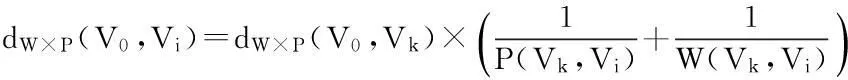带权不确定图的K最近邻查询算法
2016-03-17黄冬梅赵丹枫
黄冬梅 邓 斌 赵丹枫
(上海海洋大学信息学院 上海 201306)
带权不确定图的K最近邻查询算法
黄冬梅邓斌赵丹枫
(上海海洋大学信息学院上海 201306)
摘要社交、移动等复杂网络节点接入的不确定性给数据查询处理带来了新的挑战。K最近邻查询是社交、移动网络中经常用到的操作。已有的方法首先将网络映射为不确定图,然后,考虑边只含有概率信息的情况。讨论了K最近邻查询方法,没有考虑权重信息,具有局限性。针对这个问题,定义了带权不确定子图和ProWeiDist距离,兼顾权重和概率两个要素,提出了针对带权不确定图的K最近邻查询算法,并对算法进行优化。实验结果表明,SubDistK算法能有效地解决K最近邻查询问题。
关键词复杂网络不确定数据K最近邻查询带权不确定图子图
K-NEAREST NEIGHBOURS QUERY IN WEIGHTED UNCERTAIN GRAPH
Huang DongmeiDeng BinZhao Danfeng
(College of Information,Shanghai Ocean University,Shanghai 201306,China)
AbstractUncertainty of nodes accessing in complex social and mobile networks brings new challenge to data query and processing. K-nearest neighbours query is an operation frequently used over these complex networks. Existing methods map the network to uncertain graph first, and they consider the situation of containing the probability information only.Discussing the K-nearest neighbours query method but do not consider the weight information, therefore have limitations. In view of this problem, we defined the weighted uncertain subgraph and ProWeiDist distance, and proposed a K-nearest neighbours query algorithm targeted at the weighted uncertain graph by incorporating both probability and weight, and further optimised the algorithm. Experimental results demonstrated that the SubDistK algorithm can effectively solve K-Nearest neighbours query problem.
KeywordsComplex networkUncertain dataK-nearest neighbours queryWeighted uncertain graphSubgraph
0引言
快速发展的社交、移动等网络,由于噪声控制、隐私保护等原因,产生了大量的不确定数据[1,2]。针对不确定数据的建模有关系型数据[3]、流数据、半结构化数据、移动对象数据等[4]。在蛋白质网络、社交领域中,图模型更加适合不确定数据的建模研究[5,6]。其中,查询对象作为图的节点,对象之间的关系作为顶点之间的边,数据间的不确定性成为边的概率函数。在社交网络中[7],每位用户构成无向图的一个顶点,用户之间的关系构成顶点之间的边。在图中的每条边上加入概率信息构成不确定图,是不确定数据领域研究的一种常用方法。文献[8]提出不确定图的“可能世界”语义模型,不确定图中每条边都附带一个介于0和1之间的实数,以表示边存在的概率,边的存在概率是相互独立的。文献[9]基于不确定图数据库提出概率top-k子图匹配查询,在查询过程中,为附带概率信息的邻居子图设计索引结构,在索引结构的基础上进行查询。
K最近邻查询(KNN查询)作为一种重要的查询技术,旨在给定查询点、查询对象集合、范围约束集合以及方向,找到与查询点距离最近的k个对象[10-12]。针对不确定数据的K最近邻查询得到了国内外越来越多人的研究[13-20]。文献[13]针对蛋白质网络定义了三种衡量远近的距离概念,分别为中位距离、大多数距离和期望可信赖距离,应用KNN查询找到相互作用关系密切的蛋白质群。文献[14]在可能世界语义基础上,提出SimRank度量方法,解决由于不确定图动态演变导致的求k个近邻开销过大的问题。文献[15]定义最短距离概念,提出基于子图扩展的处理算法。
目前对不确定图的KNN查询研究还主要局限于不确定图只含有概率信息的情况,没有考虑到权重因素。在复杂网络如社交网络中,仅仅用传统的不确定图来定义是不恰当的。例如,交友网站的好友推荐系统中,用户代表图的节点,系统根据用户的籍贯、学校、职业、兴趣等因素评估用户间的亲密关系,这种好友关系存在的可能性是不确定的,在图中用顶点间边的概率表示。但是,用户在一段时间内的关注和联系次数是确定的,如果在推荐好友的过程中不考虑关注和联系次数,查询结果的准确性会受到影响。因此,需要对传统的不确定图进行改进,加入权重的概念。在社交领域中,体现为用户间一段时间的互动次数;在蛋白质交互领域中[13],体现为之间产生化学反应的次数。这样,不确定图中,边不仅含有关系代表不确定性的概率,还有可以确定的互动次数的权重。
本文针对带有权重的不确定图的查询问题,进行了以下三点研究:
1) 提出了一种带权不确定图上的KNN查询:GrapKDist查询;
2) 针对GrapKDist查询提出了SubDistK算法,并进行优化;
3) 进行实验证明查询算法的准确性和高效性。
1基本定义
定义1带权不确定图[13],是一个四元组G=(V,E,P,W),其中V是无向图的顶点集合,E=V×V ,为边的集合;P和W分别为边的概率和权重函数。∀e∈E,P(e)表示边e的概率,W(e)表示边e的权重。
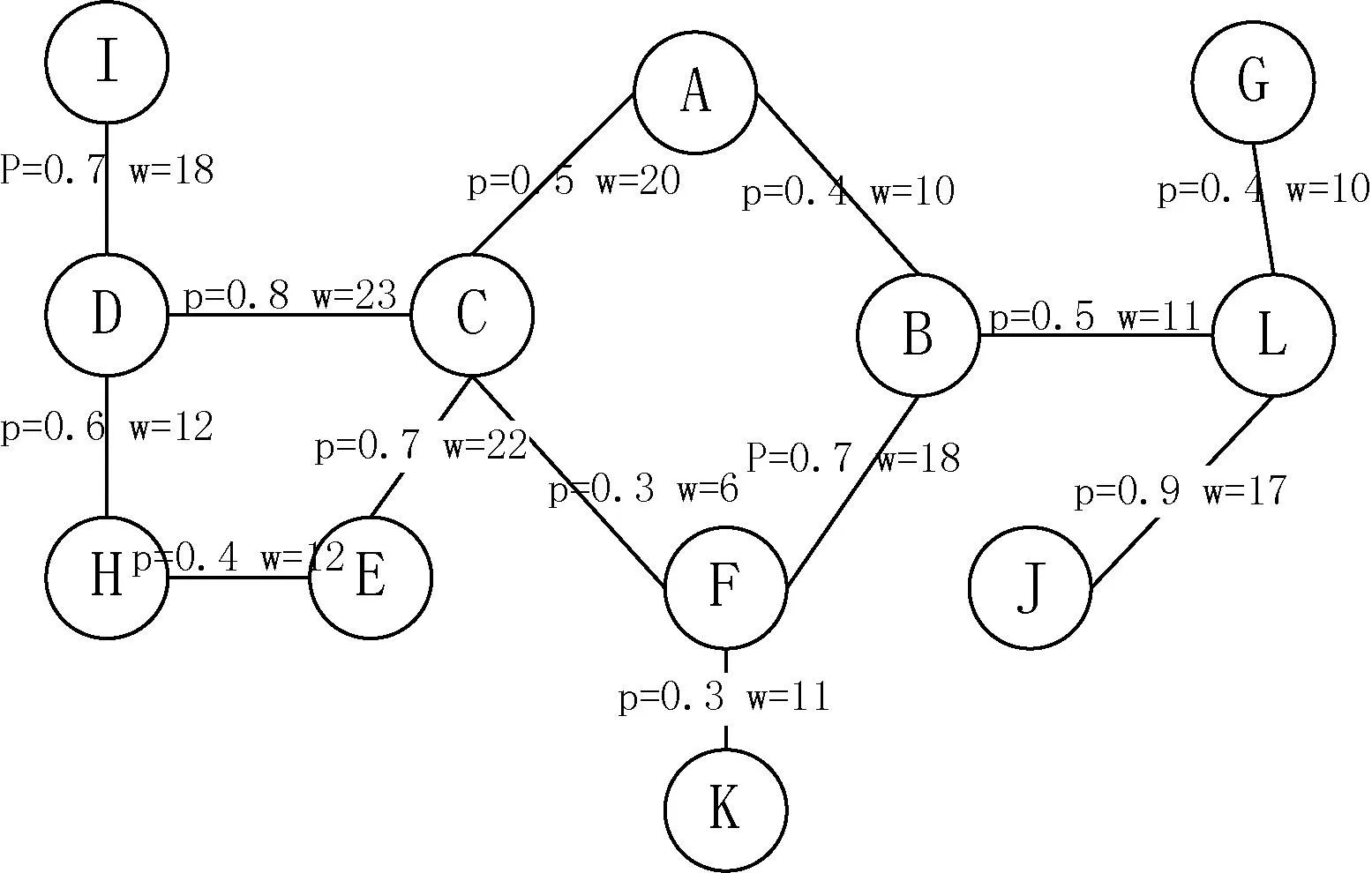
图1是一张带权不确定图,共有6个顶点和6条边,每条边附带一个概率值和权重值。每条边的概率和权重值相互独立。
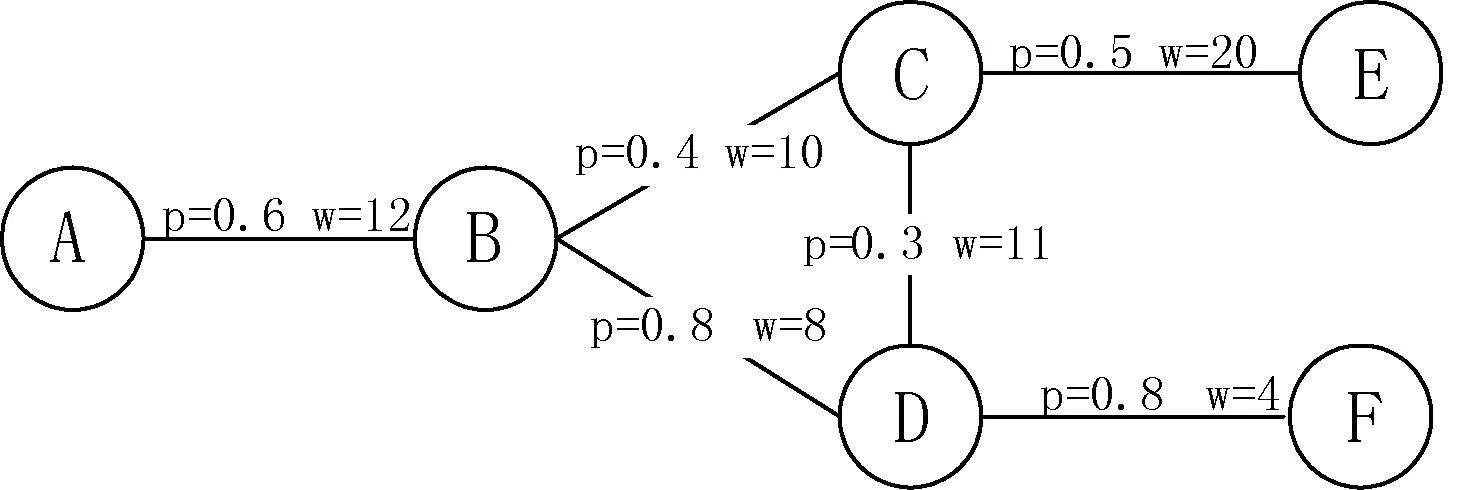
图1 带权不确定图
定义2路径步L(s, t),带权不确定图G=(V,E,P,W)中任意两个不同顶点s,t∈V,s与t的最短连接路径中顶点组成的集合Ew,L(s, t)=|Ew|-1。
图1中,L(A,C)=2,L(A,E)=3,在图2中,由于点F与A无连接路径,所以L(A,F)=∞。
定义3源顶点层σ,为一个顶点集合,给定带权不确定图G=(V,E,P,W)和查询源点V0,集合中任意两个不同顶点s,t∈V,满足L(V0, s)= L(V0, t)和|σ|<|E|。
图1中,查询源点为点A,点C与D到源点A的路径步都为2,所以同属一个源顶底层。同样,点E与F同属一个源顶点层。而点B与D属于不同的源顶点层。
定义4ProWeiDist距离,给定带权不确定图G=(V,E,P,W),查询源点V0,任意顶点Vi∈VV0,dw×p(V0,Vi)衡量顶点Vi与源点V0之间的远近关系。距离计算方法如下:
ifL(V0,Vi)=1
ifL(V0,Vi)>1&&L(Vk,Vi)=1
ifL(V0,Vi)=∞
dW×P(V0,Vi)=∞
(1)
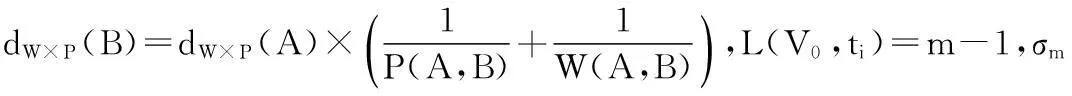
Ifm=0Rσm=1;
Ifm>0,V∈σm-1Vl∈σm
(2)
定义6带权不确定图的K最近邻查询:GrapKDist查询,给定一个带权不确定图G=(V,E,P,W),一个查询源点V0∈V,查询目标个数k≤|E|,找到一个拥有k个元素的顶点集合Sk(V0)={v1,…,vk},∀Vi∈Sk(V0),∀Vu∈ESk(V0),满足条件的dW×P(Vi)≤dW×P(Vu)。
2SubDistK算法
本节主要针对查询问题提出两个定理,并予以证明。依据定理设计查询方法,在方法基础上提出了两个查询算法。根据算法进行了实例运算。
2.1查询定理
定理1邻步定理,带权不确定图G=(V,E,P,W),查询源点V0,∀A,B∈V,且满足L(V0,B)=L(V0,A)+1,则存在dW×P(B)>dW×P(A)。
证明:
由式(1)和条件L(V0,B)=L(V0,A)+1可得:
(3)
由0 (4) 由式(4)可得: (5) 结合式(3)、式(5)可得: dW×P(B)>dW×P(A) (6) 定理1表明与查询源点的连接路径中,两个相邻顶点中路径步越长,则ProWeiDist距离越大。 定理2层次局部性定理,给定带权不确定图G=(V,E,P,W),查询源点V0,如果存在两个源顶点层dW×P(si)>dW×P(ti)与σ2,σ1={s1,s2,…,si,…,sn},σ2={t1,t2,…,ti,…,tm},满足条件L(V0,si)=L(V0,ti)+1,则存在R1>R2。 证明: 由条件L(V0,si)=L(V0,ti)+1和定理1可得: dW×P(si)>dW×P(ti) (7) 由式(7)可得: (8) 式(8)结合式(2)可得: R1>R2 层次局部性定理说明在带权不确定图中的两个相邻源顶点层,外层的层距离半径要大于里层。 2.2方法概述 带权不确定图中边同时含有权重和概率,邻接矩阵不适于作为存储结构,因此用邻接链表存储网络。把图中所有顶点按照与查询源点的路径步大小划分为不同的源顶点层。 根据层次局部性定理,与查询源点关系密切的点一般位于路径步较小的层次中。首先遍历离源点步长为1的层,对层中节点添加已访问标识;然后依次增加路径步值,直到已访问顶点总数与新源顶点层的和超过参数k;最后形成带权不确定子图,在子图中,根据访问标识计和顶点路径步的不同情况,调用式(1)计算ProWeiDist距离。依据距离大小选择k个节点作为最后的结果。 2.3算法步骤 算法1SubDistK 输入:带权不确定图G=(V,E,P,W) 查询源点V0∈V 参数k≤|E| 输出:结果集合Sk /*初始化路径步L和中间候选集合S*/ ① L=0,S=∅; /*初始化访问标识*/ ② L++; visited=false; /*遍历总顶点数为Sum*/ ③ 从V0遍历图G;Sum=0; /*即将访问的源顶点层σL和已遍历数不超过k*/ ④ while(|σL|+Sum /*根据路径步值来遍历节点*/ ⑤ for(Vi∈σL) /*顶点加入集合S*/ ⑥ insertTo(S,Vi); /*调用OpcWeiDist 算法*/ ⑦ OpcWeiDist ⑧ visited=true; ⑨ end for ⑩ /*增加路径步*/ /*S按照距离顶点进行排序*/ 算法2OpcWeiDist 输入:包含Vi,V0的带权不确定子图g 输出:dW×P(V0, Vi) /*计算路径步*/ ① P=L(V0, Vi) /*根据顶点间路径步值不同情况计算*/ ② switch(P) /*顶点直接相连*/ ③ case 1: /*顶点间接相连*/ ⑤ case n>1: /*递归调用OpcWeiDist 算法,L(Vk,Vi)=1*/ /*顶点不相连*/ ⑦ case ∞: ⑧ dW×P(V0, Vi)=∞; ⑨ end switch ⑩ Output(dW×P(V0, Vi)); KNN查询算法主要包括两个算法,SubDistK算法旨在给定带权不确定图,查找满足要求的k个节点。期间调用OpcWeiDist算法,计算被访问节点与查询源点的ProWeiDist距离。 SubDistK算法的时间复杂度为O(N3)。空间复杂度为O(N),OpcWeiDist算法的时间复杂度为O(N2)。 2.4实例分析 社交网络中用户关系网可以用带权不确定图表示:每一位用户构成图中的一个顶点;用户间的好友关系对应顶点之间的边,好友关系是相互的,所以边不带有方向;根据用户的个人信息如职业、兴趣爱好等不确定数据得出的好友关系成立的可能性表示为边的概率值;把用户在一段时间内相互关注和联系的次数作为边的权重值。图2是一张社交网络用户关系图,P表示用户间好友关系存在的概率,W表示用户在一个月内联络的次数。需要查找与用户A亲密度最高的4个用户。 图2 社交网络用户关系图 根据查询算法,与点A路径步为1的节点为B、C,构成第一个源顶点层σ1,dW×P(A,B)=2.60,dW×P(A,C)=2.05;由于|σ1|=2,小于查找目标数,因此扩大路径步值,遍历第二个源定点层中的节点D、F、L,dW×P(B,F)=1.49,dW×P(B,L)=2.09,dW×P(C,F)=3.50,dW×P(C,D)=1.29,经过两层遍历,中间集合S已经有5个元素,超过了查询参数k,因此终止遍历过程,获得一张带权不确定子图,如图3所示。计算集合中每个节点与源点的距离dW×P(A,B)=2.60,dW×P(A,C)=2.05,dW×P(A,D)=2.64,dW×P(A,F)有两个值,分别为7.18和3.87,取最小值3.87。dW×P(A,L)=5.43,选取距离值最小的四个节点,依次是C,B,D,F。因此得出结论与用户A关系最近的用户为用户C,B,D,F。 图3 社交网络用户关系子图 3算法优化 本节从空间复杂度和时间复杂度两个方面对算法进行优化,提出精简带权不确定子图,用实例进行优化分析,并给出优化后的算法。 3.1优化方法 在空间复杂度方面,带权不确定子图用来存储全部顶点和遍历经过的边,节约了其他无用边的存储空间。但是在复杂网络中,顶点的数量庞大。依据SubDistK算法,遍历过程中没有经过的节点没有成为查询目标的可能性,因此可以在子图中删除这些节点,极大地降低算法的空间复杂度。图3的所有节点中,只有B、C、D、F、L是候选节点,其他节点都可以省去,形成精简带权不确定子图,如图4所示。 图4 社交网络用户关系精简子图 在时间复杂度方面,由于查询执行时间主要在计算子图中顶点与查询源点的ProWeiDist距离,图的节点和边都比较复杂,会出现多个节点共用一条边的情况。在现实生活中,一个人成为多人的中间好友的情况是经常存在的。在距离计算中,减少遍历过程中重复边的计算,简化计算过程,有利于降低算法的时间复杂度。 图4中节点L、F在与A点的连接路径中共用了A-B边,节点D、F在与A点的连接路径中共用了A-C边。在计算L与A点的距离计算过程中,可以减少重复计算A-B边距离的步骤。同样dW×P(A,D)与dW×P(A,F)也可以利用之前计算得到的dW×P(A,C),在第二部分的算法示例中,第一层遍历的边的最可能权重距离在第二层遍历中都会用到,在应用式(1)时可以利用。 3.2优化算法 算法3ImpSubDistK 输入:带权不确定图G=(V,E,P,W) 查询源点V0∈V 参数k≤|E| 输出:结果集合Sk /*初始化精简子图g*和相邻点距离集合δ */ ① g*=(V*,E*,P*,W*);V*= ∅,E*=∅;δ =∅; ② L=0,S=∅; ③ L++; visited=false; Sum=0; ④ while(|σL|+Sum ⑤ for(Vi∈σL) ⑥ if(L==1) ⑦ 应用式(1);得dW*P(V0,Vi); ⑧ else if ⑨ ∃Vk(Vk∈σL-1&&L(Vk,Vi)==1) /*获得相邻边距离并导入到距离集合中*/ ⑩ dW×P(Vk,Vi),insertTo(δ,dW×P(Vk,Vi)); /*把已访问的节点信息加入到精简子图中*/ ImpSubDistK算法是在SubDistK算法的基础上进行优化,节省存储空间,提高查询效率。改进后的算法空间复杂度为O(log2N),时间复杂度为为O(N)。 4实验 实验部分利用社交网络真实数据构建带权不确定图,进行多组实验,从三个方面验证算法的准确度和效率,并分析实验结果。 4.1实验环境 为了证明SubDistK算法在GrapKDist查询过程中的准确性和高效性,本文以社交网络中用户关系网络为带权不确定图原型,设计多组对比实验,实验采用ego-Facebook社交网络数据。实验算法代码采用C++编程语言编写,程序运行在3.2 GHz的双核处理器上,实验平台为Win7 64位系统,4 GB内存。 实验数据为Facebook社交圈,包含4093个节点,88 234条边。该无向图出于隐私保护经过匿名化处理,用户ID用新的值代替,用户间的个人特征也经过预处理。例如“政治派别=民主党”也统一标识为“政治派别=A党”,概率描述用户间好友关系成立的可能性,在0~1之间;权重为两个用户一个月之内彼此在对方主页进行关注和留言的次数总和。 4.2实验方法 实验对比主要从3个方面来验证GrapKDist查询的准确率和效率:目标顶点数与查询中间候选集合的比例随参数k的变化、查询遍历的顶点数占总顶点数的比例随参数k的变化、查询执行时间随参数k的变化。 由于在查询过程中,遍历过的顶点会形成一个精简带权不确定子图,直到子图里的顶点数量超过要查询的顶点数k。并且目标顶点包含在这个中间候选集合中,如果候选集合的元素越多,在里面挑选目标对象的准确性会越高,目标对象被查询遗漏的可能性也就越低。这样,目标顶点数k与中间候选集合元素个数的比例可以衡量算法的准确度。如果,这个比例在随着参数k的变化一直保持在一个预期的阈值之下,那么说明查询算法的准确率达到我们的期望。查询过程中并不会遍历图中所有顶点,遍历的顶点越多,要计算的ProWeiDist距离的次数就越多;算法执行时间就越长,所耗费的计算开销就越大;另外查询如果能够以规模较小的中间候选集合就能找到目标顶点,就省去了遍历无效顶点的过程,减少了无效距离的计算,因此查询执行时间、查询顶点数、与查询顶点数占总顶点数的比例,这三个指标可以衡量查询算法的效率。 4.3结果分析 实验一只有参数k变化时,目标顶点数与中间候选集合元素个数的比例变化。 实验设定带权不确定图的规模不变,逐渐扩大查询目标个数k,从最初的查找4个对象顶点到最终的110个对象,前5次每次增加为4,后9次每次增加为10,总共测得14组比例数据,比例变化如图5所示。从图中我们可以得知,在目标顶点个数比较少的时候,遍历的层次没有变化,候选集合中包含了要查询的目标顶点,集合中的无效顶点逐渐减少,所以前期比例呈线性增长。当k逐渐增加时,以前遍历的层无法容纳所有的目标顶点,必须再向外访问新的顶点层,中间候选集合中的无效顶点瞬间增多,所以比例会突然出现比较大的下降。之后中间集合又会保持稳定,随着k增加,无效顶点较少,比例增加。整个过程中比例的变化趋势呈现锯齿状,线性增加然后大幅度下降再增加,周而复始。从实验结果得出,算法的准确率会不断变化,在k刚刚超出候选集合的顶点数即访问新一层时的准确率最高。 图5 随k增加的目标顶点与候选集合的比例 实验二只有参数k变化时,算法遍历顶点数以及与总顶点数比例的变化。 该实验设定图顶点总数不变,当逐渐增加查询目标数k时,计算算法遍历过的顶点数占总顶点数的比例。结果如图6所示,随着参数k的增加,访问的层次数也会增加,因此遍历的顶点数增加。比例线呈现“阶梯”状,这是因为在查询中,会以源点为“中心”向外层次性遍历顶点。在第一个顶点层中,虽然参数k增加了,但是访问的层次却依然保持不变,所以遍历的顶点数没有变化。随着k的进一步增加到16,访问层次扩大,中间候选集合的规模变大,所以遍历顶点数会进一步增多。从图中我们可以看到,刚开始时,顶点数比例值保持在一个非常低的水平,这是由于开始阶段查询目标数少,并且总顶点数量大。中间一段过程中,比例的增长相对平缓,并且低于0.1,当k增加到110时,比例也不会超过0.055。说明在执行算法查询过程中,从访问顶点数比例来看,算法效率都保持在一个非常好的效果。 图6 带权不确定图中访问顶点占总顶点数的比例 实验三只有参数k变化时,算法执行时间的变化。 查询的执行时间集中于顶点的遍历和ProWeiDist距离的计算方面上。而遍历的顶点数比例随参数k的变化在实验二已经得出。顶点之间距离的计算时间也与顶点数有关系。因此查询执行时间随参数值k的变化趋势会和顶点比例变化有联动效果。实验结果如图7所示,曲线为算法优化前后的执行时间,当参数k在16以内时,形成的带权不确定子图所含的边比较少,是一个稀疏图,执行时间因此相差不大。k增加时,随着遍历新的顶点层时,访问顶点数突然增多,需要进行的距离计算会大大增加,时间曲线有比较明显的增大。在同一层遍历顶点时,虽然增加k,但是时间增长平缓。当进一步增加查询目标数时,曲线又会有一个比较大的提高。当k数值增加到110以后,新访问的层所包含的顶点数量巨大,所包含的边非常多,形成了一个规模很大的带权不确定子图,因此执行时间有大幅度的增长。从实验结果得出,SubDistK算法在k在100以下时的运算时间比较小,且优化后的算法比优化前执行时间更短。 图7 SubDistK算法随参数k变化的执行时间 5结语 本文针对复杂网络中同时含有概率和权重的数据查询问题,通过带权不确定图对数据进行建模,定义了 GrapKDist查询,提出了SubDistK算法,通过三组实验证明了算法的有效性,解决了带权不确定图上的K最近邻查询问题。不足在于算法在k值在大于100时效率有所下降,这也是今后的研究方向。 参考文献 [1] Qiao Shaojie,Li Tianrui,Yang Yan.Managing uncertainty in web-based social networks[J].Intertional Journal of Uncertianty,Fuzziness and Knowledge-Based System,2012,20(1):147-158. [2] Zhu Fangzhou,Li Guohui,Zhao Xiaosong,et al.Probabilistic nearest neighbor queries of uncertain data via wireless data broadcast[J].Peer-to-Peer Networking and Applications,2013,6(4):363-379. [3] Lima D M,Rodrigues J F.DeGraph-based relational data visualization[C]//Proceedings of the International Conference on Information Visualisation,2013. [4] Wang Yijie,Li Xiaoyong,Qi Yafei,et al.Uncertain data queries Technologies[J].Journal of Computer Research and Development,2012,49(7):1460-1466. [5] Asthana S,King O D,Gibbons F D,et al.Predicting protein complex membership using probabilistic network reliability[J].Genome Research,2004,14(3):1170-1175. [6] Wang D Z,Michelakis E,Garofalakis M,et al.Bayesstore:managing large uncertain data repositories with probabilistic graphical models[J].Proc of the VLDB Endowment,2008,1(1):340-351. [7] Liben-Nowell D,Kleinberg J.The link prediction problem for social networks[J].Journal of the American Society for Information Science and Technology,2007,58(7):1019-1031. [8] Zhang Haijie,Jiang Shouxu,Zou Zhaonian.An efficient algorithm for top-k proximity query on uncertain graphs[J].Chinese Journal of Computers,2011,34(10):145-156. [9] Zhang Shuo,Gao Hong,Li Jianzhong,et al.Efficient query processing on uncertain graph databaes[J].Chinese Journal of Computers,2009,23(10):2066-2079. [10] Huang Jianhua,Ding Jianrui,Liu Jiafeng,et al.Citation-knn algorithm based on locally-weighting[J].Journal of Electronics and Information Technology,2013,35(3):627-632. [11] Zhang Shichao.Nearest neighbor selection for iteratively knn imputation[J].Journal of System and Software,2012,85(11):2541-2552. [12] Jiang Liangxiao,Cai Zhihua,Wang Dianhong.Bayesian citation-knn with distance weighting[J].International Journal of Machine Learning and Cybernetics,2014,5(2):193-199. [13] Potamias M,Bonchi F,Gionis A,et al.k-nearest neighbors in uncertain graphs[J].Proc of the VLDB Endowment,2010,3(1):997-1008. [14] Zhang Yinglong,Li Cuiping,Chen Hong,et al.K-nearest neighbors in uncertain graph[J].Journal of Computer Research and Development,2011,48(10):1850-1858. [15] Zhang Xu,He Xiangnan,Jin Cheqing,et al.Processing k-nearest neighbors query over uncertain graphs[J].Journal of Computer Research and Development,2010,3(1):997-1008. [16] Sun Yongjiao,Dong Han,Yuan Ye,et al.Knn queries method on uncertain data over P2P networks[J].Journal of Northeastern University,2012,33(5):632-635. [17] Bekales G,Soliman M A,Ilyas I F.Efficient search for the top-k probable nearest neighbors in uncertain databases[J].Proc of the VLDB Endowment,2008,1(1):326-339. [18] Kriegel H P,Kunath P,Renz M.Probabilistic nearest-neighbor query on uncertain objects[C]//Proc of DASFAA.Berlin:Springer,2007:809-824. [19] Lian X,Chen L.Efficient processing of probabilistic reverse nearest neighbor queries over uncertain data[J].The VLDB Journal,2009,18(3):787-808. [20] Cheng R,Chen L,Chen J,et al.evaluating probability threshold k-nearest-neighbor queries over uncertain data[C]//Proc of Int on Extending Database Technology:Advances in Database Technology(EDBT).New York: ACM,2009:672-683. 中图分类号TP311 文献标识码A DOI:10.3969/j.issn.1000-386x.2016.02.050 收稿日期:2014-06-26。国家自然科学基金项目(61272098)。黄冬梅,教授,主研领域:海洋大数据,WebGis等。邓斌,硕士生。赵丹枫,讲师。