结合评分可信度和动态时间加权的推荐算法
2016-02-13黄兰钱育蓉
黄兰,钱育蓉
(新疆大学软件学院,乌鲁木齐 830008)
结合评分可信度和动态时间加权的推荐算法
黄兰,钱育蓉
(新疆大学软件学院,乌鲁木齐 830008)
为了解决电子商务推荐系统在推荐新项目方面的冷启动问题,同时提高用户与推荐项目的相似度,通过对比当前的推荐算法,提出一种结合可信度和动态时间加权的推荐算法。该算法引入用户评分可信度来计算用户和项目的相似性,将新项目推荐给可信度高的用户;分析用户兴趣、项目受欢迎度和时间的关系构造动态时间加权函数,将项目推荐给用户兴趣度高且项目受欢迎度高的用户。通过实验验证该算法与传统的基于用户的推荐UBCF算法相比能够提高近7%的推荐准确度,与基于项目的推荐IBCF算法相比能够提高近4.7%的推荐准确度,同时解决新项目推荐的冷启动问题。
推荐系统;协同过滤;可信度;时间加权
0 引言
近年来,随着互联网数字信息的爆炸式增长,推荐系统[1]已成为个性化服务重要的研究热点,通过预测用户的偏好给用户推荐商品、服务及个性化的信息,帮助用户解决信息过载问题。推荐系统的主要推荐技术有基于内容的推荐、协同过滤推荐、组合推荐[2-7]等,其中协同过滤推荐算法是推进系统中应用最广泛和最成功的推荐技术之一[8]、在许多领域取得较好的发展,如电子商务(阿里巴巴,Amazon、京东等)、信息检索(百度、Google、Yahoo等)、社交网络(腾讯QQ、微信、Facebook等)等。协同过滤推荐算法现面临着两个主要的挑战:(1)冷启动问题,由于新项目没有评分记录,如何推荐新项目。(2)概念漂移问题,用户兴趣和项目受欢迎度总是在不断变化,如何找到它们与时间之间的变化关系。这两个问题不仅影响了用户相似度和项目相似度的计算精度,还影响了预测推测的准确度,导致推荐质量下降。
本文提出了一种结合用户评分可信度的相似性方法度量,从用户等级和商品时间特效两方面来及计算用户评分的可信度,对传统的相似性度量方法进行改进,提高相似的准确度;计算用户评分的可信度结果按从大到小排列,将新项目推荐给前N个可信度高的用户,提高新项目的推荐准确度,解决新项目推荐的冷启动问题。本文还提出了基于用户兴趣的时间加权和基于项目受欢迎度的时间加权,来解决用户兴趣和项目受欢迎程度随时间动态变化的问题。
1 相关概念
1.1 用户-项目评分矩阵
推荐系统通过使用m×n阶的用户-项目评分矩阵来表示用户对项目的评价信息。通常,m个用户集合用集合U={u1,u2,...,um}表示,n个项目集合用集合I={i1,i2,...,in}表示,用户i对项目j的评分值用rij表示(rij值越大,表示用户i对项目j越喜欢)。关于m×n阶的用户-项目评分矩阵如表1所示。
1.2传统协同过滤推荐算法
根据用户-项目评分矩阵可以计算用户之间的相似度或项目之间的相似度,目前常用的相似度计算度量方法有3种:皮尔森相关相似性(Pearson Correlation Codffient,PC),余弦相似性(Cosine Similarity,COS),修正的余弦相似性(Adjusted Cosine Similarity,ACOS)[9]。
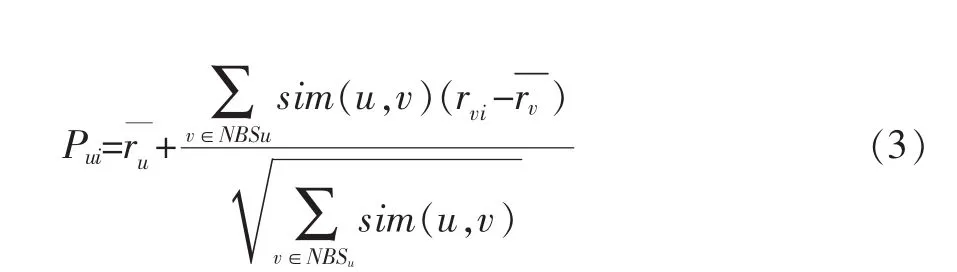

表1 用户-项目评分矩阵表
公式(3)中,rvi表示用户v对项目i的评分,表示用户u对其所评价过所有项目的均值,表示用户v对其所评价过所有项目的均值,sim(u,v)用户u和用户v的相似度,NBsu表示用户u的所有最近邻居集合,Pui表示用户u对项目i偏爱的预测评分值。其中,Pui值越大,说明用户u对项目i越喜欢。
本文使用皮尔森相关相似性PC方法作为用户之间的相似性计算,表达式如下:

公式(1)中:rui表示用户u对项目i的评分,rvi表示用户v对项目i的评分;表示用户u对其所评价过所有项目的均值,表示用户v对其所评价过所有项目的均值;Puv表示用户u和用户v评价过所有项目的公共项目集合。其中,sim(u,v)值越大,说明两个用户之间的相似度越高。
本文使用皮尔森相关相似性PC方法作为项目之间的相似性计算,表达式如下:
2 结合时间权重的协同过滤算法
2.1 用户时间权重
(1)用户评分可信度时间权重
本文使用m×n阶的用户评价时间矩阵来表示用户对项目的评价信息。其中,m个用户集合用集合U={u1,u2,…,um}表示,n个项目集合用集合I={i1,i2,…,in}表示,用户i对项目j评分时间用gij表示,用户i对项目j购买时间用bij表示(项目的购买时间及项目的评价时间都为为年月日,时间单位为天)。关于m×n阶的用户评价时间矩阵如表2所示。

表2 用户评价时间矩阵表

①用户等级因素:

公式(2)中:rui表示用户u对项目i的评分,ruj表示用户u对项目j的评分;表示评价过项目i的所有用户的评分均值表示评价过项目j的所有用户的评分均值;Uij表示项目i和项目j共同评价用户的公共用户集合。其中,sim(i,j)值越大,说明两个项目之间的相似度越高。
使用公式(1)计算预测评分值,即目标用户对项目的预测评分值,将项目月评分值的前TOP-N项目推荐给用户,预测评分公示如下:
公式(4)中:Lu为用户u等级的可信度,lu为用户u的会员级别。本文用户级别分为5个级别,用户级别越高其评分信用度也就越高(用户级别:铁牌1、铜牌2、银牌3、金牌4、钻石5)。
②商品时间特效因素:

公式(5)中:Tu表示用户u的时间权值(Tu∈[0,1]),sum表示用户u评价项目的总数,gui表示用户u对项目i的评分时间,bui表示用户u对项目i的购买时间。(gui-bui)的值越大,Tu越大,即用户评价项目时间与用户购买项目时间差越大,说明该用户的评论是比较客观而可信的,其评价过的项目也是可信的;反之,(guibui)的值越小,Tu越小,说明该用户的评论是比较主观而不可信的,其评价过的项目也是不可信的。公式(5)反映了用户评价项目的平均可信程度。
Wu为用户u的评分可信度,用户评分可信度公式如下:
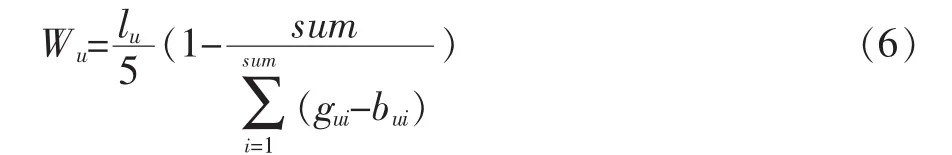
(2)用户兴趣时间权重
在日常生活中,用户的兴趣会随着时间而发生变化,而用户的兴趣对商品的销售量是有很大影响的。通常,用户近期所购买的商品为用户的短期兴趣,用户短期兴趣对项目可能未来受关注程度较为重要;而用户长期所购买的商品为用户的长期兴趣,用户的长期兴趣对项目可能未来受关注程度也有一定的影响。因此,本文通过将用户短期兴趣和长期兴趣相结合,引入用户兴趣时间权重的方法,提高项目的受关注程度,从而提高项目的推荐准确率。
用户短期兴趣时间权重公式定义如下:

公式(7)中,sP(u,i,tx)表示短时间内用户u对项目i在tx时刻的喜欢程度,tx表示某时刻时间值,ti表示用户u购买项目i的时间值(时间单位都为月)。其中(txti)值越小,因而sP(u,i,tx)值就越大,用户兴趣随时间的变化呈非递减性。说明项目i离现在的时间越近,则用户u越喜欢项目i。
用户长期兴趣时间权重公式定义如下:

公式(8)中,lP(u,i,tx)表示长时间内用户u对项目i在tx时刻的喜欢程度(tx∈T,T为定义的一个时间窗口集合),|IuT|表示用户u在T时刻时喜欢项目集合I的个数,C(x,y)表示项目x和项目y是否是同类型商品(C(x,y)=0不是相似类型项目,C(x,y)=1是相似类型项目,y∈|IuT|)。其中,C(x,y)值越大,因而lP(u,i,tx)值就越大,用户的长期兴趣受用户购买同类项目的总数影响。说明用户购买同类项目越多,用户越喜欢这类项目。
结合用户短期兴趣和长期兴趣时间权重公式定义如下:
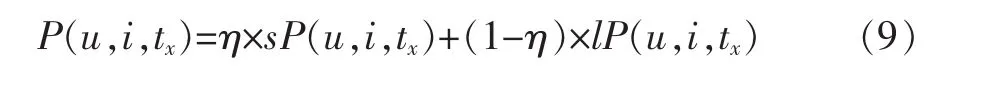
公式(9)中,η∈[0,1],影响因子η随着的取值不同,用户u对项目i的兴趣程度也会随之变化。
2.2 项目受欢迎度时间权重
在推荐系统中,由于受时间的影响,项目的受欢迎程度会发生改变,因此推荐的准确度也会被影响。一般项目随时间的变化呈现非递减性,而一些项目对不同的季节也比较敏感,如服装类产品、电器类产品、护肤类产品等,项目的受欢迎程度会随季节的变化而发生改变。
设集合T={t1,t2,…,tn},ti表示项目在i时刻卖出的项目总数(时间单位按月计算)。本文将受时间影响和受季节变化的这两种因素进行加权结合,项目时间权重公式定义如下:
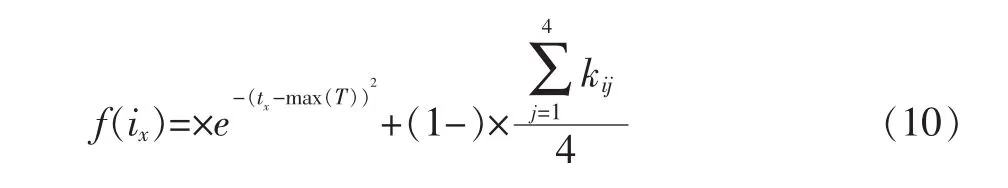
公式(10)中,f(ix)表示项目i在x时刻的受欢迎程度,max(T)表示卖出项目总数最多的时间值(T是从产品发布时间到现在的时间段集合),tx表示x时刻的时间值。Kij项目i在j季度是否敏感(Kij=0时项目对季节不敏感,Kij=1项目对季节敏感,j=1,2,3,4)。当tx-max(T)值越小,说明在tx时刻离受欢迎时刻越近,则在tx时刻项目i就越受欢迎。其中,λ∈[0,1],当影响因子λ变化时,项目受欢迎程度也会变换。
2.3 结合用户评分可信度时间权重的用户相似性算法
在皮尔森相关相似性PC算法中,用户相似性是对两个用户过去评论过的公共项目集合进行相似性计算。该算法在一定程度上实现了对用户之间的相似性计算,然而并未考虑用户在评论项目时该评价值是否可信。如果两个用户评价项目值都是可信的,两用户的相似度值较为可靠;如果两个用户评价项目值是不可信的,则两用户的相似度值就不会准确。为了提高两个用户之间相似性的准确度,本文将用户时间权重与皮尔森相关相似性PC算法相结合,公式定义如下:

公式(11)中:min(wu,wv)表示用户u和用户v评分可信度小的那个用户,|ru∩rv|/|ru∪rv|表示用户u、v公共评价项目集合与总评价项目集合的比值,用户评分可信度越大,用户之间公共评价项目越多,两个用户越相似。
2.4 结合用户兴趣时间权重的项目相似性算法
在皮尔森相关相似性PC算法中,项目相似性是对两项目过去被用户评论过的公共用户集合进行相似性计算。该算法在一定程度上实现了对项目之间的相似性计算,然而并未考虑用户对项目兴趣的改变。本文将用户兴趣时间权重与皮尔森相关相似性PC算法相结合,公式定义如下:
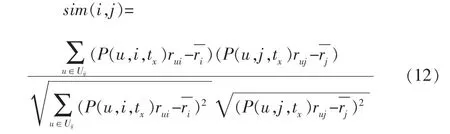
2.5 结合用户评分可信度和动态时间加权的预测推荐算法
公式(3)为用户u对项目i的预测评分值,由于该预测评分是根据用户之间的相似性来计算的,用户对项目的评分值是较为主观的,为提高预测分值的准确度,本文在考虑用户评分的可信度的变化情况下,对预测算法进行了修改,公式定义如下:
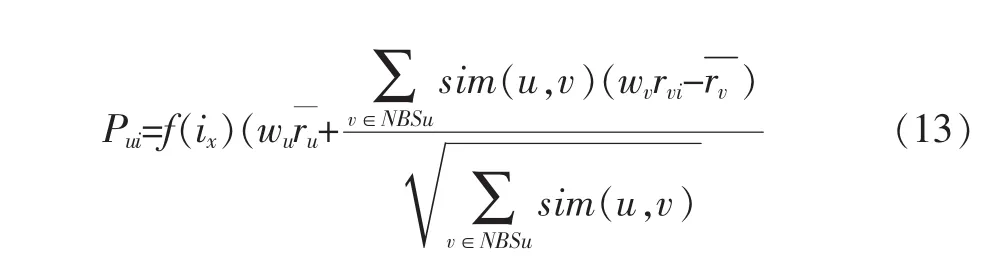
公式(13)中,sim(u,v)是公式(9)中基于用户时间权重后的用户相似性。
2.6 结合时间权重的协同过滤算法描述
输入:目标用户u,用户-项目评分矩阵R,用户时间评价矩阵T
输出:推荐给目标用户u的集合top-N
①根据用户时间评价矩阵使用公式(6),计算用户评分的可信度。
②根据用户-项目评分矩阵公式(12),计算项目的相似性。
③根据用户-项目评分矩阵使用公式(11),计算项用户间似性,然后根据计算出来的结果找到目标用户u的邻居集合U。根据用户u的邻居集合计算出用户未评分的项目集合Unot。
④判断推荐给用户的项目是否是新项目,如果是,执行⑤;如果不是,执行⑥。
⑤根据①,将用户未评分的项目集合Unot按可信度值从大到小排列,取前N个值推荐给用户u。
⑥将用户未评分的项目集合Unot用公式(13)计算出用户对项目的预测值,按从小到大排列,取前N个值推荐给用户u。
3 实验评估与分析
3.1 实验数据集
本实验采用某国内知名购物网站的数据集,由国内数据堂在线公布的数据集(http://www.datatang.com/ data/15516),可用于评论分析、情感计算、用户行为分析等研究领域。该数据集包含该网站上31万用户对18000件商品的165万条用户评论数据。其中评分值分为5个等级,评分值越高表示用户越喜爱(评分值范围1-5),0表示用户未买此商品或未对此商品进行评分。本实验数据集的数据稀疏性为:1-1650000/(310000× 18000)=99.97%,由此可知此用户评分数据的稀疏性是非常高。
3.2 评估标准
(1)预测质量方面
本文使用的是统计精度评价方法中一种常用的衡量预测结果的度量方法,即平均绝对误差(Mean Absolute Error,MAE),该方法就是通过统计用户对项目的实际评分和预测评分之间的差值,来判断预测的准确性(MAE越小,说明预测质量越高)。MAE计算公式如下:

Rui,m表示用户u对项目i的真实评分,Pui,m表示用户u对项目i的预测评分。
(2)推荐质量方面
本文是从荐全率(Precision)和荐准率(Recall)两个方面来评估推荐质量的准确度,即推荐质量标准F1。荐全率是评估推荐项目的全面性,荐准率是评估推荐项目的准确性,F1越大,则说明推荐质量越高。F1计算公式如下:

其中荐全率(Precision)和荐准率(Recall)的计算公式如下:

T为测试数据集中获得推荐的项目集合,V为推荐集合中推荐正确的项目集合,W为测试集中用户喜欢的所有项目集合。
3.3 实验结果
(1)调整用户兴趣时间权值参数
图1为基于时间用户兴趣度的不同取值对预测质量的影响(η=0.5,0.3,0.7)。当η=0.3时,用户兴趣度受长期兴趣度影响比短期兴趣度影响大;当η=0.5时,用户兴趣受长期兴趣度影响与短期兴趣度影响相同;当η=0.7时,用户兴趣受长期兴趣度影响比短期兴趣度影响小。根据图1呈现的结果可以看出,η不同取值对MEA值影响不同。根据图1中曲线可以求得不同影响因子η的MEA平均值,当η=0.3时,MEA平均值为0.766;当η=0.5时,MEA平均值为0.738;当η=0.7时,MEA平均值为0.771。由此可知,当η=0.5时,说明用户兴趣度对MEA值的影响最准确。在现实生活中,用户兴趣度受用户近期访问项目的影响和以前早期访问项目数据的影响是相同的。
结论(1):当用户长期兴趣度和用户短期兴趣度对用户兴趣度影响相同时,预测质量准确度最好。
(2)调整项目时间权值参数
图2为基于时间项目受欢迎度的不同取值对预测质量的影响(λ=0.5,0.3,0.7)。当λ=0.3时,项目受欢迎度受时间度影响度影响比受季节变化影响度影响大;当λ=0.5时,项目受欢迎度受时间度影响度影响与受季节变化影响度影响相同;当λ=0.7时,项目受欢迎度受时间度影响度影响比受季节变化影响度影响小。根据图2呈现的结果可以看出,λ不同取值对MEA值影响不同。根据图2中曲线可以求得不同影响因子λ的MEA平均值,当λ=0.3时,MEA平均值为0.775;当λ= 0.5时,MEA平均值为0.748;当λ=0.7时,MEA平均值为0.783。由此可知,当λ=0.5时,说明项目受欢迎度对MEA值的影响最准确。在现实生活中,随着时间变化,项目的受欢迎程度成非线性减弱。对项目长时间而言,大部分商品总会从受欢迎到淘汰;对项目季节而言,许多项目受季节影响,在特定的某个季节才会受欢迎,比如说受夏季的影响,电风扇需求量会比其他季节的需求量都大。
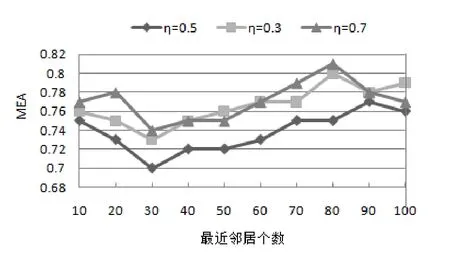
图1 参数η对MEA的影响
结论(2):当项目受时间影响度和项目受季节影响度对项目受欢迎度影响相同时,预测质量准确度最好。
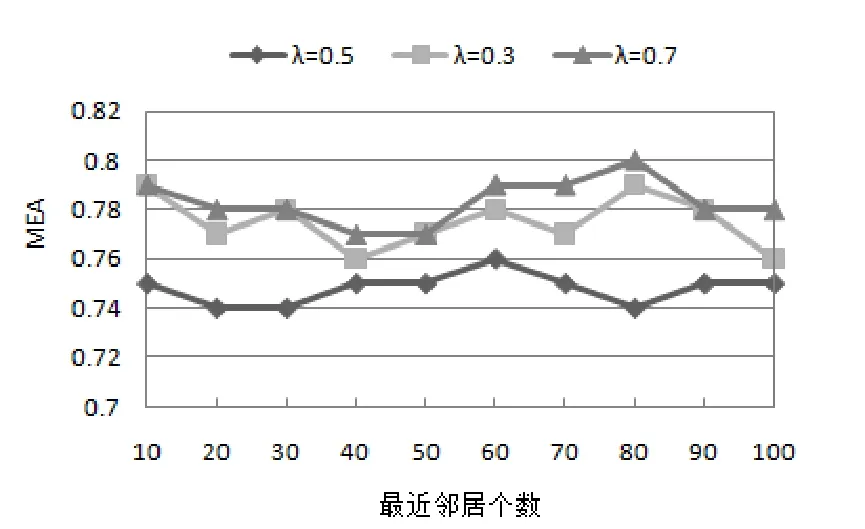
图2 参数λ对MEA的影响
(3)调整新项目推荐的用户评分可信度参数
图3为基于用户评分可信度的新项目推荐不同取值对推荐质量的影响(β>=0.6,0.7,0.8)。当β=0.6时,将新项目推荐给用户评分可信度大于0.6的用户;当β=0.7时,将新项目推荐给用户评分可信度大于0.7的用户;当β=0.8时,将新项目推荐给用户评分可信度大于0.8的用户。根据图3呈现的结果可以看出,β不同取值对MEA值影响不同。根据图3中曲线可以求得不同影响因子β的MEA平均值,当β=0.6时,MEA平均值为0.382;当β=0.7时,MEA平均值为0.347;当β=0.8时,MEA平均值为0.333。由此可知,当β=0.8时,说明推荐新项目的F1值最准确。在现实生活中,因为评分可信度高的用户会员等级高,购买东西多,信用度也高,所以将新项目推荐给用户评分可信度高的用户,推荐的新项目的准确率越好。因此通过使用用户评分可信度标准来解决新项目的冷启动问题。
结论(3):当推荐新项目时,用户评分可信度与新项目推荐准确率呈正相关性,即用户评分可信度越大,推荐准确率越高。

图3 参数β对F1的影响
(4)相似性模型比较
图4为相似性模型PC,COS,ACOS的MEA比较。如图4所示,本文从Jaccard系数和评分可信度进行优化,使用MEA进行比较。从图4可以看出,在PC相似性模型中,评分可信度相似性模型比Jaccard系数相似性高3%,比为优化相似性模型相似性高7%;在COS相似性模型中,评分可信度相似性模型比Jaccard系数相似性高4%,比为优化相似性模型相似性高9%;在ACOS相似性模型中,评分可信度相似性模型比Jaccard系数相似性高3%,比为优化相似性模型相似性高7%。由此可知,,评分可信度相似性模型的相似度比较好。与未优化的相似模型相比,Jaccard系数优化的模型可以根据用户/项目的公共集合自动调整大小,因此提高了相似性计算的准确度。但是由于用户评分的主观性,模型的性能会在一定程度上受到约束。评分可信度相似性模型是对Jaccard系数相似性模型进行优化,将Jaccard系数与用户评分可信度相结合,对用户的过去评分行为进行评分可信度的计算,通过降低用户评分的主观性误差,改善这种约束,从而提高相似性计算的准确度。
结论(4):与未优化相似性模型相比,评分可信度相似性模型提高了近7%的相似性计算;与Jaccard系数相似性模型相比,评分可信度相似性模型提高了近3%的相似性计算。因此可信度相似性模型对提高相似性计算是有效的。
(5)推荐模型比较
图5为不同推荐模型的F1比较。如图5所示,将本文的结合用户评分信用度和动态时间加权的协同过滤算法(UCTCF)与基于用户的系统过滤算法(UBCF)和基于项目的协同过滤算法相比较(IBCF)(UCTCF的F1值取最优)。根据图5可以求得不同推荐模型的F1平均值,IBCF的F1平均值为0.307,UBCF的F1平均值为0.284,UCTCF的F1平均值为0.354,由此可知,结合用户评分信用度和动态时间加权的协同过滤算法比传统推荐算法推荐性能好。
结论(5):与UBCF推荐模型相比,UCTCF推荐模型提高了近7%的推荐准确度;与IBCF推荐模型相比,UCTCF推荐模型提高了近4.7%的推荐准确度。因此UCTCF推荐模型对提高推荐准确度是有效的。
4 结语
本研究结果发现,结合评分可信度和动态时间加权推荐算法能有效地提高推荐准确率;当用户长期兴趣度和用户短期兴趣度对用户兴趣度影响相同时,预测质量准确度最好;当项目受时间影响度和项目受季节影响度对项目受欢迎度影响相同时,预测质量准确度最好;当推荐新项目时,用户评分可信度与新项目推荐准确率呈正相关性。本研究解决了新项目推荐的冷启动问题和时间概念漂移问题,优化了传统的相似性模型和推荐模型。由于本研究数据集是购物网站的数据集,根据用户的购买特点对原有的模型进行优化的,因此比较适合电子商务购物网站。
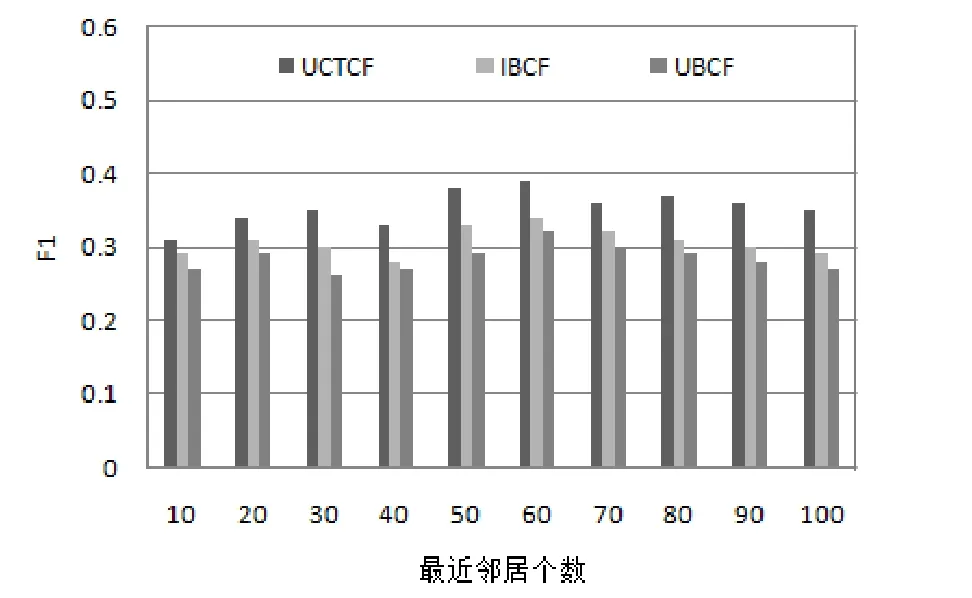
图5 推荐模型的F1比较
[1]Isinkaye FO etal.,Recommendation Systems:Principles,Methods and Evaluation,Egyptian Informatics(2015),http://dx.doi.org/ 10.1016/j.eij.2015.06.005.
[2]Silvia Puglisi,Javier Parra-Arnau,Jordi Forné,On Content-Based Recommendation and User Privacy in Social-Tagging Systems,Computer Standards&Interfaces 41(2015)17-27.
[3]Dong-sheng Li etal.Item-Based Top-N Recommendation Resilient to Aggregated Information Revelation.Knowledge-Based Systems,2014,67:290-304.
[4]Alper Bilge etal.Robustness Analysis of Privacy-Preserving Model-Based Recommendation Schemes.Expert Systems with Applications,2014,:3671-3681.
[5]Jing Zhang,Qin-ke Peng etal.Collaborative Filtering Recommendation Algorithm Based on User Preference Derived from Item Domain Features,Physica A,2014,:66-76.
[6]Nitin Pradeep Kumar,Zhen-zhen Fan.Hybrid User-Item Based Collaborative Filtering.Procedia Computer Science,2015,60:1453-1461.
[7]Ahmad A.Kardan,Mahnaz Ebrahimi.A Novel Approach to Hybrid Recommendation Systems Based on Association Rules Mining for Content Recommendation in Asynchronous Discussion Groups,Information Sciences,2013,219:93-110.
[8]Su Xiaoyuan,Khoshgoftaar T M.A Suervey of Collaborative Filtering Techniques[C].Proc.of Conference on Advances in Artificial Intelligence.[S.1.]:IEEE Press,2009:421-425.
[9]Chou AY.The Analysis of Online Social Networking:How Technology is Changing E-Commerce Purchasing Decision.Int'l Journal of Information Systems and Change Management,2010,4(4):353-365.[doi:10.1504/IJISCM.2010.036917]
Recommendation Algorithm Combining Score's Credibility and Dynamic Time Weighted
HUANG Lan,QIAN Yu-rong
(School of Software,Xinjiang University,Urumqi Xinjiang 830008)
To solve cold start problem which the new project recommends in e-commerce recommendation system and improve the similarity of user-user and item-item.Proposes a recommendation algorithm combining score's credibility and dynamic time weighted by contrasting the current recommendation algorithm.The proposed method introduces the credibility of users'ratings to compute the similarity of user-user and item-item.Then the new items are recommended to the user of high credibility.Dynamic time weighted function is constructed by analyzing the relationship between time and users'interests or the popularity of the project.Then the items are recommended to the user of high interests and the item of high popularity.The algorithm is verified by experiment that it compared with the traditional user-based collaborative filtering UBCF algorithm can improve the accuracy of nearly 7%of the recommended,and it compared with item-based collaborative filtering IBCF algorithm can improve the accuracy of nearly 4.7%of the recommended.At the same time,the algorithm solves the problem of cold start in recommendation of new project.
Recommendation System;Collaborative Filtering;Credibility;Time Weighted
国家自然科学基金项目(No.61562086、No.61462079、No.61363083、No.61262088)
1007-1423(2016)35-0013-08
10.3969/j.issn.1007-1423.2016.35.003
黄兰(1988-),女,四川遂宁人,硕士研究生,研究方向为大数据
钱育蓉(1980-),女,山东武城人,博士,副教授,研究方向为网络计算和遥感图像处理,E-mail:qyr@xju.edu.cn
2016-10-20
2016-11-25
