汉语塞−元−塞音序列语境效应机制探讨*
2016-02-01刘文理张明亮
刘文理 周 详 张明亮
(1南开大学周恩来政府管理学院社会心理学系, 天津 300350) (2山东行政学院, 济南 250014)
1 前言
言语声音知觉受到邻近言语语境的影响。如元音−流音音节/ar/和/al/, 或者擦音/s/和/ʃ/影响到随后/da/-/ga/连续体的知觉(Mann, 1980; Mann & Repp,1981)。元音/i/和/u/, 或者/e/和/o/, 影响到随后/ba/-/da/连续体的知觉(Coady, Kluender, & Rhode, 2003;Holt & Lotto, 2002)。不仅前面的言语语境影响到后面言语声音的知觉, 后面语境也能影响到前面声音的知觉。如元音/a/和/u/, /i/和/y/影响到前面擦音连续体/s/-/ʃ/的知觉(Mann & Repp, 1980; Mitterer, 2006;Smits, 2001)。探讨这种言语语境效应的机制不仅有助于了解人们感知言语声音的内在加工过程, 也有助于语音识别工程的开展。传统的语音识别模型注重单个声音声学线索的利用, 不关注语境如何影响到语音的识别, 这与人们识别语音的过程有很大差别(Lotto & Kluender, 1998)。如果语音识别模型能够综合语境效应, 可能会提高识别成绩。
自从言语知觉语境效应发现后, 研究者设计了大量的实验对此进行探讨, 并提出了几个理论模型解释这些言语语境效应。第一个理论是“协同发音的知觉弥补” (perceptual compensation for coarticulation)。这个理论认为言语知觉内隐的参照了言语产生的动作表征, 因而能够从知觉上弥补相邻音段由于协同发音所产生的同化效应(Fowler, Brown, & Mann,2000; Mann, 1980)。例如, 在流音−塞音序列中, 由于音段间的协同发音, 舌根塞音/g/的发音部位在流音/l/后相比在流音/r/后会被拉的更靠前, 因为/l/与/r/相比有一个更靠前的发音部位, 这会让/g/在发音部位和一些声学线索上更类似于/d/。同样, 齿龈塞音/d/的发音部位在音段/r/后会被拉的更靠后, 这让/d/在发音部位和一些声学特征上更类似于/g/。然而, 当语境是/al/时被试在感知/da/-/ga/连续体时会有更多的/g/反应, 语境是/ar/时被试会有更多的/d/反应。简而言之, 语境让目标音段的发音部位偏前,被试知觉到的目标音段发音部位就偏后, 反之亦然。因此, 知觉反应与协同发音的影响正好相反,协同发音的影响是一种同化效应, 被试的知觉反应似乎弥补了相邻音段间协同发音的影响。一些研究者认为这表明言语知觉参照了言语产生的动作表征, 从而为言语知觉的发音特征理论提供了支持,包括动觉理论(Liberman, Cooper, Shankweiler, &Studdert-Kennedy, 1967; Liberman & Mattingly, 1985)和直接知觉理论(Fowler, 1986)。动觉理论认为语音范畴的声学线索缺少恒常性, 恒常性只存在于音段发音的动作表征中, 言语知觉的最终目标是言语产生中的动作表征, 而非声学线索。直接知觉理论认为言语知觉是一个生态化的过程, 语音范畴的声学线索是近端事件, 言语的发音特征是远端事件, 远端的发音特征可以直接从近端的声学线索中通达。
第二个理论认为言语语境效应只是一般的听知觉现象, 可以由频谱对比机制来解释(Holt, Lotto,& Kluender, 2000; Lotto & Kluender, 1998)。以流音−塞音序列为例, 流音/l/有一个更高的F3(第三共振峰)终止频率, /r/有一个更低的F3终止频率。当被试识别/da/-/ga/连续体刺激时, 一个有更高频F3的刺激语境(/l/)会让被试对高频区产生适应, 敏感度下降, 而对低频区的敏感度会提高, 这让被试有更多的/g/反应, 因为/g/刺激有更低的F3起始频率。同样, 一个更低频的F3语境(/r/)会让被试有更多的/d/反应, 因为/d/刺激有更高的F3起始频率。这反映了听知觉中的一种频谱对比效应, 是一般的知觉现象。Lotto和Kluender (1998)发现非言语的语境,如模拟流音/l/和/r/的F3过渡段的调频正弦波滑音,或者频率等于/l/或/r/的F3终止频率的正弦波纯音,也能影响到/da/-/ga/序列的识别, 且影响方向与言语语境/al/和/ar/一致, 符合频谱对比效应的预期。这为言语语境效应只是听觉的一般现象提供了证据, 不管是言语语境还是非言语语境, 只要语境中提供了对比性的频谱成分, 就能诱发这种语境效应。
之后更多的实验发现了言语和非言语声音知觉中的这种相互影响(Coady et al., 2003; Holt, 2005, 2006;Holt et al., 2000; Lotto, Sullivan, & Holt, 2003; Stephens &Holt, 2003; Wade & Holt, 2005)。如Stephens和Holt(2003)发现言语语境能以对比的方式影响到后面非言语声音的知觉。Holt (2006)发现言语和非言语语境能够联合起来以一种合作或竞争的方式影响到目标音节的识别。这些实验结果再次表明语境效应并不特定于言语语境, 非言语语境也能诱发这种效应, 关键看语境声音和目标声音是否存在对比性的频谱特征。进而, 听觉理论者建议研究者应以一般听觉加工机制为基础来理解和研究言语知觉, 言语声音和非言语声音知觉在很多方面具有共通性, 言语知觉没有特殊性(Diehl, Lotto, & Holt, 2004; Holt &Lotto, 2008)。然而, 强调发音特征的理论者认为尽管言语声音和非言语声音都能诱发类似的语境效应,二者潜在的机制并不相同:言语语境效应表明听者的言语知觉内隐的参照了言语产生的动作表征, 是知觉对协同发音效应的弥补; 而非言语语境效应只是听觉的一种掩蔽效应(Fowler et al., 2000;Viswanathan, Fowler, & Magnuson, 2009; Viswanathan,Magnuson, & Fowler, 2010, 2013, 2014)。
另有研究者用语音学习来解释语境效应(Mitterer, 2006; Smits, 2001)。以擦−元音节为实验材料, Smits (2001)发现擦音连续体[ʃ]-[s]的识别受到后面元音[y]和[i]的影响。这种效应不能完全由元音关键的声学特征(F3)来解释, 被试给予元音的语音范畴标签解释了这种效应的大量变异, 即元音范畴的知觉影响到擦音范畴的知觉。Mitterer (2006)认为语境效应可能有不同的起源:对于流音−塞音序列(/r/和/l/对后面/da/-/ga/连续体识别的影响), 语境效应可能是一般听觉加工过程的产物, 如频谱对比效应; 对于擦音−元音序列, 这种效应主要是语音学习的结果, 听者习得了元音范畴如何引起擦音范畴声学模式的变化, 从而元音范畴知觉影响到前面擦音的识别。Mitterer (2006)认为语境音和目标音之间关键声学特征的相似性是一个重要因素:对于流−塞音序列, 二者间关键的声学线索(F3)处于同样的频率区, 这为听觉上的交互作用提供了空间,因而一般听觉加工机制可能负责了这类语境效应;对于擦−元音序列, 擦音极点频率和元音F3频率间隔超过了半个八度, 没有太多听觉上交互作用的空间, 经验诱导的语音学习可能更关键一些。
以上3个理论从不同角度对言语语境效应进行了解释。发音特征理论认为言语语境效应是听者对言语音段间协同发音效应知觉上的弥补, 言语知觉以言语动作表征为参照。听觉理论者认为言语语境效应可以用频谱对比效应进行解释, 只是一般知觉现象。另有理论强调语音学习在语境效应中的作用。近年来争论主要围绕发音特征理论和听觉理论展开(Fowler, 2006; Lotto & Holt, 2006; Viswanathan et al., 2010, 2013)。比较遗憾的是, 以往有关语境效应的例子通常难以区分发音特征理论和听觉理论的解释力度。如以研究最多的流音−塞音语境效应为例(/ar/和/al/对识别/da/-/ga/连续体的影响), 从发音特征理论角度看, /l/有较前的发音部位, /r/有较后的发音部位, 听者知觉时会弥补语境音发音部位的协同发音效应, 因而/ar/后听者会有更多的/da/反应(/da/相比/ga/有更靠前的发音部位), /al/后会有更多的/ga/反应, 实验结果与此一致。而从听觉理论角度看, /r/有较低的F3频谱, /l/有较高的F3频谱, 根据频谱对比效应假设, /ar/后听者会有更多的/da/反应(/da/有更高的F3起始频率), /al/后听者会有更多的/ga/反应(/ga/有更低的F3起始频率), 实验结果也与这个假设一致。因此, 就/r/和/l/对/da/-/ga/知觉的语境效应而言, 两种理论都可以解释, 难以区分。为了区分这两个理论的解释力度, Viswanathan等(2010)以英语和泰米尔语流音(/r/和/l/)为语境音, 考察了它们对/da/-/ga/连续体识别的影响。结果发现这些流音的语境效应与发音特征理论的预期一致, 且不能由这些流音的纯音模拟音进行解释。然而这个研究结果受到一些研究者的质疑, Kingston及其同事(2014)认为Viswanathan等人(2010)的研究中所使用的流音的纯音模拟音是一些频率固定的正弦波纯音或纯音复合音, 频率仅等于语境音节F2、F3或F4的终止频率, 他们并没有分析语境音节完整的共振峰轨迹。如果纯音模拟音能够模拟语境音节关键的或完整的共振峰轨迹, 这些非言语模拟音也许能够表现出与言语音节类似的语境效应。如果是这样,Viswanathan等人(2010)的研究结果也可以用听觉理论进行解释。
总之, 以往研究所使用的语境效应例子难以区分发音特征理论和听觉理论的解释力度。即使有研究者试图使用新的材料考察两个理论的解释力, 但由于没有全面分析语境音的声学特征, 使用了不恰当的非言语模拟音, 导致实验结果也难以区分两种理论的解释力(Kingston et al., 2014; Viswanathan et al., 2010)。为了区分发音特征理论和听觉理论对语境效应的解释力度, 当前研究创新性的采用同一塞音/p/与3个元音结合形成的3个音节/pa/、/pi/和/pu/为语境音, /ta/-/ka/连续体为目标音, 考察语境音对目标音识别的影响。/pa/、/pi/和/pu/作为语境音时能够使发音特征理论和听觉理论分别做出不同的预期, 这样就能根据实验结果检验两种理论的解释力度。根据发音特征理论, 语境音节的发音部位是最关键的因素。3个语境音节的塞音/p/的唇音发音部位是相对恒定的, 因而塞音所产生的语境效应应该是类似的。元音的发音部位在3个音节中有差别,/i/是前元音, 有最靠前的舌位; /a/也是前元音, 但舌位相比/i/稍微靠后; /u/是后元音, 有最靠后的舌位。因此整体上来看, 音节/pi/有最靠前的舌位, 其次是/pa/, /pu/的舌位最靠后。按照协同发音的知觉弥补假设, 语境音靠前的发音部位会让被试感知目标音时倾向于发音部位更靠后的语音范畴, /pi/音节做语境时被试应该会产生最多的/ka/反应(相比/ta/, /ka/的发音部位更靠后), 其次是/pa/音节, /pu/音节做语境时被试的/ka/反应最少。
根据听觉理论, 语境音节的声学特征是最关键的因素。3个语境音节和目标音连续体的简式语图见图1。塞音/p/在3个元音语境中关键的声学线索差异是F2起始频率和F2过渡段的朝向(英语塞音:Cooper, Delattre, Liberman, Borst, & Gerstman, 1952;Delattre, Liberman, & Cooper, 1955; 汉语塞音:Yan,1990)。/ta/-/ka/连续体最关键的声学线索差异是F3起始频率(从1800 Hz变化到2700 Hz, 构成一个连续体)。对于/pa/音节, F2的起始频率是800 Hz, 之后在60 ms内线性提高到1200 Hz。/pi/音节F2的起始频率是1600 Hz, 之后线性提高到2400 Hz。/pu/音节F2的起始频率是900 Hz, 然后线性下降到650 Hz。从声学特征来看, 只有音节/pi/的F2轨迹(从1600 Hz上升到2400 Hz)与目标音节/ka/的F3轨迹(从1800 Hz上升到2450 Hz)处于重叠的频率区, /pa/和/pu/音节的F2轨迹远离目标音节/ta/和/ka/的F3频率区(从1800 Hz或2700 Hz过渡到2450 Hz)。根据频谱对比效应的预期, /pi/音节作为语境时被试有更多的/ta/反应,因为/pi/音节的F2轨迹与目标音节/ka/的F3轨迹重叠,被试加工语境音节/pi/后听觉皮层对/pi/的F2轨迹产生适应, 导致被试随后在感知/ta/-/ka/连续体时对/ka/的F3线索也不够敏感, 因而被试会有更多的/ta/反应。而/pa/和/pu/作为语境时会产生怎样的语境效应并不明确。除了关键的F2轨迹, 语境音节的F1、F3和F4频率可能也会影响到/ta/-/ka/连续体的知觉。3个语境音节的F1轨迹类似, 都处于低频区。这些低频的声学线索要么对/ta/-/ka/连续体的知觉没有影响, 即使有影响, 它们的影响应该类似。3个语境音节的F3和F4频率是稳态的, 都处于同样的高频区, 包括接近2450 Hz的频率波段(/pi/音节的F2稳态频率值是2400 Hz)和等于或高于3000 Hz的频率波段。因而, 与低频区的声学线索类似, 这些高频区的声学线索要么对目标音节的知觉没有影响, 即使有影响, 它们的影响应该类似。综上, 3个语境音节关键的声学线索差异就是F2轨迹, 按照频谱对比效应假设的预期, /pi/音节作为语境会导致被试有更少的/ka/反应, /pa/和/pu/作为语境其效应并不明确。
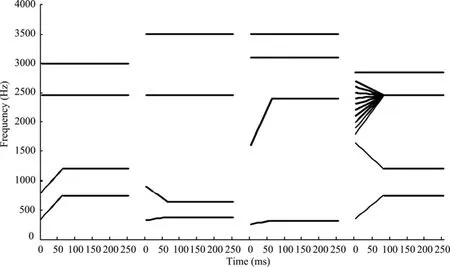
图1 语境音节和目标音节4个共振峰轨迹的简式语图
由此, 以/pa/、/pi/和/pu/作为语境音时, 发音特征理论和听觉理论做出了不同的预期。发音特征理论预期/pi/语境会导致被试产生最多的/ka/反应, 其次是/pa/语境, /pu/语境会产生最少的/ka/反应。而根据听觉理论, /pi/语境会导致被试有最少的/ka/反应,/pa/和/pu/语境的效应不明确, 可能不会影响到/ta/-/ka/连续体的识别。实验1将以/pa/、/pi/和/pu/作为语境音, /ta/-/ka/连续体作为目标音, 直接考察哪种理论与实验结果更吻合。
发音特征理论与听觉理论争论的另一个焦点是非言语声音的语境效应问题。听觉理论认为言语声音的语境效应可以由这些言语声音关键声学线索的非言语模拟音进行模拟, 二者有相同的机制。但是发音特征理论者认为非言语声音的语境效应与言语声音的语境效应潜在机制不同, 前者是一种听觉掩蔽效应。进而, Viswanathan等人(2010)的研究表明流音对塞音连续体识别的语境效应不能由流音的非言语模拟音进行解释, 但是这个研究没有全面分析语境音的声学特征, 使用的非言语模拟音只关注流音几个共振峰的终止频率, 这受到了后来研究者的质疑(Kingston et al., 2014)。当前研究在全面分析语境音声学特征的基础上, 在实验2和实验3中采用合适的非言语模拟音, 考察实验1中3个语境音节所表现出的语境效应是否能由非言语声音进行模拟。实验2的语境音是实验1中3个语境音节的F2轨迹的纯音模拟音。3个语境音节关键的声学线索差异即是F2轨迹, 实验2的目的是考察3个音节的F2模拟音对/ta/-/ka/连续体识别的影响是否与3个语境音节一致, 即3个音节的语境效应差异是否能由关键的声学线索差异来解释, 如果二者的效应一致, 则为基于声学线索分析语境效应的听觉理论提供了进一步支持。如果二者不一致, 则表明3个音节的语境效应差异不是由关键的声学线索差异(F2轨迹)引起的, 听觉理论的观点会受到质疑。但是实验2的非言语声音只模拟了实验1中3个语境音节的F2轨迹, 没有考虑其它的声学线索。事实上3个语境音节其它声学线索(F1、F3和F4)也存在细微的差异。如果实验1和实验2的结果不完全一致,也可能是由于语境音节其它线索存在差异引起的。实验3的目的是考察这种可能性。实验3使用的非言语声音模拟了3个语境音节所有的共振峰轨迹,即使用正弦波言语(采用正弦波纯音模拟言语声音所有的声学线索)作为语境音。通过对实验1三个语境音节所有声学线索的非言语模拟, 可以进一步考察实验1三个音节语境效应差异是否由于声学线索差异引起的, 特别是除F2轨迹之外的其它声学线索的作用。
2 实验1
实验1的语境音是3个塞−元音节/pa/、/pi/和/pu/, 目标音是/ta/-/ka/连续体。发音特征理论预期/pi/语境会导致被试产生最多的/ka/反应, 其次是/pa/语境, /pu/语境会产生最少的/ka/反应。听觉理论预期/pi/语境会导致被试有最少的/ka/反应, /pa/和/pu/语境的效应不明确, 可能不会影响到/ta/-/ka/连续体的识别。实验1的目的是考察哪种理论能够更好的解释当前实验的结果。
2.1 方法
2.1.1 被试
30名南开大学本科生参加了实验1, 被试母语为汉语, 男女被试各半, 平均年龄21.2岁。被试的视力或矫正视力正常, 听力正常。实验后付给报酬。
2.1.2 刺激
语境音节和目标音节都使用Klatt合成器合成,刺激时长250 ms。语境音节的合成参数见表1。每个语境音节都由一个60 ms的共振峰过渡段和一个190 ms的稳态部分组成。F1和F2频率在最初60 ms内由起始频率线性上升或下降到稳态频率, 之后频率维持恒定。F3和F4频率一直维持稳态。基频(F0)在整个音节时长内由130 Hz线性下降为120 Hz。目标音节是由10个刺激组成的/ta/-/ka/连续体, 通过变化F3起始频率合成。F3起始频率以100 Hz为步长从1800 Hz变化到2700 Hz构成连续体上的10个刺激。最初80 ms的共振峰过渡段之后, F3频率抵达2450 Hz的稳态值。F1频率在80 ms的过渡段内从350 Hz上升到750 Hz, 之后170 ms维持稳态。F2频率在80 ms过渡段内从1650 Hz下降到1200 Hz, 之后维持稳态。F4频率固定在2850 Hz。/ta/-/ka/序列刺激的F0曲线与语境音节完全一致。语境音节和目标音节都以16 bit分辨率和10 kHz抽样率进行合成。每个音节的平均RMS (root mean square)能量相等。将3个语境音节和/ta/-/ka/连续体上的10个目标音节进行拼接, 共构成30个刺激项目, 语境音节和目标音节间间隔50 ms。
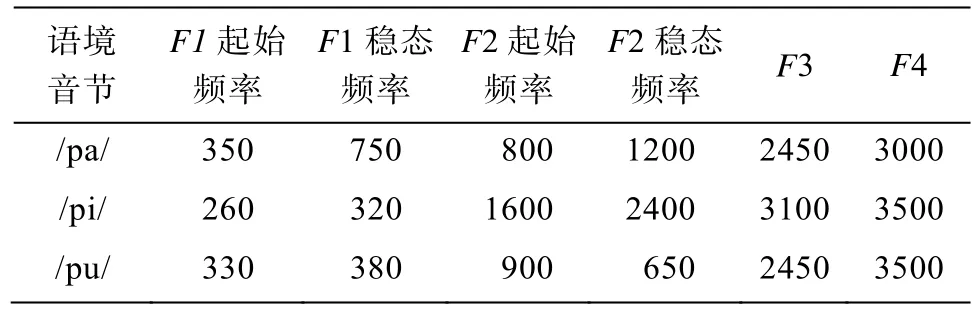
表1 实验1语境音节的合成参数(Hz)
2.1.3 程序
实验1包括4个实验条件。被试首先完成一个基线条件, 基线条件下仅呈现/ta/-/ka/连续体上的10个目标音节, 每个音节呈现10次, 要求被试识别所呈现的刺激是/ta/还是/ka/。正式识别前被试先进行一个简短的练习, 两个端点刺激(最清晰的/ta/和/ka/)每个呈现10次要求被试进行识别。实验程序及刺激呈现皆由praat软件完成。基本程序如下:首先呈现指导语, 被试点击鼠标实验开始, 屏幕上呈现左右两个黄色方框, 一个方框内标有“da”, 另一个方框内标有“ga” (此处用汉语拼音代替音标进行标示, 因为被试对汉语拼音非常熟悉, 通常不熟悉音标标音法)。之后声音刺激依次呈现(呈现顺序随机), 每个刺激呈现后, 被试判断该刺激是“da”还是“ga”, 用鼠标点击相应的黄色框进行反应, 被试反应不限时。反应后间隔2s呈现下一个刺激。
基线条件之后, 被试完成3个有语境音节(/pa/、/pi/和/pu/)的识别条件, 3个条件的顺序在被试之间进行了平衡。每个条件下被试首先完成练习, 语境音节与两个端点刺激结合每个呈现10次构成练习项目。正式识别任务语境音节与/ta/-/ka/连续体上的10个刺激结合每个呈现10次(每个语境音节100个项目)。带有语境音的识别条件与基线条件的程序基本相同:首先呈现指导语, 指导语要求被试识别语境音后面的刺激是“da”还是“ga”。被试点击鼠标任务开始, 声音刺激按随机顺序依次呈现(每个刺激都由语境音与目标音构成, 二者间间隔50 ms)。被试用鼠标点击标有“da”或“ga”的方框进行反应。反应后间隔2s呈现下一个刺激。最后在基线条件和3个语境条件之间还有一个简短的识别任务。3个语境音节每个呈现10次要求被试进行识别, 被试用鼠标点击标有“ba”、“bi”和“bu”的方框进行反应。
实验在安静的实验室里进行, 被试个别施测。刺激通过封闭式耳机(Sennheiser PX360)呈现, 音量调整到舒适的水平。整个实验约持续45 min。
2.2 结果
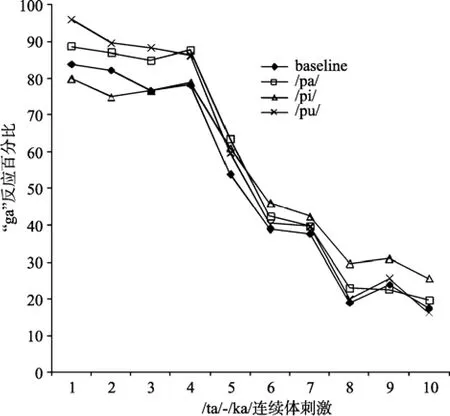
图2 基线(baseline)和3个语境条件(/pa/、/pi/和/pu/)下被试在/ta/-/ka/连续体上各刺激平均的“ga”反应比率
2.3 讨论
听觉理论的频谱对比效应预期/pi/音节作为语境时被试会有最少的“ga”反应, 最多的“da”反应,因为/pi/与端点刺激/ta/有对比性的频谱成分; /pa/和/pu/做语境时语境效应方向并不明确。而发音特征理论预期/pi/音节做语境时被试会有最多的“ga”反应,其次是/pa/音节, /pu/音节会产生最少的“ga”反应。
实验1的结果表明/pi/音节作为语境时产生了最少的“ga”反应, 在刺激1~2上的“ga”反应显著的少于/pu/语境条件, 在刺激2上的“ga”反应与/pa/语境条件差异边缘显著。/pa/语境产生的“ga”反应数量居中,与基线条件没有显著差异。音节/pu/充当语境时被试有最多的“ga”反应, 除在刺激1~3上多于/pi/语境外, 在刺激1和3上也多于基线条件。实验结果与听觉理论的预期更为一致, 与发音特征理论的预期几乎相反。听觉理论的频谱对比效应预期/pi/语境会产生最少的/ka/反应, 这与实验结果相吻合。另外实验结果发现/pa/和/pu/语境也影响到/ta/-/ka/连续体的识别, 二者都导致被试有更多的/ka/反应, /pu/语境下被试的/ka/反应比率甚至显著高于基线条件。频谱对比效应假设难以解释这种现象, 这与Mitterer (2006)的观点也不一致。Mitterer (2006)认为只有语境音与目标音共享关键的声学特征, 二者才有听觉交互作用的可能。但是音节/pa/和/pu/与目标音节并不共享关键的声学特征, 它们仍然影响到/ta/-/ka/连续体的识别。3个语境音节这种语境效应模式能由关键的声学线索差异(F2轨迹)来解释吗?实验2用非言语声音模拟了3个语境音节的F2轨迹, 目的是考察3个非言语声音的效应模式与3个语境音节的效应模式是否一致。
3 实验2
实验2的语境声音是3个非言语声音, 分别模拟了实验1三个音节/pa/、/pi/和/pu/的F2轨迹。实验2的目的是考察实验1中3个音节的语境效应差异是否源于关键声学线索(F2轨迹)的差异:如果3个音节的语境效应差异源于关键声学线索的差异, 那么3个非言语声音的语境效应模式应该与3个音节一致;如果3个非言语声音的语境效应与3个言语声音的语境效应不一致, 则说明实验1中3个音节的语境效应差异不是由关键声学线索差异引起的, 可能存在其它的原因。
3.1 方法
3.1.1 被试
南开大学26名本科生参加了实验2, 被试母语为汉语, 男女被试各半, 平均年龄20.8岁, 所有人都没有参加实验1。被试的视力或矫正视力正常,听力正常。实验后付给报酬。
3.1.2 刺激
3个非言语声音分别模拟了音节/pa/、/pi/和/pu/的F2轨迹。每个非言语声音都包括一个60 ms的调频正弦波滑音(模拟共振峰过渡段)和一个190 ms的频率恒定的正弦波纯音(模拟稳态频率段)。对于音节/pa/的F2模拟音, 起始60 ms滑音段的频率从800 Hz线性提高至1200 Hz, 之后190 ms的纯音段频率稳定在1200 Hz。对于音节/pi/的F2模拟音, 起始60 ms滑音段的频率从1600 Hz线性提高至2400 Hz,之后190 ms的纯音段频率固定在2400 Hz。音节/pu/的F2模拟音起始60 ms滑音段的频率从900 Hz线性下降到650 Hz, 之后190 ms纯音段频率稳定在650 Hz。目标音节同实验1。3个F2模拟音的抽样率和分辨率同言语语境。非言语声音和言语声音的RMS能量相互匹配。将3个F2模拟音分别与/ta/-/ka/连续体上的10个刺激进行拼接, 构成30个刺激项目, 语境声音和目标音节间间隔50 ms。3个非言语F2模拟音和目标音节的简式语图见图3。
3.1.3 程序
被试首先完成基线条件, 基线条件仅呈现/ta/-/ka/连续体上的10个刺激, 要求被试进行识别。练习和正式识别的程序同实验1。接下来被试完成3个带语境音的识别条件, 3个条件之间的顺序在被试间进行平衡。每个条件下练习和正式识别程序同实验1。整个实验约持续40 min。
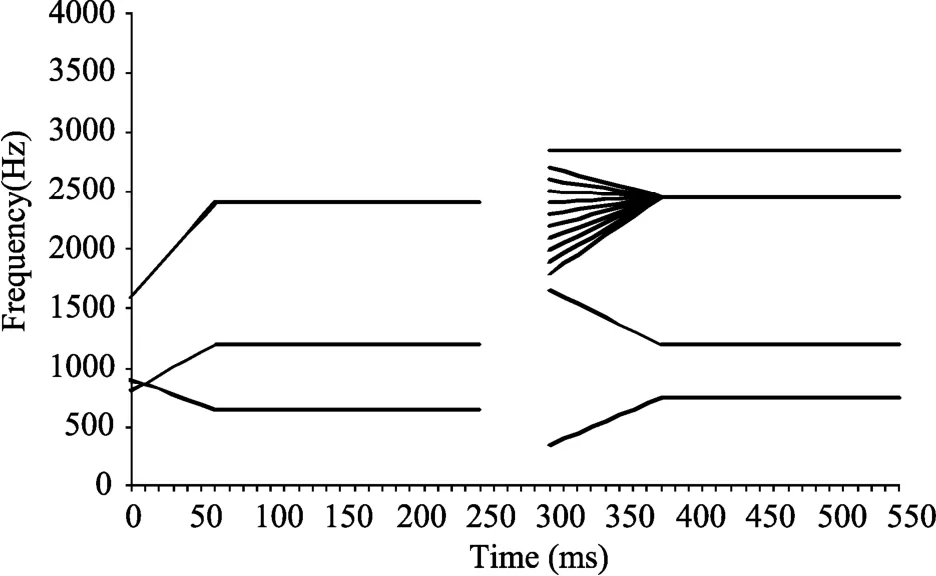
图3 三个非言语F2模拟音(左侧)和/ta/-/ka/连续体(右侧)的简式语图
3.2 结果
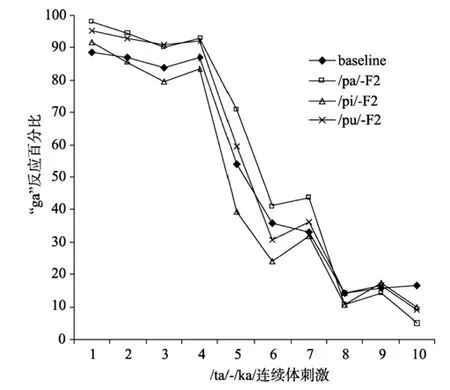
图4 基线和3个F2模拟音条件下被试在/ta/-/ka/连续体10个刺激上平均的“ga”反应比率
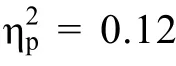
3.3 讨论
实验2结果分析表明/pa/的F2模拟音诱发了最多的“ga”反应:在刺激1、2和5上的“ga”反应显著的多于基线条件, 在刺激1-5上的“ga”反应显著的多于/pi/-F2条件。/pu/的F2模拟音诱发了第二多的“ga”反应:在刺激4-5上的“ga”反应显著的多于/pi/-F2条件。/pi/的F2模拟音产生了最少的“ga”反应, 在刺激5上的“ga”反应甚至显著的少于基线条件。
实验2与实验1的结果总体上很相似, /pi/和/pi/的F2模拟音作为语境音被试都有最少的“ga”反应,/pa/和/pu/及它们的F2模拟音做语境时被试都产生了更多的“ga”反应。这表明音节/pa/、/pi/和/pu/之间的语境效应差异很大程度上源于关键声学线索的差异, 即3个音节F2轨迹的差异, 这为基于声学线索分析语境效应的听觉理论提供了进一步的支持。实验2的结果也再次表明与目标音节关键声学特征间隔较远频率区的声学线索也能影响到目标音节的识别:/pa/和/pu/的F2模拟音所产生的“ga”反应显著的多于/pi/-F2条件, /pa/的F2模拟音所产生的“ga”反应也显著的多于基线条件。
尽管实验1和实验2的结果整体上比较类似,二者之间也存在细微的差异。一个差异是/pa/、/pi/和/pu/三个音节的语境效应要小于它们的F2模拟音。另一个差异是在实验1中, /pu/音节诱发了最多的“ga”反应, 但在实验2中/pa/音节的F2模拟音诱发了最多的“ga”反应。因此实验1和实验2的结果不完全一致。有两个可能的原因导致了这种差异。一个原因是语境音节中其它声学线索的存在导致了实验1和实验2结果的差异。因为实验2的非言语声音只模拟了语境音节的F2轨迹, 并没有考虑其它的声学线索。虽然语境音节除F2轨迹之外的其它声学线索(F1、F3和F4轨迹)大体上是匹配的, 但并没有绝对的匹配, 这些其它声学线索的差异可能导致了3个音节和其F2模拟音的语境效应存在一些差异。另一个可能是语境音节的语音范畴标签导致实验1和实验2的结果存在差异。实验1的3个语境音节除声学线索差异外, 还可以分别感知为/pa/、/pi/和/pu/三个言语声音, 既有相同的/p/范畴, 也有不同的3个元音范畴/a/、/i/和/u/。而实验2的3个非言语声音只是一些声学线索, 不能感知为语音范畴,即缺少语音标签, 这也可能是实验1和实验2的结果存在差异的原因。
实验3的目的是进一步考察实验1和实验2结果存在差异的原因, 更深入的揭示实验1的塞−元−塞音序列语境效应的来源和潜在机制。实验3的语境声音仍然采用3个非言语声音, 但这3个非言语声音模拟了实验1三个音节的全部声学线索, 即使用正弦波纯音模拟言语声音的全部共振峰轨迹。这属于一种正弦波言语, 正弦波言语在没有指导的时候被试很难将之感知为言语, 特别是单音节的声音(Remez, Rubin, Pisoni, & Carrell, 1981)。通过使用正弦波言语, 实验1和实验3的语境声音在声学线索方面匹配的更全面, 如果实验2与实验1的结果差异是由于其它声学线索差异引起的, 我们预期实验3的正弦波言语将展现出与实验1的言语声音类似的语境效应。如果实验2与实验1的结果差异不是由于其它声学线索差异引起的, 我们预期实验3与实验1的语境效应仍然会存在差异, 实验1中3个音节的语境效应差异可能部分的起源于语音范畴感知的影响。
4 实验3
实验3以3个音节/pa/、/pi/和/pu/的正弦波言语为语境音, 目的是进一步考察除关键声学线索F2之外的其它声学线索在3个音节语境效应差异中所起到的作用。如果其它声学线索是实验1和实验2语境效应差异的来源, 我们预期实验3会表现出与实验1相同的语境效应模式。否则, 实验1的语境效应差异可能有其它的原因, 如语音范畴感知的影响。
4.1 方法
4.1.1 被试
21名南开大学学生(男生11名)参加了实验3, 被试母语为汉语, 平均年龄23.8岁, 所有被试都没有参加实验1和2。被试视力或矫正视力正常, 听力正常。实验后付给报酬。
4.1.2 刺激
实验3的语境刺激是音节/pa/、/pi/和/pu/的正弦波言语。正弦波言语模拟了3个言语音节所有的共振峰轨迹(见图1)。3个音节的共振峰过渡段(包括前60 ms的F1和F2过渡段)采用调频的正弦波滑音进行模拟, 共振峰稳态部分(包括F1和F2的稳态部分, 以及F3和F4)采用频率恒定的正弦波纯音进行模拟。模拟后的正弦波言语的简要语图见图1。目标刺激仍然是/ta/-/ka/连续体。所有刺激的抽样率、分辨率及RMS能量都互相匹配。3个语境音分别与/ta/-/ka/连续体上的10个刺激进行拼接, 构成30个刺激项目, 语境声音和目标音节间间隔50 ms。
4.1.3 程序
被试首先完成基线条件。基线条件仅呈现10个目标刺激, 每个呈现10次要求被试进行识别。正式测试前先进行练习。练习和正式识别程序同实验1。基线条件后被试完成3个带语境音的识别条件, 3个条件的测试顺序在被试间进行了平衡。每个条件下练习和正式识别程序同实验1。整个实验约持续40 min。
4.2 结果
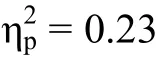
4.3 讨论
实验3的结果分析表明/pa/-SWS条件下被试产生了最多的“ga”反应, 在刺激5~7以及刺激9上显著的多于/pi/-SWS条件, 在刺激5上显著的高于/pu/-SWS条件, 在刺激9上显著的高于基线条件。/pu/-SWS和基线条件下被试产生的“ga”反应数量居中, 二者无显著差异。/pi/-SWS条件下被试产生了最少的“ga”反应, 但与/pu/-SWS和基线条件下的差异没有达到统计上的显著水平。
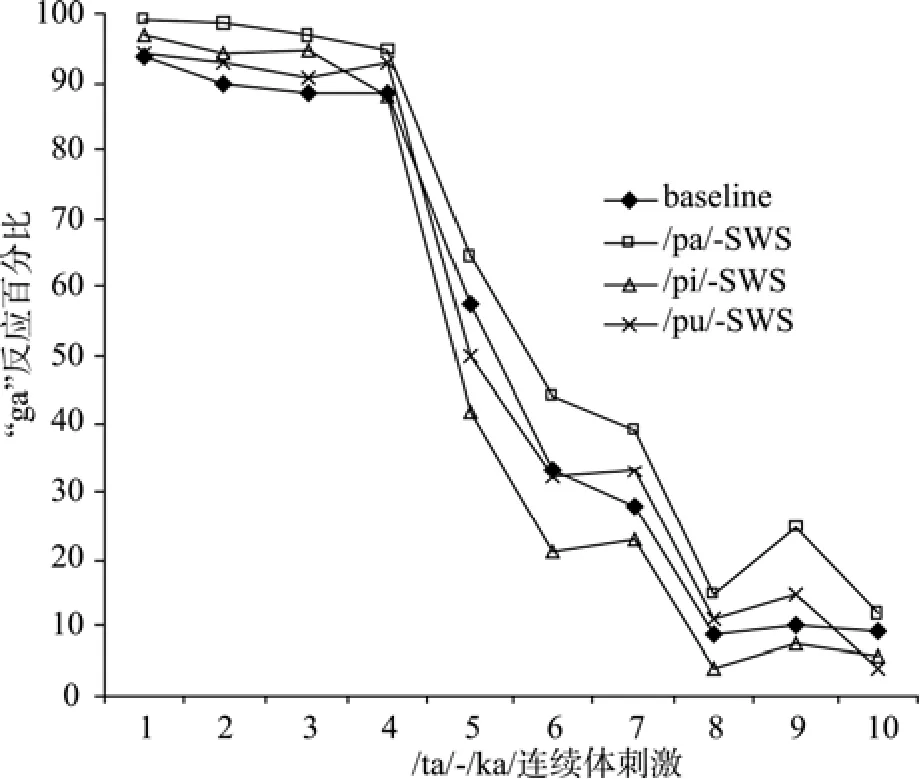
图5 基线条件及3个正弦波言语条件下被试在/ta/-/ka/连续体各刺激上平均的“ga”反应百分比
实验3的结果整体上与实验2非常类似, 都是/pa/的模拟音条件下被试产生了最多的“ga”反应, 其次是/pu/的模拟音条件, /pi/的模拟音条件被试产生了最少的“ga”反应。实验3以正弦波言语为语境音, 正弦波言语模拟了实验1中3个语境音节的全部共振峰轨迹, 只是被试不能将之感知为言语。但是实验结果发现3个正弦波言语所产生的语境效应与只模拟3个音节F2轨迹的非言语声音所产生的语境效应类似。这表明3个正弦波言语的语境效应差异应该主要源于它们的F2轨迹差异。这是可能的, 虽然3个正弦波言语除F2之外的其它共振峰模式存在细微差异,但它们总体上是匹配的, 如F1轨迹都处于低频区, F3和F4都处于高频区(见图1), 它们对/ta/-/ka/连续体知觉的影响在3个正弦波言语中应该是类似的。因此3个正弦波言语的语境效应差异还是源于它们最关键的声学线索差异, 即F2轨迹。这也导致实验3和实验2的结果总体上非常相似。
3个正弦波言语与3个音节整体的声学线索是互相匹配的, 但实验3的语境效应模式仍然与实验1存在差别。这表明实验1中3个音节的语境效应模式不完全是由于它们的声学线索差异引起的, 也表明实验1和实验2的语境效应差异不是由于其它声学线索(F1、F3和F4)差异引起的。实验2和实验3所使用的非言语声音与实验1的言语音节最重要的一个差别就是能否感知为语音。即使实验3的正弦波言语模拟了言语音节所有的共振峰轨迹, 但是仍然不能感知为言语。由此实验1中3个音节所表现出的语境效应模式至少部分的源于它们的语音范畴感知, 特别是与实验2和实验3的结果存在差别的部分。实验1与后面两个实验结果存在差别的地方主要有两点。一是/pa/、/pi/和/pu/三个音节的语境效应要小于它们的F2模拟音和正弦波言语所产生的语境效应, 方差分析发现3个音节的F2模拟音及正弦波言语条件下的语境主效应都显著, 而3个音节的语境主效应没有达到显著。这可能由于3个音节有共同的塞音范畴感知, 尽管塞音/p/在3个音节中的声学线索有差异, 但它们都能被感知为/p/。这种共同的语音范畴标签可能降低了声学线索差异所驱动的语境效应。而它们的F2模拟音和正弦波言语没有共同的语音范畴标签, 可能更能展现出声学线索差异所引起的语境效应。第二个差别是实验1中/pu/音节诱发了最多的“ga”反应, 但在实验2和实验3中/pa/音节的非言语模拟音诱发了最多的“ga”反应。这可能由于3个音节中元音范畴感知差异引起的, 元音/u/是圆唇元音, 而/a/和/i/是非圆唇元音,圆唇能够降低声学线索中F2的频率, 可能对后面/ta/-/ka/连续体的知觉产生影响, 导致/pu/语境产生了最多的“ga”反应。而实验2和实验3的非言语模拟音缺少语音范畴感知, 因此没有表现出这种模式。
5 总讨论
当前研究通过3个实验考察了汉语塞−元−塞音序列语境效应的潜在机制, 探讨了听觉理论和发音特征理论对言语语境效应的解释力度。实验1以3个塞−元音节/pa/、/pi/和/pu/为语境音, /ta/-/ka/连续体为目标音。通过对3个音节发音部位的分析, 发音特征理论预期被试“ga”反应比率在/pi/语境下最大, 其次是/pa/语境, /pu/语境下最小。而根据3个音节的声学特征, 听觉理论(频谱对比效应)预期/pi/语境下被试的/ga/反应最少, /pa/和/pu/语境的效应方向不明确。实验结果发现/pi/语境下被试产生了最少的“ga”反应, 其次是/pa/语境, /pu/语境下被试产生了最多的“ga”反应。这与听觉理论的预期更一致, 与发音特征理论的预期相反。但是听觉理论主要基于频谱对比效应做出预期, 这正确的预测了/pi/语境的效应方向, 不能解释/pa/和/pu/及其非言语模拟音的语境效应, 这在后面会进一步讨论。鉴于3个音节主要的声学线索差异是它们的F2轨迹,它们的语境效应差异是源于这种关键声学线索的差异吗?实验2以实验1三个音节F2轨迹的非言语模拟音为语境音, 考察了这种可能性。结果发现/pa/的F2模拟音产生了最多的“ga”反应, 其次是/pu/的F2模拟音, /pi/的F2模拟音产生了最少的“ga”反应。这与实验1的结果整体上是一致的, 表明/pa/、/pi/和/pu/三个音节语境效应差异主要源于它们关键的声学线索差异, 即第二共振峰(F2)模式的差异。这为基于声学线索分析和解释语境效应的听觉理论提供了进一步的支持。
除了总体上的相似性, 实验1和实验2的结果也存在一些差异, 包括实验1的语境效应更小、/pu/语境有最多的“ga”反应, 而实验2语境效应更大,/pa/音节的F2模拟音有最多的“ga”反应。这表明虽然实验1三个音节的语境效应主要源于它们F2轨迹的差异, 但F2轨迹差异不能完全解释3个音节的语境效应模式。3个音节的语境效应差异应该还有其它的原因。比较实验1和实验2的语境刺激, 主要有两个差别, 一是3个音节还包括除F2之外的其它共振峰线索, 这些共振峰所处的频率区虽然在3个音节中总体上是匹配的, 但是还存在细微的差别, 有可能是这些非关键的共振峰轨迹导致了实验1和实验2语境效应的差别。另一个区别是实验1是言语语境, 可感知为语音范畴, 而实验2是非言语语境, 无法感知为语音范畴。这可能也是实验1和实验2语境效应差异的一个来源。实验3对这两种解释进行了考察, 实验3的语境音是3个音节的正弦波言语, 正弦波言语模拟了3个音节所有的共振峰轨迹,这样实验1和实验3的语境音在声学线索上是匹配的,二者主要的差别是实验1的语境音可感知为言语,而实验3的语境音很难感知为言语。如果实验1和实验2的语境效应差别是因为实验1的语境音中其它声学线索的存在, 那么声学线索匹配后实验1和实验3的语境效应应该更类似。实验3的结果分析表明/pa/的正弦波言语产生了最多的“ga”反应, 其次是/pu/的正弦波言语, /pi/的正弦波言语产生了最少的“ga”反应。这与实验2的结果类似, 与实验1的结果仍然存在差异。这表明实验1与实验2及实验3的语境效应差异不是由于其它声学线索的作用,更可能是由于实验1的语境音能够感知为语音范畴。语音范畴感知对3个音节的语境效应产生了一定的影响, 导致实验1的语境效应模式和后面两个实验存在一些差别。
综上, 3个实验结果表明当前研究中的汉语塞−元−塞音序列语境效应差异主要起源于语境音关键声学线索的差异, 但是语境音的语音范畴感知也能调节它们的语境效应表现。总体上, 实验结果为基于声学线索分析语境效应的听觉理论提供了支持。但是听觉理论忽视了语音范畴感知对语境效应的影响, 当前实验结果对听觉理论观点是一个补充, 语境音的语音范畴也能一定程度上影响到它们的语境效应模式。事实上, 一些研究者认为语音学习和语音范畴感知是语境效应的一个重要来源(Mitterer,2006; Smits, 2001)。实验结果没有支持基于发音部位分析语境效应的发音特征理论, 即语境效应可能不是由于协同发音的知觉弥补, 更多的是由于听者对语境音中声学线索的听觉加工及语音范畴感知影响到后面目标音的知觉和识别。
当前实验结果对听觉理论的另一个重要补充是声学线索产生语境效应的模式不仅仅是频谱对比效应。听觉理论者主要依据频谱对比效应解释言语和非言语声音的语境效应。频谱对比效应假设认为存在对比性频谱成分的语境声音能以对比的方式影响到目标音节的识别, 潜在机制可能是语境音中关键频谱成分的激活导致听觉皮层加工的适应, 这种适应会使得目标音节中与语境音相同的频谱成分激活下降,因而被试会更多的以具有对比性频谱成分的范畴进行反应(Holt, 2006; Holt & Lotto, 2002; Holt et al.,2000; Lotto & Kluender, 1998)。如当前研究中语境音节/pi/的F2轨迹与目标音节/ka/的F3轨迹几乎重叠(具体分析见前言与图1), 按照频谱对比效应的预期,被试加工语境音节/pi/后听觉皮层对/pi/的F2轨迹产生适应, 导致被试随后在感知/ta/-/ka/连续体时对/ka/的F3线索也不够敏感, 因而被试会更多的以/ta/进行反应。这个理论正确的预期了/pi/音节及其非言语模拟音所产生的语境效应, 它们在3个实验中确实诱发了最少的“ga”反应。但是这个理论难以解释/pa/和/pu/及其非言语模拟音的语境效应。/pa/和/pu/的F2轨迹及其F2模拟音都处于低频区(/pa/:从800 Hz到1200 Hz; /pu/:从900 Hz到650 Hz), 与目标序列/ta/-/ka/连续体的F3频率区(从1800 Hz到2700 Hz)间隔较远, 但它们仍然影响到/ta/-/ka/连续体的识别, 都导致被试产生了更多的“ga”反应(在一些条件下甚至显著的多于基线条件)。如果按照频谱对比效应的解释, 即使存在适应效应, 这些低频的声学线索也只能引起/ka/音节F3过渡段的适应(相比/ta/音节, /ka/音节F3过渡段的频率更低), 从而会让被试产生更多的/ta/反应。然而实验结果却发现/pa/和/pu/及其非言语模拟音做语境时被试产生了更多的/ka/反应。因此频谱对比效应假设难以解释/pa/和/pu/及其非言语模拟音的语境效应。
如何解释这种语境效应呢?一种可能性是这些低频的声学语境激活了一些声学线索, 这些声学线索促进了/ka/范畴的识别。众多研究发现齿龈塞音/d/的典型声学线索包括一个高频的爆破段和一个起始频率在1500~1800 Hz左右的下倾的共振峰过渡段, /d/的频谱能量集中于高频区; 舌根塞音/g/的典型声学线索包括一个中频的爆破段和一个1~2 kHz之间的共振峰过渡段, 通常会有一个突显的中频频谱峰(Cooper et al., 1952; Delattre et al., 1955;Li, Menon, & Allen, 2010; Stevens & Blumstein,1978)。汉语塞音/t/和/k/也发现了类似的声学特征。塞音/t/爆破段的能量集中于高频区(约3000~4000 Hz左右); 塞音/k/的爆破段通常有两个频谱峰, 一个突显的中频峰(约1400 Hz左右)和一个稍弱的高频峰(阳晶, 陈肖霞, 2005)。由此塞音/t/的频谱能量主要集中于高频区, 而塞音/k/的能量主要集中于中频区, /pa/和/pu/音节及其非言语模拟音这些低中频的共振峰轨迹可能激活了一些能量集中于低中频区的声学线索, 这些低中频区的声学线索又促进了/ka/范畴的识别。研究也表明/ga/的知觉主要由中频的爆破段决定(Li et al., 2010)。按照这个假设, 可以预期有高频共振峰轨迹的语境音会促进/ta/范畴的识别。初步实验证实了这个预期, 8名汉语听者参加了一个小测验, 60 ms高频和低频滑音充当语境音, /ta/-/ka/连续体充当目标音。高频滑音从3600 Hz线性提高至4000 Hz, 低频滑音从900 Hz线性提高至1300 Hz。实验结果表明低频(高频)音语境条件下被试在刺激1~10上平均的“ga”反应百分比分别是:96.25(95), 90(93.75), 87.5(92.5), 92.5(93.75), 65(58.75),45(16.25), 51.25(17.5), 23.75(3.75), 21.25(7.5)和20(5)。实验结果符合声学线索激活假设的预期, 高频线索条件下被试有更多的/ta/反应, 低频线索条件下被试有更多的/ka/反应。这表明/pa/和/pu/音节及非言语模拟音的语境效应可能是由于激活了有利于/ka/范畴识别的声学线索, 即一些中低频的声学线索, 这些中低频的声学线索是识别/ka/范畴的关键线索。因而, 当前实验结果扩展了听觉基础上的语境效应类型, 除频谱对比效应引起的语境效应外, 某个语音范畴声学线索的激活也能促进该范畴的识别。
最后, 来自听觉神经科学的研究成果也为基于听觉理论解释语境效应提供了支持。研究表明哺乳动物听觉皮层神经元的活动受到听觉刺激历史或语境的影响(Asari & Zador, 2009; Bartlett & Wang,2005; Brosch & Schreiner, 1997; Brosch & Scheich,2008; David & Shamma, 2013; Delgutte, 1996;Lochmann, Ernst, & Denève, 2012; Ulanovsky, Las,Farkas, & Nelken, 2004)。前面的刺激能够抑制或促进听觉皮层神经元对随后刺激的反应:当前后刺激的参数(特别是频率)类似时, 会产生最强的抑制效应; 当前后刺激的参数不同时, 可能会有促进效应(Bartlett & Wang, 2005; Brosch & Schreiner, 1997;Brosch & Scheich, 2008)。听觉皮层神经元对刺激语境的敏感为语境效应提供了神经基础。刺激语境能够激活或抑制听觉皮层神经元对一些声学线索的反应, 当某个语音范畴的声学线索被前面语境抑制后, 该语音范畴的识别可能会受到抑制; 当某个语音范畴的声学线索被前面语境激活后, 该语音范畴的识别可能会受到促进。
6 总结与展望
当前研究以汉语塞−元音节及其非言语模拟音为语境音, 汉语/ta/-/ka/连续体为目标音, 通过3个实验考察了发音特征理论和听觉理论对汉语塞−元−塞音序列语境效应的解释力度, 并对塞−元−塞音序列语境效应机制进行了深入探讨。实验结果发现塞−元−塞音序列语境效应主要源于语境音声学线索的差异, 语境音的语音范畴感知可能也部分的影响到其语境效应表现。另外实验结果发现除频谱对比效应所预期的语境效应外, 频率波段远离目标音关键声学线索所处频率区的语境音也能影响到目标音的识别, 可能由于该语境音激活了特定语音范畴的声学线索。当前实验结果不仅有助于解决听觉理论和发音特征理论对语境效应解释方面的争论,还对基于频谱对比效应解释语境效应的听觉理论进行了补充和丰富。虽然实验结果总体上支持了听觉理论, 但是单纯的频谱对比效应不能解释语境效应变异的所有事实, 还需要考虑语音范畴感知及特定声学线索激活对目标音识别的影响。
当前研究虽然为汉语塞−元−塞音序列的语境效应机制提供了一些解释, 但是言语知觉中的语境效应是一个非常复杂的现象, 还有很多问题需要进一步探讨。语境效应的来源可能包括声学线索的影响、语音范畴的影响, 以及语音经验的作用, 这些因素都在什么情境中的语境效应中起作用, 它们之间有什么差别, 如听觉和语音基础上的语境效应是否存在加工时间方面的差异, 这些都值得进一步探索。即使是声学线索驱动下的语境效应, 其潜在的机制也可能存在差异, 这包括听觉基础上的对比效应, 特定声学线索对特定范畴识别的促进作用, 声学线索在什么条件下起到抑制作用(对比), 什么时候又能起到促进作用, 这也需要进一步探讨。最后, 语境效应的神经机制也值得探索, 听觉神经科学已经在微观角度上对此进行了一些探讨, 认知神经科学角度上的宏观研究还比较少, 这也是将来研究的一个方向。
Asari, H., & Zador, A. M. (2009). Long-lasting context dependence constrains neural encoding models in rodent auditory cortex.Journal of Neurophysiology, 102
, 2638–2656.Bartlett, E. L., & Wang, X. Q. (2005). Long-lasting modulation by stimulus context in primate auditory cortex.Journal of Neurophysiology, 94
, 83–104.Brosch, M., & Scheich, H. (2008). Tone-sequence analysis in the auditory cortex of awake macaque monkeys.Experimental Brain Research, 184
, 349–361.Brosch, M., & Schreiner, C. E. (1997). Time course of forward masking tuning curves in cat primary auditory cortex.Journal of Neurophysiology, 77
, 923–943.Coady, J. A., Kluender, K. R., & Rhode, W. S. (2003). Effects of contrast between onsets of speech and other complex spectra.Journal of the Acoustical Society of America, 114
,2225–2235.Cooper, F. S., Delattre, P. C., Liberman, A. M., Borst, J. M., &Gerstman, L. J. (1952). Some experiments on the perception of synthetic speech sounds.Journal of the Acoustical Society of America, 24
, 597–606.David, S. V., & Shamma, S. A. (2013). Integration over multiple timescales in primary auditory cortex.Journal of Neuroscience, 33
, 19154–19166.Delattre, P. C., Liberman, A. M., & Cooper, F. S. (1955).Acoustic loci and transitional cues for consonants.Journal of the Acoustical Society of America, 27
, 769–773.Delgutte, B. (1996). Auditory neural processing of speech. In W. J. Hardcastle & J. Laver (Eds.),The handbook of phonetic sciences
(pp. 505–538). Oxford: Blackwell.Diehl, R. L., Lotto, A. J., & Holt, L. L. (2004). Speech perception.Annual Review of Psychology, 55
, 149–179.Fowler, C. A. (1986). An event approach to the study of speech perception from a direct-realist perspective.Journal of Phonetics, 14
, 3–28.Fowler, C. A. (2006). Compensation for coarticulation reflects gesture perception, not spectral contrast.Perception &Psychophysics, 68
, 161–177.Fowler, C. A., Brown, J. M., & Mann, V. A. (2000). Contrast effects do not underlie effects of preceding liquids on stopconsonant identification by humans.Journal of Experimental Psychology: Human Perception & Performance, 26
, 877–888.Holt, L. L. (2005). Temporally nonadjacent nonlinguistic sounds affect speech categorization.Psychological Science,16
, 305–312.Holt, L. L. (2006). Speech categorization in context: Joint effects of nonspeech and speech precursors.Journal of the Acoustical Society of America, 119
, 4016–4026.Holt, L. L., & Lotto, A. J. (2002). Behavioral examinations of the level of auditory processing of speech context effects.Hearing Research, 167
, 156–169.Holt, L. L., & Lotto, A. J. (2008). Speech perception within an auditory cognitive science framework.Current Directions in Psychological Science, 17
, 42–46.Holt, L. L., Lotto, A. J., & Kluender, K. R. (2000). Neighboring spectral content influences vowel identification.Journal of the Acoustical Society of America, 108
, 710–722.Kingston, J., Kawahara, S., Chambless, D., Key, M., Mash, D.,& Watsky, S. (2014). Context effects as auditory contrast.Attention, Perception, & Psychophysics, 76
, 1437–1464.Li, F. P., Menon, A., & Allen, J. B. (2010). A psychoacoustic method to find the perceptual cues of stop consonants in natural speech.Journal of the Acoustical Society of America, 127
, 2599–2610.Liberman, A. M., Cooper, F. S., Shankweiler, D. P., &Studdert-Kennedy, M. (1967). Perception of the speech code.Psychological Review, 74
, 431–461.Liberman, A. M., & Mattingly, I. G. (1985). The motor theory of speech perception revised.Cognition, 21
, 1–36.Lochmann, T., Ernst, U. A., & Denève, S. (2012). Perceptual inference predicts contextual modulations of sensory responses. Journal of Neuroscience, 32
, 4179–4195.Lotto, A. J., & Holt, L. L. (2006). Putting phonetic context effects into context: A commentary on Fowler (2006).Perception & Psychophysics, 68
, 178–183.Lotto, A. J., & Kluender, K. R. (1998). General contrast effects in speech perception: Effect of preceding liquid on stop consonant identification.Perception & Psychophysics,60
, 602–619.Lotto, A. J., Sullivan, S. C., & Holt, L. L. (2003). Central locus for nonspeech context effects on phonetic identification (L).Journal of the Acoustical Society of America, 113
, 53–56.Mann, V. A. (1980). Influence of preceding liquid on stop-consonant perception.Perception & Psychophysics,28
, 407–412.Mann, V. A., & Repp, B. H. (1980). Influence of vocalic context on perception of the [∫]–[s] distinction.Perception& Psychophysics, 28
, 213–228.Mann, V. A., & Repp, B. H. (1981). Influence of preceding fricative on stop consonant perception.Journal of the Acoustical Society of America, 69
, 548–558.Mitterer, H. (2006). On the causes of compensation for coarticulation: Evidence for phonological mediation.Perception& Psychophysics, 68
, 1227–1240.Remez, R. E., Rubin, P. E., Pisoni, D. B., & Carrell, T. D.(1981). Speech perception without traditional speech cues.Science, 212
, 947–949.Smits, R. (2001). Evidence for hierarchical categorization of coarticulated phonemes.Journal of Experimental Psychology:Human Perception and Performance, 27
, 1145–1162.Stephens, J. D. W., & Holt, L. L. (2003). Preceding phonetic context affects perception of nonspeech (L).Journal of the Acoustical Society of America, 114
, 3036–3039.Stevens, K. N., & Blumstein, S. E. (1978). Invariant cues for place of articulation in stop consonants.Journal of the Acoustical Society of America, 64
, 1358–1368.Ulanovsky, N., Las, L., Farkas, D., & Nelken, I. (2004).Multiple time scales of adaptation in auditory cortex neurons.Journal of Neuroscience, 24
, 10440–10453.Viswanathan, N., Fowler, C. A., & Magnuson, J. S. (2009). A critical examination of the spectral contrast account of compensation for coarticulation.Psychonomic Bulletin and Review, 16
, 74–79.Viswanathan, N., Magnuson, J. S., & Fowler, C. A. (2010).Compensation for coarticulation: Disentangling auditory and gestural theories of perception of coarticulatory effects in speech.Journal of Experimental Psychology: Human
Perception and Performance, 36
, 1005–1015.Viswanathan, N., Magnuson, J. S., & Fowler, C. A. (2013)
.Similar response patterns do not imply identical origins: An energetic masking account of nonspeech effects in compensation for coarticulation.Journal of Experimental Psychology:Human Perception and Performance, 39
, 1181–1192.Viswanathan, N., Magnuson, J. S., & Fowler, C. A. (2014).Information for coarticulation: Static signal properties or formant dynamics?Journal of Experimental Psychology:Human Perception & Performance, 40
, 1228–1236.Wade, T., & Holt, L. L. (2005). Effects of later-occurring nonlinguistic sounds on speech categorization.Journal of the Acoustical Society of America, 118
, 1701–1710.Yan, J. (1990). A study of the vowel formant pattern and the coarticulation in the voiceless stop initial monosyllable of Standard Chinese. InReport on phonetic research
(pp.30–54). Institute of Linguistics, Chinese Academy of Social Sciences.Yang, J., & Chen, X.-X. (2005). The characteristic analysis for stop burst spectrum in Standard Chinese. InReport on phonetic research
(pp. 70–75). Institute of Linguistics,Chinese Academy of Social Sciences.(阳晶, 陈肖霞. (2005). 普通话塞音爆破段谱的特性分析. 见语音研究报告
(pp. 70–75). 中国社会科学院语言研究所.)