基于微观数据的居民多维福利指数空间分析
2015-12-30刘泽琴副教授北华航天工业学院经济管理系河北廊坊065099
■ 刘泽琴 副教授(北华航天工业学院经济管理系 河北廊坊 065099)
引言
虽则古今中外的研究者采用了不同的表述方式,但是总的来说,人们对“福利”这一概念的关注和研究由来已久。西方学者对这个概念的理解,由于立足于各自不同的具体领域,因而也往往带有鲜明的个人特色。阿玛蒂亚·森(Sen,A.)在批判以往研究成果的基础上,从全新的视角审视福利问题,主张将基本价值判断引入福利分析。森认为,福利的实质是可行能力的扩展,它涉及到一些实质性的自由,比如免受饥饿、营养不良、可避免的疾病、过早死亡等困苦的折磨,以及能够识字算数、享受政治参与等自由。由此可见,森对福利的阐释更偏重于客观方面,但因为涉及到“自由”这一具有一定主观性的范畴,也考虑到了居民感受的重要性。本文的研究正是基于森的这样一种福利视角的,有鉴于此,本文将福利理解为“人们可以获得并享受某些货物或服务并藉此处于某种幸福状态的自由”,当然,这种自由是可以且必须以某种具体的形式予以量化测度的。
对于福利的绝对数指标的测度相对而言较为简单,而相对数指标的测度则略显复杂。一方面在于指标的多样性,另一方面在于指标加工方法的多样性,该领域的研究多见于对收入分布公平性的研究。其中广泛使用的简单统计指标有以下几个:基尼系数(Gini coefficient),即洛伦茨曲线与绝对平均线之间所围图形面积的大小,它取决于洛伦茨曲线的形态和弯曲程度,具体的计算方法有直接计算法、等分法、不等分法、曲线拟合法等几种;对数离差均值(mean log deviation),对收入分布的每个等分组的平均收入水平分别取自然对数,然后求这些对数值的均值;变异系数平方(squared coefficient of variance),对收入分布的每个等分组的平均收入水平求方差,然后除以总体平均收入水平的平方;十等分位点比率P90/P10(P90/P10 inter-decile ratio),第九等分组的上界值与第一等分组的上界值之比;十等分位点比率P50/P10(P50/P10 interdecile ratio),收入中位数与第一等分组的上界值之比。根据定义不难发现,这几个指标的取值范围有所不同,基尼系数的取值在0和1之间;对数离差均值和十等分位点比率两类指标的下限值为1,无上限;而变异系数平方指标的下限值为0,上限为无穷。
较为复杂的测度方法有:一般化熵指数(generalized entropy measures),是将信息理论中表示平均信息量的“熵”的概念移植到分析收入分布的领域中来,把各个群体之间的收入差距视为将人口份额转化为收入份额的消息所包含的期望信息量,根据这一理解,可以写出以下形式的一般定义式:
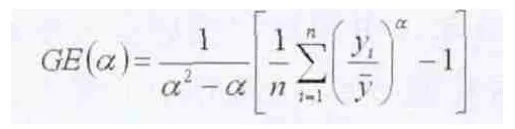
式中,n表示样本容量,yi表示个体i的收入,参数α表示收入分布各个组别之间收入差距的权数,常用取值为0、1。这类方法中较具代表性的有泰尔指数(Theil index,取α=1)和对数平均偏差指数(Mean Logarithmic Deviation,MLD,取α=0);阿特金森指数(Atkinsonindex),首先计算出等价敏感平均收入yε,然后据此计算阿特金森指数Aε。
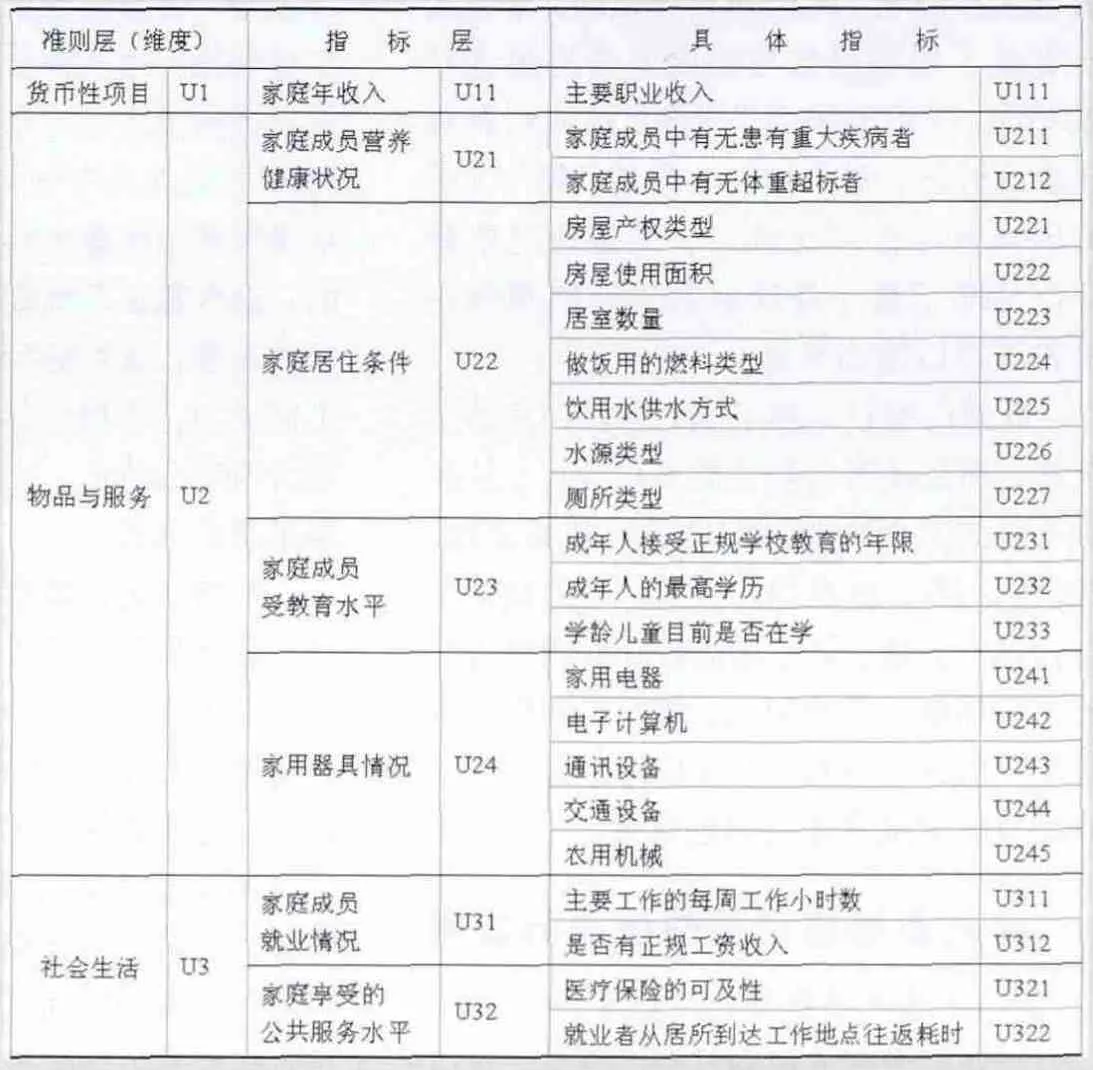
表1 基于微观数据的居民多维福利指数体系

表2 抛物线型模糊隶属函数形式
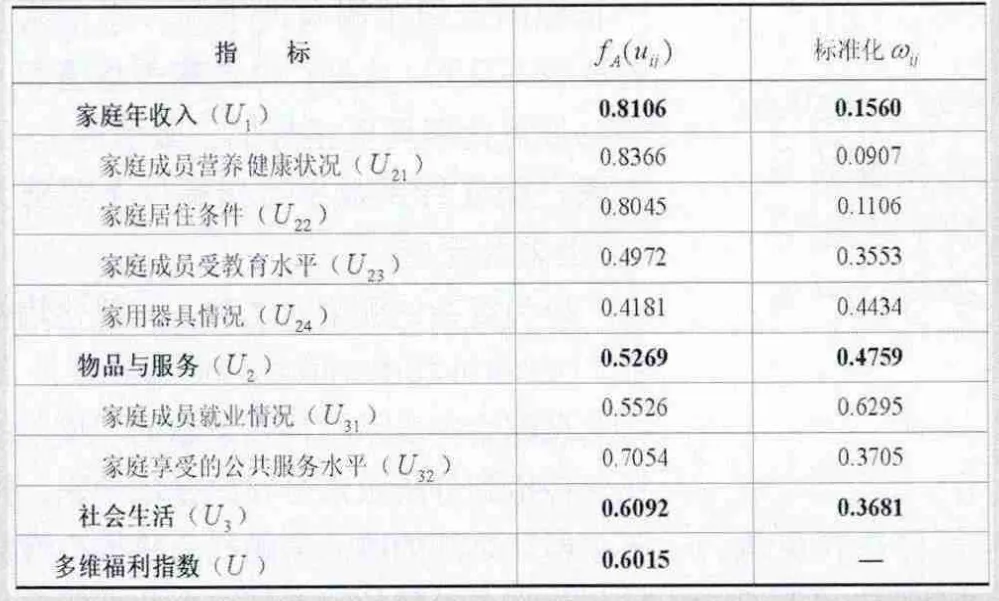
表3 基于2011年微观数据的中国居民多维福利指数的测度结果
1965年,美国加利福尼亚大学的控制论学家扎德(L.A.Zadeh)提出了模糊集合(fuzzy set)的概念,而模糊数学正是建立在这一基础之上的新兴的数学分支。模糊数学在短短四十余年的时间中取得了迅猛的发展。模糊集理论可以提供一种非常合适的处理方法,有助于我们解决那些与居民福利有关的问题。福利问题不是非黑即白、非此即彼的普通现象,而是具有明显的模糊现象的特征,它在本质上是复杂的和不明确的,无法包含在清晰、确切的界线之内。结合上一节关于福利概念与测度方法的阐述可以发现,人们对何谓“福利”的认识具有显著的分歧,对于福利水平的“高”“低”的理解也存在广泛争议,而这些现象都可以借助于善于处理自然语言的模糊评价方法得以恰当表达。
既然已经认识到了福利问题自身的复杂性,那么就有必要依据多项指标,从多个不同的方面对福利问题进行较为全面、综合的判断,就是综合评价。较为规范的综合评价方法,是依据指数分析的原理对多项指标进行综合对比,最后得到概括性的单一的评价指标,也就是构造综合评价的指数或者是多维的指数体系。
居民多维福利指数模型与数据
(一)居民多维福利指数模型
针对所考察的福利问题的特点,可以建立以下一般化的指标体系:第一,目标层。反映所考察的福利问题发展情况或隶属程度的目标值,该层只有一个指标,即最终的MWI;第二,准则层。表示影响所考察问题的主要因素,或者称之为福利的各个维度;第三,指标层。反映对准则层定义的各主要因素(维度)有影响的福利的各个分因子。据此建立评价指标集U=(U1,U2,…,Um),其中U(ii=1,2,…,m)表示评价指标体系准则层的第i个指标因素。在第i个准则层上,Ui=(Ui1,Ui2,…,Uin),其中,Uij(j=1,2,…,n)表示该层的第j个指标因子。
在对所涉及到的统计指标进行模糊化处理的过程中,本文采用偏大型的抛物线型模糊隶属函数形式,具体的函数形式则根据各项指标的实际需要而定。选择这种函数形式的理由主要是,针对各项具体的福利指标而言,该种函数形式比较符合现实情况以及人们用自然语言表述时的主观感受。例如“成年人接受正规学校教育的年限”一项,显然这个年限越长则表明被调查者的受教育程度越高,其工作机会应该更好,生活品质也可能更高,在教育这个福利指标上的评价值也应该越高,因此应当选择偏大型的隶属函数形式;与此相对,“家庭成员中有无患有重大疾病者”一项是按照罹患重大疾病的病种数量来计算的,这个数值越高则表明被调查者的身体条件越差,这可能会影响他的生活质量和工作能力,在健康状况这个福利指标上的评价值应该越低,因此应当选择偏小型的隶属函数形式。
笔者认为,考察福利问题的一个思路是,影响居民生活质量和主观感受的不仅包括货币性收入这个因素(尽管它的重要性毋庸置疑),而且应该涉及更广泛的因素,这些因素往往是非货币性的,比如家庭财产保有情况、居住条件、教育和保健等公共服务、对社会生活的参与情况等诸多方面。这些方面共同作用的合力使得居民实际享有的各种资源产生了差异,从而影响了他们的生活质量。如果将诸如上述那样一些货币性的和非货币性的各种因素纳入居民生活质量的考察范畴,那么就可以建构一个统计指标体系,由于人们往往习惯于用一个单一的指数化指标将其中的全部信息归总起来,以便进行时间序列的或空间上的比较分析,所以我们不妨据此构造一个测度居民享有的福利水平的指数,称之为“多维福利指数(MWI)”。
多维福利指数的构造至少包含两个层次,即直接构成总指数的第一层次(在此称之为“维度”)和构成各个维度的第二层次(即具体指标)。对于维度的确定,笔者采纳了Sen的“可行能力”理论和可借鉴的国际实证研究成果提出的基本框架,在本文所定义的“福利”概念的基础之上,根据经济理论与现实情况相结合的基本思想,设定“货币性项目”、“物品与服务”、“社会生活”三个维度。
之所以确定这三个维度,是因为我们在考察居民福利水平的时候,必须综合考虑以下两个方面:一是货币性维度与非货币性维度的权衡,即不能只关注收入、支出和财产积累,而忽略了诸如教育、医疗等与居民生活密切相关的非货币性指标,因为这些指标的影响不仅在当期,更关系到家庭成员尤其是未成年人未来的机会是否均等这样的重大问题;二是物质性指标与服务性指标的权衡,即既要考虑财产、耐用消费品等物品类指标,又要考虑公共服务、教育等服务性指标,二者同为“产品”的有机组成部分,理应受到同样的重视,不可偏废。
在各个维度内部指标的选择上,主要考虑了指标的相关性、明确性以及调查实务中的可操作性,据此建立共包含7个指标的指数体系。考虑到微观数据的可获得性,对各个维度和其中的指标层及具体指标简要列示如表1所示。
对于综合性指数的计算中如何处理权数的问题,各家学者持有不同见解。笔者认为,简单地对某个维度之间以及某个维度内部的各个指标之间采用相等的权数,固然具有计算简便的优点,但是其缺点同样是显而易见的。因此,笔者支持采用不等权的方法。
常用的不等权赋权方法主要有两种,即Cheli and Lemmi提出的对数函数法以及Saaty提出的专家评分构造判断矩阵法,前者是客观赋权,后者则为主观赋权。笔者曾研究证明,就最终分析结论而言,两种方法的结果差别并不大,结合原始调查数据来看,指标的隶属度大都集中于0.4-0.6这一较小的区间内,这一情况说明,权重的差异对最终结果的影响并不显著。有鉴于此,本文采用计算相对简便的客观赋权方法,即采用以下公式确定权数:

表4 基于微观数据的中国居民多维福利指数的空间测度结果(2011年)
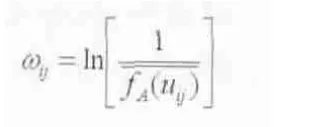
(二)数据的来源与整理方法
中国健康与营养调查(China Health and Nutrition Survey,CHNS)是一个正在发展中的开放性的、体现国际合作的项目,由美国北卡罗来纳大学的卡罗来纳人口统计中心和中国疾病控制与预防中心的国民营养与食品安全委员会合作进行,旨在研究国家和地方政府采取的健康、营养和计划生育政策的效果,以及中国社会的社会和经济改革如何影响民众的健康和影响状况。本文开展的居民多维福利指数空间分析所采用的是最近一次CHNS数据,即2011年住户调查的数据。
在汇总所需基础数据之后,有必要根据本研究的需要对这些数据进行合适的整理,主要是根据各个指标的具体特点,选定合适的模糊隶属函数形式,并确定合理的参数值,从而将原始数据转化为研究需要的模糊隶属度值,便于后续的计算与分析。
在对所涉及到的统计指标进行模糊化处理的过程中,本文对大多数指标采用抛物线型模糊隶属函数形式,具体的函数形式则根据各项指标的实际需要而定,如表2所示。
选择这种函数形式的理由主要是,针对各项具体的福利指标而言,该种函数形式比较符合现实情况以及人们用自然语言表述时的主观感受。例如“成年人接受正规学校教育的年限”一项,显然这个年限越长则表明被调查者的受教育程度越高,其工作机会应该更好,生活品质也可能更高,在教育这个福利指标上的评价值也应该越高,因此应当选择偏大型的隶属函数形式;与此相对,“家庭成员中有无患有重大疾病者”一项是按照罹患重大疾病的病种数量来计算的,这个数值越高则表明被调查者的身体条件越差,这可能会影响他的生活质量和工作能力,在健康状况这个福利指标上的评价值应该越低,因此应当选择偏小形的隶属函数形式。
而收入指标由于其特殊性,采用了偏大型柯西分布模糊隶属函数形式,即形为:

基于微观数据的居民多维福利指数空间分析结果
在对数据进行整理的基础上,可以对所形成的模糊数进行分析,从中了解中国居民福利的总体性特征。由于CHNS数据库的可用数据中,信息比较完全的最近一次调查是2011年开展的,因此表3简要列示了根据当年数据计算得到的测度结果。
表3结果显示,2011年中国居民的多维福利指数为0.6015,这个指数值究竟是大是小,需要与世界其他国家的福利指数对比,这方面的研究另案讨论。如果仅按照模糊隶属函数的取值范围定义在 [0,1]上来看,这个指数值是相对居中偏大的。就指数构成的三个维度分析,以家庭年收入为代表的货币性维度评价最高,达到了0.8106的水平,相形之下,物品与服务维度和社会生活维度的评价则分别只有0.5269和0.6092,都是明显较低的。由于权数确定规则对评价较低的项目赋予较高权数,所以后两个维度的取值偏低也造成了总的指数值偏低。
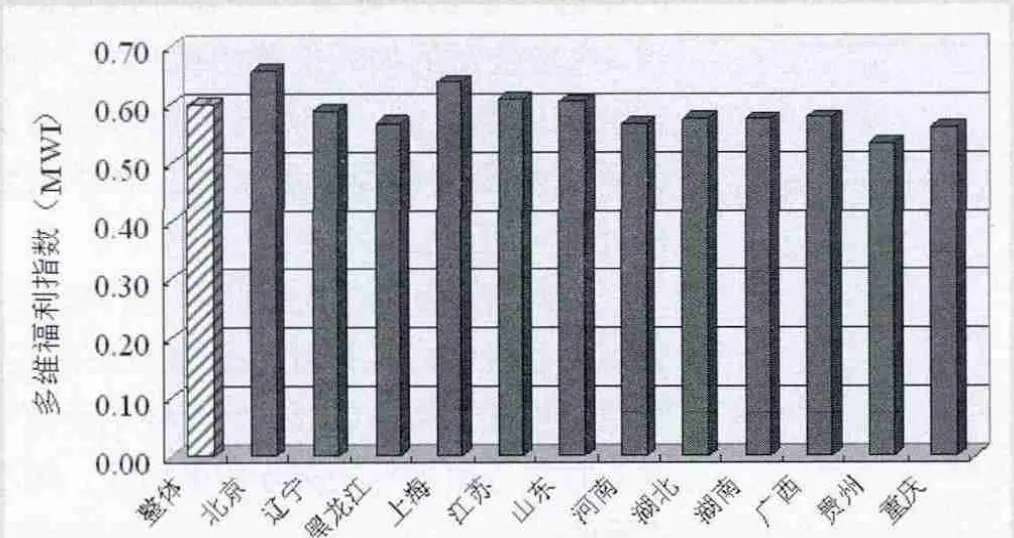
图1 基于微观数据的中国居民多维福利指数的空间比较(2011年)
从后两个维度内部的情况来看,物品与服务维度内部的各个指标的模糊评价值之间的差异性非常显著。其中评价最高的是家庭成员营养健康状况,达到了0.8366,说明新中国成立尤其是改革开放30多年来,中国居民的健康状况普遍得到了显著改善,重大疾病的发生率降低了,同时体重超标者相对较少,这可能主要得益于膳食结构比较合理。相对地,家用器具情况的评价值则偏低,只有0.4181,表明中国家庭的财产保有情况仍然不容乐观,许多家庭在家用电器、通讯设备和交通设备等方面的条件仍然有待改善,且作为农业生产中重要的农用机械的保有量是显著不足的。
2011年CHNS的调查地区涉及北京、辽宁、黑龙江、上海、江苏、山东、河南、湖北、湖南、广西、贵州和重庆共12个省(自治区、直辖市),这些地区在地理位置上分别属于东北、华北、东部沿海、中部和西部,具有一定的地域代表性。对这些省(区、市)的研究有助于我们了解各地的多维福利指数及其构成情况,并且有助于我们分析中国居民的福利水平是否存在空间差异。表4显示了空间分析的具体结果,图1显示了各地区多维福利指数总指数的比较情况。
研究结论
从图1中可以直观地发现,各个地区之间在多维福利指数的评价值上存在着一定的差距,高于整体平均水平(0.6015)的有四个省市,其余省(自治区、直辖市)则较低,其中评价最高的是北京(0.6592),最低的是贵州(0.5364),二者之间相差超过0.12。结合表4的结果分析,中国居民多维福利指数在空间上呈现出以下三个特征:
(一)区域性特征明显
总的来看,东部沿海省份的模糊综合评价值较高,样本中涉及的指数值高于整体平均水平的四个省市北京、上海、江苏、山东均处于东部沿海地区;相形之下,以黑龙江、辽宁为代表的东北省份和湖北、湖南、河南等中部省份的指数值略低;而广西、贵州、重庆三个来自西部地区的省(自治区、直辖市)则指数值最低。这一结果与区域经济研究中从经济发展水平、发展方式上对中国地理区域的划分是一致的,也表明在中国的社会结构中,表现出越深入内陆地区则经济发展程度越落后的倾向,且与之密切联系的居民生活质量以及福利水平也随之降低。
(二)北京、上海福利评价值显著领先
在被调查的12个省(自治区、直辖市)中,经济发展水平最高的当属北京和上海,在本研究的福利情况测度中,其多维福利指数的评价值最高,且在三个维度上两市的评价值均位居前两位,因而体现出相较于其他地区的明显优势。究其原因,近年来的经济高增长是功不可没的,并且,更早之前较好的“积累”也是相当重要的,这一点集中体现在社会生活以及物品与服务两个维度的评价值均较高上。因为居民能够享受的社会福利的多寡,主要取决于当地政府的服务理念和经费投入,而家庭实际享受的物品与服务的数量和质量,也主要受到家庭财富蓄积情况和生活观念的影响,这些都是较长时期积累的结果,不是一朝一夕能够轻易改变的。
(三)中西部地区具有特色
虽然与东部沿海地区相比,来自中西部的省(自治区、直辖市)的居民多维福利指数值较低,并且在各个维度上的评价值也往往处在比较低的水平上,但是不容忽视的是,中西部地区在一些福利指标上仍然具有特色,甚至可以说是优势。比如家庭成员营养健康状况(U21)居于被调查地区前三位的分别是湖北、贵州和湖南,家庭居住条件(U22)居于被调查地区前三位的分别是湖南、重庆和湖北。这些情况说明,中西部地区的重大疾病发生率较低,而体重超标者相对较少,以房屋居住状况、饮水和卫生环境为代表的居住条件相对较好,进而表明当地居民的生活状态相较于其他地区来说可能更具优势,生活压力比较低,饮食起居等生活方式比较健康。这个结果也可以从另一个角度表明,经济发展程度高,可能同时伴生种种“富贵病”的多发,即如果处理不当,或相应的政策、措施不及时到位,对于提高居民福利可能具有塞翁失马的反效果。
1.Alkire,S.,Santos,M.E.Acute Multidimensional Poverty:A New Index for Developing Countries[J].Working Paper of OPHI,July,2010
2.Atkinson A.B.On the Measurement of Inequality[J].Journal of Economic Theory,1970,2
3.Cheli,B.,Lemmi,A.A "Totally" Fuzzy and Relative Approach to the Multidimensional Analysis of Poverty[J].Economic Notes,1995,24(1)
4.Desai,M.,Shah,A.An Econometric Approach to the Measurement of Poverty[J].Oxford Economic Papers,1988,40
5.Martinetti,E.C.A Multidimensional Assessment of Well-being Based on Sen's Functioning Approach[J].Rivista Internazionale di Scienze Sociali,2000,108(2)
6.Sen,A.The Economics of Happiness and Capability[M].in Bruni,L.,Comim,F.&Pugno,M.(eds.),Capability and Happiness.New York:Oxford University Press,2008
7.Zadeh,L.A.Fuzzy Sets [J].Information and Control,1965,8
8.高进云,乔荣锋,张安录.农地城市流转前后农户福利变化的模糊评价—基于森的可行能力理论[J].管理世界,2007(6)
9.洪兴建.贫困指数理论研究述评[J].经济评论,2005(5)
10.刘扬,刘泽琴,赵春雨.民生感知的测度—理论模型与实证分析[J].经济学动态,2010(9)
