英语写作AES系统评分效度的实证研究
2016-04-21王海军
王海军
(浙江工业大学 之江学院,浙江 杭州 310024)
英语写作AES系统评分效度的实证研究
王海军
(浙江工业大学 之江学院,浙江 杭州 310024)
摘要:英语写作自动评分系统(AES)在国外的英语写作测试和教学领域应用越来越广泛,但国内对其信、效度的实证研究还十分欠缺。以句酷网为例,从人分散度、相关性和等级一致性等方面研究了AES系统的评分效度。结果表明,尽管机器评分区分度不如人工评分,但其总的评分效度尚可,其结果的稳定性可以满足国内英语写作课堂教学的需要。
关键词:英语写作自动评分系统;评分效度;句酷
作文自动评分技术(AES,Automated Essay Scoring)是计算机给作文评价和评分的技术[1],自二十世纪六十年代问世以来,已经取得了长足的进步。现阶段,国外的写作自动评分技术不仅应用于英语写作的自动评分,还在英语写作的课堂教学实践中发挥了越来越重要的作用。
机器自动评分具有节时省力效率高的特点,能使教师在很大程度上从繁重的写作作业批阅中解放出来。国外的AES技术经过多年的专家论证和实践应用已经相当成熟,其评分效度甚至高于人与人之间的评分效度。而国内的AES系统由于起步较晚,其评分效度的实证研究目前还不多见。因此,本文以句酷网为例,分别从人分散度、相关性和等级一致性等指标来检验该系统的评分效度。
一、国内外AES系统评分效度研究综述
(一)评分效度研究的进展
迄今为止,国外研发成功并投入使用的自动评分系统有十余种[2],其中最具代表性的有PEG、IEA、E-rater、IntelliMetric和Writing RoadmapTM。它们各具特色,PEG重语言形式,IEA 重作文内容,其余几种则既重形式又重内容[3]。相关研究表明,国外主流的自动评分系统的评分效度指标如相关度、一致度或回归系数等数据都非常理想,可以达到0.9以上。IEA的自动评分与人工评分之间的相关性为r=0.85[3]。而IntelliMetric的相关性也类似,达到了0.85~0.87,评分等级一致性(agreement)从1996年的50%左右上升到2002年的60%,相邻一致性(分数相差一个等级)从95%左右上升到98%[1]。而E-rater的表现更好,其自动评分与人工评分之间的等级一致性一直高于97%[3],相关系数已经高达r=0.87~0.97[4]。相对而言,PEG的表现稍微逊色一些,机器评分与人工评分之间的相关性为0.71,但同一研究中的人工评分之间的相关性仅为0.62[5],逊色于机器评分。此外,有研究表明,PEG的多元回归系数可以高达R=0.877[3]。
AES系统在中国起步较晚,从2005年梁茂成教授主持开发的“大规模考试英语作文自动评分系统”算起,仅仅十年左右。除此之外,国内现有以下几种AES:write on,冰果,IntelliMetric, iWrite和2011年投入使用的“句酷批改网”(pigai.org)。
目前国内有关AES的研究主要集中于冰果、句酷等AES系统的课堂应用效果和对比人工批改与在线批改工具的差异等方面。而在评分效度方面,国内主要有以下几项研究:王莺莺通过对比200份作文的机器评分与人工评分研究了write on的评分效度[6]。结果表明,write on的机器评分与四名人工评分员的平均评分之间的平均相关性达到了0.62,评分效度尚可。何旭良对句酷网的评分效度研究结果表明:句酷批改网的自动评分效度稍高一些(r=0.69),但评分显著地高于人工评分,尚不能反映学生英语作文的真实水平[7]。同样是研究句酷网,汪珍珠的研究结论有些不同:句酷网的机器评分与人工评分的拟合度(R2)很低,只有0.45,评分效度远低于国外的主流AES[8]。这几项研究的结果表明:与国外相比,国内的AES系统评分效度尽管可以接受,但还不够理想,仅处于国外AES系统初级阶段的水平。
(二)评分效度研究的问题
信度和效度对于任何语言测试来说都是非常重要的指标。信度是效度的基础,其通用定义是指测试结果是否可靠可信[9]。当代效度观认为信度只是效度的一种证据。Messick认为[10],在进行效度验证时需要尽可能多地收集各种数据,这其中就包括信度,信度也因此成了其效度框架的一部分。而Weir在针对考试效度所提出的社会认知框架中将信度上升到了效度的高度,即评分效度(scoring validity)[11]。
就AES系统而言,由于自动评分系统最终报告的是作文分数,传统的评分效度评估方法在某些情况下就不适用于AES系统或不能为使用者提供足够的信息量了[1]。因此,AES系统的评分效度主要指在评分标准相同的情况下,机器自动评分与人工评分的相关性(consistency)或等级一致性(agreement)是否能达到人工评分的水平。而在实际操作中,我们不仅要考虑分数能否正确地评定学生的写作等级(classification accuracy)[1],还要考虑分数的区分度(discrimination)或离散度,也就是李筱菊所说的人分散度(person separability)[9],即分数能否区分出受试者写作水平的高低。除此之外,在考查评分效度时我们还需要考虑试题的难度(facility)等指标[9]。
因此,在本研究中,AES系统的评分效度主要体现在相关性、等级一致性和人分散度上。
与国外相比,国内的AES评分效度实证研究方面主要存在以下几个问题:第一,研究数量偏少,研究范围偏窄。通过cnki搜索关键词,截至2015年6月,仅搜到了三项有关国内AES系统评分效度的实证研究:王莺莺(2012)[6]、何旭良(2013)[7]、汪珍珠、叶宬 (2014)[8]。根据上文的报告,有两项研究的对象是句酷批改网,一项是write on。目前还没有针对冰果、IntelliMetric等AES系统的研究。第二,研究结论不一。王莺莺[6]与何旭良[7]的研究分别认为write on和句酷的评分效度尚可(均高于0.6),其中句酷批改网的信度稍高一些。汪珍珠、叶宬的研究结论是句酷批改网的评分效度很低,拟合度R2仅为0.45[8]。此外,何旭良(2013)还发现句酷批改网的评分显著地高于人工评分,尚不能反映学生英语作文的真实水平[7]。第三,结论无可比性。王莺莺[6]与何旭良[7]的研究使用了Pearson相关系数,汪珍珠的研究所使用的方法为回归分析,因此,前二者与后者的研究结论无可比性,只能通过他们的分析来判断AES评分效度的高低。
(三)评分效度研究的趋势
鉴于国内AES评分效度研究中存在的上述问题,本人认为今后在实证研究中还应在以下几个方面取得突破:第一,建立系统科学的AES系统评分效度研究方法。可以借鉴国外的研究,统一AES系统评分研究所需数据的种类和研究方法,尽快建立AES系统评分效度研究的科学方法,解决不同研究的可比性问题。第二,增加横向和纵向的比较。如上所述,国内AES系统评分效度的实证研究数量很少,仅涉及到句酷网和write on。迄今为止,还没有研究涉及到横向对比国内不同AES系统的评分效度。另外,有些AES系统(如句酷网)的语料库是不断更新的,相应地,其评分效度也会随之发生变化,因此,我们需要大量的实证研究尤其是历时研究对这种变化进行跟踪调查。第三,拓宽研究范围。大学的英语教学及很多大型语言测试均要求学生掌握不同文体的写作。到目前为止,国内在文体对AES系统评分的影响方面的研究还处于空白。尽管国外的研究得出的结论是文体对AES系统评分的信、效度影响有限,只占10%~20%[1],但国内的AES系统是否对不同文体存在偏颇性还有待于通过实证研究加以证明。
综上所述,以句酷为代表的英语写作网络在线自动评分系统在中国的英语写作教学中发挥了越来越大的作用,但国内对句酷网的研究主要集中在介绍其基本功能、特点、教学效果等方面,而其信、效度的实证研究还不多见。评分效度是任何语言测试的基础,没有评分效度,其他效度就无从谈起。因此,本文主要以实证研究的方式探讨句酷网的评分效度。
天气晴朗、水质良好,小龙虾活动吃食旺盛宜多投饵,鲜活饵料的日投饵量按体重的8%,高温、阴雨天气、发病季节、活动不正常少投饵,提高饲料利用率。
二、AES系统评分效度的实证研究
(一)研究样本
本研究的试验对象为某大学2012级英语专业三年级的本科生。经过分层抽样,共有50名学生成为本研究的对象。试验时间为2014年10月,学生在教师布置英语写作任务之后,通过句酷网提交一篇说明文,与英语专业八级(TEM8)写作难度相当。
为了使人工评分和机器评分具有可比性,笔者将句酷网的作文打分标准设置成TEM8写作打分格式,满分为20分。同时,由于句酷网的语料库经常更新,其评分的参数也会随之改变,这势必会影响不同时间提交的作文得分。因此,在所有作文均提交之后,2015年3月笔者又重新提交了这些作文,所得的分数作为本研究的数据。
参与本研究评分的人工评分员共有三人,他们均有多年英语专业高年级写作教学经验,并多次参加过英语写作的阅卷工作。在人工评分之前,笔者按照TEM8写作分项式评分法对这三位评分员进行了严格的培训。评分员在经过两轮共计20篇样文的评分培训之后,对TEM8作文评分标准的理解基本达到了一致水平。
(二)研究方法
本研究主要采用语言测试专家李筱菊[9]、Cizek & Page[1]有关语言测试评分效度的理论,从人分散度、相关性和等级一致性等指标来探讨句酷网的评分效度。主要的研究问题包括:机器评分的难度、区分度、标准差等指标是否能达到人工评分的水平,同理,机器评分的相关性和等级一致性是否能达到人工评分的水平。
Cizek & Page(2003)认为,考后复考等传统的评分效度评估方法是不适用于AES的[1]。同一批作文,只要参数设置相同,不同的计算机使用同一AES所给出的评分结果肯定是一样的。因此,正如上文所述,对于AES系统而言,我们需要考查的是,在同一评分标准下,机器评分与人工评分之间的一致性(agreement)或相关性(correlation)是否能达到人与人之间的一致或相关水平。在本研究中,相关性指人工评分与机器评分的Pearson相关系数,而分数相差3分以内(包括3分)即视为评分等级一致。此外,李筱菊(2001)认为,考试结果的分数要具有人分散度(person separability),即分数分布要散开[9],其主要指标包括区分度(discrimination)、标准差和难度。前人在AES评分效度的研究中对这些指标鲜有报告,但相关性很高的两组数据整体差异也有可能非常大,因此,笔者认为在实证研究中有必要对这些数据进行报告和对比。
(三)研究结果
第一,人分散度。如上所述,人分散度主要体现在难度、标准差和区分度等指标上。表1报告了机器评分和人工评分的平均难度、标准差和区分度。从表1的结果来看,人工评分的平均难度值(0.70)稍低于机器评分(0.72),但相差不大。在标准差方面,人工评分(平均2.15)明显好于机器评分(1.97),人工评分更加分散一些。但人工评分的标准差变化非常大(1.90~2.50),最低值甚至低于机器评分(R2=1.90),这说明不同的人工评分员在评分时宽严度掌握不一致。机器评分的平均区分度(0.18)十分不理想,低于人工评分(平均0.24),评分员1的评分在区分学生的写作能力方面稍好一些(0.29),但与标准差类似,人工评分的区分度起伏也很大(0.20~0.29)。
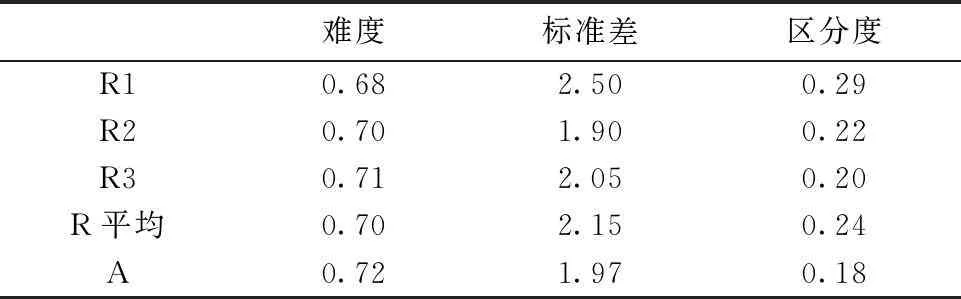
表1 机器评分与人工评分人分散度对照表(n=50)
注:A=机器评分;R=人工评分。
第二,相关性与等级一致性。表2报告了人工评分员之间、人工评分与机器评分之间的等级一致性和Pearson相关系数。从表2看,人工评分的等级一致性(0.90)与机器评分相当(0.89),但人工评分的等级一致性(0.82~0.96)不如机器评分(0.86~0.92)稳定。相对而言,人工评分的Pearson相关系数(0.65)要好于机器评分(0.59),但从稳定性上来说,人工评分(0.61~0.73)和机器评分(0.53~0.63)都差强人意。
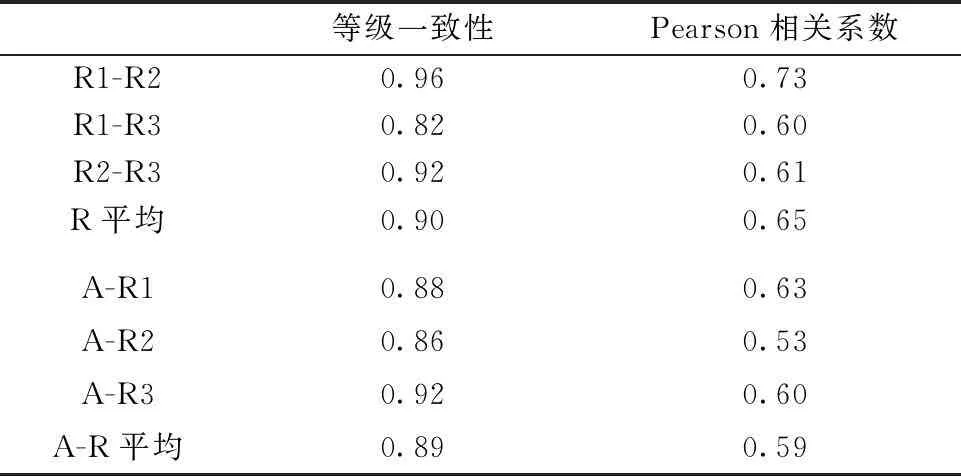
表2 机器评分与人工评分相关性和
三、AES系统评分效度的讨论
上述数据的分析结果表明:句酷批改网自动评分系统的评分区分度有待于提高,但总的来说,其评分效度尚可接受。
(一)评分效度的分析
在人分散度这个指标上(表1),机器评分与人工评分的难度判断几乎是一致的,并未出现某些研究中报告的机器评分偏高问题[7]。如前文所述,句酷网的语料库一直处于不断更新之中,其评分有越来越低的趋势,与人工评分越来越接近。但就标准差和区分度而言,机器评分明显逊色于人工评分,这说明机器评分在写作能力的区分上不如人工评分。事实上,尽管人工评分的区分度好于机器评分,但二者均不理想。一般认为,试题的区分度在0.3以上是比较理想的,而0.25左右仅仅是可以接受的水平。因此,如果说人工评分的区分度(0.24)勉强过关,则机器评分的区分度(0.18)还亟需提高。
就相关性而言,句酷网的自动评分尚可接受。尽管机器评分与人工评分的相关性总的来说只有0.59,但我们同时还发现,就TEM8写作评分来说,人工评分之间的相关性平均值也并不高,只有0.65(表2)。根据Stemler(2004)等人的研究,评分员之间的相关系数达到0.70左右才是可以接受的[12]。按照这个标准,不仅句酷批改网的评分效度不理想,人工评分也不例外。然而,国外的AES系统早期阶段的相关性也没有达到0.70这个理想的数值。在PEG最早的一次实验中,人工评分员之间的平均相关性仅为0.55;在1994年的实验中,这一数值更低,仅0.49;即便是在信度最高的1995年的实验中,人工评分员之间的平均相关性也只有0.65[3]。可见,人工评分员之间想实现较理想的评分效度是很难的,更何况人工评分员与机器之间的相关性了。因此,与国外相比,本研究中的人工评分员之间的相关性是可以接受的,但机器评分的评分效度就稍稍偏低了,与前文所报告的处于高级阶段的PEG的0.71[5]、IEA的0.85[3]还有差距,需要不断完善。然而,国外的自动评分系统多采用等级制,即5~6个等级,而句酷网的TEM8写作是从20分中为一篇作文选择一个分数,甚至整数分数后面还会出现半分,其评分难度无疑要大得多,因此,句酷网当前的相关性尚可接受。
此外,在本研究中,机器评分(0.89)与人工评分(0.90)的等级一致性基本是一致的,同时,机器评分的稳定性明显好于人工评分(表2)。这说明,句酷批改网在执行评分标准方面比人脑有优势,其中一个主要原因在于机器在评分时不会受到时间、地点、疲劳状态、精神状态等众多因素的影响。
综上所述,句酷批改网的评分效度可以满足风险较小的英语写作的自动评分,如写作课的英语写作作业等,但还不能满足风险较大的大型考试的需要。因此,其评分效度特别是区分度等指标仍有较大的提升空间。
(二)评分效度改进的方法
国外主流的AES系统在自动评分之前基本上都需要针对某次考试收集样本,对系统进行培训。一般而言,这种自动评分方法对于该次考试的作文评分效度较高,但不能用于其他考试的自动评分。事实也证明,国外的英语自动评分系统的评分效度早已高于人工评分[1]。与国外不同,句酷批改网是基于语料库的作文在线自动评分系统,不需要对系统进行培训,可以为任何题目的作文评分,其核心算法是计算学生提交的作文与语料库之间的距离,再通过映射将距离转化成作文分数和评语。这种评分方法是把双刃剑,优缺点均很明显。优点是该自动评分系统可以为任何作文评分,很适合于英语写作的课堂教学。缺点是,不对系统进行有针对性的培训,句酷网在自动评分时对内容的判断就没有了充分的依据。因此,目前句酷批改网对于“跑题”等严重的内容问题还判断不出来。即使作文跑题了,学生仍然可以利用较高级的词汇和较长的句子轻而易举地“骗过”计算机。国内研究者谢贤春就曾指出,为了取得高分,有些学生有意“欺诈”或“取悦”电脑,通过“写长”或简单地“重复”某些段落“骗得”高分[13]。克服这一缺陷需要计算机在人工智能方面取得突破,如简单知识的识别等。在目前阶段,国内机器自动评分系统在评阅风险较大的作文时还需要人工辅助,特别是在内容识别方面。
除此之外,为了提高评分效度,国内的自动评分系统在语料的选择上应有别于国外。二语写作与母语写作尽管总体模式相似,但二语作文使用的词汇量更少,文本结构更简单,形式连接方式往往多于内容连接方式,在准确性、流利性和有效性方面均逊色于母语作文,处于中介语阶段[14]。这些特点决定了二语作文的评分标准应不同于母语作文,语言与内容应同等重要。因此,笔者建议在选取语料时应借鉴并改进国外比较成熟的自动评分系统的技术:利用作文训练集对自动评分系统进行培训,建立中介语语料库。以TEM8写作为例,应不分题目和体裁地广泛搜集代表各分数段的作文,提取各个分数段与内容无关的浅层文本特征,用于培训自动评分系统。这个训练集在每个分数上都应该有足够的样本,随着样本数量不断累积,每个分数的样本都能构成一个独立的语料库,这样对代表每个分数的浅层文本特征的提取将会越来越精确,自动评分在语言上的评分也会越来越接近人工评分。
从本研究来看,句酷网的整体评分效度是可以接受的,尽管不能满足对评分效度和社会使用效度等要求较高的大型测试,但目前的水平可以满足英语写作教学的课后或课堂作业的自动评分,这既能使英语写作教师从繁重的作业批改任务中解放出来,也有助于在英语写作课上实施形成性评估这一先进的评价手段。
参考文献:
[1] SHERMIS M D, BURSTEIN J. Automated essay scoring: A cross-disciplinary perspective[M]. Mahwah, NJ: Lawrence Erlbaum Associates, 2003:vii, xiii, 25-27,76,95,125-146,128,142-143.
[2] 石晓玲.在线写作自动评改系统在大学英语写作教学中的应用研究——以句酷批改网为例[J].现代教育技术,2012(10):67-71.
[3] 梁茂成, 文秋芳. 国外作文自动评分系统评述及启示[J]. 外语电化教学, 2007 (5): 18-24.
[4] CHOI I C. A validation of EFL essay assessment based on corpus indices and error analysis[J]. Multimedia-assisted language learning, 2012 (4): 39-60.
[5] SHERMIS M D, MZUMAIA H R, OLSON J, et al. On-line grading of students essays:PEG goes on the world wide web[J]. Assessment & education in higher education, 2001(3):247-259.
[6] 王莺莺.《新视野大学英语》作文自动评分系统的效度研究[J].当代教育理论与实践, 2012 (12): 139-142.
[7] 何旭良. 句酷批改网英语作文评分的信度和效度研究[J]. 现代教育技术, 2013 (5): 64-67.
[8] 汪珍珠,叶宬. 英语作文在线批改模式的实证研究[J]. 长沙铁道学院学报,2014 (1): 161-163.
[9] 李筱菊. 语言测试科学与艺术[M]. 第2版. 长沙: 湖南教育出版社, 2001:34-36.
[10] MESSICK S. Validity[C]//Linn R L. Educational measurement (3rdEd.). NewYork: Ma cmillan, 1989:13.
[11] WEIR C J. Language testing and validation: an evidence-based approach [M]. Basin gstoke, Hampshire: Palg rave Ma cmillan, 2005:11-39.
[12] STEMLER S E. A comparison of consensus, consistency, and measurement approaches to estimating interrater reliability[EB/OL].[2015-05-03].http://pareonline.net/getvn.asp?v=9&n=4.
[13] 谢贤春. 英语作文自动评分及其效度、信度与可操作性探讨[J].江西师范大学学报(哲学社会科学版), 2010(2):136-140.
[14] SILVA T.Toward an understanding of the distinct nature of L2 writing: The ESL research and its implications[J]. TESOL Quarterly, 1993(4):657-677.
(责任编辑:薛蓉)
An empirical research into scoring validity of AES
WANG Haijun
(Zhijiang College, Zhejiang University of Technology, Hangzhou 310024, China)
Abstract:Although AES is playing a more and more important part in English writing tests and teaching abroad, little empirical research has been carried out into its reliability and validity in China. The research, a case study of Juku AES, investigated its scoring validity from the perspectives of person separability, consistency and classification agreement. It is concluded that the scoring validity of Juku is so adequate as to satisfy the needs of English classroom writing tasks in spite of its relatively poorer discrimination.
Keywords:AES; scoring validity; Juku
中图分类号:H319
文献标志码:A
文章编号:1006-4303(2016)01-0089-05
作者简介:王海军(1975—),男,黑龙江兰西人,讲师,硕士,从事语言教学与测试研究。
基金项目:浙江省社科规划课题(16NDJC213YB);浙江省高等教育课堂教学改革研究项目(kg2013525);绍兴市高等教育课堂教学改革项目(绍市教高[2014]135号);浙江工业大学人文社科研究基金(GZ152105012800)
收稿日期:2015-09-03
