交通数据中的会话识别
2016-05-03娄新燕禹晓辉
娄新燕,刘 洋,禹晓辉
(山东大学 计算机科学与技术学院,山东 济南 250101)
交通数据中的会话识别
娄新燕,刘 洋,禹晓辉
(山东大学 计算机科学与技术学院,山东 济南 250101)
会话识别因其能够提供对用户行为模式的深入理解而备受关注。交通数据会话是指用户为了完成某个任务而经过的交通路口序列。该文中我们采用超时和统计语言模型两种方法来进行会话识别。超时方法主要考察相邻交通路口之间的时间间隔对会话识别的影响,而统计语言模型则考虑路口序列的全局规律性。我们在交通数据集上进行了大量的实验,并通过比较分析两种方法性能上的差异得知时间因素比全局规律性在会话识别中的影响更大。
会话识别;超时方法;统计语言模型
1 引言

图1 捕捉车辆信息的摄像头
随着高新科技的飞速发展,越来越多的数据可以为人们所用。高清摄像技术的引入使得实时捕捉车辆信息成为了可能。在这些安装于交通主干道的摄像头的帮助下,我们可以监督并跟踪车辆的移动情况。由摄像头记录的信息包括车牌号,安装有摄像头的交通路口(以下简称卡口)编号,时间戳和方向等会被传送给交通数据中心。其中车牌号可以代表一个或多个用户。图1展示的是安装在交通主干道上用来捕捉车辆信息的摄像头。在一个卡口处通常有多个摄像头分别负责捕捉来自不同车道的车辆信息。因此,当一辆车经过某一卡口时,它的信息会被捕捉到,这样,我们就可以得到大量的交通数据。充分地运用这些数据,一是可以为用户提供个性化的基于位置的服务,例如,根据用户提交的查询信息为其推荐活动(如餐饮、购物、观光等)、位置[1-2];二是在交通数据基础上构建智能交通系统为用户提供特定路径的交通信息[3];三是改善社会网络,促进信息传播[4],例如,对一个购物者的路径进行预测,然后在该用户可能经过的位置传送一些商品促销广告。除此之外,这些丰富的数据还可以用来进行道路拥塞检测,以提醒用户及时更换路径。
本文主要研究交通数据中的会话识别问题。交通数据会话(traffic data session)是指一个用户为了完成某个特定的任务而经过的卡口序列。例如,一个用户从家到公司的行程中依次经过了若干个卡口,我们可以认为其在该过程中经过的卡口序列是一个会话,即这个序列是为了完成上班这个任务而经过的。给定一个用户在一天内经过的带有时间戳的卡口序列,我们要解决的问题就是识别哪些卡口属于同一个会话。通过研究,我们可以从丰富的数据资源中发现有用的模式和关系,以此作为路径预测,个性化位置服务等的基础。
虽然交通数据中的会话识别具有广阔的应用前景,但目前针对该研究的工作还非常有限。与Web会话识别和GPS路径预测相比虽有相似之处,然而其工作并不能完全用来解决我们的问题。在我们的交通数据中,一个用户可能经过的卡口是非常有限的;而在网络环境中,用户可以根据自己想要查询的信息随意访问各类网页,访问的页面数目虽然有限,但用户可访问的页面是没有限制的。除此之外,用户在一天中的某一个或几个时间段经过的卡口序列可能是相同或相似的,而用户在一天中访问Web网页时却没有这样的特点。与以往的GPS数据相比,虽然都是记录车辆的位置及时间信息,但用于捕捉车辆信息的摄像头是静态的,而用于收集GPS数据的设备是随车辆移动的。另外,GPS设备的采样频率通常是固定的,而摄像头是在车辆经过时随时捕捉其信息,其频率随车辆多少而改变。但对于同一辆车来说,由摄像头捕捉到的信息比用GPS设备记录的数据要稀疏很多。正是因为这种稀疏性使得抽取用户个性化信息及频繁模式成为我们工作的一大挑战。
在本文中,我们将提出两种有效的方法对交通数据进行会话识别。特别地,在第一种方法中我们认为一个会话中的任意两个连续卡口之间的时间间隔都不超过某一个特定的时间阈值,即若它们之间的时间间隔大于该阈值,则它们不属于同一个会话。这就是简单但使用最广泛的超时方法(timeout method)。这种方法与我们的常识即两个相邻卡口之间的时间间隔越大,它们属于同一个任务的可能性就越小是不谋而合的。另一种方法是统计语言模型(statistical language model),该方法不依赖任何的时间信息,而是通过衡量请求序列的信息改变来进行会话识别。在交通数据中,人们依据选择的路径依次经过特定的卡口,如果将卡口当作基本单位,就如同自然语言中的单词或字符,我们可以利用该模型来评估一个用户经过的卡口序列的概率,并用熵来评估该序列中的卡口是否属于同一个会话。
据本文作者所知,我们的工作是在交通数据领域进行会话识别的第一次尝试。现将我们的工作总结如下:
(1) 介绍我们使用的数据集以及对数据进行的预处理。
(2) 通过分析相邻卡口之间时间间隔的特点,利用超时方法进行会话识别。
(3) 介绍统计语言模型原理,并利用该模型识别会话。
(4) 在真实交通数据集上进行实验,通过比较分析两种方法性能上的差异得到影响会话识别的主要因素。
本文章节安排如下:第二节介绍与交通数据会话识别相关的工作。第三节给出对数据集及数据预处理的说明。第四节讲述对交通数据进行会话识别采用的两种方法。第五节给出实验结果并对其进行比较分析。第六节是对本文工作的总结以及未来要扩展的方面。
2 相关工作
我们从三个领域讨论与交通数据会话识别相关的工作,分别是:Web会话识别,数据库会话识别和路径预测。
2.1 Web会话识别
在Web日志文件中,一个会话被认为是一个用户为了某一个导航任务而提交的请求序列[5]。在交通数据中,车辆按照特定顺序依次经过各个卡口,类似于Web中为了完成一个任务而访问的页面。我们工作的基本目标就是识别出那些属于同一个任务的卡口序列。
Web会话识别最常用的是超时方法,该方法认为当两个相邻的页面请求之间的时间间隔大于某个预定的阈值时,这两个请求就不属于同一个会话[5]。He和Goker在文献[6]中使用不同的时间间隔在Excite日志和Reuters日志两个数据集上进行会话识别,结果表明最合适的时间阈值在10~15分钟之间。Catledge和Pitkow在文献[7]中声称用户在一个页面停留的平均时间为9分18秒,并且假设大多数显著事件发生在距离平均值1.5倍的标准差范围内,因此他们将最合适的时间阈值定为25分30秒。显然,一个最优的时间阈值往往依赖于某个特定的问题。本文通过设定不同的时间阈值来进行会话划分,依据F-Measure和编辑距离对不同阈值的结果进行比较最终得到对于交通数据而言最优的时间阈值为30分钟。
Kapusta等人在文献[8]中使用了一种不常用的基于导航的方法,即引用长度来进行用户会话识别。该方法假设用户在执行一个搜索任务时为了得到所需信息会在浏览了若干个辅助页面之后到达内容页面,而用户在一个内容页面停留的时间往往比在辅助页面停留时间长很多,因此该内容页面被认为是一个会话的终结。很明显,这种假设跟实际情况是不吻合的,如果一个内容页面的信息不能满足用户的需求,他还会访问更多的内容页面,这样,在一个会话中就不仅仅只包含一个内容页面了。在我们的交通数据中,每个卡口都是对等的,两个卡口之间的时间差并非因卡口的重要性决定,因此,引用长度方法不能用于我们的会话识别任务。
尽管统计语言模型产生的初衷是为了解决语音识别问题,但该模型已经被广泛应用于会话识别[5,9-11],文本分类[12]等领域。在文献[5-9]中,Huang等人提出使用统计语言模型来解决Web日志文件中的会话识别问题。该模型不依赖任何的时间信息,只是通过衡量请求序列的信息改变来进行会话识别。将每个被访问的页面看作一个基本单元,就像自然语言中的单词或字符,这样,一个页面序列出现的概率就可以利用该模型来估计。他们通过实验表明,对于Web会话识别,该方法要优于超时,引用长度等方法。然而,该模型虽适用于我们的问题,但因其没有考虑用户的个性化信息而未取得良好的表现。
2.2 数据库会话识别
尽管大多数对于数据库负载分析的工作都是基于数据库跟踪日志中的事务记录的,但在文献[13]中却表明一个OLAP应用的负载是以用户探索性和导航性的数据分析任务为特征的[14]。通过对会话的分析可以帮助人们发现高层次的模式,由此可以根据用户先前提交的查询来预测接下来要提交的查询[10]。
不论是超时方法还是统计语言模型都可以用来解决数据库中的会话识别问题。根据文献[15]的工作得知,超时方法是数据库供应商提供给电子图书馆数据库产品用来记录会话的唯一方法。并且,不同的供应商提供的时间阈值是不一样的,平均在 7~30分钟之间。文献[10-11]利用统计语言模型来识别数据库会话,同时提出一种自动的参数选择方法并证明通过该方法选择的参数的性能可以跟最优的统计语言模型相媲美。
2.3 路径预测
路径预测可以用来提供个性化的基于位置的服务,同时能够改善社会网络,促进信息传播[4]。另外,路径预测还可以针对一些即将到来的诸如交通事故,交通阻塞等事件给予司机一定的提醒[16]。
在文献[17-18]中,Chen和LV等人利用连续路径模式挖掘方法从用户轨迹中抽取路径模式,并在此基础上构建模式树,对于某一轨迹,通过模式匹配来进行路径预测。另外,文献[16]中提出基于豪斯多夫距离的聚类算法来得到路径模式。文献[19]利用不确定轨迹的时间和空间特性来构建路径图,在该图基础上提出一种可以根据用户查询得到前k条最受欢迎路径的算法。这些模式或受欢迎路径往往是用户经常选取的路径,然而对于一个用户来说不一定是为了完成某一特定任务而走。从某种意义来说,我们要识别的交通数据中的会话与路径模式类似但能在更细粒度上反映用户的行为模式。因此,我们所做的会话识别工作可以作为路径预测的基础,以期能够取得更好的预测结果。
3 数据集
在本节中,我们对使用的交通数据集,测试数据及数据预处理作简单的介绍。
我们所用的数据集是山东省济南市交通数据中心提供的来自市区164个卡口处的摄像头一个月内捕捉到的车辆信息。该数据集包括35 216辆车的10 344 058条记录。每条记录有四个字段,分别为车牌号,卡口编号,时间和方向。其中,车牌号类似于Web会话识别中的IP地址,可以对应一个或多个用户。在本文中,为了简单起见,我们假设一个车牌号对应一个用户。图2(a)显示的是一个用户在两天中的记录。每条数据记录中第一个字段2表示加密处理过的车牌号,可以将其看作是用户编号;第二个字段是该车辆经过相应卡口的时间,第三个字段代表卡口编号,最后一个字段表示该车辆经过相应卡口时的方向,1,2,3,4分别表示自南向北,自东向西,自北向南和自西向东。
在此数据记录的基础上,我们首先要做的是将其转换为轨迹的形式。轨迹是指一辆车在一天内经过的带时间戳的卡口的集合。将图2(a)中的数据记录表示成的轨迹形式如图2(b)所示。对于每一条轨迹,前两个字段分别表示车牌号和记录当天的日期,该车辆经过的带时间戳的相邻卡口之间用横线相连。给定一个用户在一天内的轨迹,我们要解决的问题就是识别出这条轨迹中哪些卡口属于同一个会话。

图2 数据记录及相应的轨迹实例
在交通数据集中的164个卡口中,我们选取63个带有名称和经纬度信息的卡口,并从数据中抽取那些经过的卡口中有70%以上有这些信息的数据,共得到61 762条记录。将这些记录转换为轨迹形式,共得到5 526条轨迹。利用卡口名称和经纬度信息,我们小组对这些轨迹进行人工识别,共得到30 839个会话,平均每个会话包含两个卡口。
另外,我们需要计算一条轨迹中任意两个相邻卡口之间的时间间隔,并对相同的卡口对之间的不同时间间隔进行统计分析。
4 会话识别
本节讲述我们在进行会话识别时采用的两种方法:超时方法和统计语言模型。超时方法主要考察相邻卡口之间的时间间隔对会话识别的影响,而统计语言模型则是通过估计卡口序列出现的概率来对会话进行识别。
4.1 超时方法
数据集中相邻卡口之间的时间间隔从几分钟到几个小时不等,即使是对相同的两个卡口,它们之间的时间差也不是恒定的。按照常识,两个卡口之间的时间差越小,它们属于同一个会话的可能性就越大,反之亦然。根据这一常识,我们给出超时方法的数学定义:
给定一个用户在一天内的轨迹(带时间戳的卡口集合),即:b1[t1],b2[t2],…,bi[ti],…,bN[tN]和一个特定的时间阈值tδ,两个相邻卡口bi和bi+1之间的时间间隔如式(1)所示。
(1)
如果Δt>tδ,则bi和bi+1属于不同的会话;否则,bi和bi+1属于同一个会话。
需要说明的是,我们的目标不是要寻找一个能够在任何情况下都能使得会话识别准确无误的完美的时间阈值,而是得到一个能够正确识别大多数会话的可以接受的时间阈值。为了得到这样的时间阈值,我们利用不同的时间间隔对交通数据中的轨迹进行会话识别,从而得到一个表现最好的时间阈值。
4.2 基于uni-gram的统计语言模型
统计语言模型产生的初衷是为了解决语音识别问题,其目标是要知道一个文字序列是否能构成一个大家理解而且有意义的句子,也就是要预测该序列出现的概率。在我们的交通数据中,给定某个用户在一天内经过的卡口序列,s=b1,b2,b3,…,bN, N为该序列中卡口数目。这个序列的概率可以表示为:
(2)
在我们的实验中,仅考虑卡口之间相互独立的的情况。
语言模型的一个重要问题是怎样估算条件概率p(bi|b1,…,bi-1)。通常,只要训练语料库足够大,我们就可以用最大似然估计得到该概率,如式(3)所示。
(3)
其中,c(w)表示序列w出现的次数。
然而,不论数据集有多大,都会面临数据稀疏问题。本文利用Katz’s式平滑来处理数据稀疏问题。该算法的思想是:当一个序列出现次数足够大时,最大似然是可靠的概率估计。而当序列出现次数不是足够大时,采用Good-Turing估计对其平滑,将其部分概率折扣给未出现的序列。当某序列出现次数为0时,用低元估计高元[20]。其平滑公式可以表示为:
(4)
其中,pML(bi|b1,…,bi-1)是最大似然估计,而pGT(bi|b1,…,bi-1)为图灵估计。假设:
(5)
(6)
nr表示出现次数为r的序列b1,…,bi的数目。
(7)
所以pML(b1,…,bi)可以表示为:
(8)
pGT(b1,…,bi)的计算公式为:
(9)
k是一个常数,Katz建议k=5。参数α和β是保证模型参数概率的归一化条件,即:
(10)
通过以上条件,可以得到α的值为:
(11)
β的值为:
(12)
对于一个给定的统计语言模型,可以通过计算一个序列s的熵来衡量其质量。序列s的熵可以表示为:
(13)
假设某个属于同一个会话的卡口序列在数据集中是频繁出现的,其概率值就会很大,相应地,其熵值就会很小。然而,当一个不属于该会话的卡口出现时,就会使得熵值变大。如果这两个熵值的相对改变量超过了预定的阈值,那么我们就认为这个新卡口是另一个会话的开始。
5 实验及结果
本节说明我们所用的评估标准,然后给出实验结果及针对结果的分析。
5.1 评估标准
实验中我们使用两种度量标准来评估会话识别方法的性能,一种是F-measure,它是查准率和查全率的调和平均值。其中,查准率是指正确识别出的会话数目与识别出的会话总数的比率,查全率是指正确识别出的会话数目与数据集中会话总数的比率。F-measure表达式如下:
(14)
另一种度量标准是编辑距离,它是衡量两个序列之间差异的典型标准。对于给定的两个卡口序列,它们的编辑距离是指由一个序列转换为另一个序列所需的最少编辑操作次数,许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符及删除一个字符。与F-measure相比,编辑距离衡量标准相对宽松。
5.2 实验结果及分析
在这一节中,我们使用F-measure和编辑距离来评估超时方法和统计语言模型在会话识别中的性能,并比较分析其结果。
5.2.1 超时方法的结果
对于超时方法,我们采用几个不同的时间阈值来识别会话,分别为5,10,15,…,60分钟。通过F-measure 和编辑距离衡量的结果显示在图3中。从图中可以看出,性能最优的时间阈值为30分钟,其F-measure为79%,平均编辑距离为0.545。
很显然,超时方法的性能依赖于时间阈值的设定。如果该阈值太小(如5分钟),会将本该属于同一个会话的卡口划分到两个不同的会话中而使得性能变得很差。另外,我们注意到当时间阈值增大到60分钟时,其性能虽不像5分钟时那样差,但其平均编辑距离却比5分钟时大。造成这种现象的原因是太小的时间阈值会在很大程度上将本该属于同一个会话的卡口划分到两个会话中,这样得到的会话长度都很短,且会话数目较多,因而使得平均编辑距离相对较小;而当时间阈值为60分钟时,因其宽松的时间限制使得到的会话数目较少,而每条会话长度相对较大,平均编辑距离就会偏大。除此之外,我们可以发现时间阈值从30分钟增大到60分钟,其F-measure减小程度相比30分钟到5分钟这段要小很多。
另外,从5分钟到30分钟,查准率从32.02%增大到73.72%,而从30分钟到60分钟,查准率从73.72%减小到71.58%,减小程度很小。相应地,查全率从5分钟时的54.45%增大到30分钟时的83.77%,而后,逐渐减小到60分钟时的61.94%。查准率和查全率的最大值都是在时间阈值为30分钟时取得。

图3 超时方法的结果
5.2.2 统计语言模型的结果
在统计语言模型中,我们需要考虑不同的熵差阈值对模型性能的影响。在我们的实验中,根据对数据集的观察,我们选取几个代表性的阈值,即+(-)0.000 1,+(-)0.000 5,+(-)0.001,+(-)0.005,0进行实验,结果如图4所示。当熵改变量较小时,得到的会话数目较多,平均编辑距离较小。随着熵改变量的增大,得到的会话数目逐渐减少,平均编辑距离逐渐增大,而F-measure逐渐减小。另外,查准率在熵差阈值为-0.000 5时取得最大值26.08%,在阈值为0.005时取得最小值21.15%。查全率则随着熵差阈值的增大而逐渐减小。
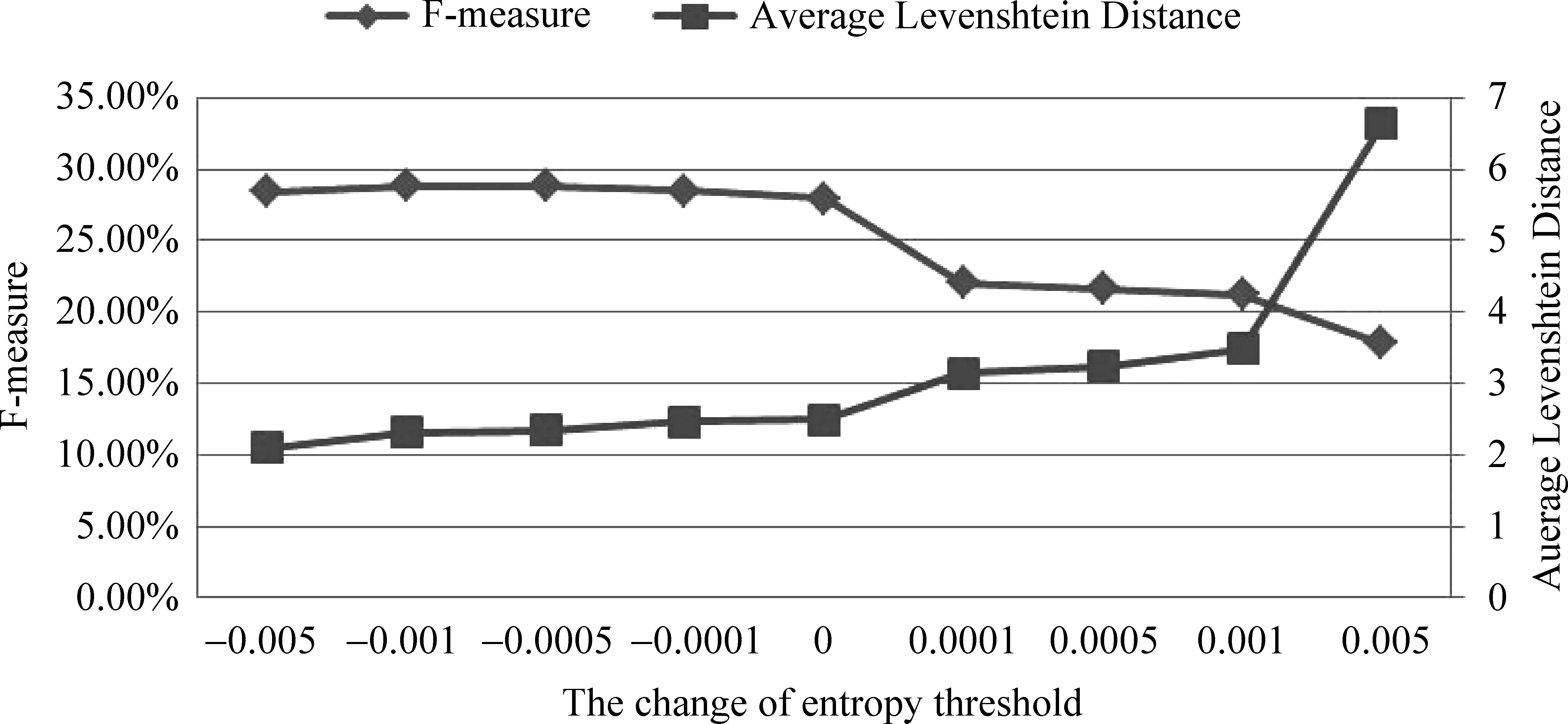
图4 统计语言模型的结果
5.2.3 比较与分析
从图3和图4可以看出,相比卡口序列的规律性而言,卡口之间的时间间隔对会话识别的影响要大得多,以至于时间阈值非常小的情况下的性能都比统计语言模型要好。通过分析可以发现:交通数据具有明显的时态特性,因而决定了超时方法的良好表现;对于一个用户而言,其卡口序列呈现出一定的规律性,然而,对于全局数据来说,这些局部规律性的序列未必是频繁的;另外,一个卡口的出现对其后面将要经过的卡口具有一定的预示作用,即卡口之间并非独立的。因为没有充分考虑上述这些因素,使得我们的uni-gram语言模型没有取得良好的表现。
6 结论
我们首次提出交通数据中的会话识别问题,并在真实的交通数据集上利用超时方法和统计语言模型来进行会话识别。通过对超时方法实验结果的分析我们知道,交通数据会话识别在很大程度上依赖于相邻卡口之间的时间间隔。使得该方法性能最优的时间阈值是30分钟。我们用该方法解决会话识别问题目的是考察时间因素对会话识别的影响,并得到一个能够正确识别大多数会话的可以接受的时间阈值。
在现实生活中,人们偏向于选择自己熟悉的路径。因此,对于一个用户来说,其所经卡口序列会呈现出一定的规律性。然而,这种局部规律性对于全局数据来说会显得微不足道。在统计语言模型中,正是因为没有考虑用户的个性化特征以及起决定性作用的时间因素,才使得该模型的性能变得很差。
在未来的工作中,我们会选取包含更长时间段内信息的数据集,并利用诸如用户相似性,卡口聚类这样的辅助信息来帮助完成会话识别工作。鉴于时间因素在会话识别中的重要性,我们考虑将时间因素融合到统计语言模型中,并考察n取更大值的情况。另外,我们可以对识别出的会话进行聚类,以此作为频繁的路径模式来进行路径预测。
[1] Zheng V, Cao B, Zheng Y, et al. Collaborative Filtering Meets Mobile Recommendation: A User-centered Approach[C]//Proceeding of the 24th AAAI Conference on Artificial Intelligence, 2010.
[2] Zheng V, Zheng Y, Xie X, et al. Towards mobile intelligence: Learning from GPS history data for collaborative recommendation[J]. Artificial Intelligence, 2012: 184-185, 17-37.
[3] Lee W, Tseng S, Shieh W. Collaborative real-time traffic information generation and sharing framework for the intelligent transportation system[J]. Information Sciences, 2010, 180(1): 62-70.
[4] Monclar R, Tecla A, Oliveira J, et al. MEK: Using spatial-temporal information to improve social networks and knowledge dissemination[J]. Information Sciences, 2009, 179(15): 2524-2537.
[5] Huang X, Peng F, An A, et al. Dynamic Web Log Session Identification With Statistical Language Models[J]. Journal of the American Society for Information Science and Technology, 2004, 55(14): 1290-1303.
[6] He D, Goker A. Detecting session boundaries from Web user logs[C]//Proceedings of the 22nd Annual Colloquium on Information Retrieval Research, 2000.
[7] Catledge L, Pitkow J. Characterizing browsing strategies in the world wide web[C]//Proceedings of the 3rd International World Wide Web Conference, 1995.
[8] Kapusta J, Munk M, Drlik M. User Session Identification Using Reference Length[C]//Proceedings of the 9th International Scientific Conference on Distance Learning in Applied Informatics, 2012.
[9] Huang X, Peng F, An A, et al. Session Boundary Detection for Association Rule Learning Using n-Gram Language Models[C]//Proceedings of the Sixteenth Canadian Conference on Artificial Intelligence, 2003.
[10] Huang X, Yao Q, An A. Applying language modeling to session identification from database trace logs[J]. Knowledge and Information Systems, 2006, 10(4): 473-504.
[11] Yao Q, An A, Huang X. Finding and analyzing database user sessions[C]//Proceedings of the 10th International Conference on Database Systems for Advanced Applications, 2005.
[12] Peng F, Schuurmans D. Combining Naive Bayes and n-Gram Language Models for Text Classification[C]//Proceedings of the 25th European Conference on Information Retrieval Research, 2003.
[13] Sapia C. On Modeling and Predicting Query Behavior in OLAP Systems[C]//Proceedings of the International Workshop on Design and Management of Data Warehouses, 1999.
[14] Sapia C. PROMISE: Predicting Query Behavior to Enable Predictive Caching Strategies for OLAP Systems[C]//Proceedings of the 2nd international conference on data warehousing and knowledge discovery, 2000.
[15] Duyand J, Vaughan L. Usage Data for Electronic Resources: A Comparison Between Locally Collected and Vendor-Provided Statistics[J]. The Journal of Academic Librarianship, 2003, 29(1): 16-22.
[16] Froehlich J, Krumm J. Route Prediction From Trip Observations[C]//Proceedings of Intelligent Vehicle Initiative Technology Advanced Controls and Navigation System, 2008.
[17] Chen L, Lv M, Ye Q, et al. A personal route prediction system based on trajectory data mining[J]. Information Sciences, 2011, 181(7): 1264-1284.
[18] Chen L, Lv M, Chen G. A system for destination and future route prediction based on trajectory mining[J]. Pervasive and Mobile Computing, 2010, 6(6): 657-676.
[19] Wei L, Zheng Y, Peng W. Constructing Popular Routes from Uncertain Trajectories[C]//Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2012.
[20] 王达,崔蕊,数据平滑技术综述[J]. 电脑知识与技术,2009,5(7):4507-4509.
Traffic Data Session Identification
LOU Xinyan, LIU Yang, YU Xiaohui
(School of Computer Science and Technology, Shandong University, Jinan, Shandong 250101,China)
Session identification has attracted much attention since it can provide insight into the behavior patterns of users. A traffic data session is a sequence of crossroad passed by a user to achieve a certain task. In this paper, timeout method as well as statistical language model are utilized to identify sessions. The timeout method deals with the effect of time interval between neighbor crossroads on session identification, while the statistical language model considers the global regularity of crossroad sequences. Extensive experiments are conducted and the results indicate that the influence of time factor is larger than global regularity on session identification.
session identification; timeout method; statistical language model

娄新燕(1988—),硕士研究生,主要研究领域为交通数据挖掘、会话识别。E⁃mail:louxinyan880207@sina.com刘洋(1977—),通信作者,博士,副教授,主要研究领域为交通大数据、社交媒体大数据的管理与分析。E⁃mail:yliu@sdu.edu.cn禹晓辉(1977—),博士,教授,主要研究领域为大数据管理、数据挖掘。E⁃mail:xyu@sdu.edu.cn
1003-0077(2016)01-0162-08
2013-05-10 定稿日期: 2014-02-10
国家自然科学基金(61272092,61572289);山东省自然科学基金(ZR2012FZ004,ZR2015FM002)
TP
A
