中文微博情感词提取: N-Gram为特征的分类方法
2016-05-03刘德喜聂建云刘晓华万常选廖国琼
刘德喜,聂建云,张 晶,刘晓华,万常选,廖国琼
(1. 江西财经大学 信息管理学院,江西 南昌 330013;2. 蒙特利尔大学 计算机科学与运筹学系,蒙特利尔 加拿大 H3C3J7;3. 华南理工大学 计算机科学与工程学院,广东 广州 510641)
中文微博情感词提取: N-Gram为特征的分类方法
刘德喜1,聂建云2,张 晶3,刘晓华2,万常选1,廖国琼1
(1. 江西财经大学 信息管理学院,江西 南昌 330013;2. 蒙特利尔大学 计算机科学与运筹学系,蒙特利尔 加拿大 H3C3J7;3. 华南理工大学 计算机科学与工程学院,广东 广州 510641)
情感词典是文本情感分析的基础资源,但采用手工方式构建工作量大,且覆盖有限。一种可行的途径是从新情感词传播的重要媒介-微博数据-中自动抽取情感词。该文以COAE 2014评测任务3提供的中文微博数据为统计对象,发现传统的基于共现的方法,如点互信息等,对中文微博数据中的新情感词发现是无效的。为此,设计一组基于上下文词汇的分类特征,即N-Gram特征,以刻画情感词的用词环境和用词模式,并以已知情感词为训练数据训练分类器,对候选情感词进行分类。实验结果表明,该方法较传统基于共现的方法要好。实验还发现,与英语不同的是,中文情感词通常会以名词词性出现,而基于共现的方法无法有效地区分该类情感词,这是造成其失效的主要原因,而该文提出的分类特征能解决这一问题。
情感词提取;中文微博;分类方法;N-Gram特征
1 引言
文本情感倾向性分析是对信息发布者的态度(或称观点、情感)进行分析,广泛应用于舆情监督、产品评论分析等领域,近些年持续成为自然语言处理领域研究的热点问题之一。构建一部覆盖广、质量高的情感词典是文本情感倾向性分析的基础,因为很多方法直接或间接地基于文本中出现的情感词来判断文本的情感倾向性。
尽管手工方式构建的情感词典比较准确,但代价大,得到的情感词典覆盖面不够,并且针对领域相关的情感词,还需要相应的领域知识。特别是随着Web 2.0和移动设备的普及,用户在互联网上陈述观点、发布评论、表达情感更便捷、更频繁,使得网络新词的更新和传播日益迅速,其中就有很多新词是带有情感倾向性的,例如,“给力”、“吐槽”、“白富美”、“飘红”(用于描述股票呈涨势)等。这些新词并未在现有的同义词典等词典资源中出现,因此其情感倾向性很难用基于词典的方法获取。
新浪、Twitter等作为互联网用户发泄情绪、表达情感、发布、接收和传播观点的微博平台,拥有数以亿计的用户,是新情感词的重要来源之一。自动抽取新情感词并判断它们的极性近年来也得到了一些学者的关注,但仍然面临着巨大挑战,特别是对于中文微博数据。这些挑战具体表现在:
(1) 微博数据主题复杂。与从商品评价中抽取情感词不同,大量微博数据不是针对一种或几种产品的评价,而是包括产品评价、时事评论、生活琐事、心情表达、商家广告等复杂多样主题,导致很多研究较早、较成熟的用于商品评价情感分析的方法无法直接用于微博数据。
(2) 微博数据不规范,语法分析困难。经典的基于规则的新情感词抽取方法通常需要利用语法分析的结果,然而微博数据不规范的表达使得语法分析准确率严重下降,阻碍了基于规则的方法在微博数据上的运用。
(3) 中文情感词词性分布广。经典的新情感词抽取方法大都以形容词、动词、副词作为候选新情感词。然而对于中文数据,很多情感词是以名词词性出现在句子中。例如,“这款手机是垃圾”中的“垃圾”。如果不考虑名词,会丢失大量新情感词,如果考虑名词,又会引入大量噪音,因为绝大部分的名词并非情感词。
(4) 共现的情感词之间极性相互矛盾情况严重。相比Twitter微博长度140个字符的要求,新浪等中文微博长度上限为140个汉字,可以表达的内容非常丰富。因此,同一微博中出现多个极性不同的情感词的现象非常普遍。因此,经典的新情感词识别中"共现的两个情感词极性相同"这一假设不再成立。
鉴于从中文微博数据中抽取新情感词所面临的挑战,COAE 2014新增一项任务(任务3),要求参赛系统从千万级规模的中文微博数据中抽取不在给定通用词典中的新情感词,并标出这些情感词的极性。基于COAE 2014任务3提供的数据,本文分析了中文微博中情感词的分布特征,充分利用已有的情感词典资源和微博数据量大的特点,提出基于分类的中文微博新情感词抽取方法NGC (N-Gram based Classification)。NGC将候选情感词扩大到名词词性上,并从(候选)情感词上下文词汇中抽取用于刻画情感词用词环境和用词模式的特征。与基于共现的点互信息-Pointwise Mutual Information (PMI)等方法相比,NGC方法效果更好,在COAE 2014的评测中也显示了很强的竞争力。
本文的主要贡献包括: (1)通过比较详尽的统计结果分析了中文微博中情感词的分布特点(第三节),发现在中文微博中,大量情感词以名词形式出现,共现的情感词极性矛盾现象比较普遍,并且点互信息等共现特征无法区分情感词与非情感词,致使以共现为基础的各类经典情感词识别方法在中文微博上失效。据我们了解,目前还没有文献涉及这些基础的分析工作。(2)针对中文微博中情感词分布的特点,提出基于分类的中文微博新情感词抽取算法NGC (第四节)。尽管有文献采用分类的方法抽取情感词,但其处理对象多为表述规范的Wordnet或网页数据,亦或商品评论数据,候选情感词多为形容词,有些方法还需要以句法分析的结果为特征。NGC将名词也纳入候选情感词,选择的特征可以刻画蕴含在数据集中的情感词用词环境和用词模式,无需句法分析,简单有效,适合主题复杂多样且表达不规范的中文文本。(3) 除参与COAE 2014的评测外,另外设计了多组实验,并从平均精度和Bpref两个指标评价和分析了NGC方法的有效性。
2 相关工作
对文本情感分析的研究成果比较丰富[1-3],包括对产品评论及评论对象(又被称为特征)的情感极性判断、微博情感极性的判断、情感摘要等。在对文本进行情感分析时,情感词典通常扮演着重要的角色[4-5],因此,如何自动从数据集中抽取情感词并判断其极性受到研究者的重视,除了在理论和方法上取得大量成果外,也产生了不少用于情感分析的情感词典,如SentiWordNet*http://sentiwordnet.isti.cnr.it/,MPQA*http://mpqa.cs.pitt.edu/等。
情感词典的自动构建方法可归为以下五类,它们所需要的资源和针对的对象不尽相同。
利用词汇或语法规则。该类方法的基本依据是共现的两个情感词之间通常存在一些显式规则。例如,Hatzivassiloglou等[6]认为,用“and”或“but”等词汇连接起来的两个形容词的极性存在关联性,因此,在其中一个极性已知的情况下,利用逻辑回归来预测另一个,逐渐扩展情感词汇。该类方法的不足是比较明显的,因为很多情况下共现的形容词间并没有显示的规则存在,并且对于中文文本,这种规则更加模糊。
计算候选词与已知情感词的相似性。这类方法假设同极性的情感词之间相似性高,极性相异的情感词之间相似性小,而无极性的词与正、负极性的情感词之间相似性相当。因此,给定一个较小规模的情感词典,对于候选词,计算它与情感词典中正、负极性情感词的相似性之差。差值越大,该候选词是情感词的可能性越大。相似性的计算时,有基于共现的PMI[7-9]、基于上下文的相似度[10]、基于词汇在Wordnet中的语义距离[11]等。该类方法简单有效,通用性强,针对的数据可以是Wordnet这样的词典资源[12]、商品的评论集合[10]、网页数据[8]、或者用户发布的微博数据[9]等。这类方法在英文文本上表现良好,因为英文中大都以形容词、动词、副词为候选情感词,但在下一节的统计分析中我们发现,当把目标转向中文微博这类数据时,名词的引入所带来的噪声,很难仅用共现等相似度计算的方法来消除。
利用情感极性在词汇图中的传播。该类方法通常构建以词汇为节点、以词汇之间关系(如相似性、共现等)为边的图,从人工选择的少量种子情感词节点出发,通过图中的边将极性逐渐传播到候选词汇,以此决定候选词汇的情感极性。这类方法类似于计算候选词与已知情感词的相似性,只是基于词汇图的方法不单可以考察候选词与已知情感词之间的直接联系,还通过图的形式考察它们之间的间接联系。尽管构建图时连接两节点的边的权重计算方法不同,情感极性传播方式也不相同,但该类方法大都基于Wordnet中的词条及对词条的解释来构建图[13-16],候选词的选择及数据的规模非常有限。Velikovich等[17]没有考虑候选词的词性,通过不到400个种子情感词,从40亿Web面页中抽取了约18万新情感词(短语),目的是将这些新情感词用于文本的情感分类,这与构建情感词典的任务是不同的,因为尽管得到的新情感词规模是参考情感词典WordNet LP的30余倍,其对WordNet LP中情感词的召回不到50%。此外,有助于情感分类的词并不一定就是情感词,例如,在COAE 2014微博情感分类数据集中,大部分关于“蒙牛”的微博都是负面的,因此“蒙牛”一词有助于微博的情感分类,但它却不是情感词。Peng等[18]充分利用了Wordnet词典资源和社交媒体数据,但其候选情感词依然是社交媒体数据中的形容词。
情感词和情感对象协同抽取。该类方法假定情感词和情感对象(特征)之间存在修饰与被修饰的关系,因此可将情感词的抽取与情感对象的抽取结合起来,协同抽取[19-22]。该类方法主要针对评论数据,其情感表达的对象比较明确。但这类方法并不适合微博数据,因为微博数据充满噪声,很多句子无情感,只是陈述事实,或者情感并不针对某一对象,只是表达某一种心情,并未对人、事或物进行评论。
将候选词极性识别视为分类问题。该类方法视候选词可能属于三个类别: 正向极性、负向极性、无极性,然后利用已有的种子词典,或者候选词所在文档的极性,对候选词进行分类。这类方法大部分是对Wordnet中的词条或同义词集作情感极性分类,以Wordnet的同义词集[23]或对词的注释[24]为特征。也有以用户对产品的打分为训练目标,对产品评论中的候选词极进行判别,目标是使得利用判别结果对产品的打分与用户打分尽量一致[25]。
本文的思想与Esuli等[24]比较相近,文献[24]是针对Wordnet数据,利用对词的注解(gloss)作为特征进行分类。但针对中文微博数据,选择什么特征进行分类还需要有丰富的实验数据作为支撑。另外,文献[24]的实验结果显示,形容词和副词被分类为情感词的频率远远超过动词和名词,分别为39.66%,35.7% 和11.04%,9.98%,因此很多文献不考虑名词性的情感词。我们在英文tweet数据上的统计发现,不考虑名词仍可以覆盖85%以上的英文情感词,但中文微博中这个比例却不到60%。最核心的区间在于,在文献[24]中,候选情感词都是Wordnet词典中的词条,对词的解释比较规范,同义或反义等意义相关的词的解释有很多相似之处。然而这些特点在中文微博数据中并不存在,这给新情感词发现带来更大难度。
Wiebe等[26-27]从Wall Street Journal数据集中抽取主观词(情感词),但仅考虑形容词为候选情感词,要求候选词所在的句子是主观句,并且需要对句子进行语法分析。Riloff等[28]抽取带有主观倾向的名词,其中用到的关键特征“候选词的词干”是不适合中文的。与本文从中文微博中抽取新情感词类似,Volkova[29]从英文Twitter中抽取新情感词。首先根据种子情感词判断tweet的极性,再考察候选词与各极性的tweet的共现关系,判断候选词的极性,每次生成数个情感词,不断扩展。该方法假设共现在相同tweet中的情感词极性相同,极性不同的情感词不会共现在同一tweet中,这与第三节在中文微博上的统计分析不符。
基于微博数据集自动构建中文情感词典的文献并不多见。Xu等[30]采用基于词汇图的方法构建中文情感词典,图中的节点来自同义词林、汉语词典和《人民日报》数据集,候选情感词限定于形容词、成词和习惯用词,不考虑名词。Du等[31]通过已知领域的情感词典构建新领域的情感词典,除了需要极性标注的文档集外,仍然只考虑了中文评论数据中的形容词、副词及形容词-名词短语。当考虑名词为候选词性时,文章的基本假设“出现在很多正(负)极性文档中的候选词极性为正(负)”就不再成立了。例如,对“蒙牛”的评论多是负向的,但“蒙牛”本身不能作为情感词。同样地,文献[32]分析了名词属性的产品可能蕴含情感,但这些产品不能作为情感词。
以上方法存在一些共性,通常规定候选情感词为形容词,也有部分考虑动词或副词等,这对中文新情感词的抽取是不够的。另外,已有文献中对新情感词的评测通常是间接的,即考察新情感词对文本情感分类的影响,但如前面例子所述,这与新情感词抽取的任务还是有区别的。再者,这些方法通常假设已知的情感词典规模为数十或上百条,通过多次迭代或传播,逐步扩展(propagation)。虽然这一方法能找出一些情感性较强的词,但它们很多时候都已经被人工纳入了相对大的情感词典,用它来发现情感词典不包含的新情感词就困难很多。实际应用中我们发现,不论英语还是中文,都已经存在多部规模过万的情感词典。如何充分利用这样的资源去发现新情感词是一个有意义的工作,这也正是本文的研究内容。
3 特征分析
本节以COAE 2014 任务3提供的中文微博数据集COAET3Corpus*http://pan.baidu.com/s/1nCafe为数据源,以大连理工大学发布的情感词典DUTSD*http://ir.dlut.edu.cn/EmotionOntologyDownload.aspx[33]为统计对象,分析情感词在中文微博中的词性分布、情感词之间的点互信息、Dice系数和Jaccard系数,以及共现在同一微博中的情感词的极性差异等,主要目的是分析经典的、用于英文微博或产品评论的新情感词提取方法中所采用的一些特征是否同样适用于中文微博。
3.1 数据准备
中文微博数据集 COAET3Corpus包含9 999 626条中文微博,不是针对某一种或多种产品评论的集合,而是包含广告、个人评论、日常心情倾述、生活琐事记录等,是真实微博的一个缩影。该数据集只包含微博内容,不含诸如作者、发布时间等信息。对该数据集,首先利用中国科学院ICTCLAS2013*http://ictclas.nlpir.org分词工具进行分词和词性标注,再用Stanford的NLP工具CoreNLP*http://nlp.stanford.edu/software/corenlp.shtml对切分后的微博进行词性标。选择ICTCLAS2013进行分词的原因是,该工具考虑了中文微博的一些特点,并且可以发现并标注新词。
情感词典 情感词典基于DUTSD,并根据任务需要进行一些必要的过滤。过滤规则: (1) COAE任务3要求从中文微博中发现新情感词并判断它的极性,极性强且无歧义的情感词应该是首选,因此,实验中去掉DUTSD中有极性歧义(不同词性或不同场合时极性不一致)的情感词及情感极性标为“0”的情感词;(2) 没有出现在COAET3Corpus中的情感词对本节的统计和后面的分类学习没有帮助,无需保留;(3)考虑到微博分词时不太可能把一个较长的短语或句子划分为一个词,因此,去掉长度超过四的情感词或短语;(4) 很少在COAET3Corpus中出现的情感词,其统计意义不明显,因此去掉文档频率(每条微博视为一个文档)小于三的情感词。通过上述四条过滤规则过滤后的情感词典称为DUTSD-,包含情感词10 681条,其中正、负极性分别为5 476条和5 205条。尽管DUTSD-无法涵盖所有的情感词,但大多数常用的情感词都被纳入,因此DUTSD-包含的情感词的分布能大致反映所有情感词的分布。
3.2 情感词的词性分布
在DUTSD-中,情感词的词性分布如表1所示。其中idiom(惯用语)的比例最大,但无论是 ICTCLAS2013还是CoreNLP,都将该类词标为其他的词性。另外,同一个词,在不同的句子中也可能会标为不同的词性。
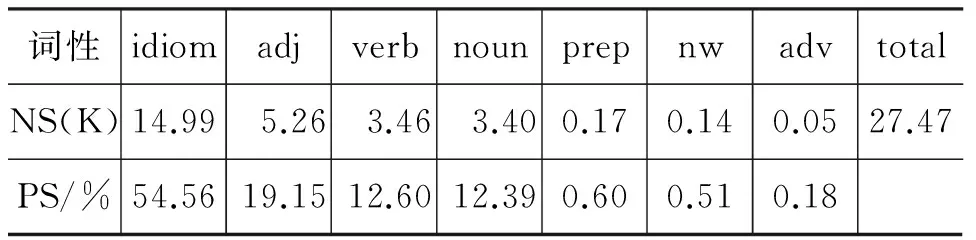
表1 情感词词性在DUTSD中的分布
表2和表3分别是DUTSD-中的情感词在COAET3Corpus中的词性分布,其中NS和PS分别表示标注为某种词性的情感词的总数(以K为单位)及其所占总情感词的比例,NT表示标为该词性的全部词数,包含其他不在情感词典中的词。需要说明的是,由于一个情感词在数据集中可能会以不同的词性出现, 因此, 表2和表3中的总词数大于DUTSD-中的总词数。表2和表3显示,有40%以
上的情感词在中文微博中以名词词性(ICTCLAS2013标为{“n”,“nl”,“nr”,“nz”,“nr2”,“n_new”, “ns”}或CoreNLP标为{“NN”, “NR”, “NT”})出现过。考虑到部分情感词会以多种不同的词性出现在数据集中,我们统计了那些只以名词词性出现的情感词,发现在英文tweets*英文微博数据来自文献[29]提供的1M tweet ids,下载后得到991 248条tweets,用Stanford CoreNLP进行词性标。中,只以名词词性出现过的情感词占情感词典MPQA*本文在统计时,采用MPQA中主观性强的词为情感词,如果是名词则添加其复数形式,如果是动词、形容词或副词,则添加其曲折变化形式,并且只考虑那些在数据集中出现的情感词。的15%,但在中文微博COAET3Corpus中,该比例高达40%。此外,tweets中以动词、形容词或副词出现过的情感词占84%,但COAET3Corpu中这一比例只有56%。结合文献[24]的实验结果,即英文中被分类为情感词的频率依次是形容词、副词、动词和名词,在综合考虑精度和召回率的情况下,在从英文微博中抽取新情感词时仅考虑动词、形容词和副词是合理的。但从中文微博中抽取新情感词时,考虑名词则非常必要。

表2 COAET3Corpus中情感词词性分布- ICTCLAS2013标注

表3 COAET3Corpus中情感词词性分布-CoreNLP标注
然而,如果将所有名词全部作为候选情感词,又会引入大量的噪音,因为大量被标为名词的词并非情感词。例如,在ICTCLAS2013标注结果中,48.38K个词标注为“n”,但仅有4.7K个是DUTSD-中的情感词,而CoreNLP标注的比较粗糙,8.25K个标为“NN”的情感词散布在335.90K个词中。
3.3 情感词的共现分析
诸如基于PMI及词汇图的方法大都假设情感词与情感词之间有较高的共现,并且同一微博中,情感词的极性是一致的。基于此假设,然后通过已知的种子情感词,扩展得到新情感词。COAET3Corpus中情感词在微博中共现的情况如表4所示。
表4显示,在COAET3Corpus中,超过36%的微博中没有包含DUTSD-中的情感词,包含两个以上情感词的微博数也仅为36%。当然,情感词典越大, 出现多个情感词的微博 数会越多。但当考察那

表4 COAET3Corpus中情感词的共现统计
些有多个情感词共现的微博时,有近40% (14.15/36.09)的微博中出现的情感词极性是冲突的。进一步的统计显示,对于DUTSD-中的10 681条情感词,有10 669条与其他的情感词在同一条微博中共现过,其中,有10 604条与相同极性的情感词共现过,而10 482与不同极性的情感词共现过。
从上面的分析可以看出,共现在同一条微博中的多个情感词的极性并不完全一致。为了进一步考察这种不一致性的统计特性,本文对情感词之间的PMI、Dice系数及Jaccard系数的平均值进行了分析,如表5所示。其中“+”,“-”分别代表正、负向极性的情感词,“0”表示非情感词。此处的非情感词是用所有不在DUTSD-中且标注为名词的词表示,尽管其中还包括一些潜在的待发现的情感词,但表2和表3显示,绝大多数这类词并非情感词。
表5显示,负向情感词之间的PMI,Dice系数和Jaccard系数明显高于该指标在其他极性词之间的值。然而,正向情感词之间、负向情感词与正向情感词之间、以及非情感词与正向情感词之间的PMI、Dice系数和Jaccard系数区别不大。因此,可以推测,用PMI、Dice系数和Jaccard系数并不能很好地评估潜在的正向情感词,进而影响到整个情感词的抽取,特别是采用Propagation方法时,极性的错误判断会传播给后续的抽取过程。
此外,当把名词作为候选情感词时,这些名词与已知情感词的PMI,Dice系数和Jaccard系数并不低于这些指标在情感词之间的值。例如,非情感词与正向情感词之间的PMI为3.25,反而高于正向情感词之间的PMI (2.47)。因此,与正向情感词共现较高的更可能是非情感词(特别是名词),而非潜在的正向情感词。当然,名词与负向情感词也存在较强的共现,因此,在实际计算候选情感词的极性时,需要考虑候选情感词与正、负向情感词共现之间的差异,但可以肯定的是,名词的加入,势必带来更多的噪声。

表5 情感词间的PMI、Dice系数和Jaccard系数
4 NGC算法
4.1 动机
3.2节和3.3节的分析表明,从中文微博中抽取新情感词时,不能仅考虑形容词、动词、副词等,名词也有必要作为候选情感词。另外,经典的基于共现的新情感词发现方法对于中文也不完全适用。原因之一是共现的情感词极性存在大量矛盾;其二是引入名词后,增加了大量的噪声,使得基于共现的思路不再有效。
在从中文微博中抽取新情感词时,两个资源的价值应该得到充分的利用,包括现有的情感词典和数亿计的微博数据。基于词汇图的方法和基于Propagation的方法通常是从数十条或上百条情感词典出发,通过极性传播或多次迭代,逐步扩展得到新情感词,适用于已知情感词极少的情况。然而,目前已有的中文情感词典非常丰富,除前面提到的DUTSD-外,还有清华大学的THUSD*http://www.datatang.com/data/44522、知网的HNSD*http://www.keenage.com/html/c_bulletin_2007.htm、台湾大学的NTUSD*http://nlg18.csie.ntu.edu.tw:8080/opinion/pub1.html等多部情感词典资源,规模都在万条左右,为基于机器学习的方法抽取新情感词奠定了良好的基础。此外,微博数据量大,可以为新情感词的学习提供大量的训练样本。因此,基于机器学习的新情感词提取方法是比较适合中文微博数据的。
根据以上分析,本文提出以N-Gram为特征的分类方法NGC,该方法以已知情感词为训练样本,以情感词上下文的N-Gram为特征,训练SVM分类器,对候选情感词进行分类,并统计分类结果,得到新情感词。需要说明的是,本文的主要目的是在统计中文微博中情感词分布的基础上,探索一种适合从中文微博中抽取新情感词的方法-基于分类思想。我们相信,采用优化的特征对分类更有利,但探索这些特征是另一项复杂的工作,我们将其放在后续的研究任务中,而本文在分类时,仅采用了非常简化的特征。尽管分类特征简单,但仍较经典的基于共现的新情感词抽取方法要好。
4.2 分类特征
尽管有文献将词、词性、依存关系等丰富的特征用于情感词提取[26],但考虑到中文微博的不规范性,本文除了将词性用于候选情感词的初步过滤外,分类特征只取决于微博中所含的词,不依赖其他语言处理工具。为简化问题并突出本文的思想,对微博中的词和标记都不做任何进一步的处理。
上下文是判断一个词是否是情感词、以及确定其情感极性的重要依据,本文采用的分类特征基于以下三个假设:
假设1 上下文中所用的词汇越一致,候选词的情感倾向性也越接近。例如,表6文档DOC458072中的“给力”和DOC76210文档中的“到位”的上下文都是“太……了”。
假设2 上下文中所含的词汇位置不同,候选词的情感倾向性也不同。例如,文档DOC458318中非情感词“感觉”和情感词“孤独”,左右窗口为1时,两词上下文相同,即{“很”,“,”},但它们与(候选)情感词的相对位置不同。此外,只考虑上下文用词与(候选)情感词前后关系是不够的,还需要考虑上下文用词之间的位置关系,例如,{“是”,“只”}在DOC113527中“有”和DOC76691中“徒劳”的前面,但前者用“是只”,后者用“只是”。
假设3 上下文的用词模式越一致,候选词的情感倾向性越接近。例如,DOC458318中的“孤独”、DOC76691中的“糟糕”、DOC76872中的“不适”,其上下文中都存在“感觉*&”这种用词模式,其中“*”为任意词,“&”为(候选)情感词。另外,“浪漫”、“孤独”和“糟糕”有相同用词模式“很&”,尽管它们的极性不同,但它们之间也有共性,即都是情感词。显然,假设2和假设3也可以捕捉到否定和修辞等对情感极性识别至关重要的信息。

表6 来自COAET3Corpus的微博样本
基于上述三个假设,使用公式(1)所示的N-Gram为特征,使得这些特征不仅包含上下文中的词,还包括词之间的序及用词模式。对于微博s=

(1)
其中,n是可调节参数, “*”表示此处为任意词或标点。例如,当n=2时,表6微博DOC458072中“给力”的特征为:F(“给力”)={“太_&”,“。_太_&”,“&_了”,“&_了_哈哈”,“。_*_&”,“&_*_哈哈”}。
尽管公式(1)基本满足了上述三种假设,但仍然存在极性判断错误的可能性,因此,还需要利用微博数据量大的特征,在分类结束后对分类结果进行投票计分并排序。例如,利用投票,如果在多数情况下将“孤独”分类为负向情感词,则最终认定“孤独”的情感倾向为负,并且将其分类为“有情感”的比例越大,认为其“有情感”的可能性越大。
我们有理由相信,恰当的预处理和更加丰富的上下文词汇特征会改善分类的效果。例如,将标点符号“。”“,”“;”等视为同一种标记、利用依存分析考虑长距离依赖、挖掘和解释更有效的用词模式等。此外,融合其他用于中文微博情感分类的特征也可能提高新情感词提取的效果,这是我们将来的主要工作之一。
4.3 算法
NGC算法主要包括以下六步。
Step 1 构建情感词词典SD和非情感词词典NSD。通过以下两个假设来构建情感词典和非情感词典: (1)情感词要求没有歧义,本文选用DUTSD-作为情感词典;(2)所有可能存在情感的词、以及未登录词都不应该作为非情感词,本文用公式(2)来构建非情感词词典。
NSD = CommonDict-MixSD
(2)
其中CommonDict是一个通用的词典,包含情感词及非情感词,本文选用COAE任务3提供的通用词典;混合情感词典MixSD(共38 445条)中,DUTSD、HNSD、THSD、NTUSD分别为来自大连理工大学、知网、清华大学、台湾大学的情感词典,新浪微博表情符号为部分标注过的符号,如“[c伤心]”标注为负极性情感词。
Step 2 对中文微博数据集进行分词和词性标注。本文选择ICTCLAS2013作分词及词性标注。
Step 3 根据SD和NSD构建训练样本。对于来自微博s的词t,如果t∈ SD,则t的标签为t在SD中的极性,"+1"表示情感倾向为正,"-1"表示情感倾向为负;如果t∈ NSD,则t的标签为"0"。t的特征如公式(1)所示。
相比情感词,数据集中更多的是非情感词,这导致样本分布严重失衡。设被贴上标签“0”的样本数为C0,为平衡样本分布,本文随机选择βC0个样本参与训练,其中参数0<β<1。
Step 4 抽取候选新情感词。微博数据集中所有未通过step 3贴上标签的词,如果满足以下条件,则被视为候选新情感词,参与后续的分类过程: (1)词长在2至4之间;(2)文档频率大于等于3;(3)被标注的词性属于指定的候选词性集合POS。作为对比,本文在实验部分考虑了不同的候选词性对新情感词提取的影响。
Step 5 训练分类器并对候选新情感词分类。利用Step 3得到的样本训练SVM分类器,并对候选新情感词进行分类。本文选择libleaner 1.94*http://www.csie.ntu.edu.tw/~cjlin/liblinear/完成训练与分类任务,训练参数设置为: “-s 4 -e 0.1”。
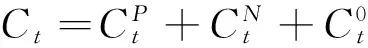
(3)
其中参数α为用于调节正向与负向情感词样本不均导致的分类偏差(在COAET3Corpus中,正负极性样本比例为3.5∶1),本文在实验的基础上设置其值为2.5。该分值大于0,表示情感倾向性为正,小于0,表示倾向性为负,其绝对值越大,表示对该词情感倾向性的划分越可信。在返回结果时,去掉Score值为0的候选词,并对剩余的候选新情感词按Score的绝对值排序(不限制返回结果的个数)。
5 实验分析
除参与COAE 2014 任务3评测外,本节组织了更详细的实验、评测和分析。中文微博数据集选用COAET3Corpus,情感词词典SD和非情感词词典NSD来自第四节的Step 1。将SD均分为两份SDTrain和SDTest,分别用于训练和测试。
5.1 评测方法
以SDTest为理想结果,采用两组评测指标,Bpref[34]以及插值后11点平均精度AP。选择Bpref作为评测指标的原因在于,对于新情感词发现任务,"理想"的新情感词词典SDTest规模非常有限,不在SDTest及NSD中的词未必不是新情感词。因此,对于这些不能确定是否为情感词的部分,Bpref不将它们纳入考虑范围。此外,Bpref还考虑了新情感词在返回结果中的位置,越靠前越好。然而,如果返回大量不在SDTest及NSD中的非情感词,Bpref同样无法检测到,但AP指标可以探测到。因此,结合Bpref和AP是必要的。实验观察到召回为0时的精度极易受到首个返回词是否来自SDTest的影响,波动较大,超出了该词对整个评测结果的影响,因此本文中的AP不考虑召回为0时的情况。另外,评测结果是将SD进行三次均分,然后进行三次训练、测试得到的结果的平均值。
5.2 结果与分析
按照第三节的分析,除形容词外,名词作为候选新情感词是必要的。为了验证该假设,本文对比了四组候选新情感词的词性集合,分别为:
PosAll = 全部词性集合,即所有词都作为候选情感词。
PosAVDN = {n, vl, a, v, vn, vi, an, nl, z, al, ad, d, b, dl, vd, bl },即根据表2中统计的情感词词性分布,从最频繁的词性开始依次选取,直到覆盖98%以上的情感词为止。
PosAVD = { vl, a, v, vn, vi, an, z, al, ad, d, b, dl, vd, bl },即去掉PosAVDN中的名词。
PosA = {a, an, al, ad},即只保留PosAVDN中的形容词。
实验结果如表7所示。其中PMI,Dice,Jaccard为文献[9]采用的情感词识别方法;Bpref和AP不考虑极性判断是否正确,只看新情感词是否在情感词词典中;而Bpref_PN和AP_PN要求新情感词的极性判断也要正确;Bprf_P和AP_P表示对正向新情感词的评测结果,Bprf_N和AP_N表示对负向情感词的评测结果。
表7显示,不论是基于共现的PMI,Dice,Jaccard方法,还是基于分类的NGC方法,将名词加入候选情感词集合中,结果的Bpref和AP值都更高。相比PosADVN,PosAll将全部词作为候选情感词,其AP得分远低于PosADVN的得分。对于NGC方法,那些不在情感词典或非情感词典中的词,由于极性无法判断因此被Bpref忽略,所以Bpref值并没明显下降。但进一步观察NGC在PosAll上的返回结果发现,的确有大量形如“赢美食卷”“美颜之”“秋冬里”之类的难以定性的词(或者根本不能称之为词),但在Bpref和AP指标上仍高于PMI等基于共现的方法。这一方面说明了NGC相比PMI的优势依然存在,另一方面也体现了增加候选词的确给新情感词的抽取带来挑战。
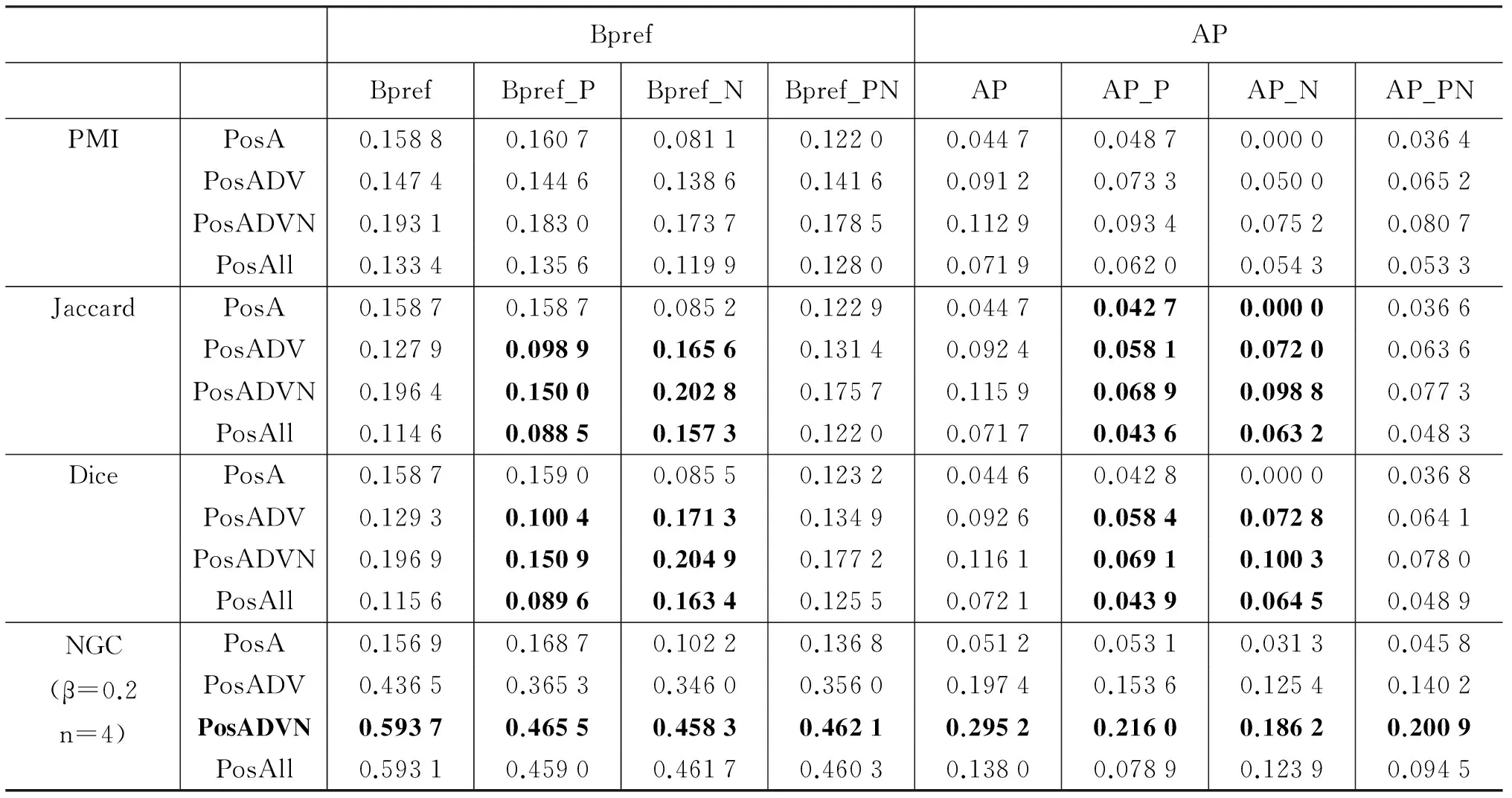
表7 情感词抽取结果评测
表7同时也显示,如果只考虑形容词,经典的基于共现的方法与NGC方法效果是相当的,并无明显差异。但考虑更多候选词性后,NGC方法远好于基于共现的方法。
在3.3节中提到,在中文微博中,负极性的情感词之间的PMI、Dice系数和Jaccard系数要明显高于这些指标在其他类型词之间的值,说明负极性情感词之间的共现更强烈,从而使得负极性的新情感词更容易被抽取,这与表7中的评测结果是一致的: 当情感词不局限在形容词时,Jaccard和Dice方法对负极性新情感词抽取结果的得分都明显高于对正极性新情感词的抽取。另外,当候选词仅为形容词时,由于其中的负向情感词太少使得召回率无法达到0.1,导致相应的AP_N得分为0。
Bpref和AP体现了各种方法的总体效果,而图1展示了基于共现的方法PMI与基于分类的方法NGC在不同候选词性上的11点精度插值曲线。
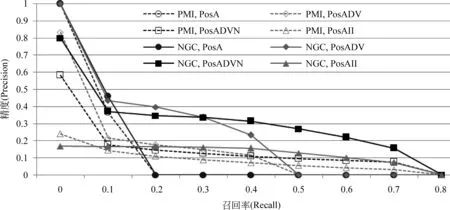
图1 11点精度插值曲线: PMI vs. NGC (β=0.2, n=4)
图1显示,基于共现的PMI方法可以比较准确地判断一个形容词是否是情感词,但随着更多词性的候选情感词加入,这种准确性越来越低。另外,当只考虑形容词为候选情感词时,召回率为0时精度(插值后)非常高,说明对排名靠前的这些形容词的情感倾向性判断是非常准确的。这从另一个侧面说明,如果只考虑形容词,基于共现及Propagation的英文新情感词发现方法不仅对英文有效,对中文也同样有效。对比图1中NGC方法与PMI方法在不同词性上的表现,结论是,无论是否考虑名词词性,NGC方法不仅在召回率为0时的精度比较高,并且在召回率较高时,发现新情感词的精确度远远高于PMI方法。
图2显示了平衡非情感词样本的参数β对新情感词抽取效果的影响。当β=0.2左右时,训练数据中标签为“0”的样本约占总样本数量的70%。之所以减少非情感词的样本数量,目的在于将更多的候选情感词分类到正、负极性集合中,然后再采用投票的办法对其打分。如果太多的候选词都被分类为无极性,则对这部分词的投票打分结果都为0,无区分性。当然,标签为“0”的样本也不能过少,否则会影响到分类的准确性。
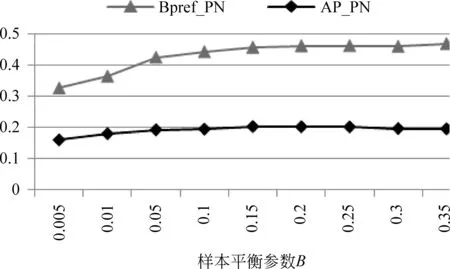
图2 参数β对NGC的影响(PosADVN, n=4)
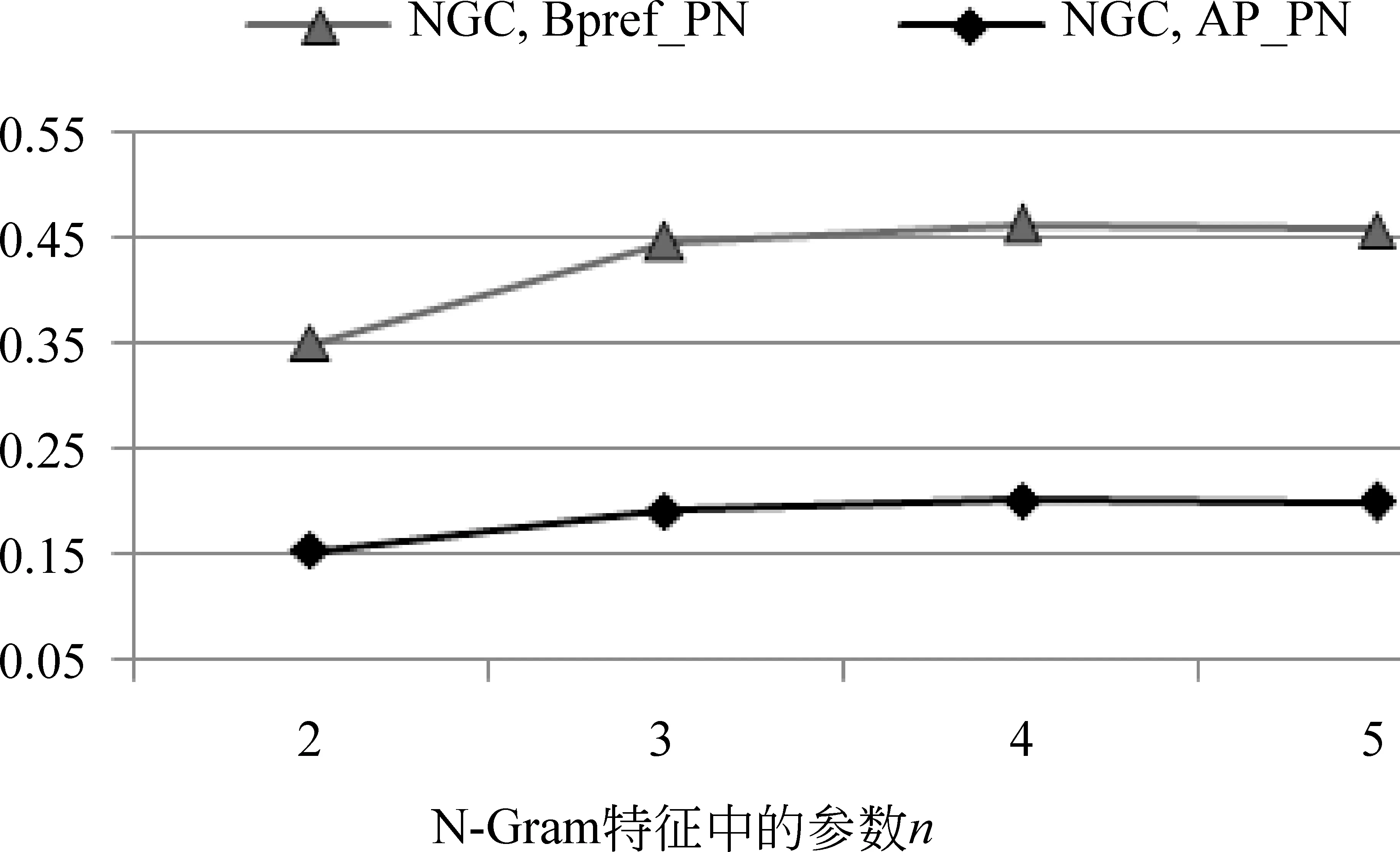
图3 参数n对NGC的影响(PosADVN,β=0.2)
图3给出了N-Gram特征中参数n的影响。可以看出,当n从2增加到3时,新情感词的抽取效果明显提高。如果n继续增加到4时,尽管有改善,但效果已不明显。也就是说,如果仅以定长窗口为上下文,窗口大小设定为3就比较合适了。当然,如4.2节所述,基于语法分析结果的长距离依赖是否有效,还有待进一步探讨。
4.2节中给出了用于确定NGC分类特征的三个假设,作为对比,图4中给出了特征选择对新情感词抽取的效果。其中UGC只考虑假设1,以上下文中的一元(unigram)信息为特征,即FUGC(ti) = {ti-n,…,ti-1,ti+1,…,ti+n};UGCL同时指定一元信息位于候选(情感词)的前或者后,即FUGC(ti)= {ti-n_&, ...,ti_&, &_ti+1, ..., &_ti+n};NGCL考虑上下文的用词及词汇位置,但不考虑其中的用词模式,即:FNGC-L(ti) = {ti-1_&,&_ti+1,
ti-2_ti-1_&,&_ti+1_ti+2, …,ti-n_..._ti-1_&,&_ti+1_..._ti+n};NGC+UGCL除采用式NGC在公式(1)中的特征外,增加了UGCL的特征,因为UGCL中的特征可以看成是另一种用词模式。很显然,只考虑上下文中的unigram是不够的,但考虑unigram位于(候选)情感词的前或后是有帮助的。仅用(候选)情感词前后N-Gram的NGCL效果已经比较理想,增加用词模式后的NGC的确可以进一步改善抽取效果,但并不意味着越多的用词模式(NGC+UGCL)就会越好。
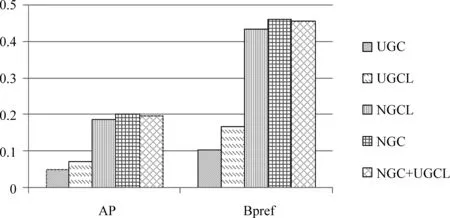
图4 不同词汇特征对分类的影响(β=0.2, n=4)
5.3 COAE 2014 任务3评测结果
COAE 2014任务3要求从COAET3Corpus中选择不出现在CommonDict词典中的新情感词一万条,26支参赛系统中排名前十的评测结果如表8所示。我们提交的两个系统中,UdeM-t3-1是采用NGC算法。由于该任务要求提交的新情感词不在给定词典CommonDict中即可,因此,作为UdeM-t3-1的参照,在UdeM-t3-2中,先从混合情感词典MixSD中选择出现在COAET3Corpus中但不在CommonDict中的词8 246条作为新情感词,不足的1 754 条再根据Score值从NGC算法得到的结果中选取。对于MixSD中存在极性歧义的情感词(在同一情感词典或不同的情感词典中标注的极性不同),其情感极性为情感词所在微博中,极性最强的那条微博的极性。微博的极性则用libleaner的线性回归
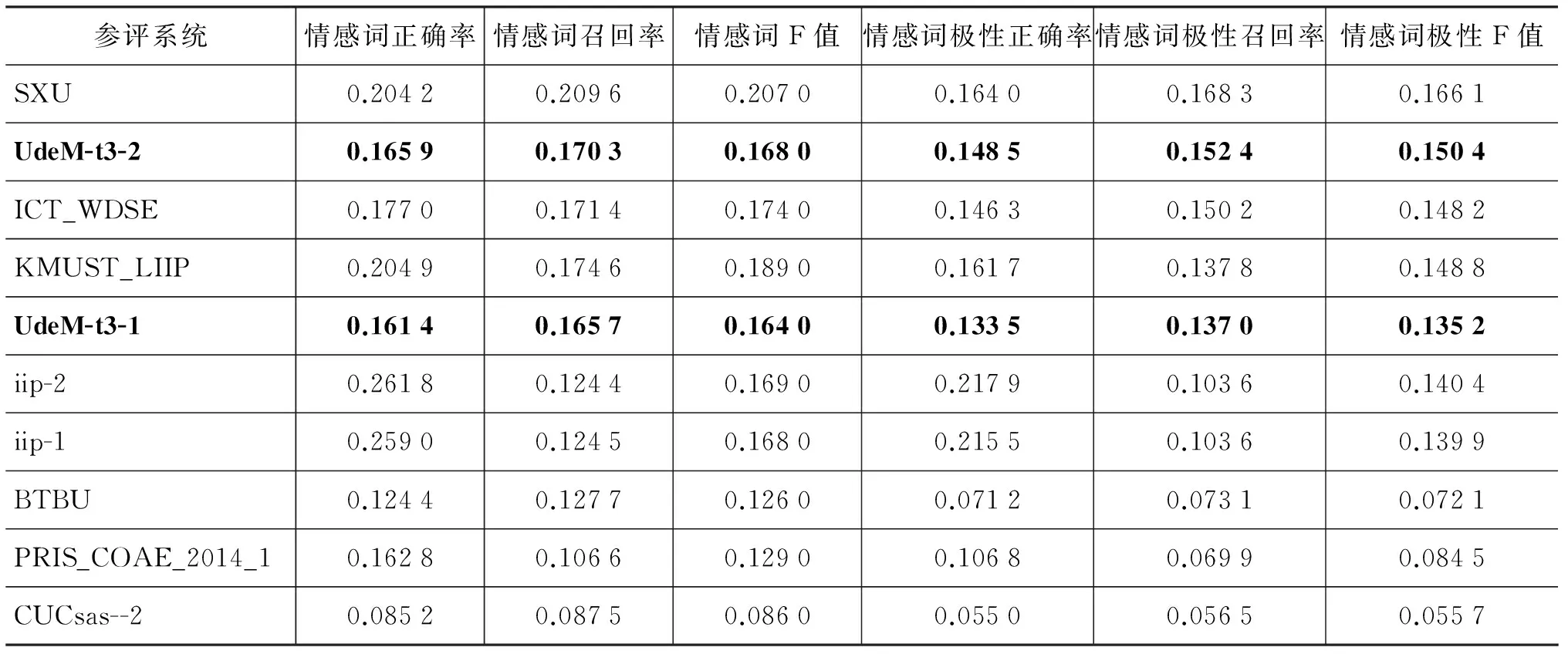
表8 COAE 2014任务3中排名前十的参赛系统及评测结果
方法,在COAE 2013*http://ccir2013.sxu.edu.cn/COAE.aspx和NLP&CC 2012*http://tcci.ccf.org.cn/conference/2013/pages/page04_tdata.html提供的微博情感分类数据集上训练得到。
表8显示,尽管UdeM-t3-2从已知的混合词典中选取了8 000余词条,但如果不考虑极性,仅从情感词的召回和精度看,F值只有0.168 0,而最好系统的F值也仅为0.207 0。一个可能的原因是,微博中的情感词远不止10 000条,这样尽管所提交结果中的80%词条来自已知的情感词典,但它与参考答案给出的情感词相互覆盖率仍然很低。普遍较低的F值也说明从中文微博中提取新情感词是一项具极具挑战性的任务。另外,采用NGC方法的Ude-M-t3-1 与UdeM-t3-2的评测结果并没有明显的差距,这反映出NCG方法的性能接近直接从已知情感词典中选择情感词的效果,其在整个参赛系统中也表现出很强的竞争力。
6 结论与展望
由于在舆情分析和产品评论分析等领域有着重要的应用价值,文本情感分析近年来受到国内外学术界和企业界的普遍关注。情感词典作为文本情感分析的重要资源,需要覆盖全、更新快、标注准。人工构建情感词典尽管标注准确,但覆盖有限,更新困难,特别在Web 2.0环境下,新情感词层出不穷、传播迅速,因此,需要采用自动或半自动的方式从各种网络数据中抽取新情感词,而微博就是可用于新情感词抽取的重要网络数据之一。
本文利用手工构建的情感词典,分析了中文微博数据中情感词分布的特点,包括其情感词的词性分布、情感词共现情况、共现的情感词间极性冲突情况,以及这些特点给新情感词抽取带来的挑战。基于以上分析,提出了基于分类的新情感词抽取方法NGC。NGC充分利用已有的情感词典资源和微博数据量大的特点,将候选情感词扩大到名词词性上,并以已知情感词或候选情感词上下文的N-Gram组合为特征,训练SVM分类器并对候选情感词进行分类,最后再采用投票的方式确定情感词的极性及该极性的可信度。在AP和Bpref两个指标上的评测结果都显示,考虑名词对中文微博新情感词抽取是必要的。考虑名词意味着加入了大量的非情感词作为候选,加大了抽取的难度。实验结果显示,考虑名词后,NGC方法比基于共现的PMI等方法更有效,其在COAE 2014 任务3中也表现出很强的竞争力。
目前,NGC采用的特征非常简单,仅考虑了已知情感词和候选情感词定长窗口内的上下文,并且没有做任何进一步的处理。对于中文新情感词的抽取,还有哪些特征可以利用,这些特征在中英文等不同语种上有何异同,在微博或新闻类数据上有何异同,都值得我们进一步探讨。此外,分词是从中文微博中抽取新情感词需要克服的一大障碍,在COAE 2014任务3提供的参考答案中,有正负极性的词条共3 468个,其中2 469个都没有被ICTCLAS2013正确分词。
[1] Pang B, L Lee. Opinion Mining and Sentiment Analysis[J]. Foundations and Trends in Information Retrieval. 2008, 2(1-2): 1-135.
[2] 赵妍妍, 秦兵, 刘挺. 文本情感分析[J]. 软件学报, 2010,21(8): 1834-1848.
[3] Liu B. Sentiment Analysis and Opinion Mining. Morgan & Claypool. 2012.
[4] Jiang L, et al. Target-dependent Twitter sentiment classification[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics: Portland, Oregon. 2011: 151-160.
[5] Bravo-Marquez F, M Mendoza, B Poblete. Combining strengths, emotions and polarities for boosting Twitter sentiment analysis[C]//Proceedings of the Second International Workshop on Issues of Sentiment Discovery and Opinion Mining. ACM: Chicago, Illinois. 2013: 1-9.
[6] Hatzivassiloglou V, K R McKeown. Predicting the semantic orientation of adjectives[C]//Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics and Eighth Conference of the European Chapter of the Association for Computational Linguistics. Association for Computational Linguistics: Madrid, Spain. 1997: 174-181.
[7] Turney P D, M L Littman. Measuring praise and criticism: Inference of semantic orientation from association[J] Acm Transaction on Information System. 2003, 21(4): 315-346.
[8] Kaji N, M Kitsuregawa. Building Lexicon for Sentiment Analysis from Massive Collection of HTML Documents[C]//Proceedings of EMNLP-CoNLL. 2007: 1075-1083.
[9] Feng S, et al. Is Twitter A Better Corpus for Measuring Sentiment Similarity?[C]//Proceedings of EMNLP2013. 2013: 897-902.
[10] Yu H, Z H Deng, S Li. Identifying Sentiment Words Using an Optimization-based Model without Seed Words[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. 2013: 855-859.
[11] Kamps J, et al. Using wordnet to measure semantic orientations of adjectives[C]//Proceedings of 4th International Conference on Language Resources and Evaluation. 2004: 1115-1118.
[12] Andreevskaia A, S Bergler. Mining WordNet for a Fuzzy Sentiment: Sentiment Tag Extraction from WordNet Glosses[C]//Proceedings of EACL. 2006: 209-215.
[13] Rao D, D Ravichandran. Semi-supervised polarity lexicon induction[C]//Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguistics. Association for Computational Linguistics: Athens, Greece. 2009: 675-682.
[14] Esuli A, F Sebastiani. Pageranking wordnet synsets: An application to opinion mining[C]//Proceedings of ACL. 2007: 442-431.
[15] Hassan A, D Radev. Identifying text polarity using random walks[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics: Uppsala, Sweden. 2010: 395-403.
[16] Hassan A, et al. Identifying the semantic orientation of foreign words[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: short papers-Volume 2. Association for Computational Linguistics: Portland, Oregon. 2011: 592-597.
[17] Velikovich L, et al. The viability of web-derived polarity lexicons, in Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics: Los Angeles, California. 2010: 777-785.
[18] Peng W, D H Park. Generate adjective sentiment dictionary for social media sentiment analysis using constrained nonnegative matrix factorization[C]//Proceedings of ICWSM. 2011.
[19] Qiu G, et al. Expanding Domain Sentiment Lexicon through Double Propagation[C]//Proceedings of IJCAI. 2009: 1199-1204.
[20] Zhao W X, et al. Jointly modeling aspects and opinions with a MaxEnt-LDA hybrid[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics: Cambridge, Massachusetts.2010:56-65.
[21] Lazaridou A, I Titov, C Sporleder. A bayesian model for joint unsupervised induction of sentiment, aspect and discourse representations[C]//Proceedings of ACL. 2013: 1630-1639.
[22] Xu L, et al. Walk and learn: a two-stage approach for opinion words and opinion targets co-extraction[C]//Proceedings of the 22nd international conference on World Wide Web companion. International World Wide Web Conferences Steering Committee: Rio de Janeiro, Brazil. 2013: 95-96.
[23] Kim S-M, E Hovy. Determining the sentiment of opinions[C]//Proceedings of the 20th international conference on Computational Linguistics. Association for Computational Linguistics: Geneva, Switzerland. 2004: 1367-1373.
[24] Esuli A, F Sebastiani. Sentiwordnet: A publicly available lexical resource for opinion mining[C]//Proceedings of LREC. 2006.
[25] Mohtarami M, M Lan, C L Tan. Probabilistic Sense Sentiment Similarity through Hidden Emotions[C]//Proceedings of The 51st Annual Meeting of the Association for Computational Linguistics.2013:983-992.
[26] Wiebe J. Learning subjective adjectives from corpora[C]//Proceedings of AAAI/IAAI. 2000: 735-740.
[27] Hatzivassiloglou V, J M Wiebe. Effects of adjective orientation and gradability on sentence subjectivity[C]//Proceedings of the 18th conference on Computational linguistics-Volume 1. Association for Computational Linguistics. 2000: 299-305.
[28] Riloff E, J Wiebe, T Wilson. Learning subjective nouns using extraction pattern bootstrapping[C]//Proceedings of the 7th Conference on Natural Language Learning at HLT-NAACL 2003-Volume 4. Association for Computational Linguistics: Edmonton, Canada. 2003: 25-32.
[29] Volkova S, T Wilson, D Yarowsky. Exploring sentiment in social media: Bootstrapping subjectivity clues from multilingual twitter streams[C]//Proceedings of Association for Computational Linguistics (ACL). 2013: 505-510.
[30] Xu G, X Meng, H Wang. Build Chinese emotion lexicons using a graph-based algorithm and multiple resources[C]//Proceedings of the 23rd International Conference on Computational Linguistics. Association for Computational Linguistics: Beijing, China. 2010: 1209-1217.
[31]DuW,etal.Adaptinginformationbottleneckmethodforautomaticconstructionofdomain-orientedsentimentlexicon[C]//Proceedingsofthe3rdACMInternationalConferenceonWebSearchandDataMining.ACM:NewYork,NewYork,USA. 2010: 111-120.
[32]ZhangL,BLiu.Identifyingnounproductfeaturesthatimplyopinions[C]//Proceedingsofthe49thAnnualMeetingoftheAssociationforComputationalLinguistics:HumanLanguageTechnologies:shortpapers-Volume2.AssociationforComputationalLinguistics:Portland,Oregon. 2011: 575-580.
[33] 徐琳宏,等. 情感词汇本体的构造[J]. 情报学报, 2008. 27(2): 180-185.
[34]BuckleyC,EMVoorhees.Retrievalevaluationwithincompleteinformation[C]//Proceedingsofthe27thAnnualInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval. 2004: 25-32.
Extracting Sentimental Lexicons from Chinese Microblog: a Classification Method using N-Gram Features
LIU Dexi1, NIE Jianyun2, ZHANG Jing3, LIU Xiaohua2, WAN Changxuan1, LIAO Guoqiong1
(1. School of Information Technology, Jiangxi University of Finance and Economics, Nanchang, Jiangxi 330013, China;2. Department of Computer Science and Operations Research, University of Montreal, Montreal, H3C3J7,Canada;3. School of Computer Science and Engineering, South China University of Technology, Guangzhou, Guangdong 510641, China)
Sentimental analysis heavily relies on resources such as sentimental dictionaries. However, it is difficult to manually build such resources with a satisfactory coverage. A promising avenue is to automatically extract sentimental lexicons from microblog data. In this paper, we target the problem of identifying new sentimental words in a Chinese microblog collection provided at COAE 2014. We observe that traditional measures based on co-occurrences, such as pointwise mutual information, are not effective in determining new sentimental words. Therefore, we propose a group of context-based features, N-Gram features, for classification, which can capture the lexical surroundings and lexical patterns of sentimental words. Then, a classifier trained on the known sentimental words is employed to classify the candidate words. We will show that this method works better than the traditional approaches. In addition, we also observe that, different from English, many sentimental words in Chinese are nouns, which cannot be discriminated using co-occurrence-based measures, but can be better determined by our classification method.
sentimental lexicon extracting; Chinese microblog; classification method; N-Gram features

刘德喜(1975—),博士,教授,主要研究领域为社会媒体处理、信息检索、自然语言处理等。E-mail:dexi.liu@163.com聂建云(1963—),博士,教授,主要研究领域为信息检索、自然语言处理等。E-mail:nie@iro.umontreal.ca张晶(1973—),博士,讲师,主要研究领域为自然语言处理。E-mail:zhjing@scut.edu.cn
1003-0077(2016)04-0193-13
2014-09-15 定稿日期: 2015-03-20
国家自然科学基金(61363039, 61173146, 61363010);国家社会科学基金(12CTQ042)
TP391
A
