对数似然相似度算法的MapReduce并行化实现
2015-12-23张明敏张功萱周秀敏
张明敏,张功萱,周秀敏
(南京理工大学 计算机科学与工程学院,江苏 南京210094)
0 引 言
Mahout是Apache软件基金会 (ASF)旗下的一个开源项目,它是一种机器学习软件库,提供了一些包括聚类、分类和协同过滤等机器学习领域经典的算法,旨在帮助开发人员更加方便高效地创建智能应用程序。Mahout还支持Apache社区的Hadoop平台,并且已经将一部分算法实现MapReduce并行化,以此来作为一种解决机器学习问题的廉价方案[1-4]。
Mahout提供了大量的协同过滤算法的功能,其中比较典型的两类算法:基于用户的协同过滤 (user CF)和基于物品的协同过滤 (item CF),都在Mahout中得到了实现。两种算法都依赖于两个事物 (用户或者物品)之间的相似性度量,或者说等同性定义[5]。在协同过滤算法中,相似性的度量是关键步骤,也是算法效率的瓶颈所在[6]。然而,Mahout中并没有提供基于MapReduce的相似度计算方法。在实际应用中,单机的相似度算法受限于内存和效率,无法处理海量的数据。
因此,本文引入了Hadoop集群和MapReduce并行计算模型,研究并实现对数似然相似度算法的并行化。根据算法自身的特点,采用复合键对和同现矩阵的思想[7]对MapReduce过程进行优化,然后在Hadoop平台上运行优化后的算法。
1 MapReduce模型简介
MapReduce是谷歌公司在2004 年提出的一种软件架构,主要用来解决大规模数据集在集群上的计算问题,它是一种用于处理和生成大数据集的编程模型[8]。文献 [9]详细地描述了MapReduce的核心思想。
MapReduce框架使用两种类型的组件来控制作业的执行过程。一个是JobTracker,负责作业的分解和状态的调控。另一个是TaskTracker,负责执行具体的MapReduce程序[10]。根据作业中输入数据的位置,JobTracker把任务分配给一些TaskTracker,并保证它们协调工作。Task-Tracker运行分配到的任务,同时向Jobtracker汇报任务的进展情况。在执行具体的程序时,每个MapReduce任务又分为map和reduce两个阶段,分别负责分解任务和汇总结果。
在作业开始之前,存储在Hadoop 分布式文件系统(HDFS)[11]中的数据被切分成很多小的数据集或者碎片(split)。每一个split对应一个map任务,每个map任务又会被分配给靠近该split的节点中的TaskTracker运行。在map阶段,map函数接收键值对形式的输入,经过处理产生同样格式的输出。然后通过重新洗牌过程[12],将键值对分配到各个Reduce节点。在reduce阶段,reduce函数将具有相同key值的键值对合并,然后对value集合进行处理,产生一个<key,value>形式的输出。其原理如图1所示。

图1 分布式的MapReduce处理过程
2 对数似然相似度算法的并行化实现
2.1 对数似然相似度算法
Ted Dunnning在1993年提出一种对数似然比的概念,主要应用于自然文本语言库中两个词的搭配关系问题。它是基于这样一种思想,即统计假设可以确定一个空间的很多子空间,而这个空间是被统计模型的未知参数所描述。似然比检验假设模型是已知的,但是模型的参数是未知的。2.1.1 二项分布的对数似然比
对于二项分布的情况,似然函数为
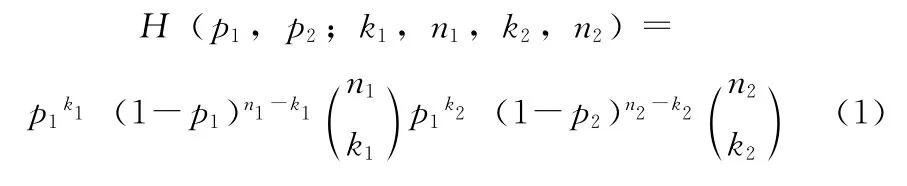
式中:H——给定的统计模型,k1,k2,n1,n2——给定实验结果的参数。p1,p2——给定模型的参数。
假设二项分布有相同的基本参数集合 {(p1,p2)|p1=p2},那么对数似然比λ就是
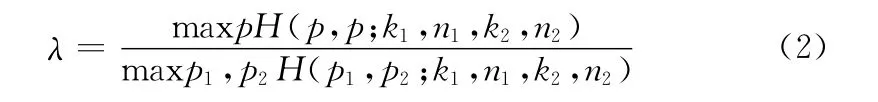
式中:maxpH ——当p取得某值时,统计模型H 的最大值。
当p1=,p2=时,分母取得最大值。当p =时,分子取得最大值。
所以对数似然比简化为

式中:L——二项分布,n——实验重复的次数,p——某事件发生的概率,k——该事件发生的次数,L(p,k,n)=pk(1-p)n-k。
两边取对数可以将对数似然比的公式变形为,-2logλ=2[logL(p1,k1,n1)+logL(p2,k2,n2)- logL(p,k1,n1)-logL(p,k2,n2)]。
2.1.2 Mahout中对数似然相似度算法的实现
由于二项分布的对数似然比能够合理地描述两个事物相似的模型,所以Mahout中利用对数似然比来计算两个事物(用户或者物品)的相似度。对数似然相似度基于两个用户共同评估过的物品数目,但在给定物品总数和每个用户评价物品数量的情况下,其最终结果衡量的是两个用户有这么多共同物品的 “不可能性”,它是一种不考虑具体偏好值的方法。对数似然相似相似度算法在Mahout中的具体实现为
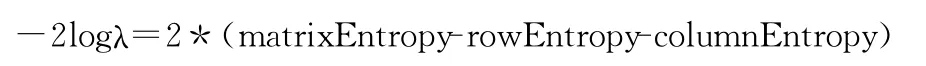
其中
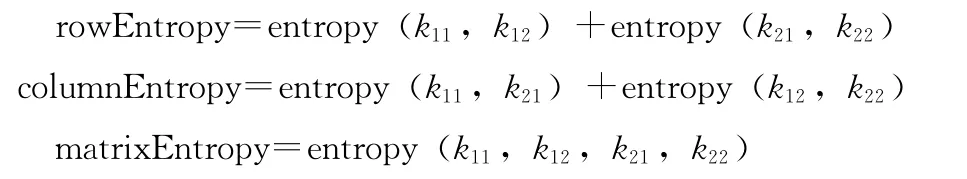
entropy(int...elements)实质上是一种简单计算熵值的函数。以计算用户1和用户2的相似度为例,k11表示两个用户共同偏好的item 数量,k12表示用户1偏好而用户2不偏好的item 数量,k21表示用户2偏好而用户1不偏好的item 数量,k22表示用户1和用户2都不偏好的item 数量,可以将这4个变量看成一个二维矩阵),然后计算这个矩阵的行熵 (rowEntropy)、列熵 (columnEntropy)和矩阵的熵(matrixEntropy),从而得出相似度值。
通过上述过程可以发现,相似度的计算最终可以归结为计算k11,k12,k21和k22的值。进一步分析可以得到,k12=k1-k11,k21=k2-k11,k22=item 总数-k1-k2+k11。其中k1,k2分别为用户1和用户2偏好的物品个数。区域具体分布情况如图2所示。在计算过程中,只需获得item 总数,用户1和用户2分别偏好item 的个数以及他们共同偏好的物品个数,就能得出所需的4个参数值。
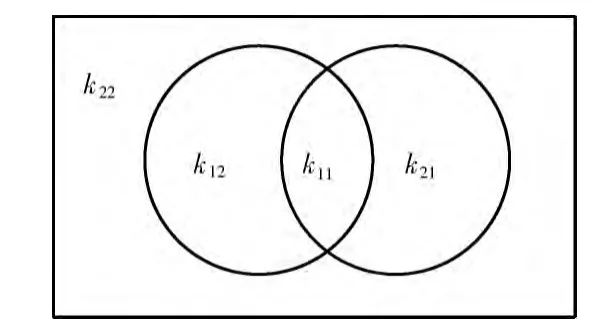
图2 4个区域的分布
2.2 算法的MapReduce实现
下面以计算用户之间的相似度为例,具体介绍对数似然相似度算法的并行化过程。以表1中的二维矩阵为例,其中U1,U2,U3为用户,I1,I2,I3,I4为物品。表格中的数字1表示某个用户偏好该物品,空白表示用户不偏好该物品。
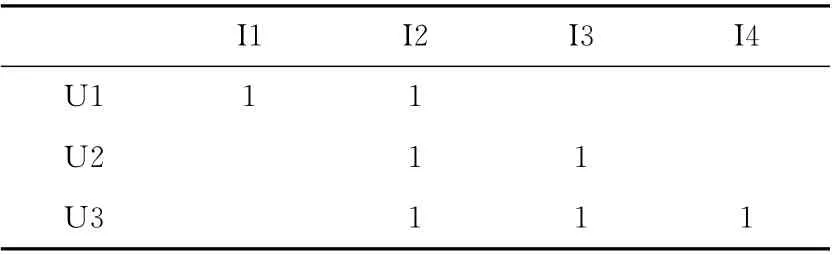
表1 二维偏好矩阵
Loglikelihood相似度并行计算将拆分成4 个MapReduce任务。第1 个MapReduce任务计算每个用户偏好的物品总数。第2 个MapReduce任务将偏好某个物品的用户放到一条记录中,形成以物品为键、偏好该物品的所有用户为值的倒排列表。第3个MapReduce任务计算两两用户共同偏好的物品个数,并且记录物品的总个数numItems。第4个MapReduce任务计算相似度。具体过程如图3所示。
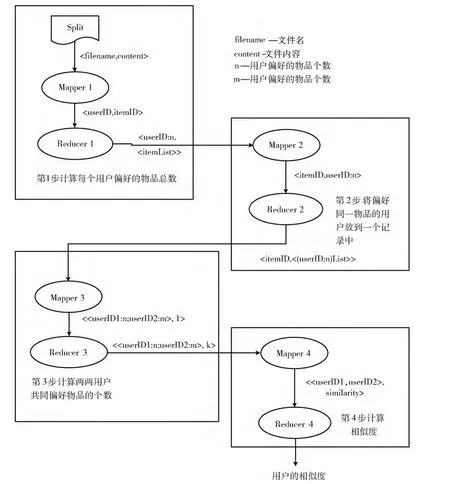
图3 MapReduce的并行化过程
第1个MapReduce过程称为倒排索引,其输入数据在文件中的存储格式为<用户,物品,偏好值>。首先将文件分割成splits并按行作为程序的输入,然后将<每行的偏移量,每行的内容>形式的键值对交付给程序中定义好的map函数进行处理。对每个用户,以用户和用户偏好的物品个数为键,该用户偏好的所有物品列表为值,中间用分号隔开,这样我们就能得到如<U1:2,<I1;I2>>、<U2:2,<I2;I3>>以及<U3:3,<I2;I3;I4>>格式的输出。这样做的目的是,能够统计出每个用户偏好的物品总数,为下面计算k12和k21打下基础。
第2个MapReduce过程还是倒排索引,其输入为第1步MapReduce输出的结果。map阶段以每一个物品为键,偏好该物品的用户和用户偏好的物品总数为值作为输出。然后经过重新洗牌过程发送到Reduce节点,reduce函数将具有相同key值 (物品)的所有value组合起来,中间用分号隔开,这样就能得到如<I1,U1:2>、<I2,<U1:2;U2:2;U3:3>>、<I3,<U2:2;U3:3>>以及<I4,U3:3>格式的输出。这样做的好处是,将偏好同一物品的所有用户都聚集在同一个value下,方便下一步MapReduce任务的处理。
第3个MapReduce过程主要是计算用户两两之间共同偏好物品的个数即k11,以及物品的总个数,其输入为第2步MapReduce输出的结果。对每一条记录,map函数丢弃掉key值,将value中的用户两两配对,并作为键值,value值设置为1。同时,map函数通过逐行读入数据,记录下总行数,即物品的总个数numItems。Reduce函数将具有相同键值的value值相加,得出两两用户共同偏好物品的总个数。最终可以得到以下输出:<<U1:2;U2:2>,1>,<<U1:2;U3:3>,1>,<<U2:2;U3:3>,2>。
第4个MapReduce过程真正用来计算用户两两之间的相似度。其以上一步MapReduce输出的结果为输入,从每一条记录里面能够提取到k11,k1,k2以及上一步MapReduce过程计算好的物品总个数numItems。通过k1,k2,numItems能够分别计算出k12,k21和k22的值,然后调用函数loglikelihoodRatio (k11,k12,k21,k22),最终计算出相似度的数值。
4个MapReduce任务采用顺序组合的方式[13],每个MapReduce任务都需要配置自己的运行代码,并按照前后关系正确的配置输入/输出的路径。程序运行后,会按照MapReduce任务之间的顺序逐个运行作业。因为前一个MapReduce任务的输出要作为后一个MapReduce任务的输入,所以需要调用job.waitForCompletion (true)来保证前一个子任务执行完成后再执行下一个子任务。
2.3 MapReduce任务的优化
初步分析和运行上述4 步MapReduce任务可以发现,第3步MapReduce任务执行的时间最长,其原因主要是:这一步MapReduce任务产生大量的键值对,而且这些键值对无法用combiner处理,Hadoop将它们写到磁盘上时需要耗费大量的时间。针对一条记录,假设同时对一个物品有偏好的用户数有n个,那么在第3步map函数将产生n* (n-1)/2个键值对,时间复杂度为O(n*n)。当n=10000时,键值对数目将达到10亿数量级。即使一台机器处理一条记录,也会非常耗费资源,达不到预期的效果。而且map阶段产生的键值对需要传输给Reduce节点,不但增加网络通信的开销,而且使得reduce阶段的copy和sort过程非常缓慢。因此,本文根据Jimmy Lin的单词同现矩阵的思想,提出一种将大量小的键值对合并为较大键值对的方法,大幅减少传送给Reduce节点的键值对数量。
如图4所示,针对第2步MapReduce产生的一条记录<I2,<U1:2;U2:2;U3:3>>,原先产生的许多小键值对可以合并成右侧大的键值对。然后,在Reduce阶段,将具有相同key值的键值对进行累加,即可获得一个用户同其他用户共同偏好物品的关系及其具体的个数。还是假设同时对一个物品有偏好的用户数有n个,那么在这一步map函数将产生n-1 个键值对,时间复杂度为O(n),所产生的键值对数量远远小于原来的步骤。此时的MapReduce相应的伪代码如图5所示。

图4 第3步MapReduce的优化过程

图5 MapReduce过程的伪代码
3 实验和结果分析
3.1 实验环境
Hadoop集群为建立在openstack云平台上的6台虚拟机,其中,1台为主节点 (master),5台为从节点(slave)。每台虚拟机的主要配置如下:两个虚拟内核,内存为2G,磁盘为10G。Java版本为Java-7-oracle,Linux系统为Ubuntu12.04,Hadoop版本为1.2.1。
3.2 实验及结果分析
实验数据:本实验采用的数据集来自于GroupLens提供的电影评分集。该数据集包含6000 多位用户对3900 多部电影的一百多万条评分记录。评分数据集中包含用户ID,电影ID,评分和时间戳。用户ID 的区间为1 到6040,电影ID 的区间为0到3952,评分区间为0到5,每个用户至少对20部电影的进行评分。因为,对数似然相似度是处理无评分数据的,所以可以将用户对某部电影评分,视为用户看过该电影,用户没有对某部电影,视为用户没有看过该电影。
实验设置:本实验采用Eclipse作为集成开发环境。首先,在单机环境中,调用Mahout中计算对数似然相似度的函数,统计运行时间。然后,分别采用1,2,3,4,5 个节点的集群,运行本文所提出的并行化的算法,统计运行时间。最后,将单机运行时间与集群运行时间进行比较。
实验结果:由图6可以看出,当节点数为1~2个的时候,集群运行的效率远低于单机运行效率。其主要原因有两个:对于集群而言,一是任务的启动和交互占据一定的时间,尤其当实际的计算量比较小时,集群的优势无法体现出来;二是数据网络传输的影响。单机版的相似度算法首先会将数据全部读入内存,然后进行计算,所以处理的速度比较快。而在Hadoop集群中,Map函数先将数据写到磁盘上,然后Reduce函数再从磁盘上读取数据,增加了数据传输的时间。但是当集群节点数大于3个的时候,集群的优势就开始逐渐体现出来。由此可知:当节点数达到一定数量时,集群的运行效率要优于单机的运行效率。
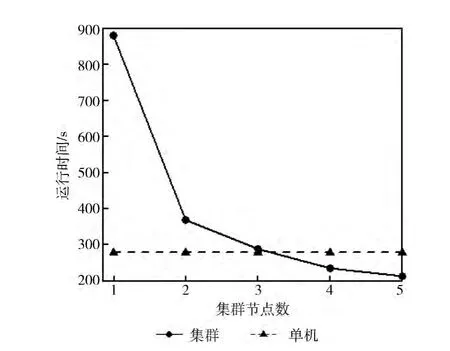
图6 集群和单机运行时间的对比
加速比S=Ts/Tm 是衡量并行系统或程序并行化性能的重要指标。其中,S是加速比,Ts是单机算法的运行时间,Tm 是m 个节点运行的时间。由图7 可以看出,加速比随着集群节点数的增加而增大,当节点数大于4时,加速比大于1。这说明,基于Hadoop集群的对数似然相似度算法具有较好的加速比。而且,随着集群节点数量的增加,这种优势将会更加明显。
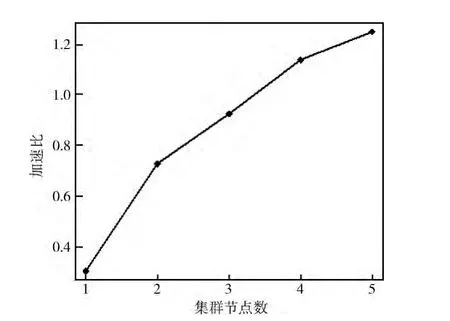
图7 集群的加速比
4 结束语
Hadoop集群和MapReduce编程模型是当前解决海量数据问题的主要解决方案,Mahout结合Hadoop将使得数据的挖掘和分析更加高效和便捷。本文主要探讨了Mahout中对数似然相似度算法的并行化问题,并使用MapReduce编程模型在Hadoop 平台上实现了该算法,并且优化了其中的MapReduce过程。相关的实验结果表明,在处理大数据集时,并行算法的运行效率要优于单机算法的运行效率。集群规模越大,算法的执行效率越高,加速比越明显。
[1]DanEr CHEN.The collaborative filtering recommendation algrorithm based on BP netral networks[J].Computer Society of IEEE,2009,121:234-235.
[2]Apache Mahout.The apache software foundation [EB/OL].[2012-02-06].http://mahout.apache.org.
[3]Apache Hadoop.The apache software foundation [EB/OL].[2012-04-01].http://hadoop.apache.org.
[4]Esteves RM,Rong C.K-means clustering in the cloud-a mahout test [J].Computer Society of IEEE,2011,136:515-516.
[5]Sean Owen,Robin Anil,Ted Dunning,et al.Mahout in action [M].US:Manning Publications,2010:41-42.
[6]MA Ning.Research and implementation of recommendation system based on mahout[D].Lanzhou:Lanzhou University,2012:30 (in Chinese).[马宁.基于Mahout推荐系统的研究与实现 [D].兰州:兰州大学,2012:30.]
[7]Jimmy Lin,Chris Dyer.Data-intensive text processing with MapReduce [M].US:University of Maryland,College Park,2010:39-52.
[8]Dean J,Ghemawat S.MapReduce:Simplified data processing on large clusters [J].Communications of ACM,2008,51(1):107-113.
[9]LANG Weimin,YANG Depeng.MapReduce technology on cloud computing [J].Telecommunications Information,2012,3:3-5 (in Chinese).[郎为民,杨德鹏.云计算中的MapReduce技术 [J].电信快报,2012,3:3-5.]
[10]Narayan S,Bailey S,Daga A.Hadoop acceleration in an open flow-based cluster [J].Computer Society of IEEE,2012,76:535-538.
[11]Konstantin Shvachko,Hairong Kuang,SanjayRadia,et al.The Hadoop distributed file system [C]//Mass Storage Systems and Technologies,2010:1-10.
[12]YAN Yonggang,MA Tinghuai,WANG Jian.Parallel implementing KNN classification algorithm using MapReduce programming mode[J].Journal of Nanjing University of Aeronautics and Astronautics,2013,45 (4):551-554 (in Chinese).[闫永刚,马廷淮,王建.KNN 分类算法的MapReduce并行化实现 [J].南京航空航天大学学报,2013,45(4):551-554.]
[13]LIU Peng.Hadoop in action [M].Beijing:Electronic Industry Press,2011:142-143 (in Chinese). [刘鹏.实战Ha-doop [M].北京:电子工业出版社,2011:142-143.]
