融合用户相似度和信任传播重组信任矩阵算法
2015-10-25原福永梁顺攀
原福永,马 琳,梁顺攀
(燕山大学信息科学与工程学院,河北秦皇岛066004)
融合用户相似度和信任传播重组信任矩阵算法
原福永*,马 琳,梁顺攀
(燕山大学信息科学与工程学院,河北秦皇岛066004)
针对协同过滤面临的一些本质问题,如数据稀疏和冷启动,本文提出了融合用户相似度和加权的信任传播来重组信任矩阵的方法。首先,将原始信任矩阵中用户相似度低于某一阈值的信任关系去掉;其次,将评分矩阵中用户相似度高于某一阈值的用户对添加到信任矩阵中;最后,考虑加权的信任传播,以此找到更多的信任邻居并对不同距离的信任邻居进行区分。在Epinions和FilmTrust数据集上进行的对比实验结果表明,重组信任矩阵的方法能够有效地提高推荐精度,并在一定程度上解决了冷启动问题。
协同过滤;用户相似度;加权的信任传播;重组信任矩阵
0 引言
Web 2.0的迅猛发展极大地改善了用户线上行为,从浏览、搜索到交互、共享[1]。协同过滤方法是推荐系统中使用最广泛、应用最成功的方法之一[2]。一般来说,协同过滤方法可以分为两大类:基于模型的方法(model-based)和基于内存的方法(memory-based)。在基于模型的方法中,使用最广泛的是矩阵分解,如SVD[3]、NNMF[4]及张量分解[5]。但是,基于模型的方法不能对如何产生推荐进行合理的解释,并且由于训练得出的模型是静态的,因此也不能有效地利用新的评分数据。所以本文针对基于内存的协同过滤方法进行改进。
协同过滤面临着数据稀疏和冷启动等一些本质问题。数据稀疏是由于用户只评论少量的项目从而很难有效地找到可信的相似用户。冷启动包括两方面的问题:1)怎样向从没有做出过任何评价的新用户进行推荐;2)怎样处理从来没有评论过的项目。为了解决这些问题,一些额外信息融入了协同过滤中,如friendship[6]、membership[7]和信任[8]等,其中信任比friendship和membership更可靠。
Jamali等人提出了TrustWalker方法[9],该方法在信任矩阵中随机选取信任邻居,将信任与基于项目的评分预测方法相结合。与之不同的是,本文方法是将信任与基于用户的评分预测方法结合以此产生推荐。Massa等人提出了MoleTrust算法[10],考虑信任传播并通过深度优先搜索方法来找到更多的信任邻居。实验结果表明随着信任传播长度增大,覆盖率增大了,但是预测精度变化很小。最近Deng等人提出了RelevantTrustWalker方法[11],首先使用矩阵分解方法来获取社交网络中信任用户之间的信任度。其次,提出了一个可扩展的随机游走算法来获取推荐结果。Guo等人提出了一种融合方法Mergex[12],该方法首先利用信任传播扩充信任矩阵,其次将扩充后的信任、PCC计算的相似度以及信任用户交集与并集的比例三部分作为权重对评分进行加权,最后利用CPCC计算新的评分矩阵中用户的相似度来产生推荐。但是该方法使用的是整个信任矩阵,并没有对信任矩阵进行预处理。Ray等人提出了另外一种基于信任的方法[13],通过重组信任矩阵来提高评分预测精度。具体来说,如果用户之间的相似度低于某一阈值,那么就要去掉这两个用户对应的信任关系。但是从实验结果可以看出高质量的预测结果是以牺牲覆盖率为代价的,并且也不能很好地解决冷启动问题。
针对以上问题,本文提出了将用户相似度与加权的信任传播结合以此重组信任矩阵的算法。具体思路如下:1)由于信任矩阵中低相似度会降低推荐质量,所以去掉信任矩阵中相似度低于某一阈值的信任关系;2)信任矩阵中相似度高的用户会提高评分预测精度,所以如果两个用户之间的相似度高于某一阈值,那就将这两个用户对应的信任关系添加到信任矩阵中;3)由于冷启动用户不活跃且信任邻居数量少,所以考虑信任传播,以此找到更多的信任邻居,但是由于信任值是二进制的,不能对不同距离的信任用户进行区分,所以引入一个权重因子来评估不同距离的信任用户的信任值。实验结果表明,本文方法能够较精确的预测评分,并且有效的解决冷启动问题。
1 重组信任矩阵
在基于信任的系统中,大多数评分预测的方法都是使用全部信任矩阵中的数据。但是,用户A信任用户B并不代表A与B之间的相似度也很高,而信任矩阵中低相似度的信任用户会对推荐结果造成一定的影响,因此本文提出了将相似度与信任结合来重组信任矩阵的方法。由于Pearson Correlation Coefficient(PCC)是协同过滤中使用较广泛的方法且计算精度较高,所以选取PCC来计算用户之间的相似度。它的定义如下:
定义1:PCC算法
对于给定的两个用户a和b,他们之间的PCC相似度用Sab来表示,定义如下所示:
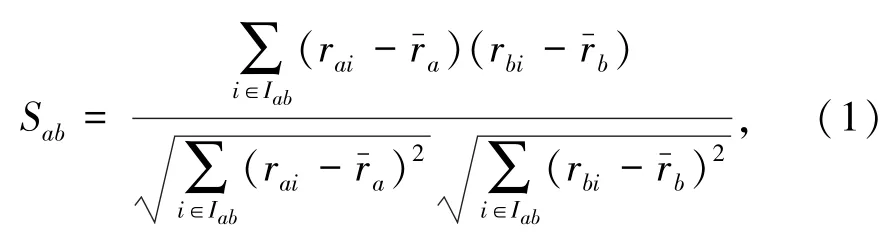
其中,rai和rbi分别表示用户a和b对项目i的评分,和分别代表用户a和b对其评价的所有项目的平均评分,Iab表示用户a和b的共评项目集合。Sab<0代表用户a和b负相关,Sab>0代表用户a和b正相关,Sab=0代表用户a和b不相关,负相关及不相关在实际计算中没有意义,故只考虑正相关的情况。
在一个推荐系统中,评分矩阵表示为Rating,原始信任矩阵用Trust表示,tab代表用户a和b的信任值。通常情况下,信任值是二进制的,即0或1,其中0代表不信任,1代表信任。在重组信任矩阵时,本文设置了两个相似度阈值,分别为α和β。重组信任矩阵包括以下两个步骤:首先,由于信任矩阵中相似度低的用户会降低评分预测质量,所以对于信任矩阵中的两个用户a和b,即tab为1,如果他们的相似度Sab<α,那么就去掉a与b之间的信任关系,即tab设置为0;若Sab>α,则保留a与b之间的信任关系。定义如下所示:
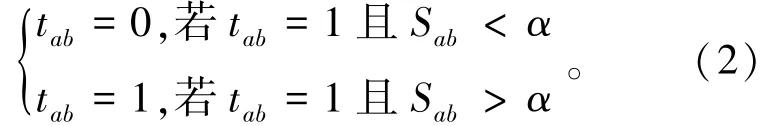
其次,由于信任矩阵中高相似度的用户会提高推荐效果,所以对于不在信任矩阵中的两个用户a和b,即tab为0,如果他们之间的相似度Sab>β,那么在信任矩阵中添加a与b之间的信任关系,即tab设置为1;若Sab<β,则不添加a与b之间的信任关系。定义如下所示:

通过上述步骤,对信任矩阵完成了重组,重组后的信任矩阵用UpTrust表示。UpTrust中去掉了原始信任矩阵中相似度低的用户信任关系,并将相似度高的用户信任添加到了信任矩阵中。
根据以上算法思想,给出重组信任矩阵算法(Reconstructing Trust Matrix Algorithm RTXA)的描述,如下所示:
算法1:重组信任矩阵算法(RTXA)
Input:Rating,Trust,α,β
Output:UpTrust
1:For each user u
2: For each user ν
3: if tuν=1 and Suν<α
4:tuν=0
5:else if and tuν=1 Suν>α
6: tuν=1
7: else if tuν=0 and Suν>β
8:tuν=1
9:else if tuν=0 and Suν<β
10:tuν=0
11: End for
12:End for
13:Return UpTrust
2 加权的信任传播
2.1相关定义
图1所示为信任网络T,网络中的每一个节点代表一个用户,每一条有向边对应一条信任关系。在信任网络中,每一个用户u有一组直接信任邻居ν∈{Nu|tuν≠0},信任值tuν为二进制值,其中0代表完全不信任(图中无有向边的用户),1代表完全信任(图中有有向边的用户)。
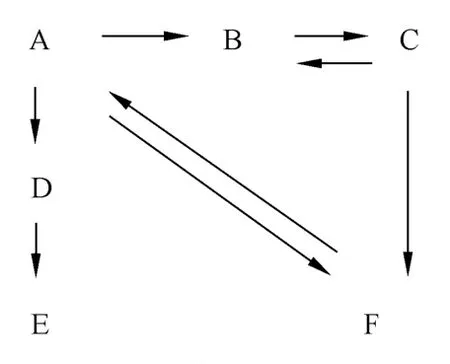
图1 信任网络图Fig.1 Trust network
定义2:信任传播步长d
设信任网络,T={u1,u2,…,un},在T中任意选取两个用户节点ui和uj,分别作为信任传播的源用户节点和目的用户节点,定义信任从源用户节点传播到目的用户节点的最短距离为信任传播步长d。
冷启动用户通常被定义为评价项目数不多于5个的用户。由于冷启动用户不活跃,他们的信任邻居也不多,所以为冷启动用户进行项目推荐非常困难。但是,由于信任具有传递性,如果用户A信任用户B,并且用户B信任用户C,那么用户A与用户C之间也存在某种程度的信任。所以通过信任传播找到更多的信任邻居来解决冷启动问题是一种非常有效的方法。MoleTrust方法就是一种用上述信任传播方式来衡量信任关系的方法,但是由于重组的信任矩阵UpTrust仍然是二进制的,所以使用MoleTrust方法计算得到的信任值也是二进制的,这样无法对不同距离的信任用户进行区分。为了解决这个问题,本文采取一个权重因子来重新评估不同距离的信任用户的信任值,定义如下:

其中,tuν表示使用MoleTrust方法得到的用户u与 ν之间的信任值,d为信任传播步长,表示加权后u与ν之间的信任值。显然d越大,找到的信任邻居越多,但同时内存消耗也越大,且产生的噪音越多。因此,本文限制d的范围为d≤3以降低计算的复杂度并防止无意义的搜索。使用加权的信任传播后得到的信任矩阵即为UpTrust_d。
根据上述描述,加权的信任传播算法(Weighted Trust Propagation Algorithm,WTPA)思想如下:
算法2:加权的信任传播算法(WTPA)
Input:UpTrust
Output:UpTrust_d
1:For user u in UpTrust
2: For user ν in UpTrust
3: if duν≤3
6: End for
7:End for
8:Return UpTrust_d
3 实验及分析
3.1数据集
为了验证重组信任矩阵算法的有效性,本文将用两个数据集进行试验。分别是:
1)Epinions数据集。该数据集包括一个评分矩阵和一个信任矩阵,其中评分矩阵是49K个用户对139K个项目的664K个评分,评分范围是1~5,稀疏度为99.95%;信任矩阵包括478K个信任关系,信任值是二进制的。
2)FilmTrust数据集。FilmTrust也包括评分矩阵和信任矩阵。评分矩阵包含1 986个用户,2 071个电影以及35 497个评分,评分范围为0.5~4.0,稀疏度为98.86%;信任矩阵,包含609个用户的1 853个信任评分,信任值也是二进制的。
实验时,采用五折交叉验证法进行试验,即将数据集随机划分为5份,其中4份为训练集,余下的1份为测试集。5次实验得到结果的平均值即为实验结果。
3.2测量指标
为了验证本文方法能否有效地提高评分预测精度以及解决冷启动问题,实验选用平均绝对误差MAE(Mean Absolute Error,MAE)、均方根误差RMSE(Root Mean Squared Error,RMSE)及评分覆盖率RC(Rating Coverage)来衡量实验结果。MAE和RMSE用于测量预测评分与真实评分的接近程度,预测评分与真实评分越接近,MAE和RMSE的值越低;RC用于测量可以预测出的评分占全部待预测评分的比例,RC值越大,说明能够预测出的项目评分越多,即算法越好。它们的定义如下所示:

其中,rui为用户u对项目i的实际评分,pui为用户u对用户i的预测评分。T为预测结果集,|T|表示集合中元素的数。

其中,M和N分别代表可预测出的项目评分数和全部待预测的项目。
3.3结果与讨论
在这一小节中,对本文提出的重组信任矩阵的算法进行验证。UpTrust_d(d=1,2,3)是本文提出的算法,对原始信任矩阵进行重组,并设置信任传播长度为d。Trust_d(d=1,2,3)是使用原始信任矩阵且信任传播长度为d来产生推荐的算法。另外还与PCC算法进行了对比,所以在每组实验中会产生7个实验结果。为了验证该算法可以有效地解决冷启动的问题,从FilmTrust数据集中提取出冷启动用户,也就是评论项目数不超过5个的用户,并将PCC和UpTrust_1两个算法在冷启动用户上就MAE、RMSE和RC进行了对比。下面分别对实验结果进行分析。
实验1 图2和图3分别是对比算法在FilmTrust数据集上MAE和RMSE的实验结果,重组信任矩阵的阈值分别设置为α=0.2,β=0.3。从图中可以看出UpTrust_d是所有方法中最好的方法,且PCC比Trust_d方法效果好,这说明信任矩阵中低相似度的用户会降低评分预测质量,而重组信任矩阵的方法能够有效地解决这一问题。从图中还可以观察到,随着信任传播长度增大,使用原始信任矩阵方法的效果越来越好,即Trust_3比Trust_2效果好且Trust_2比Trust_1效果好,这说明信任传播在提高推荐效果方面有一定的影响。但是,在本文提出的算法UpTrust_d中,随着信任传播长度d增大,方法的效果越来越差,其中UpTrust_1是最好的方法。这是因为随着信任传播长度增大,虽然可以找到更多的信任邻居,但是这并不能保证找到更多的项目,反而有可能会包含进一些干扰用户,带来噪声,从而降低评分预测的精度。

图2 各算法在FilmTrust数据集上MAE值比较Fig.2 Comparison of MAE between relevant recommendation algorithms on the FilmTrust dataset
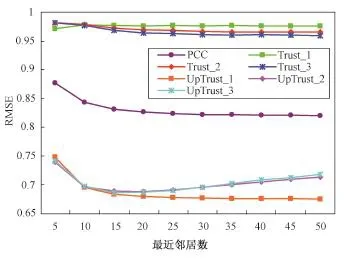
图3 各算法在FilmTrust数据集上RMSE值比较Fig.3 Comparison of RMSE between relevant recommendation algorithms on the FilmTrust dataset
实验2 图4和图5分别是对比算法在Epinions数据集上MAE和RMSE的实验结果,重组信任矩阵的阈值分别设置为α=0.1,β=0.3。从图中同样可以观察到,UpTrust_d是最好的方法,且PCC比Trust_d方法效果好,这也说明了信任矩阵中低相似度的信任关系会影响推荐效果,而重组信任矩阵的方法能够提高评分预测质量。但是,随着信任传播长度增大,Trust_1是Trust_d中最好的方法而UpTrust_3是UpTrust_d中效果最好的方法,这与FilmTrust数据集中得到的结论正好相反。这一现象同样说明信任传播不保证一定能得到最好的推荐结果,虽然它能找到更多的信任邻居,但同样会引入噪声,对推荐产生干扰。

图4 各算法在Epinions数据集上MAE值比较Fig.4 Comparison of MAE between relevant recommendation algorithms on the Epinions dataset
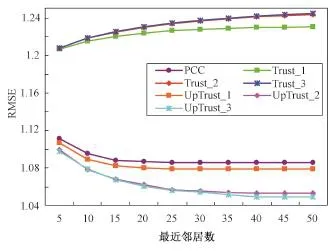
图5 各算法在Epinions数据集上RMSE值比较Fig.5 Comparison of RMSE between relevant recommendation algorithms on the Epinions dataset
实验3 为了验证本文方法能够有效解决冷启动问题,在FilmTrust数据集上提取出冷启动用户,由于UpTrust_1在FilmTrust数据集上效果最好,所以将PCC和UpTrust_1两个算法在冷启动用户上就MAE、RMSE和RC进行了对比,实验结果分别如图6、图7和表1所示。从图中和表中的数据可以看出,UpTrust_1方法在MAE、RMSE及覆盖率上明显比PCC效果好,说明本文算法能够在较大范围上对冷启动用户进行高质量的评分预测,有效地解决了冷启动问题。
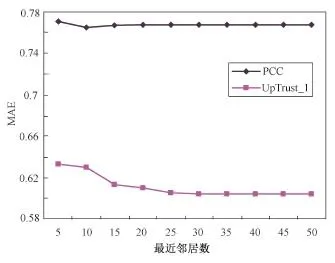
图6 各算法在FilmTrust数据集上冷启动用户的MAE值比较Fig.6 Comparison of MAE between relevant recommendation algorithms on the cold users in FilmTrust dataset
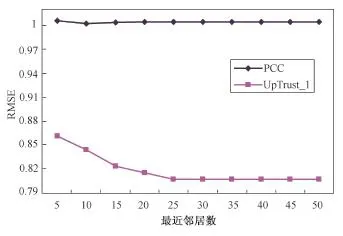
图7 各算法在FilmTrust数据集上冷启动用户的RMSE值比较Fig.7 Comparison of RMSE between relevant recommendation algorithms on the cold users in FilmTrust dataset

表1 PCC及UpTrust_1算法在FilmTrust数据集上冷启动用户的覆盖率比较Tab.1 Comparison of rating coverage between PCC and UpTrust_1 algorithms on the cold users in FilmTrust dataset
4 结束语
本文提出了结合用户相似度与加权的信任传播重组信任矩阵的方法来提高协同过滤推荐系统的评分预测精度,并解决冷启动问题。由于传统基于信任的方法中大部分使用的是全部信任矩阵数据,而信任矩阵中相似度低的用户会降低评分预测精度,所以本文首先将信任矩阵中用户相似度低于某一阈值的信任关系去掉;其次,信任矩阵中高相似度的用户会提高推荐质量,因此为相似度高于某一阈值的用户对添加信任关系;最后,由于冷启动用户不活跃且其信任邻居少,所以考虑信任传播来寻找更多的信任邻居,但是传统的信任传播方法计算所得的信任值仍然是二进制的,不能对不同距离的信任邻居进行区分,因此采用加权的信任传播,来区分不同距离的信任用户。对比实验结果表明,本文提出的重组信任矩阵的方法有效地提高了评分预测质量,并且较好地解决了冷启动问题。
[1]Zhou X,Xu Y,Li Y,et al.The state-of-the-art in personalized recommendersystemsforsocialnetworking[J].Artificial Intelligence Review,2012,37(2):119-132.
[2]Xu Hai-ling,Wu Xiao,Li Xiao-dong,et al.Comparison study of Internet recommendation system[J].Journal of Software,2009,20(2):350-362.
[3]Li Gai,Li Lei.Collaborative filtering algorithm based on matrix decomposition[J].Computer Engineering and Applications,2011,47(30):4-7.
[4]Zhang S,Wang W,Ford J.et al.Learning from incomplete ratings using non-negative matrix factorization[C]//Proceedings of the 2006 SIAM International Conference on Data Mining,Maryland,2006:549-553.
[5]Li Gui,Wang Shuang,Li Zheng-yu,et al.Personalized tag recommendation algorithm based on tensor decomposition[J].Computer Science,2015,42(2):267-173.
[6]Konstas I,Stathopoulos V,Jose J.On social networks and collaborative recommendation[C]//Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval,Boston,2009:195-202.
[7]Yuan Q,Zhao S,Chen L,et al.Augmenting collaborative recommender by fusing explicit social relationships[C]//Proceedings of Workshop on Recommender Systems and the Social Web,New York,2009:49-56.
[8]Audun J,Quattrochicchi D.Taste and trust[J].Trust Management V,2011,358:312-322.
[9]Jamali M,Ester M.Trustwalker:a random walk model for combining trustbased and item-based recommendation[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Paris,2009:397-406.
[10]Massa P,Avesani P.Trust-aware recommender systems[C]//Proceedings of the 2007 ACM Conference on Recommender Systems,Minneapolis,2007:17-24.
[11]Deng S,Huang L,Xu G.Social network-based service recommendation with trust enhancement[J].Expert Systems with Applications,2014,41(18):8075-8084.
[12]Guo G,Zhang J,Thalmann D.Merging trust in collaborative filtering to alleviate data sparsity and cold start[J].Knowledgebased Systems,2014,57:57-68.
[13]Ray S,Mahanti A.Improving prediction accuracy in trust-aware recommendersystems[C]//Proceedings ofthe 43rd Hawaii International Conference on System Sciences,Hawaii,2010:1-9.
Algorithm of reconstructing trust matrix by integrating user similarity and trust propagation
YUAN Fu-yong,MA Lin,LIANG Shun-pan
(School of Information Science and Engineering,Yanshan University,Qinhuangdao,Hebei 066004,China)
Aiming at the problems of Collaborative Filtering(CF),such as data sparsity and cold start,an algorithm of reconstructing trust matrix is proposed in this paper,which integrates user similarity and weighted trust propagation.Specifically,the trust relationship of those users whose similarity falls below a certain threshold is removed firstly.Then the users of rating matrix is added into trust matrix when the similarity between the users exceeds a certain threshold.Finally,weighted trust propagation is considered,in order to incorporate more trusted neighbors as well as distinguish trusted neighbors in a shorter distance with those in a longer distance.Experimental results on FilmTrust and Epinions data sets show that the proposed method can achieve superior prediction accuracy and solve cold user problem better.
collaborative filtering;user similarity;weighted trust propagation;reconstructing trust matrix
TP39
A DOI:10.3969/j.issn.1007-791X.2015.06.011
1007-791X(2015)06-0535-06
2015-09-05 基金项目:国家自然科学基金青年基金资助项目(51305383);教育部博士点专项基金资助项目(20131333120007)
*原福永(1958-),男,辽宁丹东人,教授,主要研究方向为网络信息检索技术,数据库技术,计算信任模型等,Email:fyyuan@ysu.edu.cn。
