基于数据挖掘的围绝经期综合征中医证候分类算法分析
2016-01-11吴宏进许家佗张志枫屠立平张婷婷徐莲薇刘巧莲
吴宏进 许家佗 张志枫 屠立平 张婷婷 徐莲薇 刘巧莲
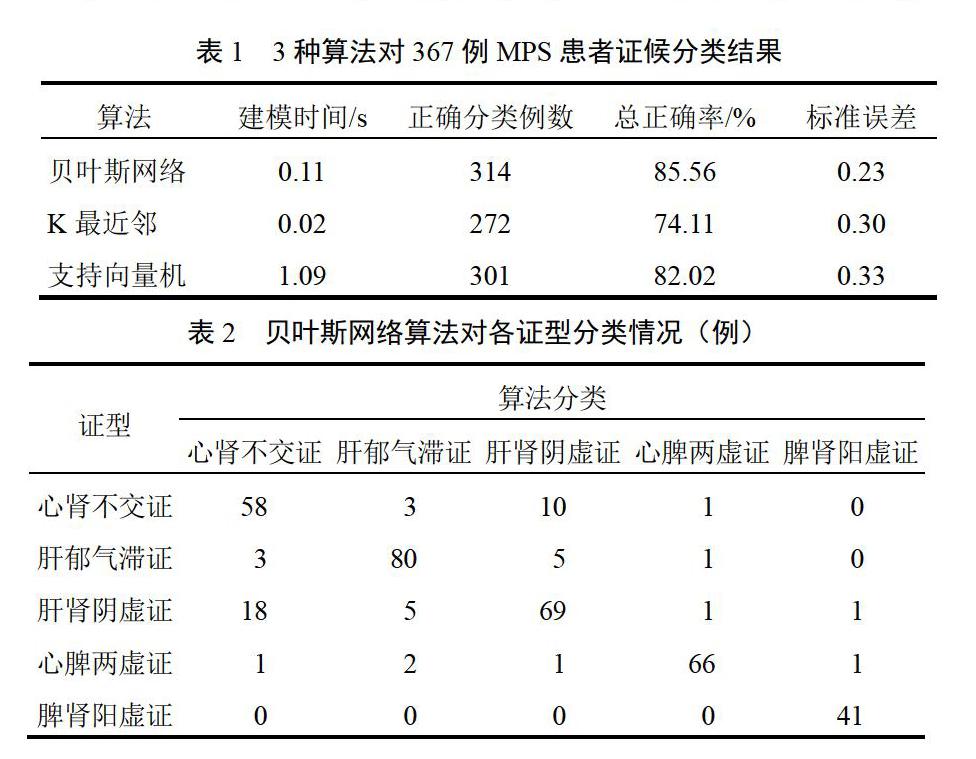
摘要:目的 采用现代中医诊断技术结合人工智能分析方法进行围绝经期综合征中医辨证研究,以期建立最佳证候分类方法。方法 门诊收集围绝经期综合征患者四诊信息,按照中医辨证标准进行证型分类,采用贝叶斯网络算法、K最近邻算法、支持向量机算法3种常用数据挖掘分类算法对围绝经期综合征四诊信息数据进行分析。结果 分别得出在相同训练、测试样本数据下3种算法建立围绝经期综合征中医证候模型所需时间、分类准确性、覆盖率及margin曲线,分析了训练样本数量对3种算法的影响,并对3种算法所建立模型进行了评价。结论 在围绝经期综合征证候分类效果方面,贝叶斯网络算法优于其他2种方法。
关键词:围绝经期综合征;中医证候;数据挖掘;分类算法;训练样本;margin曲线
DOI:10.3969/j.issn.1005-5304.2016.01.009
中图分类号:R259.886 文献标识码:A 文章编号:1005-5304(2016)01-0039-04
Classification Algorithm Analysis of TCM Syndrome of Menopausal Syndrome Based on Data Mining WU Hong-jin1, XU Jia-tuo2, ZHANG Zhi-feng2, TU Li-ping2, ZHANG Ting-ting3, XU Lian-wei1, LIU Qiao-lian3 (1. Longhua Hospital Affiliated to Shanghai University of TCM, Shanghai 200032, China; 2. Shanghai University of TCM, Shanghai 201203, China; 3. Yueyang Hospital Affiliated to Shanghai University of TCM, Shanghai 200437, China)
Abstract: Objective To establish the optimum syndrome classification method by using the technology of modern TCM diagnosis and artificial intelligence analysis method for menopausal syndrome differentiation of TCM. Methods Diagnostic information of menopausal syndrome patients was collected and syndromes were classified according to TCM syndrome differentiation standard. Three kinds of common data mining classification algorithm, Bayesian network, K-nearest neighbors and support vector machine, were used for analysis on information data of the four methods of diagnosis of menopausal syndrome. Results The time, classification accuracy, coverage rate and margin curve of establishing TCM syndrome model by the three kinds of algorithm methods under the circumstances of same training and data. The influence of the number of training samples of 3 kinds of algorithm methods was analyzed, and the model established by the three kinds of algorithms was evaluated. Conclusion Bayesian network algorithm is better than the other two methods in the menopausal syndrome classification effect.
Key words: menopausal syndrome; TCM syndrome; data mining; classification algorithm; training samples; margin curve
围绝经期综合征(menopausal syndrome,MPS)指妇女绝经前后出现的一系列绝经相关症状,是伴随卵巢功能下降乃至衰竭而出现的影响绝经相关健康的一组症候群,初为月经改变、潮热、盗汗、失眠及
泌尿生殖道症状,远期可发生骨质疏松和心血管疾患[1]。目前,国内有关本病的中医证候诊断尚无统一的规范的、客观的标准。因此,本研究采用数据挖掘分类方法对MPS证候进行分析。
数据挖掘方法主要有分类分析、聚类分析、关联分析、序列模式分析等。其中分类分析就是找出描述并区分数据类或概念的模型(或函数),以便能使用模型预测类标记未知的对象类。本课题采用数据挖掘技术中比较成熟的K最近邻、贝叶斯网络、支持向量机算法,研究其在MPS中医辨证中的应用。
1 资料与方法
1.1 研究对象
2011年4月-2012年10月上海中医药大学附属岳阳医院门诊MPS患者367例,年龄40~60岁,中医辨证为肝肾阴虚证94例、肝郁气滞证89例、脾肾阳虚证41例、心脾两虚证71例、心肾不交证72例。
1.2 纳入标准
⑴符合女性MPS诊断标准[2-4]:①年龄40~60岁妇女;②月经紊乱3个月以上;③出现潮热、烘热汗出、烦躁易怒、焦虑、情志异常等症状;④实验室检查示血清雌二醇(E2)降低,促卵泡素(FSH)明显上升。同时符合上述3条即可诊断。⑵符合肝肾阴虚证、肝郁气滞证、脾肾阳虚证、心脾两虚证或心肾不交证中医辨证分型标准[4-5]。
1.3 排除标准
①双侧附件及子宫切除术后;②合并急性感染性疾病者;③明确诊断患有呼吸、心脑血管、肝、肾、血液、内分泌等系统疾病者;④近3个月曾用过雌、孕激素替代治疗者。
1.4 调查方法
1.4.1 问诊指标及方法 采用问卷调查形式,遵循临床流行病学调研方法,设计统一的临床诊断记录表,由经过培训的中医诊断专业研究生逐一询问患者并填写记录表。该表是在前期文献分析基础上,结合本研究室《中医四诊信息采集表》(2007V2.0)和《健康状态评价问卷》(H20.V2009)[6],通过相关专家考评及数据收集反复修改而制定,包括患者年龄、职业、婚育状况、文化程度、既往史、用药史、症状体征、舌脉象等。中医辨证由相关专业具有副主任以上职称的3名医师进行辨证,取一致结果。
1.4.2 脉诊指标及方法 脉搏波采集分析设备采用上海中医药大学研制的DDMX-100型单道脉象仪(专利号ZL200520038993.8)。脉象定性分析指标为从脉图中读取的脉位、脉力、至数、脉名等。由3名以上中医诊断专家进行判读,取一致结果,判断标准以《现代中医脉诊学》[7]中的脉象分类标准为主。
1.4.3 舌诊指标及方法 舌象采集仪器采用本课题研发的TDA-1舌象仪(产品尺寸20 cm×15 cm×10 cm,包括光源设计、CCD设备构架、电源设计、外形设计等内容),采用本研究室研发的《中医舌诊分析系统》(V2.0)舌象分析软件进行数据分析。舌象定性指标:舌色分为淡白舌、淡红舌、红舌、红绛舌、黯红舌、青紫舌6类,苔色分为薄白苔、白苔、薄黄苔、少苔4类。正常舌象为淡红舌、薄白苔。舌象判断由3个相关诊断专家按颜色分类进行判断,取一致结果。
1.5 数据挖掘方法
采用基于JAVA的开源数据挖掘平台WEKA3.6数据挖掘软件[8],方法分别为贝叶斯网络算法、K最近邻算法、支持向量机算法。
1.6 实验分析
实验数据为367例病例的四诊信息,包括症状信息(包含51个特征属性)、脉搏波参数(包含24个特征属性)、舌图像参数(包含18个特征属性)。对原始数据进行预处理,并根据WEKA所要求的格式(.arff)将数据分为头信息和数据集信息2个部分;采用十折交叉验证方法进行分析。正确率为该属性被正确分类的概率,错误率指在所有被分配为该属性的记录中的错误率,精确度计算该属性的总体精确度,覆盖率评估模型在该属性上的覆盖率。
2 结果
2.1 3种算法分类结果
K最近邻算法所耗费的建模时间最短,而支持向量机算法建模时间最长,正确分类例数及总正确率最多的算法为贝叶斯网络算法,标准误差最小的是贝叶斯网络算法,最大的是支持向量机算法,见表1。
2.2 贝叶斯网络算法
脾肾阳虚证正确分类例数最多、正确率最高,其次为肝郁气滞证和心脾两虚证,而肝肾阴虚证被误分为心肾不交证的例数较多,分类正确率也相对较低(见表2、表3),考虑可能脾肾阳虚证的特征值与其他证型区别较大,而肝肾阴虚证与心肾不交证的特征值存在相似之处,因此出现误分的情况。图1表明,该算法构建模型在样本数>180时分类趋于稳定,计算代价也处于较低水平,样本数<90时分类准确率偏低且计算代价较高,样本数>90时准确性大幅度提高且计算代价大幅度下降。
2.3 K最近邻算法
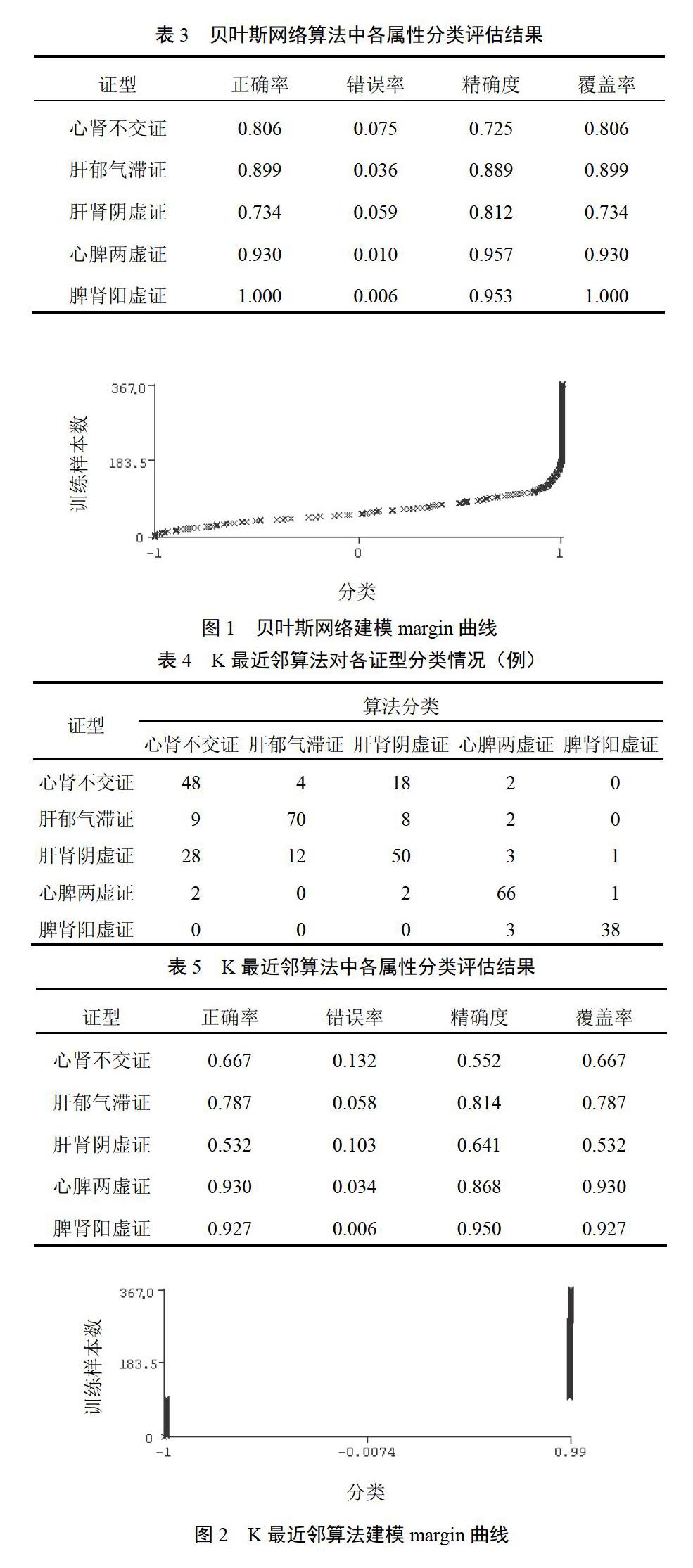
脾肾阳虚证正确分类例数最多、正确率最高,其次为心脾两虚证,而肝肾阴虚证被误分为心肾不交证的例数较多,分类正确率也相对较低(见表4、表5)。图2表明,该算法构建模型在样本数>104时分类趋于稳定,计算代价也处于较低水平,样本数<94时分类准确率偏低,而且计算代价较高。
2.4 支持向量机算法
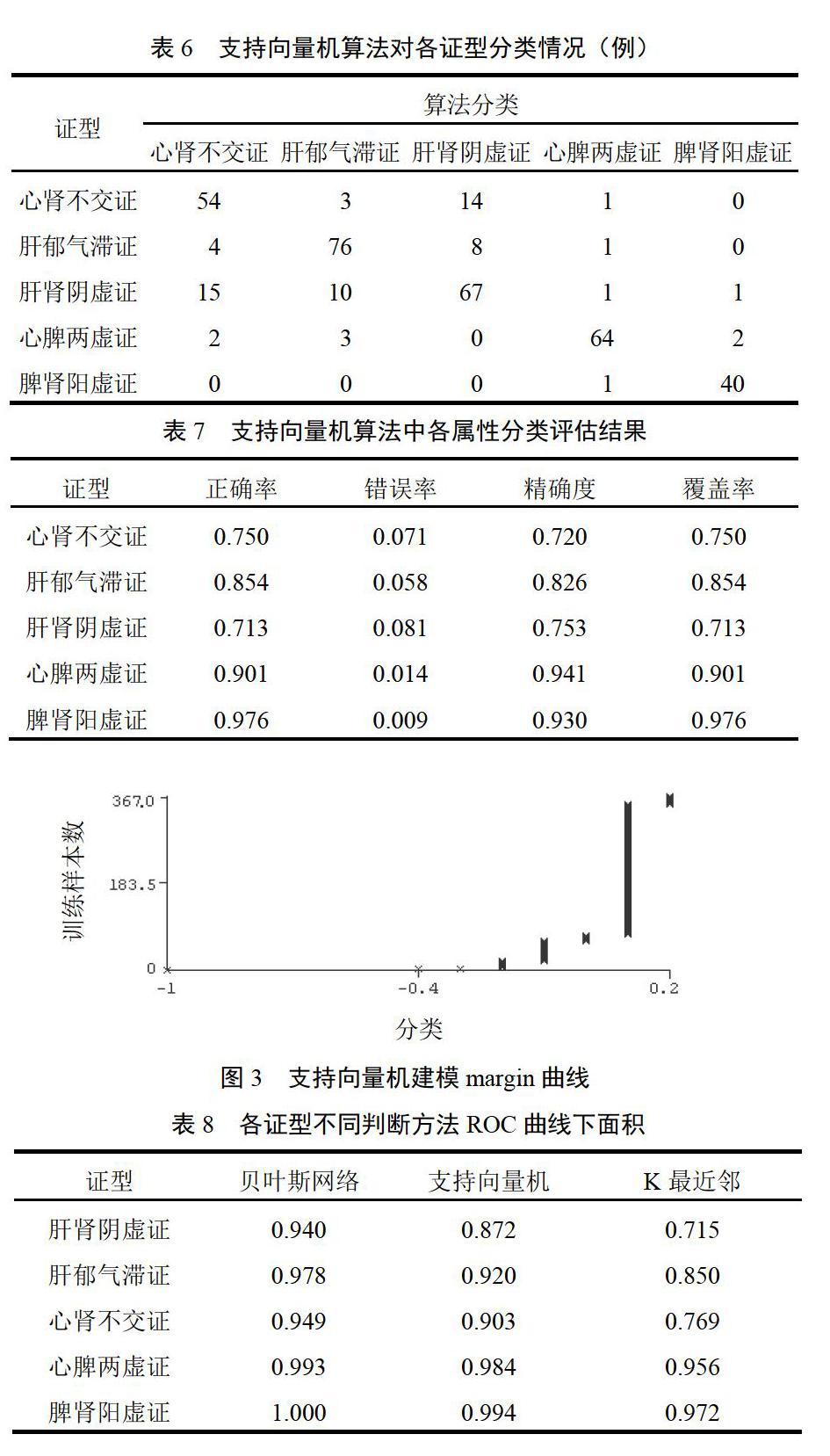
脾肾阳虚证正确分类例数最多、正确率最高,其次为心脾两虚证,肝肾阴虚证被误分为心肾不交证的例数较多、分类正确率较低(见表6、表7)。图3表明,该算法构建模型在样本数>80时分类趋于稳定,计算代价处于较低水平。该算法在小样本环境下表现出惊人的收敛速度,精确度迅速提高,计算代价大幅下降,但样本数据增加后其精度和计算代价都较差。
2.5 3种分类算法模型评估
ROC曲线常用于比较2组或多组实验结果,并判断实验结果合适分界点,常用于诊断模型的评估,比较各种分类方法所建立模型的优劣。分别采用贝叶斯网络、支持向量机、K最近邻算法,得出每个证型ROC曲线下面积,大致在0.7~1之间(见表8)。从面积诊断意义上来说,诊断价值较高。采用贝叶斯网络算法得出各证型ROC曲线面积最大,K最近邻算法得出各证型ROC曲线下面积最小。
3 讨论
基于数据挖掘技术进行的MPS中医证候分类研究在中医证候模型构建速度方面,K最近邻算法花费时间最短,支持向量机算法花费时间最长;在证候模型准确度方面,贝叶斯网络分类器所建立的证候模型准确率最高,K最近邻分类器所建立的证候模型准确率最低;在鲁棒性方面以支持向量机方法最佳,在极小的训练样本下表现了极高的分类稳定性,贝叶斯网络算法的鲁棒性最差,在训练样本不足时准确性难以提高。贝叶斯网络与其他所有的分类算法相比,其网络容易建立,没有结构学习过程,只需先验概率就可以完成,分类过程十分高效,具有最小的出错率[9-10]。因此,运用贝叶斯网络方法等数据库知识发现和数据挖掘技术,将数据挖掘结果结合专家经验和临床验证进行反复修订,是建立中医学辨证论治规范化研究方法学平台的重要手段[11]。支持向量机算法是模式识别中基于结构风险最小原理的数据分类方法,可将变量集映射到高维特征空间中并进行正确区分,其优点在于解决小样本、非线性及低维空间不易区分的难题。
实验表明,在对质量较高、样本量较大的数据集进行分类时,贝叶斯网络算法是最佳选择。而大多数情况下,能够获取的训练样本总是很有限,数据中包含空值,支持向量机算法常被选择应用。因此,综合本次研究结果,在应用数据挖掘软件进行数据分析時,应根据数据类型、特点,选用合适的分类算法,才能达到预期的效果。
参考文献:
[1] 丰有吉,沈铿.妇产科学[M].2版.北京:人民卫生出版社,2010:263.
[2] 曹泽毅.中华妇产科学[M].北京:人民卫生出版社,1999:2281.
[3] 乐杰.妇产科学[M].7版.北京:人民卫生出版社,2008:320.
[4] 中华人民共和国卫生部.中药新药临床研究指导原则:第三辑[M]. 1997:3.
[5] 张玉珍.中医妇科学[M].北京:中国中医药出版社,2002:168.
[6] 朱红红.亚健康状态的问卷评价方法与流行病学特征研究[D].上海:上海中医药大学,2010.
[7] 费兆馥.现代中医脉诊学[M].北京:人民卫生出版社,2003:163-165.
[8] WITTEN LH, FRANK E.数据挖掘实用机器学习技术(第二版)[M].董琳,邱泉,于晓峰,等,译.北京:机械工业出版社,2006.
[9] 罗敏霞.数据挖掘与知识发现的技术方法及应用(上)[J].运城学院学报,2005,23(2):1-5.
[10] 卢志茂,刘挺,郎君,等.神经网络和贝叶斯网络在汉语词义消歧上的应用对比[J].高技术通讯,2004,14(8):15-19.
[11] 胡金亮,李建生,余学庆.中医证候诊断标准研究背景与现状[J].河南中医学院学报,2005,20(3):77-79.
(收稿日期:2014-12-25)
(修回日期:2015-01-29;编辑:陈静)
