原料乳中蛋白质与脂肪的近红外光谱快速定量研究
2015-10-17匡静云
匡静云, 管 骁*, 刘 静
(1.上海理工大学医疗器械与食品学院,上海 200093;2.上海海事大学信息工程学院,上海 200135)
随着生活水平不断提高,人们对乳制品的需求量日益增加。而随着我国乳业的迅速发展,乳制品的质量及安全也越来越受到重视。原料乳作为乳制品的基本原料,对乳制品的质量有重要影响。因此,原料乳的质量检测是控制乳制品质量中最为重要的环节。蛋白质与脂肪是牛奶中最主要的营养成分,根据最新的国家标准,鲜奶中蛋白质与脂肪含量应分别高于2.9%和3.1%[1,2]。
近红外光谱(NIRS)是近年来迅速发展起来的一项快速无损检测技术,该技术所含信息极其丰富,但由于有机物分子在近红外区的倍频与合频的吸收较弱、谱带复杂、重叠严重,因此准确提取有效的光谱信息存在一定难度。随着现代化学计量学方法的发展,为较好解决上述问题带来转机[3]。化学计量学方法可提取复杂且谱峰重叠的光谱信息,结合适当的光谱预处理及建模方法,可以有效除去噪声,解决光谱共线问题,得到准确可信的预测模型[4]。已有研究对原料乳中某单项指标建立了近红外光谱模型,并得到较高的准确度,但由于原料乳受产地、环境以及人为操作等因素影响,其组成成分存在差异。目前,很少有研究对原料乳中不同成分指标同时建立预测模型,这是近红外光谱技术在实际运用中的主要障碍之一[5 - 7]。
在近红外光谱分析中,合理地运用化学计量学手段可以有效提高模型质量。目前运用最多的方法是偏最小二乘法(Partial Least Squares,PLS)以及神经网络算法(Neural Networks)[8]。本文通过对采集的大量含有不同浓度蛋白质与脂肪的原料乳近红外漫反射光谱进行马氏距离(Mahalanobis Distance)剔除异常光谱,并结合主成分分析(Principal Component Analysis,PCA)提取得到有效特征变量,进一步利用反向传播神经网络(Back Propagation Neutral Network,BPNN)对蛋白质与脂肪的含量同时建模,结果表明该方法可以快速有效地预测不同原料乳样品中的多种成分含量。
1 实验部分
1.1 主要仪器
MPA型傅里叶变换漫反射近红外光谱仪(德国,BRUKER公司);RH-SC-10精密恒温水槽(南京润鸿实验设备有限公司);XHF-D高速分散器(宁波新芝生物科技股份有限公司)。
1.2 试样制备
本实验获得的原料乳共50份,分别来自上海、江苏等地的5个牧场,各样本的蛋白质、脂肪含量测定均在本实验室分别通过凯氏定氮法与盖勃法测定。为获取蛋白质与脂肪含量变化范围更广的样本,通过对不同批次原料乳中掺入不同含量的去离子水,共获得250组含有不同含量的蛋白与脂肪的原料乳样本,其蛋白与脂肪的含量分别在0.525%~3.58%和0.688%~3.95%范围内。
1.3 近红外光谱采集与数据处理
实验环境温度稳定在25 ℃,环境相对湿度为45%。采集样本光谱前,将样本通过高速分散器均质60 s。近红外光谱仪预热10 min,设定分辨率为8 cm-1,扫描次数为64次,每次实验均通过内部系统校检,以保证获得光谱可靠性,完成后用光纤探头伸入样本中下部,每组样本采集光谱10次,取10次光谱作为原始光谱数据。原始光谱谱区范围4 000~12 501 cm-1,共有2 203个数据点。数据采集软件为OPUS 6.5,数据处理分析软件为Matlab R2009b和SPSS17.0。
2 结果与讨论
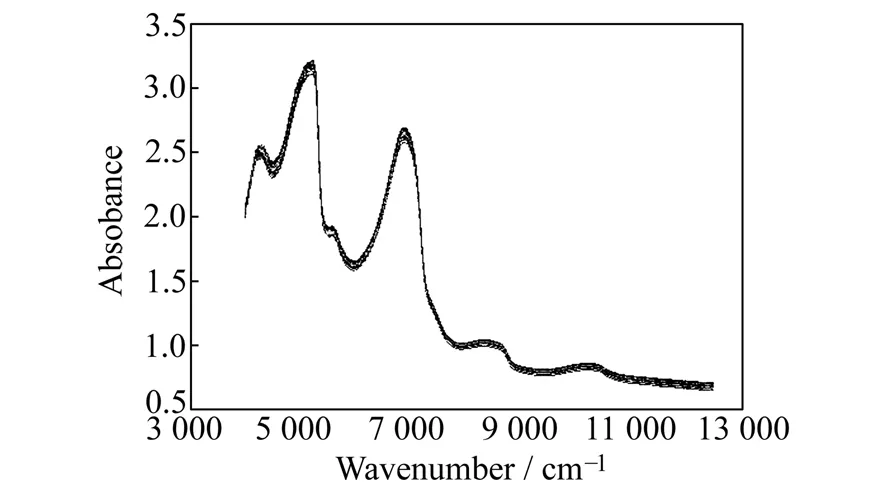
图1 代表性原料乳近红外光谱图Fig.1 Near infrared spectrum of representative raw milk samples
2.1 光谱的筛选及预处理
部分原料乳的代表性近红外光谱图如图1所示。由图可知,原料乳在4 000~5 500 cm-1、6 000~7 600 cm-1、7 800~8 800 cm-1、9 200~10 500 cm-1等波数区间均有较强的特征吸收。
为防止各样本的光谱采集存在偶然误差,对每个样本均进行了10次重复采集光谱,不可避免地出现了异常光谱。本实验采用马氏距离剔除异常光谱。它是一种有效计算两个未知样本集的相似度的方法。光谱的马氏距离是指样本光谱与平均光谱样本集的距离,计算公式如式(1):
(1)
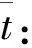
对光谱数据标准化处理后,每个样本的马氏距离大小由式(2)决定:
(2)
马氏距离可用来衡量一个样本对于整个标准样品集的影响。在近红外光谱分析中,hii表达了样本i对模型影响的大小,如果hii太大,对模型稳定性不利,说明i样本可能异常。
本实验中每组样本共采集光谱10次,将hii的阈值定为平均值的2倍,将超出范围的数据剔除后,再取每组光谱数据的平均值,作为该样本的最终图谱。随后对得到的光谱进行平滑处理,达到减低噪音对光谱影响的目的,最后将处理后的光谱作为进行下一步分析的最终图谱[9]。
2.2 特征信号提取
建立定量分析模型时,光谱信息的主因子数关系到模型的稳定性,主因子数太小模型会出现拟合不充分,主因子数太多会出现过拟合的现象[10]。因此本实验对不同光谱区间分别进行主成分分析,以主成分数与主成分累积比例为指标选择最佳主成分。假若某光谱区间主成分信息难以提取,则说明该区间不适合分析,由此逐步缩小光谱区间范围,筛选出最具代表性的主成分值,确定最佳预测光谱区间。最终本实验共确定出7个主成分因子,来自4个区间。如表1所示,其中在12 501~10 511 cm-1范围内,有多个蛋白与脂肪的吸收峰与反射峰,因此主成分提取率较高,而在6 600~7 000 cm-1范围内水的吸收峰影响严重,提取主成分相对困难[11]。
2.3 反向传播神经网络

表1 主成分分析结果
人工神经网络有多种模型,其中误差反向传播模型目前应用最为广泛。该网络结构包括输入层、隐含层和输出层,每层由若干个神经元(又称节点)组成,每个神经元均包含一定信息量,各层次神经元之间由连接权重实现相互联接,但层次内神经元之间无连接,神经元的信息经输入输出转换函数实现信息输出[12]。本实验首先将250组样本随机划分为训练集以及测试集,其中训练集225组,测试集25组,随后分别采用不同的隐含层数、隐含层节点个数、中间函数以及建立模型,并采用检验集样品来对模型的预测效果进行评定,评价参数选用预测相关系数R2、预测均方根差(RMSEP)。结果如表2所示。由表2中数据不难发现,在节点个数相同,传递函数固定的情况下,预测准确度与迭代次数成正比,而节点个数和中间函数与预测结果并无明显规律。由表2发现,当节点个数为8,传递函数为trainrp,迭代参数700次时,模型预测的准确度最高,其中对蛋白质与脂肪的预测模型R2分别为0.9883、0.9878,预测均方根差(RMSEP)为1.83%、1.85%。这表明此时预测值与化学测定值之间相关性最大,说明了该模型同时对蛋白与脂肪的预测能力非常优秀。
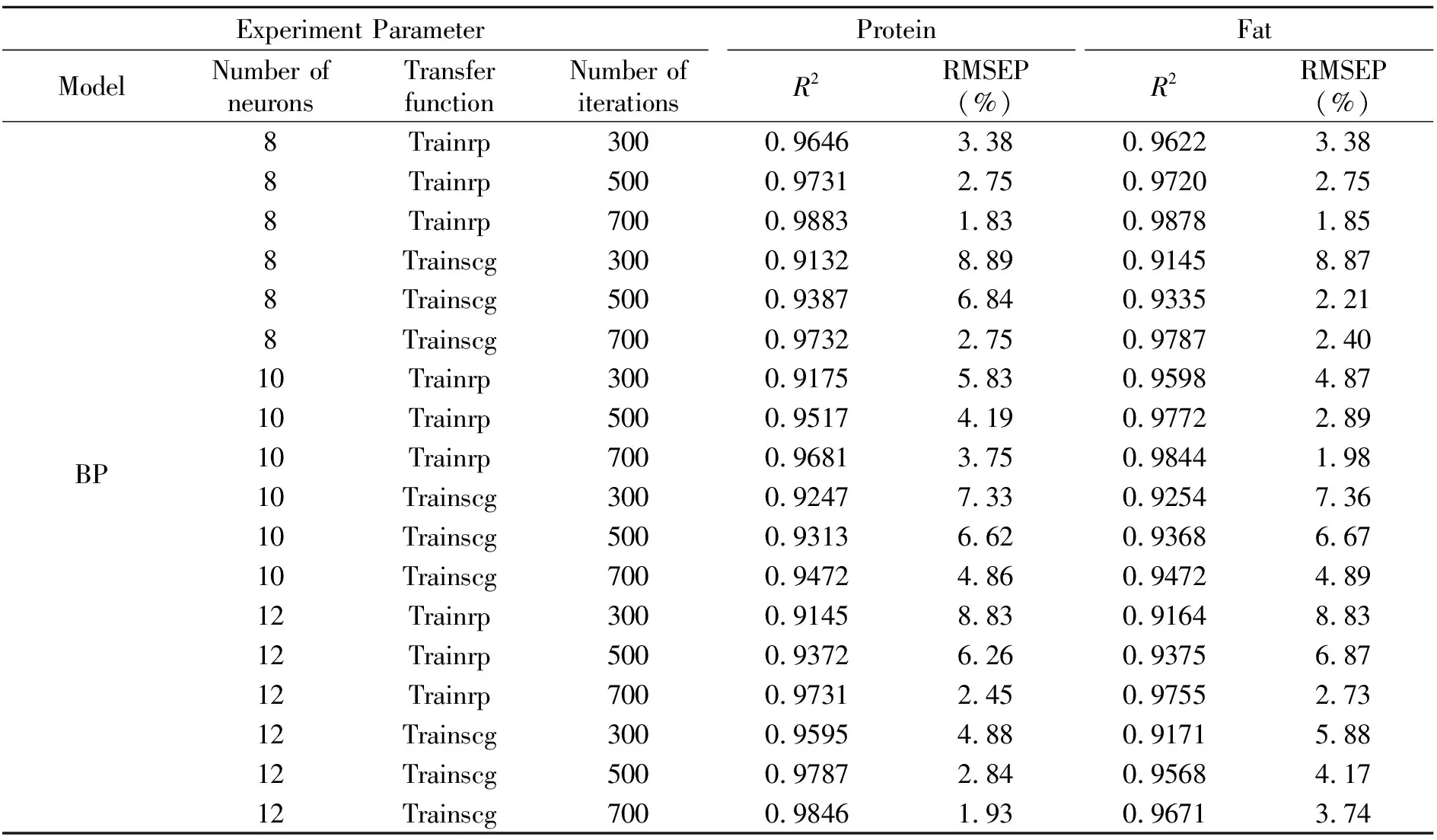
表2 BP模型对蛋白质与脂肪预测结果
3 结论
本文利用近红外光谱结合化学计量学方法对原料乳中蛋白质与脂肪进行定量分析,经过光谱异常值剔除、平滑预处理以及选择最有效的光谱区间和最适合的主成分因子数,通过反向传播神经网络建立模型,所得模型对蛋白质与脂肪预测相关系数R2分别为0.9883、0.9878,预测均方根差(RMSEP)为1.83%、1.85%,表明该方法可以对原料乳中蛋白质与脂肪含量进行准确的预测。下一步工作将围绕获取更多样本光谱作为建模数据,以进一步提高模型的预测能力以及稳定性,使该方法可实际运用于对原料乳的质量在线检测。
