面向大数据处理的Hadoop与MongoDB整合技术研究
2016-03-17曾强缪力秦拯
曾 强 缪 力 秦 拯
(湖南大学信息科学与工程学院 湖南 长沙 410086)
面向大数据处理的Hadoop与MongoDB整合技术研究
曾强缪力秦拯
(湖南大学信息科学与工程学院湖南 长沙 410086)
摘要随着数据种类的增多和数据规模的增大,NoSQL技术与MapReduce并行处理思想越来越受到重视。MongoDB作为NoSQL数据库的典型代表,支持对海量数据进行索引和查询,但MongoDB提供的MapReduce还不能满足复杂的数据分析和计算。而Hadoop虽然提供了强大的MapReduce并行计算框架,却在实时服务方面存在较高延时。针对这种情况,综合考虑扩展性,数据本地化,I/O性能等因素,提出并实现Hadoop与MongoDB四种不同的整合方案。通过设计三种具有代表性的应用作为性能的测量基准,对不同的整合方案进行性能对比实验,得出不同应用场景下的最优整合方案。实验表明,在MongoDB与Hadoop的折衷使用过程中,若对不同的应用采用合理的方案,性能最多可以提高3倍。
关键词整合MongoDBHadoop大数据
ON MONGODB AND HADOOP INTEGRATION TECHNOLOGY FOR BIG DATA PROCESSING
Zeng QiangMiao LiQin Zheng
(College of Computer Science and Electronic Engineering,Hunan University,Changsha 410086,Hunan,China)
AbstractWith the exponential growth in data variety and data volumes, NoSQL technology and MapReduce for scalable parallel analysis have garnered a lot of attentions. MongoDB, as a typical representative of NoSQL database, supports both scalable index and flexible query for massive data, but the MapReduce provided by MongoDB cannot meet the need of complex data analysis and computation. While Hadoop offers a powerful MapReduce framework for parallel computing, it performs high latency in real-time services. In view of this, we propose and implement four different integration schemes of Hadoop and MongoDB by considering comprehensively the factors of scalability, data locality and I/O performance. The optimal integration schemes under different scenarios are derived by designing three kinds of representative applications as the measuring benchmarks of performances and by performance contrastive experiments on different integration schemes. Experiments show that in the process of trade-off use of MongoDB and Hadoop, if reasonable integration schemes are applied to different applications, the performance can be improved up to 3 times.
KeywordsIntegrationMongoDBHadoopBig data
0引言
随着互联网的发展和科技的进步,不论企业,政府,科研机构还是个人,所产生的数据量越来越大。面对种类繁多的半结构化和非结构化海量数据,显然,传统的数据分析和存储技术已力不从心。在大数据时代的背景下,海量数据的存储和分析计算技术应运而生。对于海量数据的处理,应包括三个部分:存储、计算和查询。而要同时实现存储和计算的可扩展性以及查询的高效性成为大数据处理面临的一个挑战。
现今涌现出的很多云计算和云存储技术在不同程度上满足了大数据的处理要求。MapReduce[1]框架的提出,将庞大的计算任务分布在成千上万的廉价的无共享低端服务器上并行运行,从而大大提高了运行效率,Hadoop[2,3]作为MapReduce的一个开源实现,具有良好的扩展性和容错性,并在Facebook、Yahoo等公司得到了广泛的应用。Hadoop的设计初衷是针对大规模数据的批量处理,需要对整个数据集进行扫描,也因此Hadoop对于小范围内查询、实时插入等服务存在较高延时。而NoSQL[4]数据库的诞生,打破了传统数据库的关系型数据模式,能够以键值对的形式轻松处理和存储半结构化海量数据,在满足分布式存储和高可扩展性的前提下,还支持索引的建立,因而能够实现对数据的快速定位和高性能查询。在众多的NoSQL数据库中,像DynamoDB[5]、MongoDB[6,7]、BigTable[8]和Cassandra[9]专门针对大数据存储而设计,通过横向扩展的方式将服务部署在廉价的服务器上,相比传统数据库通过硬件升级的方式提高数据库性能和存储能力,大大节约了成本。由于MapReduce的流行,NoSQL数据库也纷纷引入MapReduce模型作为其聚合计算强有力的一个工具,其中的典型代表是MongoDB,MongoDB通过内置的MapReduce处理一些简单的聚合计算,但还不能满足较为复杂的数据分析。因此,结合MongoDB强大的存储能力和Hadoop MapReduce分析计算能力,搭建一个高可用、高性能的云计算和云存储平台成为本文的一个研究重点。
关于单方面评估和提高MapReduce和MongoDB性能的研究有很多[10-14],而关于MongoDB与MapReduce的整合应用的研究相对较少。文献[15]通过搭建MongoDB集群对网络日志进行分析,对于网络日志的聚合计算采用的是MongoDB内置的MapReduce,由于MongoDB内置MapReduce采用JavaScript编写且采用SpiderMonkey[16]引擎,与Hadoop MapReduce相比存在性能低下的问题[17]。文献[18]描述了MongoDB中MapReduce算法如何提高大数据的处理效率,但并没有提供量化的结果。本文通过MongoDB服务器和Hadoop计算节点重叠部署的方式实现数据本地化,在实现Hadoop与MongoDB的整合应用的基础上,通过配置不同的整合方案来应对不同应用的数据处理,并通过实验对比的方式对二者在不同方案下的性能进行评估和分析,得出Hadoop与MongoDB在不同应用下的折衷使用策略和最优整合方案。
1基于MongoDB和Hadoop的整合方案
1.1Hadoop
Hadoop MapReduce直接诞生于搜索领域,能够将庞大的计算量分布到集群的各个节点进行并行处理。它主要由两部分组成:编程模型和运行时环境。其中编程模型为用户提供了可编程组件,分别是InputFormat、Mapper、Partitioner、Reducer和OutputFormat,运行时环境则将用户MapReduce程序部署到集群的各个节点上,并通过各种机制保证其成功运行。Hadoop MapReduce处理的数据位于底层分布式文件系统HDFS,HDFS将用户的文件切分成若干个固定大小的Block存储到不同节点上,并且不同节点上保存同一Block的多个副本以实现容错。Mapreduce的执行过程分为分为两个阶段:Map和Reduce,每个Map任务以key-value键值对的形式,从分布式文件系统HDFS中读取相关的数据,再经过用户定义的Map程序,并将产生的结果合并排序,生成新的key-value键值对,将其保存到本地磁盘等待Reduce的读取。Reduce任务主要根据键值从Map读取其产生的中间结果,合并排序后交由用户定义的Reduce程序,最后将产生的结果保存至HDFS文件系统中。
1.2MongoDB
MongoDB是10gen公司开发的一个高性能,开源,无模式的文档型数据库,他是最像传统关系型数据库的NoSQL数据库,实现了关系数据库的很多特点,比如排序、二级索引、范围查询、MongoDB是面向文档型的数据库,其中每个文档(Document)相当于关系型数据库中的一条记录,每个集合(Collection)对应于关系型数据库中的一张表,每个文档中的数据是以key-value对的形式自由组织,他支持的数据结构非常松散,是类似Json的Bson格式,因此可以存储比较复杂的数据类型。图1展示了MongoDB的数据组织结构。
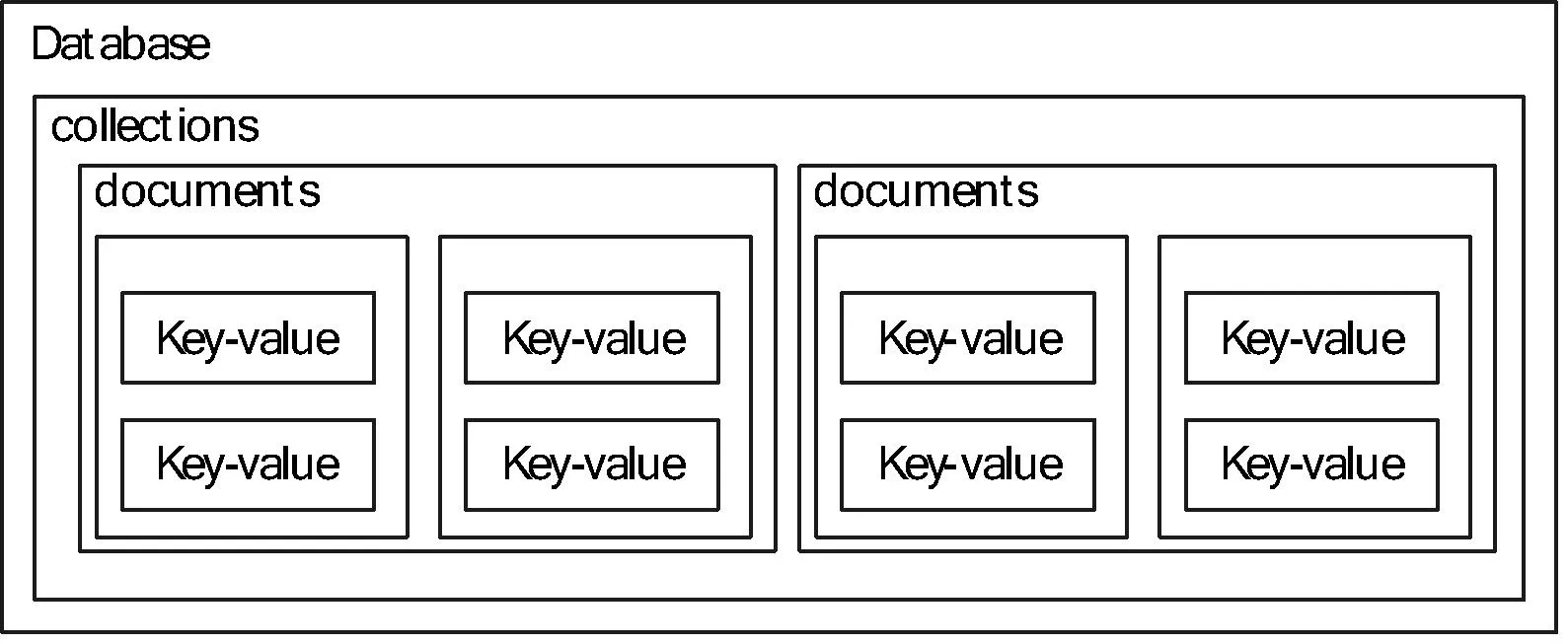
图1 MongoDB数据组织结构
同时Mongodb也是一个基于分布式存储的数据库。MongoDB本身实现的自动分片机制能够将大数据集平均分配到多个节点存储。在实际的开发当中,一个简单的分片集群由三部分组成:分片、配置服务器、路由服务器。其中分片存储了实际的数据,这些数据以固定大小的数据块(Chunck)组织,每个分片都是一个副本集,副本集是自带故障转移功能的主从复制。客户端访问路由节点来进行数据读写,配置服务器保存了两个映射关系,一个是键值的区间对应哪一个Chunk的映射关系,另一个是Chunk存在哪一个分片节点的映射关系。路由节点通过配置服务器获取数据信息,通过这些信息,找到真正存放数据的分片节点进行对应操作,路由节点还会在写操作时判断当前Chunk是否超出限定大小。如果超出,就分列成两个Chunk、Mongodb分片集群结构如图2所示。

图2 MongoDB简单分片集群
1.3整合框架
Hadoop擅长对海量数据进行分析计算,MongoDB主要用于大数据的分布式存储和查询。通过二者的整合可以同时满足海量数据的查询,存储和计算要求。具体整合框架如图3所示。

图3 整合框架Mongo-Hadoop
对于MongoDB和Hadoop的整合用到了中间件:MongoDB Hadoop Connector、MongoDB Hadoop Connector是10gen公司提供的一个免费的开源插件,该插件的作用是将MongoDB代替Hadoop HDFS作为Hadoop MapReduce的数据源,在分布式集群中,集合被分割成固定大小的块(64 MB)存储在MongoDB分片上,Hadoop Mappers通过路由节点并行读取块并解析数据,再通过Reducer合并将结果回写到MongoDB。在整个数据处理过程中,Hadoop HDFS并没有参与进来,为提高Hadoop与MongoDB二者整合的灵活性以及对数据处理的高效性。本文针对Mogodb Hadoop Connector做了一些改进和扩展:在该Connector中添加InputFormat和OutputFormat两个类。允许HDFS、MongoDB作为Hadoop MapReduce的可选输入源或输出目标。
从图3可以看出,基于Hadoop和MongoDB的整合框架Mongo-Hadoop由三部分组成:
Storage System:该部分包括HDFS和MongoDB,用于海量数据存储,其中MonogDB可对数据进行索引和查询。
Mongo-hadoop-connector:该Connector主要包括四个类,其中InputFormat、OutputFormat负责HDFS中数据的读取与写入,MongoInput Format、Mongo Output Format负责MongoDB中数据的读取与写入。对MongoDB与Hadoop的整合可通过配置的方式提供四种方案:
方案一从HDFS读数据,将计算结果写入HDFS。
方案二从HDFS读数据,将计算结果写入MongoDB。
方案三从MongoDB读数据,将计算结果写入HDFS。
方案四从MongoDB读数据,将计算结果写入MongoDB。
Hadoop MapReduce Framework:该部分用于对MongoDB或HDFS中数据的并行分析计算。
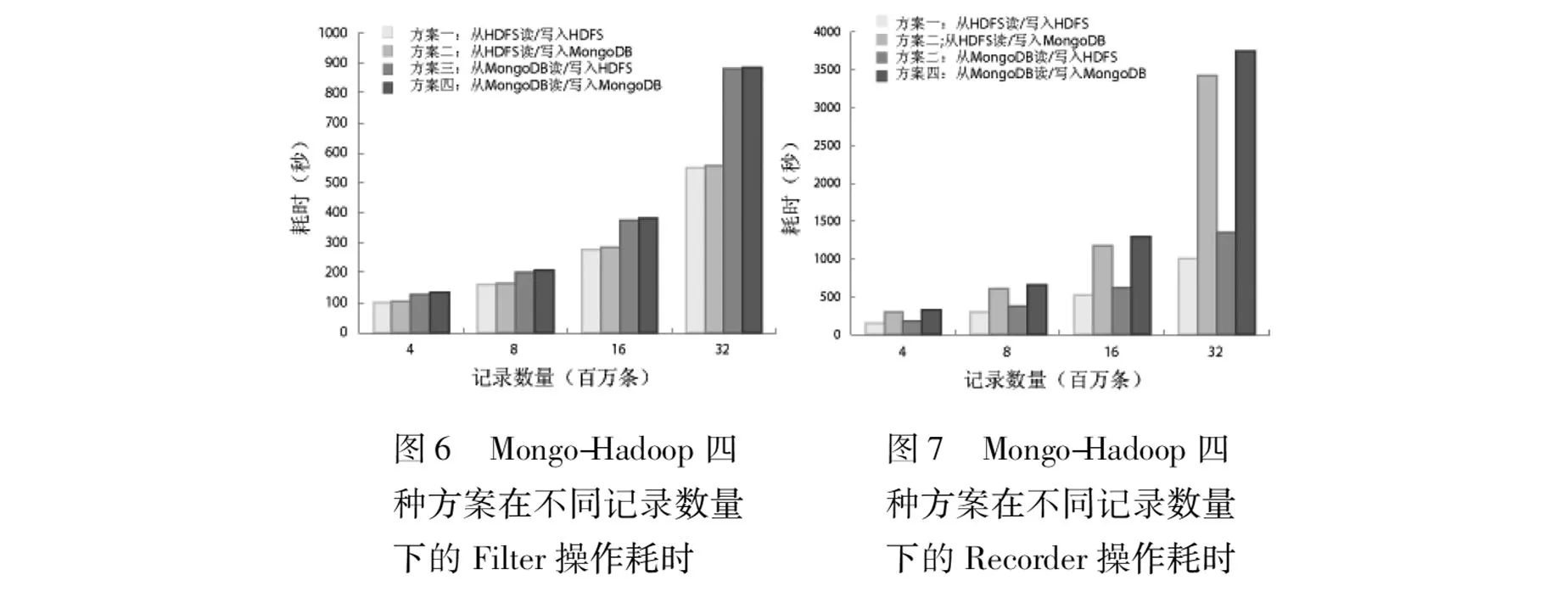
Hadoop MapReduce与底层存储系统的交互只包含读取数据和写入数据。因此本文从以下三种应用场合对不同的方案进行了性能评估和测试:
Read = Write,读写大致相等。
Read>>Write,读远远大于写。
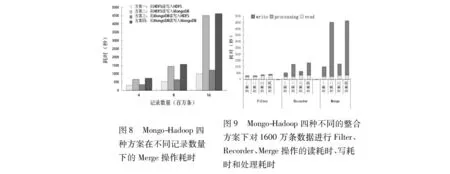
Read< 1.4集群部署策略 整合MongoDB与Hadoop应对大规模数据的查询和分析计算,集群部署显得尤为重要。本文主要从两个角度出发实现对Mongo-Hadoop集群的部署: (1) MongoDB分片读写分离。MongoDB分片读写分离通过副本集来实现,在MongoDB集群中一个副本集一般包括3台机器,其中一台作主服务器,默认承担数据的全部读写操作。另外两台作为从服务器,从服务器在后台实现对主服务器数据的同步,作为主服务器的备份。在本文中,为简单起见,在一个副本集中只设计了两台机器,一台主服务器,一台从服务器。通过参数设置,主服务器只承担写操作,而读则优先选择从服务器,用以分担主服务器高强度的写压力。 (2) 数据本地化。实现数据本地化是MapReduce框架设计的一个核心部分。数据本地化的思想是将数据块放置在计算节点的本地磁盘上,因而在需要对数据进行计算时实现对数据的本地获取,避免由于网络传输造成的性能下降。在本文实现的Mongo-Hadoop集群中,数据本地化的实现是通过Hadoop TaskTrackers和DataNodes与MongoDB分片服务器的重叠部署来实现。但需要注意的是要同时实现数据本地化和MongoDB分片读写分离,必须将Hadoop TaskTrackers和DataNodes部署在MongoDB分片的从节点上。这样MapReduce可以从本地MongoDB从节点读取数据,数据经处理后再写入MongoDB主服务器。 2实验 2.1实验数据与实验基准 本文采用的实验测试数据为某国历年航班数据[19],该数据每条记录拥有29个属性包括起飞时间、起飞地点、目的地、到达时间、航班号等。在MongoDB中每条记录约500个字节。在Mongo-Hadoop中,通过对航班数据进行三种具有代表性的应用来模拟不同的场景:1 Filter,统计各个地方某一时间段的航班总数,该操作对数据集进行统计,得到结果远远小于输入,用来模拟Read >> Write的应用场景。2 Recorder,将航班数据中年月日的分隔符“,”改为“-”,如“2000,12,05”改为“2000-12-05”,其余数据保持不变,用来模拟Read==Write的应用场景。3 Merge,每条记录添加一个备注属性,该属性的值为一个随机字符串,大小为1000字节,用来模拟Read << Write的应用场景。 2.2实验配置 实验中使用的节点配置为Pentium(R) Duo-Core CPU T6300,内存4 GB,硬盘30 GB,而运行的操作系统为Ubuntu 12.04.2 LTS(64位)。节点间通过快速以太网相连。HDFS采用默认配置,块大小设置为64 MB,副本因数设置为2。实验采用的总节点数为19,其中包括NameNode,路由器,配置服务器各1个,Hadoop DataNode与TaskTrack与MongoDB分片重叠部署的节点有8个,MongoDB分片从节点8个。 2.3实验结果与分析 2.3.1数据加载与导出性能 图4、图5中可以看出HDFS数据加载与导出性能要明显优于MongoDB,导致该性能差异的原因为,HDFS不需要读取数据,然后进行解析,再进行序列化以数据库内部格式存入磁盘,数据的加载与导出操作仅仅是文件的复制或移动。HDFS数据的导入导出性能与数据的大小大致呈正比,基本上稳定在25 000条记录/秒左右,而MongoDB的数据导入导出性能则随着数据集的增大,其导入导出速率都有所下降,导入速率表现得尤为明显,当数据为两百万的时候其速率为8620条记录/秒,随着数据集增大到800万时,其速率下降到3532条记录/秒,其原因为MongoDB对数据的存储采用内存映射机制,当数据量增大,内存占用过大,数据导致导入导出速率下降。 图4 HDFS、MongoDB加载不同记录数量耗时对比 图5 HDFS、MongoDB导出不同记录数量耗时对比 2.3.2不同应用在不同整合方案下的性能对比分析 图6展示了当输入远大于输出时(约1万∶1)数据的处理情况,如图可知,处理400万条记录时,方案一比方案四快了0.3倍,而当记录达到3200万条时,快了0.6倍,随着记录的增大,该差距也逐渐增大。方案三与方案一相比,只是数据的输入源不同,后者比前者平均快了0.4倍,因此可以判断,从MongoDB读取数据要比从HDFS中读取数据开销大。对于方案一与方案二以及方案三与方案四,其性能相差很小,原因是输出数据非常小,数据写入位置对性能造成的影响极小。 图7展示了当输入等于输出的数据处理情况,其中在不同数据集下方案一比方案四快了1.1到2.7倍,比方案二快了0.9到2.3倍,而相比方案三只快了0.16到0.3倍,与图6不同,在同样的输入下输出结果的写入位置对性能造成较大的影响,因此对同样的数据集作同样的处理但在不同的Mongo-Hadoop整合方案下,方案三在性能上最为接近方案一。 图8展示了写密集型的作业,输出为输入的四倍。从图中可以看出,数据的写入位置对性能起了决定性的作用,将数据写入到HDFS比将数据写入到MongoDB整体性能平均将近快了5倍。因此,相比HDFS来说将数据写入MongoDB开销非常大。 在图9中,由于3种不同类型的操作是对同一数据集作不同的处理,因此图中显示读取数据集所花费的时间也一样。而数据处理所花费的时间只占整个开销中很小的一部分,因此写是引起性能差异的主要因素。对比Filter操作和Merge操作,处理1600万条数据,采用方案四,读密集型作业比写密集型作业在性能上高出了11倍。而采用方案三,在性能上则只高出3.3倍。在Recorder操作中,将数据写入MongoDB的开销是写入HDFS的4倍,在Merge操作中达到了6.2倍。 图9中的方案一表示从HDFS读/写入HDFS,方案二表示从HDFS读/写入MongoDB,方案三表示从MongoDB读/写入HDFS,方案四表示从MongoDB读/写入MongoDB。 2.3.3不同整合方案配置下的可扩展性测试 从图10可以看出,当集群规模从4核扩展到8核时,方案一、方案二、方案三、方案四在整体性能上分别提高了94%、77%、99%、89%,从图中可以明显看出,各个方案下的读写时间和处理时间都接近减半。而从8核扩展到16核时,各方案下的性能分别只提高了59%、14%、55%、15%,其中数据写入MongoDB的性能仅仅提高10%~15%,而从MongoDB读取数据的性能提高55%~60%。集群规模为4核时,对1600万条数据作不同的处理,通过对CPU和内存的监控发现,其利用率都达到了90%~98%,如前所述,Mongo-Hadoop采用的是Hadoop TaskTracker、DataNode与MongoDB服务器重叠部署的方式来实现,因而在CPU和内存紧张的情况下,容易形成彼此之间对内存和CPU的竞争,从而使性能降低,当集群扩展到8核时,内存和CPU的利用率下降到55%~60%,因而缓解了CPU和内存的制约,性能获得非常大的提高,由此可知对于内存和CPU的占用率过大造成的性能损失,Mongo-Hadoop可以很容易地通过横向扩展添加节点的方式来弥补。集群规模从8核扩展到16核,从上面分析得知其性能提高得相对较少,原因是充足CPU和内存对性能的制约大大减少。在CPU和内存充足的情况下,方案四通过扩大集群规模能够显著减少读取时间,其原因是随着集群规模的增大,拥有更多的Map并发读取本地MongoDB中的数据。而对于写的情况,发生在Reduce阶段,虽然扩大集群规模同样能过增加Reduce的并发数,但是将数据分发到MongoDB各个分片服务器占用了很大的开销,因此写性能的提高相对很少。 图10中的方案一表示从HDFS读/写入HDFS,方案二表示从HDFS读/写入MongoDB,方案三表示从MongoDB读/写入HDFS,方案四表示从MongoDB读/写入MongoDB。 图10 Mongo-Hadoop进行Recorder操作的可扩展性测试 2.3.4整合方案的折衷使用 由上分析可知,将MongoDB代替HDFS成为数据的输入源和输出目标,都会引起读写性能的下降,而写表现得最为明显。在CPU和内存充足的情况下,通过横向扩展的方式可以显著提高数据的读取性能,但对于写性能的提高相对很少。由前面实验推导,在利用Mongo-Hadoop对数据进行处理时,可得出以下结论:若采用方案一,对MongoDB中的数据进行处理时,必须先将数据导出到本地,然后再上传到HDFS,经Hadoop处理后,再将结果从HDFS导入到MongoDB,这样,数据的导入导出将引起巨大的开销,因此该方案下对MongoDB中的数据作处理性能最低。若采用方案二,对于非MongoDB中的数据,或该数据集已存在于HDFS,需要对该数据进行读密集型操作且数据处理结果需要灵活查询时,该配置提供了最优性能,原因是数据导入HDFS性能比MongoDB快了4~5倍,且Mongo-Hadoop从HDFS读取数据要优于从MongoDB读取数据。若采用方案三,对于已经存在于MongoDB中的数据进行写密集型操作,且结果集需要MapReduce作后续处理时,该方案提供了最优性能。原因是将相对较大的结果集直接写入MongoDB带来的开销巨大。若采用方案四,对于已经存在于MongoDB中的数据,需要对数据进行统计和聚合计算且对结果集进行灵活查询时,该方案提供了最优性能。其原因是对于读密集型操作,Mongo-Hadoop具备良好的扩展性,能够快捷读取MongoDB分片中的数据经MapReduce处理后将相对较小的结果集轻松写回到MongoDB。 3结语 整合MongoDB与Hadoop应对大型数据集的处理,使得MongoDB可以利用Hadoop MapRecue对自身数据进行复杂的分析计算,同时MongoDB可以对结果进行检索和查询。将MongoDB代替Hadoop HDFS作为Hadoop MapReduce的数据输入源和输出目标,针对不同的应用,其性能都会有所下降,对于读密集型的操作,MongoDB作为数据源的性能略低于HDFS,其性能大致相当,但对于写密集型作业,其性能差异表现得非常明显。针对此种情况,本文将HDFS,MongoDB配置成Hadoop MapReduce的可选输入源和输出目标,对不同的应用可以通过灵活配置来获取最优性能。 参考文献 [1] Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].CACM,2008,51(1):107-113. [2] Apache Hadoop[EB/OL].(2014-06-30).http://hadoop.apache.org. [3] White T.Hadoop:the Definitive Guide[M].California:O’Reilly Media,2012. [4] Pokorny J.Nosql databases:a step to database scalability in web environment[J].International Journal of Web Information Systems,2013,9(1):69-82. [5] Amazon DynamoDB[EB/OL].http://aws.amazon.com/dynamodb/. [6] MongoDB[EB/OL].http://www.mongodb.org. [7] Plugge E,Hawkins T,Membrey P.The Definitive Guide to MongoDB:the NoSQL Database for Cloud and Desktop Computing[M].Berkely,CA,USA:Apress,2010. [8] Chang F,Dean J,Ghemawat S,et al.Bigtable:A distributed storage system for structured data[J].ACM Transactions on Computer Systems,2008,26(2):4. [9] Dede E,Sendir B,Kuzlu P,et al.An evaluation of Cassandra for Hadoop[C]//Cloud Computing (CLOUD),2013 IEEE Sixth International Conference on. IEEE,2013:494-501. [10] Fadika Z,Dede E,Govindaraju M,et al.Benchmarking MapReduce implementations for application usage scenarios[C]//Grid Computing (GRID),2011 12th IEEE/ACM International Conference on.IEEE,2011:90-97. [11] Liu Yimeng,Wang Yizhi,Jin Yi.Research on the improvement of MongoDB auto-sharding in cloud environment[C]//Computer Science & Education (ICCSE),2012 7th International Conference on.IEEE,2012:851-854. [12] Fadika Z,Dede E,Hartog J,et al.MARLA:MapReduce for heterogeneous clusters[C]//Cluster,Cloud and Grid Computing (CCGrid),2012 12th IEEE/ACM International Symposium on.IEEE,2012:49-56. [13] Fadika Z,Govindaraju M.DELMA:dynamically elastic MapReduce framework for CPU-intensive applications.Cluster[C]//Cloud and Grid Computing (CCGrid),2011 11th IEEE/ACM International Symposium on.IEEE,2011:454-463. [14] Fadika Z,Govindaraju M,Canon R,et al.Evaluating Hadoop for data-intensive scientific operations[C]//Cloud Computing (CLOUD),2012 IEEE 5th International Conference on.IEEE,2012:67-74. [15] Wei Jianwen,Zhao Yusu,Jiang Kaida,et al.Analysis farm:a cloud-based scalable aggregation and query platform for network log analysis[C]//Cloud and Service Computing (CSC),2011 International Conference on.IEEE,2011:354-359. [16] SpiderMonkey[EB/OL].https://developer.mozilla.org/en/SpiderMonkey. [17] Dede E,Govindaraju M,Gunter D,et al.Performance evaluation of a MongoDB and Hadoop platform for scientific data analysis[C]//Proceedings of the 4th ACM workshop on Scientific cloud computing,2013:13-20. [18] Bonnet L,Laurent A,Sala M,et al.Reduce,you say:what NoSQL can do for data aggregation and BI in large repositories[C]//Database and Expert Systems Applications (DEXA),2011 22nd International Workshop on.IEEE,2011:483-488. [19] Hacking Airline DataSet with H2O[EB/OL].(2013-04-12).https://github.com/0xdata/po/wiki/Hacking-Airline-DataSet-with-H2O. 中图分类号TP311.5 文献标识码A DOI:10.3969/j.issn.1000-386x.2016.02.005 收稿日期:2014-06-20。国家自然科学基金项目(61272546)。曾强,硕士生,主研领域:分布式,云计算。缪力,副教授。秦拯,教授。