一种基于无监督学习的交集型歧义处理改进方法*
2016-01-28黄鹏,张姝,陈玉华等
一种基于无监督学习的交集型歧义处理改进方法*
黄鹏1,3,张姝2,陈玉华1,文斌1
(1.云南师范大学 信息学院,云南 昆明 650500;2.云南师范大学 档案馆,云南 昆明 650500;
3.云南师范大学 民族教育信息化教育部重点实验室,云南 昆明 650500)
摘要:歧义处理是中文分词的难点之一,其中交集型歧义占该类问题的主要部分,而无监督学习可以利用互联网上的无标注语料库来处理该问题.文章将比较卡方统计量、t-测试差在歧义处理中的效果,通过对其研究提出一种改善歧义处理性能的方法.实验结果表明,所提出的方法能有效进行分词,并提高了交集型歧义消解的性能.
关键词:分词;无监督学习;交集型歧义
1引言
分词是中文文本信息处理的基础,它是将一串汉字切分成词的过程.而歧义处理是其中的一个难点,其中交集型歧义占该类问题的90%左右[1].近年来,中文分词算法得到长足发展,目前基于词典和统计相结合的分词方法以及字词联合解码[2],能有效提高分词效率和低频词的发现,并能进行歧义处理和未登录词(Out-Of-Vocabulary,OOV)的识别[3].其中统计方法主要分为有监督学习方法和无监督学习方法[4],有监督学习可以从标注语料中统计更为准确的语言模型、词出现的概率、词类之间的转移概率、发射概率等信息,如:N-最短路径方法[5]、支持向量机[6]、条件随机场[7]、最大间隔马尔科夫网络[8]等,对训练语料来自同领域内的切分歧义消解有优势,其分词效果的F值高达0.95[9],但严重依赖于有标注语料库.无监督学习可通过无标注语料库进行分词,但其F值最高仅为0.85[10].
基于这些工作,本文认为随着互联网的发展,可以从网上获取各个领域大规模无标注语料库,结合词典分词与改进无监督学习方法,通过大规模无标注语料库的运用,能有效改善文本分词中所产生的交集型歧义能力.
2分词中的歧义问题
2.1歧义类型
歧义是指中文分词过程中,同一句话可能产生2种及以上的切分方法[11].下面分别定义几种类型的歧义.
定义1在字段ABC中,AB∈W,并且BC∈W,则ABC称为交集型歧义字段,其中A、B、C为字串,W为词表.如“要了解和研究学生”,可以切分为“要了/解/和/研究/学生”和“要/了解/和/研究/学生”.
定义2在字段AB中AB∈W,A∈W,B∈W,则AB称为组合型歧义字段,其中A、B为字串, W为词表.如“请把手拿开”,可以切分为“请/把/手/拿开”和“请/把手/拿开”.
2.2交集型歧义识别
双向最大匹配法可以发现文本中的交集型歧义,原理是通过正向最大匹配算法(Forward Maximum Matching,FMM)和逆向最大匹配算法(Reverse Maximum Matching,RMM)进行分词[12],通过比较两种分词方法所得出的结果找出交集型歧义.其中正向最大匹配算法基本思想为将文本断句后,从左向右按词典中的最大长度汉字取出字段,通过比较词典中的词,如能匹配则切分出来,如不能匹配则减去最末尾一个字,再重新匹配,直到最后一个字.逆向最大匹配法和正向最大匹配法类似,只是方向不同.
2.3卡方统计量
卡方统计量主要用来计算两个字的向关联度,能够有效地解决歧义问题,提高文本分词效果[13].其公式如下
(1)
其中,c1和c2分别代表连续的两个字;A代表语料中c1、c2出现的次数;B代表语料中第1个字为c1但第2个字不为c2的次数;C代表语料中第1个字不为c1但第2个字为c2的次数;D代表语料中第1个字不为c1且第2个字不为c2的次数;N代表语料中所有二元组的个数,即N=A+B+C+D.如果两个字的卡方统计值比较大,则说明这两个字倾向于连接,如果两个字的卡方统计值较小,则说明这两个字不经常在一起出现,倾向于分离.
2.4卡方统计量归一化
在运用卡方统计量比较两字关联程度时,其值离散化较大,不方便比较,需要进一步归一化将卡方统计量归一化到0到100以内,归一化公式如下
(2)
通过对民族文化样本库中的文本处理,按照卡方统计量进行处理存在并不能完全准确的情况,如处理字符串“以极大地满足佤族群众”,发现“极大”存在歧义,其卡方统计量为0.101936,如按卡方统计值过小来处理,则“极大”应该断开,但在文中应该连接.
2.5t-测试
针对卡方统计量只比较两字之间的相关度,没有比较字与上下文中其他字的相关度,而t-测试[14]可以解决相关问题.对有序字串xyz,汉字y相对于x及z的t-测试定义为:
(3)
其中,p(x|y)、p(z|y)分别是y关于x和z关于y的条件概率,σ2(p(y|x))、σ2(p(z|y))是各自的方差.从t-测试的定义可知:(1)如果tx,z(y)>0,则y与z有相连趋势,值越大,趋势越强;(2)如果tx,z(y)<0,则y与x有相连趋势,值越大,趋势越强;(3)如果tx,z(y)=0,则无任何倾向.
2.6t-测试差
针对t-测试不方便统计两字之间的倾向度,本文采用t-测试差来进行两字间倾向度比较.
定义3对汉字串wxyz,汉字x、y之间的t-测试差定义为:
Δt(x:y)=tw,y(x)-tx,z(y)
(4)
其中,Δt(x:y)有如下两种情况:(1)如有Δt(x:y)>0,则x,y则倾向于为词;(2)如Δt(x:y)<0,则x、y之间倾向于独立.
通过对民族文化样本库中的文本处理,按照t-测试差进行处理存在并不能完全准确的情况.如处理“地区性别比例不合理”字符串,发现歧义字段“例不”,其t-测试差为18.922889,按t-测试差方法进行处理应该连接成词,但在文中正确处理应该断开.
2.7联合卡方统计量和t-测试差
通过研究卡方统计量和t-测试差发现,结合卡方统计量两字的相关度和t-测试差上下文关联度的优点,提出了以组合的方式将卡方统计量和t-测试差值进行合并,提高交集型歧义处理能力,其联合公式如下
dc(x,y)=α×chi(x,y)*+β×Δt(x,y)+C
(5)
其中α、β为卡方统计量和t-测试差的权重值,C为线性叠加值.如果dc(x,y)>0则判断为x、y倾向于连;如果dc(x,y)<0则判断x、y倾向于断.总体算法流程如图1所示.
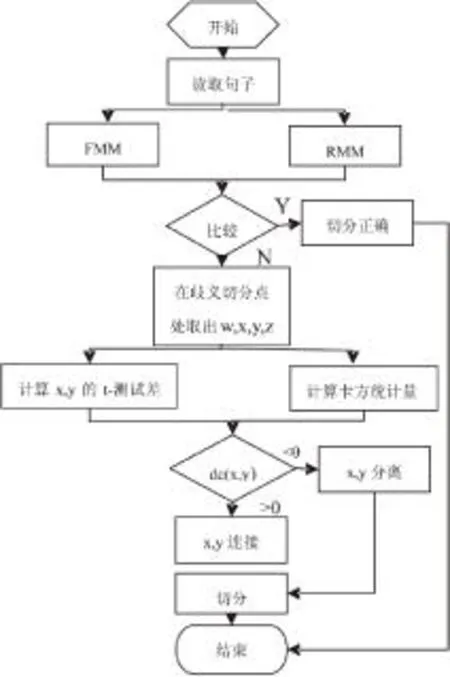
图1 总体算法流程图
3实验结果及分析
以民族文化类文本构建语料库,该语料库都爬取自互联网上的真实语料信息,民族文化类别包括法律、教育、地理、历史、军事、文化、艺术等,语料库规模大小为7M.实验使用词典方法进行粗分,选用MM进行分词,通过FMM和RMM发现歧义.然后使用卡方统计量和t-测试差以单独和组合的方式对交集型歧义进行处理.词典收录了中文常用词汇,其词汇量达20万条.
通过实验发现α的值为10、β值为1/16、C为-3时,歧义处理效果好,其结果如表1所示.
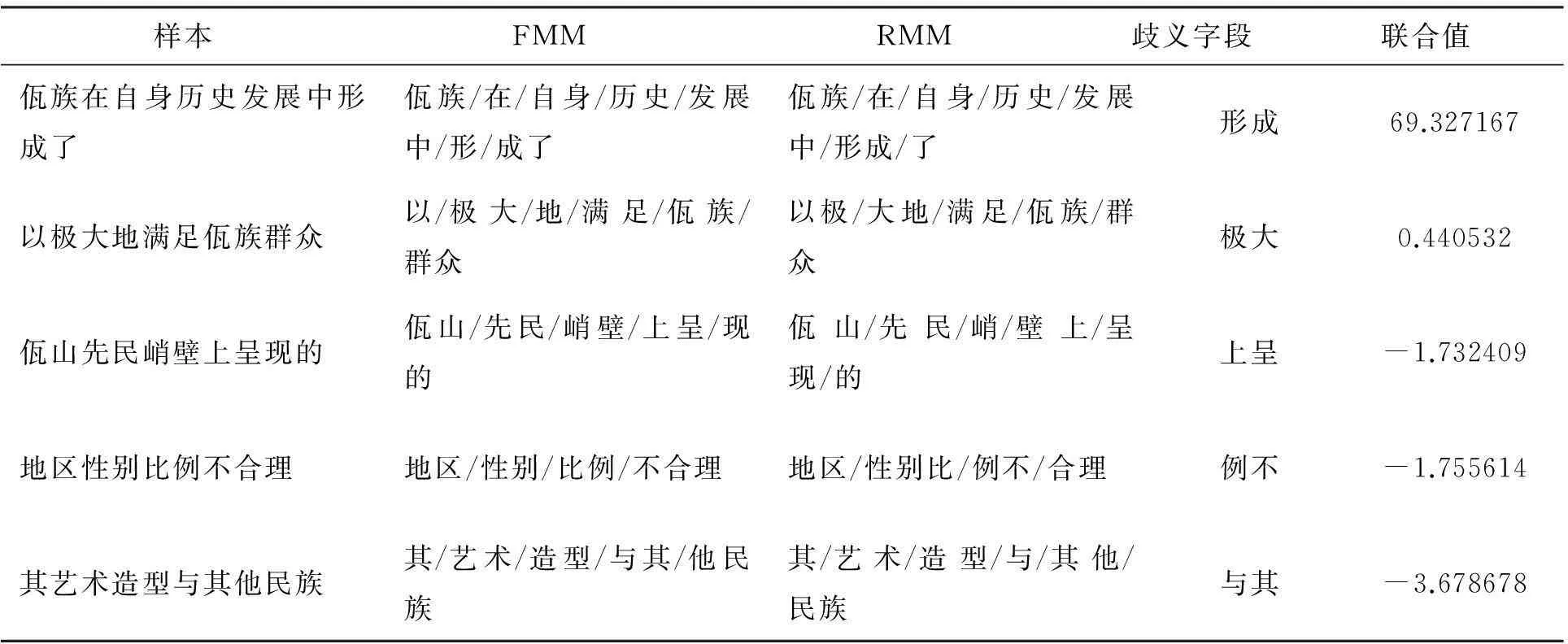
表1 样本中的卡方统计量和t-测试差联合值
根据实验结果可知,“上呈”、“例不”和“与其”的联合值为负应该断开,切分正确;“形成”和“极大”的值为正应该连接,切分正确.故以上结果表明通过联合值能够有效弥补卡方统计量和t-测试差的不足,提升交集型歧义处理效果.
运用卡方统计量和t-测试差等方法进行歧义消解后得到样本正确率等方面数据,其结果如表2所示.

表2 样本分词效果
其中F值是综合召回率和正确率的评估指标:F值=正确率×召回率×2/(正确率+召回率).实验结果表明该方法能够有效地提高歧义处理的效果,在召回率、正确率和F值方面比前3种分词方法都有提升.
4结束语
本文比较卡方统计量、t-测试差在歧义处理中的效果,通过对其研究提出一种改善歧义处理性能的方法.实验结果表明,提出的方法能有效进行分词,并提高了交集型歧义消解的性能.下一步将研究云计算环境下大规模语料库的处理问题.
参考文献:
[1]刘健,张维明.一种快速的交集型歧义检测方法[J].计算机应用研究,2008,25(11):3259-3261.
[2]宋彦,蔡东风,张桂平,等.一种基于字词联合解码的中文分词方法[J].软件学报,2009,20(9):2366-2375.
[3]韩冬煦,常宝宝.中文分词模型的领域适应性方法[J].计算机学报,2015,38(2):272-281.
[4]HUANG C N,ZHAO H.Chinese word segmentation:A decade review[J].Journal of Chinese Information Processing,2007,21(3):8-19.
[5]张华平,刘群.基于N-最短路径方法的中文词语粗分模型[J].中文信息学报,2002,16(5):1-7.
[6]BRERETON R G,LLOYD G R.Support vector machines for classification and regression.[J].Analyst,2010,135(2):230-267.
[7]LAFFERTY J D,MCCALLUM A,PEREIRA F C N.Conditional random fields: probabilistic models for segmenting and labeling sequence data[C].Proc International Conference on Machine Learning,Williamstown,USA,2001.
[8]QIAO W,SUN M.Joint Chinese word segmentation and named entity recognition based on max-margin Markov networks[J].Journal of Tsinghua University,2010,50(5):758-757.
[9]孙茂松,肖明,邹嘉彦.基于无指导学习策略的无词表条件下的汉语自动分词[J].计算机学报,2004,27(6):736-742.
[10]姜芳,李国和,岳翔,等.基于粗分和词性标注的中文分词方法[J].计算机工程与应用,2015,51(6):204-207.
[11]翟凤文,赫枫龄,左万利.基于统计规则的交集型歧义处理方法[J].吉林大学学报:理学版,2006,44(2):223-228.
[12]修驰.适应于不同领域的中文分词方法研究与实现[D].北京:北京工业大学,2013.
[13]CHANG B,HAN D.Enhancing domain portability of Chinese segmentation model using chi-square statistics and bootstrapping[C].Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing Association for Computational Linguistics,Massachusetts,USA,2010.
[14]曹卫峰.中文分词关键技术研究[D].南京:南京理工大学,2009.
An Improved Method of Crossing Ambiguities
Based on Unsupervised Learning
HUANG Peng1,3, ZHANG Shu2, CHEN Yu-hua1, WEN Bin1
(1.School of Information,Yunnan Normal University,Kunming 650500,China;
2.Archives of Yunnan Normal University,Kunming 650500,China;3.Key Laboratory of Educational
Informatization for Nationalities of the Ministry of Education,Yunnan Normal University,Kunming 650500,China)
Abstract:Processing of ambiguities is the key problem in the automatic segmentation of Chinese words.The solution of crossing ambiguities is still an open issue in this problem,and unsupervised learning can make use of the in POS-untagged corpora from internet to deal with the problem.In this article, we compare the chi-square statistic,t-test results in the ambiguity processing. Based on analysis of them,some modified methods to further improve its capacity were proposed.The experimental results show that the proposed method can effectively segment Chinese words and improve the performance of crossing ambiguity processing.
Keywords:Word segmentation; Unsupervised learning; Crossing ambiguities
中图分类号:TP391
文献标志码:A
文章编号:1007-9793(2015)06-0045-05
通信作者:张姝.
作者简介:黄鹏(1990-),男,湖南汨罗人,硕士研究生,主要从事知识工程方面研究.
基金项目:国家自然科学基金资助项目(61262071);云南省应用基础研究计划青年资助项目(2013FD015).
收稿日期:*2015-09-13
