基于Kinect的自动视频抠像算法
2015-12-23夏玉勤
夏 倩,许 勇,夏玉勤
(1.贵州民族大学 传媒学院,贵州 贵阳520025;2.华南理工大学 计算机学院,广东 广州510510;3.贵州大学 计算机科学与工程学院,贵州 贵阳520025)
0 引 言
传统的数字抠像 (digital image matting)算法例如三分图、涂鸦方式都需要用户交互,耗时多且计算复杂,使视频抠像图算法的实际应用受限[1]。
微软的Kinect体感设备能够获取深度图,它可以避免物体遮挡、亮度变化、阴影以及环境变化等的影响,因此现有的视频抠像算法引入了深度图像信息来辅助抠像。文献[2]对获取的深度图进行聚类和形态学操作,得到大致的区间分割图。接着利用深度值来改进闭式解抠像算法[3],但它没有充分利用前一步获取的透明度值a,造成无法获得精确的抠像边界。文献 [4]利用颜色信息将图像过分割,过分割区域被视为节点,接着把颜色和深度信息相似性作为邻接区域边的权重,从而构建一个带权图。最后使用归一化切割方法实现抠像,但是算法中没有考虑前背景关联性,无法将前景与背景有接触的区域分离。文献 [5]不仅考虑空间信息、颜色信息,而且结合深度信息建立一个双重双边滤波器,但这种算法没有考虑每一信息的权重,只是简单的将所有信息糅合在一起,抠像结果不理想。
针对以上问题,本文提出一种利用运动、颜色以及Kinect的深度图来提取感兴趣区域 (region of interest,RoI)的自动视频抠像算法。算法根据运动和深度信息获得到视频中的ROI,排除非主要区域及背景的干扰,减少了运算量,提高了后续抠像的速度。在ROI区域内使用改进的种子区域生长法,计算粗前景掩膜,再利用数学形态学和逻辑操作得到大致的三分图。最后在和人类视觉一致的Lab颜色空间[6]中精确计算三分图,即使用改进的Shared Matting算法[7]来减小前一步骤中大致三分图带来的误差,保证视频自动抠像结果的精度。本文算法省去了任何形式的人机交互,在降低计算复杂度的同时也提高了运算速度。
1 本文算法
本文研究的重点是利用Kinect产生的深度图像信息、颜色信息、运动信息以及帧间相关性自动生成精确的视频帧抠像,提高视频抠像效果,期望既能减少视频抠像时间,又能保证视频抠像的时空一致性。本文算法流程如图1所示。
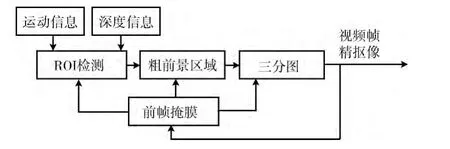
图1 本文算法流程
1.1 ROI检测
视频抠像的目标在于精确提取场景中的ROI[8,9]。例如,在大多数场景中,运动的目标经常是人们比较关注的区域。这些ROI如果能被计算机迅速发现,并进行重点分析,将提高图像处理效率和精度。
本文利用三帧差分法,首先选取视频序列图像中连续三帧,分别计算相邻两帧的差分图像,然后选择恰当的阈值将差分图像二值化处理,最后两个连续差分二值图像进行逻辑与运算,从而获得出运动目标既是视频场景中的ROI。但该方法易于受到噪声和亮度突变的影响。为了降低运动目标的误判性,在此基础上,考虑前后运动的变化相邻帧的深度信息。当Kinect设备不动时,场景中的背景不会运动,而只有运动目标才会有深度信息上的变化。因此把序列图像中的相邻帧的深度信息的变化值也作为判定运动目标的依据。为了提高计算速度,在三帧差分法前需要把彩色图像转换为灰度图像

式中:ft-1(i,j),ft(i,j),ft+1(i,j)——图像中(i,j)在t-1、t和t+1时刻对应的前一帧、当前帧和后一帧。dt(i,j),dt+1(i,j)——相应像素点分别对应的深度值,mt(i,j)——连续三帧的变化图像,选择合适的阈值T1来判断前景和背景,Mt(i,j)就是根据公式获得的当前帧大致的ROI,如图2 (a)所示。由于图像中存在一些噪声点及漏洞,需要进行膨胀处理和连通区域面积分析。设定一个阈值,当连通的区域面积大于该阈值时,就认定检测到了ROI。当然,ROI也能直接进行图像分割,但是大多数都是基于阈值的方法[10-12],其通用性差。为了得到精确的抠效果,这里的粗ROI只为后续的粗前景掩膜提供区域信息。

图2 图像掩膜
1.2 粗前景掩膜
获得序列图像精准的三分图,需要对图像进行区域划分,进而从图像中抠出前景的区域。种子区域生长算法的核心问题是种子点的选择以及相似性判断准则。本文采用了改进的自动种子区域选取方法,即基于深度信息的自动选取算法。将上一步获得ROI区域位置映射到当前帧,选取映射区域范围中心位置点作为种子点,它能够反映关注目标的图像信息。同时也考虑像素的相似性和空间上像素的邻近性。具体的算法步骤如下:
步骤1 将前一步骤获得的粗ROI区域位置映射到当前帧,把相应区域中心位置的一个像素点作为初始种子点;
步骤2 判断相邻像素 (未标记)是否满足相似性准则;
步骤3 如果满足,则该邻域像素合并到种子区域,并给该点添加相应标记;
步骤4 对于新合并的区域,重复步骤2,步骤3;
步骤5 区域将在各个方向上不断增长,直到映射区域内没有多的像素点被合并,迭代结束
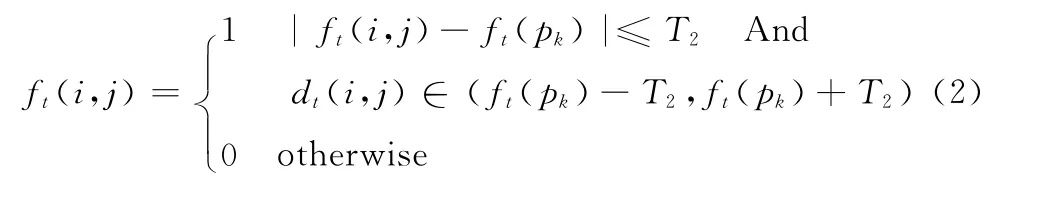
设像素点pk为前景点, (i,j)为与种子点相邻的像素。判定它属于前景区域的准则如式 (2)所示。(i,j)为前景点的条件不仅仅是该点与种子点亮度差值小于阈值T2,而且根据针对的视频场景,本文认为只要像素点的深度值变化值在一定范围内,就认为是前景点。所以设定了(i,j)的深度值要在(ft(pk)-T2,ft(pk)+T2)范围内。本文改进的自动种子区域生成算法,不但取消人工交互的过程,在降低了计算复杂度的同时,也避免了与前景颜色接近的背景而造成的抠像错误,最终得到粗前景掩膜。
1.3 三分图
考虑到分割误差、深度图包含有噪声以及自身精度的影响,前景边缘区域、前景和背景重合区域不能得到较好的处理。因此,对上述区域再处理,以得到一个包含前景、背景和未知区域的大致三分图。图2 (b)、图2 (c)是步骤3和步骤5所得结果。具体步骤如下:
步骤1 利用形态学操作对上一步操作得到的粗前景掩膜进行膨胀处理,前景边缘向外扩张,以便它能包括前景的所有边缘;
步骤2 使用Canny算子对扩大的前景掩膜提取边缘;
步骤3 由于前一步骤中提取的边缘有可能存在不连续,对边缘使用膨胀操作;
步骤4 将经过以上处理的前景掩膜和ROI区域进行逻辑与操作,去除掉背景区域的杂点;
步骤5 对前一步的结果进行两次腐蚀操作,3次膨胀操作,这样就得到了视频帧的三分图。
1.4 精前景掩膜
三分图中确定最精确的前景背景区域,扩大未知区域的范围。由于前景区域的透明度a 值为1,背景区域为0。剩余部分即为三分图的未知区域。以往的抠像算法,通过前景和背景再重建来求解未知区域的a 值,计算量巨大。为了提高视频抠像效率,文献 [7]采用了基于RGB 颜色空间的Shared Matting算法来完成未知像素的求解。它通过相邻像素间共享候选样点的方式来减少计算量。在计算最优前景和背景样本点对时,从每个像素出发,沿4条射线向外寻找,扩大采集范围,避免陷入局部最优。并且进行了平滑处理消除噪声干扰,获得较好的抠像结果。
本文对Shared Matting算法进行改进,在算法的区域扩张阶段,在与人类视觉一致的Lab颜色空间[6]中计算未知区域邻近像素的颜色相似性,进一步纠正粗三分图中未知像素点,提高了后续采样的效率,得到更好的抠像结果。采用Rhemann测试数据库[13]中的图像,Lab与RGB 颜色空间区域扩张个数和处理时间对比结果见表1。经过扩张后,统计图像中未知像素点的数量和扩张的处理时间,Lab颜色空间分别比RGB空间在像素个数上平均少约2%,在处理速度上快2.6%。图2 (d)是本文采用基于Lab颜色空间的Shared Matting算法得到的视频帧的精前景掩膜。
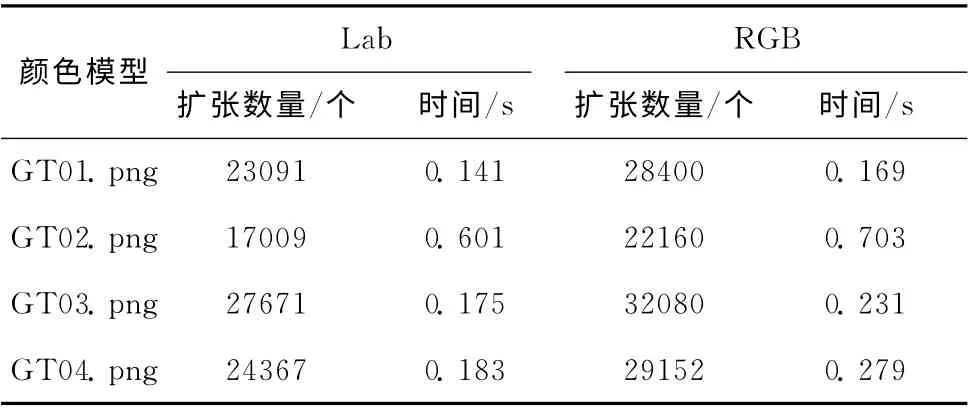
表1 Lab和RGB颜色空间处理对比
1.5 视频抠像的一致性
视频中序列图像,都会输出相应前景掩模并做标记。由于视频中前后帧之间有较强的相关性,掩膜信息在连续帧间传递,这样有助于检查视频连续帧前景掩膜信息一致性,有利于改进的视频抠像的整体性能和鲁棒性。例如,视频场景中的运动目标速度很慢,此时可能会检测不到ROI,这样粗前景区域提取时就没有可靠的种子点,从而获得不了三分图。或者视频场景中背景有和前景不相关的快速移动的物体。针对第一种情况,本文可以利用前一帧的前景掩膜信息区处理当前帧。对于第二种情况,利用深度信息的变化范围以及前后帧的相关性来判断抠像结果。
2 实验及分析
为了验证本文算法的性能。本文算法和同样利用深度和颜色信息的文献 [5]算法,分别从抠像效果、抠像准确率和抠像时间3个方面进行比较分析。实验平台配置是CPU为Intel CoreⅡ双核处理器、主频2.0GHz和RAM 2.0GB。以matlab7.0为开发环境,使用文献 [14]中 “Professor”,文献[15]中“Bellat”的测试集和自选3组Kinect视频。
从图3 (b)显示的抠像效果来看,当前景和背景颜色相近时 (“Professor”肤色、领带和背景颜色接近),文献[5]算法发生了部分图像缺失或者冗余。而本文结合颜色信息和深度信息,当前景和背景相似时,有前景区域的深度信息设定在一定范围内的辅助判断,能较好地解决上述问题,如图3 (c)所示。当视频场景比较复杂,人们往往对场景中运动目标比较感兴趣。例如,一个人在跳舞而另一个人保持不动 (如图4所示)。本文算法使用颜色信息,并且结合运动信息和深度信息,只是抠出显著运动的目标,而文献[5]是把两者都抠出 (长条方框中为不动目标)。在抠像细节方面,从图3连续三帧图像的抠像结果中可以看到,本文算法处理的结果明显优于文献[5]。
为了验证视频抠像结果的准确率,本文对视频抠像质量进行了定量的比较。即用查准率 (P)和查全率 (R)作为评价的准则,对标准图像的分割结果和正确分割结果进行比较。其中,查准率表示当前抠像结果中准确部分所占的比例,查全率表示当前抠像结果中准确部分在正确分割结果中所占的比例。它们分别定义为
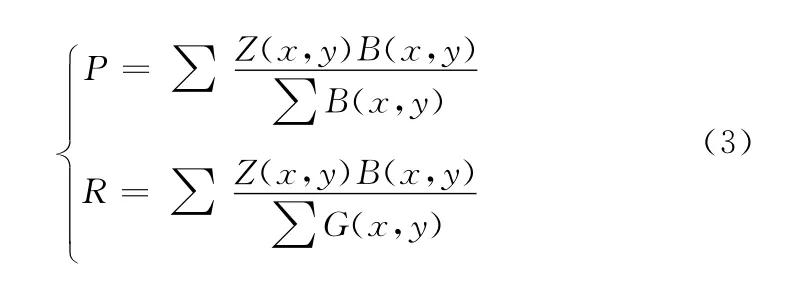
式中:Z(x,y)——正确的抠像结果,B(x,y)——抠像后得到的二值图像。比较结果如图5所示,由图中可见,本文算法的抠像效果较好,平均查准率和查全率均优于文献[5]算法。

图3 “Professor”第12、13和14帧抠像效果的比较

图4 “Bellat”第83帧抠像效果
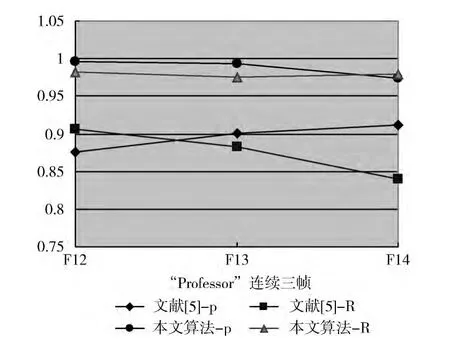
图5 查准率p和查全率R 对比
本文算法的运行时间由自动提取ROI时间、粗前景掩膜提取时间、生成三分图时间和视频帧精抠像时间组成。文献 [5]算法需要用户标记,多次交互才能完成最后的抠像,而本文算法是使用自动提取出视频帧中的ROI,大大节约了时间。两种抠像时间比较见表2,本文算法比文献[5]算法速度平均提高11倍。可以达到实时抠像效果。
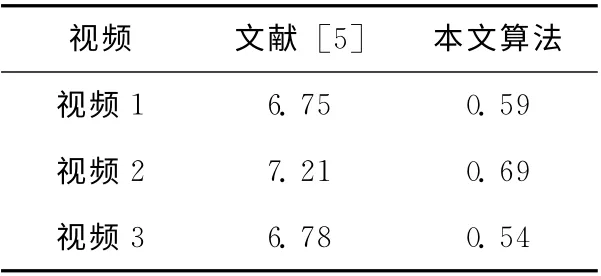
表2 Kinect视频集上本文算法和文献 [5]算法的时间比较/ (S/frame)
3 结束语
结合运动、深度和颜色信息,提出了一种基于Kinect的自动视频抠像算法。该算法对传统的视频抠像算法从4个方面进行了改进。针对抠像算法中人工交互频繁,抠像精度,计算速度等问题,利用改进的三帧间差分法自动检测到视频中的ROI;再结合深度图信息改进自动种子增长区域算法,估算出粗前景掩膜;通过数学形态操作和逻辑操作生成粗三分图;采用改进了的Shared Matting 算法,得到精确的视频帧抠像效果。实验结果表明,该算法精度高、速度快。对于大多数具有显著前景目标的视频得到较好的抠像效果。
[1]ZHANG Zhanpeng,ZHU Qingsong,XIE Yaoqin.The latest research progress on digital matting [J].ACTA Automatica Sinica,2012,38 (10):1571-1578 (in Chinese). [张展鹏,朱青松,谢耀钦.数字抠像的最新研究进展 [J].自动化学报,2012,38 (10):1571-1578.]
[2]Zhu J,Liao M,Yang R,et al.Joint depth and alpha matte optimization via fusion of stereo and time-of-flight sensor[C]//Proc of CVPR.Miami,USA:IEEE Press,2009:453-460.
[3]Levin A,Lischinski D,Weiss Y.A closed form solution to natural image matting [C]//Proc of CVPR.Minneapolis,USA:IEEE Press,2007:228-242.
[4]Cigla C,Alatan A A.Segmentation in multi-view video via color,depth and motion cues[C]//Proc of the 15th IEEE International Conference on Image Processing,2008:2724-2727.
[5]Kim S Y,Cho JH A Koschan,Abidi M A.Spatial and temporal enhancement of depth images captured by a time-of-flight depth sensor [C]//Proceedings of 20th International Conference on Pattern Recognition,2010:2358-2361.
[6]D’Angelo A,Dugelay J.A statistical approach to culture colors distribution in video sensors[C]//5th Int Workshop on VPQM,2010:13-15.
[7]Gastal E S L,Oliveira M M.Shared sampling for real-time alpha matting [J].Computer Graphics Forum,2010,29 (2):575-584.
[8]Steven Yantis.To see is to attend[J].Science,2011,29:54-55.
[9]WANG Xin,WANG Bin,ZHANG Liming.Airport detection based on salient areas in remote sensing images[J].Journal of Computer-Aided Design &Computer Graphics,2012,24 (3):336-344 (in Chinese).[王鑫,王斌,张立明.基于图像显著性区域的遥感图像机场检测 [J].计算机辅助设计与图形学学报,2012,24 (3):336-344.]
[10]Achanta R,Estrada F,Wils P,et al.Salient region detection and segmentation [C]//Proceedings of International Conference on Computer Vision Systems,2008:66-75.
[11]Achanta R,Hemami S,Estrada F,et al.Frequency-tuned salient region detection [C]//Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition,2009:1597-1604.
[12]ZHANG Qiaorong,JING Li,XIAO Huimin,et al.Image segamentation based on visual saliency [J].Journal of Image and Graphics,2011,16 (5):767-773 (in Chinese). [张巧荣,景丽,肖会敏,等.利用视觉显著性的图像分割方法[J].中国图象图形学报,2011,16 (5):767-773.]
[13]Rhemann C,Rother C,Wang J,et al.Alpha matting evaluation website[DB/OL].[2012-03-16].http://www.alphamatting.com.
[14]Mobile 3DTV research,video plus depth [DB/OL]. [2011-03-16].http://sp.cs.tut.fi/mobile3dtv/video-plus-depth.
[15]MSR video Sequences[DB/OL].[2014-03-06].http://research.microsoft.com/en-us/um/people/sbkang/3dvideodownload.
