纳税遵从度评估模型实证研究
2016-04-21谢卫平
谢卫平


【摘 要】 在税收征管理论和实践中,纳税遵从度能够反映纳税人自觉纳税的意愿,特别是客观评价税收法规执行的有效性以及评估税收流失的规模,已经成为衡量税收征纳双方关系和谐与否的重要标志。建立科学的纳税遵从度评估模型有利于税务机关找到影响税收征缴入库的诸多因素,也有利于提高税收征管的整体质效水平。文章以计量经济学中的随机前沿分析(Stochastic Frontier Analysis,SFA)为理论基础,详细分析SFA在纳税遵从度评估中的应用,创造性地提出了一种新的纳税遵从度计算方法及其影响因素的排序算法,进而构建了一个面向某市餐饮业面板数据的评估模型并进行了实际测算,完成了纳税遵从度的实证研究,进而结合税收征管改革提出政策建议。
【关键词】 纳税遵从度; 随机前沿分析; 排序算法; 实证研究
中图分类号:F230;F810.42 文献标识码:A 文章编号:1004-5937(2016)07-0098-05
一、纳税遵从度文献综述
纳税遵从又称税收遵从。2002年我国明确了纳税遵从包括及时申报、准确申报、按时缴纳三个基本要求。纳税遵从度是指纳税人遵从税法,自觉依法纳税的程度。在我国,由于各种“跑、冒、滴、漏”现象的长期存在,税收征缴入库的管理亟需加强[ 1 ]。纳税遵从度是衡量税收体制与征管效率高低的重要指标,具有直观反映纳税人纳税意愿与遵守税法的特点,能够客观评价一国税制优劣和征管能力的高低。
1972年,阿林厄姆建立了著名的A-S模型,该模型基于贝克尔关于犯罪经济学的研究和阿罗关于风险及不确定性经济学的研究。此后,斯里尼瓦桑提出了基于预期所得最大的评估模型,构筑了纳税遵从度评估分析的基本理论框架[ 2 ]。此后,国外学者又对以上两个模型不断修正,例如改变假设条件、增加影响因素,研究因素之间的彼此作用,使模型与税收征管实际更为贴近。
综上所述,国外纳税遵从度的研究模式主要分为两类:一类基于预期效用理论(Expected Utility Theory)的理性经济决策模式,另一类基于期望理论(Prospect Theory)和心理学的理论模式[ 3 ]。
我国对纳税遵从度的研究还处于起步阶段。彭秋容(2010)运用经济学和管理心理学理论,着重以实证方法研究了纳税遵从心理。徐慎刚博士以博弈论模型为基础,引入关联规则挖掘技术和OLAP技术分析了纳税遵从影响因素[ 4 ]。韩晓琴等(2011)运用Logistic回归模型,设定6个影响因素自变量进行回归分析,构建了基于遵从概率估计的风险预警模型。
二、基于随机前沿分析的纳税遵从度评估模型
将纳税人抽象为独立的纳税生产单元,以纳税人财务经济指标为基础,构建财务经济指标与年度纳税总额的关系及其数学模型,并推导出生产前沿函数。基于纳税人的年度纳税总额与外部边界的距离,即可推算出纳税人的纳税效率,从而计算出纳税遵从度。
随机前沿分析能够将生产边界的模糊估计与主体追求最优化目标的效率程度相关联,并且分析影响因素,为提高效率提供客观公正的信息基础,进而提出改进对策,提高生产效率,这无疑对促进生产、减少浪费有重大意义[ 5 ]。笔者认为,该理论适用于纳税遵从度评估,即以纳税人的年度纳税额为研究对象,一旦纳税生产函数和年度纳税额边界被界定,就可以根据纳税人实际缴税款额到年度纳税额边界的距离来定义其纳税效率,进而推算各企业的纳税遵从度并对影响因素进行排序,达到为政策制定和征管改革提供决策支持的目的。
(一)随机前沿分析模型应用思路
当前,用于纳税遵从度的效率评估方法主要有财务指标法和前沿分析法。随机前沿分析原本应用于技术效率分析,在1977年由Aigner、Lovell、Schmidt等和Meesuen、Vanden Broeck等分别提出[ 6-7 ]。该模型的优点在于承认随机干扰因素对产出能力的影响,并将影响产出能力变化的随机干扰因素与技术有效性中的其他因素分离。本文将该模型引入纳税遵从度评估与影响因素的分析中,并展开实证研究,提出MATLAB实现思路。
随机前沿模型在纳税遵从度中应用的基本思路为:通过采集相同或相近行业、地区中不同企业生产经营的相关财务经济数据,采取横向比较的方法,计算出各个企业的纳税效率,再进一步推出各个企业的纳税遵从度及税收流失规模。其核心思想在于把企业当成一个产生税收的机器,根据所选取的税务数据指标,模拟出企业产生纳税额的数学模型,再通过输入原始数据和估计出的生产函数,推算出企业所具备的税收贡献能力。其原理如图1。
基于以上原理,首先估计生产函数(本文采用对数型柯布—道格拉斯生产函数),同时考虑到生产函数中误差项的复合结构、分布形式、分布假设的不同,采取对应的数学算法来估计生产函数的各个参数(本文采用极大似然估计法)。该模型的优点在于通过估计生产函数,对个体的生产过程进行描述,从而实现对纳税效率的估计。从微观企业的角度来看,运用随机前沿方法测算纳税效率,有利于考察和评价每个企业的综合纳税指标。另外,在涉及行业分析或区域横向比较时,通过测算各个行业或地区的纳税效率,能够预测每个行业或地区的税收增长质量。
(二)随机前沿分析模型的算法实现
构造出合理的生产函数模型后,结合各生产单元的输入数据,估计出对应的技术参数,进而给出相应的随机生产边界,最后比较各生产单元与随机生产边界的距离,计算出各生产单元的生产技术无效性值。基于以上数学分析,本文提出纳税遵从度与技术有效性的相关性以及影响因素权重的计算方法,如图3所示。
其中:纳税遵从度=TE(技术有效性)×100%=(实际年度纳税总额/年度纳税总额边界)×100%;影响因素权重=该因素与全年纳税总额边界的显著相关性=t检验值。限于研究方便,本文暂定只提供应用极大似然估计法来估计各参数的数学原理,进而计算纳税遵从度和影响因素权重。
(三)模型的参数估计——极大似然估计法
应用极大似然法估计有效值主要包括两个步骤。首先,使用极大似然法估计模型中的各个参数;其次,在这些极大似然估计值已知的条件下,将极大似然估计的残差分解成噪音项和技术无效项,从而得出各生产单元的有效性。为研究方便,本文将经对数化后的生产函数模型表示为:
步骤二:根据已经估计出的参数计算出各生产单元的技术无效值及平均技术无效值。基于以上数学推理,本文运用对数型柯布—道格拉斯生产函数及某市2013—2014年餐饮业重要财务指标的面板数据,对该市餐饮企业的纳税遵从度进行测定。
三、数据采集与变量选择
为保证数据口径的一致性,本文实证研究所采用的数据均来自国家税务总局金税三期系统,且采用随机抽取方式,指标如表1。
部分企业(随机抽取10户)基本情况如表2。
因实证研究的需要,本文将所采集的面板数据全部以元为单位,在模型数据处理的过程中全部对数化处理,以满足随机前沿模型的技术要求,参数估计使用最大似然估计,评估体系数目300,时期数目2,总记录数600,自变量个数9,?滋i为半正态分布。
四、检验与结果
(一)变量的有效性检验
变量的选择是纳税遵从度评估的重要前提,选择科学、全面的指标可以使纳税遵从度评估的结果更加准确客观。针对本次实证研究选择的9个自变量,经过模型的数学计算后,其变量指标分析结果如表3。
按照0.05的显著性水平查询t检验值表,有t299,0.05=1.968。因此,只要自变量t检验值的绝对值大于1.968即可判断该自变量与因变量(全年纳税额)显著相关,本次研究所选择的9个自变量均大于该临界值。
(二)评估结果分析
本文选择了300户纳税人的财务指标数据,经过处理后得出其纳税效率及纳税遵从度的排序。
1.餐饮业纳税遵从度跨度大
本次评估结果显示,餐饮行业的纳税遵从度分布不均匀且跨度大,从20.48%到99.88%,跨度超过79个百分点,最高比最低多出近3.9倍。同时,整体行业的纳税遵从度从2013年的48.3%上升到2014年的54.3%,增长12个百分点。说明即使在同一地区,相同或相近税制的背景下,餐饮企业的运营状况因受经营地段、服务定位、管理体制等复杂情况影响,特别是企业对纳税守法认识程度的不同,各企业表现出来的纳税遵从度存在较大差异。
2.餐饮业税收增长空间巨大
根据本文提出的纳税遵从度计算方法,即实际年度纳税总额与年度纳税总额边界的比值,该市2013年、2014年的均值都低于60%,主要原因在于该行业经营形式多样,同行不同利现象突出,再加上财务核算方面的欠规范化,给税收征管提出难题,导致税款流失问题难以彻底解决。这也说明,当前该市餐饮业的税收征管还有进一步精细化管理的必要性,而通过提高整体行业的纳税遵从度,能够实现45.7%的税收增长空间。
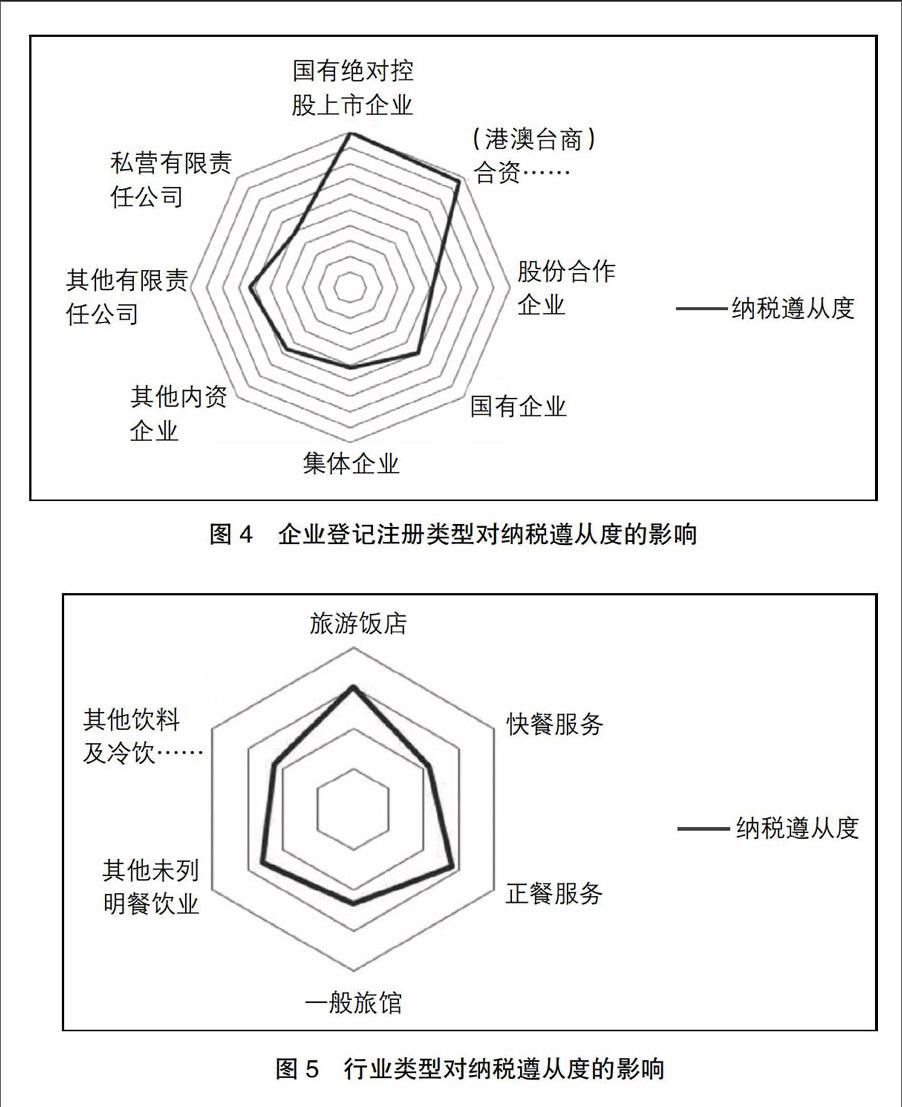
3.企业登记注册类型对纳税遵从度的影响
通过对评估结果的分析发现,企业登记注册类型对纳税遵从度的影响如图4。
基于图4得到如下结论:登记注册类型为国有绝对控股上市企业的纳税人其纳税遵从度最高,原因在于其经济业务透明,财务制度健全,所受监管较多,依法纳税的意识高;其次是(港澳台商)合资经营企业,纳税遵从度均超过90%,主要原因在于这些企业管理体系健全,财务制度较为完善,依法纳税意识较高;最低的为私营有限责任公司,仅为49.2%,说明其依法纳税意识相对薄弱,财务制度不够完善,容易产生税收流失漏洞。
4.行业类型对纳税遵从度的影响
纳税人行业类型对纳税遵从度的影响如图5。
通过分析发现,行业类型对纳税遵从度的分布影响较大,其中快餐服务业和其他饮料及冷饮服务的纳税遵从度最低,仅为42%和45%。其原因主要在于:这些行业属于劳动密集、人员流动性大的行业,其税款总额在税收主体中所占比例较低且入库税款零星分散;同时,纳税人成本核算混乱,经营淡旺季现象突出,经营规模差距悬殊,进而导致税收难,税款流失严重。
5.纳税遵从度与纳税额大小无直接关系
传统观念认为,纳税遵从度与全年纳税总额有较强关系,即纳税大户遵从度相对较高,纳税额少则遵从度相对较低,但通过将300户企业纳税遵从度与各自年度纳税总额相比较,发现并未呈线性相关性。实证研究中有9家餐饮企业2014年全年纳税额均超过100万元,但其纳税遵从度均不足80%,这说明纳税遵从度与其实际纳税额大小并无直接关系。
五、模型推广策略研究
随着税源专业化管理改革的不断深入,税务机关愈加重视现代评估手段的引入,以便优化征管资源,实现投入产出最大化,并弥补经验式纳税评估的不足。本文构建的纳税遵从度评估模型,借助于随机前沿分析的方法体系,具有信息化和系统化的优点,易于推广应用。
(一)适用于大规模选户与初步疑点筛查环节
本文所用的随机前沿分析模型,通过企业财务经营数据,模拟出企业生产经营结构并推算出企业年度应纳税总额的前沿分布,综合性强,可以有效解决选户排队和锁定疑点科目问题。从上文分析结果可知,与传统指标评估相比,随机前沿分析模型能够更好地反映各项考核指标要素对税收能力的综合作用,并能结合企业状况得出初步、合理、可供参考的结论。与此同时,该模型还实现了对各企业的纳税遵从度进行排序并估算企业偷漏税数额的功能,为征管工作选取重点关注企业、强化征管力度提供了科学合理的参考依据。
(二)先难后易便于推广应用
随机前沿分析算法复杂,求解存在困难,初步构建后需要进行系统的探索、实测和校验,困难主要集中于模型构建的早期,而后期应用则相对简单。原因为:一方面数据采集主要源自金税三期系统,工作人员需集中精力开发复杂的SQL程序并从海量数据中筛选符合要求的数据;另一方面,在指标固定的前提下,工作人员只需更新、变换数据,便可得出所需的结果。
(三)接入第三方数据提高评估准确度
通过采用第三方数据,既可提高评估模型的可靠性,又能够在质疑企业时增强说服力。以餐饮业为例,可考虑引入工资薪金支出、电量、用水量、经营面积、所在街道平均租金等指标数据,进一步优化随机前沿分析模型。
(四)不同行业推广应用
金税三期上线,对企业经营状况、年度报表等数据的采集日趋便捷,为数学建模打下坚实基础。理论上讲,可以对大多数行业进行类似的建模,借此科学地评估企业纳税遵从度,并评估税款流失额度。评估模型的推广对偷逃税款的企业具有较大威慑力,因为企业被税务机关查处的信息一旦披露,就会直接影响企业的形象、公司股票价格,进而影响到企业的融资和发展[ 10 ]。
六、结语
总体而言,通过随机前沿分析模型开展纳税遵从度评估,有传统评估手段不可比拟的系统性、科学性和先进性,能够实现以往经验式评估难以达成的目标。随着税源专业化管理改革的不断深入,随机前沿模型的应用、纳税遵从度评估的推广,都将发挥日益重要的作用。长远来看,通过结合信息手段,为模型开发配套的软件系统,有利于开展规模化、高效化的纳税评估工作。税务机关应积极采用科学化手段,将各类优秀的经济模型应用到税收征管实际工作中,进一步提高税收征管水平,推动税源专业化改革,实现精细化管理。
【参考文献】
[1] 吴敬琏.当代中国经济改革[M].上海:上海远东出版社,2004:324.
[2] 梁朋.税收流失经济分析[M].北京:中国人民大学出版社,2000:52-53.
[3] SIMON JAMES, JOHN HASSELDINE, PEGGY HITE,et al.Developing a tax compliance strategy for revenue services[M]. International Bureau of fiscal Documentation,April 2001.
[4] 徐慎刚.中国纳税遵从问题的研究[D].华中科技大学博士学位论文,2011.
[5] 王传美,刘洋,吴海英.基于MLE的随机前沿面模型技术效率分析[J].统计与决策,2004(10):23-24.
[6] YAO QING LIU. Existence, multiplicity and infinite solvability of positive solutions to a nonlinear fourth-order periodic boundary value problem[J].Nonlinear Analysis,2005,63(2):237-246.
[7] LI FUYI, LIANG ZHANPING. Existence of positive periodic solutions to nonlinear second order differential equations[J].ApplMath Lett,2005,18(11):1256-1264.
[8] BATTESE G E, COELLI T J. A model for technical inefficiency effects in a stochastic frontier production function for panel data [J].Empirical Economics,1995,20(2):325-332.
[9] BATTESE G E,COELLI T J.Frontier production functions,technical efficiency and panel data:with application to paddy farmers in India[J].Journal of Productivity Analysis,1992,3(1):153-169.
[10] 盖地.避税的法理分析[J].会计之友,2013(26):4-7.
