的性能。
6 总结与展望
本文提出翻译模型和语言模型相融合的双语句对选择方法。相比于基准系统,利用本文所提方法选择句对训练所得特定领域机器翻译系统,在测试集上BLEU值提升了3.5个百分点。此外,本文进一步提出基于句对重排序的特征权重优化方法,利用该方法优化后的系统,在测试集上BLEU值进一步提升0.68个百分点。
在未来工作中,本文尝试提出更多有效的领域特征用以选择特定领域双语句对。另外,本文方法仅从统计角度,通过融合翻译模型和语言模型特征得分选择双语句对,忽略了句对本身蕴涵的语义信息。因此,未来工作中可进一步融合句对的语义信息,如采用主题模型或神经网络等方法评价和选择双语句对。
[1] Pavel P, Antonio T, Andy W, et al. Towards using web-crawled data for domain adaptation in statistical machine translation[C]//Proceedings of the 15th Annual Conference of the European Association for Machine Translation.2011: 297-304.
[2] 刘昊, 洪宇, 刘乐等. 基于全局搜索和局部分类的特定领域双语网站识别方法[C]. 第二十届全国信息检索学术会议(CCIR). KunMing, China, 2014.
[3] SpencerRarrick, Chris Quirk, Will Lewis. MT detection in web-scraped parallel corpora[C]//Proceedings of the Machine Translation Summit.2011: 422-429.
[4] Su J, Wu H, Wang H, et al. Translation model adaptation for statistical machine translation with monolingual topic information[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2012: 459-468.
[5] Foster G,Goutte C, Kuhn R. Discriminative instance weighting for domain adaptation in statistical machine translation[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2010: 451-459.
[6] Sennrich R, Schwenk H, Aransa W. A Multi-Domain Translation Model Framework for Statistical Machine Translation[C]//Proceedings of the 51th Annual Meeting of the Association for Computational Linguistics.2013: 832-840.
[7] Lü, Yajuan, Jin H, Qun L. Improving Statistical Machine Translation Performance by Training Data Selection and Optimization[C]//Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational, 2007: 343-350.
[8] 黄瑾, 吕雅娟, 刘群. 基于信息检索方法的统计翻译系统训练数据选择与优化[J]. 中文信息学报, 2008, 22(2): 40-46.
[9] Yasuda K, Zhang R, Yamamoto H, et al. Method of Selecting Training Data to Build a Compact and Efficient Translation Model[C]//Proceedings of the IJCNLP.2008: 655-660.
[10] Moore R C, Lewis W. Intelligent selection of language model training data[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2010: 220-224.
[11] Axelrod A, He X,Gao J. Domain adaptation via pseudo in-domain data selection[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2011: 355-362.
[12] Haddow B, Philipp K. Analysing the effect of out-of-domain data on SMT systems[C]//Proceedings of the Seventh Workshop on Statistical Machine Translation. Association for Computational Linguistics, 2012: 422-432.
[13] Duh K,Neubig G, Sudoh K, et al. Adaptation Data Selection using Neural Language Models: Experiments in Machine Translation[C]//Proceedings of the 51th Annual Meeting of the Association for Computational Linguistics.2013: 678-683.
[14] 姚树杰, 肖桐, 朱靖波. 基于句对质量和覆盖度的统计机器翻译训练语料选取[J]. 中文信息学报, 2011, 25(2): 72-77.
[15] 王星, 涂兆鹏, 谢军, 等. 一种基于分类的平行语料选择方法[J]. 中文信息学报, 2013, 27(6): 144-150.
[16] Brown P F,Pietra V J D, Pietra S A D, et al. The mathematics of statistical machine translation: Parameter estimation [J]. Computational linguistics, 1993, 19(2): 263-311.
[17] Buckley C, Voorhees E M. Evaluating evaluation measure stability[C]//Proceedings of the 23rd annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2000: 33-40.
[18] Liu L, Hong Y, Lu J, et al. An Iterative Link-based Method for Parallel Web Page Mining [C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics.2014: 1216-1233.
[19] Xiao T, Zhu J, Zhang H, et al. NiuTrans: an open source toolkit for phrase-based and syntax-based machine translation[C]//Proceedings of the ACL 2012 System Demonstrations. Association for Computational Linguistics, 2012: 19-24.
[20] Och F J, Ney H. A systematic comparison of various statistical alignment models [J]. Computational linguistics, 2003, 29(1): 19-51.
[21] Andreas Stolcke. SRILM-an extensible language modeling toolkit[C]//Proceedings of the International Conference on Spoken Language Processing.2002: 901-904.
[22] Och F J. Minimum error rate training in statistical machine translation[C]//Proceedings of the 41st Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2003: 160-167.
[23] Papineni K, Roukos S, Ward T, et al. BLEU: a method for automatic evaluation of machine translation[C]//Proceedings of the 40th annual meeting on association for computational linguistics. Association for Computational Linguistics, 2002: 311-318.
Combining Translation and Language Models for Bilingual Data Selection
YAO Liang, HONG Yu, LIU Hao, LIU Le, YAO Jianmin
(Provincial Key Laboratory of Computer Information Processing Technology Soochow University, Suzhou, Jiangsu 215006,China)
Data Selection aims at selecting sentence pairs most relevant to target domain from large scale general-domain bilingual corpus that are , so as to alleviate the lack of high quality bi-text for statistical machine translation in the domain of interest. Instead of solely using traditional language models, we propose a novel approach combining translation models with language models for data selection from the perspective of generative modeling. The approach can better measure the relevance between sentence pairs and the target domain, as well as the translation probability of sentence pair. Experiments show that the optimized system trained on selected bi-text using our methods outperforms the baseline system trained on general-domain corpus by 3.5 BLEU points. In addition, we present an effective method based on sentence pairs re-ranking to tune the weights of different features which are used for evaluating quality of general domain texts. Machine translation system based on this method achieves further imporvments of 0.68 BLEU points.
bilingual data selection; generative modeling; translation model; language model; weight tuning

姚亮(1993—),硕士,主要研究领域为统计机器翻译,自然语言处理。E⁃mail:yaoliang310@163.com洪宇(1978—),博士后,副教授,主要研究领域为话题检测、信息检索、和信息抽取。E⁃mail:tianxianer@gmail.com刘昊(1990—),硕士,主要研究领域为统计机器翻译,自然语言处理。E⁃mail:liuhao19900412@gmail.com
1003-0077(2016)05-0145-08
2015-07-31 定稿日期: 2016-01-25
国家自然科学基金(61373097, 61272259, 61272260)
TP391
A
