反向对抗逻辑范式的创立与证实
——人工语法PDP对抗逻辑的改进*
2016-02-01张剑心李莹丽刘电芝
张剑心 汤 旦 李莹丽 刘电芝
(苏州大学教育学院, 苏州 215123)
1 引言
1.1 内隐学习对抗逻辑范式
对抗逻辑把意识定义为能被外显策略控制的受控反应, 把无意识定义为不受外显策略控制的自动反应, 两种反应在特殊测量任务中对抗竞争(Jacoby, Woloshyn, & Kelley, 1989)。Jacoby (1991)根据对抗逻辑, 在再认任务中提出了加工分离程序即PDP, 包括包含任务(inclusion test)和排除任务(exclusion test):包含任务要求被试用先前学过的词完成任务, 如果有意识回忆失败也可用其它任何信息, 即被试可以利用有意识提取和无意识熟悉性两种加工来完成任务; 排除任务要求被试用首先想到的但又不能是先前学过的词来完成任务, 如果被试错误地选择了学过的词, 那么这些词就是记忆的无意识成分——正是无意识熟悉性导致其不受意识控制。包含任务中受控反应(即有意识提取)和自动反应(即无意识熟悉性)的关系是Inclusion=C + (1 −C)A, C表示controlled, A表示automatic; 排除任务中受控反应和自动反应的关系是Exclusion=(1 −C)A 。那么受控反应可以用包含任务减去排除任务而得到C=Inclusion – Exclusion=〔C + (1 − C)A〕−(1 − C)A; 自动反应则由排除任务和受控反应的值获得A=Exclusion / (1 − C)。Jacoby通过这两个任务成功分离了再认的意识成分和无意识成分, 此后PDP成为内隐记忆的主要分析范式之一。在PDP对抗逻辑中意识=外显=受控反应, 而无意识=内隐=自动反应, 下文将采用这些等同性概念进行论述, 不再每次都加以说明。
而内隐学习经典范式之一的人工语法学习在2000年之前主要采用任务分离逻辑。Reingold和Merikle(1988)认为, 为了测量到纯净的意识和无意识, 需要设置两种对照的测量任务即直接测量和间接测量。直接测量对意识更敏感, 而间接测量对无意识更敏感。人工语法范式采用主观报告直接测量被试掌握语法规则的程度, 询问被试是否发现任何构成字符串的规则; 采用对新字符串是否符合语法的判断任务来间接测量对语法规则的掌握程度, 不要求说出语法规则本身, 只要求判断新字符串是否合法。如果两种测量成绩差异显著, 就证明意识成分和无意识成分具有相对独立性。可见分离逻辑存在明显缺陷:其逻辑必须建立在直接测量和间接测量结果的分离上, 但却无法证明直接测量就是意识成分, 间接测量就是无意识成分, 更无法证明两者差值是意识还是无意识(Jiménez, Méndez, & Cleeremans,1996)。
为了克服分离逻辑的缺陷, Higham, Vokey和Prithard (2000)首次成功地将PDP对抗逻辑引入人工语法学习(首次引入者是Dienes, Altmann, Kwan, &Goode, 1995, 但在检测自动反应上并不成功, 见下一段), 认为不管是直接测量还是间接测量, 都是受控反应和自动反应共同作用的结果, 任务分离逻辑无法精确区分这两种过程。由于内隐学习和内隐记忆的相似性, 内隐学习应该符合双加工模型(Yonelinas, 2002), 并且已有大量研究证实内隐学习确实存在自动反应(Cohen & Poldrack, 2008; Soetens,Melis, & Notebaert, 2004), 因此PDP对抗逻辑可以应用到人工语法内隐学习。Higham等(2000)借鉴PDP对抗逻辑, 通过意识和无意识的“协同”与“对抗”关系来考察受控反应和自动反应。(1)其实验设计是:采用被试间设计, 设置了意识成分和无意识成分的不同关系条件, 称之为“相容条件”和“对抗条件”。实验材料使用两种不同的限定状态语法A和B, 以及非法字符串U。(2)实验程序是:学习阶段要求被试记忆并排呈现的两个字符串, 5秒后字符串消失, 被试立即把记忆过的字符串分别写在标有“词单A”和“词单B”的栏内。然后再呈现两个新字符串, 依次类推。测量阶段指导语告诉被试有两个不同的语法规则A和B用来生成两个词单中的字符串, 但不告诉语法规则的细节。要求相容条件组将任何认为符合语法A或语法B的新字符串评为合法G; 将不符合两种语法的非法字符串U评为不合法NG; 要求对抗条件组仅将语法A评为合法,而将语法B和非法字符串U都评为不合法。(3)实验结果发现:语法B的接受率在相容条件组(0.65)比在对抗条件组(0.51)大, 证明被试能明确地否定由语法B产生的新字符串来控制其任务, 这就是受控反应的证据。而对抗条件组以非法字符串U误判为合法的概率作为基线水平, 对抗条件组语法B的接受率(0.51)比非法字符串U的接受率(0.39)更大,这就是自动反应的证据:尽管被试的受控加工试图避免肯定语法B的新字符串, 但是较之非法字符串U, 被试还是更可能无意识地自动接受语法B的新字符串。
但是Dienes等(1995)在人工语法学习中首次采用了相容条件和对抗条件, 发现了受控反应的证据,却没有发现自动反应的证据。在该实验中语法B(或A)在对抗条件组的接受率在数值上反而小于非法字符串U的接受率。Wan, Dienes和Fu (2008)使用了Dienes等(1995)的实验程序探索主观熟悉性能否受控, 在其两个实验中都得到了同样结果:只发现受控反应, 没有自动反应; 在实验二中, 还发现被试可以通过主观熟悉性来完美分辨语法A和B,主观熟悉性对外显任务要求非常敏感并且对内隐知识扮演着策略控制的角色——测量阶段需要被拒绝的语法B在学习阶段学习了两次, 需要被肯定的目标语法A只学习了一次, 被试却仍然可以按照外显任务要求正确选择语法A且熟悉性更高, 而正确拒绝语法B且熟悉性更低, 可见其熟悉性是主观的, 并不服从客观的重复次数。Norman, Price和Jones(2011)使用了同样的范式, 但测量阶段随机要求被试判断新字符串是否属于A或者是否属于B, 这种随机设置增加了任务难度, 让被试的判断标准必须在两套语法间切换, 但结果发现被试仍能正确分辨出两套语法, 没有出现自动反应。
内隐序列学习是内隐学习的另一个经典范式,要求对陆续呈现的刺激位置进行按键反应, 刺激位置遵循某套序列规则, 但是不告知被试。对抗逻辑范式在内隐序列学习中的应用却很成功:Destrebecqz和Cleeremans (2001)在内隐序列学习的学习阶段使用两套不同的序列, 测量阶段使用了生成任务(包含任务和排除任务), 发现被试能够控制使用所学的两套序列。Mong, McCabe和Clegg (2012)使用类似的范式, 但测量阶段是再认任务, 设置了相容条件和对抗条件, 结果发现了受控反应和自动反应的证据。相比人工语法学习, 内隐序列学习中采用对抗逻辑范式能轻易找到自动反应, 这可能是因为内隐序列学习是对序列的重复学习, 规则相对简单导致习得程度较高, 而测量阶段仍然是针对学过的旧序列片段, 则被试区分序列片段和随机片段较容易,对随机片段的接受率不会太高。而人工语法学习获得的是需要做出判断推理的内隐语法规则:学习阶段通过对一部分合法字符串的学习, 被试只内隐习得了语法的部分规则, 测量阶段时新字符串是否合法必须由旧字符串的规则推导出来, 则非法字符串U可能因推导过程不完备或不准确而被错误接受,造成对非法字符串U的高接受率而掩盖了自动反应。
1.2 人工语法对抗逻辑范式的缺陷
正因对抗逻辑范式难以捕捉到人工语法的自动反应, 无法通过客观测量分离出内隐成分, 所以在人工语法学习中很少应用。本研究分析两个具有开创性和代表性的实验即Higham等(2000)与Dienes等(1995)的矛盾, 试图找到可能的原因。他们的实验程序有5点不同, 可能导致了实验结果不一致。
第一, 学习阶段对两套语法的记忆方式不同。
Dienes等(1995)的学习阶段是先记忆语法A的词单, 再记忆语法B的词单, 对每套语法都是连贯学习, 各自内部的字符串能够互相参照比对, 可能习得了深层语法结构, 即产生了规则学习(Pothos,2005)。这样在学习阶段就可能通过外显/内隐辨别把两套语法充分辨别开来, 在对抗条件组更易分辨新字符串符合哪套语法, 而按外显要求完成任务,就很难产生自动反应。因此这种结果虽然被对抗逻辑认为是受控反应, 但事实上可能是与外显任务要求协同的特殊内隐知识(Kiefer, 2012; Horga & Maia,2012)。反之, Higham等(2000)的实验程序让两套语法同时记忆, 打乱了同一套语法字符串的连贯学习,则在学习阶段可能不能够把两套语法充分辨别开来, 在对抗条件组内隐知识与外显任务要求无法协同而产生了真实的对抗。而且Higham等(2000)同一时间出现的两个字符串并不是匹配出现的, 长短不一致, 难以提供两套字符串差异的结构线索, 被试可能无法充分习得各自的深层语法结构, 即只产生了熟悉性学习(Nosofsky, 1988; Nosofsky & Zaki, 1998),甚至把语法A和B当做是一套联合语法A*B来学习和存储(未来应该研究这种可能性)。这导致在对抗条件组测量阶段被试根本区分不出新字符串是属于语法A或B, 既无法也无需拒绝语法B, 因为语法B可能根本不存在, 只存在一个联合语法A*B!或者至少被试无法准确辨别出属于B的新字符串, 所以更易受形式相似性影响, 觉得只要与语法A相似,就倾向于判断为G。
上述分析仅仅从两套语法A和B的学习程度和形式相似性来分析两个研究的差异, 并未涉及到非法字符串U的影响。
第二, 非法字符串U的设计有差异, 导致对非法U的拒绝难易不同。
Higham等(2000)对Dienes等(1995)的实验结果推测是:其实验保证了非法字符串U与两个语法A和B的字符串非常相似, 而Higham等(2000)的实验没有做这样的限制, 非法字符串和合法字符串有更大的差异, 可能使得拒绝非法字符串更容易, 导致至少部分自动反应来自于被试拒绝古怪字符串的能力。这就可能由于三套字符串之间的形式相似性的差异使得真实的自动反应无法被测量到:如果三组字符串形式相似度都高, 拒绝非法字符串变得困难, 基线水平上升就掩盖了自动效应; 如果合法字符串A和B之间形式相似度高, 而非法字符串U与之相似度相对较低, 则非法字符串U就更易被拒绝, 而与语法A更相似的语法B自然就更易被接受, 并不是真实内隐知识导致的自动反应。因此Redington(2000)对Higham等(2000)的对抗逻辑范式进行了尖锐批评:假如被试只学习语法A, 但测量阶段既有语法B又有语法A, 还有非法字符U。由于语法B在形式上和语法A很相似, 比起非法字符串U被试会更容易接受语法B, 这样就检测到了自动反应的证据。但逻辑矛盾是, 被试根本没有学过语法B,谈何自动反应呢?这个质疑非常有力。Higham和Vokey(2000)回应Redington说其自动反应并不虚假, 至少是相似性导致的熟悉性产生的真实自动反应, 类似内隐记忆中的基于熟悉性产生的自动反应。但本研究并不认同其解释, 笔者认为:Higham等(2000)检测到的自动反应仅仅是因为没有在学习阶段把A和B辨别开来而已, 被试从自动和受控层面都把语法B和A看做是同一套联合语法A*B来学习和存储。因此在对抗条件组, 将语法B自动判定为合法正是遵从外显任务要求的受控反应!其认知过程并没有产生任何对抗, 谈何自动反应呢?
Tunney和Shanks (2003) 则认为对抗逻辑范式得到的数据不能显示出受控反应和自动反应的二元加工, 而完全可以被一元的熟悉性加工所解释。他们使用了简单反馈网络(Simple Recurrent Network—SRN)对Higham等(2000)实验数据做了拟合, 结果显示受控反应和自动反应的数据不能让SRN区分出是双加工系统还是单系统, 而可以由熟悉性的分辨系统产生。Vokey和Higham (2004) 回答说Tunney和Shanks (2003)的模型不能完全解释Higham等(2000)所获得的分离, 所以使用了自动联结网络模型(auto associative network model)发现受控反应和自动反应的数据只能由双加工系统获得。但是Vokey和Higham (2004)的模型只是一种可能性, 不能证明Tunney和Shanks (2003)的模型就是错的——因为其模型同样能与实验数据完美吻合。也就是说Vokey和Higham (2004)只是证明了在自动联结网络模型中, 实验数据只符合双加工系统; 但不能否定Tunney和Shanks (2003)在简单反馈网络模型中证明实验数据可以由单系统产生, 因为Vokey和Higham (2004)没有证明(可能尚无法证明)实验数据只能采用自动联结网络模型来模拟。
上述分析只是从排除非法字符串U的难易来论述两个实验的差异, 尚未涉及到形式相似性的差异对测量阶段辨别语法A和B的影响, 即内隐辨别加工的差异。
第三, 测量阶段的内隐辨别加工不同。
Dienes等(1995)和Higham等(2000)对非法字符串的设计不同, 还可能导致两者测量阶段的内隐辨别加工都产生本质差异。Higham等(2000)的实验由于非法字符串U与语法A和B差异较大导致任务较容易, 辨别系统可能只在形式层面激活, 只辨别出非法字符串U即可, 而对语法A和语法B不进行深入辨别。而Dienes等(1995)的实验, 由于三者形式上都相似导致任务很困难, 则可能充分激活内隐辨别系统, 在测量阶段对已学习过的语法A和B进行了进一步辨别加工(当然这种辨别加工只能针对记忆中的语法知识), 因此很好地内隐辨别出了语法B。经过了深入辨别的语法B可能仍是内隐知识, 但已能与外显任务要求协同而被正确拒绝, 是一种不具有自动反应特征的特殊内隐知识。由此还可以推测内隐知识不等于自动加工(Fu, Dienes, & Fu,2010)。
第四, 上述三种因素交互, 导致两个实验的学习机制和知识提取机制都不同。
Dienes等(1995)实验对人工语法的学习和提取的方式正好一致, 都需要掌握两套语法深层规则并辨别开来, 造成无法检测到自动反应。而Higham等(2000)实验对人工语法的学习可能只是基于熟悉性, 或者是对一套联合语法A*B的规则学习, 两种可能都导致无法分辨语法A和B; 而提取又正好不需要深入辨别两套语法, 这就造成了虚假的自动反应。
综合以上4点, 两种对抗逻辑范式都有很大缺陷, 研究者们不能解决这个难题, 所以人工语法对抗逻辑范式就一直停留在原地。Johansson (2008)试图建立新的人工语法对抗逻辑范式来调和两者矛盾:只使用一套语法回避了形式相似性。要求被试首先记忆一套语法字符串, 接着告知字符串遵循某种规则但没有细节; 然后要求生成新的合法字符串(包含任务)或者不合法字符串(排除任务), 自动反应的证据被定义为在排除任务中生成了高于随机水平的合法字符串。但是遗憾的是在寻找受控反应和自动反应方面都失败了, 因为无论包含任务还是排除任务都处于随机水平。张润来和刘电芝(2014)同样采用一套语法, 测量阶段设置了包含任务和排除任务, 包含任务让被试在4个新字符串(其中只有一个符合已学过的语法)中选出符合学过语法的字符串, 排除任务让被试在4个新字符串中选出最先想到的却又不符合学过语法的字符串, 结果发现排除任务中错误选择了合法字符串的概率仍然大于随机, 成功得到了自动反应。但笔者发现该范式同样没有平衡新字符串中合法字符串和非法字符串的形式相似性:其测量阶段每个试次有5个新字符串, 其中有一个是新合法字符串, 另外4个非法字符串是将此新合法字符串改动1~4个字母,那么这4个非法字符串与该新合法字符串以及已学过的旧合法字符串相似度不同。包含任务是选出与学过的字符串最相似的新字符串, 被试能通过相似性轻易排除不相似的非法字符串, 成功选择最相似的新合法字符串或者比较相似的非法字符串, 从而得到虚高的包含任务成绩(其计分是完全正确记2分, 选了错一个字母的非法字符串仍记1.5分, 以此类推)。排除任务是选出与学过的字符串最不相似的新字符串, 被试又能通过相似性轻易排除合法字符串, 成功选择最不相似的非法字符串, 从而得到虚低的自动反应。两种任务相减, 就得到虚高的受控反应!因此这种设计不但没有排除形式相似性,反而是鼓励了形式相似性发挥作用。另外其排除任务是快任务, 每个试次被试对快速呈现的5个新字符串不易看清, 这又引入了知觉意识的额外变量,得到的自动反应也不纯净。并且该范式只适用于一套语法, 仍没有解决两套语法的经典对抗逻辑范式的缺陷。为何非得研究两套语法的经典对抗逻辑范式呢?(1)现实生活中存在多套规则, 一套语法的实验生态效度较低; (2)两套语法的设计能探测到被试排除别的规则, 专门针对某套规则进行学习的抗干扰内隐学习和辨别过程, 这是不同的领域; (3)对两套语法采用对抗逻辑范式, 还能探测到内隐层面刻意否定某套规则的加工过程, 这能与社会认知中的消极刻板印象如种族、外群体、性别歧视等相联系。因此研究两套语法对抗逻辑范式非常必要且有理论和应用价值。
以上论述对Higham等(2000)的质疑还只局限在自动反应的虚假上, 笔者发现其受控反应掺杂了高概率判断偏向效应, 极有可能也是虚假的。见以下分析。
第五, 测量阶段的相容条件组设置不同, 导致两者的高概率判断偏向效应不同。
Dienes等(1995)的实验对抗条件组程序和Higham等(2000)相同, 但是相容条件组却不一样。Dienes等(1995)只设置了两个对抗条件组, 两组学习阶段完全一样, 都分别连贯学习语法A和B; 但在测量阶段组1只需要从60个新字符串中挑出符合规则A的20个新字符串, 而拒绝符合规则B的20个新字符串和20个非法字符串U, 组2则相反只挑出规则B。因此将两组结合起来看, 对于规则A来说, 组1就是相容条件组, 组2却是对抗条件组; 对于规则B则相反, 由此可以得到受控反应和自动反应的值。这种设计的好处在于语法A或B在两组中面临的判断概率背景是一样的, 都是1/3概率判断为合法, 2/3的概率判断为不合法, 那么检验到的受控反应就很纯粹。
Higham等(2000)的实验则有专门的相容条件组。这就导致同一个新字符串在相容条件组和对抗条件组面临的判断概率环境不同。对于语法B, 在相容条件组需要被判定为合法, 由于该组每个新字符串判断为合法的背景概率是2/3, 被试受此影响,自然更容易把语法B判断为合法; 在对抗条件组需要被判定为不合法, 该组每个新字符串判断为不合法的背景概率又是2/3, 被试受此影响, 自然更容易把语法B判断为不合法。两组的高概率判断偏向效应大小相等, 方向相反, 必然造成相容条件组对语法B的接受率虚假偏高, 而对抗条件组对语法B的拒绝率虚假偏高则接受率虚假偏低。受控反应的操作性定义就是检验两组语法B的接受率差异, 那么这种差异必然包含了高概率判断偏向效应。如何检测呢?通过语法A或非法U在两组的接受率差异就可以量化出来。但由于语法A和B形式上同质(相似度较高), 而非法U与语法B形式上不同质(相似度较低), 故应采用语法A在两组的接受率差异来衡量语法B的高概率判断偏向效应。Higham等(2000)的实验数据如下:相容条件组, Bin=0.65,Ain=0.70, Uin=0.34; 对抗条件组, Bop=0.51, Aop=0.645, Uop=0.39, 其研究报告称Bin和Bop差异显著(相差0.14)证明检测到了受控反应。笔者计算高概率判断偏向效应指标为Pr=(Ain− Aop)/2=(0.70 −0.645) / 2 ≈ 0.028。再析出Pr效应这种干扰变量, Bin– Pr=0.65 − 0.028=0.622, Bop+ Pr=0.51 + 0.028=0.538, 两者相差很小只有0.084, 受控反应接近消失了。可见由于没有考虑高概率偏向效应, Higham等(2000)的实验检验到的受控反应不纯粹, 甚至是虚假的!即在对抗条件组, 被试根本无法按照外显任务要求正确排除语法B, 这佐证了第一点分析中对于联合语法A*B的推测。
Dienes等(1995)的实验只能确证人工语法学习中存在受控反应, 无法确证存在自动反应, 而Higham等(2000)的实验得到的自动反应和受控反应都极有可能是虚假的。那么人工语法学习是否是内隐学习, 或者至少是否存在内隐成分, 就大大存疑了!并且无法为进一步研究各种学习机制的意识特征提供量化指标, 如片段学习、熟悉性学习和规则学习各自对内隐/外显成分的贡献量。因此本研究试图弥补其缺陷。
1.3 本研究提出反向对抗逻辑范式
针对以上缺陷, 本研究新设计了反向对抗逻辑范式。完全采用Dienes等(1995)的实验材料, 使用两套语法A和B以及非法字符串U, 三者形式上都很相似。把语法A和“YES”标签绑定, 让语法A生成合法“词单G”; 把语法B和“NO”标签绑定, 让语法B生成“词单NG”, 它虽然也是合法, 但通过指导语让被试在学习阶段认为它是不合法“NG”。这样被试内隐习得语法A并认为它合法; 内隐习得语法B但认为它不合法。然后测量阶段设计相容条件组, 要求把符合“词单G”的新字符串判断为合法“G”; 把和“词单NG”相像的新字符串判断为不合法“NG”。而对抗条件组则要求把符合“词单G”的新字符串判断为合法“G”; 并把符合“词单NG”的新字符串也判断为合法“G”, 这就和学习阶段把“词单NG”标定为不合法“NG”的内隐学习产生了对抗。参照对抗逻辑的计算方式, 就能得到反向对抗逻辑范式的受控反应和自动反应(详见2.5实验结果)。
由于语法B在学习阶段是被当做非法字符串NG学习的, 那么在对抗条件组中, 外显任务要求把语法B判断为合法, 而语法B在形式上和语法A相似, 如果被试的判断只是出于形式相似性, 那么应该能够很准确地把语法B判断为合法; 如果结果显示被试仍然将其判断为不合法, 那只能是不受控的自动反应在起作用。而真正的非法字符串U, 在形式上与语法A和B都相似, 如果认为把语法B判断为不合法是因为它和真正非法字符串U相似,那么对语法A也应该有同样的效应, 即把语法B和A判断为不合法的概率应该相等; 如果语法B判断为不合法的概率显著大于语法A, 就表明语法B存在自动反应。由此可见, 如果反向对抗逻辑得到自动反应, 就完全排除了形式相似性的影响。Redington (2000)对Higham等(2000)对抗逻辑实验的尖锐批评, 对于本研究的反向对抗逻辑实验, 完全失效。
本研究几乎完全采用Dienes等(1995)的实验材料和实验程序, 所以对两套语法的学习程度和辨别程度与其实验一致。但有三个改变:一是把正向对抗逻辑变成了反向对抗逻辑。Dienes等(1995)的实验对语法B先肯定学习后否定判断, 产生了对抗,没有发现自动反应, 可能是对于内隐的肯定知识,外显具有很强的控制力, 外显否定更容易。本研究对语法B先否定学习后肯定判断, 也产生了对抗,但是内隐否定知识可能更深刻而更不易受控, 对其做外显肯定判断很难, 或许就能测量到自动反应。二是增加了对学过语法A和B的旧字符串进行再认辨别和订正, 被试对两套语法的学习和辨别程度应该比Dienes等(1995)的还要高, 那么如果本实验发现了自动反应的证据, 就证明反向对抗逻辑可以不受辨别力的影响。三是测量阶段采用Higham等(2000)的相容条件组和对抗条件组, 因为更容易设置反向对抗程序; 但是使用的新字符串采用的是Dienes等(1995)严格的实验材料。
可见如果实验结果理想, 能测量到受控反应和自动反应, 就证明反向对抗逻辑范式能够不受形式相似性和辨别力影响, 有效地分离出受控反应和自动反应。这种范式既能适用于Dienes等(1995)的严格实验材料, 又能解决Higham等(2000)范式的缺陷, 是对抗逻辑范式的改进版。
因此本研究假设:(1)外显否定标签NG (no grammer)可以和语法B绑定学习, 使被试内隐习得否定标签NG+语法B。(2)反向对抗逻辑可以不受语法A和B以及非法字符串U三者之间的形式相似性和被试辨别力影响, 有效地检测到受控反应和自动反应。下面将通过实验创立反向对抗逻辑范式来验证假设。
2 实验方法
2.1 被试
45个苏州大学本科生或研究生, 男生18人,女生27人, 平均年龄22.7,SD=1.6, 随机分配20人为相容条件组, 25人为对抗条件组。
2.2 实验材料
和Dienes等(1995)的实验材料完全一样。由图1的两套人工语法A和B生成字符串各52个, 语法A作为“词单G”, 语法B作为“词单NG”。其中各有32个用在学习阶段, 各有20个用在测量阶段。非法字符串U有20个, 只用在测量阶段, 并保证非法字符串U与语法AB三者在形式上都很相似。
2.3 实验设计和程序
采用单因素(测量阶段:对抗条件和相容条件)被试间设计, 分为两个组:对抗条件组和相容条件组。所有被试都收到固定顺序排列的5张试卷, 并被告知测量记忆和辨别能力, 必须按照主试的现场指导语一步步作答。
首先, 被试只能看标有“词单G”的试卷1, 需努力记忆32个字符串, 并在每个字符串后第一个格子内写上 “G”, 然后在第二个格子内把这个字符串抄写一遍。时间8分钟。这一步目的是把语法A和标签“G”绑定。由于没有告知被试字符串符合语法, 只要求记忆, 所以被试进行的是内隐学习。
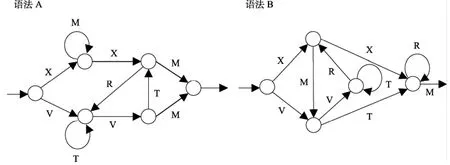
图1 语法A和B (摘自Dienes et al., 1995)
记忆结束后, 要求只看标有“词单NG”的试卷2, 同样有32个字符串。指导语告诉被试, 在试卷1记忆的“词单G”是通过某套语法生成的有规则的字符串, 标记的“G”表示它们符合语法“grammer”, 但是不告知任何语法A的细节; 试卷2的词单“NG”则不符合试卷1的语法, 是不合法的“no grammer”。同样要求被试努力记忆词单“NG”的字符串, 并在每个字符串后第一个格子内写上大写的“NG”表示不合法, 然后在第二个格子内把这个字符串抄写一遍。时间8分钟。这一步的目的, 先解释试卷1的标签“G”表示合法, 以进一步把“合法G”标签与语法A绑定; 然后对应的把试卷2的语法B与标签“不合法NG”绑定起来, 这样被试不会主动寻找试卷2的“不合法字符串”的语法规则, 保证对试卷2的词单“NG”也是内隐学习, 从而标签“不合法NG”就可能和语法B绑定进入内隐学习。
对试卷2记忆结束后是再认辨别任务。被试只能看试卷3, 64个字符串是由试卷1的32个合法字符串和试卷2的32个不合法字符串混合而成, 任务是把它们区分开来。指导语要求在认为合法的字符串后面格子内写上大写的“G”, 在不合法的字符串后面格子内写上大写的“NG”, 时间6分钟。再认辨别任务结束后, 要求被试拿出试卷4“正确答案”,在试卷3上订正作业, 在错误答案上画一条斜线,在此格子内写上正确答案, 并记忆该字符串属于“G”还是“NG”, 时间4分钟。这一步能测量到被试对试卷1和试卷2的字符串的记忆和辨别能力, 并进一步强化二者的合法和不合法的区别。
所有被试都进行上述任务。下面的任务, 则分为对抗条件组和相容条件组。
对抗条件组的被试, 拿到试卷5, 被指导语告知:试卷2“词单NG”虽然不符合试卷1“词单G”的语法, 但是符合另一套语法, 所以本质上也是合法的, 前面的任务只是强行贴上“NG”标签。试卷5有60个字符串, 都是没有记忆过的, 其中20个是由试卷1“词单G”的语法生成的新字符串, 需判断为合法“G”; 20个是试卷2“词单NG”的语法生成的新字符串, 和词单“NG”相像, 也需判断为合法“G”;另外20个是混乱的字符串U, 则需判断为不合法“NG”。时间7分钟。
相容条件组的被试, 也拿到同样的试卷5, 但是指导语不会告知试卷2“词单NG”是合法的, 而是告知其中有20个是由试卷1“词单G”的语法生成的新的合法字符串, 请判断为合法“G”; 有20个是新的不合法字符串, 和试卷2“词单NG”的不合法字符串相像, 请判断为不合法“NG”; 另外20个是混乱的字符串U, 也是不合法字符串, 也判断为不合法“NG”。时间7分钟。
3 实验结果
剔除了3个未按要求做的被试的数据。相容条件组和对抗条件组各项数据见表1。

表1 相容条件组和对抗条件组对语法A和B及非法U的判断结果
3.1 检验语法A的学习有效性, 以及标签“NG”和语法B绑定学习的有效性
比较相容条件组A-miss-in、B-hit-in和U-hit-in,三者方差不齐性不能做ANOVA, 故进行两两配对样本t检验, 三者之间都差异显著, 见表2。B-hit-in显著大于A-miss-in,t(18)=4.20,p< 0.01,d=1.841;U-hit-in显著大于A-miss-in,t(18)=4.33,p< 0.01,d=1.642。这两点证明对语法A的学习是有效的, 被试能很好地拒绝语法B和非法U, 而对语法A作出接受反应, 故把语法A误判为NG的概率显著小于把另两者判断为NG的概率。

表2 相容条件组对语法A和B及非法U判断的差异(M ± SD, n=19)
B-hit-in显著大于U-hit-in,t(18)=1.91,p<0.05,d=0.618, 表明被试已能很好地辨别出语法B, 前面的学习阶段是有效的, 已掌握了其深层结构; 且已和否定标签“NG”成功绑定, 被试学会了拒绝语法B, 所以在测量阶段的相容条件组更有把握地拒绝了它, 甚至高于对真正非法字符串U的拒绝。真正非法字符串U之前没有出现过, 且和语法A相似, 辨别它有更大的难度, 所以拒绝率反而不如语法B。这可在一定程度上证明Dienes等(1995)的实验没有发现自动反应, 正是因为被试能很好地辨别出语法B, 既能区分语法B和语法A, 又能区分语法B和非法U。由于本研究测量阶段相容条件组, 要求判断为NG的个数是恒定的40个, 故此结果还显示语法B部分侵占了对非法U作出拒绝判断的空间。这种侵占空间的现象正是否定标签“NG”和语法B绑定后得到有效学习的证据。当然此处的学习可能包括了外显和内隐知识, 要检验出是否存在内隐否定知识, 则还需要分析对抗条件组语法B的自动反应。
3.2 检验受控反应的证据
3.2.1 初步检验受控反应的证据
相容条件组要求对语法B做拒绝反应, B-hit-in是把语法B正确判断为NG的击中率; 对抗条件组要求对语法B做接受反应, B-miss-op是把语法B误判为NG的误判率。在相容条件组的B-hit-in和对抗条件组的B-miss-op的差异, 就是受控反应的证据。对二者进行独立样本t检验, 差异显著,B-hit-in显著大于B-miss-op,t(40)=9.57,p< 0.01,d=2.930。证明在对抗条件组, 被试确实可以外显控制语法B的一部分学习量, 而进行接受判断。
3.2.2 析出高概率判断偏向效应
相容条件组有对语法A的误判率A-miss-in,对抗条件组也有对语法A的误判率A-miss-op。两者进行比较, 做独立样本t检验, A-miss-in显著大于A-miss-op,t(40)=4.99,p< 0.01,d=1.612。相容条件组对语法A的误判率高于对抗条件组, 这可能是由合法/不合法的相对概率决定的:相容条件组字符串合法的概率是1/3, 不合法的概率是2/3, 由于不合法的概率更高所以对语法A会产生了更多的拒绝; 而对抗条件组字符串合法的概率是2/3, 不合法的概率是1/3, 由于合法的概率更高所以对语法A会有更多的接受。因此必须将高概率判断偏向效应作为一个误差因子。假设高概率不合法NG和高概率合法G二者导致的偏向效应大小一致, 方向相反, 设对于语法A高概率不合法的判断偏向效应为PrA即概率Probability, 则高概率合法的判断偏向效应为-PrA。
由于两组在学习和再认辨别阶段的实验程序完全相同, 故设相容条件组和对抗条件组对语法A的学习量是一样的, 则两组对语法A学习的真实缺失量(即未习得量)也是一样的, 设为LoseA。毕竟对语法A只进行一次的内隐学习基本不可能完全掌握其语法结构, 排除了随机误差, 必有真实的缺失。由于A-miss-in由对语法A的学习的真实缺失量LoseA、高概率不合法判断偏向效应PrA和随机误差E1组成; A-miss-op由对语法A学习的真实缺失量LoseA、高概率合法判断偏向效应-PrA和随机误差E2组成, 故有:

同理, 相容条件组有非法U的击中率U-hit-in;对抗条件组也有非法U的击中率U-hit-op。两者进行比较, 做one-way ANOVA检验, U-hit-in显著大于U-hit-op,F(1, 40)=67.15,p< 0.01, η2=0.627,这同样是高概率判断偏向效应。则有:
PrU=(U-hit-in-U-hit-op-E) / 2 ≈ (U-hit-in-U-hit-op) / 2=(0.72 − 0.49) / 2 ≈ 0.12.
可见PrA和PrU在数值上非常接近, 又由于语法A和B与非法U三者都相似, 故可用PrA和PrU的平均数作为高概率判断偏向效应的近似值:
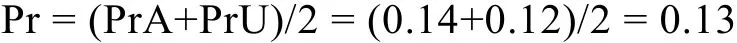
3.2.3 检验纯粹受控反应的证据
在3.2.1中初步检验了受控反应的证据, 但没有排除高概率判断偏向效应, 得到的受控反应是不纯粹的:相容条件组把语法B判断为NG的概率B-hit-in显著高于对抗条件组把语法B判断为NG的概率B-miss-op, 可能仅仅是受到各自环境的高判断概率的影响, 而非受控反应。而Higham等(2000)没有分析和排除高概率判断偏向效应, 导致其受控反应很可能是虚假的, 这是已有人工语法对抗逻辑范式的另一大缺陷。因此下面将排除高概率判断偏向效应, 以检验出纯粹受控反应。
由3.2.2的分析可知相容条件组B-hit-in包含了一个Pr, 对抗条件组B-miss-op包含了一个-Pr, 必须把两者都剔除, 则在B-hit-in中减去一个Pr, 在B-miss-op中加上一个Pr。由统计法则可知每个数据加上/减去同一常数, 平均数增加/减少此常数而标准差不变。故B-hit-in − Pr=(0.81 − 0.13) ± 0.18=0.68 ± 0.18, B-miss-op + Pr=(0.35 + 0.13) ± 0.13=0.48 ± 0.13。对二者进行独立样本t检验差异显著,B-hit-in − Pr显著大于B-miss-op + Pr,t(40)=4.46,p< 0.01,d=1.274, 两者相减得到差值为0.20, 这证明在统计上完全排除了高概率判断偏向效应后,结果显示对抗条件组的被试确实可以外显控制一部分学习量, 而对语法B给予接受判断, 这就是纯粹受控反映的证据(0.20)。
3.3 检验自动反应的证据
Higham等(2000)的对抗逻辑范式用对抗条件组中语法B的误判率(误判为G)与其基线水平——非法字符串U的误判率(同样误判为G)做比较, 如果语法B的误判率显著大于基线水平就证明存在自动反应。相对应地, 本研究创立的反向对抗逻辑范式的对抗条件组中, 语法B的误判率B-miss-op是误判为NG的概率(而非误判为G), 因此基线水平只能采用将语法A误判为不合法NG的概率即A-miss-op, 而不能采用非法字符串U的误判率U-miss-op, 因为它是将非法U误判为合法G的概率, 与B-miss-op方向相反。另一个理由是被试对语法A和B进行了同等学习, 对非法U则没有进行任何学习, 因此Higham等(2000)和Dienns等(1995)采用非法U的误判率作为基线水平就有缺陷——没有匹配学习程度和熟悉性。本研究采用A-miss-op作为基线水平则匹配了学习和熟悉性因素, 弥补了该缺陷。
本研究认为基线水平的本质是真实缺失量+随机误差。对抗条件组要求将语法A和B都判断为合法G, 由于学习的真实缺失量+随机误差, 必然对语法A产生一定的误判率(误判为NG), 故以A-miss-op作为基线水平就是最标准的指标。那么如果语法B误判为NG的概率B-miss-op显著高于基线水平A-miss-op, 则可以排除真实缺失量和随机误差等因素, 而认定其差值是自动反应量。
古诗文的创造不是凭空产生的,它们都有一定的历史寓意,或许是在一个特定的历史环境或许是要纪念某人某物。因此,教师在讲解古诗词的时候,应该提前对古诗文的创作背景做详细了解,了解当时的背景,发生了什么事情,作者写这篇古诗文的寓意是什么。这些事情都应该一清二楚,尤其是在讲解某一典故或者英雄事迹的时候,更应该要对此展开有针对性的教学。并在讲解过程中引入传统文化,加深学生对传统文化的领悟能力。
比较对抗条件组A-miss-op、B-miss-op和U-hit-op, 三者方差齐性, 做ANOVA, 模型主效应显著,F(2, 23)=3.03,p< 0.01, η2=0.209; 组间主效应显著,F(2, 23)=35.39,p< 0.01, η2=0.755。对三者做成对比较, 见表3, B-miss-op (0.35)显著高于A-miss-op (0.18),F(1, 23)=3.91,p< 0.01, η2=0.145, 两者相减得到差值为0.17, 这就是自动反应的证据:尽管被试的控制加工过程试图接受符合语法B的新字符串, 但是较之语法A, 被试还是更多地无意识拒绝语法B。这很好地验证了实验假设:反向对抗逻辑范式确实能够排除形式相似性的影响, 比对抗逻辑范式更有效地检测到真正的自动反应。
而U-hit-op显著高于A-miss-op,F(1, 23)=3.95,p< 0.01, η2=0.147; U-hit-op显著高于B-miss-op,F(1, 23)=10.04,p< 0.01, η2=0.304, 这证明比起拒绝语法A和B, 被试确实能够更好地拒绝非法字符串U。但是非法字符U的击中率U-hit-op (0.49)处于随机水平, 原因是对抗条件组要求判断为不合法NG的个数是恒定的20个, 故对语法B的自动拒绝反应部分侵占了对非法U作出拒绝判断的空间。这是标签“NG”与语法B绑定得到有效内隐学习的另一证据。
3.4 辨别力和自动反应的关系
在引言1.2中论述了Dienes等(1995)的实验可能充分激发了被试辨别力而掩盖了自动反应。本研究在其实验程序基础上加入了对语法AB的再认辨别和订正任务, 被试对两套语法的学习和辨别程度应该比Dienes等的实验还要高, 但却成功发现了自动反应, 这证明反向对抗逻辑可以不受辨别程度的影响而测得自动反应。下面将进一步从数据上证明这一点。
将再认辨别任务的正确率作为被试辨别力指标, 记为DiscAB即对AB的辨别力Discrimination。由于所有被试从试卷1到试卷4的实验处理都是一样的, 所以相容条件组与对抗条件组的辨别程度完全同质; 更由于对自动反应的检验只出现在对抗条件组,所以只需考察对抗条件组的辨别力DiscAB与自动反应的关系。设自动反应为AutoR即Automatic Response,则由分析3.3可知AutoR=B-miss-op﹣A-miss-op。

表3 对抗条件组对语法A和B及非法U判断的差异(M ± SD, n=23)
对DiscAB (0.74 ± 0.19)和AutoR (0.16 ± 0.21)做皮尔逊相关, 相关不显著,r=0.32,p> 0.05, 证明再认辨别阶段的辨别力与自动反应没有相关, 本研究新设计的反向对抗逻辑范式所产生和测得的自动反应不受对两套语法的辨别程度影响, 抗辨别力干扰的能力很强, 可能比对抗逻辑范式更强。
4 讨论
4.1 自动化的新途径:内隐联结自动化
反向对抗逻辑范式将外显的否定标签NG和语法B绑定进行内隐学习, 在对抗条件组检测到了否定的自动反应, 证明内隐知识可以接受否定标签而成为内隐否定知识。根据Cleeremans和Jiménez (2002)的表征质量意识理论, 内隐、外显和自动化的本质是表征质量渐进递增, 低级表征可通过不断练习渐进转化为高级表征。本研究证明外显标签只需和内隐语法规则的一部分联结, 随着对语法的内隐学习就可以扩展到新字符串, 获得了自动化特征, 不再受外显意识控制。此时的标签是内隐表征还是自动化表征尚需进一步确定, 但能确定的是自动化联结可以发生在外显标签和内隐知识之间, 而不只发生在外显知识之间。经典自动化是外显知识通过练习形成的, 而如果只练习一部分则只有该部分能够自动化。本研究由内隐联结产生的自动化形成速度更快, 且只需要和内隐规则的一部分联结就能自动扩散到整个内隐规则, 这种内隐联结自动化可能是新的特殊自动化。未来应进一步研究外显规则与内隐标签、外显规则与内隐规则的联结。
4.2 内隐否定知识比内隐肯定知识更加自动化
本研究相容条件组被试对语法B和非法U都要做拒绝的NG判断, 对语法B的击中率显著高于对非法U的击中率, 证明对学到的内隐否定知识能够很好地做出拒绝判断, 既符合外显的拒绝要求,又符合内隐的自动拒绝反应。这和Dienes等(1995)的对抗条件组相似, 其对抗条件组要求对语法B(或A, 详见1.2的第五点, 下同)和非法U都要做拒绝的NG判断, 只是语法B的击中率高于非法U的击中率但不显著, 而学习阶段对语法B做的是肯定学习, 那么对抗条件组语法B的击中率(即拒绝率)本应显著低于非法U的击中率。这个矛盾证明即使学到的语法B是内隐肯定知识, 但仅仅是外显要求对它做拒绝判断时, 否定倾向同样非常强大; 而内隐肯定知识的自动反应不足以抵抗这种强大的否定倾向, 甚至会协同外显要求做出拒绝反应。本研究相容条件组和Dienes等(1995)的对抗条件组得到了同样结果:对内隐知识做否定操作很容易。
而在检测自动反应方面, Dienes等(1995)的实验对语法B先肯定学习后否定判断, 产生了对抗,没有发现自动反应; 本研究反向对抗逻辑对语法B先否定学习后肯定判断, 也产生了对抗, 却发现了显著的自动反应。由两者结果的矛盾可推论:内隐知识不是完全自动的, 受到内隐标签的制约。对于内隐肯定知识, 外显具有很强的控制力; 但对于内隐否定知识, 外显则难以控制而产生自动否定反应。这从纯认知层面显示人类内隐加工可能天生就具有否定倾向:内隐知识从肯定转化为否定易, 从否定转化为肯定难(Wilder, Simon, & Faith, 1996), 否定的力量何其强大!
4.3 反向对抗逻辑范式能有效地检测到真实的自动反应和纯粹的受控反应
在引言中提到, Dienes等(1995)的实验在学习阶段是把语法A和B分别连贯学习, 被试可能更能够在同一套语法中比较不同的字符串, 从而习得深层的语法结构; 而在测量阶段语法A和B以及非法U三者具有同等的相似性, 使得采用相似性和熟悉性的策略无法完成任务, 只能提取语法规则知识来完成。而本研究创立的反向对抗逻辑范式能够在这种最严格和学习程度较高的人工语法学习范式中获得纯粹的受控反应和真实的自动反应, 比较有力地证明了人工语法学习确实包含了真实的内隐成分!
内隐序列学习范式中探索意识的研究很多, 主要原因就是遵从对抗逻辑范式产生的包含排除任务能够客观和定量地分离出内隐序列学习获得的受控反应即受控意识和自动反应即内隐成分(Fu et al,2010)。而人工语法范式无法成功应用对抗逻辑, 难以客观定量地分离其中的内隐和外显成分, 所以其意识研究走向了主观意识领域(Dienes & Scott,2005), 而在客观意识领域发展缓慢。因此本研究的反向对抗逻辑范式的成功, 可以为人工语法范式提供一种良好的客观定量的意识测量范式; 而作为一种普适性的工具, 可以进一步探索片段学习、组块学习、熟悉性、规则学习等不同的人工语法学习机制, 以及对应的研究范式(Pothos, 2007)各自产生的受控反应和自动反应有何特征和差异?受控反应和自动反应的组合与互动模式能否作为这些学习机制的良好校标?在此基础上可将该范式改造成被试内设计, 采用受控反应和自动反应的关系来确定每个人工语法字符串属于哪种学习机制和哪种知识。这将可能促进人工语法学习和意识机制研究的发展。当然还可以扩展到其它内隐学习和内隐认知领域, 探索抗干扰内隐学习和内隐辨别, 以及否定性内隐规则的学习机制。
4.4 内隐知识不等同于自动反应
需要强调的是, 反向对抗逻辑范式和已有的对抗逻辑范式的自动反应存在一定程度的本质差异:反向对抗逻辑范式的自动反应, 既是测量得到的也是本范式产生出的内隐成分。如3.2指出本范式的自动反应是对带有否定标签的内隐知识的自动拒绝反应, 可能对内隐否定知识的反应本就更自动。另外本范式要求被试写上标签“G”和“NG”, 并有再认辨别任务, 可能加深了内隐学习, 这是新增的实验程序, 与 Higham等(2000)和Dienes等(1995)都不同。因此可能是因为本研究在学习阶段通过手写将标签和语法更好地绑定, 建立起了反应联结。而Dienes等(1995)只是在学习结束后告诉被试记忆的语法B是合法的“G”, 在学习阶段没有给予反应联结, 得到的内隐知识和标签“G”的联结可能比较松散, 在测量阶段就难以对语法B产生相应标签“G”的自动反应。故进一步研究可以改进其实验程序——在学习阶段对语法B手写打上标签“G”; 同理可以反过来在本研究范式中撤销手写步骤, 如果还是检验出自动反应就证明并非是手写反应联结的贡献。
同理Higham等(2000)测量到的自动反应也是其实验范式制造出来的, 其成分和本研究有本质差异, 它可能是形式相似性造成的虚假自动反应。而Dienes等(1995)虽然没有发现自动反应, 但不能认为一定没有自动反应和内隐成分, 因为按照经典人工语法口语报告的测量标准, 其实验中对语法的学习存在很多内隐成分。由于实验范式很严格, 可能这种自动反应被非法字符串U的高接受率掩盖了;也可能是这种自动反应本身容易受到外显的拒绝要求控制, 失去了自动特征(详见3.2); 还可能是严格的实验材料提高了被试辨别力, 导致这种自动反应被辨别力所控制而与外显要求协同, 失去了自动特征(详见3.3)。无论哪种情况, 这种可能存在的“自动反应”和本研究的自动反应的本质确实不一样。对比可推论:内隐知识不等于自动反应, 既存在自动的内隐知识, 也存在受控的内隐知识(Kiefer,2012; Horga & Maia, 2012); 外显知识也可能如此,既有受控的外显知识, 也有明明意识到却无法控制的自动外显知识。
5 结论
为了解决人工语法对抗逻辑范式的缺陷, 本研究创立了反向对抗逻辑范式, 实验证明:
(1)外显否定标签可以和语法绑定进行内隐学习, 成为自动化的否定标签; 内隐否定知识比肯定知识更自动; 内隐知识从肯定转化为否定易, 从否定转化为肯定难。
(2)首次析出了高概率偏向效应, 得到纯粹的受控反应。
(3)反向对抗逻辑范式能有效地检测到真实的自动反应, 不受语法间形式相似性和被试辨别力的影响, 因此在对抗逻辑范式不能得到自动反应的严格匹配了形式相似性的实验材料上却非常有效, 解决了人工语法对抗逻辑范式的几个重大缺陷。
Cleeremans, A., & Jiménez, L. (2002). Implicit learning and consciousness: A graded, dynamic perspective. In R. M.French & A. Cleeremans (Eds.),Implicit learning and consciousness: An empirical, philosophical and computational consensus in the making?(pp. 1–40). Hove, UK: Psychology Press.
Cohen J. R., & Poldrack R. A. (2008). Automaticity in motor sequence learning does not impair response inhibition.Psychonomic Bulletin & Review, 15, 108–115.
Destrebecqz, A., & Cleeremans, A. (2001). Can sequence learning be implicit? New evidence with the process dissociation procedure.Psychonomic Bulletin & Review, 8, 343–350.
Dienes, Z., Altmann, G. T. M., Kwan, L., & Goode, A. (1995)Unconscious knowledge of artificial grammars is applied strategically.Journal of Experimental Psychology: Learning,Memory, and Cognition, 21, 1322–1338.
Dienes, Z., & Scott, R. (2005). Measuring unconscious knowledge:Distinguishing structural knowledge and judgment knowledge.Psychological Research, 69, 338–351.
Fu, Q. F., Dienes, Z., & Fu, X. L. (2010). Can unconscious knowledge allow control in sequence learning?.Consciousness and Cognition, 19, 462–474.
Higham, P. A., & Vokey, J. R. (2000). The controlled application of a strategy can still produce automatic effects: Reply to Redington (2000).Journal of Experimental Psychology:General, 129, 476–480.
Higham, P. A., Vokey, J. R., & Pritchard, J. L. (2000). Beyond dissociation logic: Evidence for controlled and automatic influences in artificial grammar learning.Journal of Experimental Psychology: General, 129, 457–470.
Horga, G., & Maia, T. V. (2012). Conscious and unconscious processes in cognitive control: A theoretical perspective and a novel empirical approach.Frontiers in Human Neuroscience, 6, 199.
Jacoby, L. L., Woloshyn, V., & Kelley, C. (1989). Becoming famous without being recognized: Unconscious influences of memory produced by dividing attention.Journal of Experimental Psychology: General, 118, 115–125.
Jacoby, L. L. (1991). A process dissociation framework:Separating automatic from intentional uses of memory.Journal of Memory and Language, 30, 513–541.
Jiménez, L., Méndez, C., & Cleeremans, A. (1996). Comparing direct and indirect measures of sequence learning.Journal of Experimental Psychology: Learning, Memory, and Cognition,22, 948–969.
Johansson, T. (2008).Knowledge representation, heuristics,and awareness in artificial grammar learning. Printed in Lund, Sweden, by KFS in Lund AB.
Kiefer, M. (2012). Executive control over unconscious cognition: Attentional sensitization of unconscious information processing.Frontiers in Human Neuroscience, 6, 61.
Mong, H., McCabe, D. P., & Clegg, B. (2012). Evidence of automatic processing in sequence learning using processdissociation.Advances in Cognitive Psychology, 8(2), 98–108.
Norman, E., Price, M. C., & Jones, E. (2011). Measuring strategic control in artificial grammar learning.Consciousness and Cognition, 20, 1920–1929.
Nosofsky, R. M. (1988). Similarity, frequency, and category representations.Journal of Experimental Psychology: Learning,Memory, and Cognition, 14, 54–65.
Nosofsky, R. M., & Zaki, S. R. (1998). Dissociations between categorization and recognition in amnesic and normal individuals: An exemplar-based interpretation.Psychological Science, 9, 247–255.
Pothos, E. M. (2005). The rules versus similarity distinction.Behavioral and Brain Sciences, 28, 1–14.
Pothos, E. M. (2007). Theories of Artificial Grammar Learning.Psychological Bulletin, 133, 227–244.
Redington, M. (2000). Not evidence for separable controlled and automatic influences in artificial grammar learning:Comment on Higham, Vokey, and Pritchard (2000).Journal of Experimental Psychology: General, 129, 471–475.
Reingold, E. M., & Merikle, P. M. (1988). Using direct and indirect measures to study perception without awareness.Perception & Psychophysics, 44, 563–575.
Soetens, E., Melis, A., & Notebaert, W. (2004). Sequence learning and sequential effects.Psychological Research, 69,124–137.
Tunney, R. J., & Shanks, D. R. (2003). Does opposition logic provide evidence for conscious and unconscious processes in artificial grammar learning?.Consciousness and Cognition,12, 201–218.
Vokeya, J. R., & Higham, P. A. (2004). Opposition logic and neural network models in artificial grammar learning.Consciousness and Cognition, 13, 565–578.
Wan, L. L., Dienes, Z., & Fu, X. L. (2008). Intentional control based on familiarity in artificial grammar learningConsciousness and Cognition, 17, 1209–1218.
Wilder, D. A., Simon, A. F., & Faith, M. (1996). Enhancing the impact of counterstereotypic information: Dispositional attributions for deviance. Journal of Personality and Social Psychology, 71, 276–287.
Yonelinas, A. P. (2002). The nature of recollection and familiarity: A review of 30 years of research.Journal of Memory and Language,46, 441–517.
Zhang, R. L., & Liu, D. Z. (2014). The development of graded consciousness in artificial grammar learning.Acta Psychologica Sinica, 46, 1649–1660.
[张润来, 刘电芝. (2014). 人工语法学习中意识加工的渐进发展.心理学报, 46, 1649–1660.]
