基于词重要性的信息检索图模型
2016-05-03王明文江爱文左家莉
王明文,洪 欢,江爱文,左家莉
(江西师范大学 计算机信息工程学院,江西 南昌 330022)
基于词重要性的信息检索图模型
王明文,洪 欢,江爱文,左家莉
(江西师范大学 计算机信息工程学院,江西 南昌 330022)
在信息检索建模中,确定索引词项在文档中的重要性是一项重要内容。以词袋(bag-of-word)的形式表示文档来建立检索模型的方法中大多是基于词项独立性假设,用TF和IDF的函数来计算词项的重要性,并未考虑词项之间的关系。该文采用基于词项图(graph-of-word)的文档表示形式来捕获词项间的依赖关系,提出了一种新的基于词重要性的信息检索图模型TI-IDF。根据词项图得到文档中词项的共现矩阵和词项间的概率转移矩阵,通过马尔科夫链计算方法来确定词项在文档中的重要性(Term Importance, TI),并以此替代索引过程中传统的词项频率TF。该模型具有更好的鲁棒性,我们在国际公开数据集上与传统的检索模型进行了比较。实验结果表明,该文提出的模型都要优于BM25,且在大多数情况下优于BM25的扩展模型、TW-IDF等模型。
词项重要性;词项图;检索模型;TI-IDF
1 引言
随着互联网的迅速发展,用户越来越依赖Google、百度、搜狗等搜索引擎来获取他们日常生活中所需要的信息。对于用户而言,都希望能找到与他们给定的需求(查询)最相关的信息。这就涉及到在信息检索过程中,如何定义一个针对给定查询计算文档排名的得分函数。现有的检索模型大多是以词袋(bag-of-word)的形式,即词项频率TF信息,来表示一篇文档。这些模型包括向量空间模型[1](TF-IDF),概率模型[2](BM25)和使用Dirichlet先验的语言模型[3]等,且词项重要性的计算均建立在词项的独立性假设上,并未考虑词项之间的相关性。Rijsbergen[4]已经验证了词项间的依赖关系在信息检索等文本处理中能起到重要的作用。但这种依赖关系目前并没有得到足够的重视,主要原因在于计算代价比较大,缺乏有效的表达形式。
本文基于词项图(graph-of-word)的形式提出一种新的、有效的文档表示方法。对每篇文档建立一个关于词项的无向有权图,图中的节点对应了文档中的索引词项,边代表两个词项节点的共现关系,边上的权重表示两个词项在文档中共现的句子数。根据词项图,可以得到文档中词项的共现矩阵,进而得到词项的概率转移矩阵。最后,通过马尔科夫链计算方法确定词项在文档中的重要性(Term Importance,TI),结合Zhai等[5-6]提出的启发式约束条件,得到检索模型TI-IDF。词项图充分地考虑到词项之间的依赖关系,比简单的文档向量保留了更多有用的信息,且构建过程不需要太多额外的时间开销,因此不影响检索过程的时效性。通过对比实验发现,本文的检索模型取得的检索结果都要优于BM25,并在大多数情况下优于BM25的扩展模型、TW-IDF等模型。
本文接下来第二部分将介绍相关工作;第三部分重点介绍词项图的构建以及词项重要性TI的计算;第四部分将主要介绍本文提出的检索模型TI-IDF;与已有检索模型的对比实验和结果分析将在第五部分给出;最后,进行总结以及给出下一步工作。
2 相关工作
基于图的算法已经被成功运用于检索中,典型的代表是L Page等[7]提出的PageRank。该算法使用图形表示Web结构,根据图结构计算出网页的重要性。相应地,如何构建检索中文档的词项图结构,也就是考虑词项之间的依赖关系,以及如何根据词项图确定词项在文本中的重要性,成为信息检索模型的一个重要课题。Blanco和Lioma根据词项之间的共现关系,构造出文档内词项的无向无权图,并采用类似PageRank的随机游走方法计算词项在文档中的权重[8-9]。Rousseau等[10]依据词项之间的共现关系以及词项间的顺序关系,构造出文档词项的一个有向无权图,并根据该图中节点(词项)的入度数确定词项的权重。上述工作均以固定滑动窗口的形式统计词项间的共现关系,特别地,Blanco和Lioma还依据调整窗口的大小计算词项在文档中的权重。本文与前述工作的主要区别是: (1)以句子为计算窗口统计词项共现次数,其优点在于句子是一个相对完整的语义单元,因此不需要进行窗口大小的调整以及考虑词项间的顺序关系;(2)本文构造的是文档内词项的无向有权图,边上的权重由两个词项共现的句子数确定;(3)本文采用马尔科夫链计算方法来确定词项在文档中的重要性。另外,洪欢和甘丽新等[11-12]通过构建整个文档集中词项间的Markov网络图形结构,提取出相应的词项团用于检索中(即将与查询词语义紧凑的词项用于修正该词项在文档中的重要性),从而取得较好的检索效果,这也体现了图模型很好地运用在查询扩展中。
Zhai等[5-6]提出信息检索模型需要满足的一些启发式约束条件,并对一些具有代表性的模型的得分函数进行验证,发现当得分函数满足越多的约束条件,取得的检索效果就越好。Rousseau等[10]则从这些检索模型的得分函数中归纳出三类词项频率归一化方法,包括: 1)凹面函数方法(TFk或者TFl),该方法主要是用于解决词项在文档内出现的次数线性增长时,查询检索到该文档的概率(文档得分)也线性增长,而应该是服从一个衰减函数的问题。举例来说,文档中出现查询词项为两次的文档得分减去为一次的得分要大于出现101次和100次的得分差;2)主轴文档长度归一化方法[13](TFp),该方法是用来防止查询倾向于长度长的文档,也就是对文档的长度进行归一化;3)低边界规则化方法(TFδ),该方法一般是结合TFp来使用,用于防止对长文档过度惩罚而增加一个补偿因子,因为Zhai等[14-15]提出当文档长度非常长的时候,采用TFp归一化方法的BM25检索模型不能取得很好的检索结果,而加入了TFδ方法后可以改善检索结果。具体的归一化方法如式(1)~(4)所示。
(1)
(2)
(3)
(4)
其中,tf(t,d)表示词项t在文档内出现的次数,k1是经验参数,b是文档长度倾斜参数,用于文档长度的归一化,在不同的模型中会有不同的取值,avdl表示数据集中文档的平均长度, |d|表示当前检索文档的长度,参数δ是补偿因子。
Rousseau等[10]将已有的一些形式为TF×IDF检索模型的得分函数归纳成由以上三类TF归一化方法的不同组合,不同的检索模型采用不同的组合方式。例如,BM25模型的得分函数可以认为是TFk、TFp与IDF的组合形式,记作TFkοp×IDF,Singhal等[1]提出的Piv模型得分函数是TFl、TFp与IDF的组合形式,记作TFpοl×IDF。也可以用单独一类的归一化方法与IDF组合成一些得分函数形式,例如,TFl×IDF和TFk×IDF等。
3 词项重要性度量
受日常生活中全国飞机航线图的启发,如果把文档中的词项看作航线图中的机场,词项之间的共现关系看作是航线图中的航线,由所有的航线构成了整个完整的航线图,相应地,所有词项之间的共现关系组成了文档的词项图。观察飞机航线图可以发现,一些重要的城市存在多条飞达该城市的航线,这些城市一般都是中心城市。相应地在词项图中,如果一个词项能够很好地概括文档的内容,那么该词项的度数会比较高,相应地,该词项在文档中权重应该比较高。以下我们将具体介绍词项重要性的计算方法。
3.1 词项图(Graph-of-word)
我们将每篇文档用词项的无向有权图(即词项图)来表示。在词项图中,节点表示文档中出现的索引词项,词项之间存在的无向边表示两个词项在文档中的某一个句子中共现,无向边上的权重则代表两个词项在文档中共现的句子个数。选择以句子为计算窗口来统计词项之间的共现次数,是因为一个句子所表达的语义会更为完整,句子中词项之间的关系也较为紧凑。已有的工作[8-10]均以滑动窗口的形式来统计词项间的关系,这需要额外地调整滑动窗口的大小,增加计算开销,并且许多跨句的词项之间的关系并没有同一句子中共现的词项关系密切。举一个简单的示例,我们取TREC-1目录下的WSJ数据集中第一篇文档分句后的三个句子,它们经词干化和去停用词后得到: “rosenfieldcbexecutindustrisourc.industrisourcputpropoacquisitmillion.rosenfieldofficejohnblairreachcomment.”,由这部分文本内容构建出词项图如图1所示。
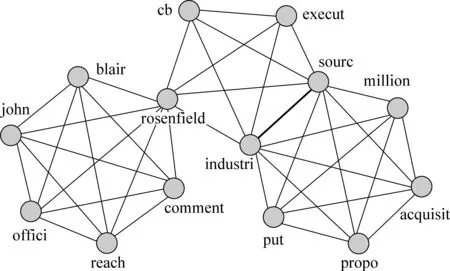
图1 词项图示例
在图1中,节点表示文档内的词项,边表示在某一个句子中词项间有共现关系,黑色以及加粗的边分别代表两个词项共现的句子数为1和2。我们会发现,文档内每一个句子中的词项关系都构成一个完全多边形,而文档的词项图则由这n个(n代表文档的句子数)完全多边形组合而成。
3.2 词项图构建过程
词项图的构建主要包括三个步骤。
1) 从给定的数据集中提取出每篇文档的文本内容,并采用LingPipe*http://alias-i.com/lingpipe/index.html程序对所有文档进行分句。
2) 去停用词及词干化: 对每篇文档的文本内容采用Terrier*http://terrier.org/download停用词表去除停用词并采用Porter的词干化程序进行词干化。这一过程能够帮助缩小词项图的规模,并更好地捕获词项之间的依赖关系。
3) 对每篇文档依次构建词项图: 统计每篇文档内所有词项之间的共现关系(以句子为计算窗口),并构建出该文档内词项的无向有权图。采用无向有权图的理由有两个:a)无向图的构建过程更简单,不用考虑词项之间的顺序关系;b)边权重可以提高那些在文档中经常出现的词项的权重,因为这些词项可能是文档的中心词(类似保留词项的频率TF信息)。最后,通过词项图可以得到每篇文档内词项的共现矩阵,有利于后续词项重要性的计算。
3.3 词项重要性度量
本文采用马尔科夫链计算方法来确定词项在文档内的重要性。马尔科夫链计算方法是一种关于事件发生的概率计算方法,它利用目前的初始状态概率向量与状态转移概率矩阵,确定事物未来的状态。马尔科夫链计算过程包括三部分。
1) 确定初始状态概率向量 B0: 相应地,在本文中就是确定文档内每个词项的初始概率如式(5)所示。
(5)
其中,M表示文档内所有不同的词项数。
2) 计算状态转移概率矩阵: 根据构建出的词项图得到文档内词项的共现矩阵,再通过共现矩阵得到词项间的概率转移矩阵 PN×N,Pij(i,j=0,1,…,M-1)的计算方法如式(6)所示。
(6)
其中,ni,j表示两个词项在文档内共现的句子数。式(6)中计算转移概率 Pij时只考虑了词项在同一句中(局部)的共现关系,考虑到词项在一篇文档内的全局共现关系,采用类似PageRank中加入阻尼因子的方法,将公式(6)修改为式(7)。
(7)
其中,d表示阻尼因子,取默认值0.15(实验中未进行调整,文献[12]验证了该参数的最优值为0.15),其他符号和之前公式的意义一致。
3) 计算转移的结果: 马尔科夫链计算方法有一个重要的性质[17],当概率转移矩阵 P经过m步概率转移变成正规概率矩阵 U,代入马尔科夫链计算模型 Bk=B0*Uk中,再经过若干步(k步)会发现 Bk将收敛,即 B=B*U。这里我们给出正规概率矩阵的定义:
定义1 一概率矩阵 P,若它的某次方 Pm的所有元素均为正数,则称其为正规概率矩阵[17]。
通过式(7)我们发现,本文使用的概率转移矩阵 P已经是正规概率矩阵。因此,实验中直接将转移矩阵 P代入马尔科夫链计算模型中,经过若干步(k=8-12)迭代 B将会收敛。
4) 确定词项的TI: 收敛得到的状态概率向量 B中的概率将用于计算词项在文档内的重要性TI,具体的计算如式(8)所示。
(8)
其中,i表示文档d中词项对应的下标,Bi表示收敛后的向量 B中第i个元素(词项)对应的概率。
4 检索模型构建
类似已有的检索模型TF-IDF以及BM25的得分函数,我们定义了一个新的检索模型TI-IDF。同样地,我们将关于词项频率(TF)归一化方法运用在TI上,这些归一化方法已经被验证可以很好地满足信息检索中的启发式约束条件[5-6]。
4.1 TF-IDF和BM25
在本文中,我们将对本文提出的TI-IDF模型与TF-IDF、BM25以及它们的一些变形作对比实验。对于TF-IDF检索模型,我们主要参照Singhal等[1]使用主轴文档长度归一化后的模型TFpοl×IDF,记作Piv[6],该模型的得分函数如式(9)所示。
(9)
其中,b是经验参数,一般取默认值为0.2(实验中将调整该参数),df(t)表示词项t的出现的文档数,N表示整个数据集中包含的文档数。
对于BM25模型,我们参照的是Robertson等[2]给出的模型的得分函数,也称OkapiBM25(实验中简称Okapi)。Okapi中的IDF部分在df(t)>N/2出现负数时,会导致检索效果下降(实验部分将给出验证)。为了让Okapi模型更好地满足Zhai[5-6]提出的启发式约束条件,我们将Okapi的IDF部分进行修正,修正后的模型称为mod-Okapi[5]。各模型对应的得分函数如式(10)和式(11)所示。
(10)

(11)
其中,K=k1×(1-b+b×|d|/avdl),b是经验参数,一般取值0.75(实验中将调整该参数),k1取默认经验值1.2[2]。
在本文的实验中,我们还将和Zhai等[6]提出的TF-IDF和BM25的扩展模型作对比实验,这些扩展模型本质上是把TFδ归一化方法也组合进来,具体模型的得分函数被记作Piv+和BM25+[6],在本文中分别对应TFδοpοl×IDF和TFδοkοp×IDF,实验中δ参照文献[6]取默认值1.0。
4.2TI-IDF
类似已有TF×IDF形式的检索模型得分函数,并结合凹面函数和主轴文档长度归一化两种方法,我们定义出本文模型的新的得分函数:TIpol×IDF和TIkοp×IDF,参照公式(9)和(11)给出具体的形式。
(12)
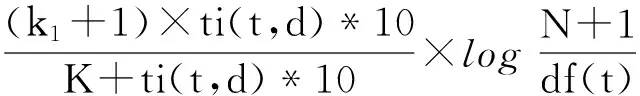
(13)
其中,ti(t,d)表示词项在文档中的权重(即上文所说的TI),式中的其他符号和之前公式的意义一致。经过实验发现b取值0.06,且不需要调整。由于参数b非常小,尽管文档长度 |d|远比avdl大,但乘以参数b后,b×|d|/avdl依然比较小,不会造成对长文档的过度惩罚。因此,对于本文的TI-IDF模型不需要使用类似TF的低边界归一化方法TFδ。
公式(12)和(13)中我们采用ti(t,d)*10的形式,乘以10是因为计算得到的词项重要性TI一般要比词项频率TF小一个数量级,为了适应TF归一化方法,所以将TI的值乘以10。
5 实验设计与分析
5.1 数据集与评价指标
本文采用的数据集是TREC-1 (AdhocTestCollections)中的四个子数据集,分别是:AP(美联社新闻专线故事文章)、DOE(美国能源部技术文章摘要)、WSJ(华尔街日报文章)和ZIFF(Ziff-Davis出版公司文章)。TREC-1是用于TREC中的adhoc检索任务的数据集,可以很好地判断检索模型的效果,数据集文档保存在disks1&2中。查询选用TREC-1adhoctopics.51-100, 在这些查询文件
中只有title域的内容作为查询用,相关判断集合选取查询对应的qrels.51-100文件。数据集(经过分词以及词干化处理)的具体情况如表1所示。
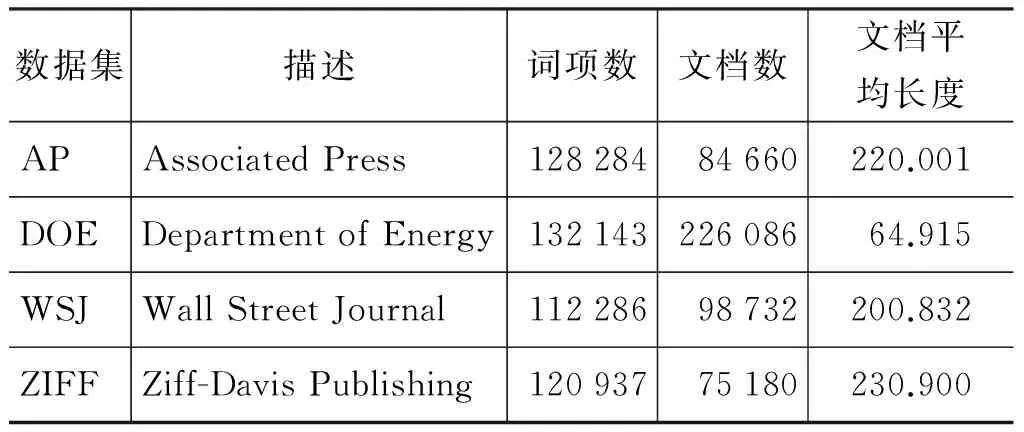
表1 TREC1中的数据集
我们采用的评价指标是3-avg和11-avg,分别代表一组测试查询在三个召回率点(0.2, 0.5, 0.8)和11个召回率点(0, 0.1, 0.2, ……, 1.0)上精确率的平均值。这种平均精度-召回率数值已成为信息检索系统的标准评价指标,在信息检索文献中被广泛采用。
5.2 实验结果与分析
5.2.1 已有检索模型实验结果
本文首先对比了检索模型BM25和TF-IDF使用不同归一化方法组合后的实验结果。也就是使用在第四节介绍的各种得分函数的检索结果,实验中所有得分函数中的参数k1和δ的取值取参照文献中[6]确定的经验参数值k1=1.2,δ=1.0;对于参数b,实验结果分为固定b和调整b两种,具体的结果分别如表2和表3所示。

表2 固定参数b时,已有检索模型的实验结果
注: 加粗数字表示最好结果

表3 调整参数b时,已有检索模型的实验结果

续表
通过表2和表3我们发现,改进BM25模型得分函数中IDF部分后的mod-Okapi模型的检索结果确实都要优于初始的Okapi模型。实验中,一开始我们将模型TI-IDF的得分函数中参数取值和TF-IDF模型一致,发现所得的检索效果不是很理想。究其原因,主要是词项重要性TI的取值不会像TF一样受到文档长度很大的影响,也就是在采用主轴文档长度归一化方法TFp时,参数b的取值应该比较小,在接下来的实验中我们将验证这一观点。
5.2.2 主轴文档长度归一化方法中参数b对TI-IDF模型的影响
在实验中,TI-IDF检索模型我们使用的得分函数是:TIpol×IDF,主要是它的检索结果都要优于得分函数TIkop×IDF。为了验证TI受文档长度的影响不会很明显,我们分析得分函数中的TIp归一化方法内文档倾斜参数b对TI-IDF模型检索结果的影响,具体如图2所示。

图2 参数b对结果的影响
从图2中我们发现,随着参数b的增长,TI-IDF模型的检索效果开始有小规模提高,当b=0.06时相对地稳健,之后逐渐下降。特别地,当参数b=0时,也就是不采用主轴文档长度归一化方法,检索结果也较好;而在b=0.2时,检索结果已经变得很差,这也验证了5.2.1节中给出的观点。因此,实验中我们将TI-IDF模型中参数b的取值设为达到稳健时的0.06,它的取值比Piv(b=0.2)和BM25(b=0.75)中的经验取值要小一个数量级,究其原因是,虽然文档的长度变长,所包含的句子数以及词项数也随之增加,但文档总的概率1没有变化,TI增长的幅度较TF小得多,且在同一句话中多次出现的词项与其他词项之间只算一次共现。
5.2.3TI-IDF对比实验结果
首先,为了验证本文中采用基于词项图的文档表示形式的检索模型要优于传统的以词袋形式来表示文档的检索模型,实验中我们分别对比在不使用归一化方法情况下,TF与TI、TF-IDF与TI-IDF的实验结果,具体结果如表4所示。
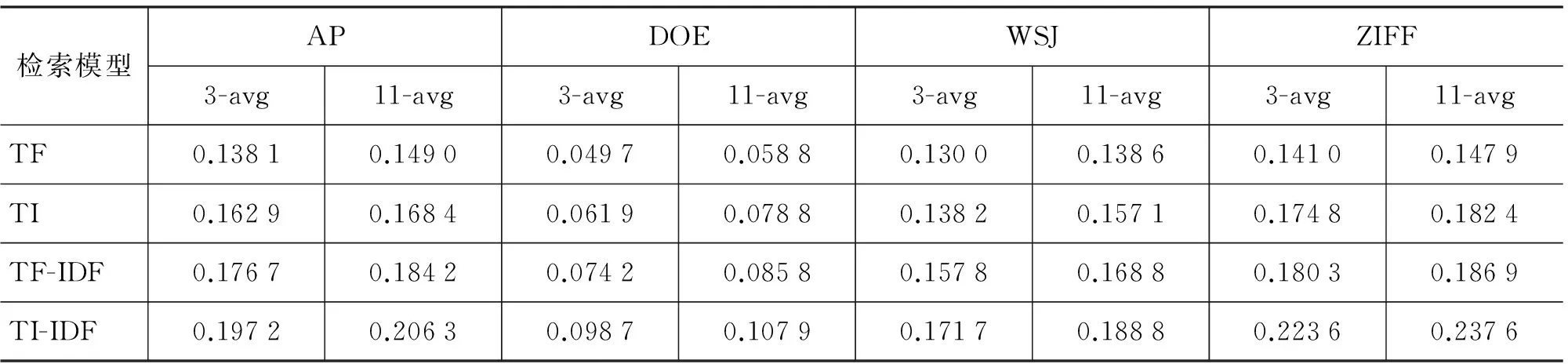
表4 不使用归一化方法的对比实验结果
从表4我们发现,在四个数据集上TI都要优于TF,且TI-IDF都要优于TF-IDF,说明本文提出的基于词项图来表示文档比传统基于词袋形式保留了更多有用的信息。
最后,我们将TI-IDF模型取得最好的检索结果时的得分函数TIpοl×IDF与已有检索模型中取得最好的检索结果,包括固定参数b和调整参数b(分别记作Best和T_Best)以及初始的BM25模型(Okapi)作比较。另外,我们将Rousseau等[10]提出的检索模型TW-IDF也用于对比实验(实验中参照原文取计算窗口大小为4来构建文档的有向无权图,得分函数使用TWpοl×IDF,通过实验取得到最好检索结果的参数b,b=0.04)。具体对比实验的结果如表5所示。
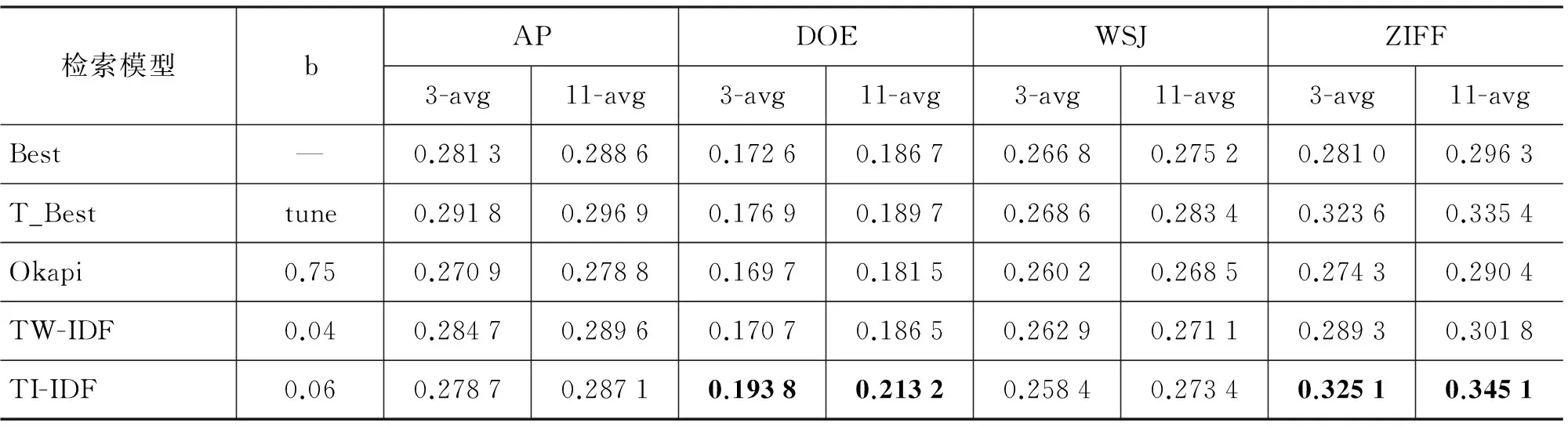
表5 使用归一化方法的对比实验结果
表5显示本文的TI-IDF模型可以取得和Best、T_Best以及TW-IDF相当的检索结果,且都要优于初始的BM25 (Okapi)模型。在DOE和ZIFF数据集上TI-IDF的检索结果最优。另外,本文的TI-IDF模型和TW-IDF模型一样无需参数调整,具有更好的鲁棒性,对过长的文档不会造成过度惩罚,因此都不需要低边界归一化方法TFδ。对于构建每篇文档的词项图造成的额外时间开销,可以通过并行平台来解决,因为词项图的构建以及TI的计算过程中文档集中所有文档相互之间不存在依赖关系,且都可以离线计算。在AP和WSJ两个数据集上检索效果不是最优的原因包括: 1)由于AP和WSJ中的文档是新闻报道文章,存在许多口语化的单词和长度较短的句子,另外,文章中的许多单词缩写、人名、地名等影响分句,也会造成出现一些词项数很少的短句,使得文档内词项与词项之间的依赖关系少,这样不利于捕获词项间的依赖关系,造成构建的词项图不精确。而TI的取值非常依赖于构建的词项图,最终导致TI的值不精确。2)本文在对TI进行归一化的时候,直接使用已有的TF归一化方法。从表4我们发现TI-IDF模型的检索结果在所有数据集上都要优于TF-IDF模型,因此,我们相信找到更适合TI的归一化方法将会取得更好的检索结果,在下一步的工作中我们将尝试找出这些方法。
6 总结与展望
本文提出一种新的文档表示形式——词项图(graph-of-word)和检索图模型TI-IDF,通过词项图捕获词项之间的依赖关系,得到词项的共现矩阵以及概率转移矩阵,然后采用马尔科夫链计算方法确定词项在文档中的重要性TI,最后结合已有的TF归一化方法,定义一个新的有效的得分函数TIpοl×IDF用于文档检索。实验证明,本文提出的基于词重要性的检索图模型,在公开测试数据集TREC-1上性能都要优于BM25,并在大多数情况下优于BM25的扩展模型、Piv及其扩展模型以及TW-IDF。此外,TI-IDF模型无需参数调整,较传统TF-IDF无需增加过多计算开销,具备良好的检索性能,且具有更好的鲁棒性不会对长文档造成过度惩罚。为了得到更好的检索效果,下一步的工作我们将从寻找更适合词项重要性TI的归一化方法着手,改进TI-IDF模型的得分函数。
[1]SinghalA,ChoiJ,HindleD,etal.At&tatTREC-7[J].NISTSPECIALPUBLICATIONSP, 1999: 239-252.
[2]RobertsonSE,WalkerS,JonesS,etal.OkapiatTREC-3[J].NISTSPECIALPUBLICATIONSP, 1995: 109-109.
[3]ZhaiC,LaffertyJ.Astudyofsmoothingmethodsforlanguagemodelsappliedtoadhocinformationretrieval[C]//Proceedingsofthe24thAnnualInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.ACM, 2001: 334-342.
[4]VanRijsbergenCJ.Atheoreticalbasisfortheuseofco-occurrencedataininformationretrieval[J].JournalofDocumentation, 1977, 33(2): 106-119.
[5]FangH,TaoT,ZhaiCX.Aformalstudyofinformationretrievalheuristics[C]//Proceedingsofthe27thAnnualInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.ACM, 2004: 49-56.
[6]LvY,ZhaiCX.Lower-boundingtermfrequencynormalization[C]//Proceedingsofthe20thACMInternationalConferenceonInformationandKnowledgeManagement.ACM, 2011: 7-16.
[7]PageL,BrinS,MotwaniR,etal.ThePageRankcitationranking:Bringingordertotheweb[J].StanfordInforlab,1999:1-14.
[8]BlancoR,LiomaC.Randomwalktermweightingforinformationretrieval[C]//Proceedingsofthe30thAnnualInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.ACM, 2007: 829-830.
[9]BlancoR,LiomaC.Graph-basedtermweightingforinformationretrieval[J].InformationRetrieval, 2012, 15(1): 54-92.
[10]RousseauF,VazirgiannisM.Graph-of-wordandTW-IDF:newapproachtoadhocIR[C]//Proceedingsofthe22ndACMInternationalConferenceonConferenceonInformation&KnowledgeManagement.ACM, 2013: 59-68.
[11] 甘丽新, 涂伟, 王明文, 等. 基于混合相关的Markov网络信息检索扩展模型[J]. 中文信息学报, 2013, 27(4): 83-88.
[12] 洪欢, 王明文, 万剑怡, 等. 基于迭代方法的多层Markov网络信息检索模型[J]. 中文信息学报, 2013, 27(5): 122-128.
[13]SinghalA,BuckleyC,MitraM.Pivoteddocumentlengthnormalization[C]//Proceedingsofthe19thAnnualInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.ACM, 1996: 21-29.
[14]LvY,ZhaiCX.Whendocumentsareverylong,BM25fails![C]//Proceedingsofthe34thInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.ACM, 2011: 1103-1104.
[15]LvY,ZhaiCX.Adaptivetermfrequencynormalizationforbm25[C]//Proceedingsofthe20thACMInternationalConferenceonInformationandKnowledgeManagement.ACM, 2011: 1985-1988.
[16]RousseauF,VazirgiannisM.CompositionofTFnormalizations:newinsightsonscoringfunctionsforadhocIR[C]//Proceedingsofthe36thInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.ACM, 2013: 917-920.
[17]RhoadesBE.TheconvergenceofmatrixtransformsforcertainMarkovchains[J].StochasticProcessesandtheirApplications, 1979, 9(1): 85-93.
An Information Retrieval Graph Model Based on Term Importance
WANG Mingwen, HONG Huan, JIANG Aiwen, ZUO Jiali
(School of Computer Information Engineering, Jiangxi Normal University, Nanchang, Jiangxi 330022, China)
In information retrieval modeling, to determine the importance of index terms of the documents is an important content. Those retrieval models which use a bag-of-word document representation are mostly based on the term independence assumption, and calculate the terms’ importance by the functions of TF and IDF, without considering about the relationship between terms. In this paper, we used a document representation based on graph-of-word to capture the dependencies between terms, and proposed a novel information graph retrieval model TI-IDF. According to the graph, we obtained the co-occurrence matrix and the probability transfer matrix of terms, then we determined the terms’ importance (TI) by using the Markov chain computing method, and used TI to replace traditional term frequency at indexing time. This model possesses a better robustness, we compared our model with traditional retrieval models on the international public datasets. Experimental results show that, the proposed model is consistently superior to BM25 and better than its extension models, TW-IDF and other models in most cases.
term importance; graph-of-word; retrieval model; TI-IDF

王明文(1964—),博士,教授,博士生导师,主要研究领域为信息检索、数据挖掘、机器学习。E-mail:mwwang@jxnu.edu.cn洪欢(1991—),硕士,主要研究领域为信息检索、数据挖掘、自然语言处理。E-mail:honghuan252008@126.com江爱文(1984—),博士,副教授,主要研究领域为多媒体检索、视觉与语言。E-mail:jiangaiwen@jxnu.edu.cn
1003-0077(2016)04-0134-08
2014-08-14 定稿日期: 2015-03-21
国家自然科学基金(61272212,61462043,61462045);江西省自然科学基金(20122BAB211032,2015BAB217014)
TP391
A
