中国碳排放量的组合模型及预测*
2016-04-15肖枝洪王明浩
肖枝洪, 王明浩
(重庆理工大学 数学与统计学院,重庆 400054)
中国碳排放量的组合模型及预测*
肖枝洪, 王明浩**
(重庆理工大学 数学与统计学院,重庆 400054)
摘要:根据碳排放的演化规律,采用ARIMA模型与BP神经网络集成的组合模型,对中国碳排放量进行预测研究;取1980—2007年中国碳排放量作为训练样本,确定模型参数;然后取2008—2013年中国碳排放量作为测试样本对文中的组合模型进行验证,并与已有文献所建立的预测模型进行比较,结果显示,此处所建立的组合模型预测误差极小;最后,根据组合模型对2014—2020年中国碳排放量进行预测,指出中国还将继续面临碳减排压力。
关键词:ARIMA模型;BP神经网络;碳排放;组合模型
随着全球气候逐渐变暖,各国开始着手研究其原因[1],结果表明,气候变暖的主因是二氧化碳过量排放,从而提出碳排放量这一概念。中国碳排放量预测的准确与否极大地影响着中国未来的发展及绿色城市构建。目前,关于碳排放量预测的方法主要分为两种。第一种是分析碳排放量与其影响因素之间的关系,构建能源消费模型,随后基于情景分析法对碳排放量进行预测。但不足之处在于,情景分析法会受到较大主观因素的影响。第二种根据碳排放量过去变化的趋势对未来碳排放量进行预测[2],其主要采用时间序列方法,如ARIMA模型。ARIMA模型的优点在于简单、灵活、可行。但其局限于研究序列的线性关系,不能反映序列的非线性关系。然而在实际情况中,绝大多数时间序列都包含了非线性关系[3]。神经网络模型具有较强的学习与数据处理能力,可以提取数据中隐含的非线性关系,在预测中得到了广泛应用[4-5]。但神经网络模型在处理呈现线性关系的数据时,其结果往往不如ARIMA模型。因此,采用单一的模型进行预测效果不佳。
Zhang[6]认为时间序列过程是由线性和非线性部分组合而成的。肖枝洪[7]等提出用干预模型与BP神经网络集合的组合模型预测中国的GDP。其研究结果表明,组合模型比单一模型预测的准确性高。为了提高中国碳排放量预测精度,拟将ARIMA模型与BP神经网络相结合,构造组合模型,对中国2014—2020年碳排放量进行准确预测。
1模型原理与算法
1.1ARIMA(p,d,q)模型
ARIMA(p,d,q)模型[8]的结构为
(1)
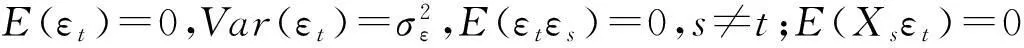
1.2BP神经网络
BP神经网络是神经网络中广泛应用的一种模型[9],它包括输入层、隐含层和输出层。隐含层可以有一层或者多层,相邻上下层之间的神经元实现全部连接,而每层各神经元之间相互独立,如图1所示。
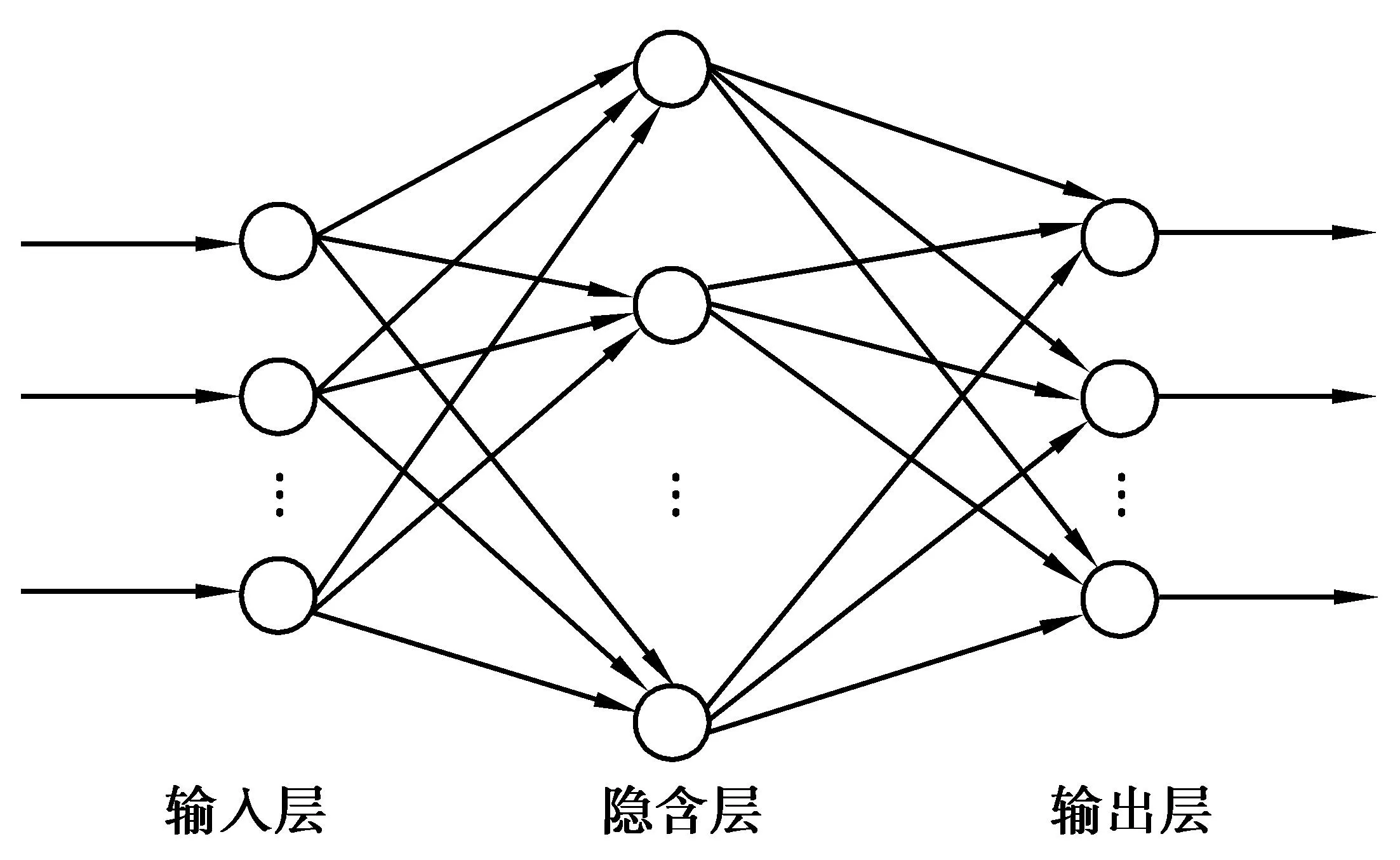
图1 单层神经网络Fig.1 Single layer neural network
BP神经网络的原理是通过样本数据的训练,不断修正网络的权值和阀值,使误差函数沿负梯度方向下降,逼近期望输出。训练数据由输入层单元传到隐含层单元,经隐含层单元逐个处理后传到输出层单元,由输出层单元处理后产生输出模式。若输出模式与期望输出模式有误差,则将误差值沿着连接通路逐层传送并修正各层的连接权值,即网络状态前向更新和误差反向传播,通过反传误差函数,不断调节网络的权值,使误差函数达到极小。
1.3基于ARIMA模型与BP神经网络的组合模型
1.3.1组合模型建立步骤
组合模型的构建步骤如下:
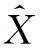
2) 运用BP神经网络模型来拟合残差序列。设网络输入有n个,将残差关系表示成
(2)
其中,f为神经网络模型的非线性函数,nt为随机误差。
3) 由模型(1)和模型(2)建立组合模型如下:
(3)
1.3.2模型的评价方法
所建立模型的预测性能通常通过目标变量的观测值与预测值进行比较来判断。其评价标准有平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)、归一化均方误差(NMSE)、归一化平均绝对误差(NMAE),表达式如下:
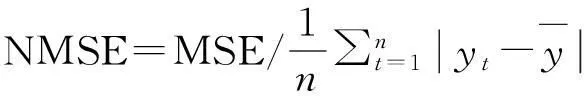
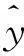
平均绝对误差(MAE)表示预测值与真实值偏差的绝对值均值;均方误差(MSE)表示预测值与观测值偏差的平方均值;均方根误差(RMSE)是均方误差的开方;归一化均方误差(NMSE)表示计算模型预测性能和基准模型预测性能之间的比率,可以评价模型得分的好坏。NMSE的取值为(0,1)区间,如果模型表现优于非常简单的基准模型,那么NMSE应明显小于1。NMSE的值越小,模型的性能越好。
2组合模型在中国碳排放量预测中的应用
2.1数据来源及描述
中国碳排放量数据由全球碳计划(Global Carbon Project)所提供,如表1所示。
为方便计算,用{Xt}表示中国碳排放量序列,以1980—2007年中国碳排放量数据作为训练样本,建立模型;再以2008—2013年中国碳排放量数据作为测试样本,用来检验所建立模型的优良性。
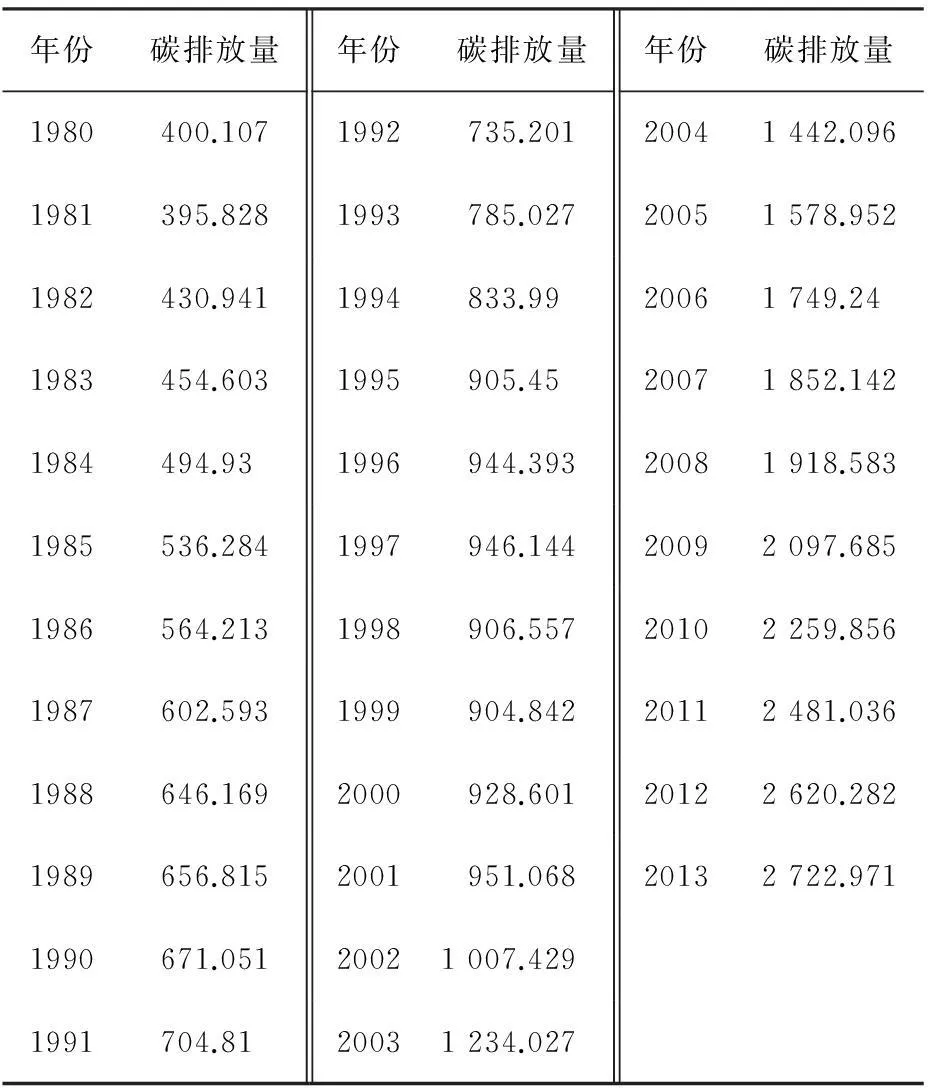
表1 1980—2013年中国碳排放量(单位:百万t)
2.2中国碳排放量组合模型的建立
首先对{Xt}进行探索性分析,运用R软件对训练样本绘制1980—2007年{Xt}时序图,如图2所示。根据图2可以看出,1980—2007年中国碳排放量呈现指数上升趋势。对其进行对数变换,即Yt=ln(Xt),经过变换后Yt的时序图,如图3所示。从图3可以看出,在1998—2002年中国碳排放量上升趋势较缓,但其他点连线,近乎呈现出线性上升趋势。所以,认为经过变换后的序列Yt呈现线性趋势,同时,也可以发现Yt为非平稳序列。
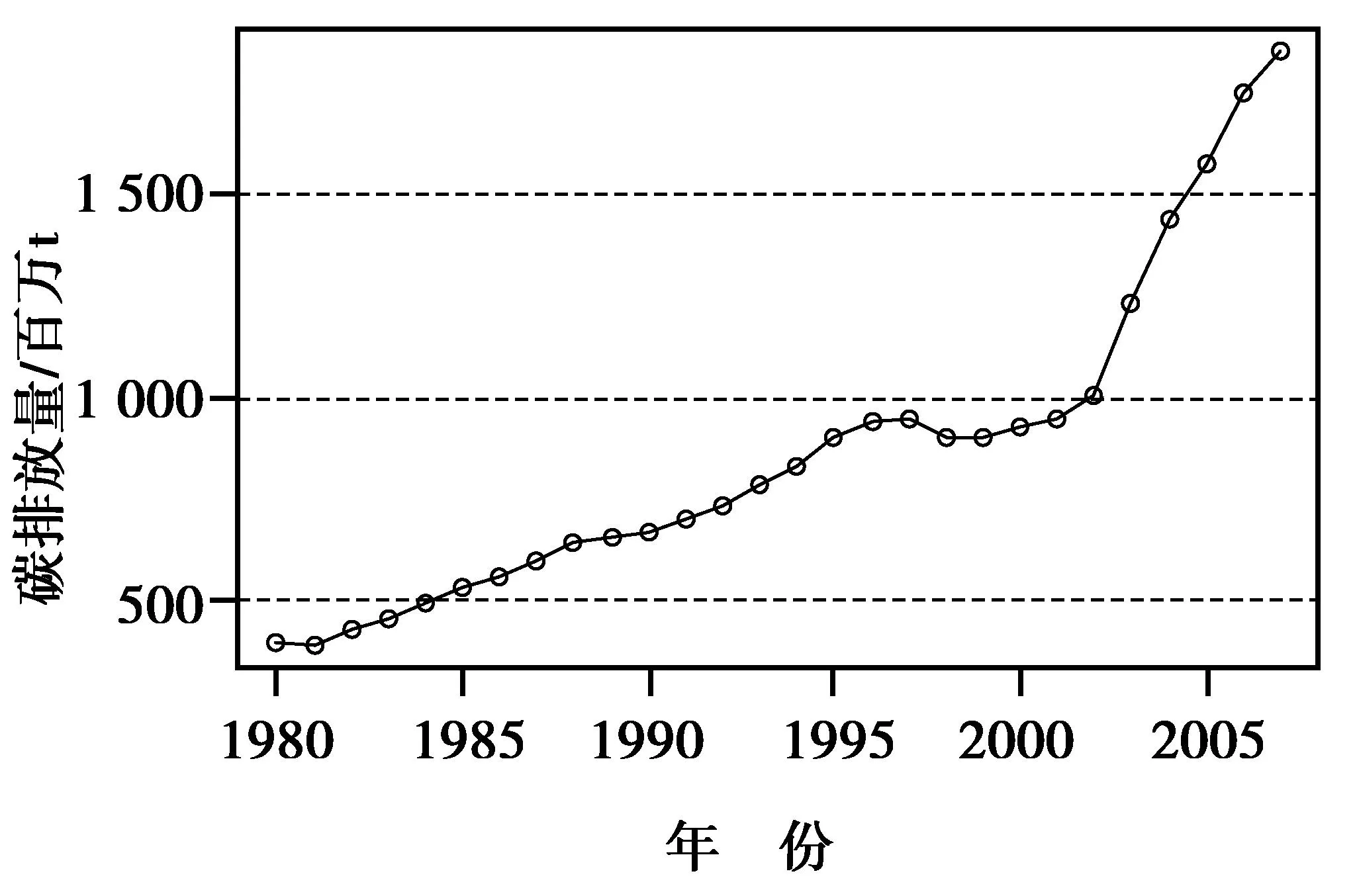
图2 中国1980—2007年的碳排放量Xt时序图Fig.2 Carbon emission amount Xt time-sequencechart during 1980—2007
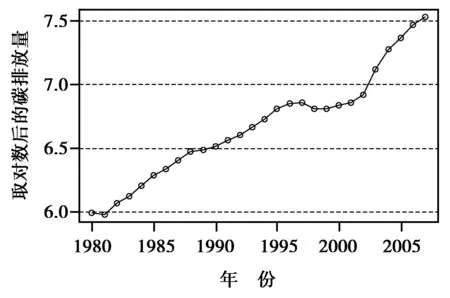
图3 中国1980—2007碳排放量取对数后的Yt时序图Fig.3 Logarithm Yt time-sequencechart of carbon emission during 1980—2007

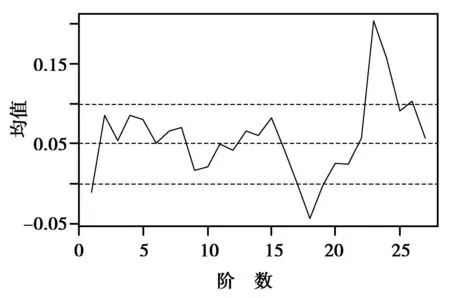
图4 Yt的时序图Fig.4 Yt time-sequence chart
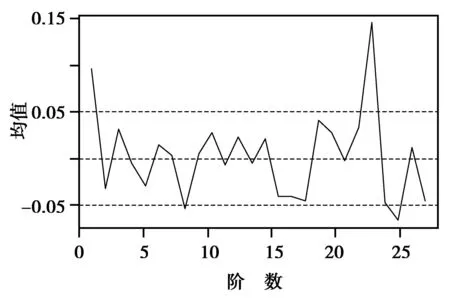
图5 2Yt的时序图Fig.5 2Yt time-sequence chart
“这个小区的防盗门存在严重的质量问题。”吕凌子双手捧着杯,顺时针转了一圈,再逆时针转了一圈。茶杯口呼呼冒着热气。
(4)
对模型(4)的残差进行Ljung-Box检验,其p值为0.951 7,此残差序列通过白噪声检验,认为模型(4)合适,可以用来预测。从模型(4)可以看出,时刻t的Yt会受到前一时刻Yt-1的正影响,同时,也会受到前两时刻Yt-2的负影响。也就是说,第t年的碳排放量,会受到其前一年与前两年碳排放量影响,但影响程度不一样。同时,时刻t的Yt,不仅受到当期的随机因素影响,而且也受到前一时刻的随机因素影响。
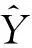
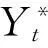
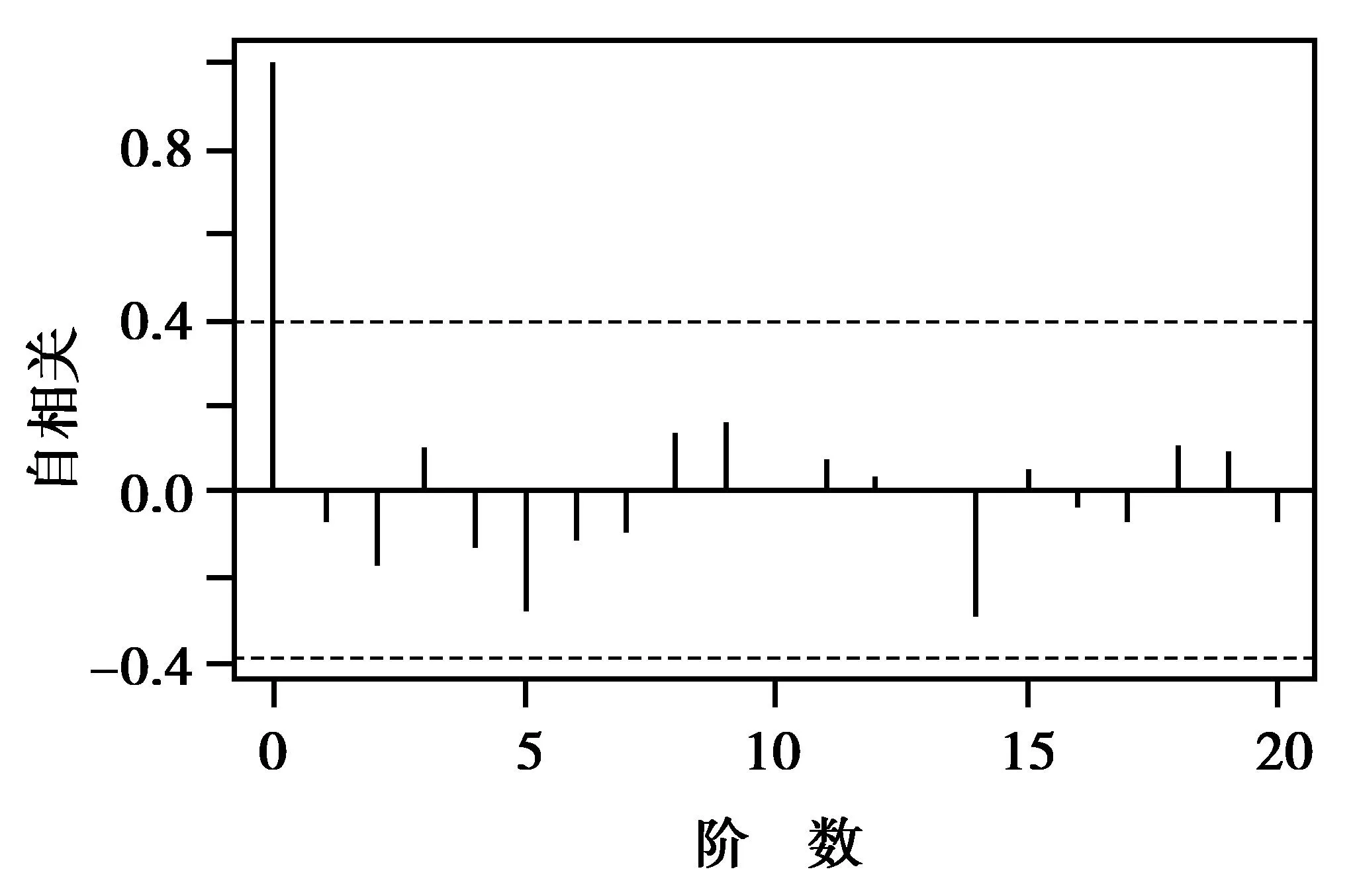
图6 2Yt自相关函数图Fig.6 2Yt auto-correlation function chart
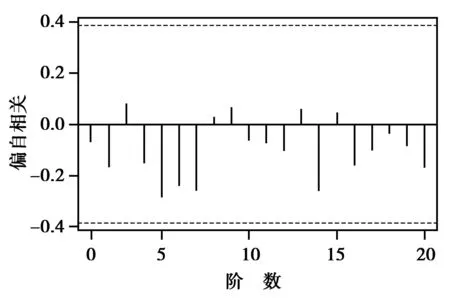
图7 2Yt偏自相关函数图Fig.7 2Yt partial auto-correlation function chart
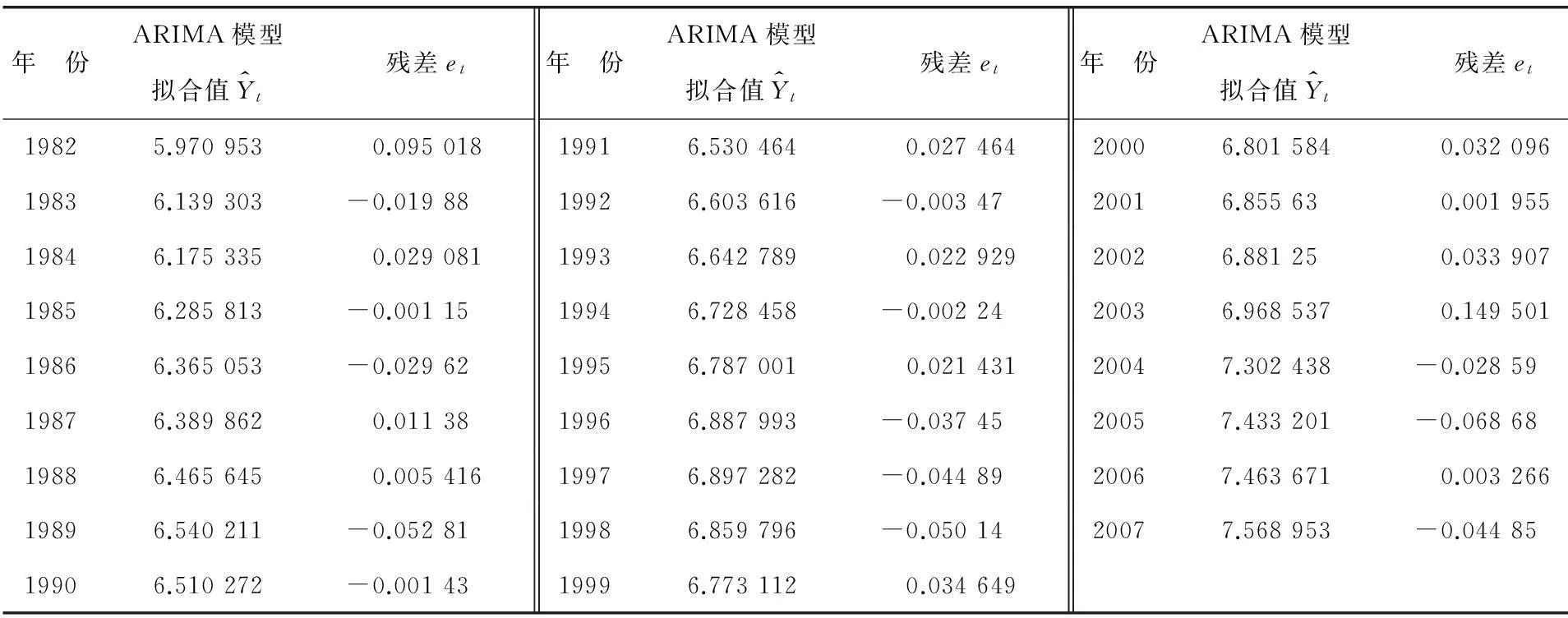
年 份ARIMA模型拟合值Y^t残差et年 份ARIMA模型拟合值Y^t残差et年 份ARIMA模型拟合值Y^t残差et19825.9709530.09501819916.5304640.02746420006.8015840.03209619836.139303-0.0198819926.603616-0.0034720016.855630.00195519846.1753350.02908119936.6427890.02292920026.881250.03390719856.285813-0.0011519946.728458-0.0022420036.9685370.14950119866.365053-0.0296219956.7870010.02143120047.302438-0.0285919876.3898620.0113819966.887993-0.0374520057.433201-0.0686819886.4656450.00541619976.897282-0.0448920067.4636710.00326619896.540211-0.0528119986.859796-0.0501420077.568953-0.0448519906.510272-0.0014319996.7731120.034649

表3 预测残差与组合模型的中国碳排放预测结果

2.3模型预测性能的评价
将两个模型5种评价准则的结果列表,如表5所示。由表5可以看出,组合模型与ARIMA模型的NMSE,NMAE接近于0,NMSE,NMAE越小表示模型的预测性能越好,所以,两个模型都具有良好的预测能力。其中,组合模型的NMAE与NMSE均比ARIMA模型小一个数量级。通过对MAE,MSE,RMSE的比较可以发现,组合模型的预测能力是ARIMA模型不可比拟的。
唐建荣[10]采用随机森林模型预测的平均相对误差率为1.931 5%,偏最小二乘预测的平均相对误差率为2.537 61%,也比此处提出的组合模型的平均相对误差率0.873 37%大得多。从而可以看出,此处所建立的组合模型对中国碳排放量预测显示出了优良性。
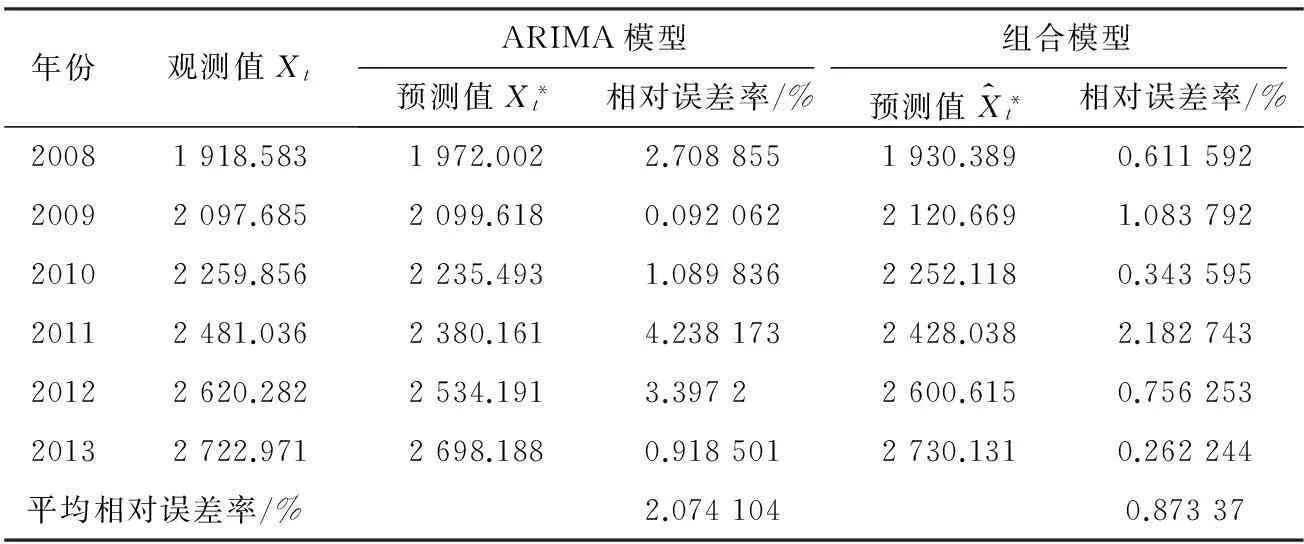
表4 两种模型预测结果的比较

表5 模型5个评价准则
现利用1980-2013年的数据按照上述方法建立组合模型(5):
(5)
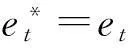
3结果与分析
3.1中国碳排放量预测结果
由所建立的组合模型(5)对2014—2020年中国碳排放量进行预测,预测结果如表6所示。
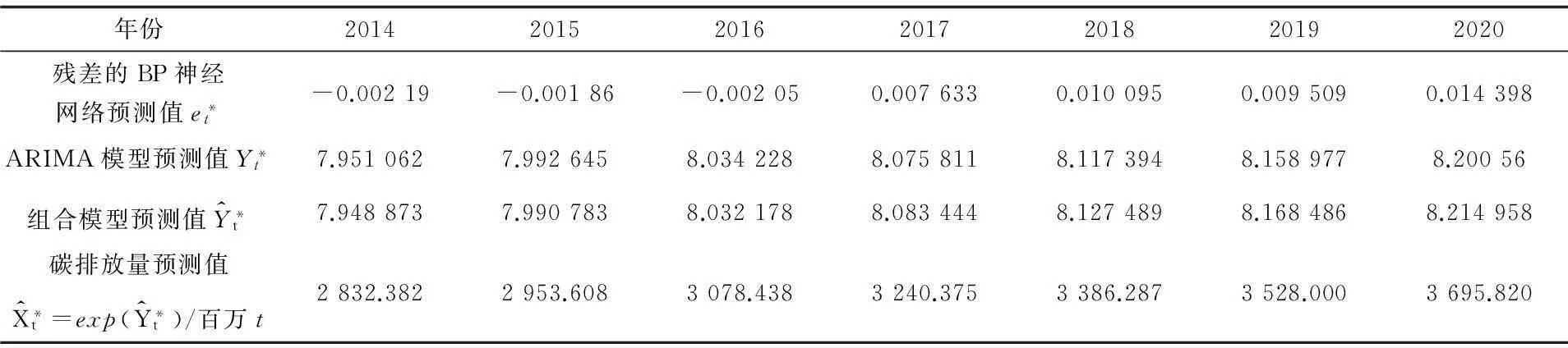
表6 2014-2020年残差、ARIMA模型、组合模型预测值
由表6可知,从2014年开始,中国碳排放量将会以每年100百万t甚至更高的速度增长,直到2020年中国碳排放量为3 695.82百万t,将会是2013年的1.36倍。
3.2结果分析
中国碳排放量持续增长,为探索中国碳排放量的增长规律,将表1与表6数据联系起来,绘制出1980—2020年中国碳排放量趋势图,如图8所示。由图8可以看出,中国碳排放量发展有4个阶段。第一阶段,从1980年开始到1997年,中国碳排放量呈现上升趋势。第二阶段,中国碳排放量在1998年先下降,然后从1999年开始缓慢上升持续到2003年,此阶段与1996年之前相比增长速度较慢。第三阶段,从2003年转折,到2013年中国碳排放量呈现出了前所未有的快速上升状态。第四阶段,2014—2020年中国碳排放量依旧持续快速上升,其年均碳排放量为3 244.99百万t(图中第一条虚线),是1980—2013年的年均碳排放量1 128.35百万t(图中第三条虚线)的2.88倍。因此,中国在2014—2020年的发展中应更加关注节能减排,控制碳排放增长。
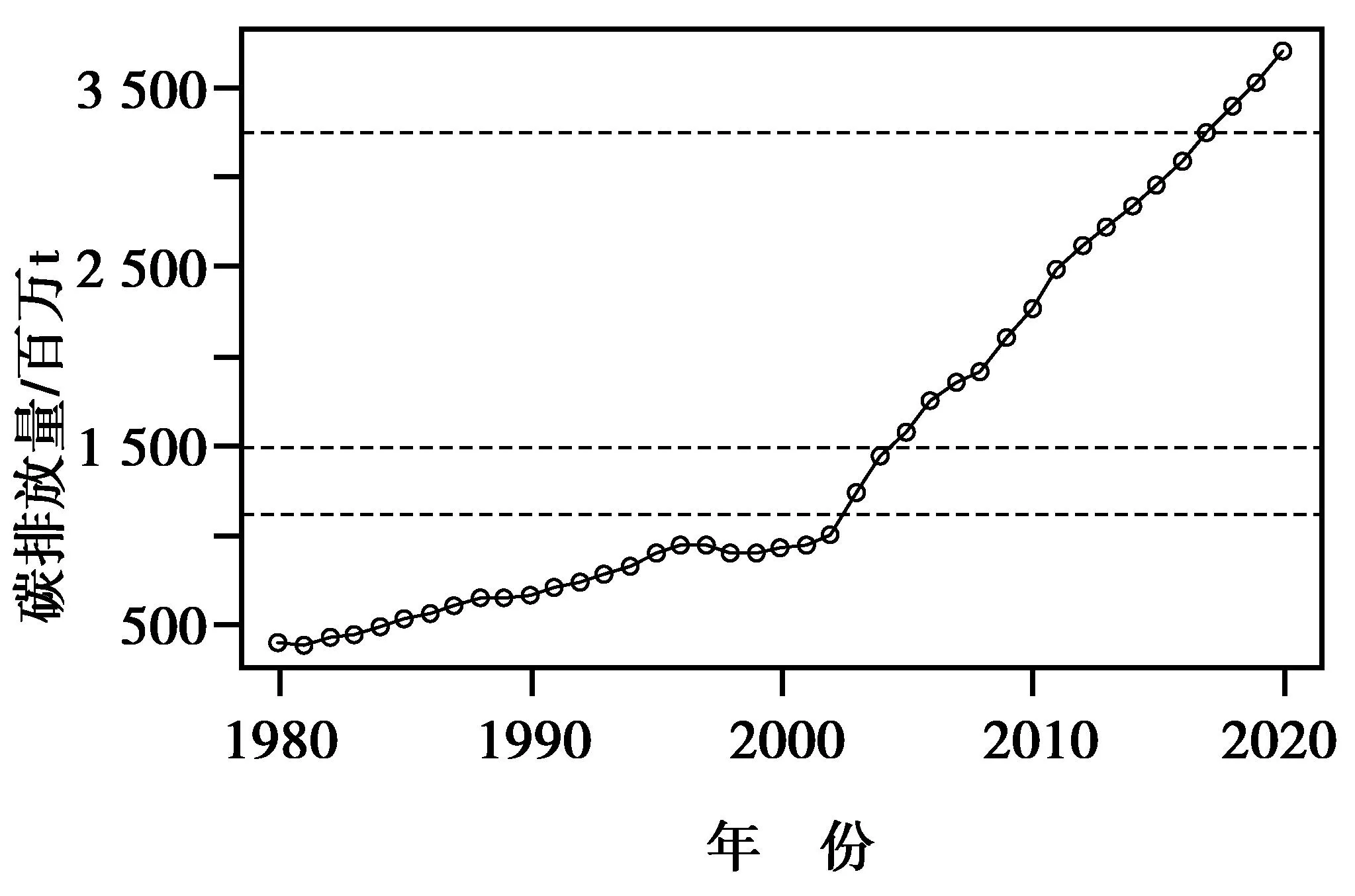
图8 1980—2020年中国碳排放量趋势图Fig.8 1980—2020 China’s carbon emission trend
中国碳排放量增长依旧显著。根据1980—2020年中国碳排放量,经计算得出1981—2020年中国碳排放增长率,并绘制折线图,如图9。从图9可以看出,中国碳排放量增长率几乎在0~10%区间内波动,且1981—2013年平均碳排放增长率为6.09%,2014—2020年预测的年均碳排放增长率为4.46%,1981—2020年平均碳排放增长率为5.81%(图中虚线部分)。所以,中国碳排放量会一直持续增长,并且越往后增长的速度越快。这意味着中国将面临前所未有的减排压力。
合理制定减排额度。根据模型(5)可知,当年的中国碳排放量,主要受其前一、两年的碳排放量影响,并且其前一年的碳排放量对当年的碳排放量影响较其前两年更大。因此,中国在未来的能源减排中,应实行逐年减排的政策。在制定减排计划时,应根据前一年的碳排放量合理制定减排额度。
预测模型评价及意义。此处所建立的组合模型预测误差明显低于单个模型或随机森林模型,证实了组合模型在中国碳排放量预测方面的优越性,能够为政府提供精准的中国未来碳排放量预测值,为今后碳排放额的制定起到指导作用,为中国对国际社会承诺碳减排数量起到参考作用。
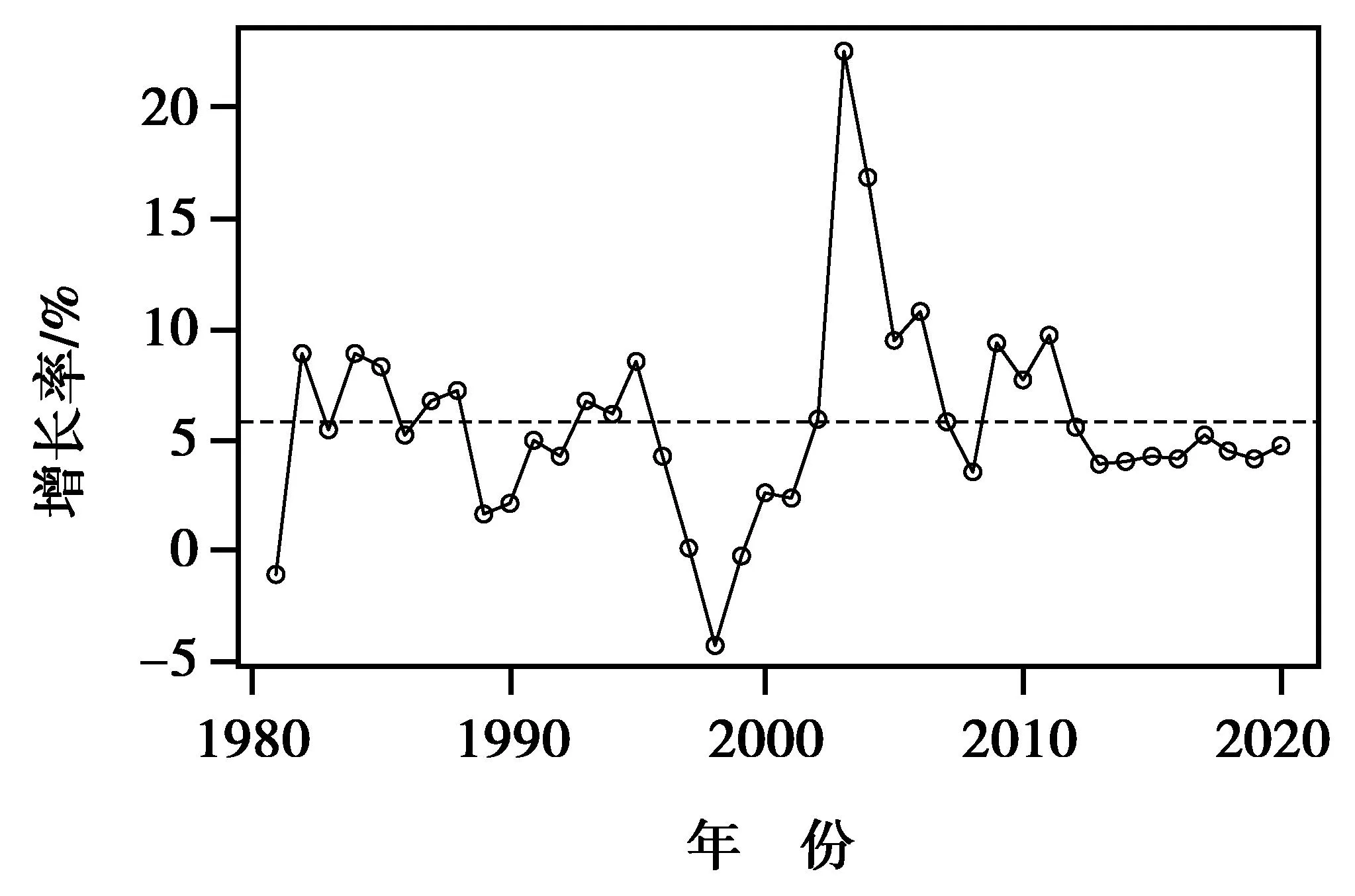
图9 1981—2020年碳排放增长率Fig.9 1980—2020 carbon emission growth rate
参考文献(References):
[1]BRIAN O’Neil,DATON M.Global Demographic Trends and Future Carbon Emissions[J].PNAS,2010,107(41):17521-17526
[2] 李岩岩.ARIMA模型在重庆市能源消耗量预测中的应用[J].重庆工商大学学报(自然科学版),2015,32(8):54-60
LI Y Y.Application of ARIMA Model in the Prediction of Energy Consumption of Chongqing[J].Journal of Chongqing Technology and Business University(Natural Science Edition),2015,32(8):54-60
[3] KHASHEI M,BIJARI M,ARDALI GAR.Improvement of Auto-regressive Integrated Moving Average Models Using Fuzzy Logic and Artificial Neural Networks[J].Neurocomputing,2009(72):956-967
[4] KAASTRA,BOYD M.Designing a Neural Network for For-ecasting Financial and Economic Time-series[J].Neurocomputing,1996(10):215-236
[5] DIORDANO F,LA ROCCA M,PERNA C.Forecasting Nonlinear Time Series with Neural Network Sieve Bootstrap[J].Comput Stat Data Anal,2007(51):3871-3884
[6] ZHANG G P.Time Series Forecasting Using a Hybrid ARIMA and Neural Network Model[J].Neurocomputing,2003(50):159-175
[7] 王鑫,肖枝洪. 基于干预模型与BP神经网络集成的GDP预测[J]. 统计与决策,2012(20):141-144
WANG X X,XIAO ZH H.Prediction of GDP Based on BP and Intervention Model[J].Statistics & Decision,2012(20):141-144
[8] 肖枝洪,郭明月.时间序列分析与SAS应用[M].武汉:武汉大学出版社,2012
XIAO ZH H,GUO M Y.Time Series Analysis and SAS Application[M].Wuhan:Wuhan University Press,2012
[9] CHEN Y,YANG B,DONG J,et al.Time-series Forecasting Using Flexible Neural Tree Model[J].Inf Sci,2005,174(3):219-235
[10] 唐建荣,陈实.基于随机森林方法的碳足迹及其影响因素研究[J].统计与信息论坛,2013,28(10):70-74
TANG J R,CHEN SH.Study on the Impact Factors of Carbon Footprint Based on Random Forest[J].Statisitice & Information Forum,2013,28(10):70-74
责任编辑:李翠薇
Prediction of Carbon Emission Quantity of China Based on Combined Model
XIAO Zhi-hong, WANG Ming-hao
(School of Mathematics and Statistics, Chongqing University of Technology, Chongqing 400054, China)
Abstract:According to evolution law of carbon emission, by using the combined model from ARIMA Model and BP neural network integration, this paper studies the prediction of carbon emission quantity of China. By taking carbon emission quantity of China during 1980-2007 as training sample, the model parameters are made, then the combined model in this paper is tested by taking the carbon emission quantity of China during 2008-2013 as testing sample and the model is compared with the prediction model established in the existed references. The result shows that the deviation is relatively small by using the combined model constructed in this paper, and finally 2014—2020 carbon emission quantity of China is predicted based on the combined model and the predicted result show that carbon emission quantity of China will continue to face reduction pressure.
Key words:ARIMA Model; BP neural network; carbon emission; combined model
中图分类号:F206
文献标志码:A
文章编号:1672-058X(2016)01-0009-07
作者简介:肖枝洪(1965-),男,湖北汉川人,教授,博士,从事数据分析、应用统计研究.**通讯作者:王明浩(1990-),男,辽宁本溪人,硕士研究生,从事数据分析、应用统计研究.E-mail:wmh@2013.cqut.edu.cn.
*基金项目:国家统计局科研项目(2014LZ25);重庆理工大学研究生创新基金资助项目(YCX2014235).
收稿日期:2015-07-27;修回日期:2015-09-10.
doi:10.16055/j.issn.1672-058X.2016.0001.002
