大数据研究的知识图谱分析*
2015-12-31詹川
詹 川
目前人类社会已进入大数据时代。“大数据”这一术语最早可追溯到Apache org的开源项目Nutch,当时大数据用来描述为实现网络搜索索引更新,同时进行批量处理或分析的大量数据集。随着谷歌MapReduce、Google File System(GFS)的发布,大数据不仅用来描述大量的数据,还涵盖处理数据的速度。业界用Volume(大量)、Velocity(高速)、Variety(多样)、Value(价值)来描述大数据的特征。大数据引起政府、企业界和学术界的极大关注。2012年3月奥巴马宣布美国启动“大数据研究和发展计划”。中国工程院院士、中国互联网协会理事长邬贺铨在第十届国家信息化专家论坛上建议尽早启动大数据国家战略。国际上Google、Facebook、IBM、EMC等IT企业部署大数据领域,国内的百度、阿里巴巴、腾讯等IT巨头积极跟进。在学术界,Nature 在2008年推出大数据专刊,Science 在2011年2月推出Dealing with Data专刊,现在大数据成为国际学术界研究热点。本文旨在分析全球大数据理论研究现状,提供大数据研究图谱,分析大数据主要研究领域和研究热点。
1 数据获取及描述
笔者选用WoS数据库,即SCI索引的Web版本。SCI是公认的世界上最权威的科学技术文献索引工具,收录了科技领域最重要、最新的研究成果。SCI引文检索体系在全球独一无二,不仅可从文献引证角度评估文章的学术价值,还可迅速方便地组建研究课题的参考文献网络。因此,选用WoS作为检索大数据研究成果的数据源,能确保所获数据的全面性和权威性。
检索设置条件见表1。由于难以确认大数据研究的正式起源时间,因此检索时段的设置没有时间限制,以便能从文献数量角度观察大数据研究规律。文件类型选择会议论文(Proceedings Paper)、期刊文章(Article)和评论(Review),前两种是发表学术研究成果的最主要方式;“Review”类型的文章虽然数量不多,共49篇,但被大量引用,对大数据研究有较大影响。检索时间是2014年8月20日,获得主题为“big data”的文献1311篇。

表1 检索设置
2 研究方法
采用文献计量和科学知识图谱相结合的方式对大数据研究文献进行分析。选择的知识图谱分析软件是CiteSpace[1]。
3 大数据研究基础分析
3.1 文献时间分布
主题为“big data”的1311篇中,最早的文献出现在1999年,有1篇;2000年没有。2001-2008年,每年论文数量为几篇,属于大数据研究萌芽阶段。2008年Nature 出版专刊Big data,讨论互联网技术、网络经济学、超级计算、环境科学、生物医学等多方面大数据带来的挑战,对大数据研究影响深远。2009-2011年,大数据研究处于早期发展阶段,每年发表数量保持在10来篇左右。2011年Science 推出Dealing with data 专刊,讨论数据洪流带来的问题,推动大数据研究快速发展。2012年大数据的技术优势被广泛认可,越来越多的互联网企业应用大数据技术来构建平台的数据处理架构,大数据论文数量飙升到196篇。2013年大数据得到进一步普及,很多国家把大数据产业上升到战略高度,关于大数据的研究文献上升到755篇,占总数的57.79%。从文献数量看,2012年至今,大数据文献迅速增加,形成研究热潮。
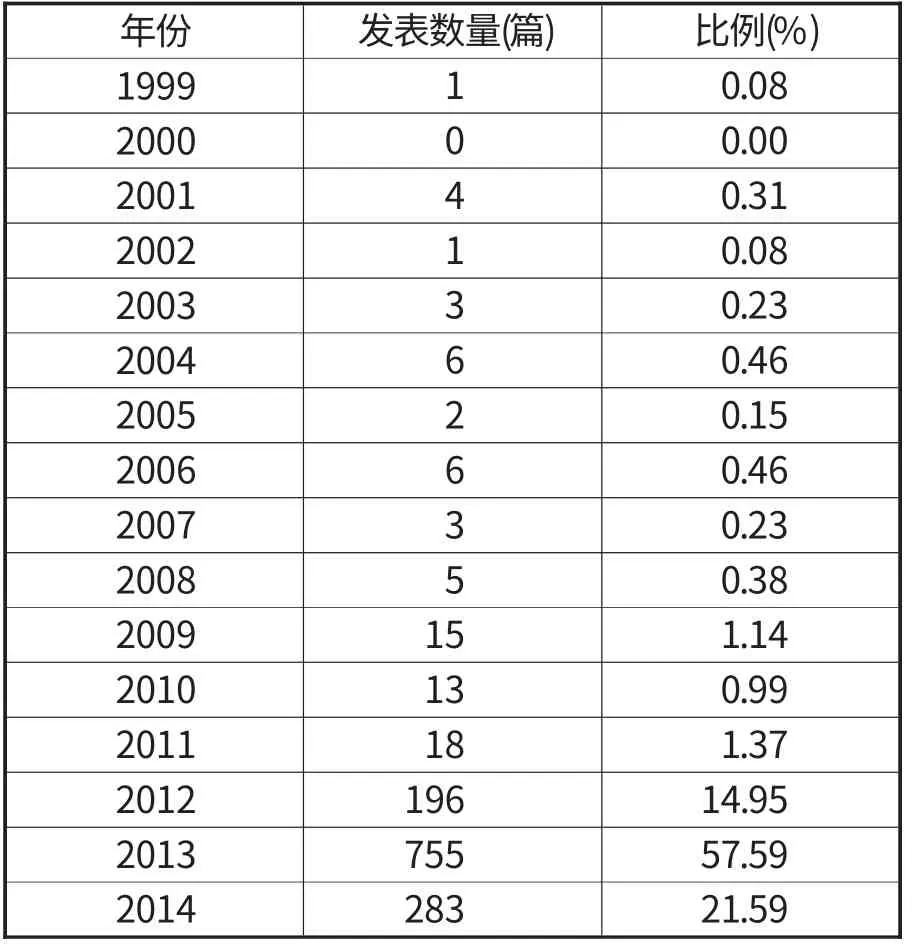
表2 大数据研究文献时间分布统计
3.2 主要发文期刊或会议
大数据论文数量排在前十位的期刊或会议见表3,其中8个是国际会议,说明专题会议是发表大数据研究成果的主要途径。排名第一和第五的是IEEE的大数据专题会议,刊发大量的大数据论文,特别是排在第一位的2013 IEEE International Conference on Big Data刊文111篇,占总数的8.47%。医学健康领域专题会议,如第三和第四位关于E-健康的国际会议,以及第八位医学领域专业期刊PLOS ONE,发表的大数据论文也较多,说明医学健康领域对大数据的应用研究很重视。第十位是唯一一个计算机类期刊,共发表14篇,占总数的1.07%。
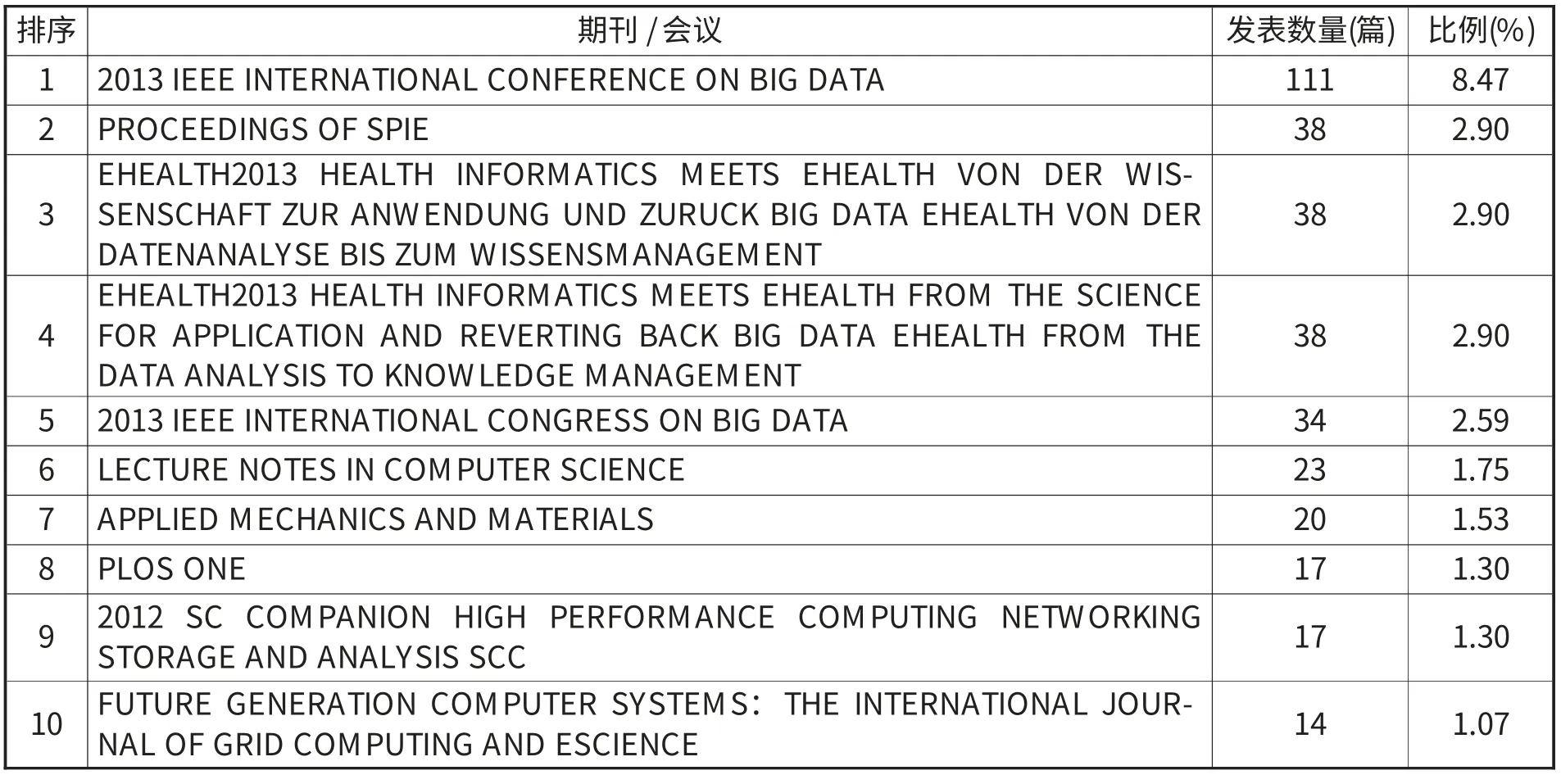
表3 刊发大数据文献数量排前十的期刊/会议
3.3 主要发文国家
发表论文数量排名前十的国家见表4。美国共发表489篇,占37.30%,表明美国在大数据研究上占主导地位。中国共发表241篇,说明中国在大数据研究方面成果较丰硕。从地理分布看,大数据研究主要集中在北美、东亚和欧洲。
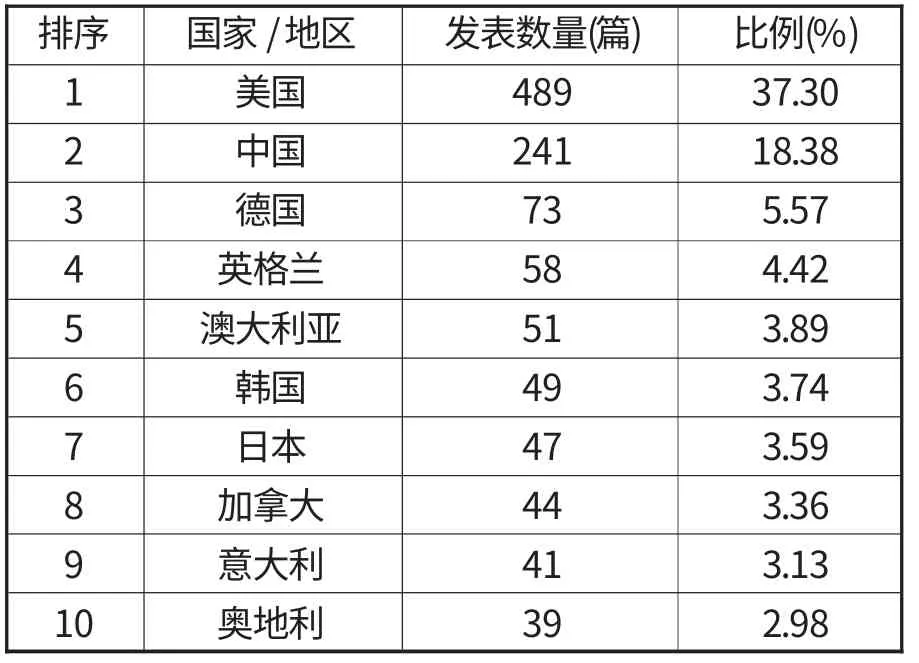
表4 论文发表数量前十的国家和地区
3.4 主要发文机构
论文发表数量排在前十位的机构见表5。中国科学院排第一,共发表30篇,占总数的2.29%,是前十中唯一的科研院所,其余都是大学。排名前十的机构从所属国家看,美国最多,有七家美国知名大学;然后是中国,有两家,分别是中国科学院和清华大学。
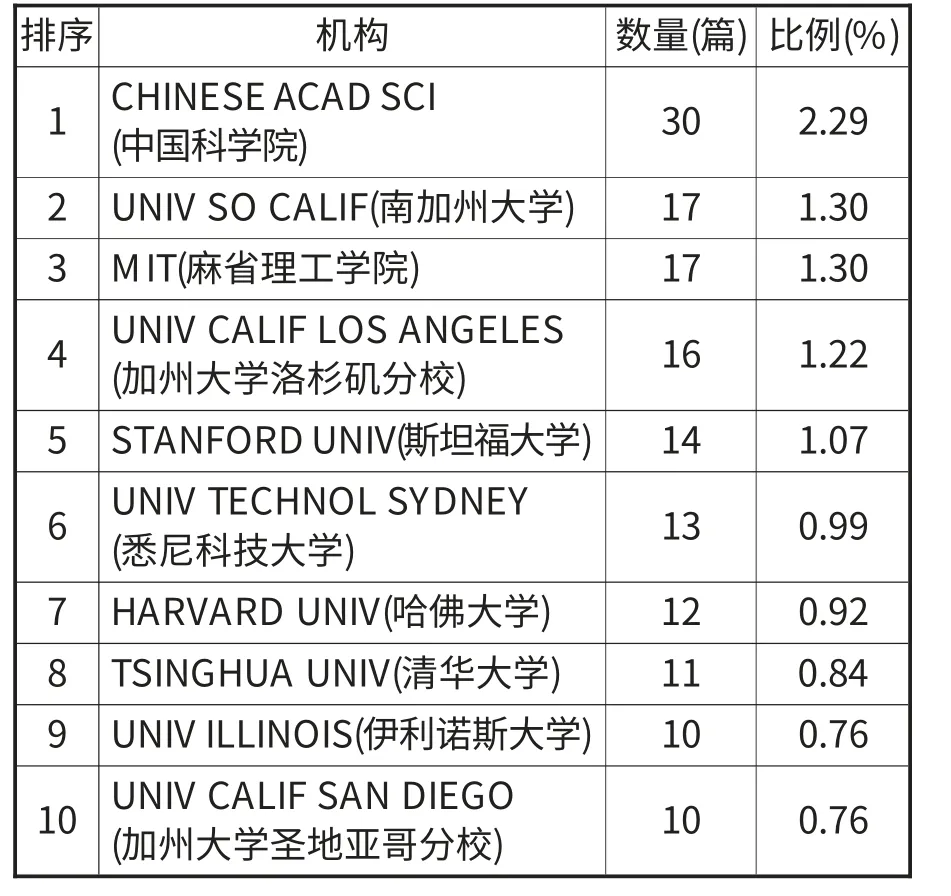
表5 论文发表数量前十的机构
4 大数据研究的可视化分析
4.1 大数据研究的知识基础与研究前沿
普赖斯最早提出“研究前沿”的概念,用来描述研究领域的动态本质。他认为某个领域的研究前沿由科学家积极引用的文章所体现。2009年陈超美把研究前沿定义为一组突现的动态概念和潜在的研究问题,而研究前沿的知识基础则是它在科学文献中的引文和共引轨迹[2],即由引用研究前沿术语的科学文献所形成的演化网络。
为进一步研究大数据研究的前沿领域,笔者把从WoS获得1311篇文献作为数据源导入CiteSpace,参数“Time Slicing”设置为1999-2014,“Per Slice”为1,“Node Types”选择Cited Reference,进行共被引文献分析。文献需经过聚类处理,聚类效果的好坏可从Modularity Q和Mean Silhouette的大小来衡量。Modularity Q值越大,越接近1,表示类群之间的耦合越小,划分清晰;Mean Silhouette值越大,越接近1,说明类群内部节点之间的同质性越高。经过多次测试,当“Top Nper slice”方式数量设为50,剪枝方式“Pruning”同时复选“Pathfinder”和“Pruning the merged network”两种方式时,得到的聚类具有较高Modularity Q和Mean Sil houette值,分别为0.9542和0.8068。这两个值都相当高,说明在此参数设置下,聚类效果俱佳。最终形成合并的共被引文献网络图共有538个节点,1705个连线,聚类后得到68个聚类群。采用“keyw ord”+“tf*idf”方式获取聚类标识,共标识出35个类,其中4个标识语为空,具体每个类标识见表6。表6从大到小列出每个聚类标号、拥有的节点数量及对应标识特征词,这些特征词代表大数据研究前沿领域。进一步对共被引文献网络图进行“Citation Burst”处理,然后转换成“Timeline View”得到图1,更加直观地显示各个类的研究历史和相互引用关系。共被引文献网络图中引用文献节点间相互引用关系构成大数据的知识基础。表7列出排名前十的高被引文献,它们是大数据研究知识基础的重要代表,对大数据研究影响深远。

表6 大数据主要研究前沿领域
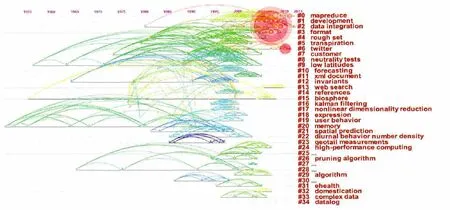
图1 大数据研究前沿聚类图

表7 排名前十的高被引文献
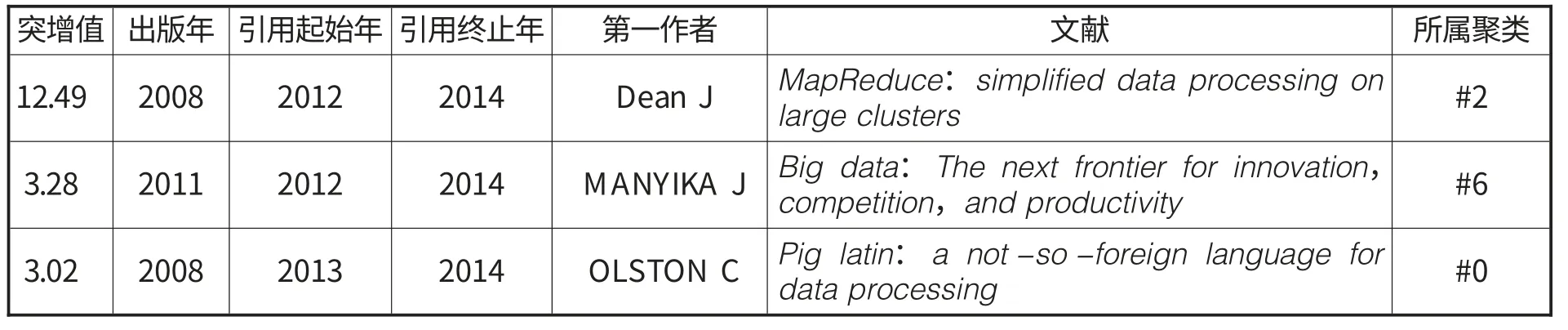
表8 引用次数突增的文献
共被引文献网络中的突增节点预示着该领域的研究热点。经过突变处理,那些被引用次数出现突然增长的文献节点以红色圆圈标示出,图1中共有3个突变节点,如表8所示。第一突增节点是Google公司的Dean J在2008年发表的关于MapReduce算法的论文。该文献突现值高达12.49,同时也是被引用次数最多的文献,高达124次,表明该论文在大数据研究中至关重要。现在MapReduce已成为开源大数据架构Hadoop的核心算法,广泛应用于大型互联网平台中,该节点归属于#2data integration类。第二个突增节点是2011年麦肯锡咨询公司Manyika J等人发布的一份关于大数据的详尽报告,对大数据的影响、关键技术和应用领域进行了详尽分析,帮助人们全面认识大数据,对指引大数据的研究发展起到积极作用,该节点属于#6twitter。第三个是Yahoo公司的Olston C等人针对大数据分析设计的高级程序语言Pig Latin,通过Pig编译平台产生Map Reduce程序,它比使用Map Reduce直接编写更加容易、灵活,更便于维护和重用,因此在大数据分析中得到广泛应用,Pig现是Hadoop项目的一部分,属于#0MapReduce。Data Integration和Twitter这两个方向从2012年到现在一直是大数据研究热点,而表8中Dean J一文的突增值特别高,说明Data Integration方向在大数据研究中受到格外重视,是当前最大研究热点。Map Reduce方向的突增发生在2013-2014年,是最近大数据研究关注的热点。
4.2 共被引作者分析
对1311篇文献继续进行共被引作者分析,参数“Time Slicing”设置为1999-2014,“Per Slice”为1,“Node Types”选择Cited Author,“Top N per slice”数量设为50,剪枝方式“Pruning”同时复选Pathfinder和Pruning the merged network两种,得到一个494个节点,1590条连线的合并网络,选择只显示大于30次的节点标示,结果如图2所示。表9列出被引次数排名前十的作者及具体次数。结合图2与表9的分析,排名第一的作者是Dean J,被引次数高达184次,远远超过其他作者,几乎是第二名的3倍。Dean J正是Map Reduce:simplified data processing on large clusters 一文的作者,该文献在大数据研究中被引次数最高,达124次,对大数据发展影响深远。White T是排名第二的作者,他在2009年出版的Hadoop the definitive guide 是Hadoop的权威指南,是学习和了解大数据架构Hadoop的重要书籍,该书在高被引文献排名中位居第二,被引56次。其余高被引作者的被引次数大致在50至30次左右,变化不大,其中MANYIKA J和OLSTONC发表的论文同时进入高被引文献排名的前十位。
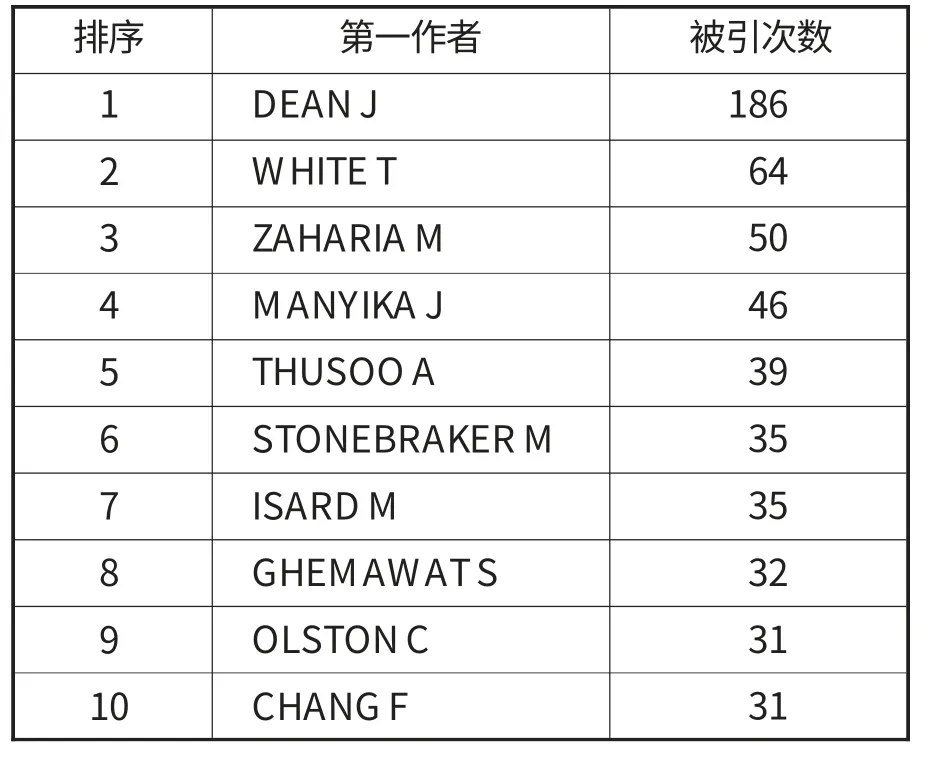
表9 被引次数前十的作者
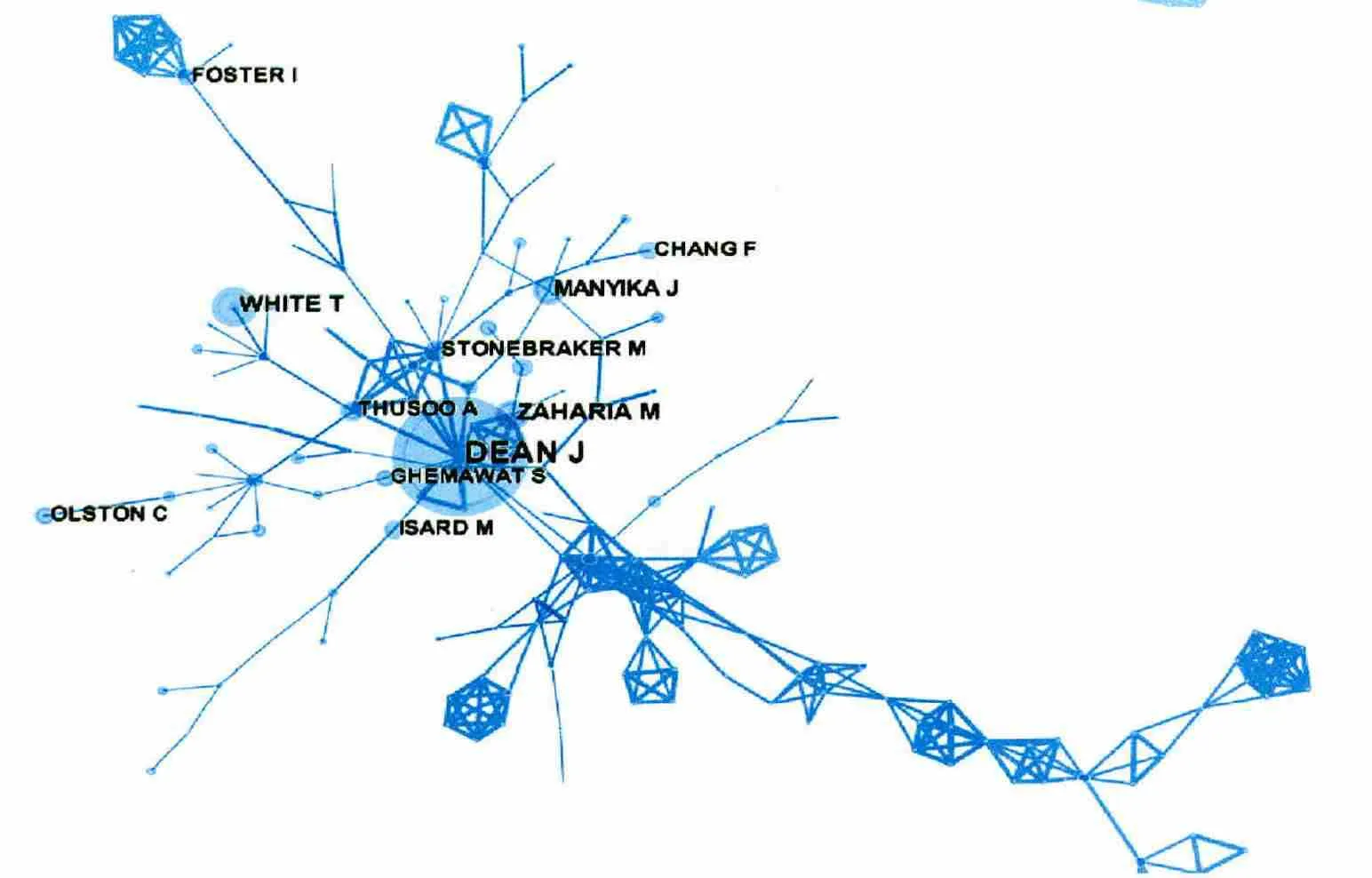
图2 共被引作者分析
4.3 共被引期刊分析
采用类似参数对1311篇文献进行共被引期刊分析,得到一个423个节点、1632条连线的网络合并图,选择只显示大于65次的节点标示,得出图3。表10列出排名前十的期刊和会议。Communications of the ACM 是美国计算机协会的旗舰刊物,刊载计算机领域的重要研究和创新,对计算机发展影响重大;在排名前十的高被引文献中,有两篇出自该期刊。Lecture notes in computer science 是Springer集团出版的计算机领域的专业期刊。两种期刊的被引次数较接近,分别为244次和229次,它们都是计算机领域的期刊。排在前十且属于计算机领域的还有第六名的IEEE Transaction on knowledge and data engineering,是IEEE旗下知识及数据工程类的学报,被引次数93;第9名Journal of Machine Learning Research 被引次数为69次。从图3可见,计算机领域四个期刊聚集在图的左上方。排在第三至五名的分别是Nature、Science 期刊和Proceedings of the national academy of sciences of the united states of America会议,被引次数依次是167、161和113。Nature 和Science 是世界顶级期刊,一般刊载全球最前沿的科学研究,最重大的理论发现,属于综合类期刊。第七、八和十名期刊属于生物信息领域,被引次数分别为87、87、69,聚集在图3的中心周围,说明大数据技术在生物信息领域也得到广泛应用。
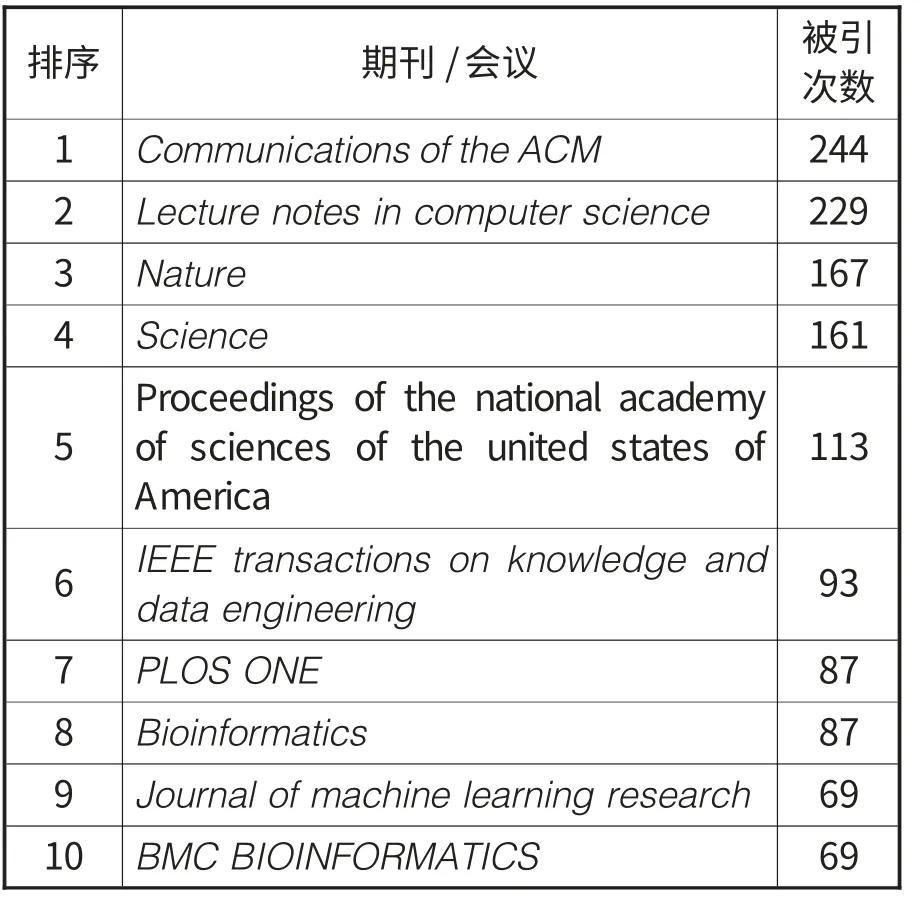
表10 被引次数前十的期刊/会议
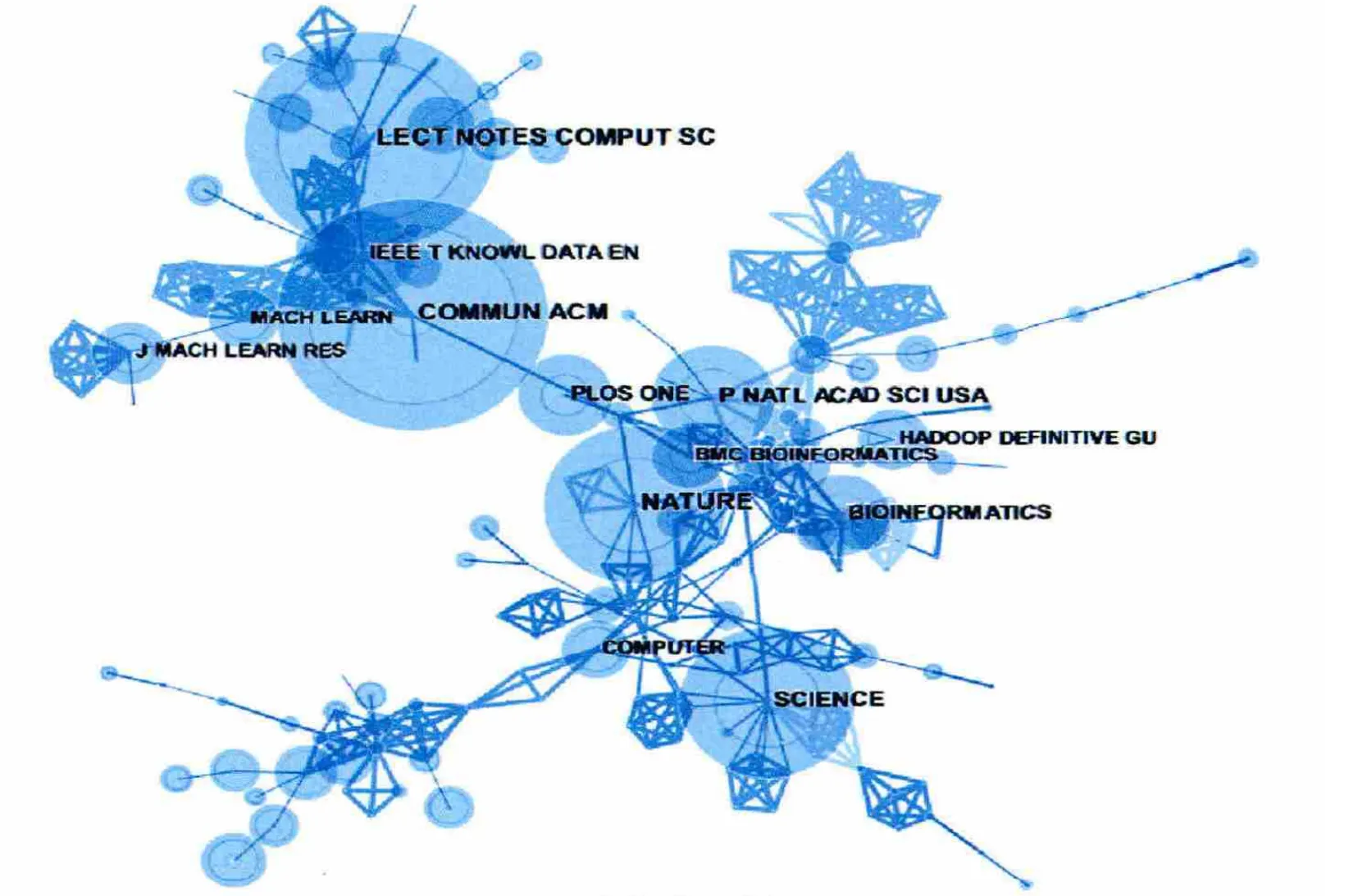
图3 共被引期刊分析
5 结论
(1)从WoS数据库收录的相关大数据论文数量看,大数据研究最早可追溯到1999年。1999-2008年,每年与大数据相关的论文都在几篇左右,处于零星研究状态。2008年Nature 和Communications of the ACM 刊发的大数据论文对大数据研究发展影响深远。2009-2011年,从数量看大数据研究进入新的阶段,每年发表的论文在15篇左右,说明大数据逐渐被关注。2012年论文数量快速增长到196篇,2013年更升至755篇,大数据研究进入快速成长期,大量专家学者投入大数据研究中,大数据受到空前的重视。
(2)从发表大数据论文数量最多的十个期刊或会议看,有八个是国际会议,说明专题会议成为发布大数据最新成果的主要途径,其中IEEE的大数据专题会议,发表论文111篇,排名第一。另外,医学健康方面的会议和期刊也大量登载关于大数据研究的论文。而从文献被引用次数来看,排在前十的主要是期刊,其中对大数据研究影响最大的是Communications of the ACM。从被引用次数最多的前十种期刊或会议的类型来看,主要是三类期刊:计算机类、综合类和生物信息类。综合刊发大数据论文数量和被引用次数排名前十的期刊或会议的统计数据,大数据研究主要集中在计算机、生物信息、医学健康领域。
(3)从发文国家看,美国排第一,中国排第二。从发文机构看,前十所机构中有七家是美国大学,两家是中国科研和教学机构。说明美国对大数据研究的重视,以及在此领域的领导地位,而中国也紧跟其后,走在世界前列。
(4)通过可视化分析,大数据的研究前沿共有34个方向,当前的研究热点是MapReduce、Data Integration和Twitter。
(5)2008年Dean J在Communications of the ACM 发表的Map Reduce:simplified data processing on large clusters 对大数据研究影响深远,此文及其作者、所在期刊都是被引用次数最多的,说明该文献对大数据研究影响重大,文中提出的MapReduce理论模型已成为被广泛应用,成为开源大数据架构Hadoop的核心技术。
[1] Chen C.CiteSpace II:Detecting and visualizing emerging trends and transient patterns in scientif ic literature[J].Journal of the American Society for Inf ormation Science and Technology,2006,57(3):359-377.
[2] Chen C,SanJuan FI,Hou JH.The structure and dynamics of co-citation clusters:Amultiple-perspective co-citationanalysis[J].Journal of the American Society for Information Science and Technology,2010,61(7):1386-1409.
[3] Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[4] White T.Hadoop the def initive guide[M].Sebastopol:O’Reilly Media,2009.
[5] Manyika J,Chui M,Brown B,et al.Big data:The next f rontier f or innovation,competition,and productivity[R].[S.I]:McKinsey Global Institute,2011.
[6] Howe D,Costanzo M,Fey P,et al.Big data:The future of biocuration[J].Nature,2008,455(7209):47-50.
[7] Schadt EE,Linderman MD,Sorenson J,et al.Computational solutions to large-scale data management and analysis[J].Nature Reviews Genetics,2010,11:647-657.
[8] Lynch C.Big data:Howdo your data grow[J].Nature,2008,455(7209):28-29.
[9] Ekanayake J,Fox G.High Performance Parallel Computing with Clouds and Cloud Technologies[J].Lecture Notes of the Institute f or Computer Sciences, Social-Informatics and Telecommunications Engineering,2010,34:20-38.
[10]Dean J,Ghemawat S.MapReduce:aflexible dataprocessing tool[J].Communicationsof the ACM,2010,53(1):72-77.
[11]Hey T,Tansley S,Tolle K.The Fourth Paradigm:Data-Intensive Scientific Discovery[R].[S.I]:Microsoft Research,2009.
[12]Olston C,Reed B,Srivastava U,et al.Pig latin:a not-so-foreign language for data processing[C].SIGMOD'08 Proceedings of the 2008 ACMSIGMODinternational conf erence on Management of data.[S.I]:[s.n.],2008:1099-1110.
