基于动态GMM模型的歌曲歌唱部分检测
2016-02-13吕兰兰
吕兰兰
(湖南科技学院电子与信息工程学院软件工程系,永州425100)
基于动态GMM模型的歌曲歌唱部分检测
吕兰兰
(湖南科技学院电子与信息工程学院软件工程系,永州425100)
针对人工标注歌声/纯伴奏信号存在的误差,以及初始训练的歌唱模型/伴奏模型与测试歌曲之间在音乐风格、乐器等方面的差异,提出建立基于对数似然比的动态GMM模型。在使用初始模型对测试歌曲的每一帧进行分类后,根据似然比选出可信度较高的连续帧数据,对初始模型进行动态更新,使得更新后的模型与测试歌曲之间的差异缩小。实验结果表明,相对初始模型,使用动态更新后的模型对歌曲的歌唱部分进行检测,准确率更高。
歌唱部分检测;高斯混合模型;似然比;动态模型
0 引言
歌曲中的歌唱部分是一首歌曲的精华所在,对于歌曲的检索和分类有很大帮助。一首歌曲通常由歌手演唱部分和纯伴奏部分构成,其中歌手的演唱部分是人声与伴奏音乐的叠加,纯伴奏部分则不含人声、纯粹由伴奏乐器的声音构成。歌曲中的歌唱部分检测,指的是在歌曲中定位这两种信号出现的起始时间和结束时间。通过检测歌曲的歌唱部分,可以快速挖掘歌曲中与歌曲内容有关的信息。此外,歌曲中的歌唱部分检测,也可以作为歌词识别和歌手识别的前端处理。
大量研究表明,现有的歌曲歌唱部分检测算法大多采用声学特征参数和概率统计模型分类器相结合的处理方法[1-3]。在语音信号处理中广泛使用的声学特征参数很多,常用的声学特征参数有:梅尔倒谱系数(MFCC,Mel-Frequency Cepstral Coefficients)、感知线性预测系数(PLPC,Perpetual Linear Predict Coefficients)、线性预测倒谱系数(LPCC,Linear Predict Cepstral Coefficients)、短时能量(Short-Term Energy)、过零率(Cross Zero Rate)、基音(Pitch)等。文献[4]的研究结果表明,MFCC不仅能很好地体现说话人的语音特征,在音乐信号的各种声学特征参数中,MFCC对音乐信号的特征表现能力也很不错,而且是最合适的。常用的的分类器包括:隐马尔科夫模型(HMM)、高斯混合模型(GMM)、支持向量机(SVM)、人工神经网络(ANN)、决策树(Decision Tree)、朴素贝叶斯分类器(Naive Bayes)等。研究表明,支持向量机的分类效果最好,但与GMM相差不大,且GMM具有较强的数据描述能力[5-7]。因此,本文尝试采用MFCC作为声学特征,使用GMM作为分类器来对歌曲中的歌唱部分和纯伴奏部分进行区分。
由于不管采用哪种分类器,都要使用人工标注好的歌声信号和伴奏信号作为训练数据,以建立歌唱模型和伴奏模型。因此,人工对歌曲中的歌声信号和伴奏信号进行标注的精确度极为关键,直接影响到所建立的模型的好坏以及识别的准确率。同时,在实际检测中发现,初始训练的歌唱模型/伴奏模型与测试歌曲之间在音乐风格、乐器等方面常常存在不小的差异,这对识别的准确率有一定影响。
针对上述问题,本文提出一种歌唱模型和伴奏模型的动态更新算法。使用人工标注好Sing和Non-singing的音频数据建立初始模型,利用初始模型定位待测歌曲中最有可能是歌唱部分的片段,以及最有可能是伴奏部分的片段,并使用这些数据对初始模型进行动态更新,一方面消除人工标注误差的影响,另一方面缩小训练模型与测试歌曲的差异。
1 基于GMM的歌唱部分/伴奏部分检测
1.1 歌唱模型/伴奏模型的建立
使用人工标注好Singing和Non-singing的歌曲作为训练数据,对其进行分帧,每一帧提取MFCC特征向量。根据人工标注将这些帧分为歌唱和纯伴奏两类,然后用这些数据分别建立歌唱部分的GMM模型和纯伴奏部分的GMM模型,记为λS和λN。
1.2 歌唱部分/伴奏部分的识别
对歌曲的歌唱部分进行检测时,对其分帧,每一帧提取MFCC特征向量。假设共有T帧,这样得到一个特征向量序列:{x1,x2,…,xT}。对每一帧的特征向量xt,分别计算其在歌唱部分的GMM模型λS和纯伴奏部分的GMM模型λN下的对数似然率,即:logp(xt|λS)和logp(xt|λN),其中t=1,2,…,T。从而得到一组随时间变化的对数似然比:
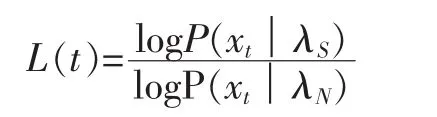
其中t=1,2,…,T。
若L(t)≥0,则将xt识别为歌唱部分,否则将xt识别为伴奏部分。设识别结果为D(t),则有:
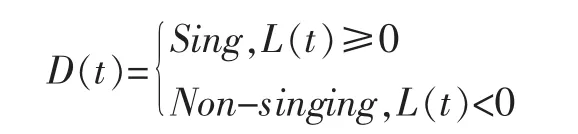
其中,Sing代表歌唱帧,Non-singing代表伴奏帧,t=1,2,…,T。
由于歌唱的发声以及音乐的产生不是骤然停止或者开始,而是具有一定的延续性和稳定性,因此歌唱帧的附近很有可能还是歌唱帧,伴奏帧的附近很有可能还是伴奏帧。并且,通过分析实验数据发现,绝大部分的歌曲中的歌唱部分和伴奏部分的持续时长至少在1s以上。根据歌曲信号的这一平稳特性,考虑以基于GMM的识别结果为基础,对短暂突变的识别结果,使用中值滤波对原始的对数似然比L(t)进行平滑处理,如下所示:其中,h(t)为一个101点的中值滤波器,*为卷积符号,Lsm(t)为使用中值滤波平滑后的处理结果。再将中值滤波结果分为两类,这样就得到了帧识别结果Dsm(t),如下所示。
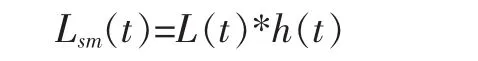
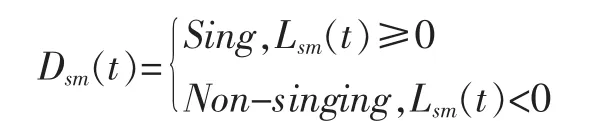
其中,Sing代表歌唱帧,Non-singing代表伴奏帧。
2 歌唱模型/伴奏模型的动态更新算法
由于人工标注歌曲中的歌声/纯伴奏信号时,人的大脑、耳朵和双手之间存在着一定的延迟,这样会导致在标注歌声部分的开始区域或者纯伴奏部分的开始区域时出现误差,使得训练数据本身存在标注错误,从而影响训练所得到的模型的质量。同时,由于歌曲的风格、种类和流派众多,所用乐器及其演奏方式、歌手的性别、嗓音及唱腔等都千差万别,造成初始训练的模型与某一首特定的待测试歌曲之间存在较大差异,不利于准确地检测出其中的歌唱部分。为解决上述问题带来的影响,提出采用一种歌唱模型/伴奏模型的动态更新算法,对初始训练好的模型进行动态更新,以达到更高的识别准确率。歌唱模型/伴奏模型的动态更新算法如2.1和2.2所示。
2.1 基于对数似然比选择可靠数据
利用1.2介绍的方法对歌曲信号进行处理,对每一帧特征向量xt计算其在初始训练的歌唱部分的GMM模型λS和伴奏部分的GMM模型λN下的对数似然比Lsm(t)。使用该组随时间变化的对数似然比数据Lsm(t)来定位歌曲中最可能是歌唱部分的歌声片段:
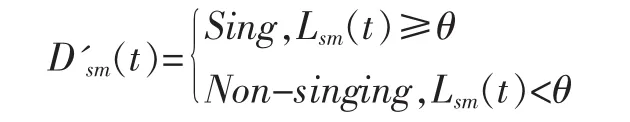
其中,θ是一个动态的判决阈值,只需保证n%的Lsm(t)在此阈值之上。θ具体数值将由实验决定,此处取20。将检测到的所有歌声帧融合在一起作为动态更新歌唱模型的可靠数据。同时,也可通过设置动态的判决阈值θ,保证n%的Lsm(t)在此阈值之下,将检测到的所有伴奏帧融合在一起作为动态更新伴奏模型的可靠数据。
2.2 基于最大后验估计动态更新模型
采用基于最大后验估计(MAP,Maximum a Posterior)的GMM模型自适应算法[8],使用2.1得到的可靠数据对初始的歌唱模型λS和伴奏模型λN进行更新,得到更新后的歌唱模型和伴奏模型,分别记为λS'和λN'。利用1.2介绍的方法,使用更新后的歌唱模型λS'和伴奏模型λN',对待测歌曲的歌唱部分进行检测。
3 实验结果及分析
实验选取了20首中文流行歌曲建立音频数据库,为方便处理,预先将歌曲从MP3格式转换为WAV格式,采样率为16kHz,量化位数为16。人工对这20首歌曲的歌唱部分和纯伴奏部分进行了手工标注。测试方法为留一交叉检验(Leave One Out Cross Validation),即:假设测试样本总容量为L,依次将L-1份数据用作训练样本,而将剩下的1份数据作为测试样本。实验中采用的帧长为32ms,帧移为16ms,MFCC特征维数为39维,高斯混合数为13。采用基于帧的错误率(ER,Error Rate)、漏检率(MDR,Miss Detection Rate)、错检率(FAR,False Alarm Rate)三个指标来评价识别效果,其中漏检是指歌曲中的歌唱部分未被检测出来,即被错误地识别为伴奏部分,错检指的但是歌曲中的伴奏部分被错误地检出,即被错误地识别为歌唱部分。错误率、漏检率和错检率的计算公式如下:


表1给出了使用初始歌唱/伴奏GMM模型和动态更新后的歌唱/伴奏GMM模型的识别结果。从表1中可以看到,使用动态更新后的GMM模型可以有效地降低平均错误率,同时平均漏检率和平均错检率也有所降低。
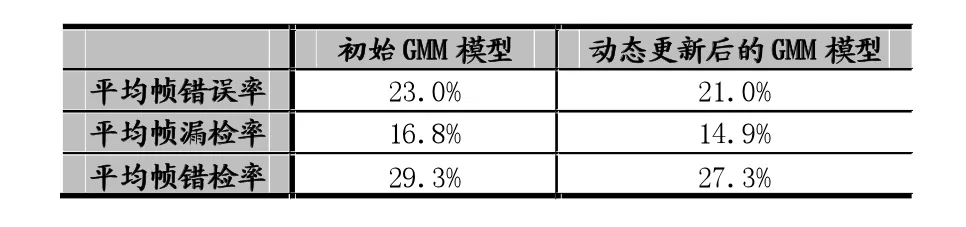
表1 初始GMM模型和动态更新后的GMM模型的识别结果
4 结语
本文采用MFCC作为声学特征,使用GMM作为分类器,进行歌曲中歌唱部分的检测研究。针对人工对歌曲中的歌声信号和伴奏信号进行标注时可能存在的误差,以及训练模型与测试歌曲在音乐风格、乐器等方面可能存在的差异,提出基于对数似然比选择可靠数据、动态更新训练模型,获得与待测歌曲在音乐风格、乐器等方面差异较小的训练模型,同时也使人工标注中的误差的影响降低。实验表明,使用动态更新后的训练模型可以有效地降低帧层次的错误率。与此同时,帧层次的漏检率和错检率也得到了有效降低。
[1]B.Lehner,G.Widmer,R.Sonnleitner.On the Reduction of False Positives in Singing Voice Detection.In Proc.of the 2014 IEEE Int. Conf.on Acoustics,Speech,and Signal Processing,ICASSP 2014.IEEE,2014,pp.753-7534.
[2]B.Lehner,R.Sonnleitner,G.Widmer.Towards Light-Weight,Real-Time-Capable Singing Voice Detection.in Proc.of ISMIR,2013.
[3]H.Lukashevich,M.Gruhne,C.Dittmar.Effective Singing Voice Detection in Popular Music Using Arma ltering.in Proc.of DAFx-07,Bordeaux,France,2007.
[4]M.Rocamora and P.Herrera.Comparing Audio Descriptors for Singing Voice Detection in Music Audio Files.in Proc.of Brazilian Symposium on Computer Music,11th.San Pablo,Brazil,volume 26,page 27-30,2007.
[5]Ramona M,Richard B,David G.Vocal Detection in Music with Support Vector Machines[J].Proc of ICASSP,2008:1885-1888.
[6]王天江,陈刚,刘芳.一种按节拍动态分帧的歌曲有歌唱部分检测新方法[J].小型微型计算机系统,2009,30(8):1561-1564.
[7]石自强,李海峰,孙佳音.基于SVM的流行音乐中人声的识别[J].计算机工程与应用,2008,44(25):126-128.
[8]闵葆贻,贺光辉.基于UBM-MAP的说话人识别系统研究[EB/OL].北京:中国科技论文在线[2014-03-07].http://www.paper.edu. cn/download/downpaper/201403-204.
作者简介:
吕兰兰(1980-),女,湖南永州人,讲师,硕士,研究方向为语音及音频信号处理
Singing Voice Detection in Songs Based on Dynamic GMM Models
LV Lan-lan
Proposes a dynamic GMM model based on likelihood ratio,in order to deal with the occasional errors in manual annotation of songs,and the differences between initial training models and the tested song in music style,instruments,etc.By use of initial training models,the tested song is classified frame by frame to either singing or non-singing.According to the logarithm of likelihood ratio,the high reliable frames are searched out.The initial training models then are dynamically updated based such frames,which narrows the gap between updated models and the tested song.The experimental results show that relative to the initial training model,using dynamic updated model to detect the singing voice in a song can get higher accuracy.
Singing Voice Detection;Gaussian Mixture Models;Likelihood Ratio;Dynamic Model
1007-1423(2016)35-0029-04
10.3969/j.issn.1007-1423.2016.35.006
2016-10-20
2016-12-01
永州市科技计划指导性项目(2011)流行歌曲歌词实时智能提取技术研究
(Department of Software Engineering,College of Electronic and Information Engineering,Hunan University of Science and Engineering,Yongzhou 425100)
