基于马尔科夫逻辑网的中文专利最大名词短语识别
2016-05-03蔡东风赵奇猛王裴岩
蔡东风,赵奇猛,饶 齐,王裴岩
(沈阳航空航天大学 知识工程研究中心,辽宁 沈阳 110136)
基于马尔科夫逻辑网的中文专利最大名词短语识别
蔡东风,赵奇猛,饶 齐,王裴岩
(沈阳航空航天大学 知识工程研究中心,辽宁 沈阳 110136)
缺少标注语料和难以识别动词和名词类是阻碍中文专利最大名词短语识别的主要问题。针对上述问题,该文提出了一种基于马尔科夫逻辑网的中文最大名词短语识别方法。该方法避免对开放类的名词短语的识别,而将主要精力放在了相对封闭的分隔符的识别上,利用句子自身特征、领域迁移特征以及双语对齐特征来识别最大名词短语的边界。结果说明,双语信息较好地促进了动词、介词、连词等MNP边界的识别。MNP识别的F值可达83.27%。
最大名词短语;马尔科夫逻辑网;中文专利
1 引言
文本的实体和概念通常可由句中的名词短语来描述,识别出句中的名词短语,也就基本抓住了文本所包含的主要意思[1]。最大名词短语(Maximal-length Noun Phrase, MNP),即句子中不被其他任何名词短语所嵌套的名词短语。
早期MNP识别相关工作主要围绕以英文为主的西方语言中进行,且具有实用性。从早期基于规则的方法[2-3],到后期基于统计模型的方法,其中很多是在马库斯等[4]基础上展开的。
相对于英文的MNP识别,中文由于存在着大量套叠现象[5],进一步加大了对MNP识别的难度。李文捷等[6]较早开展了中文MNP识别的工作,使用词性标记对和短语边界共现概率识别句中的MNP,其开放测试的准确率达到了71.3%。代翠等[7]提出一种利用边界特征和内部结构特征,基于统计和规则的方法,系统开放测试结果F值达到了90.2%。鉴萍等[8]提出了一种同时利用“分歧点”的概率和确定性的双向标注技术的识别方法,在封闭测试中,F值为86.9%。钱小飞等[9]提出融合多模型识别结果,以及使用针对性的规则识别歧义边界的集成方法,在清华大学TCT树库上的MNP识别的F值达到89.46%。Zhou等[10]在CTB5.1树库语料上,使用句法分析结果的重排序策略对MNP进行识别取得较好的结果。
相对于通用领域的中文MNP识别的众多研究,针对中文专利文献MNP识别的研究甚少,其主要原因是缺少标注的领域语料以及其中的动词和名词类识别困难。针对这一问题,本文从MNP边界分析着手,提出一种在双语摘要基础上,结合通用领域语料的迁移特征,应用马尔科夫逻辑网自动识别MNP的方法。
本文的后续组织结构如下: 第二部分为本文提出的中文专利MNP的自动识别方法;第三部分为实验结果及分析;最后是结论及将来工作介绍。
2 基于MLN的中文专利MNP的识别
专利文献句子用词严谨、形式规范和结构性强,一定程度上来说适合使用规则进行结构成分的识别。但中文专利句子长度过长、大量未登录术语和动词的频繁使用的特点又增加了对句子整体结构识别的难度。
本文对中文专利语料的分析发现,能够充当MNP外边界分割符的词类有介词、动词、连词、标点符号、副词等。相对于识别存在大量未登录词的名词集合,我们通过对相对封闭的分隔符集的识别来达到MNP识别的目的。即使如此,对动词这类分隔符的识别也是较为困难的,原因在于汉语中动词的使用非常灵活,一个动词经常具有多种语法功能,导致出现大量的语法歧义现象。例如,“……生成MNP[滚动角指令]驱动MNP[第二单轴转台]转动……”,其含有的动词集合为{“生成”, “滚动”, “驱动”, “转”, “转动”},这里称为候选分割符集,而其中只有“生成”、“驱动”和“转动”是正确的分隔符。对于动词类分隔符识别的难度主要体现在两点: 一是动词边界特征不明显;二是在专利中经常作为名词性术语短语的构成部分出现。而英文属于屈折语,其词特征和句法特征比较明显,可以很好辅助中文MNP边界的识别。
本文设想利用中英平行语料的词对齐信息来辅助汉语的MNP识别。然而在实际应用中,会存在两个问题: 一是中文和英文的词并不是一一对应,会有不同程度的省略等;二是即使双语信息都较为全面,算法以及双语词典规模的限制也并不能保证词对齐的完全召回以及正确。出于上述考虑,本文同时利用句子局部信息、其他领域迁移的特征信息以及双语信息来实现中文专利MNP识别,利用马尔科夫逻辑网对上述三类信息进行统一表示。
本文的整体系统框架流程图如图1所示。
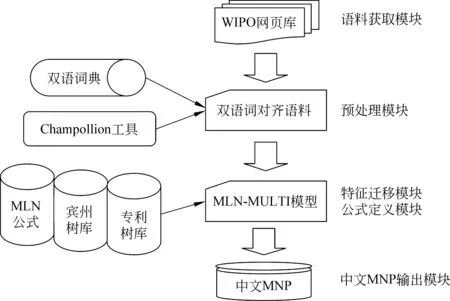
图1 系统流程图
本文的中文专利MNP识别方法包括四部分内容: 双语语料的获取与预处理、候选分割符集获取、特征迁移以及马尔科夫逻辑网的构建。
2.1 双语语料获取与预处理
中文专利文献和学术论文一般都会提供双语的标题和摘要。这两类文献的中英标题与摘要都是相关行业专业人员精心编写,质量较高。
本文从世界知识产权组织WIPO网站自动抓取了电子和计算机相关方向的24 485篇专利文献的中英标题和中英摘要部分,作为原始平行语料。
本文将双语标题充作高质量的句对齐语料。而摘要部分通常由多个句子组成,为了获得较好的词对齐结果,需要预先对双语摘要进行句对齐。对英文摘要的分句使用开源工具OpenNLP得到。中文摘要段落的断句则是通过识别“……、。、!、?、;”等标点符号完成的。紧接着,通过CTK/CSA(champol-lion sentence aligner)对已经完成断句的中英文摘要进行句对齐,CTK/CSA (champollion sentence aligner)是一种基于双语词典和句子长度的句对齐算法。双语词典对句对齐至关重要,本文通过动态获取每对中英摘要词对齐来补充CTK/CSA的双语词典。简而言之,获取双语摘要初始的词对齐,将可信度高的词对齐(中到英和英到中都存在对齐)加入CTK/CSA词典,在此基础上再次进行句对齐。接着,在句对齐的基础上进行基于词典的词对齐,得到双语词对齐语料。
2.2 候选分隔符词表收集
候选分隔符词表收集来源主要有宾州中文树库CTB5.1、北大词表和3 000常用词以及本实验室标注的中文专利依存树库(CPDT1.0)。其中,专利依存树库CPDT的句子来源有生化、机电等学科的中文专利文献摘要部分,其标注的类别有分词(Seg)、词类(Pos)、实体块(Chunk)和依存句法。中文专利依存树库的相关统计信息见表1。
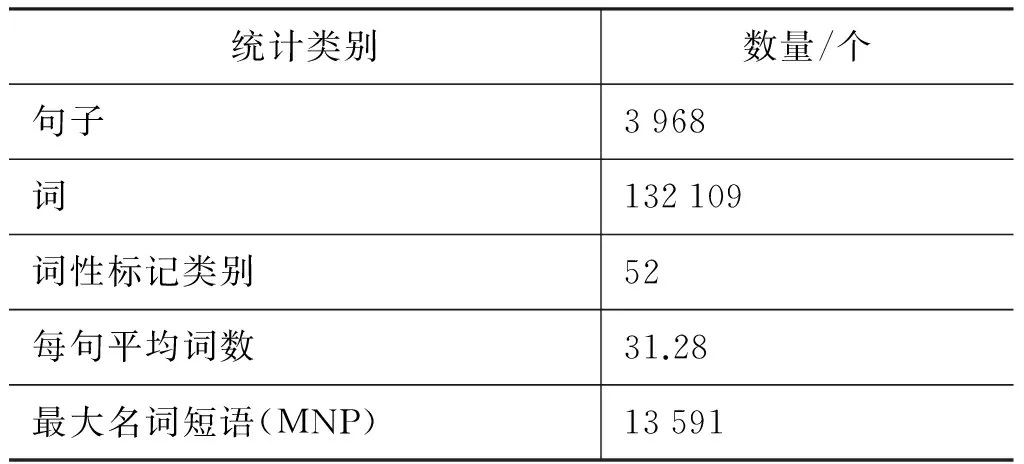
表1 中文专利依存树库相关数据
从树库获取候选分隔符集的主要依据是该词所标注的词性属于介词、动词、连词、标点符号、副词等分隔符词类集且在MNP界外。收集的候选分隔符词表各类别统计如表2。
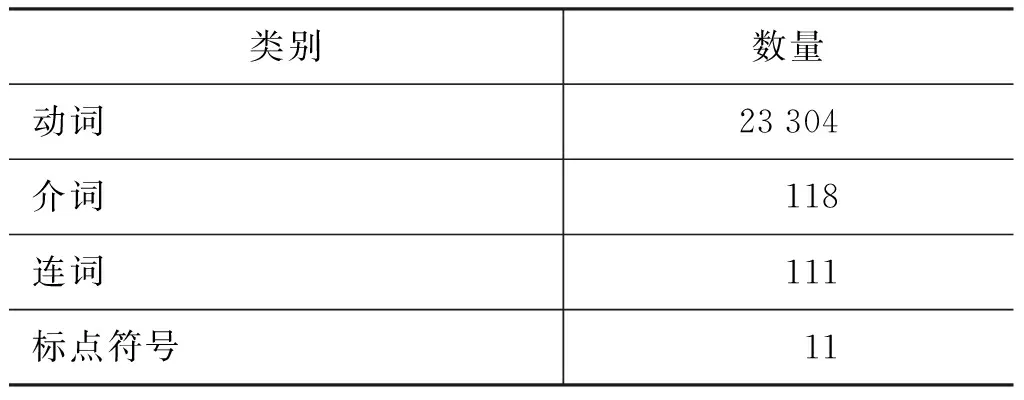
表2 候选分隔符词表相关数据
2.3 特征迁移
专利领域标注资源的缺乏,制约着基于统计学习的中文专利MNP识别方法的性能。将其它领域的已有标注资源作为扩充信息迁移到目标领域加以有效利用,可以在一定程度上缓解特征稀疏问题。本方法基于一种迁移其他领域的字和词级别特征信息能够带来中文专利MNP识别性能提升的假设,并验证。本文特征迁移的来源有两个,一是宾州中文树库CTB5.1,二是中文专利树库CPDT1.0。
进一步说,为使从两个语料库迁移的特征分布能够相似,也即本文使用相同的句子切分方法依次对CTB5.1和CPDT1.0中的句子重新进行切分。句子切分方法见算法1。
算法1 句子切分算法
输入: 双语词对词典bi_dict,所有候选分隔符集合candidate_separator_set,句子串sen_str
结果: 对sen_str进行切分后的词串word_str
第三方工具: 开源工具ICTCLAS
步骤:
1. 使用词典bi_dict对句子串sen_str应用最大正向初步切分,得到sen_seg_str
2. 使用candidate_separator_set对步骤1结果sen_seg_str中没处理的块应用最大正向切分,得到can_seg_str
3. ICTCLAS不加载用户词典的情形下对can_seg_str中没处理的块进一步切分,得到word_str
6. 返回切分结果word_str
需要说明该算法定义为句子切分而不是分词是因为我们无需名词等分词的正确性,需要确保的是句中的候选分隔符都能够被准确地切分出来。算法中双语词典的应用可以很好地转换中文到英文以解决切分的交集型歧义。如“使用具”可被正确的切分为“使 用具”。
对于2.2节中获取到的候选分隔符词表中的每个词进行特征提取。特征集包括不同窗口字级特征和词级特征。字级特征包括: 字级公共组合特征C_Com;C_L1-R1,即分隔符的左1字与右1字的组合;C_R1-R2,分割符的右1字与右2字的组合;C_L1-R1-R2,分隔符的左1字、右1字与右2字的组合。词级特征包括: 词级公共组合特征W_Com;W_L1-R1,分割符的左1词与右1词的组合;W_R1-R2,分隔符的右1词与右2词的组合;W_L1-R1-R2,分隔符的左1词、右1词与右2词的组合。
最后,为了计算各个候选分隔符集相关特征的权重,需要统计正例和负例的出现次数。如式(1)所示。
(1)
其中,featureYesNum表示候选词是正例的情况下该特征出现的次数,featureTotal表示候选词正例和负例情况下该特征出现的次数。
2.4 MLN模型的构建
马尔科夫逻辑网[11](Markov Logic Networks,MLN)是一种将马尔科夫网络概率的思想应用到确定性一阶逻辑的框架。从两方面来说,一是可以使用一阶逻辑来描述构建复杂Markov网更加方便,二是一阶逻辑同时具备了概率推理的能力。
在本文的方法中,对于每个候选分隔符而言,其有两种状态,True和False。True表示该候选分隔符为正确的分隔符,即MNP外边界。False表示该候选分隔符并不是正确的MNP边界。其概率如公式(2)所示。
(2)
其中,wi是逻辑公式的权重,公式包括局部公式和全局公式,ni代表取值为真的公式个数。判断该词是否为分隔符只需判断P(yj=True)是否大于设定的阈值。
有关MNP识别的MLN的构建包括谓词的定义和逻辑公式的定义。公式的权重则由统计学习得到。
2.4.1 谓词定义
本文中定义的谓词如表3所示。
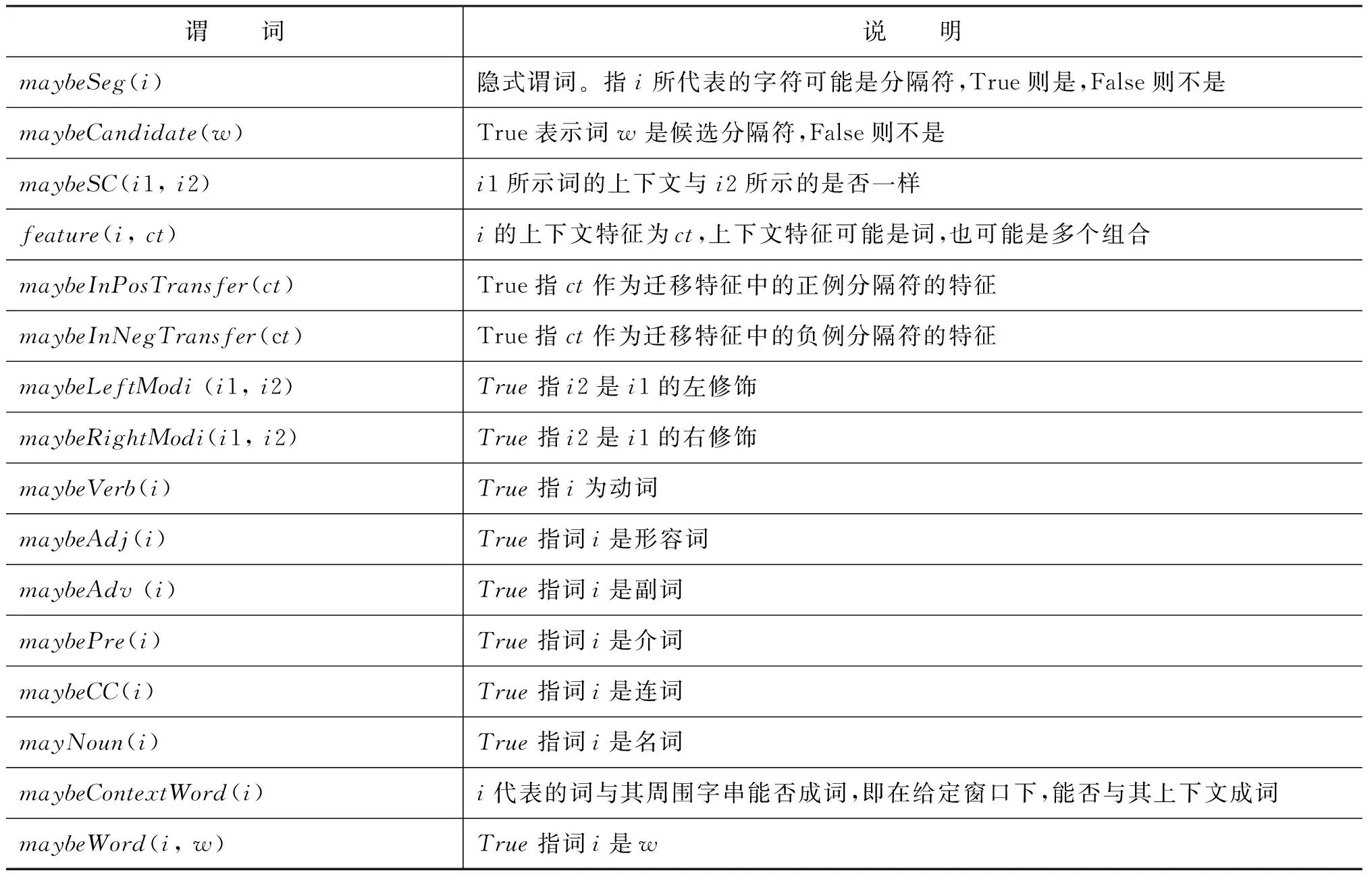
表3 谓词定义
上述表3中仅有maybeSeg是隐式谓词。隐谓词的值是通过观察谓词与隐谓词以及隐谓词与隐谓词之间的逻辑关系公式推断出的,因此,需要定义描述谓词之间关系的逻辑公式。本文定义了17个逻辑公式,包括六个局部公式和11个全局公式。局部公式描述了观察谓词与隐谓词之间的关系。全局公式则可表示隐谓词之间的关系。
2.4.2 局部公式定义
通过对语料的观察发现,我们可以将句中的自身信息集成使用。如,对于连词与介词,在字符个数大于等于2的情况下是分隔符的可能性比较高。而在字符个数是1的则不高,见式(3)和式(4)。如在“图像”中的“像”字符个数是1,在这里作为名词一部分。

(3)
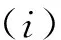
(4)
判断候选分隔符与其上下文搭配的字串是否成词使用到了北大词表。其中,因为中文专利有很多专业术语,如果仅仅使用北大词表会出现很多未登陆此,如“聚像控件”。为了补充未登陆词,我们发现可以通过中英标题对中的词语很好地部分解决,如“一种虚拟摄像机规划布局方法和系统<==>Virtual video camera planning and distributing method and system”。英文不需要分词,连词如“and”等干扰词很容易去掉。确定例句中的“像”是否可能组成一个新的未登陆词方法是: 调用金山词典接口翻译标题中的英文,比对中文标题,如果“像”都出现,则说明是。
对于候选分隔符的判断也可依据其上下文特征。在迁移特征集中,若候选分隔符在当前上下文中通常作为分隔符,那么在当前句子中,该候选词也很有可能作为分隔符,见式(5)。反之,见式(6)。
(5)
(6)
在候选分割符的判别中,对动词的决策难度最大。判断候选动词是否为动词除了简单词性(如VBZ)以及序列结构(如“is
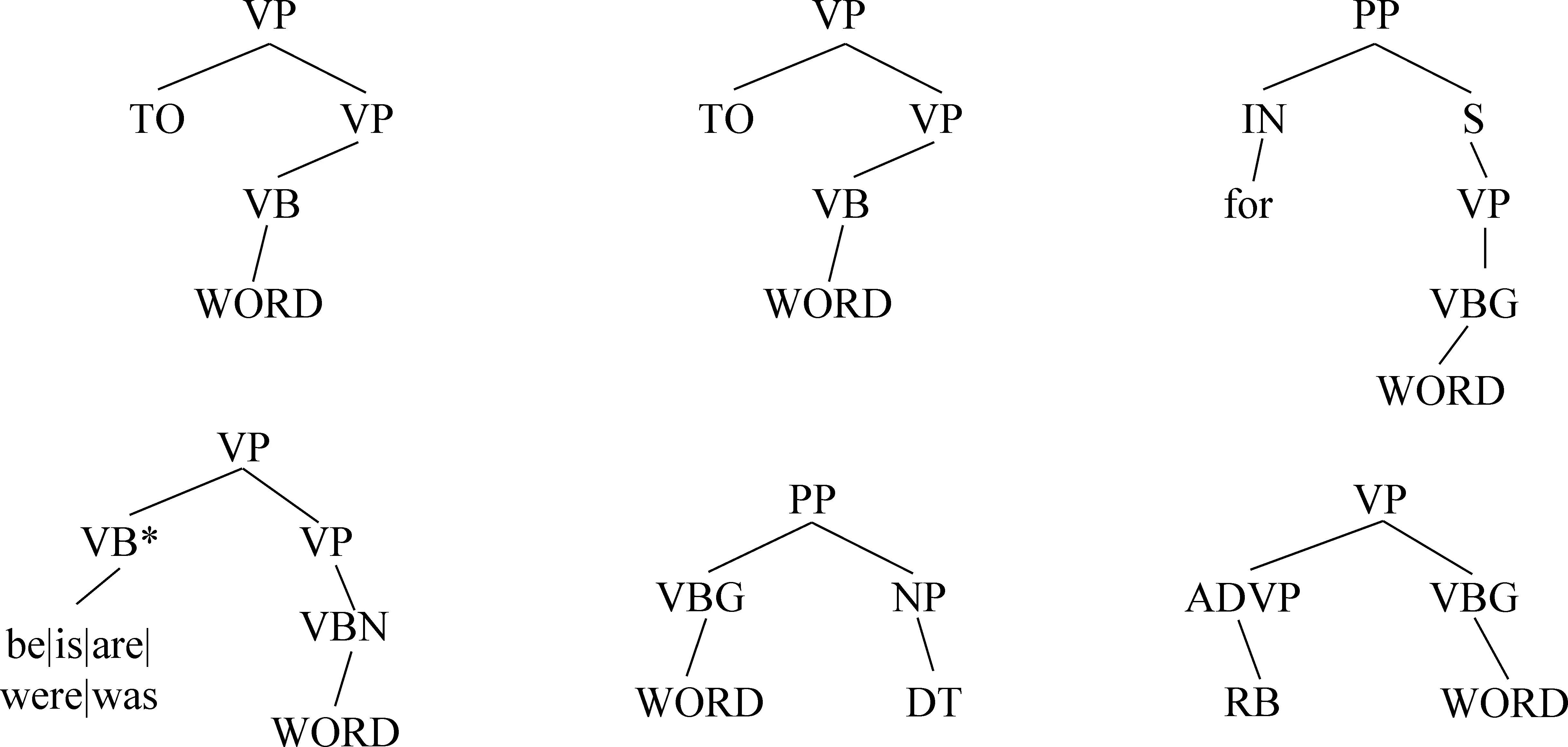
图2 动词结构模式
其中,“WORD”表示匹配一个单词,*表示匹配0个或任意一个字符。判断候选动词是否为分隔符见式(7)
(7)
同样,依据候选词词性是否为Noun或Nouns来判断其是否为名词,如果是,则可能不是分隔符,见式(8)。
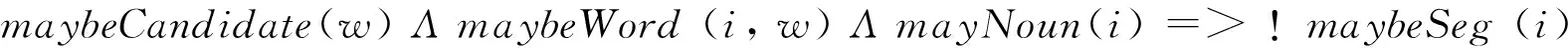
(8)
2.4.3 全局公式定义
对于上下文一致的候选分隔符最终的输出应该保持一致。如“MNP[一种视频信息记录装置],包括MNP[视频信息]记录”中的“记录”一词则不是分隔符,见式(9)。
(9)
对于动词来说,其左右经常会出现修饰语,本文将其左边的修饰语称为左修饰,其右边的修饰语称为右修饰。左右修饰如“进行”和“了”。如果该动词是分隔符,则其左右修饰也可能是分隔符,如式(10)和式(11)所示。
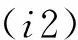
(10)
(11)
对于被识别为形容词Adj,副词Adv的候选分割符,在Adj+Noun的组合结构中,即形容词修饰名词的结构,若Adj不是分割符,则Noun也不是。同理,若Noun不是分隔符,则Adj也不是。见式(12)和式(13)。
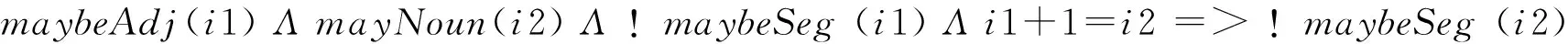
(12)
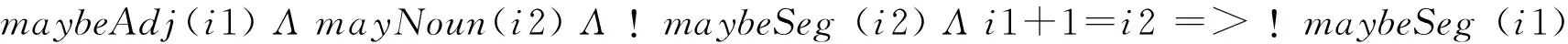
(13)
对于Adv+V组合,即副词修饰动词的情形,若Adv是分隔符,则V就可能是分隔符,同理,若V是分隔符,则Adv也可能是分隔符,见式(14)和式(15)。
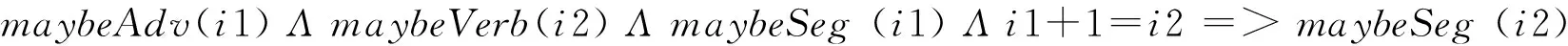
(14)
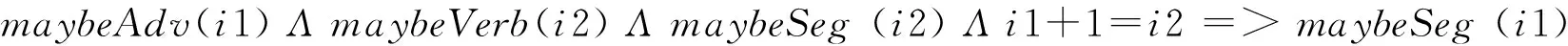
(15)
对于并列结构中的候选词,尽量保持它们输出的一致性,本文使用的是启发式规则,如“压缩,解码和存储”中,“压缩”、“解码”、“存储”都作为分隔符。公式的定义如式(16)所示。
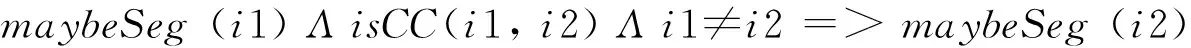
(16)
在专利文本中对并列连词的处理不容忽视。本文主要对有标记的并列结构进行处理,以块为处理单位,块的划分以标点符号为依据。对于在块中只有一个并列标记的情况,如果其左右都没有分隔符,则该连词可能不是分隔符,反之则是。对于并列标记在开始与结束位置的情况,将其视作分隔符,见式(17)~式(19)。
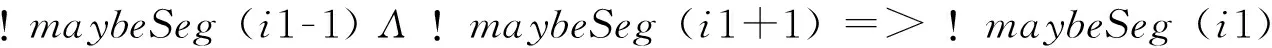
(17)
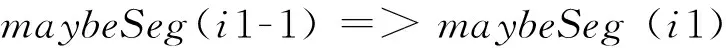
(18)
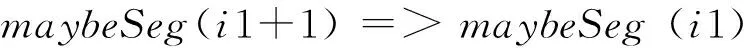
(19)
对于在同一块中出现的多个并列标记,若并列标记之间不出现分隔符,则并列标记可能不是分隔符,反之则是分隔符。如“……线形酚树脂、红外吸收染料、热分解型产酸源……”。
另如,“与”既可为连词,也可为介词。处理方法是,从该词开始直到动词分隔符,中间如果不含有“的”,则为分隔符,如,“……与MNP[通信网络]相连……”。同理,从该词开始,直到分隔符,中间如果含有“的”,则不为分隔符,如,“……MNP[与输入内容相对应的元数据],……”。
3 实验与分析
本文从自动抓取的24 485篇专利摘要中均匀随机采样220句进行人工标注,作为测试语料。实验性能使用准确率、召回率和F-值来进行评价。其中,系统对正确识别采用了严格的定义,即当且仅当MNP 的左右边界都被正确识别时为正确。
3.1 阈值的选择
阈值被用来最终界定一个词是否为分隔符,如式(2)所示,若计算得到的候选分隔符的概率值大于设定的阈值,则将其判定为分隔符。为了解阈值对MLN- MULTI模型(由全部公式组成)的影响,本文针对迁移特征来源的两种树库分别测试不同阈值下的MNP识别性能,用词作为迁移特征,窗口长度是2,阈值步长是0.01,实验结果如图3所示。
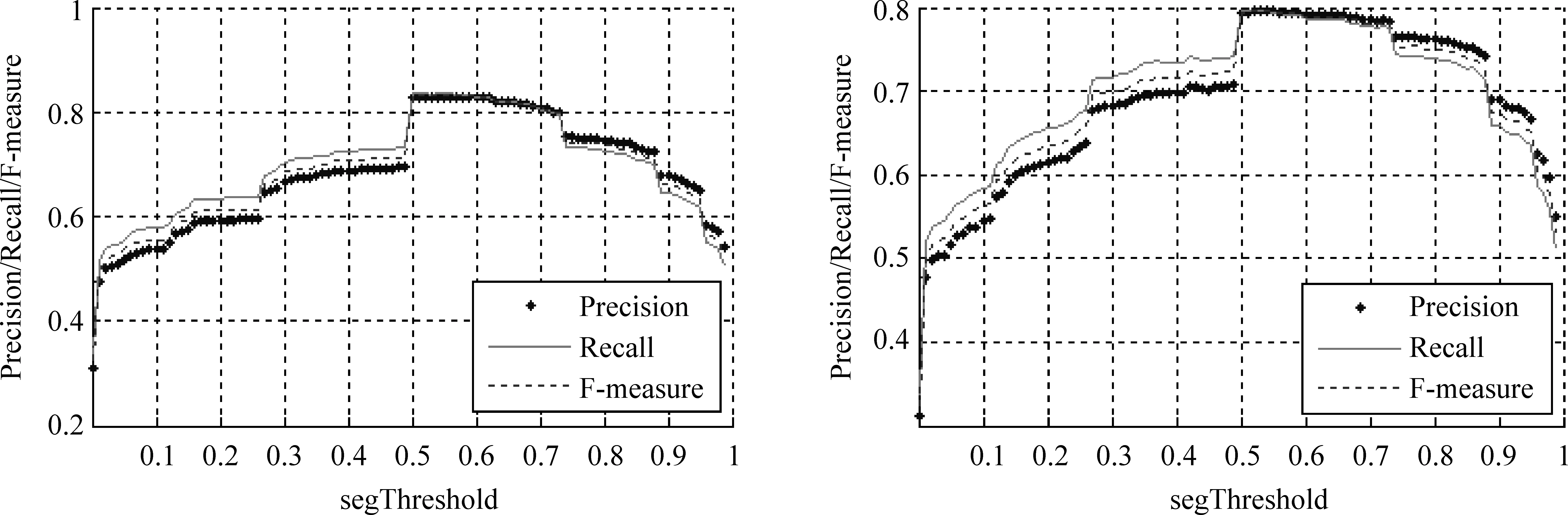
图3 左: 宾州树库阈值结果分布图 右: 专利树库阈值结果分布图
单个分隔符的正确性随着segThreshold值的增大而相应提高,作为一个整体MNP的识别却不一定。一个MNP由多个候选分隔符组合而最终确定,segThreshold如果过高,则会遗漏正确的分隔符,最终导致MNP识别不正确。相反,如果segThreshold过低,单个分隔符正确性不可靠,同样导致MNP的错误,故 segThreshold只能在一个合理区间。从上图可得出,无论是宾州树库还是专利树库,区间[0.5-0.7]是较为合理的,在此区间segThreshold的取值对最终MNP识别的影响不大。另外,本文提供的两个库在0.5处都有不错的表现。所以,下文实验的segThreshold均设置为该点。
3.2 模型的验证
我们设置了四组对比试验,相应定义了四个模型。ChSelfTransfer是由仅仅包含中文专利句子自身特征和迁移特征的一阶公式组成的模型。MaxEntropy是由包含除全局公式外所有其他公式组成的模型。MLN-MULTI是由所有公式组成的模型。MLN-MULTI- NoTransfer是由包含除迁移特征公式外其余公式组成的模型。需要说明的是,以上所有模型的窗口长度选取的是2,迁移的特征在词的粒度。结果如表4所示。
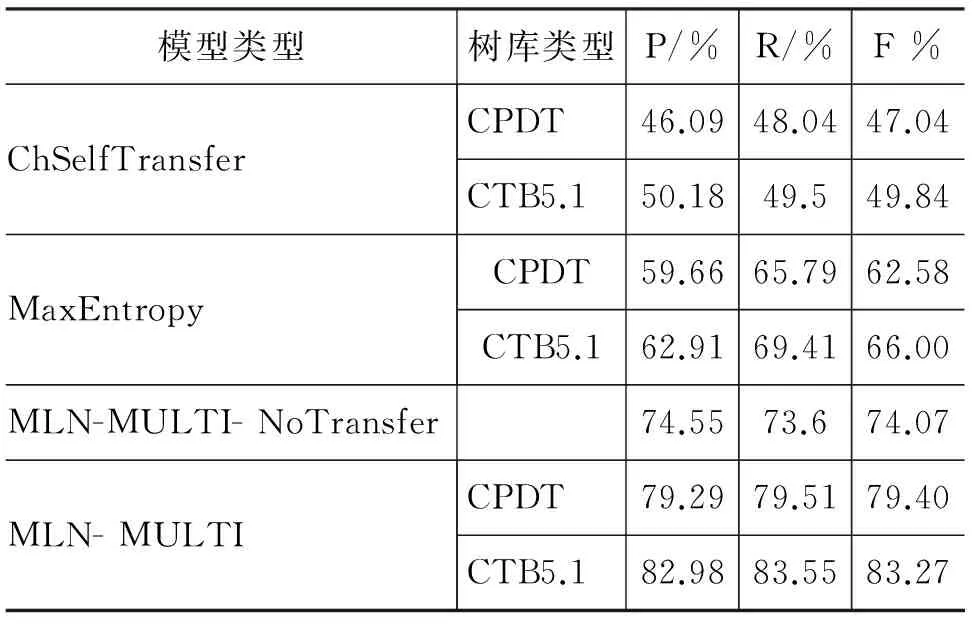
表4 不同模型下的结果对比
从表4中可以看到,使用了双语对齐信息的MaxEntropy组较仅使用中文信息的ChSelfTransfer组,其F值的提高了15.54%,可见双语信息的引入对MNP识别性能的提升效果显著。其原因在于,借助高质量的双语词典及词对齐信息,我们能更准确从句子中切分出候选分隔符,特别是动词性的候选分隔符,进而能在此基础上对MNP边界进行判别。
MLN- MULTI组与MLN-MULTI- NoTransfer组的对比,其F值提高了至少5.33%,可见迁移特征对于专利MNP识别也有明显帮助。迁移特征的引入,丰富了候选分隔符的特征集,有效地应对了特征稀疏的问题。
从表4中我们也可以看到,从宾州树库迁移特征的表现要好于从专利树库迁移特征,这表明,至少在词级别的特征迁移上,语料的领域相关性对于专利MNP识别的影响并不大,而宾州树库的语料规模较专利树库更大,可以得到更丰富的词特征,所以在MNP识别上表现更优。
3.3 与其他方法比较
由于未发现同等条件下使用双语作为输入的系统,本文只能利用当前输入是单语较为优越的系统作对比。MLN- MULTI与目前表现较好的模型在中文专利MNP识别上的结果如表5所示。
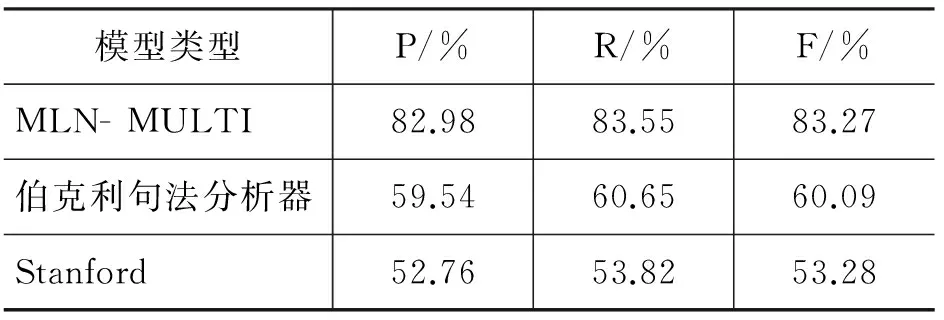
表5 MLN-MULTI与其他模型的对比
需要说明的是,在测试句中,有一句的字符长度超过了Berkeley句法解析器的解析范围,为了公平的对比,所有模型都过滤了该句。相比较而言,本文的方法具有更好的识别效果。
4 结束语
本文提出一种面向双语摘要的中文专利MNP识别的方法,利用马尔科夫逻辑网对句子局部信息、其他领域迁移的特征信息以及中英双语信息三类信息进行统一整合。实验结果表明,加入其他领域迁移特征,有效地缓解了目标语料中的特征稀疏问题,中英双语对齐信息的引入,也对MNP识别起到很好的辅助作用。
本文的后续改进工作将从以下两个方面展开: 一是为解决语料特征稀疏的问题,可对迁移特征的进一步泛化,如,对词性单一的特征进行词性泛化;二是可进一步利用句子间一致性的特征信息,有些句子对应的英文信息完整,有助于MNP的识别,而有些被省略,跨句的推理可以保证MNP识别的一致性。
[1] 周强,孙茂松,黄昌宁. 汉语最长名词短语的自动识别[J]. 软件学报, 2000,11(2): 195-201.
[2] Church K. A stochastic parts program and noun phrase parser for unrestricted[C]//Proceedings of the Second Conference on Applied Natural Language Processing. Texas, 1988: 136-143.
[3] Voutilainen A. NPTool, a detector of English noun phrases[C]//Proceedings of the Workshop on Very Large Corpora Association for Computational Linguistics. 1993: 48-57.
[4] Ramshaw L, Marcus M. Text chunking using transformation-based learning[C]//Proceedings of the Third Workshop on Very Large Corpora. 1995: 82-94.
[5] 陆俭明. 汉语句法成分特有的套叠现象[G]. 陆俭明自选集. 郑州:河南教育出版社, 1993: 174-192.
[6] 李文捷,周明,潘海华,等. 基于语料库的中文最长名词短语的自动提取[J]. 计算语言学进展与应用, 1995: 119-124.
[7] 代翠,周俏丽,蔡东风,等. 统计和规则相结合的汉语最长名词短语自动识别[J]. 中文信息学报, 2008,22(6):110-115.
[8] 鉴萍,宗成庆. 基于双向标注融合的汉语最长短语识别方法[J]. 智能系统学报, 2009: 406-413.
[9] 钱小飞,侯敏. 基于混合策略的汉语最长名词短语识别[J]. 中文信息学报, 2013, 27(6):16-22.
[10] ZHOU Q, ZHANG L, CAI D, et al. Maximal-length noun phrases identification based on re-ranking using parsing[J]. Journal of Computational Information Systems, 2013, 9(6): 2441-2449.
[11] Domingos P, Lowd D. Markov logic: an interface layer for artificial intelligence[J]. Synthesis Lectures on Artificial Intelligence and Machine Learning, 2009, 3(1): 1-155.
Chinese Patents Maximal-length Noun Phrases Identification Using Markov Logic
CAI Dongfeng, ZHAO Qimeng, RAO Qi, WANG Peiyan
(Knowledge Engineering Research Center, Shenyang Aerospace University, Shenyang, Liaoning 110136, China)
The main problems that limited the development of Maximal-length Noun Phrases recognition on Chinese patent literatures are the lack of annotated corpus and the difficulty of recognizing verbs and nouns. This paper presents a new Markov Logic approach to maximal-length noun phrases identification from Chinese patents. Instead of recognizing various of noun phrases, the approach focuses on the identification of MNP’s boundary markers. To recognize Chinese patents MNPs, three categories of features, i.e. word features from sentences, transfer features from TreeBanks and bilingual features from patents’ abstractions, are employed. The experiment results show that bilingual features can bring a notable improvement on identification of MNP boundary markers such as verbs, prepositions and conjunctions. And the F-score on MNP identification reaches 83.27%.
MNP;MLN;Chinese patent

蔡东风(1958—),博士,教授,主要研究领域为人工智能、自然语言处理。E-mail:caidf@vip.163.com赵奇猛(1988—),硕士研究生,主要研究领域为开放式信息抽取。E-mail:zhaomeng1123@126.com饶齐(1990—),硕士研究生,主要研究领域为信息抽取。E-mail:hbraoqi@gmail.com
1003-0077(2016)04-0021-08
2014-08-05 定稿日期: 2015-02-09
国家“十二五”科技支撑计划项目(2012BAH14F00);国家自然科学基金(61073123)
TP391
A
