基于短语和句法的统计机器翻译
2015-10-25冯志伟
冯志伟
(杭州师范大学外国语学院,浙江杭州311121)
基于短语和句法的统计机器翻译
冯志伟*
(杭州师范大学外国语学院,浙江杭州311121)
回顾了统计机器翻译发展的历程,讨论了噪声信道模型、基于短语的统计机器翻译和基于句法的统计机器翻译,主张把理性主义方法和经验主义方法结合起来,以推进机器翻译的进一步发展。
机器翻译;统计机器翻译;噪声信道模型;理性主义方法;经验主义方法
0 引言
传统的机器翻译技术使用小规模的数据或者语言学家的主观语感作为机器翻译知识的来源,采用基于规则(rule-based)的复杂算法,追求个别句子翻译的精确性,而不重视翻译对象的整体覆盖面[1]。这样的机器翻译系统只能覆盖小范围的语言材料,一旦扩大翻译的范围,系统就往往显得捉襟见肘,翻译的效果便马上降低[2-3]。
与传统的机器翻译不同,统计机器翻译(statistical machine translation,简称SMT)使用大规模的数据作为机器翻译的知识来源,采用基于统计(statistics-based)的简单算法,不追求个别句子翻译的精确性,而追求翻译语言材料的覆盖面,尽管个别句子的翻译精确度不是很高,但是,对于语言材料的覆盖面比较大,翻译的总体效果大大优于传统的机器翻译[4]。
目前,越来越多的互联网和软件公司都推出了基于统计的在线的机器翻译系统。统计机器翻译已经成为当前机器翻译的主流技术,值得我们高度关注[5]。
为了推动统计机器翻译进一步发展,我们主张把基于统计的机器翻译与基于规则的机器翻译技术结合起来,在统计机器翻译中,融入短语知识和句法知识[6-7],让计算机进行深度机器学习(deep machine learning),获取更加丰富的语言学知识[8]。
本文介绍近年来学者们在这方面的一些探索性研究。首先介绍基于短语的统计机器翻译,然后介绍基于句法的统计机器翻译。
1 统计机器翻译的噪声信道模型
在机器翻译产生的初期,就有学者提出了采用统计方法进行机器翻译的思想。
1949年,信息论的奠基人之一、美国洛克菲勒基金会副总裁Weaver W发表以《翻译》为题的备忘录,提出了使用解读密码的方法来进行机器翻译。他认为翻译类似于解读密码的过程[9]。Weaver W提出的这种解读密码的机器翻译需要采用统计的方法进行计算,实际上就是一种基于统计的机器翻译。
这样的基于统计的机器翻译需要有高性能的计算机进行大规模的计算,还需要有联机的机器可读的语料作为统计的对象,当时还不具备这样的条件,因此,Weaver W的这种方法难以付诸实现,只不过是一种具有远见卓识的想法而已。
随着计算技术的进步和大规模双语并行语料库建设的发展,实现Weaver W这种思想的技术条件逐渐成熟,于是在20世纪90年代初,IBM公司的Peter Brown等人在Weaver W思想的基础上提出了统计机器翻译的数学模型[10]。
统计机器翻译的这种数学模型把机器翻译问题看成是一个噪声信道(noisy channel)问题,叫做噪声信道模型(noisy channel model),如图1所示。
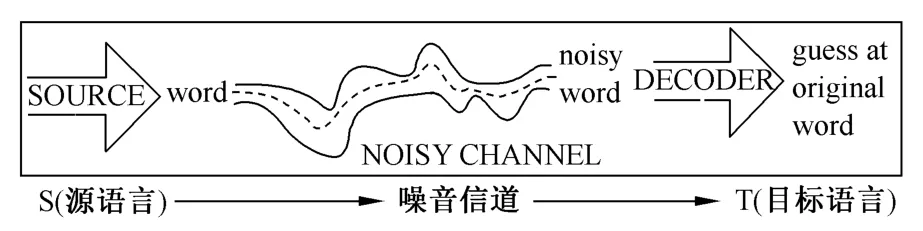
图1 统计机器翻译的噪声信道模型Fig.1 Noisy channel model for SMT
在图1中,源语言(source)S由于经过了噪声信道(noisy channel)而发生了扭曲变形,成为了噪声词(noisy word),于是在信道的另一端呈现为目标语言T,翻译实际上就是如何根据观察到的目标语言T进行解码(decoder),来猜测噪声词本来的面貌(guess at original word),从而恢复最为可能的源语言S。因此,统计机器翻译系统的任务就是在所有可能的源语言S的句子中寻找概率最大的那个句子作为目标语言T中的句子的翻译结果。
在这个模型中,噪声信道意义上的源语言就是翻译意义上的目标语言,而噪声信道意义上的目标语言就是翻译意义上的源语言。
统计机器翻译的基本公式如下:

在这个公式中,T表示翻译意义上的目标语言,S表示翻译意义上的源语言,P(T)是翻译意义上的目标语言的语言模型,而P(S|T)是给定翻译意义上的目标语言T的情况下,翻译意义上的源语言S的翻译模型。需要注意的是,统计机器翻译基本公式中的T和S与噪声信道模型中的T和S的所指是截然不同的。
2 基于短语的统计机器翻译
统计机器翻译的噪声信道模型是基于单词的。例如,如果要建立一个西班牙语到英语的统计机器翻译系统,首先就要根据西班牙语和英语的双语文本语料库,使用统计分析的方法把西班牙语转换为质量低劣的英语,我们把它叫做“破英语”(broken English),然后,再用统计分析的方法,从破英语生成目标语言英语,如图2所示。

图2 西班牙语-英语统计机器翻译系统Fig.2 Spanish-English SMT system
在图2中,输入西班牙语(Spanish),对于西班牙/英语双语文本(Spanish/English Bilingual Text)进行统计分析(Statistical Analysis),得到破英语,再根据英语文本(English Text)进行统计分析(Statistical Analysis)的结果对破英语进行加工,最后输出英语(English)译文。
例如,西班牙语句子Que hambre tengo yo(我是多么饿啊)首先被转换为若干个不同的破英语句子:
What hunger have I
Hungry I am so
I am so hungry
Have I that hunger
…
最后,使用统计方法在这些破英语句子中进行优选,得到比较好的英语译文:I am so hunger。
在图3中,Translation Model表示翻译模型,Language Model表示语言模型,Decoding algorithm表示解码算法。如果用s表示西班牙语,用e表示英语,从噪声信道模型的角度来看,首先使用翻译模型P(s|e),把西班牙语转换为破英语,再使用语言模型P(e),把破英语改造为正确英语的译文。
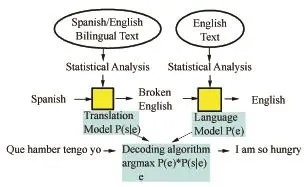
图3 基于噪声信道模型的统计机器翻译系统Fig.3 "Noisy channel model"based SMT system
在对于破英语进行优选时,使用解码算法求解argmax P(e)*P(s|e),最后得到正确英语译文I am so hunger。
这样解码过程是在单词的基础之上进行的。输入的西班牙语句子Que hambre tengo yo中的每一个单词,经过统计分析之后,还可能与若干个英语单词相对应:例如,西班牙语的Que对应于英语的单词what,that,so,where,西班牙语的hambre对应于英语的单词hunger,hungry,西班牙语的tengo对应于英语的单词have,am,make,西班牙语的yo,对应于英语单词I,me。
针对这种复杂的对应情况,使用解码算法进行计算,最后得到最优的英语单词序列:I am so hunger,如图4所示。
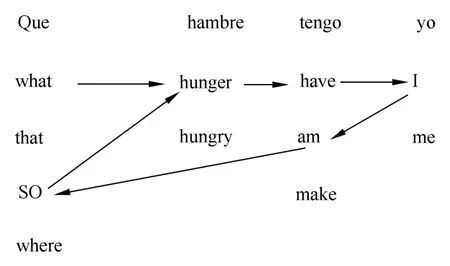
图4 使用解码算法得到英语译文Fig.4 English translation by decoding algorithm
在图5中,与西班牙语单词对应的英语单词是目标语单词(target word)排列成柱状,形成1sttarget word(第1个目标语单词),2ndtarget word(第2个目标语单词),3rdtarget word(第3个目标语单词),4thtarget word(第4个目标语单词)等柱子(beam),从start开始,解码器采用动态规划柱状搜索(dynamic programming beam search)技术,从柱子中选出与西班牙语单词最匹配的英语单词(best predecessor link),当源语言西班牙语句子中的单词都全部覆盖时(all source words covered),达到终点(end),搜索结束,就可以得到相应的英语译文。
上面描述的这种统计机器翻译是建立在单词的基础之上的,可以叫做基于单词的统计机器翻译(Word-Based SMT,简称WBSMT),这种基于单词的统计机器翻译技术存在如下的不足:
第一,这种技术可以处理源语言中的一个单词对应于目标语言中的若干个单词的“一对多”情况,但是,当源语言中的多个单词对应于目标语言中的一个单词的“多对一”的时候,这种技术就束手无策。
第二,这种技术无法处理源语言中固定短语。例如,固定短语interest in中interest的含义是“兴趣”,而固定短语interest rate中的interest的含义则是“利息”,如果只孤立地考虑单词interest本身,这种固定短语是无法处理的。

图5 动态规划柱状解码Fig.5 Dynamic programming beam decode
因此,有必要在统计机器翻译中结合短语的知识,建立基于短语的统计机器翻译系统(Phrase-Based SMT,简称PBSMT)。
例如,在德语到英语的统计机器翻译系统中,当把德语句子Morgen fliege ich nach Kanada zur Konferenz(明天我将飞往加拿大去参加会议)翻译为英语句子Tomorrow I will fly to the conference in Canada的时候,把德语中的nach Kanada组成一个短语与英语的in Canada相对应,把德语中的Zur Konferenz组成一个短语与英语的to the conference相对应,形成图6的对应关系,就比之于完全依靠单词对应要好得多。
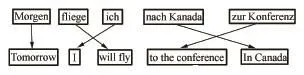
图6 德语和英语的短语对应Fig.6 Phrase alignment between German and English
在这种基于短语的统计机器翻译系统中,源语言的句子首先切分为短语和单词的组合,然后根据从双语语料库中获取短语翻译的知识,把每一个源语言短语翻译成目标语言短语的可能性用概率表示。如果用P表示概率(Probability),对于上面的例子,可以得到
P(to the conference|zur Konferenz),
P(into the meeting|zur Konferenz),其中短语之间翻译的可能性是用概率表示的。
这种基于短语的统计机器翻译系统的好处是:
第一,可以实现源语言和目标语言单词“多对多”的映射,因为当源语言中的多个单词对应于目标语言中的多个单词的时候,就可以把它们当作短语来处理;
第二,可以使用短语中的局部上下文进行多义词的排歧。例如,在短语interest in中的interest的词义可判定为“兴趣”,在短语interest rate中的interest的词义可判定为“利息”。
因此,结合短语知识的统计机器翻译系统克服了基于单词的统计机器翻译系统的不足。
Koehn P等指出,在基于短语的统计机器翻译中,也可以使用柱状搜索解码的方法。在Koehn P建立的统计机器翻译系统“法老”(Pharaoh)中,就使用了柱状搜索解码器来进行基于短语的分析[11]。
实践证明,这种基于短语的技术,可以改善统计机器翻译的质量,但是,当短语的长度扩大到3个以上的单词时,翻译系统的性能就很难提高,随着短语中包含单词数目的增大,数据稀疏问题会变的越来越严重。
David Chiang提出基于层次短语的统计翻译模型(hierarchical phrase-based model for statistical machine translation)。这种模型的基本思想是,在不干预基于短语的机器翻译方法的前提下,第一遍调整短语内部单词之间的顺序,第二遍再调整短语与短语之间的顺序,短语是由单词和子短语(subphrase)构成的,这样在短语之内就出现了子短语这个层次。这种基于层次短语的翻译知识是从没有任何句法信息标注的双语语料库中通过机器学习(machine learning)获得的[12]。
这种基于短语的机器翻译模型要依靠源语言和目标语言的短语对应表(phrase list)来进行翻译,而短语对应表要通过双语并行语料库来自动地抽取,为了自动地抽取短语对应表,关键问题是要进行“短语对齐”(phrase alignment),为此,Och提出了建造短语“对齐模板”(alignment templetes)的方法[13-15]。例如,通过德语和英语的双语言并行语料库,对于德语短语drei Uhr Nachmittag(下午3时)和英语短语three o′clock in the afternoon,计算机可以自动地建造这样的对齐模板,如图7所示。
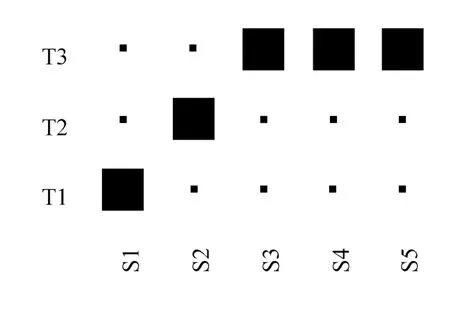
图7 德语和英语的短语对齐模板Fig.7 Phrase alignment template between German and English
其中,T1、T2、T3表示德语drei Uhr Nachmittag(下午3时)中的单词drei、Uhr、Nachmittag,S1、S2、S3、S4、S5表示英语单词three、o′clock、in、the、afternoon。T1与S1对应,T2与S2对应,T3与S3、S4、S5对应。其中,英语的in the afternoon是短语,而德语的Nachmittag是单词,这样就实现了短语和单词的对齐。所以,这样的短语对齐模板对于基于短语的统计机器翻译是非常有用的。
仿照这样的短语对齐模板,还可以在汉语和英语的双语言并行语料库中自动地建造如下的模板来实现汉语短语“在印度人民党的压力下”(在模板中用汉语拼音转写)与英语短语“under pressure from the Indian People′s Party”的对齐,如图8所示。

图8 汉语短语与英语短语的对齐模板Fig.8 Phrase alignment template between Chinese and English
在图8中,竖行表示汉语短语,横行表示英语短语,汉语的“在”(zai)和“下”(xia)与英语的under对应,汉语的“印度”(yindu)与英语的Indian对应,“人民”(renmin)与People′s对应,“党”(dang)与Party对应,而英语的the在汉语中没有对应的单词,这样,汉语短语的“印度人民党”就与英语的短语the Indian People′s Party实现了对应,汉语的“的”(de)与英语的from对应,汉语的“压力”(yali)与英语的pressure对应。在对齐“印度人民党”这个短语的时候,首先对齐了其中的单词“印度”、“人民”、“党”,接着处理了没有汉语对应单词的the,然后再实现短语的对齐,这意味着,可以首先分别实现单词对齐,然后在单词对齐的基础上进一步实现短语对齐;同样,“印度人民党”(the Indian People′s Party)是整个大的短语中的一个子短语,可以首先实现子短语的对齐,然后再实现整个短语的对齐。
在把两种语言中对应的单词归并为对应的短语的时候应该注意保持两种语言的短语中所包含的单词的一致性,一定要包含短语中含有的全部单词,不能有遗漏,也不能超出短语范围之外,否则,归并出的短语就是不可靠的。
例如,如果要在西班牙语的短语Maria no和英语的短语Mary did not之间对齐,由于单词Maria和单词Mary单词是对应,单词no和短语did not也是对应的,因此,可以得到图9中的第1个对齐的结果,短语中的单词保持了一致性(图9中为consistent),这是正确的短语对齐,如图9中的第1种情况;如果英语中的单词只包含Mary和did,不包含not,短语中少了一个单词,就不能与西班牙语的短语Maria no保持一致性(图9中为inconsistent),对齐的结果就是错误的,如图9中的第2种情况;如果西班牙语短语中再加上一个dió,也不能与英语的短语Mary did not保持一致性(图9中为inconsistent),对齐的结果也是错误的,如图9中的第3种情况。

图9 保持短语中单词的一致性Fig.9 Keeping words consistent in phrase
短语对齐是建立在单词对齐的基础上的,如果得到了单词对齐的结果,就可以在这个基础上进一步进行短语对齐。例如,在西班牙语-英语的统计机器翻译系统中,通过双语语料库的训练,得到了西班牙句子Maria no dió una bofetada a la bruja verde(Maria没有拍击绿色的女巫)和英语句子Mary did not slap the green witch的单词对齐结果,如图10所示,假定这时,西班牙语句子和英语句子中的单词都达到了最好的对应。
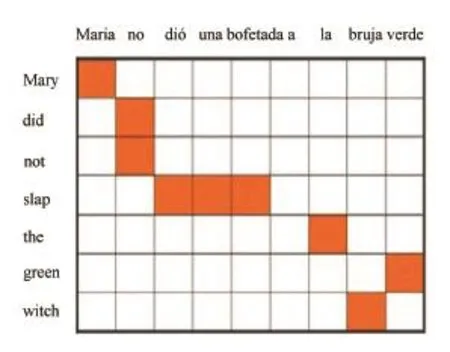
图10 西班牙语句子与英语句子的单词对齐结果Fig.10 Words alignment result between Spanish sentence and English sentence
从图10中可以看出,有些单词是与短语相对应的。例如,西班牙语中的单词no与英语中的短语did not相对应,英语中的单词slap与西班牙语中的短语dió una bofetada相对应。有的单词在对方的语言中没有相应的对应单词或短语。例如,西班牙语中的a,就没有相应的英语单词与它对应。
在图11中,凡是对齐了的单词和短语,都用黑色粗线的边框标出。一共有6组:(Maria,Mary),(no,did not),(dió una bofetada,slap),(la,the),(bruja,witch),(verde,green)。

图11 单词和短语的对齐Fig.11 Alignment of words and phrases
在这个基础上,在保持西班牙语短语与英语短语一致性的原则下,继续进行短语对齐,西班牙语中的a在英语中没有对应的单词,把它纳入到短语dió una bofetada和单词la中,得到如下的对齐短语:(dió una bofetada a,slap the),(a la,the),如图12所示。

图12 双语短语对齐之1Fig.12 Bilingual phrase alignment(1)
还可以进一步得到如下的几组对齐短语:(Maria no,Mary did not),(no dióuna bofetada,did not slap),(dió una bofetada a la,slap the),(bruja verde,green witch),如图13所示。

图13 双语短语对齐之2Fig.13 Bilingual phrase alignment(2)
然后,还可以得到如下的对齐短语:(Maria no dió una bofetada,Mary did not slap),(a la bruja verde,the green witch),(no dió una bofetada a la,did not slap the),(Maria no dió una bofetada a la,Mary did not slap the),(dió una bofetada a la bruja verde,slap the green witch)。最后,把短语对齐扩大到整个的句子,得到(Maria no dió una bofetada a la bruja verde,Mary did not slap the green witch),如图14所示。
在使用对齐模板在双语言并行语料库中进行双语的短语对齐时,可能会产生很多的对齐短语偶对,这时可以使用短语中的高频词来过滤掉一些多余的短语偶对。如果一个源语言的短语对应于目标语言中的若干个短语,就会产生对齐的歧义,当出现歧义短语偶对时,可以根据上下文来排歧。

图14 双语短语对齐之3Fig.14 Bilingual phrase alignment(3)
如果使用这样的方法从双语语料库中提取出对齐的短语,建成双语言的“短语对应表”,在进行基于短语的统计机器翻译时,首先将源语言句子切分成短语串,然后将这些源语言中的短语串,按照双语言的短语对应表进行映射,把它们映射成目标语言中相对应的短语,最后对目标语言的短语串进行排序,得到目标语言的输出。双语言的短语中包含了局部的单词选择和单词的局部顺序以及很多的习惯表达和搭配信息,这些是基于单词的统计机器翻译不具备的。由于引入了短语的语言信息,基于短语的统计机器翻译(PBSMT)在性能上超过了基于单词的统计机器翻译(WBSMT),所以基于短语的统计机器翻译系统受到了机器翻译研究者的欢迎。
3 基于句法的统计机器翻译
基于短语的统计机器翻译尽管优于基于单词的统计机器翻译,但是,基于短语的统计机器翻译只考虑短语本身的信息,并没有考虑短语与短语之间的句法关系,因此,在机器翻译时,难以处理短语之间重新排序的问题。例如,在把英语中的SVO(主-动-宾)结构转换成日语中的SOV(主-宾-动)结构时必须进行重新排序,这种情况使得基于短语的统计机器翻译感到困惑;对于在短语之间的长距离依存关系(long distance dependency),基于短语的统计机器翻译也常常感到捉襟见肘,难以对付。
由于基于短语的统计机器翻译的这些不足,学者们希望通过引入句法信息来解决这些问题,2001年Yamada K和Knight K提出了基于句法的统计机器翻译(syntax-based SMT,简称SBSMT)[16]。
在他们的机器翻译系统中,输入是源语言的句法树,输出是目标语言的句子。因此,源语言必须经过自动句法剖析,得到了句法树之后,才作为初始的输入进入统计机器翻译系统SBSMT。
基于句法的统计机器翻译过程分为如下几个步骤:
1)调序(reorder):输入树形图中的每个子树需要根据它们的概率重新排列,进行顺序的调整。
2)插入(insert):在子树结点的左边或右边随机插入恰当的功能词,插入时,左插入、右插入和不插入的概率取决于父结点和当前结点的标记,所插入单词的概率只与该单词本身有关,与位置无关。
3)翻译(translation):根据词对词的翻译概率,把树形图中每一个叶子结点上的单词翻译为目标语言的相应单词。
4)输出(output):输出译文句子。
例如,应用SBSMT方法,把英语句子He adores listening to music翻译为日语的过程如下:
首先,对于英语句子进行自动剖析,得到如下的树形图,如图15所示。
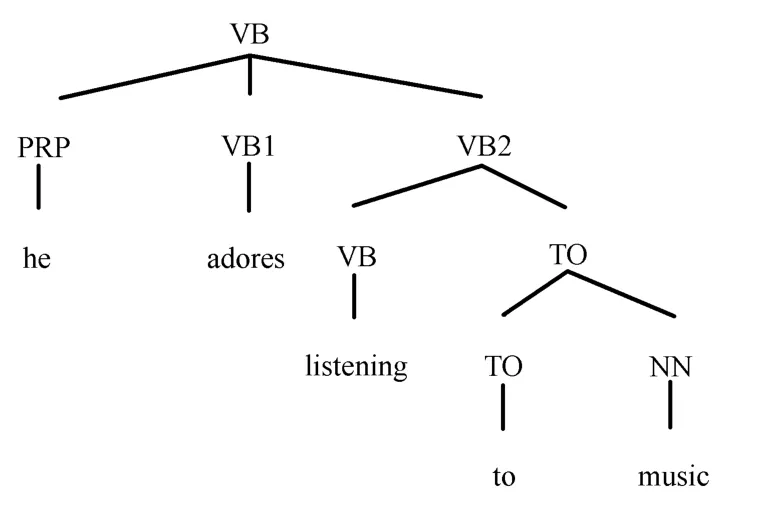
图15 输入树形图Fig.15 Input tree graph
然后,根据英语与日语双语言并行语料库中关于英语和日语调序(reorder)关系的概率,对于输入树形图中的子树重新排列,把VB1移动到VB2之后,在以VB2为父结点的子树中,把结点VB移动到结点TO之后,在以TO为父结点的子树中,把结点TO移动到结点NN之后,得到的结果如图16所示。

图16 调序Fig.16 Reorder
经过调序之后,树形图中的子树已经具有了日语的顺序,再根据日语语法的规则,插入日语的功能词(如格助词、助动词等),把它们添加到树形图的有关结点上,得到的结果如图17所示。
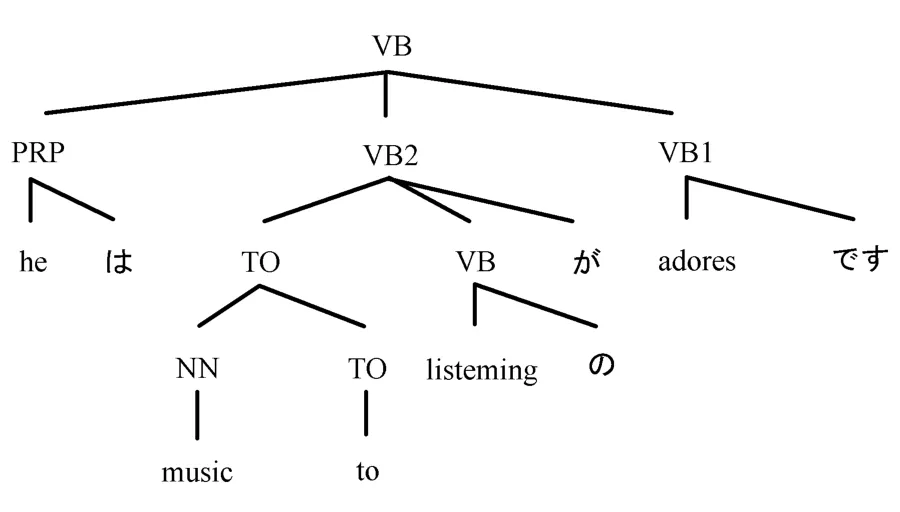
图17 插入日语功能词Fig.17 Inserting Japanese functional words
最后,根据词对词的翻译概率,把树形图叶子结点上的英语翻译为日语,得到的结果如图18。かれはぉんがくをきくのがたぃすきです。
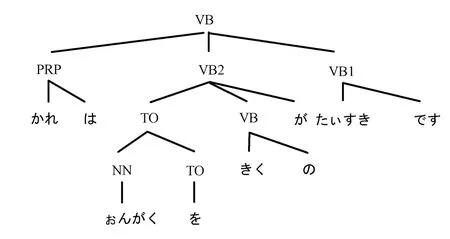
图18 翻译叶子结点上的英语为日语Fig.18 Translating English words on the leafs to Japanese word
顺次取出叶子结点上的单词,得到日语的译文:
最后,再把有关的假名符号转写为日语汉字,就得到可读性强的日语译文如下:
彼は音樂を聞くのが大好きです。
从这个例子中可以看出,在基于句法的统计机器翻译中,需要进行3种操作:
1)调序操作(Reordering operation):调整句子中符号串(在树形图中表现为子树)的顺序,把源语言符号串的顺序A1A2A3调整为目标语言符号串的顺序A1A3A2。其公式为

2)插入操作(Insertion operation):在符号串A1的前面或后面插入功能词w。其公式为
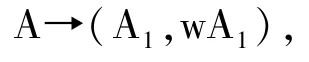

3)翻译操作(Translating operation):把源语言的单词x翻译为目标语言的单词y。其公式为

上述操作的统计知识通过训练双语言并行语料库来获取,建立不同的模型参数表(model parameter tables)。
为了进行调序操作,需要建立调序表(reordered table,简称r-table),如图19所示。
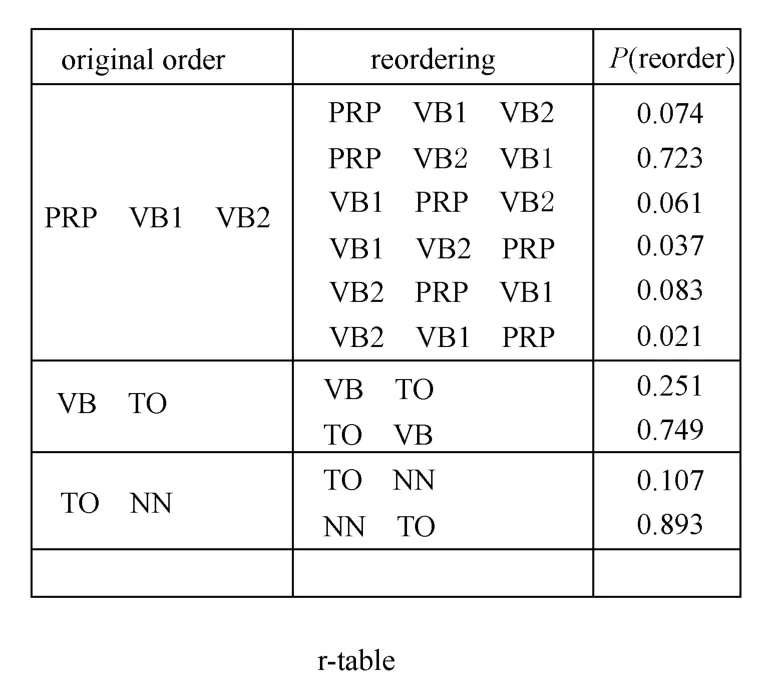
图19 调序表Fig.19 Reorder table
在调序表r-table中,记录着调序规则的概率P(reorder),第1列表示原词序(original order),第2列表示可能的调序结果(reordering),第3列表示相应的调序概率P(reorder)。对于符号串PRP VB1 VB2调序时,存在着多种可能性:PRP VB1 VB2(保持原来顺序),PRP VB2 VB1,VB1 PRP VB2,VB1 VB2 PRP,VB2 PRP VB1,VB2 VB1 PRP等,其中,调序为PRP VB2 VB1的概率最大,为0.732,故选择调序为PRP VB2 VB1,也就是把VB2移动到VB1之前。同理,把VB TO调序为TO VB,因为这种调序的概率最大,为0.749;把TO NN调序为NN TO,因为这种调序的概率最大,为0.893。
为了进行插入操作,需要建立结点表(node table,简称n-table)。
图20的结点表分左右两个,分别叫做n-table(1)和n-table(2)。

图20 结点表Fig.20 Node table
n-table(1)记录着非终极符号插入树形图中有关结点上的概率。
例如,当父结点(parent)为TOP(句子的顶点),当前结点(node)为VB时,如果不插入任何单词,保持原状[P(NONE)],那么,其插入概率为0.735,记为
P(None|Parent=TOP,Node=VB)=0.735。
又如,当父亲结点VB,当前结点为PRP,而且在PRP中插入的单词は处于子树的右侧时,其插入概率为0.652,记为
P(Right|Parent=VB,Node=PRP)=0.652。
图18的树形图中的8个非终极结点上,分别有8个非终极符号:VB,PRP,VB2,VB1,TO,VB,NN,TO,它们都分别要进行插入操作,所以一共需要进行8个插入操作,其中有4个插入操作都在右侧插入了功能词。
此外还要考虑功能词本身的插入概率,n-table(2)记录着各个功能词的概率:

为了进行翻译操作,需要建立翻译表(translation table,简称t-table)。在t-table中记录着源语言单词翻译为目标语言单词的概率。
最后还需要计算调序-插入-翻译的联合概率。
这个机器翻译系统使用英语-日语双语语料库进行训练,包括例句2 121对,日语平均句长9.7词,英语平均句长6.9词,词典中英语3 463词,日语3 983词。他们使用Brill的词性标注器(Brill’s POS Tagger)和Collins的剖析器(Collins’Parser)进行句法剖析,使用中心词词性标记提取短语标记,合并中心词相同的句法子树从而压扁句法树。
经过测试,该系统明显地优于IBM公司的基于噪声信道模型的统计机器翻译模型。可见,在统计机器翻译中使用句法信息有助于译文质量的提高。
4 结束语
基于规则的机器翻译方法是一种理性主义的方法(rationalist approach),基于统计的机器翻译方法是一种经验主义的方法(empiricist approach),基于短语和句法的统计机器翻译,把短语规则、句法规则融入统计机器翻译中,从而把基于规则的机器翻译方法与基于统计的机器翻译方法结合起来,把理性主义方法与经验主义方法结合起来,让这两种方法取长补短,相得益彰,这是机器翻译发展的正确方向。
近年来,在统计机器翻译中,又开始使用深度机器学习的方法,让计算机自动地学习自然语言中的抽象特征表示,自动地建立输入信号与输出信号之间的复杂的映射关系,这种深度学习方法,给统计机器翻译提供了新的思路[17]。
[1]冯志伟.机器翻译研究[M].北京:中国对外翻译出版公司,2004.
[2]冯志伟.机器翻译-从梦想到现实[J].中国翻译,1999(4):37-40.
[3]冯志伟.机器翻译-从梦想到现实[J].中国翻译,1999(5):52-55.
[4]冯志伟.自然语言处理中的哲学问题[J].心智与计算,2007,1(3):333-353.
[5]Brown P F,John C,Della Pietra S A,et al.A Statistical Approach to Machine Translation[J].Computational Linguistics,1990,16(2):79-85.
[6]梁华参.基于短语的统计机器翻译模型训练中若干关键问题的研究[D].哈尔滨:哈尔滨工业大学,2013.
[7]熊德意,刘群,林守勋.基于句法的统计机器翻译综述[J].中文信息学报,2008,22(2):28-39.
[8]刘群.汉英机器翻译若干关键技术研究[M].北京:清华大学出版社,2008.
[9]Weaver W.Warren Weaver's memorandum in 1949:Translation,Milestones in machine Translation[C]//Locke W N,Booth A D. Machine Translation of languages:fourteen essays,Cambridge,Mass:MIT Press,1955:15-23.
[10]Brown P F,Della Pietra S A,Della Pietra V J,et al.The mathematics of statistical machine translation:parameter estimation[J]. Computational Linguistics,1993,19(2):263-311.
[11]Koehn P.Pharaoh:A beam search decoder for phrase-based statistical machine translation models[C]//Proceedings of the 6th Conference of the Association for machine translation in the Americas,Los Angeles,2004:115-124.
[12]Chiang D.Hierarchical phrase-based translation[J].Computational Linguistics,2007,33(2):201-228.
[13]Och F J,Tillmann C,Ney H.Improved alignment models for statistical machine translation[C]//Proceedings of the Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora,University of Maryland,College Park,MD,USA,1999:20-28.
[14]Och F J,Ney H.Discriminative Training and Maximum Entropy Models for Statistical Machine Translation[C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics(ACL),Baltimore,Maryland,USA,2002:295-302.
[15]Och F J,Gildea D,Khudanpur S,et al.Final Report of John Hopkins 2003SummerWorkshoponSyntaxforStatistical MachineTranslation[M].Baltimore:PressofHopkins University,2003.
[16]Yamada K,Knight K.A Syntax-Based Statistical Translation Model[C]//Proceedings of the 39th Annual Meeting of the Association for Computational Linguistics(ACL),Toulouse,France,2001:23-27.
[17]冯志伟.《统计机器翻译》述评[J].外语教学与研究,2013,45(4):629-633.Phrase-based and syntax-based statistical machine translation
FENG Zhi-wei
(School of Foreign Languages,Hangzhou Normal University,Hangzhou,Zhejiang 311121,China)
The development process of statistical machine translation(SMT)is described in this paper,and the noisy channel model in SMT,phrase-based SMT and syntax-based SMT are introduced.In order to give impetus to MT,the rationalist approach and the empiricist approach should be combined.
machine translation;statistical machine translation;noisy channel model;rationalist approach;empiricist approach
TP391
A DOI:10.3969/j.issn.1007-791X.2015.06.013
1007-791X(2015)06-0546-10
2015-03-20
*冯志伟(1939-),男,云南昆明人,教授,博士生导师,主要研究方向为自然语言处理、计算语言学,Email:zwfengde2010@ hotmail.com。
