基于软加权映射的局部聚类向量表示方法
2016-04-13周毅书张海涛周剑雄
刘 琦,梁 鹏, 周毅书, 张海涛, 周剑雄
(1.中国移动南方基地,广东 广州 510640; 2. 广东技术师范学院 计算机科学学院,广东 广州 510665)
基于软加权映射的局部聚类向量表示方法
刘 琦1,梁 鹏2, 周毅书1, 张海涛1, 周剑雄1
(1.中国移动南方基地,广东 广州 510640; 2. 广东技术师范学院 计算机科学学院,广东 广州 510665)
基于特征码本的图像分类方法依赖于需要特征向量与聚类中心之间的映射,然而硬加权映射方法导致了相似的特征向量被映射为不同的聚类中心,从而降低了分类的查全率。为此提出一种基于软加权映射的局部聚类向量表示方法。该方法首先用k均值算法将特征向量聚类为k个聚类中心,采用最近邻算法寻找最接近的s个聚类中心,通过特征向量与聚类中心之间的相似度和邻近程度构建软加权映射的局部聚类向量,然后统计特征直方图,最后用主成分分析减少特征直方图维度。实验结果分析表明,相比较硬加权映射方法,文中方法提高了约5%的分类准确率。
软加权映射; 图像分类; 特征码本; 主成分分析
0 引言
复杂纷乱的背景、局部遮挡和几何变化给目标图像分类带来了应用上的困难,因此词包模型分类方法得到了广泛的应用。如图1所示,词包模型是基于特征聚类得到的,即对特征向量进行聚类量化得到多个聚类中心,所有的聚类中心组成一个特征码本,特征向量与聚类中心之间的映射称为特征量化。

图1 词包模型表示示意图
特征向量可以选择角点或者SIFT特征、SURF特征等,近期这方面的工作可参见文献[1-3]等。然而,词包模型在量化过程中丢失了目标物体的空间结构信息,仅仅使用了特征的视觉信息。这使得一些视觉上类似但是分布完全不同的物体难以分类,因此加入空间信息成为了另一个研究的热点。Svetlana Lazebnik等提出了空间金字塔Spatial pyramid模型[4],其将图像分成多个同样大小的网格,对每个网格内的局部特征分别进行频率直方图统计,再将直方图按照网格顺序连接起来形成具有空间分布信息的直方图。在此基础上,出现了一系列类似的变化方法[5-9]。其中局部聚类向量表示[10](Vector Local Aggregating Descriptors, VLAD)通过比较同一个聚类中心内所有的特征向量方向以加入空间信息,既降低了特征码本量化的精度,又降低了计算复杂度。然而上述方法的特征映射过程均采用硬加权映射方法,即一个特征向量只映射到最近邻的聚类中心。近期研究发现[11,12],这些方法的查全率难以提升,这是因为硬加权映射方法在量化特征码本过程中存在误差,从而导致特征映射时无法映射到准确的聚类中心。如图2所示的硬加权映射聚类结果表明,对于5个聚类中心,点1,2,3,4, 5表示特征向量,按照硬加权特征映射方法,即使点3,4空间距离十分相近,在特征匹配阶段,点3和点4仍然被认为是完全不同的特征,这就给后续的分类带来了匹配上的误差。

图2 硬加权映射的聚类结果
这样的硬加权映射结果将导致特征点3和特征点4被量化为两种不同的特征,从而在分类过程中容易产生混淆,降低了分类的查全率。
软加权映射方法可以有效地增加特征的鲁棒性,模糊C聚类和模糊k均值是两种软加权映射方法。Li等采用模糊C均值聚类提高了聚类的准确率[13]。Khang等用分层模糊C均值聚类提高了彩色图像分割精度。然而模糊聚类使得特征维度变长,特征直方图更加稀疏,从而在一定程度降低了分类准确率[14]。
为了解决硬加权映射带来的问题,文中提出一种基于软加权的局部聚类向量表示方法,既保留了软加权映射的鲁棒性,又减少了特征维度。该方法通过特征向量与聚类中心之间的相似度和邻近程度实现软加权映射,实验结果表明了方法的有效性。
1 基于软加权的局部聚类向量表示
特征码本的构建是词包模型中必不可少的一个环节,通过特征码本实现了特征向量与特征单词之间的映射,极大地减少了特征向量的维数。然而,特征码本的量化精度也成为了检索方法准确率的瓶颈,为了尽可能提高特征之间的可区分性,需要提高量化的精度;而要提高检索系统的泛化能力,则要降低量化的精度,因此需要在两者之间寻找一个平衡。此外,传统的特征码本构建方法通常采用k均值方法,为了保证量化精度,通常将特征码本维数n取为很大的值,该方法的计算复杂度为O(n2),计算效率很低。为了降低算法复杂度,提出了近似聚类方法(KD-tree和hierarchical kmeans),但又无法保证聚类的精度。
为了解决上述问题,文献[10]提出了一种VLAD局部聚类向量表示方法,该方法既可以降低特征码本量化的精度以实现降低计算复杂度,又加入了特征之间的空间关系以保证检索的准确率,VLAD构建过程如图3所示。
VLAD采用的是硬加权特征映射方法,即一个特征向量映射到与其距离最近的聚类中心。给定M个特征向量Φ=[r1,r2,…,rM],聚类为N个聚类中心的特征码本W=[w1,w2,…,wN],则特征向量rj与聚类中心wi的映射表示如公式(1)所示,d(rj,wi)表示特征向量rj和聚类中心wi的直方图距离。
(1)

图3 VLAD方法构建过程
特征直方图H(wi)则由特征向量rj映射到聚类中心wi的频次n(rj,wi)和聚类中心wi在图像I中出现的频次n(wi,I)计算得到,如公式(2)所示:
(2)
然而,两个极其相似的特征向量如果被映射给两个不同的聚类中心,则将被认为是完全不同的特征。
据文本检索的研究表明,单词存在多义性,即一个单词在不同的情况下有不同的含义。而硬加权特征映射方法则减少了特征单词多义性带来的泛化能力。为此,本文提出一种基于软加权的局部聚类向量表示方法。
采用一个距离向量V来取代传统的单个特征向量映射,距离向量V=[v1,v2,…,vs]表示为该特征向量与多个聚类中心之间的距离表示,s表示最近邻居聚类中心的个数。则VLAD中特征向量rj与聚类中心wi之间的映射关系n(rj,wi)如公式(3)所示:
(3)

(4)
使用软加权映射后,增大了特征直方图的维度(从J维变为J×s维),然而经过对特征直方图进行统计分析后发现,特征向量维度增加导致直方图大部分值为0,特征直方图很稀疏,这给后续的分类带来不必要的数据冗余。为此,采用主成分分析(PCA)对特征直方图进行降维,提取出数据中最重要的部分。降维步骤如下:
(1)将所有的特征直方图组成一个矩阵A∈RJ*s×d,d表示特征直方图的个数;
(2)计算矩阵A的均值和协方差矩阵;
(3)根据协方差矩阵计算出特征值和特征向量,将特征值按从大到小的顺序排列,选择特征值较大的特征向量组成主成分矩阵;
(4)将主成分矩阵与矩阵A相乘,得到降维后的特征直方图。
2 实验及讨论
为了验证本文提出的基于软加权的局部聚类向量表示方法的有效性,将该方法用于目标分类。实验数据集采用著名的Scene15数据集,Scene15数据集有15种类别的场景图像,平均每个类别约有300张图像,示例图像如图4所示。

图4 Scene15部分示例图像
本次实验的局部特征提取方法采用的是SIFT局部特征,聚类方法采用k均值聚类,分类器使用的是libsvm工具箱。实验的分类策略是每个类型抽取前100张图像用作训练,剩余的图像作为测试集。SVM分类器的分类参数采用交叉验证法获取,分类参数为c=5,g=0.5,核函数采用RBF径向基核函数,分类策略采用二分类法,即每个类别的分类器由多个二分类器组成,该分类器的分类结果由二分类器的投票结果决定,得票最多的分类器类型即是测试图像的类型。采用的分类评价准则为平均准确率(mean Average Precision, mAP)
2.1 不同参数下的软加权对聚类精度的影响
首先检验文中方法在不同参数下对分类准确率的影响,改变参数σ和s,获取不同参数下Scene15数据库分类实验的mAP值,结果如表1所示。当s>3后,平均准确率有所降低,这是因为过多的聚类中心映射反而导致特征匹配准确率的下降。因此后续的实验采用参数s=3,σ2=5 000。
图5是本文方法与硬加权映射方法在不同大小的特征码本下的mAP曲线图。从图中可以看出,本文方法相比较硬加权映射方法,mAP提高了约5%。随着特征码本不断增大,两种方法的mAP提高均有限,此时增加特征码本不仅对分类准确率没有提升,反而增加了特征匹配的错误率,因此选择合适大小的特征码本可以减少算法的计算复杂度。
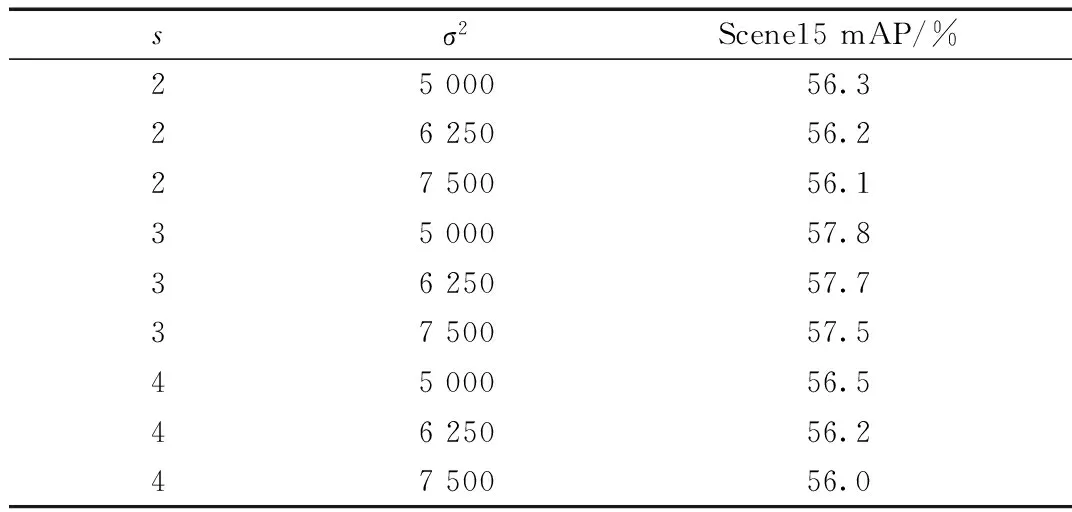
表1 不同参数的实验对比结果

图5 不同大小特征码本的mAP曲线
2.2 方法对比实验
为了更好地体现文中方法的性能,将文中方法与VLAD+硬加权映射方法进行对比,实验对比的结果如图6所示。

图6 不同图像数据库大小的mAP曲线
从上图的实验数据可以得出,随着图像数据库数量的不断增加,两种方法的mAP值均明显下降,也说明了无论是哪种方法,在大数据量的图像分类中其作用都相当有限。相比较硬加权映射方法,本文方法通过软加权映射,能更有效地提高特征匹配的鲁棒性和分类准确性。
3 结论
本文提出了一种基于软加权映射的局部聚类向量表示方法,首先用k均值算法将特征向量聚类为k个聚类中心,采用最近邻算法寻找最接近的s个聚类中心,通过特征向量与聚类中心之间的相似度和邻近程度构建软加权映射的局部聚类向量,然后统计特征直方图,最后通过主成分分析减少特征直方图维度。基于Scene15数据库的图像分类实验表明,文中提出的基于软加权映射的局部聚类向量表示方法与硬加权映射方法表示相比较,可以提高分类准确率。但文中方法仍存在不足之处,例如特征码本构建的准确率是本文方法的瓶颈,如何更加快速、准确地量化特征向量,是今后工作的重点。
[1] GRAUMAN K,DARRELL T. Pyramid match kernels: Discriminative classification with sets of image features[C]. Proceedings of the IEEE International Conference on Computer Vision, 2005:1458-1465.
[2] 王林灏, 宋臻毓. 基于SURF特征的人脸识别方法研究[J]. 微型机与应用, 2014, 33(7):31-34.
[3] 李倩影,陈锻生,吴扬扬. 基于图像距离匹配的人脸卡通化技术[J]. 微型机与应用, 2014, 33(10):44-46.
[4] LAZEBNIK S. Semi-local and global models for texture, object and scene recognition[D]. University of Illinois at Urbana Champaign, 2006.
[5] KIM G, FALOUTSOS C, HEBERT M. Unsupervised modeling and recognition of object categories with combination of visual contents and geometric similarity links[C]. In ACM International Conference on Multimedia Information Retrieval (ACM MIR), 2008: 419-426.
[6] LEORDEANU M, HEBERT M. A spectral technique for correspondence problems using pairwise constraints[C]. In ICCV, 2005: 1482-1489.
[7] LEORDEANU M, HEBERT M, SUKTHANKAR R. Beyond local appearance: Category recognition from pairwise interactions of simple features[C]. In CVPR, 2007:1-8.
[8] 刘扬闻, 霍宏, 方涛. 词包模型中视觉单词歧义性分析[J]. 计算机工程, 2011, 37(19):204-209.
[9] Tian Qi, Hua Gang, Huang Qingming, et al. Generating descriptive visual words and visual phrases for large-scale image applications[J]. IEEE Transactions on Image Processing, 2011, 20(9): 2664-2667.
[10] JEGOU H, DOUZE M, SCHMID C, et al. Aggregating local descriptors into a compact image representation[C]. IEEE Conference on Computer Vision Pattern Recognition, 2010: 3304-3311.
[11] KANUNGO G K, SINGH N, DASH J, et al. Mammogram image segmentation using hybridization of fuzzy clustering and optimization algorithms[C]. Processing in Intelligent Computing, Communication and Devices Advances in Intelligent Systems and Computing, 2015: 403-413.
[12] PHILBIN J, CHUM O, ISARD M, et al. Object retrieval with large vocabularies and fast spatial matching[C]. In Proc. CVPR, 2007:1-8.
[13] LI M J, NG M K, CHEUNG Y M, et al. Agglomerative fuzzy K-means clustering algorithm with selection of number of clusters[J]. IEEE Transactions on Knowledge and Data Engineering, 2008, 20(11): 1519-1534.
[14] KHANG S T, NOR A M I. Color image segmentation using histogram thresholding-fuzzy C-means hybrid approach[J]. Pattern Recognition, 2011, 44(1): 1-15.
Vector of locally aggregated descriptor based on soft assignment approach
Liu Qi1, Liang Peng2, Zhou Yishu1, Zhang Haitao1, Zhou Jianxiong1
(1. China Mobile South Base, Guangzhou 510640;2. School of Computer Science, Guangdong Polytechnic Normal University, Guangzhou 510665, China)
The traditional bag-of-words image classification approaches are based on feature vectors mapping to clustering centers by hard assignment, which will cause vision similarly features vectors being mapped to different clustering centers. In this case, we propose a novel vector of locally aggregated descriptor based on soft assignment approach. Firstly, we associate local features withsnearby cluster centers instead of its single nearest neighbor cluster depending on the distance between the features and the cell centers by usingk-means clustering algorithm. Then, we construct vector of locally aggregated descriptors by computing distances and similarity between feature vectors and clustering centers. Finally, we use PCA algorithm to reduce the dimension of feature histogram. The experimental results show that the proposed method can improve 5% accuracy rate.
soft assignment; image classification; feature dictionary; PCA
广东省自然科学基金博士启动项目(2015A030310340);广东省高等学校科技创新项目(2013KJCX0117)
TP391
A
1674-7720(2016)01-0038-04
刘琦,梁鹏, 周毅书,等.基于软加权映射的局部聚类向量表示方法[J].微型机与应用,2016,35(1):38-41.
2015-09-14)
刘琦(1984-),男,硕士,主要研究方向:大数据应用、云计算、图像处理。
梁鹏(1981-),通信作者,男,博士研究生,讲师,主要研究方向:图像处理、模式识别,E-mail:cs_phoenix_liang@163.com。
周毅书(1981-),男,硕士,主要研究方向:大数据应用、云计算、图像处理。
