中文文法规则的化简及其语义计算效果对比
2015-12-23刘运通梁燕军
刘运通,梁燕军
(安阳师范学院 计算机与信息工程学院,河南 安阳455000)
0 引 言
为了更好地进行自然语言处理,语义的作用越来越被研究者们所重视。Wordnet、Framenet、Hownet、中文概念词典CCD、Chinese FrameNet(CFN)、同义词词林等词汇语义知识库先后被构建出来,作为语义分析的基础性资源,维基也被用作语义计算的网络数据资源。许多学者对语义关系计算也做了研究:文献 [1]研究了5 种基于Wordnet的词汇语义相关度计算方法;文献 [2]研究了基于维基百科的文章网络和分类树,进行词汇语义关联的计算方法;文献 [3]研究了基于维基链接的词汇最近语义关联度的计算方法;文献 [4]研究了在Hownet表达汉语知识的基础上,改进语义相关度的计算模型;文献 [5]研究了基于Wordnet的词汇相关度计算方法;文献 [6]研究了不同语义相关计算方法的计算效果评价方法。还有许多学者利用语义信息来解决自然语言理解中的部分难题:文献[7]研究了利用语义词典Web挖掘语言模型的无指导译文消歧;文献 [8]研究了基于北京大学中文网库的语义角色分类;文献 [9]研究了基于浅层句法分析的中文语义角色标注。
由于自然语言拥有隐含、多变、数量庞大的语法规则,使得研究人员很难将语义分析与语法分析有机地结合起来,而当前的大多数研究,主要是利用语义信息来解决自然语言处理中的部分难题,还没有一个比较成熟、且有广泛影响的基于语义分析的自然语言处理模型。
为了解决这个问题,本文在文献 [10-12]中提出了一个自然语言语义计算模型,并对该模型做了探索性的研究,通过构造一个文法,来描述普通的中文语句,并研究了模型的求解方法和语义消歧方法。这个模型及其求解方法将语法分析、语义分析、语义消歧有机地结合起来,初步形成了一个较为系统的自然语言处理语义分析研究的新思路。然而,该文法中的语法规则较多,形式较为复杂,导致计算复杂度较高。为了降低模型求解时的计算复杂度,对该文法进行了化简,构造了一个更为简洁的文法规则,并通过实验,进行模型求解,比较简化前后的两个文法的计算效果。探索了文法化简的方法和思路,为更高效的模型求解方法研究做了必要的技术储备。
1 语义计算模型
假设一个语句 (CS)中的任意实词Wi(除去谓语中心词)均语义修饰于另外一个实词WGi,并用函数Rel(Wi,WGi)来表示其语义相关度。假设V 是谓语中心词,S是V的施动者,O 是V 的承受者,则语句的语义相关度fAi可以下面的表达式来计算
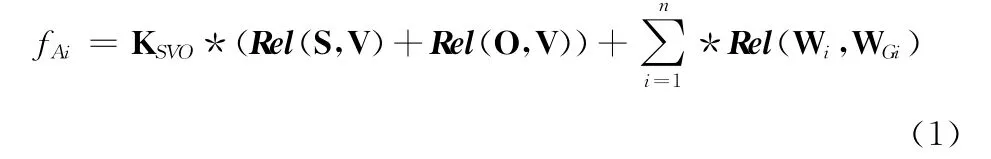
根据语义修饰目标的不同,每个语句可能有多个语法分析方案;遵循少量的语法规则,可以 “穷举”出所有可能的语法分析方案。
一个语句的多个语法分析方案如图1所示。
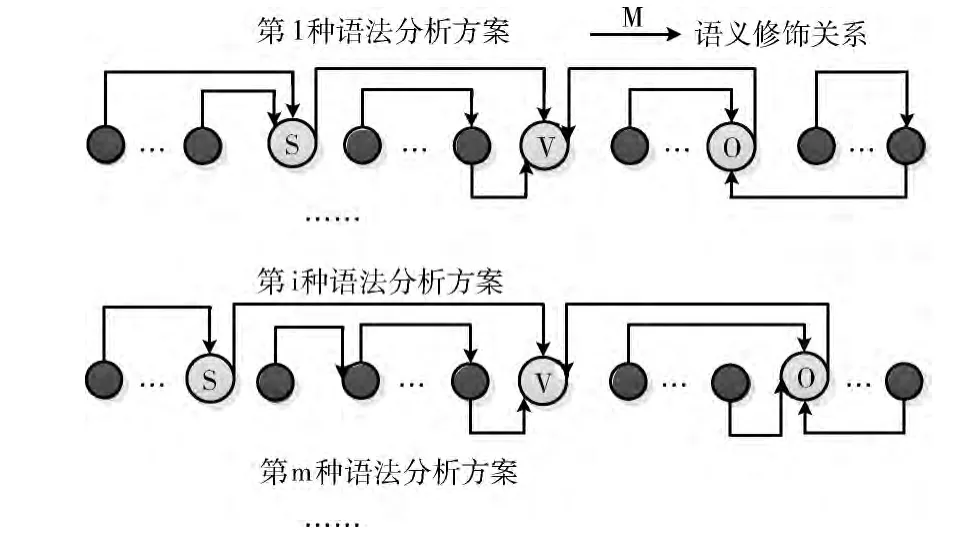
图1 一个语句的多个语法分析方案
模型求解基本规则:fAi值最大的语法分析方案Ai是符合语义逻辑的语法分析方案。
2 文法规则的化简
2.1 文法规则在模型求解中的作用
模型求解过程主要有两个阶段:语法分析阶段、语义分析阶段。
在语法分析阶段:由于自然语言具有隐含、多变、数量庞大的语法规则,任何人也不可能穷举出所有的语法规则。
假如我们换一个思路,假设自然语言无需遵守任何语法规则。则一个包含n个词汇的语句,根据每个词汇语义修饰目标的不同,由于词汇不能修饰自身,则理论上共有(n-1)n种不同的语法分析方案,则可以按照式 (1)计算出每个语法分析方案的语义相关度,选择出最佳结果,就可实现模型求解。但其计算复杂度属于指数级别,实践中根本不可行。
另外,对于某种语法分析方案来说,即使计算出的语义相关度值最大,但由于该语法分析方案可能会违背 “自然语言必须遵守的某些语法规则,是明显违背语义逻辑的”,必须加以排除。
因此,我们在语法分析阶段,引入极少量、最常见、最普适的语法规则,构建一个文法,依据这个文法,进行语法分析,排除明显不可能的语法分析方案;同时也可以极大程度地降低模型求解的计算复杂度,将其降低到实践可行的地步,具体方法见文献 [10]。
在语义分析阶段:忽略其它繁琐、多变、不重要的语法规则,用 “穷举法”生成所有 “符合普适语法规则”的语法分析方案,并通过语义相关度计算,来选择最佳结果,从而进行模型求解。
这种方法,就可以将语法分析、语义分析、语义消歧有机地结合起来,而所构造的文法,在整个模型求解过程中起着至关重要的作用。
2.2 已有的文法规则
我们课题组在文献 [10]中已经设计出了一个文法,用来描述自然语言。根据语义结构的复杂程度,将语句划分为两个层次:
(1)简单子句:没有从句的语句CS,其文法规则见表1 (不包含规则L→CS)。
(2)复杂句:包含从句的语句CS,其文法规则见表1;规则L→CS意味着一个简单子句可以作为一个复杂句中任意成分,实现了对简单句递归,因此可以描述复杂句。
2.3 简化后的文法规则
模型求解时,可以采用自底向上的简单子句归结法,具体细节参见文献 [10];在进行简单子句的归结时,必须进行CYK 算法[13]的运算,以识别符合文法G1(不包含规则L→CS)的简单子句;而这些规则却不能直接进行CYK算法运算,必须将文法G1的所有规则转化为满足乔姆斯基范式的规则集合,经过我们转换后,新文法规则数量有236条之多,规则数量比较多,增加了计算复杂度。更加复杂的是,在归结后,还需要验证新语句是否满足文法G1,还要进行一次CYK 算法的运算。
为了简化语法分析过程,我们对文法G1进行了简化。其思路如下所示。
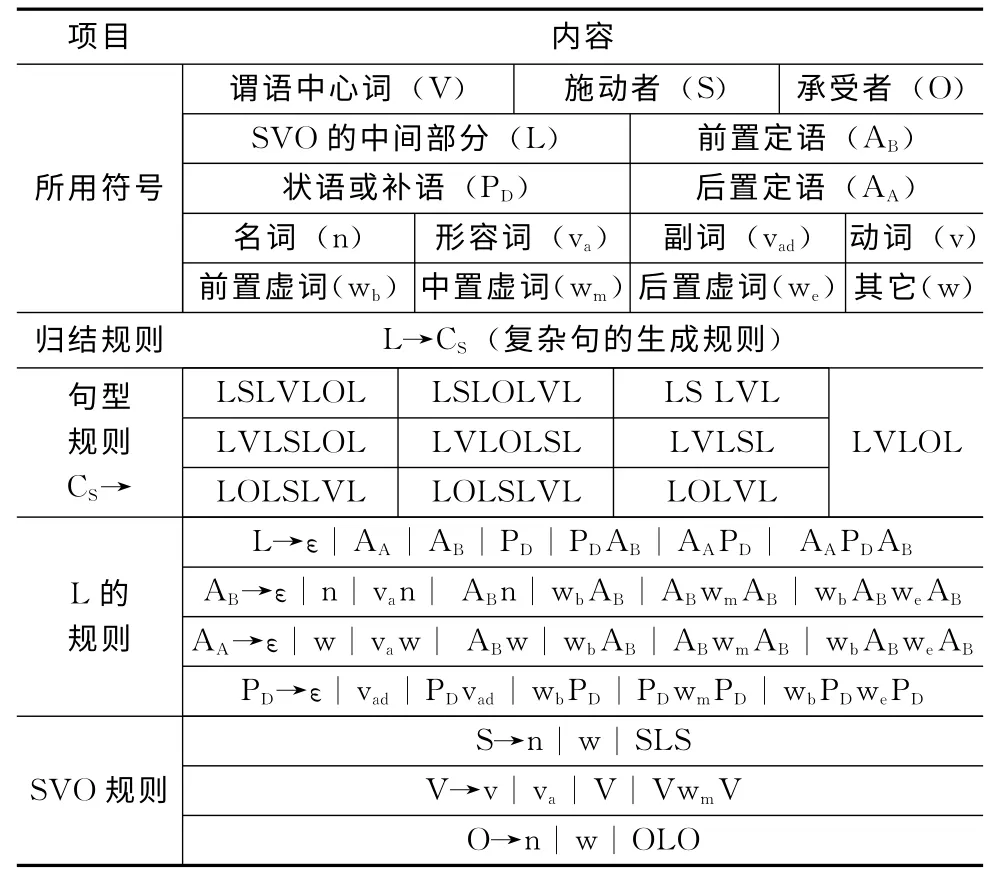
表1 文法G1 的内容
(1)忽略S、O 的区别,仅用一个文法符号R (后文称为主题词)表示这两种情况;S 与O 在语义计算时加以区分;
(2)忽略L中AA、PD、AB的区别,仅用一个文法符号L;在语义计算时,再对L进行AA、PD、AB的划分;
(3)将n、w、vad归为一类,仅用一个文法符号w 表示这3种情况,在语义计算时,再对其进行区分;
(4)将wb、wm、we归为一类,仅用一个文法符号wb表示这3种情况,并且仅使用1条文法规则 (L→wbw)来描述。
简化后的文法规则G2见表2。
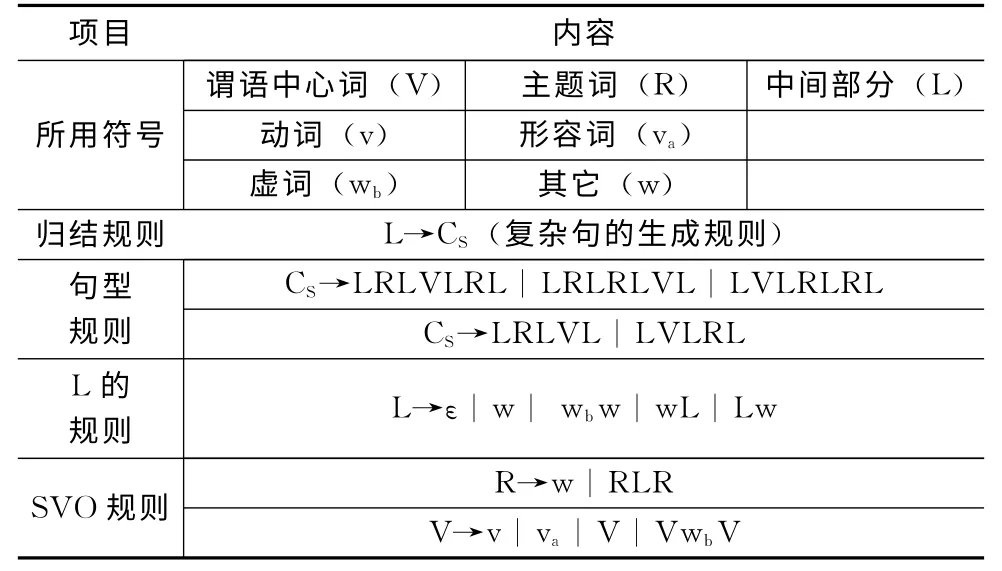
表2 文法G2 的内容
在CYK 算法计算前,需要把文法G2的所有规则转化为满足乔姆斯基范式的规则集合,经过我们转换后,新文法规则数量有55 条,下降约80%。因此可以有效地降低“语法分析”的计算复杂度。
3 依据新文法的语义计算过程
依据文法G1进行语义计算,从而进行模型求解的方法有以下几个步骤:
(1)简单子句归结过程:找出语义相关度最佳的简单子句,反复归结,求出最佳归结顺序。在计算简单子句的最佳语义相关度的过程中,确定每个词汇的最佳语义修饰目标。具体内容在文献 [10]中有详细的论述。
(2)简单子句最佳内部结构的分析:先将简单子句转化为简单语义单元,在用简单语义单元语义修饰关系图模型进行语法分析和语义消歧。具体内容在文献 [12]中有详细的论述。
依据文法G2进行的语义计算时,主要的步骤与上述的过程一致。这里不再引用。差别在于:文法G2将AA、PD、AB的划分等内容,放在 “语义分析”的过程中,用语义计算来代替语法分析。
3.1 L的划分方法
对L进行语义计算时,需要根据语义逻辑,将L 划分为AA、PD、AB等几部分,划分方法见表3 (句型中R、V的位置已选定)。

表3 L的划分方法
例如,在语义计算时,已经确定简单子句的句型是CS→LRLRLVL,则根据语义逻辑,句型中第2个L就应当被划分为如下的AA、PD、AB这3部分,并与其修饰的R 或V 组成一个整体,该整体被称为 “简单语义单元”。简单语义单元的语法分析和语义消歧方法,在文献 [12]中有详细的论述。
L的划分方法如图2所示。
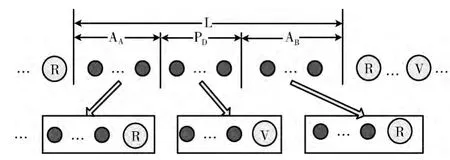
图2 L的划分方法
3.2 AA\PD\AB 的划分位置
对L (假定L包含p个词)进行AA\PD\AB的划分时,根据表3,其划分位置有3种情况:
(1)无需划分:当L仅包含PD时;
(2)一个划分位置:L包含AA|PD或PD|AB时,共有p+1个位置可供选择,p+1种划分方法;
(3)两个划分位置:L包含AA|PD|AB时,共有p+1个位置可供选择,有 (p+1)*p种划分方法。
针对这多种划分方法,用式 (1)算出几部分的语义相关度的值,并求总和,选择总和最佳的划分方法即可。
4 实验结果及分析
本文的实验中,以Hownet作为词汇语义计算时所依据的资源。选取200 个语句,依据文法G1和文法G2,分别进行模型求解的对比实验,具体情况如下 (实验环境为windows xp;CPU:Xeon E5-2403,2GHz;Mem:8G)。
4.1 时间对比实验
根据语句的长度 (按照词汇个数计算)进行分组,共分为8组,表4列出了依据文法G1和文法G2进行模型求解所需的时间。
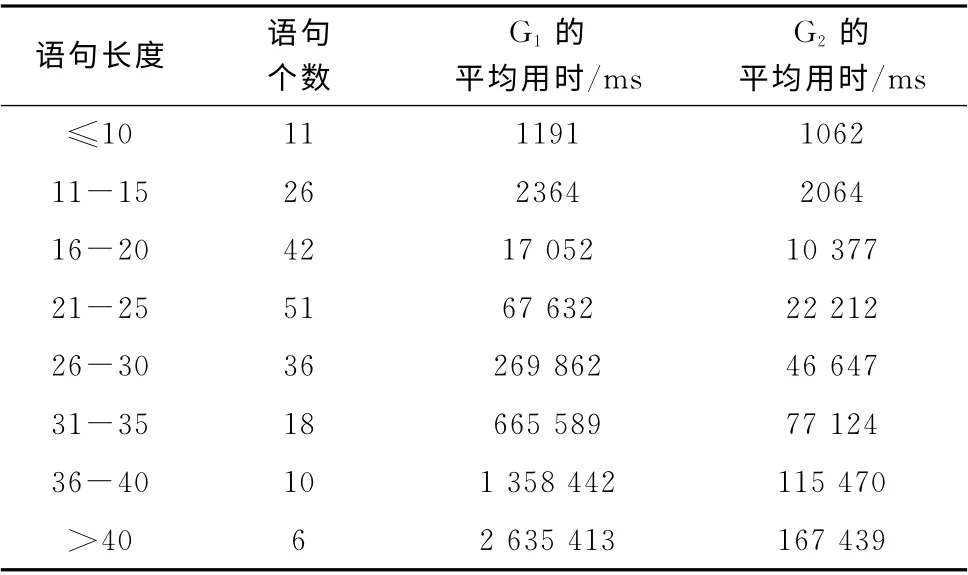
表4 两个文法的求解时间对比
G2的平均用时/G1的平均用时如图3所示。
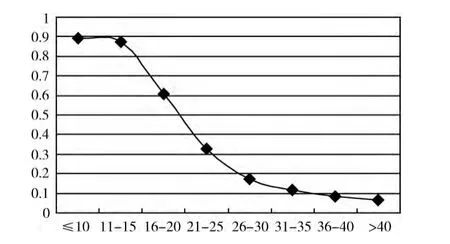
图3 G2 的平均用时/G1 的平均用时
显然,语句的长度越长,包含的简单子句也越多,求解时所需的时间也越长,文法G2的时间效率也越高。
4.2 正确率对比实验
在正确率对比实验中,有以下几类情况,如表5所示:
(1)SVO 选择的正确率 (包括简单子句内的SVO 选择),其对比如图4所示;
(2)简单子句所辖范围的正确率,其对比如图5所示;
(3)简单子句归结顺序的正确率,其对比如图6所示;
(4)L中AA|PD|AB划分的正确率,其对比如图7所示;
(5)所求出的语义修饰目标的正确率,其对比如图8所示。
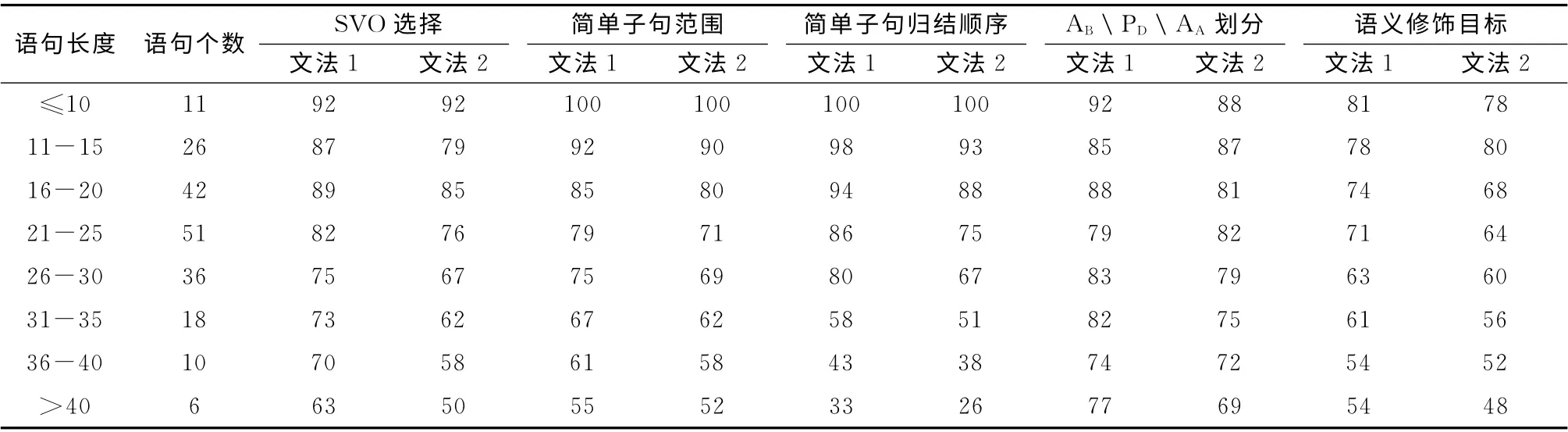
表5 正确率对比情况/%
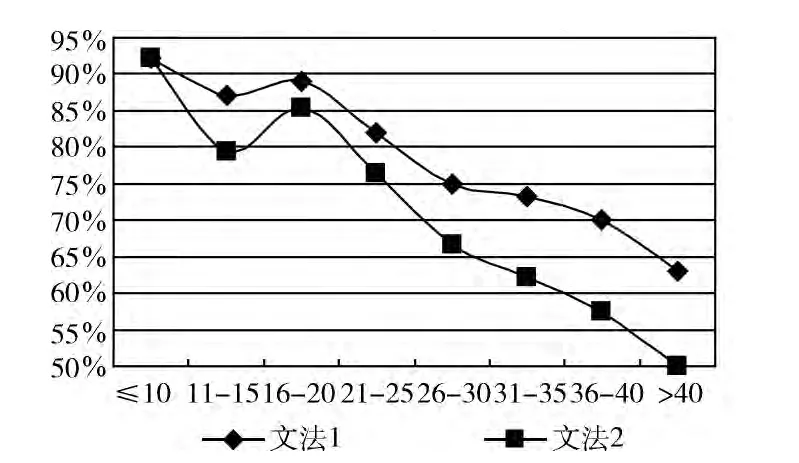
图4 SVO 的正确率对比
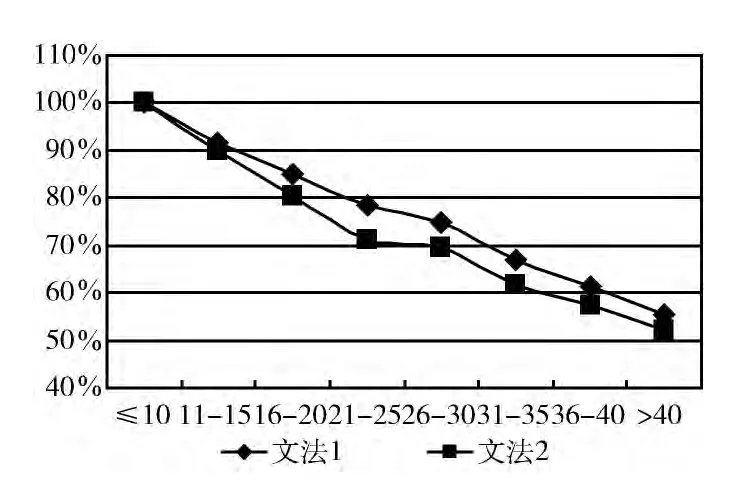
图5 简单子句范围的正确率对比
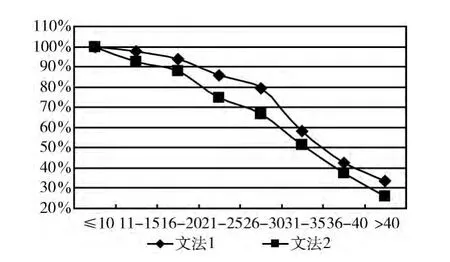
图6 简单子句归结顺序的正确率对比
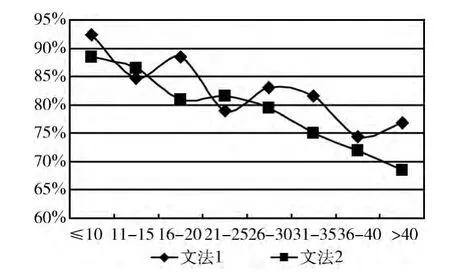
图7 L划分的正确率对比

图8 语义修饰目标的正确率对比
从实验情况可以看出,文法G2的求解过程相对于文法G1,有以下几个特点:
(1)时间效率得到了较大程度的提升;
(2)各项正确率均有所下降,但下降程度并不大;其主要原因在于文法G2的规则被大幅精简,语法描述的准确性下降,导致语法分析阶段的准确度下降,后期的语义计算,并不能完全弥补 “语法分析精度下降”的损失;
(3)综合来看,依据文法G2进行模型求解,是一种“准确度损失”不大、更为快捷、效率更高的语义计算方法。
5 结束语
本文构造了一个更为简洁的文法规则,依据该文法规则,可以进行语义计算和语义模型求解;通过实验,比较简化前后两个文法的计算效果;探索文法化简的方法和思路,研究在文法化简过程中,文法化简与 “降低时间复杂度”和 “准确度下降”等问题之间的关系,为构造出更简单的文法和更快捷的模型求解方法做了探索。但在论文的研究中,实验数据量较小,语义计算时所依据的词汇语义库的语义信息还不够细致,不能够完全满足语义计算的需要,下一步研究中,需要增加实验数据,构建语义信息更准确、语义粒度更小的词汇语义库作为语义计算的依据。
[1]Alexander B,Graeme H.Evaluating wordnet based measures of lexical semantic relatedness[J].Computations Linguistics,2009,32 (1):13-47.
[2]SUN Chenchen,SHEN Derong,SHAN Jing,et al.WSR:A semantic relatedness measure based on wikipedia structure[J].Chinese Journal of Computers,2012,35 (1):2361-2370 (in Chinese).[孙琛琛,申德荣,单菁,等.WSR:一种基于维基百科结构信息的语义关联度计算算法 [J].计算机学报,2012,35 (1):2361-2370.]
[3]Milne D,WittenI H.An effective,low-cost measure of semantic relatedness obtained from Wikipedia links [C]//Proceedings of the 23th Association for the Advancement of Artificial Intelligence,2008:25-30.
[4]ZHONG Maosheng,LIU Hui,LIU Lei,et al.Method of semantic relevance relation measurement between words[J].Journal of Chinese Information Processing,2009,23 (2):115-122 (in Chinese).[钟茂生,刘慧,刘磊,等.词汇间语义相关关系量化计算方法[J].中文信息学报,2009,23 (2):115-122.]
[5]Mohamed AHT,Mohamed BA,Abdelmajid BH.A new semantic relatedness measurement using WordNet features [J].Knowledge and Information Systems,2013 (8):1-31.
[6]Felice Ferrara,Carlo Tasso.Evaluating the results of methods for computing semantic relatedness [C]//14th International Conference on Intelligent Text Processing and Computational Linguistics,2013:447-458.
[7]LIU Pengyuan,ZHAO Tiejun.Unsupervised translation disambiguation by using semantic dictionary and mining language model from Web [J].Journal of Software,2009,20 (5):1292-1300 (in Chinese). [刘鹏远,赵铁军.利用语义词典Web挖掘语言模型的无指导译文消歧 [J].软件学报,2009,20 (5):1292-1300.]
[8]YANG Min,CHANG Baobao.Semantic role classification based on Peking university Chinese NetBank [J].Journal of Chinese Information Processing,2011,25 (6):3-8 (in Chinese).[杨敏,常宝宝.基于北京大学中文网库的语义角色分类 [J].中文信息学报,2011,25 (6):3-8.]
[9]WANG Xin,SUN Weiwei,SUI Zhifang.Research on Chinese semantic role labeling based on shallow parsing [J].Journal of Chinese Information Processing,2011,25 (1):116-121 (in Chinese).[王鑫,孙薇薇,穗志方.基于浅层句法分析的中文语义角色标注研究 [J].中文信息学报,2011,25 (1):116-121.]
[10]LIU Yuntong,LIANG Yanjun.K-pruning algorithm for semantic relevancy calculating model of natural language [J].Computer Engineering and Design,2013,34 (8):2939-2943(in Chinese).[刘运通,梁燕军.自然语言语义相关度计算模型的k 枝剪求解法 [J].计算机工程与设计,2013,34(8):2939-2943.]
[11]LIU Yuntong,XIONG Jing.An algorithm for parsing the simple semantic units based on the semantic relevancies [J].International Journal of Applied Mathematics and Statistics,2013,47 (17):372-379.
[12]LIU Yuntong,SUN Hua.Word sense disambiguation for the simple semantic units based on dynamic programming [J].Computer Engineering and Design,2014,35 (4):1480-1485(in Chinese).[刘运通,孙华.基于动态规划的简单语义单元词义消歧 [J].计算机工程与设计,2014,35 (4):1480-1485.]
[13]LI Yongliang,HUANG Shuguang,LI Yongcheng,et al.Improved CYK algorithm based on shallow parsing [J].Journal of Computer Applications,2011,31 (5):1335-1338 (in Chinese).[李永亮,黄曙光,李永成,等.基于浅层剖析的CYK 改进算法 [J]. 计算机应用,2011,31 (5):1335-1338.]
