一种基于用户偏好和反馈的页面排序技术
2016-01-08廖辉传
一种基于用户偏好和反馈的页面排序技术*

廖辉传
(华东交通大学信息工程学院,江西 南昌 330013)
摘要:传统的排名方法没有考虑用户的喜好、反馈和用户兴趣,很难满足用户的个性化需求.针对这个问题,提出一种新的网页排名方法,将网页的相似度、链接结构信息、用户偏好及用户反馈相结合进行页面排名.实验结果表明,改进的排序算法在一定程度上帮助用户提高检索网页的质量,最大限度地满足用户的需求.
关键词:网页排名;搜索引擎;链接分析;用户偏好

万维网是一个巨大的、多样的和动态的信息来源.为了查找相关数据,用户必须使用各种搜索引擎寻找需要的资源.搜索引擎能够收集、分析、整理来自互联网的数据,并且为这些用户提供检索网络资源的界面.搜索引擎返回的结果集包含了与查询相关和不相关的各种网址信息,为了向用户提供相关的高质量信息,其根据查询的相关性和重要性,使用页面排名模块来对网页进行排名.
基于链接结构的网页排名是当今搜索引擎中的一个重要技术.最成功的2个Web信息检索方法是Google的PageRank和Kleinberg提出的HITS算法.它们都是基于链接结构的方法.链接结构是将网络作为一个有向图,其中网页形成图的节点,超链接为有向边,可以根据输入和输出链路的数目计算网页的整体排名.然而,不同的人有不同的需求和选择,一个统一的排名可能不满足所有用户的要求.在搜索结果集中,由于缺乏任何偏好、分类和细化,搜索引擎不能够提供精确的信息,因此用户还必须手动地对结果信息进行提炼.笔者提出一种新的网页排序算法,该算法结合Web内容挖掘、Web使用挖掘和结构挖掘,使得网页的排序结果更好地满足用户查询的要求.
1相关工作和背景
网页排名是搜索引擎使用的一种优化技术,根据重要性原则对成百上千的网页给出一个相关的排序.搜索引擎一般使用2种不同的排名因素:依赖查询因素(即词的频率、查询词的位置等)和独立查询因素(即链接率、点击率等).依赖查询因素包含了查询文本所有的排名因素.独立查询因素是与具体文档相关的,并不关心给定的查询文本如何.基于链接的排序算法在当前的搜索引擎中占主导地位.页面排序算法指出,如果一个网页具有一些重要的输入链接,那么它的输出链接也变得非常重要.在PageRank中,一个网页的等级评分(P)平均分配给其所有的输出链接.HITS(超链接引起的主题搜索)算法则将每个页面分为权威页面(Authority)和中枢(Hub)页面.表达某一主题的页面称为权威页面.将权威页面结合在一起就成为中枢页面.一般而言,好的中枢页面会指向很多好的权威页面,好的权威页面也会有许多中枢页面指向它.页面根据它们的中枢页面和权威页面的得分推送给用户.这2种方法的优缺点在文献[1-2]中都作了介绍.
目前主要的网页排序技术不足之处如下所述[3-4]:
(1)基于网页结构挖掘的网页排序算法与用户查询不太相关,因为它们不考虑网页内容和当前主题的用户趋势.
(2)基于网页内容的排序算法完全忽略页面的价值,它们完全依赖于传统的搜索引擎和元搜索引擎返回的结果集.
(3)仅根据链接关系而不考虑用户对网页的兴趣和偏好.
随着搜索引擎的普及,用户与搜索引擎的交互作用可以用来改进排名技术.个性化网页排名技术需要大量的计算和存储设备,因此,有必要设计一种新的页面排序技术,可以方便快捷地提供用户特定的和相关的信息,可以分析隐含的和明确的用户反馈.
2改进的网页排序算法
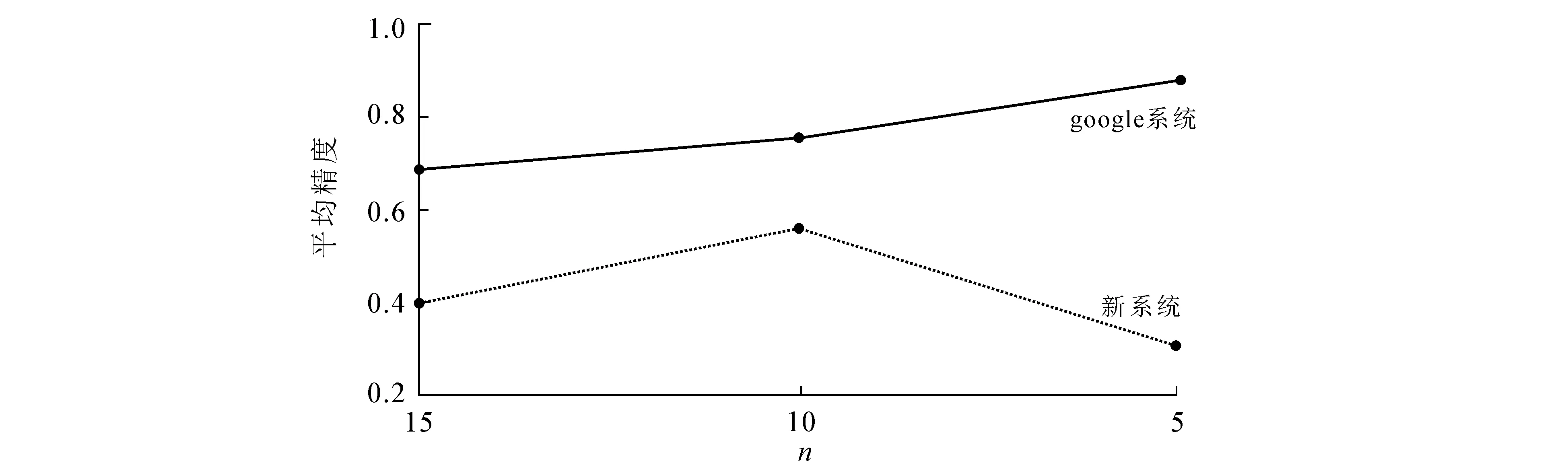
如上所述,目前网页排名算法中普遍存在不足,用户无法通过他们的搜索查询获得准确的结果.为了克服这些不足,提出了一种新的网页排名方法.这种方法将网页结构(网页的链接结构)、网络使用(基于域名和页面类型的网页过去的使用模式和用户偏好)和网页内容挖掘(查询词与页面内容的匹配关联度)组合在一起,目的是为用户提供最佳的需求与利益的结合.图1给出了该算法的体系结构.
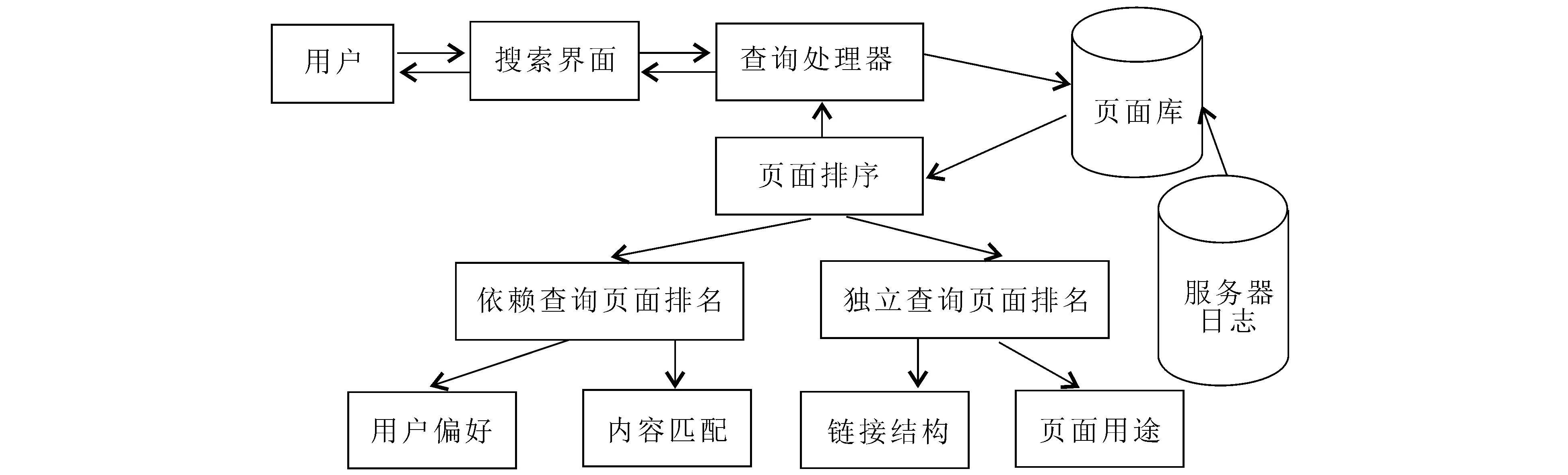
图1 改进的排序算法结构
关键词用户首先键入查询和选择自己感兴趣的网页域名或类型,这些细节由查询处理器完成.所有与用户查询匹配的页面从存储库转发到页面排序模块,并根据依赖查询(域名和内容简介)和独立查询(链接数量和用户行为)分配一个页面等级.排序好的页面通过查询处理器返回给用户.
算法的主要组成部分为:(1)查询界面模块.用于提供给用户输入查询信息和显示排序结果的界面.(2)存储库.用于存储库检索网页,包含4个检索项,分别为检索词、网址、域名信息和花费在出现检索词的网址上的平均时间.(3)服务器日志.它是用来存储一组用户在多个搜索会话中的花费在每个网页的平均时间.(4)查询处理器.用于接收用户的查询和域名偏好信息,然后,它从查询字符串中过滤掉一些不构成直接影响的单词,再进行来自查询字符串中的相关关键词的检索.(5)页面排序模块.
为了给从存储库中获得的网页进行排序,需要计算页面的排序分数,在这主要考虑如下4个权重值:
(1)页面的流行程度权重(PR).每一个网页的流行程度可通过其链接结构来衡量,将网络看作一个有向图,网页为图的节点,网页之间的超链接为图的有向边.设网页A有n个网页(T1,T2,…,Tn)指向它,Q(Ti)是一个从网页 A输出的网页数量,则页面A的流行度权重PR值为
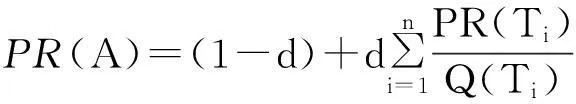
计算基于链接结构的页面排名算法如下:
(ⅰ)给每个页面的排名值初始化为1/n,其中n为参与排名的页面总数,即A=1/n(0 (ⅱ)取阻尼因子的值0 (ⅲ)重复每一个结点i(0≤i (ⅳ)更新A的值,A=PR(0≤i< n). 重复(ⅲ)直到排序值收敛. (2)页面的历史权重(PH_Score).网页的浏览历史是由一组用户在一个搜索会话中所花费的平均时间决定.此信息由服务器日志维护,每一个网页停留时间(平均花费时间)都与其他网址和域名信息一起存储在存储库中. (3)用户偏好权重(Dm).用户偏好权重基于网页句法分类或网页域名,即用户想要获取的页面类型或从什么域名获取.域名权重(Dm)被定义为一个单位函数: (4)文档内容权重(PC_Score).内容权重是根据页面字段中(如URL文本、Meta标记、Head标签、Body标签)有多少项和查询关键词匹配来决定的,不同类型的页面其计算方法是不同的.例如可用下式来计算HTML页面内容分数: PC_Score=0.2*URLT+ 0.2*TitleT+0.3*LinkT+0.3*BodyT. 关键词其中:URLT为出现在页面URL中的查询数目/URL文本中总的词汇数;TitleT为出现在页面Tile Tag中的查询关键词数目/Title Tag中总的词汇数;LinkT为出现在页面Link Tag中的查询关键词数目/Link Tag中总的词汇数;BodyT为出现在页面Body Tag中的查询关键词数目/Bodyr Tag中总的词汇数. 同样地,研究页面和广告页面也可分别由下式计算: PC_score=0.4*TitleT+0.6*BodyT, PC_score=0.5*no_of_images + 0.5*no_of_hyperlink. 关键词其中:TitleT为出现在标题中的的数目/标题中总的词汇数;BodyT为出现在pdf body中的查询词数目/pdf中总的词汇数;no_of_images为图片数;no_of_hyperlink为超链接数目. 最后,所有的权重值相加,共同组成排序总成绩(PageRankScore)的值.PageRankScore分数高的页面给定的等级也高,并提交给用户参考: PageRankScore = 0.2*PR + 0.2*PH_Score + 0.3*PC_Score +0.3*Dm. 3实验仿真 为了验证改进排序算法的可行性,设计以JAVA作为前端开发工具,MySQL作为后台数据库管理系统的实验环境.一个网页的流行度可以考虑用其链接结构计算出来的,整个页面被解析为提取页面的链接.所提取的链接,存储在适当的数据库表中. 当访问一个网页时,脚本从网络服务器端加载到客户端.脚本用来检查点击事件的发生.当一个点击事件发生时,一个消息被发送到具有当前网页和超链接信息的网络服务器.在服务器端,使用日志文件的数据库来存储网页上的ID、超链接和超链接的点击次数.每点击1次超链接,计数值每增加1次.数据库或日志文件将通过网络爬虫的网络抓取来访问.点击计数信息存储在搜索引擎的数据库中,并用于计算不同网页或文档的等级值.每个文档的相关信息存储在数据库的Doc_info表中(表1). 为判断用户偏好的域名,需要考虑表2中列出的网页特征. 关键词计算网页内容的得分需要用到和文档信息,关键词和文档信息存储在数据库的file_index表中(表3).当用户键入查询关键字时就会在file_index表中搜索. 文章编号:1007-2985(2015)06-0018-05 中图分类号:TP391.3文献标志码:A DOI:10.3969/j.cnki.jdxb.2015.06.005 收稿日期:*2015-09-29 作者简介:廖辉传(1973—),男,江西万载人,华东交通大学信息工程学院副教授,硕士,主要从事数据挖掘和人工智能研究. 表1 Doc_info表的表结构 表2 不同类型的网页及其特征 表3 file_index表 用户搜索界面操作很简洁,用户首先在文本框中键入查询字符串,并在下拉列表中选择域名类型和文件类型,然后就可开始查询. 为了检验网页排序模块的效果,做了用户模拟测试,对文中提出的网页排名方法(基于网页结构、页面内容和网页使用挖掘)和Google排名方法Page Rank(基于网页结构)进行对比.选定一些研究生作为测试者,不给他们有关这项研究目标的任何信息.该数据库包括在50个数据挖掘学科的网页中,选择总共12个查询来作研究.测试者开始在系统中键入查询字符串,选择指定的域名或网页类型的.提交查询后,测试者在屏幕上可以看到使用2种方法的排序结果.用户界面的设计操作简单,不容易评估错误. 4测试结果 当测试者面对2套结果集时,他们将在每套结果集中选择数量相等的URL,然后根据选定的网页和用户的查询需求是否相关及相关程度进行标记,主要分为“相关的”、“不相关”和“无关紧要”3种.分数1,0.5,0分别表示相关度高、相关度低和不相关的网页.可以使用下式计算每个搜索查询的精度: 精度=通过排序方法得到的相关网页分数总和/得到的页面总数. 表4,5列出的是前N个结果的精度,分别对应改进的新方法和Google Page Ranking方法. 表4 改进的页面排序方法的精度 表5 Google排序法的精度 图2绘制的是2种方法的平均精度(结果集合n=5,10,15).从图2可看出,使用推荐的新系统的效果更好,能够为用户提供更多的相关网页.这些初步的测试结果,虽然是基于少数用户的研究数据,但为人们提供一个思路,就是在基于用户偏好的基础上为用户提供高质量的搜索结果. 图2 2个排序系统的平均精度对比 5结语 许多互联网用户不懂如何使用查询语法语言从搜索引擎获得检索结果,他们必须执行多个查询,才能获得满足他们需要和兴趣的信息.而且,由于传统页面排序算法中普遍存在的弱点,一些重要的页面可能不会出现在相对较高的排名位置.笔者提出网页排名方法,不仅考虑了网页的链接结构和页面内容,还考虑用户的反馈和喜好.这种改进的新方法的优点是,用户可以在前几个网址得到需要的信息,而不必到搜索引擎返回的大量的搜索结果中去找寻.用户测试结果表明,改进的排序算法在一定程度上帮助用户提高检索网页的质量,最大限度地满足用户的需求. 参考文献: [1]任丽芸,杨武,唐蓉.搜索引擎网页排序算法研究综述.电脑与电信,2010(5):38-40. [2]王冲,曹姗姗.基于用户反馈与主题关联度的网页排序算法改进.计算机应用,2014,34(12):3 502-3 506. [3]TYAGI N,SHARMA S.Comparative Study of Various Page Ranking Algorithms in Web Structure Mining (WSM).International Journal of Innovative Technology and Exploring Engineering,2012,1(1):14-19. [4]KUMAR G,DUHAN N,SHARMA A K.Page Ranking Based on Number of Visits of Webpages//International Conference on Computer & Communication Technology(ICCCT).DC,USA:IEEE Computer Society Washington,2011:11-14. [5]DUBEY H B,ROY N.An Improved Page Rank Algorithm Based on Optimized Normalization Technique.International Journal of Computer Science and Information Techniques(IJCSIT),2011,2(5):2 183-2 188. New Page Ranking Algorithm Based on User Preference and Feedback LIAO Huichuan (School of Information Engineering,East China Jiaotong University,Nanchang 330013,China) Abstract:It is difficult to meet the individual requirements of users in the traditional ranking methods without considering the user preference,feedback and interest.In view of these problems,a new method of web page ranking is proposed based on web page similarity,link structure information,user preference and user feedback. Experimental results show that the improved ranking algorithm can improve the quality of web page retrieving and can meet the users’requirements greatly. Key words:page ranking;search engine;link-analysis;user preference (责任编辑向阳洁)