基于Apriori算法的高危人群2型糖尿病预测研究
2015-12-05于启炟
韦 哲 于启炟 辛 迈③
基于Apriori算法的高危人群2型糖尿病预测研究
韦 哲①②于启炟②辛 迈②③
目的:利用数据挖掘中的关联规则,为及早地在高危人群中发现和预防糖尿病。方法:选择兰州某大型三甲医院的323例2型糖尿病及IFG、IGT患者的首次病程记录,采用Apriori算法和SPSS Clementine 12软件设计,建立2型糖尿病的预测模型。结果:共形成10条强关联规则,其中蕴含着与2型糖尿病相关的一些因素之间的关联关系。结论:通过这些关联规则以实现对糖尿病高危人群简便而准确的初判断。
数据挖掘;Apriori算法;关联规则;糖尿病,2型
[First-author’s address] Lanzhou General Hospital PLA Lanzhou Military Command, Lanzhou 730050, China.
糖尿病(diabetes mellitus,DM)已成为世界性疾病,据世界卫生组织(WHO)报道,目前全球已有DM患者1.75亿,2025年将达到3亿,而更严重的是与DM相关的病死率在过去的12年内增加了30%,全球DM相关的死亡人数为每年320万[1]。随着人们生活方式的巨变和生活水平的提高,DM发病年龄呈现低龄化,我国的DM患病率急剧增加。近5年的流行病学调查显示,在我国经济发达地区DM的患病率已高达9%~10%[2]。DM患者的平均寿命较非DM者少15年。因此,DM的早期发现和早期治疗具有非常重要的意义。
本研究利用数据挖掘中的关联规则,在DM患者首次病程记录的基础上,研究简单易测(在家中获得检测数据)的关联因素与2型糖尿病之间的关系,利用其规则使DM高危人群能够及时准确地对自身情况做出初步判断。首次病程记录为患者进入医院后未经过任何治疗措施的真实记录,在对2型DM高危人群的预测中比一般的电子病历更具有普遍意义,本方法的先进意义就在于此。
1 Apriori算法基本概念
Apriori算法是一种最有影响的挖掘关联规则频繁项集的算法,其核心是基于两阶段频繁集思想的递推算法。其中,所有支持度大于最小支持度的项集称为频繁项集,简称频集(使用递推的方法生成所有频集)[3]。Apriori(先验的,推测的)算法,其基本思想是首先找出所有的频集,这些项集出现的频繁性至少和预定义的最小支持度一样,然后由频集产生强关联规则(即同时满足最小支持度阙值和最小置信度阙值的规则称为强关联规则),这些规则必须满足最小支持度和最小置信度,然后应用所找到的频集产生期望的规则,产生只包含集合的项的所有规则,一旦这些规则被生成,则只有那些支持度和置信度分别大于用户所给定的最小支持度和最小置信度的关联规则才能留下来。利用Apriori算法对数据进行分析能够高效的产生频繁项集,从而生成强关联规则,发现隐藏在数据间的相关性。
为了生成所有频繁项集,Apriori算法使用了递推的方法[4]。其核心思想为:首先产生1-项集(L1),然后是频繁2-项集(L2),直到有某个r值使得Ly为空,这时算法停止。在第k次循环中,其过程先产生候选k-项集的集合Ck,Ck中的每个项集是对两个只有1个项集不同的属于Lk-1的频集做1个(k-2)连接而产生的[5]。Ck中的项集是用来产生频集的候选集,最后的频集Lk必须是Ck的一个子集。Ck中的每个项集需在数据库中进行验证来决定其是否加入。
2 信息资料的提取
本研究信息资料提取于兰州某大型三甲医院医学信息数据库,其中包括2009年1月至2014年3月2型DM、空腹血糖受损(impaired fasting glucose,IFG)及糖耐量受损(impaired glucose tolerance,IGT)患者的首次病程记录,信息数据为患者住院号、性别、年龄、既往病史、家族病史、饮食习惯、职业及生理数据等指标。研究中病程指标为:①以空腹血糖≥7.0 mmol/L或餐后2 h血糖≥11.1 mmol/L为DM;②空腹血糖<7.0 mmol/L或餐后2 h在7.8~11.0 mmol/L为IGT;③空腹血糖在6.1~7.0 mmol/L或餐后2 h血糖<7.8 mmol/L为IFG[7]。
根据世界卫生组织(WHO)最新标准,DM高危人群的定义为:①年龄≥45岁且常年不参加体力活动;②体质量指数≥24 kg/m2;③以往有IGT或是IFG;④有DM家族史;⑤有高密度脂蛋白胆固醇降低或三酰甘油血症;⑥有高血压或是心脑血管病症;⑦年龄≥30岁的妊娠妇女[8]。
3 关联因素与2型DM之间的相关性挖掘
3.1 数据预处理
本研究根据数据挖掘专业知识对数据进行预处理,使数据记录量和特征属性的数量达到研究要求[9]。预处理过程分为2步:①数据选择,从首次病程记录中提取出性别、文化程度及创伤史等方面的信息。考虑到患者的姓名、出生年月及住院号等信息与本次研究关系不大,可以直接去掉。经过删减的部分数据如图1所示;②数据变换,按照数据挖掘中关联分析的要求将本研究的数据转变成布尔型的二值数据, 经过量化后得到的部分数据如图2所示。

图1 删减后的患者部分数据电脑截图

图2 量化处理后的患者部分数据电脑截图
有些属性很容易量化,如性别中男性可设置为1,女性可设置为0;饮酒可用1代表平时饮酒,0代表平时不饮酒。但有些属性则需要分段,然后再进行相应的量化,如患者的文化程度以初中为标准,初中以下属于低文化水平用0表示;而初中及以上属于高文化水平,用1表示。对于性格的量化,采用的方式为能控制自己情绪的用1表示,其他均用0表示。对于身体质量指数(body mass index,BMI)的量化,采用的方式为BMI<24 kg/m2的属于正常用0表示,BMI>24 kg/m2的属于肥胖用1表示。对于腰臀比(waist-hip ratio,WHR)的量化,采用的方式为男性WHR>0.8的用1表示,女性WHR>0.85的用1表示,其余均用0表示。
3.2 数据挖掘模型
利用Apriori算法,在Clementine下建立的数据挖掘模型,针对本次挖掘任务所设计流。流中将“数据源.xls”作为源文件节点,添加过滤节点和类型节点建立库与模型间的数据传输,最后将Apriori算法执行模型和图形节点填入流中[10](如图3所示)。
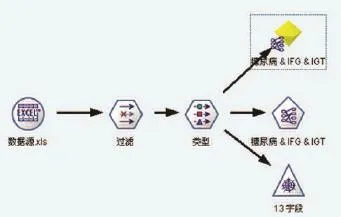
图3 基于Apriori算法的关联规则挖掘模型图
4 结果
在进行关联分析时发现,当设置的最小支持度阙值为minsupport=0.10,最小置信度阙值为minconfidence=0.70时得到的关联规则最佳,如果关联规则的最小支持度和最小置信度不满足事先设置最小支持度和最小置信度的要求,则会被“剪枝”处理,最终得到结果如图4、图5所示。

图4 模型-数据挖掘部分结果示图
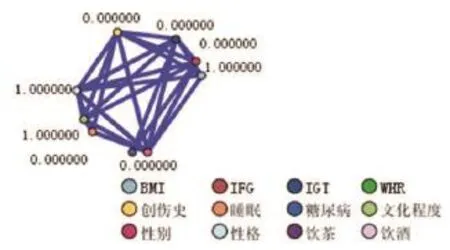
图5 图形-数据挖掘结果示图
本研究中图4、图5显示:①男性人群中喝酒是造成DM的一个危险因素,女性人群中肥胖是造成DM的一个危险因素,其中女性DM患者的BMI和WHR指数普遍超标;②在最后的结果中并没有看见“运动”这个因素,表明DM患病人群在平时的生活中坚持锻炼的人数非常少,提示应加强DM的预防与教育工作,使公众对DM不再陌生和轻视,患者要改变平时不利于DM健康的行为,形成高度的自我管理模式;③本研究中“创伤史”这个因素因为支持度低于预设值而被删减,表明大量的DM患者是近年来随着生活水平的改善而新增加的;④饮茶也可能导致DM,这个因素常常被患者所忽略;⑤本研究未考虑季节性对DM的影响,在后续的研究中会增加此项内容。以上结论与实际情况基本相符。
5 结论
关联分析的目的是找出数据库中隐藏的关联网,是对数据库中数据之间相关性的一种描述,基于关联分析的计算机辅助医学数据挖掘系统能够对现有病历数据库中数据进行自动分析并提取有价值的知识,尤其适合DM的流行病学分析和全民健康评估。因此,Apriori算法与社区医疗和医院信息系统结合是未来的发展方向。本研究尝试将数据挖掘算法引入DM的发病规律研究中,期望从大量的DM数据中发现该病的发病规律,挖掘出有意义的规则,使高危人群能从这些规则中对自身的情况做出相应的判断,引起自身足够的重视并做出相应的调整,从而达到预防DM的目的。
[1]Gülçin YE,Karahoca A,Uçar T.Dosage planning for diabetes patients using data mining methods[J]. Procedia Computer Science,2011,3:1374-1380.
[2]李武成,王官权,金科.2型糖尿病并发高血压的危险因素分析[J].实用医学杂志,2010,26(17):3180-3181.
[3]刘敏娴,马强,宁以风,等.基于频繁矩阵的Apriori算法改进[J].计算机工程与设计,2012,33(11):4235-4239.
[4]李良,米智伟,向新.基于FP-Growt的战略绩效关联分析算法研究[J].微计算机应用,2011,32(2):1-8.
[5]Goethals B.Surveyon frequent pattern mining,HUT basic research unit[D].Helsinki:Department of Computer Science,University of Helsinki,2003:1-43.
[6]Patil BM,Joshi RC,Toshniwal D.Association rule for classification of type-2 diabetic patients[C].2010 Second International Conference on Machine Learning and Computing,2010:34-38.
[7]胡艳文,申红.2型糖尿病及其并发症QT期间及离散度变化的临床意义[J].贵州医药,2007(5):542-543.
[8]张翠丽,高晓红,李晓枫,等.2型糖尿病发病高危因素的分析[J].大连医科大学学报,2005,27(2):99-100.
[9]严刚.中医数据挖掘中数据预处理方法研究[J].辽宁中医杂志,2010,7(11):2144-2147.
[10]元昌安,邓松.李文敬,等.数据挖掘原理与SPSS Clementine应用宝典[M].北京:电子工业出版社,2009.
Study on prediction of high risk group of Type 2 diabetes based on Apriori algorithm
WEI Zhe, YU Qi-da, XIN Mai// China Medical Equipment,2015,12(1):45-47.
Objective: To discover and prevent diabetes early in high-risk group. Methods: Chose 323 records of type 2 diabetes or IFG,IGT patients with first course which come from a large hospital in Lanzhou between 2009 January to 2014 March; Use Apriori algorithm and the SPSS Clementine 12 software design; Set up prediction model of type 2 diabetes. Results: A total of 10 strong association rules are formed. The strong association rules contain some associations between factors and type 2 diabetes. Conclusion: Through the association rules, the initial judgment on the high-risk group of diabetes is simple and accurate.
Data mining; Apriori algorithm; Association rules; Diabetes mellitus, type 2
韦哲,男,(1963- ),博士,高级工程师。兰州军区兰州总医院医学工程科,从事医学信息检测和处理方面的研究工作。
1672-8270(2015)01-0045-03
R197.324
A
10.3969/J.ISSN.1672-8270.2015.01.014
2014-05-28
①兰州军区兰州总医院医学工程科 甘肃 兰州 730050
②兰州理工大学电气工程与信息工程学院 甘肃 兰州 730050
③解放军94804部队 上海 200000
