关注可视化文本分析中的技术优势*——基于全国教育科学规划教育技术类课题的命题分析
2016-01-15
关注可视化文本分析中的技术优势*——基于全国教育科学规划教育技术类课题的命题分析
□郁晓华
摘要:可视化文本分析表达了一种对文本数据运用交互式图形呈现方式,实现知识发现的信息分析技术和过程,其应用过程一般分为文本处理、可视化呈现和交互理解三个阶段。进行文本可视化分析操作时,需根据研究对象的特征,选择恰当的工具,从原始材料中抽取文本的特征属性或元数据,在合适的视觉编码描绘和概括文本内容、结构、关系等基础上,与用户互动,揭示文本信息的特征和规律。已有研究表明,借助技术在计算和可视化上的能力,可视化文本分析技术可以弥补人工分析时存在的耗时长、主观性强等问题,提升文本信息处理与理解的效率,深入探察数据中隐藏的特征、关系和模式。基于全国教育科学规划教育技术类课题的案例研究验证了这些优势,且这一做法正逐渐引发业内的研究关注,成为一大发展趋势。案例研究还发现:受中文自然语言处理技术还不够成熟的影响,可视化文本分析在中文文本应用中还比较有限,在分词、工具选用以及分析深度等方面还存在不足。
关键词:信息可视化;文本分析;可视化工具;操作方法;案例研究
一、引言
科技的迅猛发展使得现今社会比以往任何一个时期都更富于变化与创新,知识的大量涌现和激烈的社会竞争要求人们能快速从大量文本信息和不同观点中建构自己的理解并加以创新。为应对这一转变,有效利用技术的力量加速人们对于文本信息的处理与理解,进而发现数据中隐藏的特征、关系和模式就成为了解决问题的有力路径,在此背景下,可视化文本分析技术(Visual Text Analytics)应运而生。可视化文本分析有效整合了文本分析和信息可视化两个技术领域的核心优势,用直观、交互式图形对抽象、非结构化文本数据加以呈现,以有效支持信息的分析理解和知识的挖掘发现。虽然当前国内有一些可视化文本分析技术的介绍,但人们对于如何选用可视化文本分析工具,如何进行文本信息的抽取、可视化结果呈现等还缺乏直观、深入的了解。本文以“十一五”、“十二五”全国教育科学规划教育技术类立项课题为应用案例,运用可视化文本分析技术对这些课题的标题信息展开研究,在验证其优势的基础上,展示可视化文本分析技术的应用过程,探讨其在应用方面的一些操作技巧以及在中文应用中所存在的不足。
二、可视化文本分析技术概述
1.文本分析、信息可视化与可视化文本分析
从字面含义剖析,可视化文本分析涉及两类关键技术,即文本分析(Text Analytics)和信息可视化(Information Visualization)。
文本分析也称为文本挖掘(Text Mining),泛指对非结构化文本中所包含数据进行分析的技术(Miner et al.,2012)。这一主题下隐含的核心任务就是要将非结构化的文本转化为有意义的数据,用算法加以分析从而为决策提供支持。文本分析的方法覆盖了从完全算法型(Algorithmic)到完全探索型(Exploratory)两极。算法型方法和探索型方法的根本区别在于是否有一个明确遵循的目标或处理过程。其中,探索型方法一般不预设目标和过程,分析时侧重在不断地探索中寻找线索形成指向(Kings College London,2007)。文本分析在社会科学领域的一个典型应用就是内容分析(Content Analytics)。Stemler(2001)认为内容分析其实就是一种系统的、可复制的技术,它将文本中众多的词汇依据明确的编码规则压缩成少量的内容分类。因此,文本分析常常会涉及概念词典的建立和应用,或者是某一固定术语词汇集的应用。依据这些词典或词汇集,文本数据将被抽取出来进行匹配或统计计算。
信息可视化研究的是如何用计算机技术对抽象数据实现互动化的视觉呈现(Card et al.,1999)。一张图抵千言万语。信息可视化充分利用了人类与生俱有的对图像信息迅速辨识和理解的能力,以直观方式传递抽象信息,增强了人们对于信息的观察和理解,进而放大了人类的认知能力,尤其是在工作记忆、模式的识别、各种关系的知觉推理等方面(Thomas et al.,2005)。在各类抽象数据中,文本是其中很重要的一类,因此文本可视化是信息可视化的一个重要子集。余红梅等(2011)、唐家渝等(2013)认为文本可视化就是将复杂文本中的内容、结构、关系和内在规律等提取出一定的模式,以视觉符号的形式表达出来,让用户通过与可视化界面的交互来快速理解文本,为知识发现提供支持。
总的来讲,文本分析侧重于非结构化文本中信息的抽取以及关系和规律模式的形成,而信息可视化侧重于结果的视觉化呈现与互动,两者在方法和过程上存在一些重叠。将两者相结合,可视化文本分析描述了一种对文本数据运用交互式图形呈现方式实现知识发现的信息分析技术和过程(Risch et al.,2008)。这一技术和过程将计算机的能力(如图形和计算的功能)和人的智慧(如认知、关联和推理的能力)紧密联合在一起,为更好地理解文本和发现知识提供了新的有效途径(刘世霞等,2011;唐家渝等,2013)。
2.可视化文本分析的过程与方法
可视化文本分析的主要目标是快速从文本中找出重要内容,形成图形,揭示文本的内容结构和关系规律,以帮助用户快速获取所需信息。这一过程一般可划分为文本处理、可视化呈现和交互理解三个阶段(唐家渝等,2013)。
(1)文本处理阶段
这一阶段将生成可视化分析所需数据,文本的特征属性或其他元数据将被分析抽取出来。一般来讲,文本特征或元数据获取越多,越有利于后面的信息分析。分析中常应用到的文本特征有词频、位置、词性和词义等。其中,词频表示词在文档中出现的次数,也是最容易获取的数据。一般而言,除去联系词,词频越高表示词与所在文档主题的相关性越高,也意味着其在文档中的重要性越高。另外,由于首段、末段、段首、段尾等特殊位置在文档中常用于揭示文档的主要内容和核心观点,因此出现在这些位置的词尤其要加以关注。在词性上,名词、动词、形容词等实词相对于连词、介词等虚词在文本信息传达上的表现力要更强些。词义最难,一般系统在处理词义时需同时配合领域知识库或领域知识本体的运用。
文本处理时常用到的关键技术有文档结构解析方法、实体提取技术和情感分析技术等。其中,解析文档结构时的分词技术非常重要,分词的准确率和合理性将直接对后面信息分析的有效性产生重大影响。分词要求能正确识别单词或词汇单元中的连词符(比如人名中的中间点)、特定符号等(比如电子邮件),单词的大小写、缩写等。分词、抽取、归一化等操作后提取出的词汇利用特征数据构建向量空间模型并进行降维,或利用主题模型处理特征数据,原始无结构或结构较弱的文本数据与其特征属性加以整合后将变成有意义的结构化信息,这些最终形成的数据将用于后面阶段的可视化呈现和交互。
(2)可视化呈现阶段
这一阶段将完成数据到图形的转换,一个重要任务就是选择合适的视觉编码来描绘和概括文本的内容、结构、关系等,得出所谓的文本可视化。通常,文本词汇的视觉编码主要服务于突显内容的重要程度,可使用的方式有大小、长度、颜色、形状、面积、位置等,比如用字体的大小反映词频,用区块面积反映重要性;而文本结构、关系等的视觉编码相对更为复杂,需要综合使用多种文本特征数据,甚至需要结合文档来源的社会、历史和文化等背景信息,主要用到的手段有时间线、树状图、网络图、叠式图、主题地图、知识图谱等。
依据文本可视化对特征属性数据的不同选取,文本可视化可分为基于文本词汇的可视化、基于文本关系的可视化以及基于多层面信息的可视化三大类(刘世霞等,2011;袁海等,2014),分别服务于不同的分析目标,如表1所示。
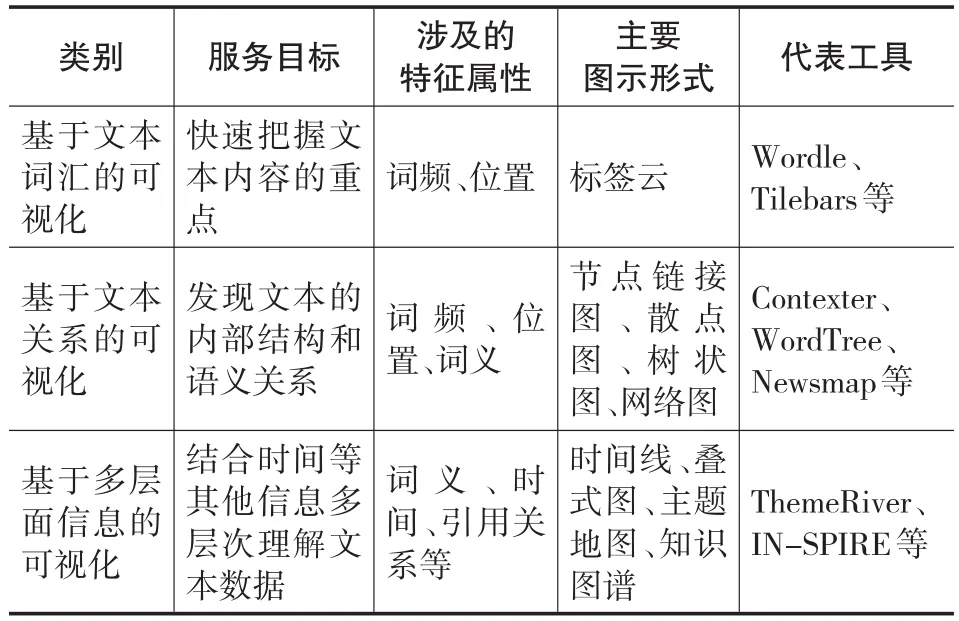
表1 文本可视化分类
(3)交互理解阶段
这一阶段用户与视觉图形互动以发现文本信息的特征和规律。一般而言,文本可视化后都会提供一定的交互功能以帮助用户设置合适的视角加以观察和理解,主要应用到的交互手段有全局+详细、平移+缩放、焦点+上下文及变形、动态过滤、多视图关联协调等(杨彦波等,2014)。
三、案例研究的设计
1.研究对象
科教兴国是我国实现国家强盛、民族复兴长期秉持的发展战略,每年的全国教育规划课题申报工作可以说是我国教育科研领域的最大盛事。优秀的选题不仅指明了我国教育改革发展和现代化建设中亟需解决的重大理论与实践问题,还将引领我国教育科学研究的未来发展方向(全国教育科学规划领导小组办公室,2012)。这些研究选题的思想、方法和价值大多通过好的课题命题被有效加以表达和传递。因此,标题文字不仅要浓缩课题研究的精华,其遣词造句上的立意也需用心良苦,才能使其在课题评审中被高效识别并得到广泛认同。要揭露课题命题中的秘密,对标题信息开展可视化文本分析研究将是一个不错的方法选择。
2.研究假设
区别于以往同类型主题研究(张刚要,2008;刘晶波等,2008)中较多依赖于人的主观加工和处理的做法,可视化文本分析大量借助了技术在计算和可视化上的优势。因此,本文假设这一做法将在案例的以下研究方面发挥作用:
(1)传统同类型主题研究往往需要人为凝炼标题的主要内容或抽取标题的核心观点,不仅工作量巨大且在分析之前就使分析材料带有了一定认知偏向,这在一定程度影响了结论的客观性。采用可视化文本分析后,技术对人工的替代可以克服这两方面的不足。
(2)由于标题所涵盖的信息有限(课题申请书是不公开的),人工分析的范畴和程度也会比较有限。传统同类型主题研究几乎都仅聚焦于现状及发展变化上,而采用可视化文本分析后,通过关系和规律的可视化揭露,应能在分析的视角上有所突破,比如命名中的一些构造规则和常用范式,以及课题研究的区域分布特点等。
3.文本可视化工具的选取
可视化文本分析提供了一条不同于以往的全新方式去解读文本。当前,实现文本可视化的工具很多(Brady,2012),但能够服务于中文可视化分析的却很少。在这些工具中,比较知名且免费的有IBM研究中心和IBM Cognos软件组共同主持的Many-Eyes实验项目所开发的一套可视化工具集(http:// www-958.ibm.com/software/data/cognos/manyeyes/visualizations①)以及由Stéfan Sinclair和Geoffrey Rockwell研究文本分析工具和文本分析修辞合作项目所开发的基于网络的可视化分析环境Voyant/ Voyeur(http://hermeneuti.ca/voyeur/tools)。这两套可视化工具集都可支持用户输入自由文本(即原始文本信息),并在最基本的词频分析上提供了很多可视化呈现方式,比如词频曲线、气泡集合、标签云等。但相比较而言,Voyant在分析因素的种类上相对更为丰富、应用更为多样,其主要可视化工具如表2所示。
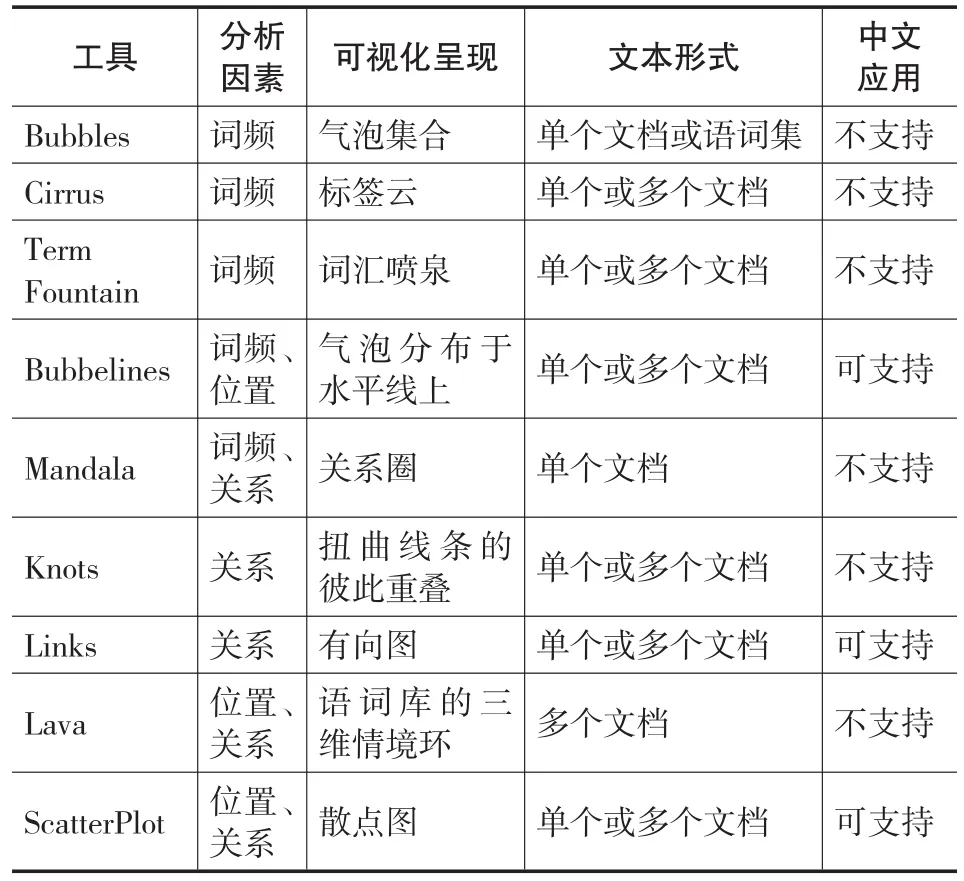
表2 Voyant工具集
本研究将从Voyant和ManyEyes中选取适合的且没有语言要求的工具展开针对全国教育科学规划教育技术类立项课题名称的可视化文本分析研究。
四、案例的研究过程
1.研究材料的处理
本研究的可视化文本分析材料来自于全国教育科学规划领导小组办公室在其官方网站(http://onsgep.moe.edu.cn/)上公布的“十一五”(2006-2010年)、“十二五”(2011-2013年)以来教育技术领域的立项课题(课题编号中含“CA”),共计201项,各年立项及地区分布情况如表3所示。
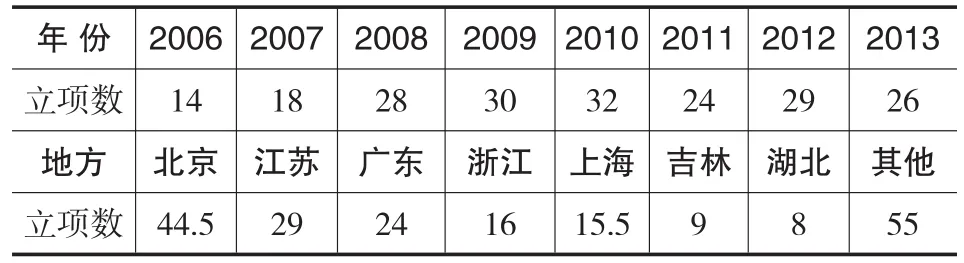
表3 2006-2013年全国教育科学规划教育技术类课题立项情况
由于案例研究不像以往同类型主题研究那样人工提炼核心词汇,而是直接分析原始词汇,因此首要工作就是要对课题名称进行分词处理。但中文是以字为单位,中文词语之间不像英文用空格对每个单词加以分隔自然形成分界,是没有明显区分标识的。此外,中文连续字之间的不同切割和组合还会产生不同的含义或语义侧重,因此中文分词的状况将直接影响可视化分析得出的结论。为保证中文分词的合理与准确性,本研究对课题名分词采用了技术分词和人工分词相结合的方式。技术分词就是使用分词工具实现快速分词,目前比较常见的中文分词工具有SCWS、NLPIR(前身ICTCLAS)、CJKAnalyzer、IKAnalyzer、paoding、MMSeg4j、imdict等。分词工具的选用除了考虑工具的分词原理与分词速度之外,还需要考虑工具所带词典种类、规模、可扩展性,以及工具对于歧义、数字、英文混合分词的处理效果等。综合以上多个因素的考虑,本研究选用了NLPIR汉语分词系统(http://ictclas.nlpir.org/)进行分词的初始处理;然后在此基础上,为进一步优化分词效果,结合了三位教育技术领域内研究人员的意见进行修订和调整;最终形成一份相对比较客观、合理的文本分词词汇集合。
在分词过程中,研究发现,无论分词工具如何设置和调整,对于语义的把握目前仍然不太成熟。因此,人工修订对分词的微调可从以下几个方面入手:
(1)去重复词。同一标题中重复的词汇只需统计一次,以有效获取主题的频次。比如课题“重庆市城市地区与农村地区中小学生信息素养的比较研究”,分词拆分会得到两个“地区”,但词频统计只需要计算一次即可。
(2)表示统一。标题中的同一词义,有的课题用中、英文分别表示;有的课题用类似但不同的词汇,这些情况在分词时会形成多个不同的词汇,不利于对课题专题的分析理解,因此人工调整阶段时应选用一种表示方式加以统一归并。比如“计算机支持的协作学习”与“CSCL”(统一用“CSCL”),“网络”与“WEB”(统一用“网络”),“虚拟学习社区”与“教育虚拟社区”(统一用“虚拟社区”),“教育资源”、“教育信息资源”和“数字化资源”(统一用“教育资源”)等。
(3)词意拆解。中文的词汇有时一个复合词可包含多个含义,这非常不利于对标题语义的分析,因此分析之前可人工进一步拆分为多个词汇分别表达。比如中小学生,可拆解为中小学和学生两个词汇。
2.可视化的呈现与解读
上一阶段分解获得的课题标题词汇集,将在这一阶段,在不同的目标需求下选择恰当的可视化方式加以呈现,实现对信息的分析和对知识的发现。虽然表1已给出了文本可视化应用的一般性指导原则,但在具体操作时,还需要根据可视化工具的特点做出灵活调整。
(1)用简单、可视化的词频变化解读当前教育技术领域研究需求和方法的转变
教育技术领域研究的关注点集中体现在一定时期内课题标题中一些关键词汇的运用,因此关注点的发展变化可结合这些词汇在不同时期的频次变化加以考察。从可视化文本分析的角度,这需要利用词汇的时间特征。由于本研究中将2006-2013年间的全国教育科学规划教育技术类立项课题名称的分词词汇集合按时间先后顺序放置在一个文本文件中,就将词汇的时间特性转换为相对比较简单的位置特性,因此可以使用Voyant中的Bubblelines工具。Bubblelines工具使用水平线作为时间轴,每个词汇都可有自己的时间轴,词汇就以气泡方式按其在文本中的先后分布情况在水平线上对应呈现。气泡的大小反映了词汇的频次,对于本研究而言,也即反映了词汇在特定时期受关注的重要程度。
由于Bubblelines工具支持选定词汇组的对比观察,因此可以从不同视角考察关注点的发展变化。在本研究中,我们不再重复以往同类型主题研究在教育技术研究主题和领域方面的研究结论,而试图通过可视化分析技术从研究需求和研究方法上加以揭示,因而选取对应的词汇集如表4所示。导入立项课题名称的分词词汇集合之后,在Bubblelines工具中按照设定的词汇集经过观察筛选可分别得如图1、图2所示的图示。

表4 当前教育技术研究领域变化的词汇集
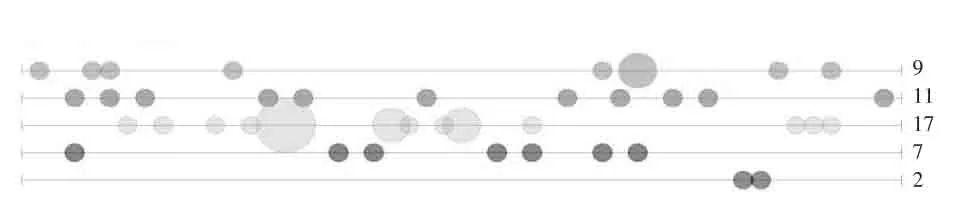
图1 技术应用于教育在不同时期需求层次的演变
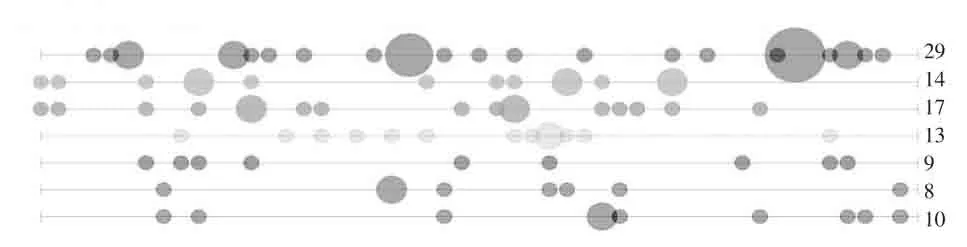
图2 教育技术研究在不同时期研究方法或方式上的侧重
进行可视化解读时,虽然时间轴不是很精确,但在理解趋势发展上影响并不是很大。因此,可大致将Bubbleline图示的水平轴等分成2006-2008(“十一五”前期)、2009-2010(“十一五”后期)、2011-2013(“十二五”前期)三段。借助这些直观图示,我们不难发现当前教育技术领域研究需求和研究方法的关注变化:
第一,技术带给教育的发展和创新需求一直是教育技术领域不变的话题。在“十一五”后期,效益需求被激发。而从“十二五”开始,变革需求开始提上议程。但奇怪的是,共享需求在“十一五”后期出现断档(见图1所示)。
第二,方法和结果在现实中的“应用”价值以及对实践的指导作用是教育技术领域研究一直十分强调的目标。在“十一五”期间,这一目标在课题标题中还常会用到“理论”与“实践”两个词汇分别表示方式上的侧重。“十一五”中、后期,使用“实证”和“评价”方式论证研究的有效性和合理性尤其突显(见图2所示)。
可见,在本次应用中,可视化文本的分词技术起到关键作用。相对于以往同类型专题的研究,技术分词的应用,使得词汇数据的粒度相对较小,也使得很多人工处理时容易忽视的“平凡”、“琐碎”的词汇被保留了下来,比如“理论”、“实践”、“创新”、“发展”等,从而有了更多层次、更多维度视角看待事物的支持基础。
(2)通过可视化交互突显观察要素,透视当前教育技术领域的区域研究特点
要分析当前教育技术领域的区域研究特点,除了课题名称词汇本身的特征属性数据之外,还需要用到课题来源的地区信息。选用ManyEyes的Country Map工具,将立项课题的地区分布情况数据值叠加在中国地图上,就可用比表格更为直观、形象的方式观察立项课题的全国空间格局。从图3中我们不难发现,教育技术类课题研究存在严重的区域分布不均衡现象,研究多集中在东部沿海地区,而黑龙江、青海、西藏、云南、贵州、宁夏、海南等地区在2006-2013年间竟无一项课题立项。
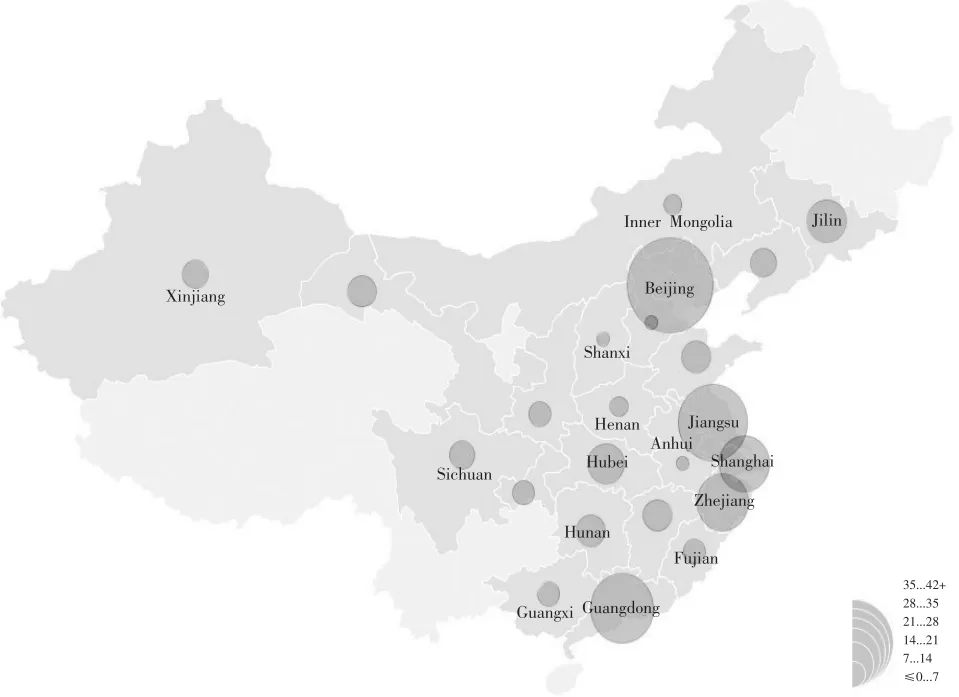
图3 2006-2013年间课题立项的区域分布
为进一步分析教育技术的区域研究特点,我们选用了标签云工具。由于标签云中所显示词汇的字体大小是直接映射该词汇在文本中出现的频次,从某种程度上也代表了该词汇对文本的重要性,因此使用标签云可快速将各地区研究课题中的核心主题和内容突显出来。虽然Voyant和ManyEyes都提供了实现标签云的工具,但功能上都无法很好支持本案例研究所需的互动观察,因此研究另外选用了服务上更为专业的标签云工具WordItOut(http://worditout.com)。首先,将立项课题的分词词汇集合按地区归属抽取出来分别加以整理,各自形成一个独立的文本文件。接着,在WordItOut中分别导入文本中的词汇。考虑可视化文本分析合理性对文本数量有一定要求,本研究仅选择立项数较多的北京、江苏、广东、浙江和上海5个省市加以考察。在WordItOut中,调整显示词汇的最低频次限度对显示词汇加以筛选过滤,得到5个省市对应的标签云(见图4)。
通过这些可视化图示,我们不难对当前教育技术领域的区域研究特点做出如下分析归纳:
第一,对于教育技术研究的主要组成内容,北京侧重于教师和资源,江苏侧重于教师和环境,浙江和上海分别侧重于环境与资源,而广东在这方面没有体现出明显的研究侧重。
第二,在教育技术应用领域上,北京和江苏都非常重视中小学中的教育应用。此外,北京还关注农村教育,江苏关注聋教育,广东关注职业教育,浙江关注高校,上海关注基础教育。
第三,在研究方式上,北京、江苏、浙江都非常看重应用,江苏还特别强调理论建构与实证评价,广东强调模式研究,上海则突出研究的实践。
第四,在研究主题上,北京对于教育技术能力的研究十分突出,而浙江则对课堂教学的研究比较侧重。
在本次应用中,可视化文本分析的交互技术起了关键作用。相对于以往同类型专题的研究,最低频次限度的过滤设置使得文本重心快速突显出来,视点得以聚焦,研究者不再被庞大、繁杂的数据所淹没。
(3)在文本关系的可视化中剖析课题命名的构造规则和常用范式

图4 5省市立项课题的标签云
对课题命名构造规则和常用范式的剖析,这一研究内容在以往同类型专题研究中几乎没有。分解课题名称的构造,大体可划分为条件背景、内容主题和方法结果三部分。其中,条件背景部分展示了课题开展的时代背景、研究领域或实验环境条件,内容主题部分表明了课题关注的领域主题、研究对象或问题,而方法结果部分则指出了课题使用的研究方法、实验手段以及最后的结果产出等。本研究所希望揭示的课题命名构造规则和范式,主要是指这三部分阐述中的一些用词习惯、搭配关系以及彼此之间的常用连接词等,其实质就是基于文本关系的可视化。这可以使用Voyant中的Links工具加以观察。Links工具在分析词汇词频与位置特征属性的基础上,发现词汇间的组合规律,然后使用有向图给予视觉的直观呈现,并以尺寸作为视觉编码展现词汇与邻近关键术语间的链接强弱。

图5 课题词汇的关系网络图
本研究将处理后的2006-2013年间的全国教育科学规划教育技术类立项课题名称的分词词汇集合导入Links工具中,调整所需要观察的频次较高的关键词汇,获得如图5所示的关系网络图,从中我们不难识别出课题名称构造中的常用词汇,如表5所示。

表5 课题名称构造中的常用词汇
进一步,再分别选取连接词汇和内容词汇细节化观察课题命名中的搭配关系。图6a、b、c分别显示了标题条件背景部分、内容主题部分、方法结果部分的构造习惯。总的来讲,借助可视化文本分析技术,我们可对课题命名的构造规则和常用范式作如下概要归纳:
第一,“研究”一词为课题命名中最为重要的构造用词(词频为187/201≈0.93)。
第二,“基于”、“下”、“中”三词常用于引导课题研究的条件背景说明。三者的区别在于“基于”用于技术研究,“下”用于对策研究,“中”用于应用研究(见图6a所示)。
第三,课题名称的内容主题部分,常用“及其”实现研究对象的并列陈述,并往往需在标题中用“在”和“中”指明研究的条件背景;用“促进”说明研究对象间的作用关系,同时搭配“发展”明示价值意义,“设计”明示结果产出(见图6b所示)。
第四,课题命名对于方法结果说明的用词中,“理论”与“实践”两词经常一起使用,且还会搭配“体系”一词。实证研究中,对“效益”开展“实证”,对“建设”进行“评估”。实践研究中,往往会开发“关键”“技术”,探讨“应用”“支持”(见图6c所示)。
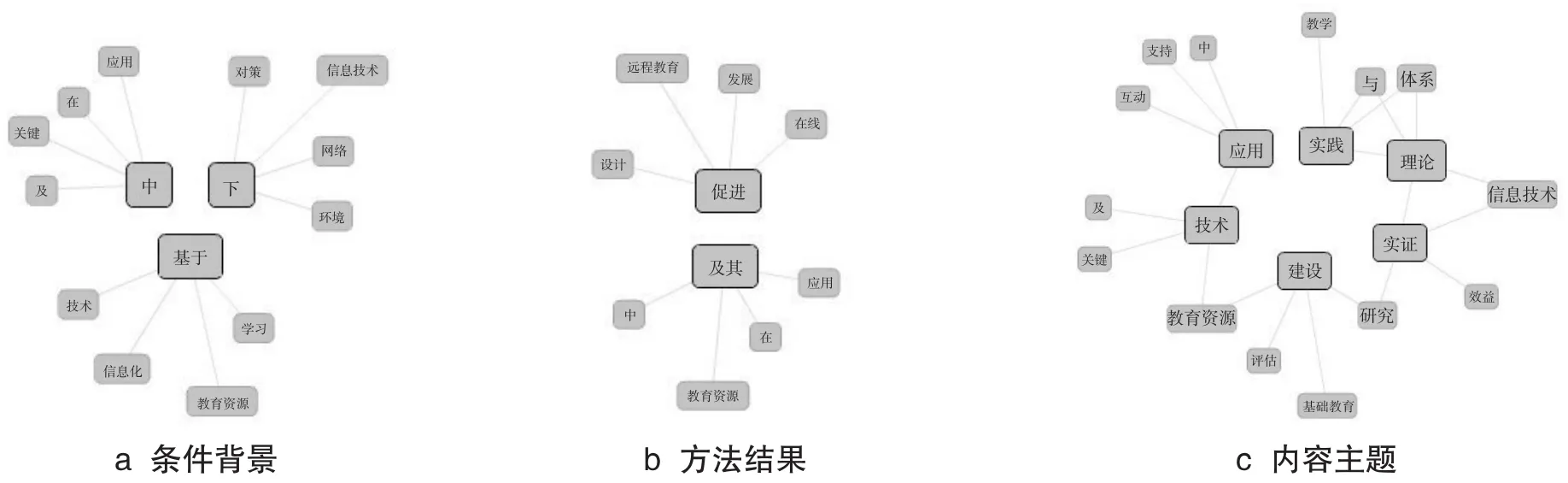
图6 课题命名构造规则和常用范式
虽然对于可视化后关系图的解读,主观因素的影响会很大。但相对于人工操作在关系和规律揭露上的费时费力,甚至束手无策,可视化文本分析的优势展露无遗。
五、结论与展望
可视化文本分析技术的价值不仅在于能用更为丰富和生动的方式展现结果,以帮助用户更方便地理解和接受所要传达的信息,更为重要的是能通过一系列的设计与算法,将文本中潜在的语义、结构等方面的关联和规律显性展现出来,帮助用户分析和发现更多有趣的有用信息。本文通过案例研究逐一验证了这些优势,而这一做法也正逐渐引发业内的研究关注,成为一大发展趋势(如胡晓玲等,2013)。
本研究虽然利用可视化文本分析技术对2006-2013年间全国教育科学规划教育技术类立项课题命名规律加进行探索和归纳,分析并揭示了当前教育技术领域研究的发展变化和区域分布特点,但也存在着以下一些不足:
第一,相对于人工提炼后的标题关键词汇,直接对标题分词后的原始词汇进行分析不仅快捷,而且还可有效增强结论的客观性。但由于中文文体的独特构造,在案例研究中不得不引入人工修订,这额外增加了工作量,同时也增加了主观影响的风险。
第二,由于现有大部分可视化文本分析工具不支持中文,因此案例研究在工具的选用上非常有限,很多工具的优势无法加以有效利用,比如单词树(以树状层次结构展现特定单词或语法在文本中的不同应用情境,工具如Word Tree)、层次词频结构(中心为特定词汇,外圈是整个文本中曾与该词汇搭配出现的词,词的大小是由出现的频次决定,工具如Docu-Burst),使得在后续图示的分析与解读上开展得不够全面充分,结论上难免有遗漏或误解之处。
第三,案例研究所选用的文本特征属性主要是频次、位置、时间等较为简单的数据,相应能支持对立项课题名称开展的分析也比较有限,因此研究结论中的一些理解可能还比较肤浅。若要深入解读和挖掘,研究还需借助质性研究中的内容分析技术,结合语法、语义和语用层面加以剖析。
总之,可视化文本分析技术现已逐渐彰显出其巨大的应用价值和广泛的发展空间,正被大量应用于信息处理、情报研究、知识挖掘、决策支持等相关领域。但更为有效的应用,应该是将可视化文本分析技术与学科领域的相关知识有机整合,从而更有效发挥计算机的计算能力,增强文本挖掘和知识发现的效能,在有效节省人类认知付出的同时高效提升人类理解的智慧。虽然受中文自然语言处理技术还比较薄弱的影响,可视化文本分析技术在中文文本中的应用还十分有限,但我们相信这仅是时间上的问题。
注释:
①论文发表时,ManyEyes的网址更改为http://www-969. ibm.com/software/analytics/manyeyes,工具类型及其使用操作也作了部分调整。
参考文献:
[1]胡晓玲,胡铁生,潘国等(2013).我国基础教育信息技术课题研究现状与趋势研究[J].教育信息技术,(12):18-20.
[2]刘晶波,丰新娜(2008).“全国教育科学规划课题”中学期教育课题研究的状况与分析[J].学前教育研究, (11): 12-17.
[3]刘世霞,曹楠(2011).可视化文本分析[J].中国计算机学会通讯, (7): 26-30.
[4]全国教育科学规划领导小组办公室(2012).全国教育科学规划课题管理办法[EB/OL]. [2014-08-26].http://onsgep.moe. edu.cn/edoas2/website7/level3.jsp?infoid=1335361775186559&id= 1335427422154100&location=null.
[5]唐家渝,刘知远,孙茂松(2013).文本可视化研究综述[J].计算机辅助设计与图形学学报, (3):273-285.
[6]杨彦波,刘滨,祁明月(2014).信息可视化研究综述[J].河北科技大学学报, (1):91-102.
[7]余红梅,梁战平(2011).文本可视化技术与竞争情报[J].图书情报工作, (8):79-83.
[8]袁海,陈康,陶彩霞等(2014).基于中文文本的可视化技术研究[J].电信科学,(4):114-122.
[9]张刚要(2008).全国教育科学规划2001-2007年教育技术学立项课题统计分析[J].电化教育研究, (10):90-93.
[10]Brady, A. (2012).See Text in Whole New Way: Text Visualization Tools[EB/OL]. [2014-08-26].http://blogs.princeton.edu/ etc/2012/08/16/see-text-in-whole-new-waytext-visualization-tools/.
[11]Card, S. K., Mackinlay, J. D., & Shneiderman, B. (1999). Readings in Information Visualization: Using Vision to Think[M]. Morgan Kaufmann.
[12]Kings College London (2007). Method in Text-Analysis: An Introduction [EB/OL]. [2014-08-26]. http://www.cch.kcl.ac.uk/legacy/teaching/av1000/textanalysis/method.html.
[13]Miner, G., Elder, J., & Hill, T. et al.(2012). Practical Text Mining and Statistical Analysis for Non-Structured Text Data Applications[M]. Academic Press.
[14]Risch, J., Kao, A., & Poteet, S. R. et al.(2008). Text Visualization for Visual Text Analytics[A]. Simoff S.J. et al. (Eds.). Visual Data Mining [C]. Springer Berlin Heidelberg:154-171.
[15]Stemler, S.(2001). An Overview of Content Analysis [J]. Practical Assessment, Research & Evaluation, 7(17) : 137-146.
[16]Thomas, J. J., & Cook, K. A. (2005).Illuminating the Path: The Research and Development Agenda for Visual Analytics[M]. National Visualization and Analytics Center.
[17]UCLA Library (n.d.). Text Analysis Tools[EB/OL]. [2014-08-26]. http://guides.library.ucla.edu/text.
design of these learning spaces, such as highly flexible seating arrangements and facilities for instantaneous information sharing within and across groups; yet it is also already clear that research on learning spaces is still in an early stage because of a small amount and poor quality of related academic research literature, the lack of scientific basis of learning spaces design and the shortage of rigorous empirical research. In the future, universities and research institutes should establish the interdisciplinary research team to further expand the research field as well as strengthen exchanges and cooperation in areas inside and outside.
Focusing on the Power of Visual Text Analytics——An Analyticsof the Titlesof Educational Technology Research Projectsofthe National Education Science Plan
Yu Xiaohua
Abstract:Visual text analytics shows a kind of information analysis techniques and processes of using interactive graphical methods to achieve knowledge discovery. Its application has three steps, including text processing, visual presentation and interactive interpretation. First, feature attributes or metadata should be extracted from the original text material with appropriate tools according to the characteristics of the study object. Then, based on the proper visual coding to describe and summarize the content, structure and relations of texts, traits and rules of the textual information are discovered through user interaction. Studies have shown that, with the capability of calculation and visualization of the technology, visual text analytics can make up the problems existing in manual analysis such as the time-consuming and subjectivity, enhance the efficiency of text information processing and understanding, and deeply explore the hidden characteristics, relationships and patterns of data. A case study carried out on the topics of educational technology research projects of the National Education Science Plan from 2006 to 2013 verified the advantages of visual text analytics in text comprehension. Visual text analytics is gradually arousing research attention and becomes a major trend. The case study also discussed the weakness of title tokenization, the inadequacies of research tools to support Chinese text analytics and the insufficient utilization of text features. Affected by the immaturity of Chinesenaturallanguageprocessingtechnology,theapplicationofvisualtextanalyticsin Chineseisstilllimited.
Keywords:Information Visualization; Text Analytics; Visualization Tools; Operation Method; Case Study
收稿日期2014-12-15责任编辑汪燕
作者简介:郁晓华,博士,副教授,华东师范大学教育信息技术学系(上海200062)。
*基金项目:全国教育科学“十二五”规划2013年度教育部重点课题“智慧教育视域下学习活动流及其信息模型建构与应用”(DCA130222)。
中图分类号:G434
文献标识码:A
文章编号:1009-5195(2015)03-0104-09 doi10.3969/j.issn.1009-5195.2015.03.012
