一种YARN和Spark框架的网格聚类方法
2016-02-13王志刚陈名辉赵振凯
王志刚,陈名辉,赵振凯
(湖南师范大学数学与计算机学院,长沙 410081)
一种YARN和Spark框架的网格聚类方法
王志刚,陈名辉,赵振凯
(湖南师范大学数学与计算机学院,长沙 410081)
分布式计算为大数据的处理提供一种新的平台,能有效提升算法的执行速度。在DBSCAN算法基础上提出一种数据分网格算法,该算法将每个分区上的数据集划分成以Eps半径为边长的单元格数据块,将查找Eps邻域的范围缩小到数据对象的八个相邻单元格之内,从而提高查找Eps邻域的速度及聚类速度,具有较好的加速比和扩展率。同时还优化分区聚类合并方法。
分布式计算;DBSCAN;Spark;YARN;Tachyon
0 引言
分布式计算平台具有易于扩展、学习、使用和部署等特点,是一种简洁抽象的并行编程环境。用户只需要关注解决自己的并行计算任务,而不需关注细节实现。
加州伯克利大学AMP实验室最先推出Spark,但直到2014年才开始大幅度发展。目前,较流行运用Hadoop的MapReduce[1]实现并行数据挖掘,算法K-means和DBSCAN是其主要代表。文献[2]提出了基于Hadoop的K-means、DBSCAN、近邻传播算法和谱聚类算法的MapReduce编辑模型。文献[3]提出了DBSCAN增量聚类算法的MapReduce实现。文献[4]提出了网格控制因子的DBSCAN聚类算法,并用MapReduce对聚类算法进行封装,提高了算法的效率。文献[5]利用数据分箱和网格划分技术,通过对核心点生成无向图后进行广度优先搜索生成聚类,是一种效率较高的网格DBSCAN算法。文献[6]对各个局部数据集采取不同的参数值分别进行聚类,最后合并各局部聚类结果。文献[7]的DPDGA算法在数据划分时利用遗传算法获得较优的初始聚类中心,据此中心点划分数据集,对各局部数据集分别使用DBSCAN算法进行聚类,最后合并各局部数据集的聚类结果。文献[8]在Spark平台用ACURE算法实现了数据和任务同时并行。文献[9]基于Spark平台设计和实现了并行化的线性回归、向量机和聚类算法。文献[10]研究了Spark并行计算集群对于内存的使用行为。通过对Spark内存行为进行建模与分析,对Spark内存的使用进行了决策自动化以及替换策略优化。虽然针对DBSCAN算法的优化研究很多,针对Spark的研究也有,但针对Spark平台的DBSCAN聚类算法分析目前相对较少。
本文基于HDFS+Tachyon+YARN+Spark平台研究了DBSCAN算法,在此基础上构建了YARN数据挖掘系统的模型结构;在基于MapReduce编程模式上,根据算法的特点采用相应的并行策略将让算法运行到Spark分布式计算平台上。
1 DBSCAN简介
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是Ester Martin等人提出的一个基于密度的聚类算法。密度相连点的最大集合称之为簇,簇可以产生任意形状的聚类,甚至在含有噪声的空间数据中。该算法根据给定的密度阈值(Eps和MinPts)识别一个类,Eps和MinPts分别代表半径和在此半径范围内核心点至少应该含有的点的数量。以下是关于DBSCAN的一些基本定义:
●Eps邻域:数据对象半径为Eps内的全部空间区域;
●核心对象:如果数据对象p的Eps邻域内的对象数大于等于MinPts值,则p是核心对象;
●噪声对象:如果数据对象p的Eps邻域内的对象数小于MinPts值,并且p不在其他核心对象的Eps邻域内,则p是噪声对象;
●直接密度可达:设在样本集合D中,p为核心对象,如果样本点q在p的Eps领域之内,则对象q到p直接密度可达;
●密度可达:设在样本集合D中,给定一串样本点p1,p2,…,pn,p=p1,q=pn,如果对象pi到pi-1直接密度可达,则对象q到p密度可达;
●密度相连:设样本集合D中某对象o,如果o到p和q都是密度可达,则p和q密度相连。
DBSCAN聚类算法是寻找密度相连对象的最大集合。如图1所示。

图1 概念示意图
算法描述:
(1)若数据集中的对象p还未被处理,标记为簇或者噪声,若其Eps邻域包含的对象数大于等于MinPts,则创建新簇C,并将其中的所有点放入候选集N;
(2)对候选集N中还尚未被处理的对象q,检查其Eps邻域,如果包含至少MinPts个数据对象,则将这些对象加入数据集N;如果q还未归入一个簇,则将q放入数据集C;
(3)重复步骤(2),直到候选集N为空;
(4)重复步骤(1)~(3),直到数据集中的数据对象都被处理完毕。
DBSCAN算法也存在一些问题:
(1)当不使用索引时,算法的时间复杂度为O(n2),面对大数据进行聚类时,需要的内存和I/O开销都很大。
(2)算法需要传入Eps和MinPts全局参数且对这两个参数敏感,它们的变化会影响聚类结果,尤其是在密度分布不均匀的情况。
(3)算法处理边界对象时根据“先到先得”的原则决定所属簇,这使聚类的精度受到处理顺序的影响。
2 改进的并行设计
基于Spark平台的DBSCAN算法存在数据和任务双并行化。任务并行化由YARN平台根据节点资源情况来自动分配。
2.1 网格划分
网格划分:通过在数据集中不断查询获取数据对象的Eps邻域,并返回区域中的所有对象,DBSCAN算法的时间复杂度O(n2)较大。故此,以Eps为边长,将数据空间在X、Y两个维度上划分成n×m个矩形单元组成的网格,在此网格上进行聚类操作。虽然此方法表面上是将数据分片并行化,但是由于每一个矩形单元都有统计信息及相应特征,所以不仅是对数据进行分片并行化,也提高了查询速度。
网格单元:即边长为Eps的网格矩形单元:
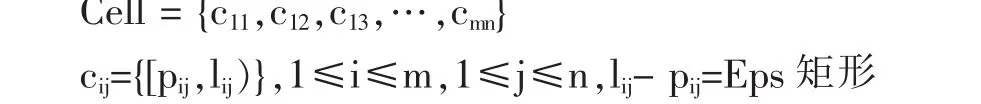
如图2所示。

图2 DBSCAN网格
这是一个左上封闭、右下开放的矩形区间,对于边长不足Eps的单元,按实际的边长计算,在保证计算一致性前提下不影响计算的准确性。
邻接网格集合:与网格单元相邻的8个单元格所构成的矩形区域。
2.2 算法描述
算法首先获取对象的本网格及其邻接网格集合,如果这9个网格中的数据对象数小于MinPts,则标记数据对象为噪声;否则继续进行下一步的运算。基于网格单元的DBSCAN改进算法步骤如下:
(1)将空间划分为n×m个网格单元;
(2)建立数据对象到网格单元的映射关系;
(3)查找数据集中未被标识为簇或噪声的对象,如果p未被处理,则检查该网格及邻接网格共9个网格中的对象数,如果对象数大于等于MinPts,则将其标记为新簇C,并将其中的所有点放入候选集M;否则将该数据对象标记为噪声;
(4)选取候选集M中还未被处理的对象q,检查其邻接网格集合,若包含的对象数大于等于MinPts,则将这些对象放入候选集M;如果q未被归入某一个簇,则将q标记为簇C;
(5)若候选集M不为空,重复步骤(4);
(6)重复(3)~(5)步,直到所有的数据对象都被归到了某个簇或被标记为噪声。
2.3 聚类合并
在各分区的数据聚类之后,再对各分区上的局部簇进行聚合。此时存在两种情况:一是两个没有交叉点的独立簇,不需要对两个簇进行操作;二是有交叉点,此时边界点的二次聚类结果决定是否进行合并。
边界点是指数据集中有特定意义的一类数据对象,位于一个或多个分区的边缘地带,可能属于一到多个簇;但也可是归属性并不确定的孤立数据对象。它是不同分区簇合并的关键点。本文的边界点是指在分区边界边长Eps区域内的点,如图3所示。
经过聚类处理,各分区块上的数据对象都已经打上了簇标记。不同分区块上的簇的合并则跟各分区块上边界点的二次聚类结果相关。需要根据两次簇标记的不同情况来做出不同的处理。
对于任意边界点,在各分区内首次聚类的时候,会存在三种类型:核心、非核心和噪声点。在进行二次聚类时,同样可能存这三种类型的点。求两者的笛卡尔积,得到九种组合。算法流程如图4所示。

图3 边界点聚类合并示意

图4 边界点聚类合并流程
3 平台的并行实现
基于YARN的Spark分布式计算平台将大的任务划分成若干小任务,然后分配给不同平台执行,并依靠HDFS上的Tachyon分布式文件系统存放中间数据结果。HDFS负责存放待处理的原始数据集和聚类分析结果。并行算法运行流程如图5所示。
在Spark平台上,可以利用弹性分布式数据集(RDD)的Transformation和Action操作实现数据并行,RDD的mapPartition能按指定的分区方式进行数据加载,在各个分区上进行数据运算,之后对各分区的运算结果进行聚合。
Spark平台把作业分成若干个阶段,根据服务器资源情况,任务由不同的机器处理。①从Tachyon文件系统读取数据并进行区块划分,将不同的点存放到不同的分区上加以标记。②分别对各分区做聚类运算,给数据点做簇标记,获得局部聚类;提取分区边界点,根据区块编号做二次聚类运算,获取边界点的二次簇标记。③比较边界点前后两次簇标记,根据簇合并规则进行局部簇合并。④更新合并后的簇标记,保存结果至HDFS分布式文件系统。
4 结语
Spark是一个正在不断发展的平台,通过对其深入的学习和了解,能有效的运用好并行运算平台,提升HDFS+Tachyon+YARN+Spark平台的性能并发挥其价值,对大数据的处理将会更快更好。

图5 基于Spark的DBSCAN
[1]王恺.基于MapReduce的聚类算法并行化研究[D].南京:南京师范大学,2014.
[2]孙雨冰.基于MapReduce化的数据聚类算法的研究、设计与应用[D].上海:华东理工大学,2013.
[3]王雅光.基于Hadoop平台的DBSCAN算法应用研究[D].广州:广东工业大学,2013.
[4]罗启福.基于云计算的DBSCAN算法研究[D].武汉:武汉理工大学,2013.
[5]张枫.基于网格的DBSCAN算法和聚类边界技术的研究[D].郑州:郑州大学,2007.
[6]熊忠阳,孙思,张玉芳,王秀琼.一种基于划分的不同参数值的DBSCAN算法[J].计算机工程与设计,2005.
[7]孙思.利用遗传思想进行数据划分的DBSCAN算法研究[D].重庆:重庆大学,2005.
[8]邱荣财.基于Spark平台的CURE算法并行化设计与应用[D].广州:华南理工大学,2014.
[9]梁彦.基于分布式平台Spark和YARN的数据挖掘算法的并行化研究[D].中山:中山大学,2014.
[10]冯琳.集群计算引擎Spark中的内存优化研究与实现[D].北京:清华大学,2013.
[11]迟学斌.高性能并行计算[D].武汉:华中科技大学图书馆,2007.
[12]孙吉贵,刘杰,等.聚类算法研究[J].软件学报,2008,19(1):48-61.
[13]Pang-Ning T,Michael S,Vipin K.Introduction to Data Mining[M].Addison Wesley,2005.
[14]Michael A,Armando F,et al.Above the Clouds:A Berkeley Vew of Cloud Computing[J].Communications of the ACM,2010,53(4): 50-58.
[15]Ralf L.Google's MapReduce Programming Model-Revisited[J].Science of C Programming,2008,70(1):1-30.
[16]Oliveira B C,Gibbons J.Scala for Generic Programmers.Proceedings of Proceedings of the ACM SIGPLAN Workshop on GenericProgramming,New York,NY,USA:ACM,2008:25-36.
[17]阿斯力别克.流数据挖掘算法在金融领域的应用研究[D].广州:华南理工大学,2012.
[18]郑洪英.数据挖掘聚类算法的分析和应用研究[D].重庆:重庆大学,2002.
[19]徐军莉.分布式聚类算法研究及其应用[D].南昌:南昌大学,2009.
[20]祁小丽.一种改进的快速聚类算法及并行化研究[D].兰州:兰州大学,2009.
[21]Barry Wilkinson,Michael Allen.并行程序设计[M].北京:机械工业出版社,2005.
[22]Wikipedia.Tachyon.https://en.wikipedia.org/wiki/Tachyon,2015.
[23]Borthakur D.HDFS Architecture Guide.Hadoop Apache Project.http://hadoop.apache.org/common/docs/current/hdfs_design.pdf, 2008.
[24]Ghemawat S,Gobioff H,Leung S T.The Google File System.Proceedings of Proceedings of the Nineteenth ACM symposium on Operating systems principles,New York,NY,USA:ACM,2003:29-43.
[25]黄晓云.基于HDFS的云存储服务系统研究[D].大连:大连海事大学,2010.
[26]Uavilapalli V K,Murthy A C,Konar M,Shah H,Seth S,Saha B,O'Malley O,Radia S,Baldeschwieler E,Douglas C,Curino C,Agarwal S,Evans R,Graves T,Lowe J,Reed B.Apache hadoop yarn:Yet Another Resource Negotiator.In Proceedings of the 4th Annual Symposium on Cloud Computing.ACM,2013:5.
[27]董西成.Hadoop技术内幕:深入解析YARN架构设计与实现原理[M].北京:机械工业出版社,2013:153-184.
[29]Dean J,Ghemawat S.MapReduce:Simplified Data Processing on Large Clusters[J].Communications of the ACM,2008,51(1):107-113.
A Grid Clustering Method of YARN and Spark Framework
WANG Zhi-gang,CHEN Ming-hui,ZHAO Zhen-kai
(College of Math and Computer Science,Hunan Normal University,Changsha 410081)
Distributed computing for large data processing provides a new platform which can effectively improve the speed of the algorithm.Based on DBSCAN algorithm,proposes a data sub-grid algorithm,which divides the data of each partition into cell data block with Eps radius as the side length,to reduce the search for Eps neighborhood range data objects within eight adjacent cells,so as to improve the speed of Eps neighborhood search and the clustering speed,good speed ratio and extension ratio.At the same time,optimizes the partition clustering consolidation methods.
Distributed Computing;DBSCAN;Spark;YARN;Tachyon
1007-1423(2016)35-0033-05
10.3969/j.issn.1007-1423.2016.35.007
王志刚(1962-),男,湖南沅江人,教授,研究方向为软件工程、计算机网络
2016-11-01
2016-12-01
