浅析Web元搜索引擎排序算法
2012-07-04桑秀芝
文/桑秀芝
(南京航空航天大学金城学院 江苏·南京)
一、序言
Internet上的信息量已呈爆炸性趋势增长,据研究报告显示,Internet上的网页目前已超过数百亿,如何从浩如烟海的信息中查找需要的信息成为人们最关心的事情。搜索引擎就是为了帮助人们解决这一问题而开发出的一种高效的信息检索工具,它已经成为Internet中最重要的部分。然而,目前还没有哪个独立的搜索引擎能够覆盖整个网络,而且由于所采用机制、算法与适用范围等的不同,导致同一搜索请求在不同搜索引擎中获得的查询结果的重复率不足34%,而每一个搜索引擎的查准率不到45%。因此,要想获得一个比较全面、准确的结果,需要同时使用具有不同数据搜索范围的搜索引擎,在多个检索结果列表之中挑选对自己有用的内容,这就增加了检索的不便。Web元搜索引擎的出现,在一定程度上解决了这些问题。Web元搜索引擎是集成多个搜索引擎的特殊搜索引擎。用户输入查询后,系统将查询词发送给成员搜索引擎,各成员搜索引擎开始检索。检索完毕后,系统将各部分结果集合在一起,整理后采用一定的排序方式返回给用户。将多个搜索引擎的查询结果集合在一起,这样可以扩大检索面,提高查询率。然而,面对如此海量的结果数据,系统本身就需要提供一套比较适用的排序算法,将用户最想要的结果尽可能地展现在前几页。因此,排序算法是影响元搜索引擎性能的关键技术之一。
二、Web元搜索引擎搜索流程
Web元搜索引擎(简称元搜索)通过一个统一用户界面帮助用户在多个搜索引擎中选择和利用合适的搜索引擎来实现检索操作,是对分布于网络的多种检索工具的全局控制机制。其搜索流程如图1所示。(图1)可以看出,首先用户通过一个统一界面输入查询词,任务分配器将检索词分配给合适的多个独立搜索引擎;各独立搜索引擎接收到查询词后,立即进行相关文件查询,并按照相关度高低顺序将结果文件排列,然后反馈到结果集成中心;结果集成中心接收到给定的各独立搜索引擎发回的结果文件序列后,就将按照一定的排序算法对所有结果文件汇总重新排序,最后输出一个结果文件序列给用户。这期间,针对不同的独立搜索引擎将用户的提问做不同转换,以适应相应索引数据库的调用;需要强调的是,元搜索是基于独立搜索引擎结果的二次加工,元搜索引擎的结果基于独立搜索引擎的查询结果,少数简单的直接调用原始的结果页面,但这都实现了对独立搜索引擎查询结果的二次加工,如重复结果的删除、结果的再度排序等。在定制结果输出形式的元搜索引擎中,检索结果一般都标明记录的来源搜索引擎及其相关度。
三、Web元搜索引擎排序机制
Web元搜索引擎排序是指对其调用的多个成员搜索引擎所返回的结果进行收集、去重处理,然后按照一定的准则排序,最终将排序结果按一定顺序展现给用户的过程。由于调用的成员搜索引擎可以各式各样,其收集的查询结果组成也形式多样,归纳起来其结果主要是由网址(URL)、网页标题、内容摘要、相关度等信息组成。因此,元搜索引擎排序可以在利用成员搜索引擎排序的基础上,从网页标题、内容摘要等方面着手考虑。总的来说,其排序方法可以从以下三方面来阐述:
1、引用排列。指直接采用搜索引擎提交的结果顺序,依次将不同来源的结果显示出来。这种方式无需进行结果去重而只需完成格式转换,因此显得简单易行,而且它有利于用户了解哪些搜索引擎对自己所需的信息不能提供或提供很少,以后再查询时可将它们从自己的引擎组合中删除。但这种方式也很有可能致使一个搜索引擎的不相关结果排在另一个搜索引擎相关结果之前,使用户错过重要信息。
2、重新排列。这种排序的方法比较单一,相当于把成员搜索引擎搜索的结果融合到一起再重新选择一种方法排序。这种方法仅仅提高了查全率,对于一些重要的信息,可能会排在比较靠后的位置而不易被用户检索到,准确率也不高。早期的元搜索引擎通常使用这种算法思想。基于此类算法思想的方法主要有直接合并、根据响应速度排序、摘要排序等。
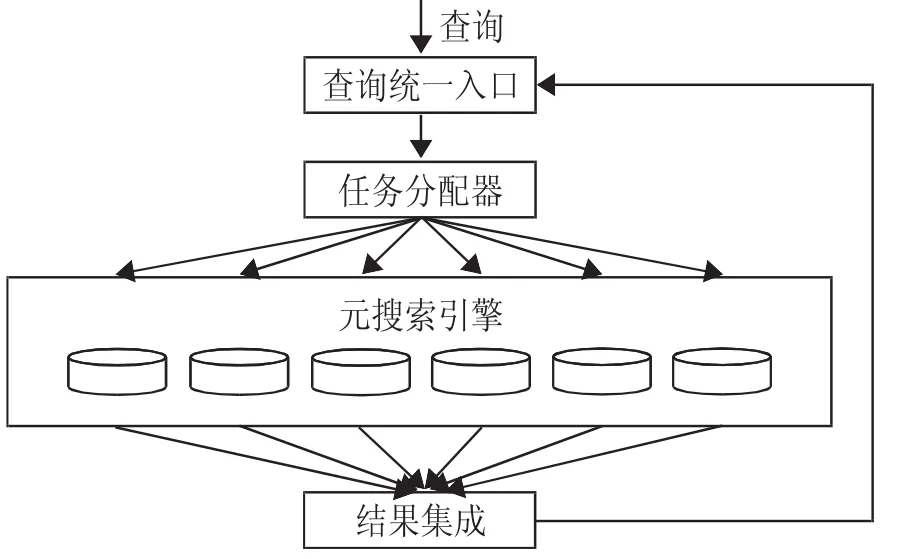
图1 Web元搜索引擎搜索流程图
3、利用搜索引擎排序信息排序。将各个成员搜索引擎所返回的结果集中在一起重新排序,这样就打乱了原来搜索引擎的排序信息,而这些信息也是非常重要的排序依据。尽管有些成员搜索引擎的排序方法未知,但是它肯定是按查询结果与查询词的相关程度大小排序的,只不过不同的搜索引擎所侧重的因素不同。若是能充分利用各成员搜索引擎的排序信息,在其基础上进一步地合成,则能够将查准率进一步提高。轮询法、星星排序、Borda排序、贝叶斯概率模型排序、位置排序等方法就是基于此基础上的。
4、相关分值融合。相关分值融合也是充分利用各个成员搜索引擎的排序信息。针对某个查询,各成员搜索引擎对自己搜索的所有结果均根据不同的情况分配一定的相关分值,对于同一结果在多个搜索引擎中出现的,将它们的相关分值进行融合后再排序。相关分值融合的方法有很多种,其中以Comb融合法(六种)、SDM融合法、MEM融合法、CORINET排序等最为常见。
四、Web元搜索引擎排序算法改进建议
鉴于目前元搜索引擎开发技术不同,且内部算法也存在重大差异,很难用统一的标准要求和衡量搜索结果的优劣。但对于元搜索引擎排序算法方面,其改进的方法主要体现在以下几方面:
1、直接将两种或者两种以上的基础算法进行综合,这是比较常见的改进方法。摘要/位置排序法就是将摘要排序法和位置排序法综合在一起的。元搜索引擎Ixquick、Metor等的结果排序方式都是基于相关度与星星评价指标相结合排序算法。
2、根据加权平均(简称WM)算法的原理,针对成员搜索引擎性能的不同分配一定权重,权重值与所引用的搜索引擎名称、个数有关,这样能够突出成员搜索引擎之间的差异。加权轮询法、加权规范分法、加权Comb排序等均是在基础算法的基础上为搜索引擎分配权值得到的。
3、依据信息集结算子的原理,首先确定所有成员搜索引擎搜索结果的文件序列;然后确定最终显示的文件名称和总个数,系统会按照确定的文件名称和文件数统计各文件在每个序列位置出现的次数;接着系统按从大到小顺序排列每个文件在序列中出现的次数;最后根据搜索引擎的个数和信息集结程度,运用信息集结算子计算每个位置的权重,权重和排序后(降序)的文件在序列中出现的次数相乘,得到最终集结结果,系统把每个文件最终的集结结果按从大到小顺序排列,该顺序即为元搜索引擎关于每个文件最终的顺序。针对成员搜索引擎检索的每个文件在序列中每个位置出现次数如何确定权重,目前国内外相关成熟的算法也比较多,如加权有序平均(OWA)算子、模糊语言量词、尤其是规范单调递增(RIM)量词。
4、综合2和3算法的原理,首先赋予每个元搜索引擎一定的权重,然后再对最终结果文件序列每个位置赋予一定的权重,当然这两个权重值和算法各不相同。然后利用集结算子原理,计算每个文件在所有元搜索引擎中的最终集结值;再把检索结果文件按集结值降序排列,该顺序即为元搜索引擎关于每个文件最终的顺序。针对这两种权重的确定方法,目前国内外相关成熟的算法还不是很多,比较成功的算法有加权有序、加权平均(简称WOWA)算子。
此外,虽然目前排序算法众多,但随着新的搜索引擎的出现、搜索技术的改进及外界环境的变化,笔者认为还需要定期对元搜索引擎排序结果进行测评,主要指标包括查全率和查准率。对于查全率,由于元搜索引擎作为一种特殊的搜索引擎,对于一个固定的查询,它的结果来自于成员搜索引擎。因此,整体查全率是由成员搜索引擎所确定的;而对于查准率,搜索引擎本身提供的排序算法就是将相关度较大的结果尽可能排在前面,即提高查准率,它是衡量元搜索引擎性能的一个重要尺度。因此,要想使用户在最短的时间内检索到最需要的文件信息,必须不断优化元搜索引擎技术和元搜索引擎排序算法。
五、元搜索引擎排序算法展望
目前,搜索引擎技术逐渐趋于成熟阶段,尤其是在查全率和查准率方面都有了较大的改进,时效性也有较大的改善。而元搜索引擎在国内尚处于起步阶段,但其还是具有自己独特的生存优势的,因为它集合了多个搜索引擎,具有较高的查全率,这些都是其他搜索引擎不能具备的。但由于不同的搜索引擎在收集信息的数量、范围、排序方法等方面有较大的差异,再加上搜索引擎技术的隐蔽性,设计者很难获取它们的技术细节。对于元搜索引擎来说,无论采取哪种排序方式,总不尽如人意。实际上,对某元搜索引擎来说(排序方法已定),不同的查询,它的查准率和查全率也有不同;对于同一个查询,不同的排序方式也会引起很大的差别,导致这种问题的主要是信息重叠率的不同。Wu Sheng-li和McClean经过研究表明,当信息重叠率不同时,各种排序算法差异显著。所以,要想从排序算法上提高元搜索引擎的查准率和查全率,除了对基础算法进行改进外,还要根据不同的查询选择不同的算法。专业搜索引擎的出现对元搜索引擎来说可以是一个借鉴,即将专业搜索引擎综合实现专业元搜索引擎;或者将元搜索引擎更进一步的智能化。针对用户输入的查询串自动地进行分类,然后根据类别选择最佳的排序方法。当然,对于某个固定的元搜索引擎,还可以通过科学的统计方法来检测成员搜索引擎的技术细节,尽管检测出来的技术细节不是很精确,但却能够在一定程度上反映出该成员搜索引擎的技术情况。综合这些技术给出一个统一排序方法对所有结果进行重新排序,这样势必能够提高用户的满意度。
[1]彭喜化,张林.基于agent的元搜索引擎结果优化技术 [J].计算机应用,2003.12.
[2]文坤梅,卢正鼎,邓曦等.元搜索引擎中检索结果排序的优化方法[J].华中科技大学学报,2003.3.
[3]徐宝文,张卫丰.搜索引擎与信息获取[M].北京:清华大学出版社,2002.
[4]张强弓,喻国宝,廖湖声等.一种元搜索引擎的查询结果处理模型[J].华南理工大学学报(自然科学版),2004.32.Z1.
