一种基于集群的通用并行计算框架设计
2016-02-13王宁
王宁
(四川大学计算机学院,成都610065)
一种基于集群的通用并行计算框架设计
王宁
(四川大学计算机学院,成都610065)
近年来各领域应用的数据量和计算量需求都大幅增加,传统单个计算设备往往无法胜任如此规模的计算量,因此越来越多的领域开始尝试使用并行计算技术,分布式并行计算是进行并行计算的一种主要方式,常见的框架为基于MapReduce的Hadoop。提出一种基于集群的通用并行计算框架,参考“管道过滤器”模式,对三个模块“任务划分”、“控制器节点”和“计算节点”都进行详细设计描述,相对于Hadoop,对有向无环图型任务由更好支持,并且支持迭代型任务,另外增加缓存机制,减少系统耗时,一定程度支持实时性应用。
并行计算;集群;系统框架;有向无环图;缓存
0 引言
并行计算[1](Parallel Computing)是指同时使用多种计算资源解决计算问题的过程,是提高计算机系统计算速度和处理能力的一种有效手段。它的基本思想是用多个处理器来协同求解同一问题,即将被求解的问题分解成若干个部分,各部分均由一个独立的处理机来并行计算。并行计算系统既可以是专门设计的、含有多个处理器的超级计算机,也可以是以某种方式互连的若干台的独立计算机构成的集群。通过并行计算集群完成数据的处理。
目前应用较为广泛的并行计算模型为Jeffrey Dean等提出的MapReduce[2],MapReduce的基本思想是将所有任务的执行看做两个操作,分别是Map(映射)和Reduce(化简),首先,Map会先对由很多独立元素组成的逻辑列表中的每一个元素进行指定的操作,且原始列表不会被更改,会创建多个新的列表来保存Map的处理结果。也就意味着,Map操作是高度并行的。当Map工作完成之后,系统会接着对新生成的多个列表进行清理(Shuffle)和排序,之后,会这些新创建的列表进行Reduce操作,也就是对一个列表中的元素根据Key值进行适当的合并。
Hadoop作为最早的基于MapReduce的并行计算框架之一,目前得到了十分广泛的使用,其以MapReduce为计算核心,添加了任务分配、负载均衡、网络传输等模块。Hadoop的优点在于对大数据问题的处理很方便,并且系统具有高可扩展性,即很容易将新的计算资源加入已有系统中,Hadoop对用户隐藏了底层任务调度、负载均衡、网络传输等细节,使用户只需专心于MapReduce模块的制定。
如果用户定义了多个Job,并指定了它们之间的先后关系,则多个Job会依次按照MapReduce的方式进行处理,最终用户需要的结果就存储在最后一个Reduce节点上,整个的任务调度、网络通信、数据存储、负载平衡等工作都是MapReduce框架底层完成的,不需要用户关心。
MapReduce框架的优点在于对大数据问题处理很方便,并且具有很高的可扩展性,即很容易将新的计算节点加入到已有的系统中。另外MapReduce和Hadoop也有一些很明显的缺点:
①所有Reduce任务必须等前一步的Map任务全部完成才可以执行,这样会大大降低可并行度;
②对DAG(有向无环图)类型的任务支持不足,Hadoop虽然可以用多个Job来模拟出DAG图,但是Job间的依赖需要开发者分别管理维护,并且不同层次的任务不能并行执行;
③很难支持迭代类型任务,迭代类型的任务通常无法预知迭代次数,所以无法预先生成定量的Job;
④MapReduce强制定义了Map和Reduce两个阶段,但有时用户并不需要两个阶段的处理;
⑤无法支持实时性应用,Reduce操作生成的数据,会被HDFS存入硬盘中,由于没有相应的缓存机制,所以存储耗时导致系统时延过高,进而无法支持实时性应用。
本文提出的基于集群的并行计算框架在参考了MapReduce模型和Hadoop框架的基础上,对于以上5点问题均得到了一定程度的解决,下面几个小节将分别对此框架的整体架构和各模块做相应说明。
1 整体架构描述
系统整体架构如图1所示,整个框架大体分为TaskSplitter(任务分割)、Master(主控节点)和ComputeNode(计算节点)三部分。TaskSplitter部分负责任务划分,本文设计了一种脚本语言,用户使用脚本描述自己的应用,TaskSplitter会根据脚本自动切分任务,并生成任务间的依赖关系,很容易构建DAG应用,随后将任务填充到TaskManager中。Master部分主要负责任务调度,分别从TaskManager和ComputeNodeManager获取任务信息和计算节点信息后,再由Schedule负责调度分配,最终Master下发消息给ComputeNode。ComputeNode部分主要负责接收Master发送过来的消息,执行具体的计算任务,并且对计算产生的数据进行存储。
整个架构参考了“Pipe-Filter”架构模式[4],”Pipe-Filter”总体思想如图1所示,将系统看做一系列对原始数据的加工动作,首先将原始数据经过一次处理(即Filter一次),加工后的数据放到管道(Pipe)中,然后等待下一个Filter继续对数据做加工处理,再放到一个Pipe里,如此持续进行下去直到所有Filter都完成了数据加工,那么最终数据就保存在最后一个Pipe里。
对于并行框架来说,所有的任务都可以抽象成先从某处取得对输入数据,做一定的处理后输出新的数据,我们很自然而然的用Filter类来表示一次计算,为了充分利用起计算资源,使用ComputeNode这样一个逻辑上的节点来管理多个Filter,每个ComputeNode本身也是Pipe(这样设计的原因后面再做详述),Master则做为一个创建Filter、将Filter和Pipe连接起来的角色,Master和ComputeNode在逻辑上是一对多的,在这样的设计下,整个架构流程为:首先TaskSplitter划分得到任务(与此同时各个ComputeNode节点会通过线程自动向Master注册信息以填充ComputeNodeManager),然后Master由调度模块生成调度信息(调度信息包括计算任务信息和数据Pipe信息),发送给Com-puteNode,ComputeNode解析这些信息生成相应Filter去执行计算任务,计算完成后,由Pipe存储数据,然后将任务完成的消息返回给Master,Master更新相应任务状态后继续执行下一次的任务调度,如此往复直到所有任务都执行完毕。

图1 系统整体架构

图2 Pipe-Filter
2 TaskSplitter部分
TaskSplitter部分的目的是给用户提供一种方式(接口、脚本等)用以描述用户的应用需求,根据用户的描述进行分析,生成任务为后面的调度做好准备。因为此部分会直接和用户交互,因此可理解性和可扩展性很重要,要尽可能让用户方便地去描述多类型的需求,为达到此目的,本文设计了一种简便的脚本语言,脚本应用举例如下:

以上所示是一个对图片序列进行特征检测的应用,脚本共包含四部分,INPUT:预定义一些变量,用以协助控制任务流程,支持INT、STR、BOOL、DOUBLE类型;KERNEL:预声明计算处理功能,对应Filter的种类,用来创建不同Filter,CPU和MEMORY表示任务代价(1 CPU表示5%,1 MEMPRY表示100M);DATA:预定义变量,可以是数组;PROCEDURE:描述应用流程,整个应用是从上到下串行处理的,对于同一层次可并行任务,使用FOR或WHILE循环来描述。根据此脚本,TaskSplitter会自动生成任务并设置好它们之间的依赖关系。
此脚本解决了2个问题:
①描述DAG任务很方便,用户只需按照实际应用思路编写PROCEDURE,系统会自动生成满足依赖关系的任务列表,并且不同层次的子任务只要没有前置依赖项便可以并行执行;
②支持迭代式任务,用户使用BOOL类型变量和WHILE循环便可以描述迭代式任务,BOOL变量的值可以在用户自定义的Filter中更改。
在进行解析时,本文使用一个语句池(Statement-Pool)来存放解析得到的单条语句,TaskSplitter不断从语句池中取得语句去生成新的任务(Task)并更新与其他任务间的依赖关系,生成的任务被不断填充到任务管理器中(TaskManager)。使用语句池的目的在于,避免TaskSplitter解析大量循环时导致Master阻塞,Master没有必要等待全部任务解析完成,任务解析和任务分配可以同时进行。
3 Master部分
Master负责任务管理、任务调度、计算节点管理等工作。Master的设计使用了组合模式,任务管理功能由TaskManager完成,计算节点管理由ComputeNodeManager完成,任务调度由Schedule完成,而Master本身只负责协调各方工作,这样可以避免Master变得臃肿,并且各组件可以二次开发,提高了系统可扩展性,用户甚至可以自行定制各组件以满足特殊需求。以下对消息机制、计算节点管理、任务调度和容错机制做进一步的介绍。
3.1 消息机制
网络中所有传输的数据都以Packet为基类,由Packet派生得到Message类,作为各种消息的基类,这些消息按照Master To ComputeNode、ComputeNode To Master和ComputeNode To ComputeNode分类如图3所示:
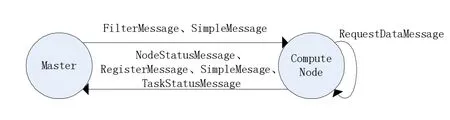
图3 消息类型

Master和ComputeNode均使用MessagePool来做消息缓冲池,收到的消息先压入消息池,然后每次从中取一条消息进行处理,在消息处理方面使用了命令模式,即为每类消息创建一个Handle类,在处理消息时,根据消息类型由工厂模式[5]创建相应的MessageHan dle,调用execute方法执行处理,这样方便对消息类型进行扩展。
3.2 计算节点管理
要对计算节点(ComputeNode)进行管理,首先要获得计算节点的信息,而计算节点信息的获取又分为两个阶段,第一个阶段是初始化,当一个计算节点启动时,会自动开启一个线程,向配置文件里配置的Master的IP和PORT发送注册请求,Master收到注册请求后便将此节点信息添加到ComputeNodeManager中,计算节点只有当收到Master的SimpleMessage::RegisterConfirmed消息后,才会停止注册请求;第二个阶段是更新信息,当注册成功后,计算节点会开启一个Keep-Alive线程,每隔固定时间K便向Master发送NodeStatusMessage消息更新ComputeNodeManager中相应的计算节点信息,需注意K设置的太大会使任务调度时信息不准确,K设置过小又会使得此线程开销过大影响系统效率。
3.3 任务调度
任务调度有三个关键问题,分别是调度对象,调度时机和调度策略。
对于本系统,调度对象指的是任务和计算节点,根据前面的描述,我们知道当执行任务调度时,TaskManger和ComputeNodeManager中已有了用来调度的任务和计算资源。
调度时机有两个,首先当有新的计算节点注册时,在执行完注册相关操作后会进行任务调度,其次当Master收到TaskStatusMessage后,会接着进行一次任务调度,因为Task的执行状态只有两种,分部是成功和失败,执行成功意味着有计算资源处于空闲,可以进行新的任务分配,而执行失败表示有空闲的任务可被调度。
在进行调度时,Schedule首先从TaskManager和ComputeNodeManager获取所有可分配的任务和计算资源,先对可用计算节点分别按CPU和内存排序,然后对每一个任务,若CPU权值>=内存权值,则优先选CPU最大的节点分配此任务,否则优先按内存大小寻找节点,然后此节点减去消耗值,将此任务加入此节点的待分配队列,然后对下一个任务继续如此分配,直到所有待分配任务分配完成或所有节点不满足任何一个任务的分配,最后下发消息将待分配队列的内容分别发送给各个计算节点。
3.4 容错机制
容错机制指的是当计算任务出现问题,或者计算节点出现问题时整个系统的应对机制。首先当任务执行错误时,会由ComputeNode主动向Master报告此错误,然后Master会回滚此任务状态重新分配执行;而当计算节点因为断电、机械故障等原因无法和整个系统通信时,Master若超过3个Keep-Alive线程周期都没有收到某ComputeNode的节点状态信息,则认为此节点故障,此时Master会先检查任务列表,查看此节点上哪些已完成任务还有后置任务(即有其余的尚未完成的任务依赖于此节点上已完成的任务),将这些任务和上一次分配分配给此节点的任务一起重新调度执行,这样便可使得整个系统的任务依赖和数据依赖重新修复,但会因为任务重做造成一定的时间损耗。
4 ComputeNode部分
ComputeNode部分主要是完成Master分配的计算任务,任务完成或失败后返回消息给Master,并且通过Pipe对计算得到的数据进行存储,接收到其他节点的数据请求时发送数据给对方。此部分的消息处理机制
和Master部分是一样的。当收到Master发来的Filter-Message时,便对任务队列的每一个任务单独开启一个线程,由工厂创建对应的Filter执行计算任务(如果所需数据不在本地,需要进行数据请求),执行完成后,通过Pipe进行数据存储。下面对数据存储和请求数据两部分做进一步说明。
4.1 数据请求
FilterMessage消息携带了每个任务所需数据存放的节点IP、名称等信息,当Filter执行时,对每一个所需参数先检查数据IP是否和本地IP一致,若一致则检查下一个,若不一致则向此IP发送数据请求消息(RequsetDataMessage),目的ComputeNode接收此消息后,通过Pipe查找到数据,发送给请求方的PipePool(使用Pool是为了避免多个数据传输阻塞),请求方获取到数据后,再对下一个参数做同样检查或请求,直到所有参数都准备就绪,便开始执行计算。
4.2 数据存储
当Filter执行完计算任务后,需要通过Pipe将数据存储下来,Pipe本身不执行存储操作,它只负责对数据名称、路径等信息做记录,真正的存储操作交给更底层的Storage处理,本文在设计Storage时使用了缓存技术,即以一定大小的内存来缓存数据对象,避免写到硬盘带来的序列化和逆序列化时间消耗,使用的内存大小由配置文件进行设置。内存缓存策略为:新生成的数据会优先存到内存中,如果可用内存超过了阈值的话,就将一部分数据置换到硬盘上,置换算法使用LRU[6]算法,即存储中的每个数据对应一个int,刚存入时置为0,每次存储新数据时,以前的都加1,被访问的数据重新置0,这样当置换时,优先置换int值最大的数据。缓存技术加上底层Infiniband高速网络[7-8]使得本文并框架对实时性应用也有很好的支持。
5 实验结果
本文通过一个实际的应用来验证并行计算框架的实用性和有效性,选取的应用是“全景图拼接”[9],其处理流程如图4所示,包含多个步骤,该应用是一个典型的DAG型应用,如图5所示,有的步骤可以切分成多个子任务,有的步骤又需要全局的数据,各步骤之间的任务存在较复杂的依赖关系,可以全面地检验本文并行系统的有效性。
5.1 实验平台
实验环境中,每台计算机配置相同,配置均为:处理器:Intel Xeon CPU E3-1230 v3@3.30GHz四核;内存:16.0GB;操作系统:Windows 7(64位)。
5.2 结果分析
为了证明本文并行计算框架的有效性,分别对不同计算节点数量、不同规模输入数据情况下的计算耗时做测试,各情况下耗时如表1所示。
可以看出,在数据量较小时,任务并行计算带来的效率提升被数据传输的损耗所抵消,在2台计算节点、108张输入图片的情况下,多机并行的执行速度已经超过了单机串行的速度,并且随着计算节点、输入数据规模的增大,效率提升越来越明显。当计算节点为4个,输入图像数量为288张时,并行框架效率比串行时高了一倍。

图4 景图拼接流程
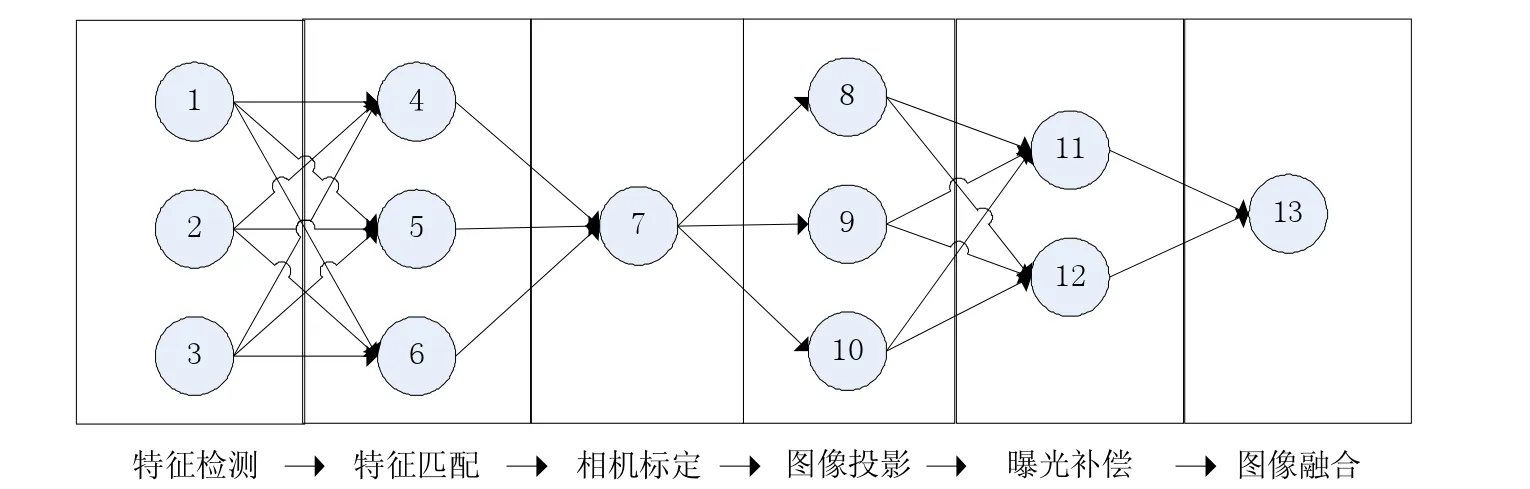
图5 全景图拼接子任务依赖

表1 不同输入图像(张)和不同计算节点(个)下运算耗时
通过此实验可以验证本文并行框架的有效性,但是效率提升并未达到1:1(即效率提升倍数等于同等配置计算节点个数),分析其原因主要有以下3点:(1)并行框架底层的消息传输、数据传输以及任务分配算法都会有一定耗时;(2)对于DAG型应用,各任务间有依赖,有时需要等待任务同步;(3)全景图拼接应用中有一些“瓶颈”任务(例如相机标定),这类任务依赖于上一步的所有数据,因此无法进行并行。
6 结语
本文提出一种基于集群的通用并行计算框架,参考“管道过滤器”模型,由TaskSplitter解析自定义的任务描述脚本,自动划分子任务和生成依赖关系,由Master进行计算资源管理和任务调度,由ComputeNode完成任务计算和数据存储。框架支持任何DAG型应用,并且支持迭代式应用和实时性应用,另外对于ComputeNode具有一定程度容错备灾能力。
本文框架目前无法解决Master节点单点故障,下一步计划采用分布式共享存储系统[9]重新对Master信息和计算数据做冗余备灾。
[1]王磊.并行计算技术综述[J].信息技术,2012,10.
[2]J.Dean,S.Ghemawat.MapReduce:Simplified Data Processing on Large Clusters[J].Communications of the ACM-50th Anniversary Issue:1958-2008.2008.51(1):107-113.
[3]T.White.Hadoop:The Definitive Guide,Third Edtion[M].United States of America.O'Reilly Media,Inc.2012:3-12.
[4]V.Ambriola.G.Tortora.Advances in Software Engineering and Knowledge Engineering[M].Farrer Road,Singapore 9128.World Scientific Publishing Co.Pte.Ltd.1993:95-109.
[5]W.Pree.Design Patterns For Object-Oriented Software Development[M].Wokingham,England.Computing Machines(ACM)and Addison-Wesley Publishing Company,1994
[6]E.J.O'Neil,P.E.O'Neil and G.Weikum.The LRU-K Page Replacement Algorithm for Database Disk Buffering.Proc.of the 1993 ACM SIGMOD International Conference on Management of Data,pp.297-306.
[7][2]Pentakalos O I.An Introduction to the InfiniBand Architecture[M].High Performance Mass Storage and Parallel I/O:Technologies and Applications.Wiley-IEEE Press,2002:616.
[8][4]Vivek D.Deshmukh.InfiniBand:A New Era in Networkint[C].Proceedings of National Conference on Innovative Paradigms in Engineering&Technology.New York,USA:Foundation of Computer Science,2012.
[9][8]Pandey A,Pati U C.Panoramic Image Mosaicing:An Optimized Graph-Cut Approach[M].Proceedings of 3rd International Conference on Advanced Computing,Networking and Informatics.Springer India,2016:299.
[10]K.Shvachko,H.Kuang,S.Radia,R.Chansler.The Hadoop Distributed File System[J].Mass Storage Systems and Technologies (MSST),2010 IEEE 26th Symposium on.IEEE,2010:1-10.
Design of a General Parallel Computing Framework Based on Cluster
WANG Ning
(College of Computer Science,Sichuan University,Chengdu 610065)
In recent years,the amount of data and computation requirements in various fields has increased significantly.Traditional single computing devices are often incapable of performing such computational tasks.More and more fields are beginning to use parallel computing. Distributed computation is one of the main parallel computing methods,Hadoop is a most common framework based on Map-Reduce in distributed computation.Proposes a general parallel computing framework based on cluster.Describes the"task splitter","master node" and"computing node"in details with reference to"pipeline filter"mode.Compared with Hadoop,directed acyclic graph task is better supported,iteration task is supported.In addition,caching mechanism is added to reduce system time-consuming and support real-time application to a certain extent.
Parallel Computing;Cluster;System Framework;DAG;Cache
1007-1423(2016)35-0020-07
10.3969/j.issn.1007-1423.2016.35.004
王宁(1992-),男,陕西咸阳人,硕士研究生,研究方向为计算机图形学、并行计算
2016-10-18
2016-11-30
