Feature Selection by Merging Sequential Bidirectional Search into Relevance Vector Machine in Condition Monitoring
2015-11-01ZHANGKuiDONGYuandBALLAndrew
ZHANG Kui*, DONG Yu, and BALL Andrew
1 School of Economics & Management, Wuhan Polytechnic University, Wuhan 430023, China2 School of Information Engineering, Communication University of China, Beijing 100024, China3 School of Computing & Engineering, University of Huddersfield, Huddersfield, HD13DH, UK
Feature Selection by Merging Sequential Bidirectional Search into Relevance Vector Machine in Condition Monitoring
ZHANG Kui1,*, DONG Yu2, and BALL Andrew3
1 School of Economics & Management, Wuhan Polytechnic University, Wuhan 430023, China
2 School of Information Engineering, Communication University of China, Beijing 100024, China
3 School of Computing & Engineering, University of Huddersfield, Huddersfield, HD13DH, UK
For more accurate fault detection and diagnosis, there is an increasing trend to use a large number of sensors and to collect data at high frequency. This inevitably produces large-scale data and causes difficulties in fault classification. Actually, the classification methods are simply intractable when applied to high-dimensional condition monitoring data. In order to solve the problem, engineers have to resort to complicated feature extraction methods to reduce the dimensionality of data. However, the features transformed by the methods cannot be understood by the engineers due to a loss of the original engineering meaning. In this paper, other forms of dimensionality reduction technique(feature selection methods) are employed to identify machinery condition, based only on frequency spectrum data. Feature selection methods are usually divided into three main types: filter, wrapper and embedded methods. Most studies are mainly focused on the first two types, whilst the development and application of the embedded feature selection methods are very limited. This paper attempts to explore a novel embedded method. The method is formed by merging a sequential bidirectional search algorithm into scale parameters tuning within a kernel function in the relevance vector machine. To demonstrate the potential for applying the method to machinery fault diagnosis, the method is implemented to rolling bearing experimental data. The results obtained by using the method are consistent with the theoretical interpretation, proving that this algorithm has important engineering significance in revealing the correlation between the faults and relevant frequency features. The proposed method is a theoretical extension of relevance vector machine, and provides an effective solution to detect the fault-related frequency components with high efficiency.
feature selection, relevance vector machine, sequential bidirectional search, fault diagnosis
1 Introduction*
The increasing complexity of machinery systems causes the data used to represent a system more complex. The representation of system condition often relies on the data with up to 40 variables, sometimes even hundreds and thousands of variables, and the data often come from a variety of sensors. However, the number of samples is limited due to the workload of data acquisition. Such high-dimensional data with small sample sizes makes pattern classification methods suffer from the ‘curse of dimensionality'. Many classification algorithms such as Radial Basis Function(RBF) networks[1], Support Vector Machine(SVM)[2-3]and k-Nearest Neighbour(k-NN)[4-5]are intractable when the number of features in the data is sufficiently large. This problem is further exacerbated by the fact that many features in a learning task may either be irrelevant or redundant to other features with respect to predicting the class of an instance.
To process such high-dimensional data, engineers have to resort to dimensionality reduction techniques. As one of dimensionality reduction methods, feature extraction methods have been widely applied to fault diagnosis, for example, principal component analysis(PCA)[6-7],independent component analysis(ICA)[8-9], self-organizing manifold learning(SOML)[10]and time-frequency distribution(TFD) matrix factorization method[11]etc. However, the choice and exploitation of all these methods demand intensive knowledge of statistics and experience of engineering data processing. Moreover, the new features transformed by feature extraction methods have lost the engineering meaning of the original features, which prevents engineers from understanding the essential correlation between features and machinery condition[12]. Therefore, other dimensionality reduction methods called feature selection are explored in fault diagnosis.
Feature selection methods can be divided into three main types[13]: filter, wrapper and embedded methods. Filters totally ignore the effects of the selected feature subset on the performance of classifier, independent of the chosen predictor[14]. Wrappers conduct a search for a good subset using the prediction algorithm itself as part of the evaluation[15], but regardless of the chosen learning machine. Embedded methods incorporate variable selection as part of the training process and are usually specific to given learning machines. The feature selection methods widely used in fault diagnosis are mainly focused on the first two types, for example, ant colony algorithm[16], global geometric similarity scheme[17]and genetic algorithm(GA)[18]. However, the embedded methods can make better use of the available data and reach a solution faster than other two methods[13]. Therefore, a novel embedded feature selection algorithm called RVM-SBidirS is proposed in this study to select optimal features by merging sequential bidirectional search(SBidirS) method into scale parameter tuning within a kernel function in the relevance vector machine(RVM). It will give a notable fact that it not only can be readily understood by field engineers who are not familiar with statistical methods, but it can be applied to high-dimensional data processing with high efficiency. As a consequence, the goal of fault diagnosis with lower computational cost, less storage space and improved prediction performance can be achieved.
This paper is organized as follows. Section 2 begins with an introduction to the RVM model and then follows a structured analysis of the extended RVM for feature selection based on scale parameter tuning theory within a kernel function. Following a brief review on feature selection algorithms, section 3 explores a novel feature selection algorithm by merging SBidirS into scale parameter tuning to achieve the goal of feature selection with high accuracy in classifier performance. In section 4, a case study is presented aiming to demonstrate the advantages of the algorithm in processing high-dimensional condition monitoring data. The final section contains a summary of the paper and a look towards future work.
2 Extended RVM for Feature Selection
RVM has been successfully applied to a number of applications as a classifier or regressor[19-22]since its introduction by TIPPING in 2000[23]. The key feature of this approach is that the inferred predictors are particularly sparse in that the majority of weight parameters are automatically set to zero during the learning process. However, it does not yet appear to have been exploited in feature selection, especially for high-dimensional data with redundant features. Therefore, feature selection becomes a potential topic to extend the RVM performance. TIPPING gave a suggestion for dealing with irrelevant input variables by tuning multiple input scale parameters within kernels,for example, the input width parameters of the Gaussian kernel[23]. TIPPING also attempted to realize it by using conjugate gradient methods, i.e., a joint nonlinear optimization over hyperparameters and scale parameters. However, he admitted that such an automatic optimization over hyperparameters and scale parameters is computationally demanding, and it is impractical when applied to complicated high-dimensional data processing. Therefore, the RVM-SBidirS algorithm is proposed in this paper to select optimal features by applying the SBidirS method to scale parameter selection within a kernel function in the RVM.
2.1 RVM model with single scale parameters
In this section, an insight into the standard algorithm of the RVM classifier with single scale parameters within a Gaussian kernel function is given aiming at further analysis of the feature selection method based on multiple scale parameters in section 2.2.
Given an input set x=[ x1, x2,…, xM]T(x ∈ RD) with xm=[ xm1, xm2,…, xmD] (m=1, 2,…, M, and D is the number of features), the supervised learning is to attempt to construct the classifier function y that can map training vector x′=[ x1′, x2′,…, xN′ ]Twith xn′=[ xn1′, xn2′,…, xnD′ ](n=1, 2,… , N) onto corresponding target t=[t1, t2,…,tN]T, i.e., to estimate the weights w=[ w1, w2,…, wN]Tthat maximize the likelihood of the training set.
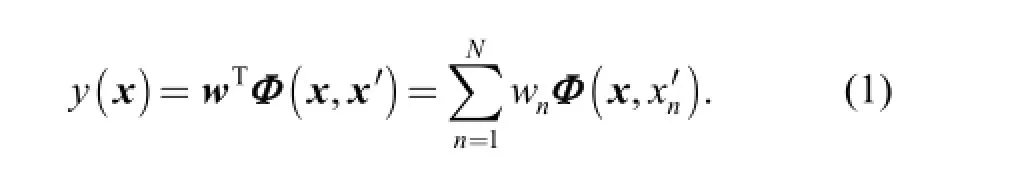
The basis function Ф(x, x′) is M×N design matrix with Ф (x, xn′)=[ Ф(x1, xn′), Ф(x2, xn′),…, Ф(xM, xn′) ]T. In this case it is chosen as Gaussian kernel centered on each of the training points:
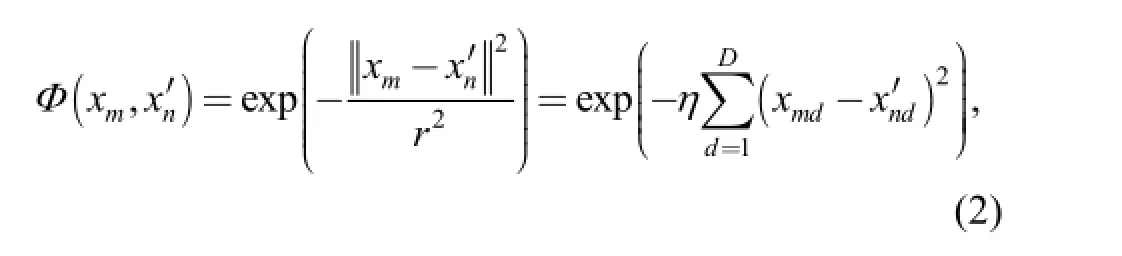
where r is input scales parameter and η=1/r2. It is worth pointing out that η (or r) is the same for all variables.
The model assigns an individual hyperparameter αnto each weight wn. According to the Bayesian theorem, the posterior probability of w is
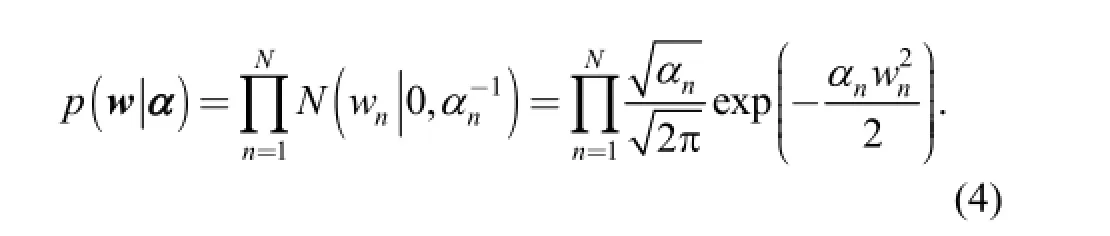
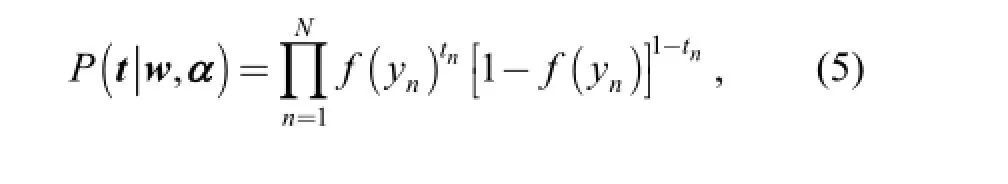
where f (y)=1/(1+exp(-y)) is the logistic sigmoid link function with yn=y(xn, w).
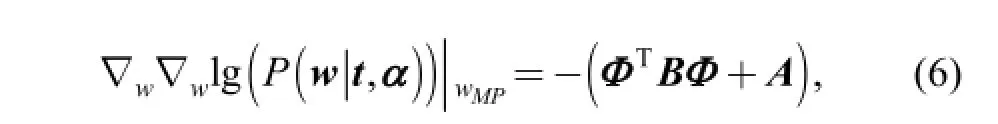
where B=diag (β1, β2,…, βN) is a diagonal matrix with βn= f (yn) (1- f (yn)) and A=diag (α1, α2,…, αN).
Thus, the covariance and mean for a Gaussian approximation to the posterior around weight centred at wMP(in place of µ) can be obtained:
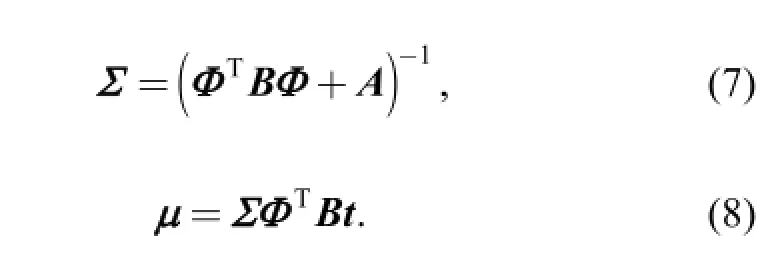
Update αnby using
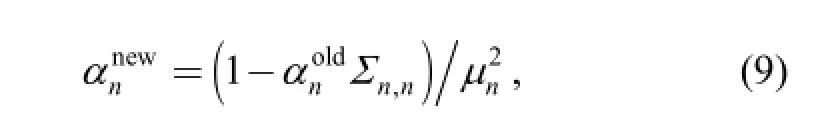
where Σn,nis the nth diagonal component of the posterior covariance given by Eq. (7) and μnis the nth component of the posterior mean given by Eq. (8).
If αnexceeds a preset maximum value, the corresponding weight wnis set to zero and the corresponding column in Ф is removed. After several iterations, just a few active terms in Eq. (1) are retained. The remaining active vectors with non-zero weights are called the relevance vectors. With the sparse vectors, the trained RVM can be used to classify the unseen data efficiently.
2.2 Adaptive kernel with multiple scale parameters
In the RVM model with single scale parameters, only the optimization of weights and hyperparameters is emphasized,while scale parameters η (or r) in Gaussian kernel are held constants all the time (see Eq. (2)). Here, a more adaptive Gaussian kernel Ф(xm, xn′) with multiple scale parameters is proposed:
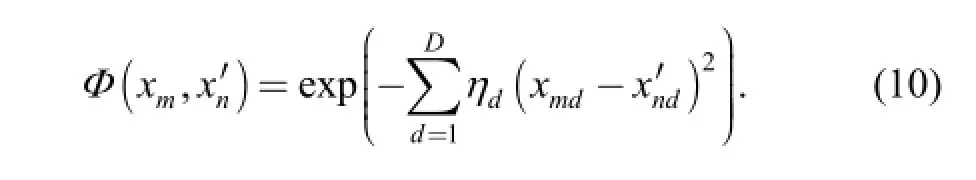
Compared with Eq. (2) in section 2.1, it is found that scale parameters ηd(d=1, 2,…, D) are assigned to each of D input variables individually, instead of a common scale parameter being used. This adaptation will not only help to improve the generalization performance of the classifier,but will lead to the following idea for feature selection.
The kernel function Ф(xm, xn′) can measure the similarity between xmand xn′[24]. In the Gaussian kernel, not all input variables are useful for classification problem and some irrelevant or redundant data even degrade the accuracy of classification. If one of the input variables is useless, its scaling factor is likely to become small. As a scale parameter becomes small, the Gaussian kernel becomes relatively insensitive to the corresponding input variable[25]. This idea gives a rationale for developing an algorithm for feature selection. By choosing optimal values for the scale parameters ηd, we can keep the features whose scaling factors are the largest and remove those which can be rescaled with a zero factor without harming the generalization.
3 Feature Selection by RVM-SBidirS
This section presents the novel feature selection algorithm RVM-SBidirS in details. This algorithm technically merges a sequential bidirectional search algorithm into scale parameter tuning within the Gaussian kernel to realize the fast feature selection.
3.1 Sequential bidirectional search(SBidirS)
The procedure for feature selection is always based on two components: evaluation criteria and search strategies[25].
The evaluation function used in this study is the classification error rate of the RVM classifier and the objective of feature selection is to seek the smallest subset of features with error rate below a given threshold. The search strategies are categorized into three groups by DOAK[26]: the first is exponential such as Branch & Bound(BB)[14]and exhaustive search; The second is randomized such as simulated annealing(SA) and genetic algorithms(GA)[27-28]. The third is sequential such as sequential backward search(SBS) and sequential forward search(SFS). The exponential search is impractical since the number of combinations of features(2D-1) increases exponentially as the dimensionality increases[29]. In randomized search algorithms, the setting of parameters is difficult[30]. The SFS and SBS are two basic sequential search algorithms. The SFS firstly initializes the set of significant input variables with empty set. Then, among all possible subsets with one more input variable, select the input variable combination that has the best merit value based on evaluation function. Conversely, the SBS firstly starts with all input variables. Then, among all possible subsets with one less input variable, select the input variable combination that has the best merit value based on the evaluation function[31]. Both these methods are generally suboptimal with low search efficiency. In this paper, a bidirectional sequential search algorithm is used in search of the best value of scale variables in kernel function.
In bidirectional search, the SFS and SBS are carried out concurrently. The program terminates when a common state is reached, since this means that a path has been found from the initial state to the goal state.
The algorithm is described briefly as follows.
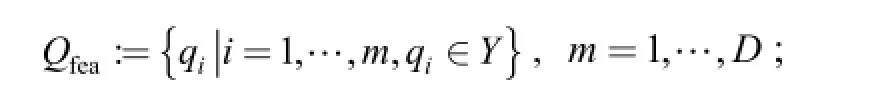
/* relevant feature subset */
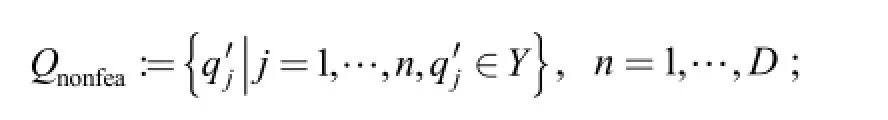
/* irrelevant feature subset */
f0; /* minimum classification error rate as evaluation function threshold*/
(2) Initialization
Qcand:=Y-Qfea-Qnonfea;
/* candidate subset for further feature selection */
(3) Termination
Stop when the number of relevant features will not increase any more and the error rate is kept below a given threshold.
(4) Start SBS
X:=Qcand; /* temporary feature subset for SBS */ Repeat
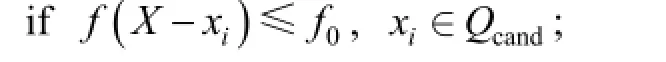
/* find one nonsignificant feature in Qcand*/ then X:=X-xi; /* remove one feature at a time */
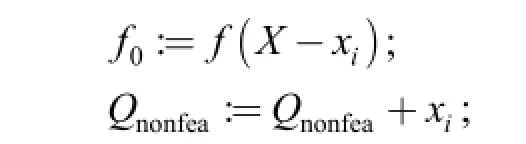
endif
Move to next xiin Qcandfor further test;Stop when all features are evaluated;
Qcand:=X;
Goto step 5;
(5) Start SFS
X:=Qfea; /* temporary feature subset for SFS */
Repeat
if f( X+xi)≤f0, xi∈Qcand;
/* find one significant feature in Qcand*/
then X:=X+xi; /* add one feature at a time */
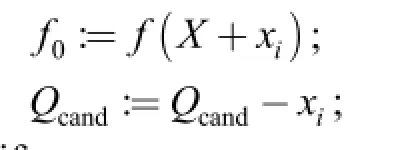
endif
Move to next xiin Qcandfor further test;
Stop when all features are evaluated;
Qfea:=X
Goto step 4;
(6) Return Qfea
3.2 Scale parameter selection using SBidirS
To search the scale parameters which are relevant to significant features, a bidirectional search algorithm is applied. The procedure can be explained as follows.
(1) Initialize all scale parameters ηd(d=1, 2,…, D) to some nonzero initial value η0, where D is the dimension of the candidate feature set.
(2) Use a standard RVM classification algorithm to find out the initial classification error rate f0as a threshold.
(3) Set the scale parameter of the ith feature to zero: ηi=0, and keep others unchanged(η0) in Gaussian kernel function, then calculate the classification error rate fiby using RVM classifier.
(4) If fiis much greater than the initial error rate f0, i.e.,the ith feature is significantly relevant to the performance of the classifier, then the value of corresponding ηiwill be reset to η0and inserted into the queue of feature subset Qfea. However, if the error rate fiis not greater than f0, i.e., the ith feature is irrelevant to or weakly relevant to the performance of the classifier, then the ith feature is removed and inserted into the queue of irrelevant feature subset Qnonfea. The remaining features form candidate feature subset Qcandfor further evaluation.
(5) Start with SBS. Set ηi=0 and other ηj=η0( j ≠ i ), and then calculate fi. If fi≤ f0, then remove the ith feature from Qcandand insert into Qnonfea; otherwise, keep the ith feature in Qcandand set ηi=η0. Repeat step 5 to test next feature. After all features in Qcandare evaluated, go to step 6.
(6) Start with SFS. Set η=η0and other ηj=0 ( j ≠ i ), and then calculate fi. If fi≤ f0, then remove the ith feature from Qcandand insert it into Qfea; otherwise, keep the ith feature in Qcandand set ηi=0. Repeat step 6 to test next feature. After all features in Qcandare evaluated, go to step 5.
(7) Repeat step 5 and step 6 till the number of relevant features will not increase any more when classification error rate is kept below a given threshold.
4 Application to Detection of Fault-Related Frequency Components
The time domain data collected from the machine can be easily converted into frequency domain data by using a Fast Fourier Transformation(FFT). However, it is still an intractable task for engineers to diagnose the fault by visual inspection of the frequency spectrum.
Fig. 1 shows two sets of frequency amplitude data from two machinery conditions: faulty bearing with line defect of 1.04 mm×16 mm and faulty bearing with line defect of 0.11 mm×16 mm. Fourier analysis yields 200 candidate features with a frequency resolution of 4.83 Hz and a frequency range of 0 Hz to 1000 Hz. The number of training samples was limited to 90, for a 2-class problem. Obviously, the number of training samples is far fewer than the number of features, which will cast a doubt on the classification accuracy of the classifier. Thus, the number of variables must be reduced so that the performance of the classifier which differentiates two faulty conditions will be ensured.
The following will detail how the RVM-SBidirS algorithm is exploited to select relevant features from 200 candidate variables.
(1) Initialize the scale parameters for all 200 input variables to ηd=4(d=1, 2,…, 200), and calculate the classification error rate of RVM classifier f0=1.111 1% as evaluation measure.
(2) Set ηi=0, other ηd(d=1,…, i-1, i+1,…, 200 ) were still 4, and calculate the classification error rate fi. Repeatstep (2) to obtain the corresponding error rate for each feature with ηi=0. In the process, if fi≤ f0, then f0=fi.
(3) Group the features for which error rates were much greater than f0into a subset Qfeafor further forward search. Group the features where error rates were less than f0into a subset Qnonfeafor a further backward search. Others were grouped into the candidate feature subset Qcand.
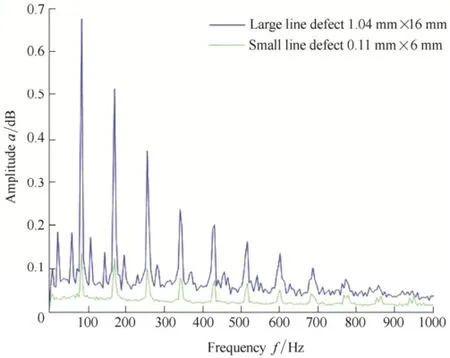
Fig. 1. Acoustic emission envelope amplitude spectra of bearings with seeded defects
As shown in Fig. 2, five features (36th, 53rd, 87th, 104th and 121st) caused classifier error rates up to 41.67%. The error rates were far greater than the initial error rate of f0=1.111 1%, which means that these features may be relevant to the classifier target. Thus, a feature subset Qfeacontaining these five features(as shown in triangle in Fig. 2)was formed for a further forward search.
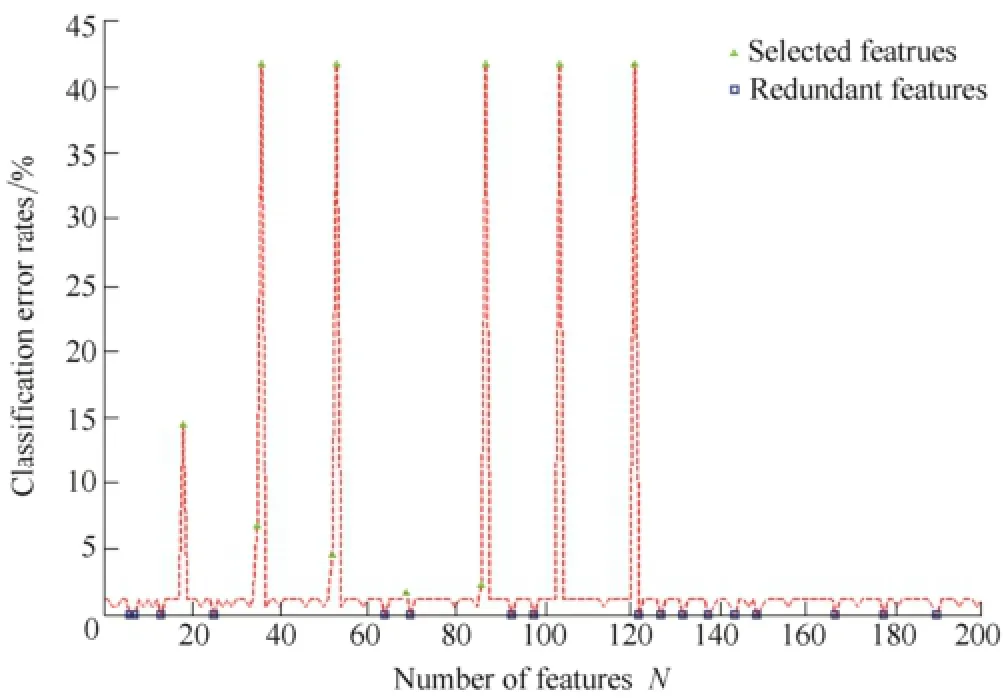
Fig. 2. Initial relevant feature subset and redundant feature subset from candidate 200 features
As a contrast, the classifier error rates with some features(for example, 6th, 7th, 190th etc) were less than f0=1.111 1%,which means that these features are irrelevant or weakly relevant to the classifier target. Thus, the 17 irrelevant features(as shown in square in Fig. 2) were grouped into a subset Qnonfeafor a further backward search.
The remaining 178 features formed the candidate feature subset Qcand.
(4) Start sequential bidirectional search. The search was stopped when the number of relevant features did not increase. The error rate of classification also decreased to 0%, which was slightly lower than the original error rate( f0=1.111 1%).
The subset Qfeaincluding minimum number of features was regards as the optimal feature subset. The optimal features in this experiment included 18, 35, 36, 52, 53, 69,86, 87, 104, 120, 121, which corresponded to seven main frequencies of 86.94 Hz, 173.88 Hz, 255.99 Hz, 333.27 Hz,420.21 Hz, 502.32 Hz and 579.6 Hz respectively.
These results have an important engineering significance for revealing the dependence between the faults and relevant frequency features, which can be interpreted theoretically as follows.
The bearing type used in the experience was an N406 parallel roller bearing of bore diameter 30 mm, outer diameter 90 mm, roller length 23 mm, pitch diameter 59 mm and having 9 rollers of diameter 14 mm. The rotational speed is 1456 r/min (24.3 Hz). Thus, the outer-race defect frequency was calculated to be 83.3 Hz according to the following formula:
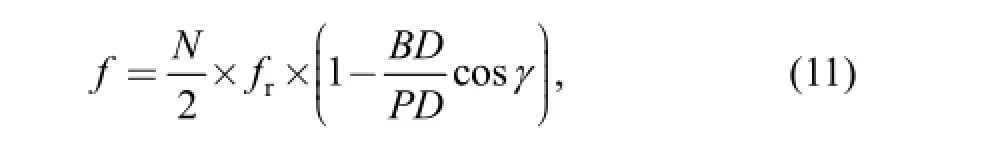
where N is the number of elements; BD is the roller diameter; PD is the pitch diameter; fris the rotational frequency and γ is the contact angle(assumed to be zero since this is a parallel roller bearing). If a fault produces a signal at a known frequency, then the magnitude of this signal is expected to increase as the fault develops. The seeded line defect on the outer race causes repetitive impulses when struck by the rollers, the defect should hence appear at the frequency, the values of which are around multiples of 83.3 Hz. Obviously, the results obtained by using RVM-SBidirS algorithm are consistent with the theoretical prediction.
5 Conclusions
(1) The exploration of the extending capability of Relevance Vector Machine classification algorithm for feature selection demonstrates a highly efficient solution to high-dimensional feature selection in the applications of condition monitoring.
(2) The bidirectional search is an effective way to find the optimal feature subset. The SBidirS starts with a backward search, and then turns to a forward search. However, it depends on the specific problem. It seems that a forward algorithm should be used first and then a backward algorithm in the case where the number of selected features is very small and the inverse holds in the case where the number of selected features is close to full candidate features.
(3) Although the sequential bidirectional search algorithm is used to select features by being merged into scale parameters of a kernel function in RVM, it can also be directly used as a feature selection tool with other classifiers.
[1] ZHANG K, LI Y, SCARF P, et al. Feature selection for high-dimensional machinery fault diagnosis data using multiple models and radial basis function networks[J]. Neurocomputing,2011, 74: 2941-2952.
[2] MURALIDHARAN V, SUGUMARAN V, INDIRAC V. Fault diagnosis of monoblock centrifugal pump using SVM[J]. Engineering Science and Technology, an International Journal,2014, 17(3): 152-157.
[3] SUN J, XIAO Q, WEN J, et al. Natural gas pipeline small leakage feature extraction and recognition based on LMD envelope spectrum entropy and SVM[J]. Measurement, 2014, 55: 434-443.
[4] PANDYA D H, UPADHYAY S H, JARSHA S P. Fault diagnosis of rolling element bearing with intrinsic mode function of acoustic emission data using APF-KNN[J]. Expert Systems with Applications,2013, 40(10): 4137-4145.
[5] SAFIZADEH M S, LATIFI S K. Using multi-sensor data fusion for vibration fault diagnosis of rolling element bearings by accelerometer and load cell[J]. Information Fusion, 2014, 18: 1-8.
[6] GHARAVIAN M H, ALMAS G F, OHADI A R, et al. Comparison of FDA-based and PCA-based features in fault diagnosis of automobile gearboxes[J]. Neurocomputing, 2013, 121: 150-159.
[7] LI S, WEN J. A model-based fault detection and diagnostic methodology based on PCA method and wavelet transform[J]. Energy and Buildings, 2014, 68(A): 63-71.
[8] AJAMI A, DANESHVAR M. Data driven approach for fault detection and diagnosis of turbine in thermal power plant using Independent Component Analysis (ICA)[J]. International Journal of Electrical Power & Energy Systems, 2012, 43(1): 728-735.
[9] MI J, XU Y. A comparative study and improvement of two ICA using reference signal methods[J]. Neurocomputing, 2014, 137: 157-164.
[10] CHEN X, LIANG L, XU G, et al. Feature extraction of kernel regress reconstruction for fault diagnosis based on self-organizing manifold learning[J]. Chinese Journal of Mechanical Engineering,2013, 26(5): 1041-1049.
[11] GAO H, LIANG L, CHEN X, et al. Feature extraction and recognition for rolling element bearing fault utilizing short-time fourier transform and non-negative matrix factorization[J]. Chinese Journal of Mechanical Engineering, 2015, 28(1): 96-105.
[12] ZHANG K, BALL A, LI Y, et al. A novel feature selection algorithm for high-dimensional condition monitoring data[J]. International Journal of Condition Monitoring, 2011, 1(1): 33-43.
[13] GUYON I, ELISSEEFF A. An introduction to variable and feature selection[J]. Journal of Machine Learning Research, 2003, 3: 1157-1182.
[14] NARENDRA P M, FUKUNAGA K. A branch and bound algorithm for feature subset selection[J]. IEEE Transactions on Computers,1977, C-26(9): 917-922.
[15] KOHAVI R, JOHN G H. Wrappers for feature subset selection[J]. Artificial Intelligence, 1997, 97(1-2): 273-324.
[16] ZHANG X, CHEN W, WANG B, et al. Intelligent fault diagnosis of rotating machinery using support vector machine with ant colony algorithm for synchronous feature selection and parameter optimization[J]. Neurocomputing, 2015, 167: 260-279.
[17] LIU C, JIANG D, YANG W. Global geometric similarity scheme for feature selection in fault diagnosis[J]. Expert Systems with Applications, 2014, 41(8): 3585-3595.
[18] BORDOLOI D J, TIWARI R. Support vector machine based optimization of multi-fault classification of gears with evolutionary algorithms from time-frequency vibration data[J]. Measurement,2014, 55: 1-14.
[19] ZHANG B, HUANG W, GONG L, et al. Computer vision detection of defective apples using automatic lightness correction and weighted RVM classifier[J]. Journal of Food Engineering, 2015,146: 143- 151.
[20] MATSUMOTO M, HORI J. Classification of silent speech using support vector machine and relevance vector machine[J]. Applied Soft Computing, 2014, 20: 95-102.
[21] KHADER A I, MCKEE M. Use of a relevance vector machine for groundwater quality monitoring network design under uncertainty[J]. Environmental Modelling & Software, 2014, 57: 115-126.
[22] ZHANG K, LI Y, FAN Y, et al. An evaluation of the potential offered by a relevance vector classifier in machinery fault diagnosis[J]. International Journal of COMADEM, 2006, 9(4): 35-40.
[23] TIPPING M E. Sparse Bayesian learning and the relevance vector machine[J]. Journal of Machine Learning Research, 2001, 1: 211-244.
[24] SCHOELKOPF B, SMOLA A. Learning with Kernels[M]. Cambridge: MIT Press, 2002.
[25] BISHOP C M. Neural networks for pattern recognition[M]. Oxford: Oxford University Press, 1997.
[26] DOAK J. Intrusion detection: The application of input selection, a comparison of algorithm and the application of a wide area network analyzer[D]. California: University of California, 1992.
[27] SRINIVAS M, PATNAIK L M. Genetic algorithms: A survey[J]. Computer, 1994, 27(6): 17-26.
[28] LI X Y, GAO L, SHAO X Y. An active learning genetic algorithm for integrated process planning and scheduling[J]. Expert Systems with Applications, 2012, 39(8): 6683-6691.
[29] CHEN X. An improved branch and bound algorithm for feature selection[J]. Pattern Recognition Letters, 2003, 24: 1925-1933.
[30] KUDO M, SKLANSKY J. Comparison of algorithms that select features for pattern classifiers[J]. Pattern Recognition, 2000, 33(1): 25-41.
[31] UNCU O, TURKSEN I B. A novel feature selection approach: combining feature wrappers and filters[J]. Information Sciences,2007, 177(2): 449-466.
Biographical notes
ZHANG Kui, born in 1966, is currently employed as a professor at Wuhan Polytechnic University, China. She obtained her PhD degree from University of Manchester, UK, in 2007. Her research interests include feature selection, machine learning, time-series forecasting, condition monitoring and fault diagnosis.
Tel: +86-27-85306456; E-mail: k.zhang@whpu.edu.cn
DONG Yu, born in 1995, is currently an undergraduate candidate at Communication University of China. Her research interests include feature selection, time-series forecasting, communication engineering, digital media technology and condition monitoring.
Tel: +86-13121073796; E-mail: carina_yudong@163.com
BALL Andrew, born in 1965, is currently a professor of diagnostic engineering and a pro-vice-chancellor for research and enterprise at University of Huddersfield, UK. He obtained his PhD degree from University of Manchester, UK, in 1991 and was promoted to professor at University of Manchester, UK, in 1999. His research interests include condition monitoring and fault diagnosis, data analysis and signal processing.
Tel: +44-1484-473640; E-mail: a.ball@hud.ac.uk
10.3901/CJME.2015.0706.087, available online at www.springerlink.com; www.cjmenet.com; www.cjme.com.cn
* Corresponding author. E-mail: k.zhang@whpu.edu.cn
Supported by Humanities and Social Science Programme in Hubei Province, China(Grant No. 14Y035), National Natural Science Foundation of China(Grant No. 71203170), and National Special Research Project in Food Nonprofit Industry(Grant No. 201413002-2)
© Chinese Mechanical Engineering Society and Springer-Verlag Berlin Heidelberg 2015
November 27, 2014; revised June 16, 2015; accepted July 6, 2015
杂志排行

Chinese Journal of Mechanical Engineering的其它文章
- Influence of Alignment Errors on Contact Pressure during Straight Bevel Gear Meshing Process
- Shared and Service-oriented CNC Machining System for Intelligent Manufacturing Process
- Material Removal Model Considering Influence of Curvature Radius in Bonnet Polishing Convex Surface
- Additive Manufacturing of Ceramic Structures by Laser Engineered Net Shaping
- Kinematics Analysis and Optimization of the Fast Shearing-extrusion Joining Mechanism for Solid-state Metal
- Springback Prediction and Optimization of Variable Stretch Force Trajectory in Three-dimensional Stretch Bending Process