近红外光谱结合判别分析法初步鉴别食用植物油的质量
2015-10-17顾从英唐倩倩相秉仁徐建平
顾从英, 唐倩倩, 相秉仁, 徐建平
(1.中国药科大学分析测试中心,江苏南京 210009;2.中国药科大学理学院,江苏南京 210009;3.山东绿叶制药有限公司药物分析研究室,山东烟台 264000;4.中健药业有限公司,广东中山 528437)
食用植物油含有人体必需的脂肪酸和脂溶性维生素,是人类日常生活的必需品。但一些不法商贩将劣质油作为合格食用油出售,严重损害消费者健康。因此,如何识别不合格的食用植物油就非常必要。但不合格的食用植物油在感官上是难以辨认的。目前,人们对食用油的检测常采用的方法有:用质谱方法分析食用油的溶剂残留[1]、砷化合物[2];用色谱方法分析食用油的抗氧化剂[3];用顶空固相微萃取结合多变量分析方法来区别食用油和烹调过的油[4]等。但这些方法的分析速度一般不快,而且经常需要复杂的样品前处理,因而会带来化学污染问题。近红外光谱[5,6]是利用物质在近红外光谱区的光学特性快速测定某种物质中的一种或多种化学成分含量的新技术,具有分析速度快、样品准备简单、不破坏样品、没有化学污染等优点[7,8]。近几年,近红外光谱在油的定量[9 - 13]和定性[14 - 16]分析中都有应用。
偏最小二乘判别分析法(PLSDA)[17,18]是一种基于偏最小二乘[19]回归分析的多元线性统计方法。最小二乘支持向量机(LSSVM)[20]是经典向量机的一种改进,降低了计算复杂性,加快了求解速度。偏最小二乘判别分析法及最小二乘支持向量机的判别分析的输出值都为表征类别的一组虚拟变量,对于未知样本,其预测值若接近代表某个类别的虚拟变量,则标明该样本属于对应的类别。近红外(NIR)光谱与偏最小二乘判别分析[21]相结合,或者与最小二乘支持向量机的判别分析[22,23]相结合都可以应用于定性分析方面。
本研究以过氧化值为参考,采用近红外光谱结合判别方法初步鉴别食用植物油的质量。首先使用Kennard-stone(KS)及SPXY(既考虑了光谱X矩阵又考虑了性质参数Y矩阵的训练集和验证集划分方法)这两种方法对训练集和验证集样本进行划分,再使用偏最小二乘判别分析和最小二乘支持向量机的判别分析对食用植物油的近红外光谱进行建模和预测,该方法可对食用植物油的质量控制提供参考。
1 实验方法
1.1 食用植物油样品的收集及过氧化值的测定
共收集了不同品种或同一品种但不同批次的210个食用植物油样品,根据ISO 3960-2001中的方法检测所有食用植物油样品的过氧化值。
过氧化值的测定过程简述如下:(1) 称取一定量的食用植物油于锥形瓶中;(2) 将食用植物油用50 mL的冰乙酸-异辛烷(体积比为60∶40)溶解;(3) 加入0.5 mL饱和KI溶液,盖上塞子使其反应,时间为1 min±1 s,同时振摇锥形瓶;(4) 立即加入蒸馏水;(5) 用约0.01 mol/L的Na2S2O3溶液滴定上述溶液,滴定的同时用力振摇,直至黄色几乎消失;(6) 添加约0.5 mL淀粉溶液,继续滴定,临近终点时不断振摇,使所有的碘从溶剂层释放出来,至蓝色消失,即为终点。过氧化值的计算公式为:

(1)
其中,V与V0为食用植物油和空白消耗的Na2S2O3溶液的体积,单位为 mL;c为Na2S2O3溶液的浓度,单位为 mol/L;m为食用植物油的质量,单位为 g;过氧化值的单位为 meq/kg。
1.2 近红外原始光谱的采集
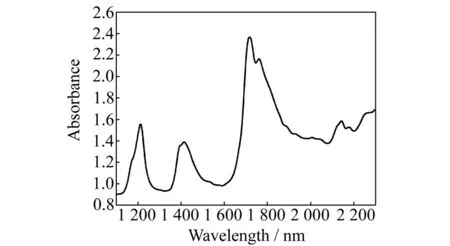
图1 金龙鱼食用调和油(第二代)的原始近红外光谱Fig.1 Original near infrared spectra for Jinlongyu edible blend oil(second generation)
利用配有积分球检测器的YDZ1-1近红外光谱仪(南京中地仪器有限公司)采集食用植物油的漫反射光谱,波长范围为1 100~2 300 nm,分辨率为2 nm,测量温度为25±2 ℃。总共得到210个近红外谱图。图1是金龙鱼食用调和油(第二代)的原始近红外光谱。
1.3 训练集样本的选择方法
近红外分析技术必须依赖数学模型。如何挑选具有代表性的样本组成训练集,是该技术的核心问题。根据不同的方法选择的样本作为训练集,模型的预测结果肯定也不同。常用的方法包括KS及SPXY法等。KS法[24]是通过计算样本之间的欧氏距离来选择训练集样本,具体步骤如下:
首先按照下式计算所有样本两两之间的欧氏距离,选择距离最大的两个作为第一个和第二个训练集样本。
(2)
其中,xp(j)和xq(j)是p和q样本在j波长处的光谱参数,J是光谱的波长个数,N是样本个数。
然后计算每个剩余样本与已选的两个样本之间的距离,其中最短距离被选择;等所有的剩余样本计算完,选择这些最短距离中的最长距离所对应的样本作为第三个训练集样本。
重复上一个步骤,直至所选的训练集样本的个数等于预先确定的数目为止。
KS法的一个缺点就是它仅仅考虑了样本间的光谱差异,而光谱差异包含着仪器差异和环境差异等,它们会干扰KS法选择样本。为了寻求样本间差异的更好的表示方法,在计算样本间差异时,最好同时考虑样本间的光谱差异和性质参数差异。
SPXY[25]法是在KS法的基础上发展而来的,是综合考虑光谱和性质参数差异来选择训练集。在公式(2)基础上考虑了性质空间因素dy(p,q), 即:
(3)
式中,yp和yq是p和q样本的性质参数。
SPXY法的逐步选择过程和KS法相似,但用dxy(p,q)(见公式(4))代替了dx(p,q)。式中将dx(p,q)和dy(p,q)分别除以它们在数据集中的最大值,是为了确保样本在光谱空间和性质空间具有相同的权重。
(4)
SPXY法能够有效地覆盖多维向量空间,从而有可能改善所建模型的预测能力。
1.4 软件
Matlab7.6.0(Math Works Inc.Natick,USA), PLS 6.2 版工具箱(http://www.eigenvector.com/software/pls-toolbox.htm 下载), LSSVMlab v.1.8(http://www.esat.kuleuven.be/sista/lssvmlab 下载)。
2 结果与讨论
2.1 划分训练集与验证集
分别采用KS法及SPXY法从210个样本中抽取三分之二的样本作为训练集,另外三分之一的样本作为验证集。对于不同的划分训练集和验证集的方法,训练集中都有140个食用植物油样本,验证集中都有70个食用植物油样本。
2.2 偏最小二乘判别分析模型及预测结果
根据国际食品法典委员会规定的食用油脂的过氧化值卫生标准,过氧化值小于或等于10 meq/kg的食用植物油为合格油,否则为不合格油。因此在偏最小二乘判别分析法中,将过氧化值小于或等于10 meq/kg的食用植物油样本赋值为0,将过氧化值大于10 meq/kg的食用植物油样本赋值为1。采取留一交互验证,阈值是PLS Toolbox 6.2 自动设定的。假如预测值大于阈值,则判断该食用植物油的质量不合格;假如预测值小于阈值,则判断该食用植物油的质量合格。偏最小二乘判别分析模型的预测能力是用所有样本的总正确率来评估的。一般认为总正确率越高,模型越好。
表1是不同的划分训练集和验证集方法及不同的前处理方法的偏最小二乘判别分析的预测结果。由表1可见,对同种划分训练集和验证集的方法,数据中心化及方差比例的预测结果一般稍好于正交信号校正。最好的预测结果是:用SPXY法划分训练集和验证集,当前处理方法为数据中心化或者方差比例时,训练集中只有1个样本被误判,验证集中也只有11个样本被误判,所有样本的判别总正确率为94.3%。图2和图3分别是用SPXY法划分训练集和验证集时前处理方法为数据中心化的偏最小二乘判别分析的训练集和验证集的预测结果图。
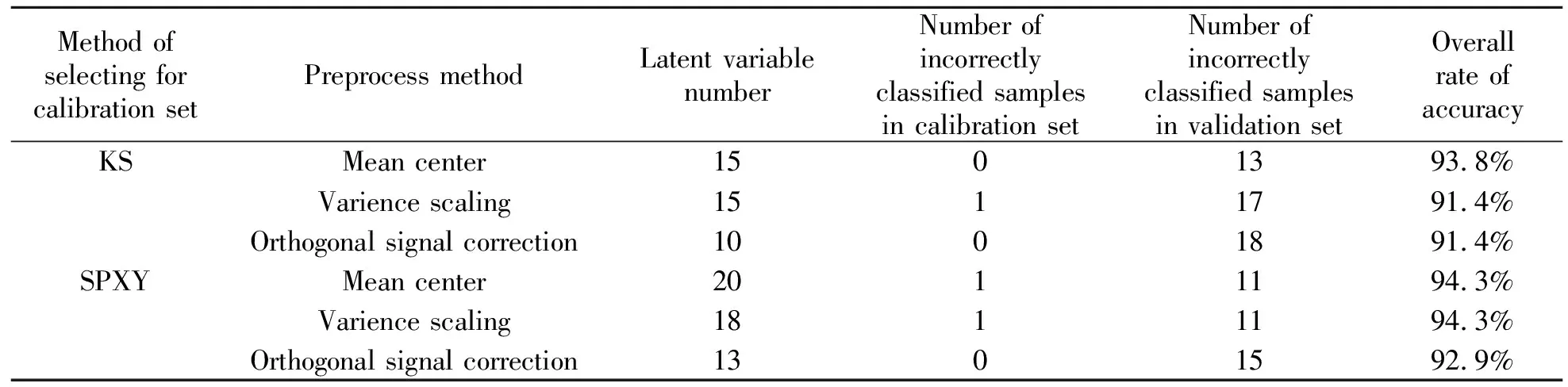
表1 偏最小二乘判别分析的预测结果

图2 用SPXY法划分训练集和验证集时前处理方法为数据中心化的偏最小二乘判别分析的训练集的预测结果Fig.2 Prediction results in calibration set(partial least squares discriminant analysis,pretreatment method is mean centre,and method of selecting for calibration set is SPXY)
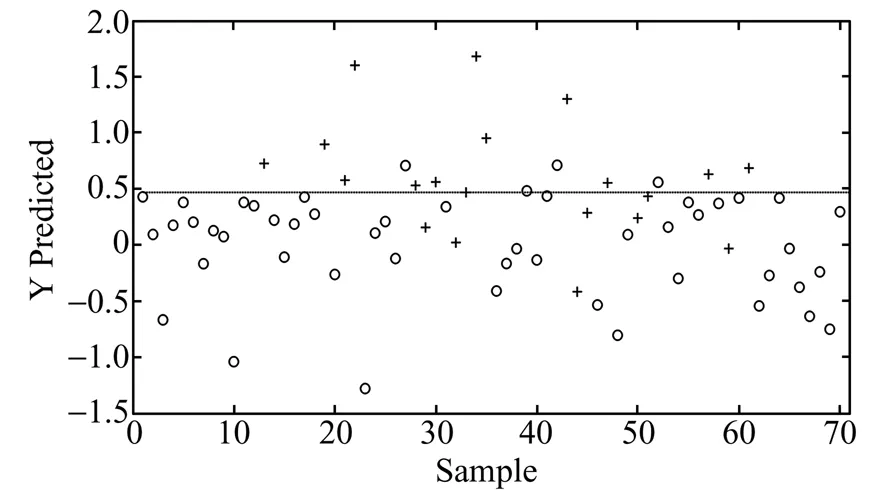
图3 用SPXY法划分训练集和验证集时前处理方法为数据中心化的偏最小二乘判别分析的验证集的预测结果Fig.3 Prediction results in validation set(partial least squares discriminant analysis,pretreatment method is mean centre,and method of selecting for calibration set is SPXY)
表1中的潜变量数是根据总正确率并参照交互验证均方根误差选择的。图4是用SPXY法划分训练集和验证集时前处理方法为数据中心化的总正确率与潜变量数之间的关系。图5是用SPXY法划分训练集和验证集时前处理方法为数据中心化的交互验证均方根误差与潜变量数之间的关系。

图4 用SPXY法划分训练集和验证集时前处理方法为数据中心化的偏最小二乘判别分析总正确率与潜变量数之间的关系Fig.4 Relationship between overall rate of accuracy and latent variable number(partial least squares discriminant analysis,pretreatment method is mean centre,and method of selecting for calibration set is SPXY)

图5 用SPXY法划分训练集和验证集时前处理方法为数据中心化的偏最小二乘判别分析交互验证均方根误差与潜变量数之间的关系Fig.5 Relationship between RMSECV and latent variable number(partial least squares discriminant analysis,pretreatment method is mean centre,and method of selecting for calibration set is SPXY)(RMSECV:root-mean-square-error of cross validation)
2.3 最小二乘支持向量机模型及预测结果
最小二乘支持向量机的判别分析将过氧化值小于或等于10 meq/kg的食用植物油样本赋值为-1,认为质量合格,将过氧化值大于10 meq/kg的食用植物油样本赋值为1,认为质量不合格。
采用径向基核函数[26],构建最小二乘支持向量机模型需要先确定两个重要模型参数,即正则化参数Gam和核函数参数Sig2。采用二步格点搜索法和留一交叉验证法相结合对这两个模型参数进行寻优。前处理方法为数据中心化。以KS法划分训练集和验证集时,Gam和Sig2的搜索范围分别为2.54~7 568.62、1.89~280.45。以SPXY法划分训练集和验证集时,Gam和Sig2的搜索范围分别为0.35~1 055.85、2.33~346.08。优化后的Gam和Sig2值见表2。
不同的划分训练集和验证集方法的最小二乘支持向量机的预测结果见表2。不管用KS法还是用SPXY法划分训练集和验证集,前处理方法为数据中心化时,所有样本的判别总正确率都在94%左右。

表2 最小二乘支持向量机的预测结果
ROC曲线被用来评价二分类最小二乘支持向量机模型的性能。图6和图7分别为用SPXY法划分时的最小二乘支持向量机模型的训练集和验证集ROC曲线,其中横坐标为1-特异度,纵坐标为灵敏度,ROC曲线下的面积越大表示两类样本的分类准确率越高。由图6和图7可知,所建最小二乘支持向量机二分类模型的训练集和验证集ROC曲线面积分别为0.9992和0.9160,表明此模型判别能力较强。
2.4 训练集选择方法的比较
由表1和表2可见,虽然训练集与验证集的样品数目相同,但偏最小二乘判别分析和最小二乘支持向量机的预测结果略有不同。对于相同前处理方法的偏最小二乘判别分析,SPXY法的预测结果比KS法稍好(表1);对于相同前处理方法的最小二乘支持向量机,SPXY法的预测结果和KS法相近(表2)。可见,不同的训练集选择方法对PLSDA和LSSVM的预测结果影响均较小。

图6 用SPXY法划分训练集和验证集时前处理方法为数据中心化的最小二乘支持向量机的训练集的ROC曲线Fig.6 Receiver operating characteristic curve of calibration set(least squares support vector machines,pretreatment method is mean centre,and method of selecting for calibration set is SPXY)
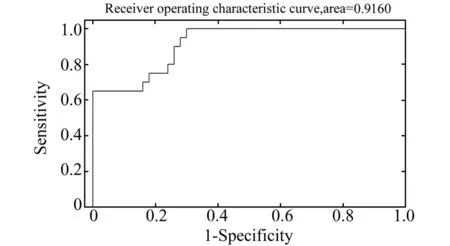
图7 用SPXY法划分训练集和验证集时前处理方法为数据中心化的最小二乘支持向量机的验证集的ROC曲线Fig.7 Receiver operating characteristic curve of validation set(least squares support vector machines,pretreatment method is mean centre,and method of selecting for calibration set is SPXY)
2.5 偏最小二乘判别分析与最小二乘支持向量机的判别能力比较
当前处理方法为数据中心化时,利用SPXY法划分训练集和验证集,PLSDA和LSSVM的判别总正确率分别为94.3%和93.8%;用KS法划分训练集和验证集时,PLSDA与LSSVM的判别总正确率分别为93.8%与94.3%。可见在以过氧化值为参考方法的基础上,PLSDA与LSSVM这两种方法判别能力相近,都可以与近红外光谱结合用来初步鉴别食用植物油的质量。
3 结论
根据过氧化值为参考方法,用偏最小二乘判别分析和最小二乘支持向量机这两种方法对食用植物油的近红外光谱进行建模和预测,可初步鉴别食用植物油的质量。实验分析了数据中心化、方差比例、正交信号校正三种不同的前处理方法对PLSDA预测结果的影响,对同种划分训练集和验证集的方法,数据中心化的预测结果都比较好。同时分析了KS法及SPXY法这两种不同的训练集和验证集划分方法对PLSDA和LSSVM的预测结果的影响,结果表明训练集和验证集划分方法都对两者的影响较小,最后比较PLSDA与LSSVM的判别能力,结果显示,在以过氧化值为参考方法的基础上,两种方法的判别能力相近。
近红外光谱法快速价廉,PLSDA可靠直观,LSSVM适用范围广。近红外光谱法结合这两种判别法中的任意一种很快就可以测一个样品,相对于常用的质谱法或色谱法,既快速价廉又容易操作。将这两种方法中的任意一种用于初步筛选合格的食用植物油具有一定的现实意义。
