关系型数据库数据的高效判重
2015-12-14李恒新韩坚华
李恒新,韩坚华
(广东工业大学计算机学院,广州510006)
随着互联网信息量的增加,处理海量数据成了迫切需要解决的问题. 但大量数据中存在数据相似或者重复的现象,如信访数据:某一热门问题不同社会公众的多次咨询,以及他们对投诉的处理不满或得不到答复的再投诉等等. 对这些信访业务相似数据的判重能够使政府工作人员及时发现信访人重复咨询、反复投诉的现象,为提高政府部门的服务效能发挥辅助作用.因此,有必要快速地检测出相似(相同)数据以达到判重的目的. 判重算法更多应用于网页检测领域,极少涉及到关系型数据库中的数据.但是这些数据也存在相似甚至重复的现象,对这类数据的处理也同样重要. 关系型数据库中的数据独具自己的特点:数据类型丰富,空值数据多,表模式不同等.因此,用什么方法快速地从关系型数据库中检测出相似数据成了本文研究的主要内容.
数据相似性检测可以用到以下几种主要的判重算法:DSC 算法(Shingle 算法)、DSC-SS 算法、IMatch 算法、Simhash 算法、VSM 模型、SCAM 算法布尔模型和中文特有的特征码索引方法等. 其中DSC算法全称Digital Syntactic Clustering,也就是有名的Shingle 算法,最初由Broder 等[1]提出.算法内容:一个长度为L 的文档,每隔N个汉字取一个Shingle(瓦片),一共截取了L-N +1个Shingle,一个很长的文档,其Shingle 会很多. 因此对于大文档来说运算量太大,可以考虑对Shingle 集合进行抽样,以降低空间和时间计算复杂性[2-3].
当不考虑Shingle 出现的位置和顺序,就有了IMatch 算法[4].I-Match 算法认为在文档中频繁出现的词并不会增加文档的语义信息,因此过滤掉这些重复次数较多的Shingle. 再计算出每个Shingle 的IDF(Inverse Document Frequency)值,根据IDF 值挑选比较重要的Shingle.累积这些Shingle 的hash 值,作为这篇文档的指纹特征值. 如果指纹特征值发生了冲突,则表示文档重复.
VSM 为常见的向量空间模型[5],统计文档中各个单词出现的次数. 然后按照倒排索引存储法存储文档和词频信息.将文档用关键词的特征向量表示.VSM 直接计算2个文档的特征向量的夹角余弦来度量相似性.
Shingle 算法的空间和计算复杂性高,相似性精度也高,适合数据量不大且对精度要求高的应用.而I-Match 算法依赖于语料库,缺乏深层挖掘文档本身的语义特征,不适合多领域内容的数据检测[6].VSM模型算法的前提是假设词与词之间是不相关的,但这种假设不现实,词与词之间往往存在语义相关,可能影响了算法的可靠性.
针对以上算法存在的缺点,目前的Simhash 算法对数据库数据的相似性检测是一种较好的去重算法.Simhash 算法能够根据数据内容的权重不同特征,转化为特征值的同时,根据特征值累积起来的差别大小来判断数据的差别程度.不过度依赖语料库,对海量数据集的相似性计算速度也较快,在计算性能方面上具有很大优势,并且文档特征值存储空间小.该算法是对大量数据库数据相似性检测的最佳选择.
本文采用的数据来自于广州市某区政府的信访业务综合信息汇集与处理平台,介绍并改进Simhash算法,提出一种高效处理指纹特征值的算法,并展示改进算法的时间效率和准确率.
1 Simhash 算法
1.1 Simhash 算法实现
Simhash 算法由Charikar[7]提出.算法的主要思想是降维,将高维的数据特征向量映射成一个f-bit的指纹(fingerprint),通过比较数据的f-bit 指纹的海明距离(hamming distance)来确定数据是否重复或者高度近似.
从数据库中提取出数据,作为Simhash 算法的输入,通过该算法计算得出数据的语义指纹值.算法的整体流程图见图1.wn代表数据中的词汇,经过字符串Hash 函数分别计算出二进制特征值,再把这些特征值累加,正数取1,负数和零取0,重新构成了一个代表这整个数据的特征值,称为指纹特征值.
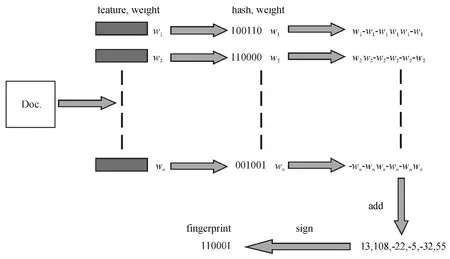
图1 Simhash 算法流程图Figure 1 Flowchart of Simhash algorithm
Simhash 算法自身携带的字符串Hash 函数具有冲突高、速度慢的缺点. 另外,如果对数据库不同字段值的数据同等对待处理,会造成相似性检测精确度低的现象,所以提出采用改进的Simhash 算法.
1.2 改进的Simhash 算法
首先,不同的特征值赋予不同的权重.针对数据库数据,小文本字段值赋予较大权重,大文本采用词频作为权重,以使产生的指纹值更能代表数据特征.
其次,Simhash 算法最后产生的代表数据特征的指纹值S,其维度可以有32 位、64 位和128 位等.一般维度越大,计算也就越复杂,好处就是数据差异性更能体现出来.为了在复杂性和高效性间做平衡,指纹值S 的维度设为64 位较合适.
最后,针对指纹值S 的维度为64 位,选择一种字符串Hash 函数尤为重要. 算法中,对每个特征值的计算要用到字符串Hash 函数,可见,这个字符串Hash 函数是Simhash 算法的核心,选择字符串Hash函数是使Simhash 算法高效最为关键的一步. 传统的字符串Hash 函数有不少,比如BKDRHash、APHash、DJBHash、JSHash 和RSHash 等. 但是这些字符串Hash 函数都是运行在32 位系统上的算法,稍加改动,也能运行在64 位系统上,不过效率必定打了个折扣.为了更好地产生64 位Hash 值,Austin Appleby 创立了一种非加密 Hash 算法:MurmurHash[8].MurmurHash 的最新版本是MurmurHash 3,支持32 位、64 位及128 位值的产生,并在多个开源项目中得到应用,包括Libstdc、Libmemcached、Nginx、Hadoop 等.受MurmurHash 的启发,Google 发布了CityHash 字符串散列算法. 该算法比MurmurHash 略快,比传统Hash 算法快30% 以上[9].CityHash 计算的过程很繁杂,但是充分利用了64 位系统硬件的性能,因此能得到较快的速度[10]. 本文采用CityHash 算法研究Simhash 算法,在64 位计算机上计算每个特征值的Hash 值,同时和采用其他字符串Hash 函数的Simhash 算法做比较,验证了改进后的Simhash 算法的快速性.
2 针对64 位指纹特征值的快速处理
指纹特征值的比较一般用海明距离来表示.所谓的海明距离,就是指2个二进制数对应比特位不同的个数.对于2个指纹特征值x =(x1x2x3…xn)和y=(y1y2y3…yn),海明距离计算公式为:
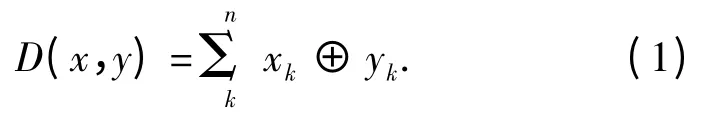
海明距离越小,说明数据内容越相似. 对于64位指纹特征值相似性的检测,阀值HD 一般设为3,也就是说海明距离小于等于3 的话,数据就相似.
对所有的数据都进行判重处理,称为集中处理.在旧数据已处理过的前提下,单独对新加入的数据判重处理,可称之为增量处理.大数据下的集中处理耗时较长,非常有必要改进处理的方式,以提高处理的速度.本文根据特征指纹值的特点,采用索引归类方法来提高全部数据集中处理的速度,大大缩短了处理的时间. 对于增量处理,采用MongoDB 数据库来存储指纹值,新加入的指纹值可以很快比对旧指纹值,从而判断出是否为重复数据. 在处理的速度上,比传统关系型数据库快.
2.1 集中处理
对所有指纹特征值的判重.传统做法多采用聚类算法.文献[11]所采用的Single-Pass 算法属于聚类算法中的层次凝聚算法. 大体思想就是认为所有的个体都是一个单独的类,类与类之间进行比较,相似的合并成一类,如此循环,直到满足条件且都不能再合并为停止运行条件. 这个算法运用在指纹值的比较上,当设置低相似阀值或者所有指纹相似度高的时候,该算法能有较高性能.最好的时间复杂度为O(n).指纹相似度不高时,最差的时间复杂度能达到O(n2).
上述的算法如果用在大规模的数据处理上,性能将会非常低下.考虑到阀值HD 为3 即数据就相似的特点,采用索引归类的方法,速度就会得到提升.
64 位二进制指纹值分为4 块,每块16 位.根据鸽巢原理,要海明距离为3,则一定有1 块是相同的.把每一块的值都作为索引值,按索引值进行归类存储.例如一个64 位指纹值Q1Q2Q3Q4,Qn代表第n类由16 位构成的索引值.那么这个指纹值就可以分别存入索引值为Q1的第1 类中,索引值为Q2的第2 类中……16 位二进制的索引值,能产生的索引为216个. 一个指纹值根据对应的索引值需要存储4次,但只需找到对应索引,然后和索引里面的指纹做比较就可以了,比较次数大大减少.建立索引流程如图2 所示.
假设数据量足够大,有F个指纹值,当F=2n(n>34),那么F 就会超过10 亿个. 按索引归类进行存储,需要存储4F个指纹值,每个类中的每个索引平均需要存储S =F/216=2n/216=2n-16个指纹值,新加入的指纹需要在4个类中都进行比较,大概需要比较4S 次.假如不采用这种算法的话,需要比较F 次(大于10 亿).两者对比,计算量减少到原来的当然,跟前面的算法比较,存储空间多了4 倍,可是比较次数却大大减少,是一种以空间换时间的策略.

图2 索引建立图Figure 2 Figure of indexing
2.2 增量处理
用数据库存储集中处理后的特征指纹值.较为传统的做法就是把这些值与值对应的数据信息存储到关系型数据库中的一张表中.根据上节理论分析,用象限值作为索引,可以加快查找速度.表模式见表1.

表1 特征指纹值表模式Table 1 Table mode of fingerprint feature value
可以预见,当数据量非常大时,表的规模也会很大,查找的时间将会延长,造成分析检测用时过长,无法达到快速检测的目的.
MongoDB 是一种面向文档存储的数据库,具有强大、灵活和可扩展的功能[12].文档以类似JSON 格式来进行存储,对某些字段建立索引,可以实现关系型数据的某些功能. 指纹特征值是先按象限值查找进而再作比较.因此,我们可以把一个象限值内装的所有指纹特征值作为一个“文档”来存储,这个“文档”相当于一个索引,索引下的全部特征指纹值构成了一个集合.
MongoDB 是一种表模式自由的数据库,因此不用设计表的结构.根据上面的设计,我们将以下面的方式来存储特征指纹值:
"blockName" :"象限值";
"info" :[{"hashcode" :"指纹特征值1","textname" :"数据名称1"},{"hashcode" :"指纹特征值2","textname" :"数据名称2",…}]}.
类似JSON 的格式,很简单就表示了所有象限值和对应的指纹特征值. 在查找的速度上优于关系型数据库.当不管检测的结果是否有相似数据,都执行插入新增数据操作时,MongoDB 所耗时间也少于传统关系型数据库,因差别不大,所以不再做实验分析.
3 结果与分析
算法采用Java 语言实现,采用平台中的数据库信访表作为分析对象.此表具有多个字段,有些字段值为空,其中信访内容为大文本,没有空值.除了大文本,其他字段值都赋予2 的权重.大文本经过分词工具处理,词频作为权重.该分词工具为IKAnalyzer 2012,该工具具有160 万字/s 的高速处理能力,同时支持自定义的扩展词汇表和停用词汇表. 在扩展词汇表里面加入了搜狗语料库. 停用词汇表加入一些语气助词等,以使分词更为精确.
实验软硬件环境为Intel(R)Core(TM)i7-4500U CPU@2.4 GHz,内存为8 G,操作系统为64位windows8.1,编程工具为IntelliJ IDEA 13.0.2,采用Java7.
为了评价改进后的Simhash 算法执行效率和正确性,本文设计了一系列实验,其中,实验1、实验2是对算法的时间效率和正确性进行验证,实验3 是关于特征指纹值的集中处理以及增量处理实验.
3.1 算法的时间效率
指纹特征值是对数据中词汇特征值总和的表现.Simhash 算法采用不同的字符串Hash 函数对相等的数据量会有不同的时间效率. 时空性是衡量一种算法是否得到有效改进的重要指标之一.因此,分别对原有字符串Hash 函数的Simhash 算法和改进后的Simhash 算法进行了对比实验.
其中,在官方提供的Simhash 算法实现中,包含有自带生成64 位二进制值的字符串Hash 函数. 另外,BKDRHash 字符串函数是32 位Hash 函数的优秀代表,在字符串生成的过程中作了改进,使它能对字符串产生64 位Hash 值,并应用于Simhash 算法.最后我们用CityHash 字符串函数改进Simhash 算法,因为是运行在64 位计算机上,理论上时间效率应该是最高的.实验数据为三万条信访记录,数量从少到多都进行了测试.实验结果如表2 所示.

表2 不同Hash 函数下的Simhash 算法时间性能Table 2 Time performance of the Simhash algorithm in different Hash function
从表格数据可以看出,改进后的Simhash 算法对同样数量的数据生成指纹值耗时更少.采用32 位BKDRHash 函数改进的Simhash 算法比自带的快,而采用CityHash 字符串函数的Simhash 算法在时间效率上最优. 可见改进过的Simhash 算法都提高了处理的速度,具有更快的性能.以下实验所说的改进Simhash 算法都是指采用CityHash 字符串函数的Simhash 算法.
3.2 算法评估
采用经典的信息检索度量标准来评估算法:召回率和准确率,定义如下:

选择“教育”、“城市管理”和“城乡建设”三个主题.评估改进后的Simhash 算法,每个主题分别在数据库的信访表里找出多组相似数据,共计300 条,作为测试之前已知相似数据量. 然后混合到5 000条不相似混杂内容数据中. 分别运行I-Match 算法、官方提供的Simhash 算法和改进后的Simhash 算法进行相似数据检测. 检测结果为测试找出的相似数据量,在这些数据量中与已知的300 条相似数据吻合的就为测试正确的相似数据量.结果见表3.

表3 各算法的评估结果Table 3 Evaluation results of the algorithms
改进后的Simhash 算法在各类数据的判重中具有较高的召回率(约90%)和准确率(95%左右),都源自于携带的低冲突率CityHash 函数算法.I-Match 算法在城市管理版块表现出较高的召回率.这主要是因为本实验采用的搜狗语料库中有不少日常词汇,所以在该版块中,I-Match 算法表现出了较好性能.但在其他2个版块,召回率都有所下降. 这说明了I-Match 算法具有领域相关的缺点. Simhash算法基于所有词汇来构建指纹特征值,因此与语料库的关系没有I-Match 算法的大,召回率相对稳定.
3.3 指纹特征值的处理分析
指纹特征值的匹配是找出相似文档的最后一步骤.先做集中处理的实验,也就是一次性处理所有的数据.用Single-Pass 聚类算法来找出相似数据,再针对64 位指纹值和海明距离小于等于3 就归为相似的特点,用了索引归类的方法,理论上效果应该大大提高.实验在不同数据量下分别运行这2 种算法.
从表4 的结果看,在少量数据的前提下,Single-Pass 聚类算法所耗费的时间和索引归类相比就已经有差距了,这种差距随着数据量的增加呈几何级地增长.当需一次性处理大量数据时.索引归类算法无疑是最好的选择.
索引归类处理后的特征指纹值可以存储到数据库中.实验中分别存储到了关系型数据库MySQL 和NoSQL 数据库MongoDB.增量处理又可分为2 种:一种只是判断与历史数据是否有相似的情况,一种就是判断有相似数据的前提下返回所有的相似特征指纹值,以便进一步的分析需要.在大量不同的新增数据处理前提下对处理时间做了平均值,以使实验结果更趋于准确(表5).

表4 指纹特征值处理所耗时间表Table 4 Characteristic value of fingerprint processing cost schedule ms

表5 不同数据库下增量处理所耗费的时间Table 5 The cost processing time in the different database by incremental processing ms
MongoDB 数据库处理的速度比MySQL 数据库快,主要是因为MongoDB 本身的高性能和面对文档存储的特性非常符合指纹特征值按象限存储的要求,提高了对增量数据的处理速度.
4 结论
针对传统关系型数据库数据的特点,应用改进后的Simhash 算法来计算出每行数据的指纹特征值,再用设计好的索引归类方法一次性找出所有的相似数据,即使是新增数据,也能得到快速的处理.纵观整个过程,时间效率和准确率都高于其他算法.在后续的研究中还需进一步优化分词效果,减少数据的噪声,以提高Simhash 算法的召回率. 此外,可进一步探索在分布式环境下应用该算法,在大数据的前提下,使速度再一次得到提升.
[1]Broder A Z,Glassman S C,Manasse M S,et al. Syntactic clustering of the web[J]. Computer Networks and ISDN Systems,1997,29(8-13):1157-1166.
[2]Broder A Z. On the resemblance and containment of documents[C]∥The compression and complexity of sequences. New York:IEEE Computer Society,1997:21-29.
[3]Han B,Keleher P. Implementation and performance evaluation of fuzzy file block matching[C]∥Proceeding of the 2007 usenix annual technical conference. Berkeley:Usenix Association,2007:199-204.
[4]Chowdhury A,Frieder O,Grossman D,et al. Collection statistics for fast duplicate document detection[J]. ACM Transactions on Information Systems,2002,20(2):171-191.
[5]Salton G,Wong A,Yang C. A vector space model for automatic indexing[J]. Communications of the ACM,1975,11:613-620.
[6]曹玉娟,牛振东,赵堃,等. 基于概念和语义网络的近似网页检测算法[J]. 软件学报,2011,22(8):1816-1826.Cao Y J,Niu Z D,Zhao K,et al. Near duplicated web pages detection based on concept and semantic network[J]. Journal of Software. 2011,22(8):1816-1826.
[7]Charikar M S. Similarity estimation techniques from rounding algorithms[C]∥Proceedings of the 34th annual ACM symposium on the theory of computing. New York:ACM,2002:380-388.
[8]Tanjent. MurmurHash,final version[EB/OL]. (2008-03-03)[2014-08-13]. http:∥tanjent. livejournal.com/756623.html.
[9]Josh Haberman. State of the hash functions[EB/OL].(2012-01-29)[2014-08-13]. http:∥blog. reverberate.org/2012/01/state-of-hash-functions-2012.html.
[10]陆阳,高宝. 基于CityHash 的政务网站完整性检查方法研究[J]. 计算机工程与应用,2014(6):1-6.Lu Y,Gao B. Research on file integrity checking based on CityHash for e-government websites[J]. Computer Engineering and Applications,2014(6):1-6.
[11]李纲,毛进,陈璟浩. 基于语义指纹的中文文本快速去重[J]. 现代图书情报技术,2013(9):41-47.Li G,Mao J,Chen J H. Fast duplicate detection for chinese texts based on semantic fingerprint[J]. New Technology of Library and Information Service,2013(9):41-47.
[12]Chodorow K,Dirolf M. MongoDB:The definitive guide[M]. 2nd Ed. Sebastopol:O'Reilly Media,Inc,2013:1-3.
