CF-HNLBI:一种新的闪存数据库B-树索引
2015-10-13刘颖杰林子雨赖永炫
刘颖杰,林子雨*,赖永炫
(1.厦门大学信息科学与技术学院,2.厦门大学软件学院,福建厦门361005)
CF-HNLBI:一种新的闪存数据库B-树索引
刘颖杰1,林子雨1*,赖永炫2
(1.厦门大学信息科学与技术学院,2.厦门大学软件学院,福建厦门361005)
提出了一种新的基于B-树的闪存数据库索引——CF-HNLBI索引.使用链表组织缓冲区中的更新信息,减少了缓冲区遍历时间,通过链表结构减少冗余信息,提高了缓冲区利用率.将缓冲区分为冷区和热区,并采用基于更新信息频度的替换算法,有效地减少了闪存写操作次数.实验结果表明,CF-HNLBI索引比其他已有索引具有更好的性能.
闪存;数据库;索引;B-树
闪存是一种电可擦除可编程只读存储器(electrically erasable programmable read only memory,EEPROM),具有非易失、读写速度快、抗震、低功耗、体积小等特性,目前已广泛应用于嵌入式系统、航空航天、消费电子等领域[1-2].随着闪存技术不断发展,其相对于磁盘的竞争优势更加明显,已经有越来越多的企业把基于闪存的存储产品(比如固态盘)作为数据库系统的底层存储介质[3].闪存比磁盘具有更高的读写速度,因此,闪存数据库系统可以获得比传统的磁盘数据库系统更好的性能.但是,由于传统的数据库系统是面向磁盘设计的,而闪存具有和磁盘截然不同的物理特性[4](比如闪存读写不对称以及随机读写与顺序读写具有相近的性能),这使得现有的数据库的数据结构和算法无法与闪存物理特性相匹配,因此,如果直接将传统数据库应用在闪存上,将无法发挥闪存的优良性能,在某些特殊负载的情况下(如随机写密集型应用),甚至会导致数据库性能的严重下降[5-6].因此,必须重新设计针对闪存数据库的数据结构和算法.目前,在这个方面已经存在大量相关的研究工作[7-22],面向闪存的数据库索引技术是其中的一个研究热点.
数据库索引记录了数据和其存储地址的映射关系,利用索引可快速访问数据库表中的特定信息,降低I/O操作代价、提高查询效率.闪存相对于磁盘具有读写不对称的特性,其写代价远远高于读代价,而传统的数据库索引结构并没有考虑这个特点.以B-树索引为例,B-树节点更新往往只是针对小部分数据的修改,而闪存以页为最小单位进行读写,少量数据更新也会使整个页面被重写;同时,由于闪存的写前擦除特性,索引更新也会带来大量擦除操作,这将极大降低索引性能和寿命.

为解决上述问题,本文首先提出了一种基于最大节点更新的HNLBI(head node list B-tree indexing)索引,它以头结点链表的形式组织缓冲区中的信息,并将节点信息存放在链表的头节点中.HNLBI索引相对于传统索引结构具有3个优势:1)节点信息集中存储在头节点中,进一步减少了缓冲区中的信息冗余;2)在发生查询操作或者缓冲区更新操作时,不必遍历整个缓冲区,提高了时间效率;3)缓冲区发生替换操作时,HNLBI索引遍历头节点选择更新信息最多的节点刷新至闪存,提高了闪存的写操作效率,并减少了闪存写次数.由于朴素的HNLBI索引并没有利用节点访问频度的信息,这使得更新频繁的节点可能被过早地替换出缓冲区,因此,在HNLBI索引的基础上,我们提出了改进之后的CF-HNLBI(cold-first head node list B-tree indexing)索引,该索引将缓冲区分为冷区和热区,分别存放不同访问频度的节点信息,当缓冲区满时,替换操作发生在冷区.这使得被频繁更新的节点能够更长时间地驻留在缓冲区中,进一步减少了闪存写操作的次数.实验结果表明,CF-HNLBI索引相对于传统索引能够有效提高缓冲区利用效率,减少闪存写操作的次数,并且在不同访问模式的工作负载下,都能够取得比其他已有算法更好的性能.
1 相关工作
闪存数据库的相关研究包括若干方面:缓冲区管理、数据库索引管理、查询处理和事务恢复等.不少研究人员提出了许多具有代表性的研究方法[7-13],其主要思想分为2种:索引结构优化和延时更新.
优化索引结构是提高索引性能的一种有效途径,通过索引结构的更改可以降低索引更新代价并提高数据查询效率,目前主要的优化方式包括μ-Tree索引[11]、Mircro Hash索引[12]、PBFilter索引[13]等.延时更新方法将数据更新引发的索引变化首先缓存在内存,当缓存的数据满足设定条件时再执行批量更新操作.延迟更新通过消除冗余操作和批量提交的方式减少了写操作代价,相关的主要算法有:BFTL[7]、IBSF[8]、LA-Tree[9]、Lazy-Update B+-Tree[10]等.由于本文采用第2类方法,即延时更新,因此,这里重点介绍该领域的相关研究.
BFTL[7]由缓冲区和节点转换表组成,当针对B-树的某个节点做插入、删除或者更改操作时,更新信息将首先被缓存在缓冲区中;缓冲区满后,信息将被更新到闪存中,同时,BFTL将为这些信息建立对应的索引单元,并写入闪存物理页中.索引单元和节点的相对应关系通过节点转换表来获得.BFTL存在以下缺点:1)由于B-树的节点信息分散在不同的物理页,因此,当访问一个节点时往往引起多次的读操作;2)节点转换表必须存储在内存中并不断增长,这会消耗大量的内存空间;3)由于BFTL缓冲区只是按序记录更新信息,因此,当节点发生分裂或其他操作时容易导致过多的冗余信息,使得缓冲区利用率较低.
IBSF[8]是针对BFTL的改进方法,它取消了节点转换表并对缓冲区中的信息进行了处理,这在一定程度上减少了冗余信息.IBSF的主要思想是:1)将关于同一个节点的信息存在同一个闪存物理页中,因此不再需要节点转换表;2)删除缓冲区中的冗余节点信息从而推迟写闪存的时间.IBSF的主要缺陷表现在以下几个方面:1)缓冲区每个更新单元除记录更新信息外,还需记录所属节点的信息,这造成了信息冗余;2)缓冲区中信息依然采用按序记录的方法,导致每次查询或者刷新操作时都要遍历缓冲区;3)执行缓冲区替换操作时,没有考虑更新信息的冷热属性,更新频繁的节点数据往往会被刷新至闪存,造成更多的写操作.
相反,本文提出的CF-HNLBI索引能够有效地解决上述算法中存在的各种问题,紧凑地组织缓冲区中的更新信息,尽可能地提高缓冲区利用率,并依据数据访问频度以及节点更新信息的数量提供高效的替换算法,极大地降低了索引更新的写代价.
2 基于最长节点链表替换算法的B-树索引HNLBI
传统B-树索引存在缓冲区利用率不高,闪存写次数仍然较多的问题.为了克服上述缺陷,本文提出了基于最长节点链表替换算法的B-树索引HNLBI.
2.1 传统B-树索引的不足
传统的B-树索引每一次更新都会导致一次闪存写操作,频繁发生的索引更新将会导致频繁的闪存写操作.为了提高闪存数据库索引的性能,很多关于闪存数据库B-树索引的研究,都采用缓冲区进行批量索引更新,有效降低了B-树频繁更新引起的闪存写代价;但是,通过大量实验我们发现,它们都没有高效地利用缓冲区空间,同时,在减少闪存的写操作次数方面还有很大的改进空间.
IBSF[8]是一种典型的采用延迟更新策略的B-树索引结构,对于B-树索引节点的更新信息首先会被写入缓冲区中,在满足适当条件时,将属于同一个B-树节点的更新信息从缓冲区中写入到同一个闪存页中,并且不需要使用节点转换表.这里通过一个实例来说明IBSF的主要思想.
例1 如图1所示,我们对B-树索引进行一系列的值插入和删除操作.图2中op(n)表示针对B-树的实际操作,即操作单元.op(1)表示向节点B插入3的操作,当op(1)发生时,IBSF在缓冲区中新建一个存储单元N(1),存放该操作的相关信息;当发生删除操作时,IBSF创建带有位图的删除索引单元,如对于操作单元op(5)所表示的针对节点B删除8的操作, IBSF会为该删除操作创建新的缓冲区存储单元N(5),并将N(5)的键值区域替换为删除信息位图(如100 000)来记录删除信息.当新的插入或者删除操作到来时,IBSF依据操作单元中包含的键值对已存在的所有存储单元进行扫描;对于键值相同的存储单元, IBSF算法删除旧的存储单元,创建新的存储单元,比如,op(9)所表示的删除5操作发生时,IBSF会把已存在的、与插入5这个操作对应的缓冲区中的存储单元N(4)删除,然后创建N(9)存储单元.当缓冲区满时会发生替换操作,IBSF根据FIFO选择缓冲区存储单元N(1),然后,扫描整个缓冲区,找到所有与N(1)同属于一个节点的存储单元N(3)和N(9),批量刷新至闪存中.

图1 B-树更新操作示意图Fig.1 The operation of B-tree
IBSF索引虽然在一定程度上提高了缓冲区利用率,但是,在新的插入或删除信息到来时,为删除冗余信息,IBSF总是需要遍历缓冲区中的所有存储单元;在发生替换操作时,选择要替换的节点之后,IBSF仍然需要遍历整个缓冲区,造成很高的扫描代价;此外, IBSF的替换算法的设计过于简单,没有考虑到节点更新不均衡的特点.上述缺陷的存在,使得IBSF在许多实际应用中不能取得很好的效果.
2.2 HNLBI索引的基本思想
为了克服以IBSF为代表的传统B-树索引的缺陷,提升闪存数据库B-树索引的性能,本文提出了一种新的闪存数据库B-树索引,即HNLBI.HNLBI索引采用延时更新的索引优化策略,利用缓冲区组织节点更新信息,并在适当的时候批量更新至闪存,这种批量更新的方式可以有效减少闪存的写操作次数.需要指出的是,采用这种优化策略以后,在执行查找操作时,需要结合缓冲区中的信息来重构索引,这会在一定程度上增加了额外的开销;但是,由于写操作次数大量减少而带来的收益远远大于这种额外增加的开销,因此,HNLBI索引可以获得较好的整体性能.接下来我们详细介绍HNLBI索引的相关策略.
HNLBI索引采用与IBSF类似的索引单元存储策略,对B-树索引节点的更新信息(插入或删除信息)首先写入缓冲区中,在满足适当条件时,将对于同一个B-树节点的信息写入同一闪存页中,不需要使用节点转换表.与IBSF不同的是,HNLBI索引将缓冲区内的索引单元重新组合,并采用基于最长节点链表的缓冲区替换算法,其主要思想如下:
(i)当关于某一节点的更新信息第一次出现时, HNLBI首先在缓冲区中为该节点创建头节点,并将该头节点插入头节点链表中;头节点中记录了该节点的具体信息(如链表长度),此外,头节点中还使用一个位图来表示删除操作;如果该更新信息是插入操作,则在头节点后添加存储节点,保存插入的键值;如果该更新信息是删除操作,则更新头节点中的位图来记录删除信息.
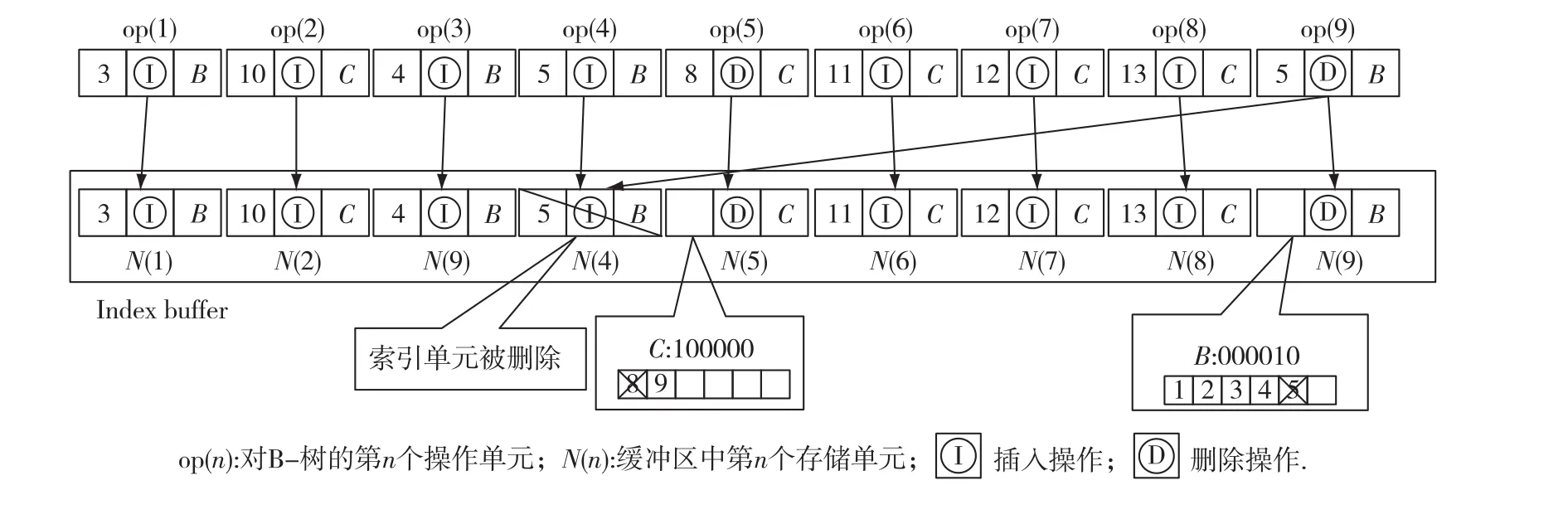
图2 IBSF算法缓冲区情况Fig.2 The buffer of IBSF
(ii)当关于某个已存在节点的更新信息到来时, HNLBI首先遍历头节点链表,找到该节点;若该更新信息是插入操作,则在该节点的更新信息链表尾部创建新的存储节点,记录插入信息;若该信息是删除信息,则遍历该节点的更新信息链表,若发现已存在键值相同的存储节点,则该已存在的存储节点是冗余的,删除该冗余节点后,更新头节点中的位图记录删除信息,若没有冗余节点,则直接更新头节点中的位图来记录删除信息.
(iii)HNLBI索引的头节点链表以及每个节点的更新信息链表,实际上连接形成了一个头结点链表.当缓冲区满要进行替换操作时,遍历头节点链表,根据头节点信息找出最长的节点更新信息链表进行替换,这样的替换策略可以为缓冲区提供更多的空余空间,有效减少了替换操作发生频度,从而在较大程度上减少了闪存写操作次数.
为了更好地理解HNLBI索引的核心思想,下面给出一个实例.
例2 当发生如图1的索引更新时,HNLBI对应的缓冲区信息变化情况如图3所示.在图3中,op(n)表示针对B-树的实际操作,即操作单元.op(1)表示向节点B插入键值3的操作,当该操作发生时,由于缓冲区此时没有节点B的相关更新信息链表,因此,创建关于节点B的头节点,并在头节点后增加存储节点,键值为3,对于op(2)操作单元进行同样处理;当op(3)索引单元所示的操作发生时,遍历头节点链表,找到与op(3)相关的节点B后,遍历节点B的节点更新信息链表,发现op(3)插入的键值与已存在的存储节点无冲突,增加存储节点,键值为4;当发生删除操作时,如op(5)操作单元所表示的删除节点C中8的操作,HNLBI找到op(5)相关的节点C的更新信息链表并遍历,没有发现需要删除的存储节点,因此,直接修改头节点C中的位图信息;当发生op(9)所表示的删除节点B中5的操作时,遍历op(9)相关的节点B的更新信息链表,发现该链表中存在键值与op(9)同样为5的存储节点,因此,如图所示删除该节点,然后,修改头节点B中的位图信息,将相应的位设置为1来表示删除.当缓冲区满时,遍历头节点链表,找到最长的链表,然后将其替换出缓冲区,在本例中选择节点C的更新信息链表.
2.3 算法设计
HNLBI索引的插入过程如算法1所示.插入前首先检查缓冲区是否已满,若缓冲区没有足够空间,则遍历头节点链表,根据头节点中记录的节点更新信息链表长度,选择最长的节点更新信息链表链表刷新至闪存.然后,遍历头节点链表,查找更新信息对应的头节点是否存在.若已经有对应头节点存在,则在该头节点的更新信息链表尾部插入存储节点,并更新头节点中的节点相关信息.若对应的头节点不存在,则创建该头节点,加入到头节点链表中,并在该头节点所在的链表中插入新的存储节点,然后更新头节点中的信息.


图3 HNLBI缓冲区示意图Fig.3 The buffer of HNLBI

HNLBI索引对于删除操作的处理如算法2所示.对于删除操作,首先检查缓冲区是否已满,若缓冲区满则执行刷新操作,选择最长的节点更新信息链表刷新至闪存;然后查找头节点链表,如果对应的头节点已存在,则查找要删除的键值是否存在于该节点对应的更新信息链表中,若存在,则删除该键值对应的存储节点,若不存在,则直接更新该头节点信息.如果对应的头节点不存在,则创建对应的头节点,用来记录删除操作.

2.4 与IBSF索引的比较
IBSF索引采用按序存储索引单元的方式组织缓冲区中的数据,这样的结构导致在执行插入、删除、查找以及批量更新操作时需要遍历整个缓冲区;此外,对于IBSF的每一个索引单元都必须记载对应的节点信息,这也造成了一定的信息冗余.而在HNLBI索引中,进行相关操作时,首先查找对应的节点,然后针对相关的节点信息进行集中处理,节省了遍历所需的时间;此外,HNLBI索引中的节点信息集中记录在头节点中,这样,头节点之后的节点仅需要记录插入的键值,这大大减少了信息冗余.另外,由于IBSF算法没有对缓冲区中的信息进行归类,这导致在批量更新时,IBSF索引只能采用FIFO或者LRU算法.而HNLBI索引采用了基于最长节点链表的替换算法,根据头节点中记录的信息,选择更新信息最多的节点(即节点的更新信息链表最长)将其刷新至闪存中.通过图2和图3的比较可知,IBSF选择节点B替换出缓冲区,HNLBI索引的更新策略选择占用更多缓冲空间的节点C替换出缓冲区,这使得闪存闪存写操作有更高的效率,并为缓冲区节省了更多空间.
3 基于冷热分区替换算法的CF-HNLBI索引
HNLBI索引虽然重新组织了缓冲区中的更新信息,并选择最长节点更新信息链表替换出缓冲区,但是没有很好地利用数据使用频度的信息.于是,我们提出了针对HNLBI索引的改进版本——基于冷热分区的替换算法的CF-HNLBI索引.CF-HNLBI针对HNLBI算法的缓冲区替换策略进行了改进,加入了冷热分区的概念,热区中存放更新频繁的节点数据,冷区中存放更新不频繁的节点数据.当发生缓冲区替换时,CF-HNLBI只选择冷区中的节点进行替换.
3.1 改进策略
HNLBI索引的主要缺陷是缓冲区替换策略只是简单选择最大长度的更新信息链表进行替换.但是,当某个B-树节点更新频繁时,即使该B-树节点的更新信息在缓冲区中多于其他B-树节点,也应该使该B-树节点驻留更长的时间,从而可以防止对同一个B-树节点在某一段时间内多次写入闪存.
为解决该问题,CF-HNLBI索引将缓冲区头节点链表分为冷区和热区,并为头节点设置冷标识位来反映该头节点所对应的B-树节点的更新频度.当冷标识位为1时,表明该头节点为冷节点,其对应的B-树节点更新不频繁;当冷标识位为0时,表明该头节点为热节点,其对应的B-树节点更新频繁.此外,当缓冲区中的冷节点被再次访问时,需要将其标记为热节点,即将冷标识位设置为0.CF-HNLBI的具体细节如下:
(i)将索引缓冲区分为冷区和热区,冷区大小设定下限阈值,热区中存放至少更新两次的节点,冷区中存放只更新过一次的节点.
(ii)每当新的更新信息被加入到缓冲区之前,首先检查缓冲区是否已满,若缓冲区已满,则在冷区中执行缓冲区替换策略.具体方法是,遍历冷区中的头节点链表,获取头节点中记录的更新信息链表长度信息,选择冷区中最长的更新信息链表驱逐出缓冲区并批量写入闪存.
(iii)缓冲区中为某个B-树节点新建立的头节点存放在冷区,此时该头节点冷标识位为1,是一个冷节点;当该B-树节点再次发生更新时,将该B-树节点对应的更新信息链表转移到热区MRU(most recently used)位置,并设置冷标识位为0;当冷区中有更新信息链表转移至热区或者冷区中有更新信息链表被驱逐出缓存时,如果冷区中的更新信息链表所占的空间小于冷区大小的下限阈值,则从热区中选择若干个更新信息链表转移至冷区;当需要从热区中选择更新信息链表转移至冷区时,首先从热区头节点链表的LRU (least recently used)位置开始遍历,如果遇到冷标志位为1的头节点,说明它是一个冷节点,则将其更新信息链表转移至冷区,如果冷标识位为0,则给该头节点第2次机会,将该头节点的冷标识位设置为1,继续扫描其他头节点,如果没有发现合适节点,则重新遍历热区,直至找到合适节点转移至冷区为止.如果热区中的某个头节点对应的B-树节点被更新,则将该头节点的冷标识位重新设置为0,并将其移动至热区的MRU位置.
CF-HNLBI索引所采用的替换算法细节如算法3所示.


3.2 实 例
为了更好地理解CF-HNLBI索引的基本思想,下面给出一个具体实例.
例3 缓冲区初始状态如图4(a)所示,我们假设头节点所占的空间为存储节点的2倍,缓冲区空间上限为可容纳24个存储节点,而冷区空间的下限阈值为容纳11个存储节点.缓冲区包含6个B-树节点(D、E、F、G、H和I)的相关信息,这里用B-树节点的名称作为其对应的缓冲区头节点的名称,D、E、F位于热区,G、H、I位于冷区,其中,热区中的D与F冷标识位为1,E冷标识位为0,冷区中的B-树节点的冷标识位均为1.当针对B-树节点的更新信息到达缓冲区时,将包含以下两种可能的情况:
(i)该B-树节点所对应的头节点已存在于缓冲区中的情况.在某个时刻,一个针对节点F的更新操作到达,CF-HNLBI索引检查缓冲区后发现其所对应的的头节点F已经在缓冲区中存在(热区中),则更新头节点F的链表信息,然后将F的冷标识位设置为0,并将其移动至热区的MRU位置(如图4(b)所示).在针对F的操作处理结束后,一个针对B-树节点I的更新操作到达,CF-HNLBI索引检查缓冲区后发现其所对应的头节点I已在缓冲区中存在(冷区中),则更新头节点I的链表信息,然后,设置其冷标识位为0,使其成为热节点,并将头节点I的更新信息链表移动至热区的MRU位置.此时,CF-HNLBI检测到冷区更新信息不足,冷区中只有8个存储节点,低于设定的下限阈值(即11个存储节点),CF-HNLBI索引从热区链表的LRU位置开始遍历,发现E冷标识位为0,是一个热节点,则将其设置为1,使其变为冷节点,给它第二次机会;然后,继续遍历,发现头节点D的冷标识位为1,是一个冷节点,则将其直接移动至冷区,此时检测发现冷区更新信息已经足够(冷区拥有13个存储节点,大于下限阈值11),停止操作(如图4(c)所示).
(ii)该B-树节点所对应的头节点不存在于缓冲区中的情况.在上述操作完成后,一个新的针对B-树节点J的更新操作到来.此时缓冲区已有24个存储节点,达到缓冲区空间上限值,于是CF-HNLBI索引遍历冷区头节点链表,读取头节点中记录的更新信息链表长度信息,找到更新信息链表最长的头节点G,将其驱逐出缓冲区并写入闪存;然后,CF-HNLBI遍历缓冲区,发现头节点J不存在,则创建头节点J并将其插入冷区头节点链表中;这时冷区只有10个存储节点,再次低于设定的下限阈值11,因此CF-HNLBI选择热区中的头节点E,将其移动至冷区(如图4(d)所示).
3.3 性能分析
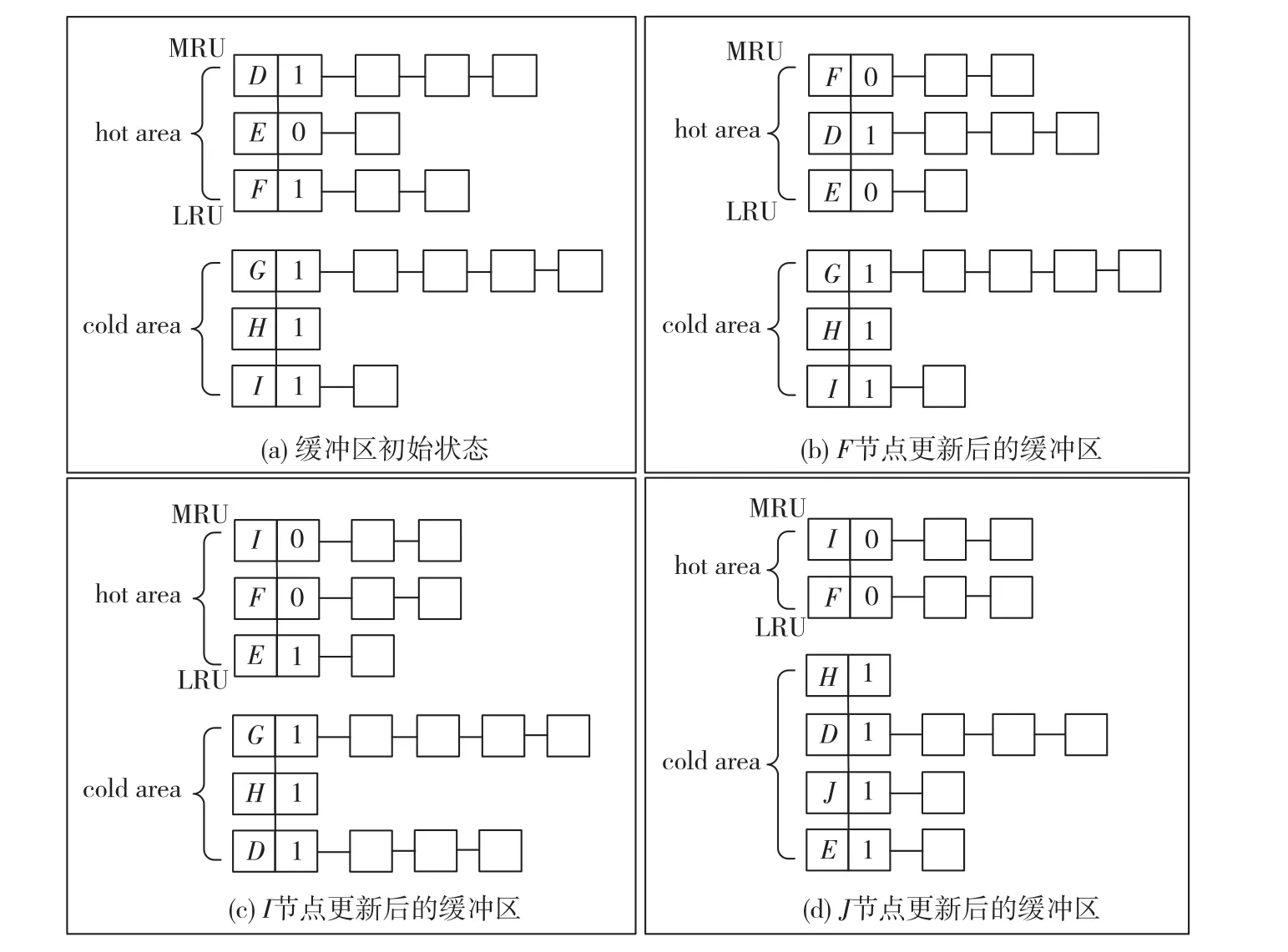
图4 CF-HNLBI索引冷热缓冲区示意图Fig.4 The cold-hot buffer of CF-HNLBI
相对于IBSF而言,本文的CF-HNLBI索引采用了冷热分区的机制,这虽然增加了一定的时间开销,但是与IBSF相比,本文算法不需要遍历整个缓冲区,因此总的时间开销相对于IBSF减少了,这在之后的实验中将得到进一步验证.
在读写性能方面,我们分别分析不同索引读闪存的性能和写闪存的性能.

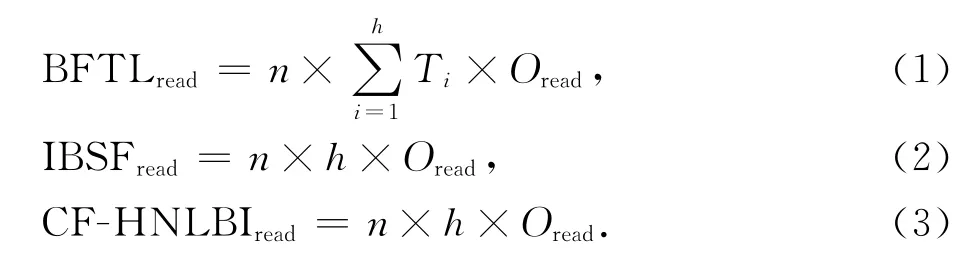
(ii)闪存写代价.由于B-树在构建过程中会发生节点分裂操作,而该类操作涉及到对父节点以及同级其他节点的修改,因此,这会造成额外的3次写操作;我们假设在插入n条记录的过程中,会发生δ次B-树节点的分裂操作,则对于普通B-树的插入,写操作的次数为{n+(δ×3)}×Owirte,其中Owrite表示一次写闪存页的操作代价.由于BFTL、IBSF和CF-HNLBI索引均使用了缓冲区进行批量更新操作,因此它们都可以减少闪存写操作的次数,其写代价分别如公式(4)~(6)所示.
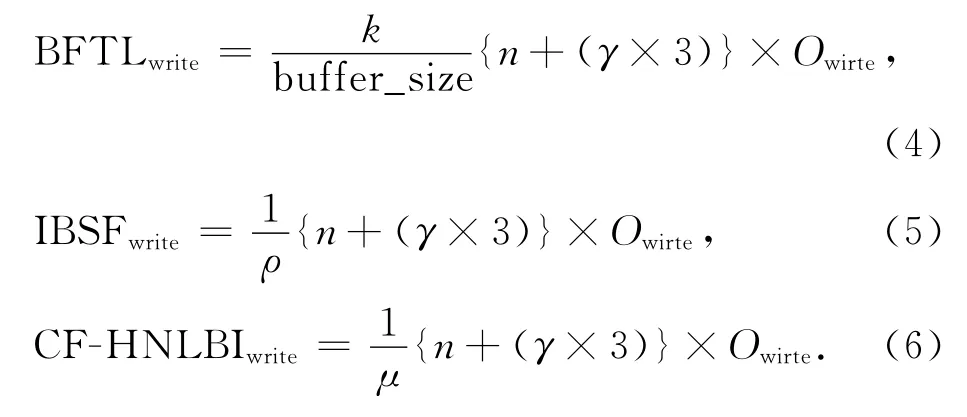
式(4)中k表示BFTL将一个节点的信息写入闪存平均需要写k个页,buffer_size表示BFTL索引的缓冲区大小.式(5)中ρ表示IBSF索引在一次写闪存操作过程中所更新信息的平均数量.式(6)中μ表示CF-HNLBI索引在一次写闪存操作过程中所更新的信息的平均数量.对于IBSF和CF-HNLBI所言,由于IBSF并未考虑一次写闪存操作的更新信息数量,而CF-HNLBI索引每次均选择冷区中更新信息最多的节点(即选择最长的更新信息链表)驱逐出缓冲区,因此,CF-HNLBI索引在每次写闪存操作时所更新的信息的平均数量μ,大于IBSF每次写闪存操作时所更新的信息的平均数量ρ,从而可以通过式(5)、(6)得出, CF-HNLBI索引的写闪存操作的平均次数小于IBSF索引.
4 实验设计与结果
4.1 实验设计
实验使用Flash-DBSim[23]平台模拟闪存存储系统.Flash-DBSim是一种高效的、可重用和可配置的闪存存储系统仿真平台.本文模拟一个128 MB的NAND闪存固态盘,该固态盘所采用的NAND闪存的数据页大小是2 k B,每个数据块包含64个数据页,读写代价比为1∶8,擦除代价为1.5 ms/块,擦除次数为100 000.
在运行BFTL、IBSF、CF-HNLBI索引时,我们将缓冲区的大小设置为40 k B,对于BFTL和IBSF算法,缓冲区中的索引单元设置为512 bits,对于CFHNLBI索引,头节点设置为512 bits,存储节点设置为256 bits;所有实验中B-树设为40阶B-树.IBSF索引中采用了LRU和FIFO 2种缓冲区替换算法,但由于其性能相差无几,这里选择实现LRU算法进行对比.实验中,我们选择插入100 000条记录,并将插入记录的键值分布情况分为4种情况:完全无序、基本无序、基本有序和完全有序.
4.2 CF-HNLBI索引冷区下限阈值的选择
本实验测试冷区不同的下限阈值对于索引性能的影响.实验设定缓冲区大小为40 kB.如图5所示,我们对于4种不同分布的插入记录分别测试了冷区下限阈值占缓冲区比值从10%增加至90%的性能变化情况.从图中实验结果来看,在冷区下限阈值设定为占缓冲区空间的30%时,CF-HNLBI的闪存写操作次数比IBSF最少.所以,本文之后对于CF-HNLBI索引的性能比较均采用30%的冷区下限阈值.

图5 冷区下限占不同比值时算法写闪存次数Fig.5 The number of write requests under different minimum sizes of cold area
4.3 不同索引构建过程的性能比较
本实验对BFTL、IBSF和CF-HNLBI分别执行100 000条记录插入操作,从而比较它们的闪存读写性能.图6演示了不同算法的读写情况.从图6(a)中可以看到,BFTL由于同一B-树节点可能存储在不同的闪存页中,因此,其在建立一棵B-树时需要更多的读操作;IBSF索引与本文的CF-HNLBI索引均将同一B-树节点信息记录在同一闪存页中,因此,它们有相近的闪存读性能,并且均优于BFTL索引.从图6(b)中可以看出,CF-HNLBI的闪存写次数明显少于BFTL索引和IBSF索引,这得益于CF-HNLBI索引进一步减少了缓冲区中的信息冗余,并使用了更好的替换算法.总体而言,CF-HNLBI的写闪存操作次数平均减少了16.2%.
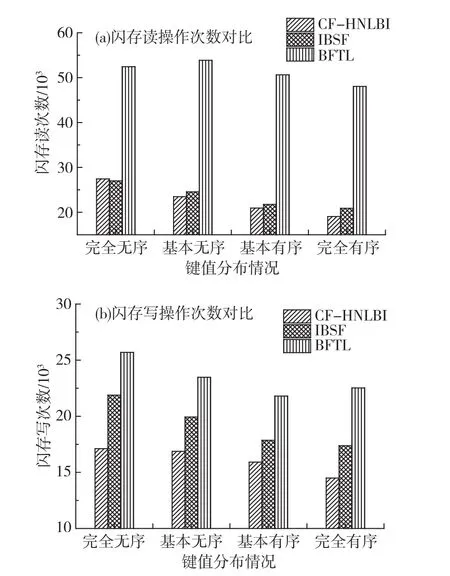
图6 BFTL、IBSF、CF-HNLBI索引闪存读/写性能比较Fig.6 The read/write performance of BFTL,IBSF,CF-HNLBI
图7显示了不同索引构建过程的时间开销.CFHNLBI索引虽然由于冷热分区机制而在一定程度上增加了时间开销,但由于节省了缓冲区遍历的时间和减少了写闪存次数,因此在总体时间性能上仍然优于BFTL和IBSF.总体而言,CF-HNLBI构建B-树的时间开销比IBSF平均降低了18.2%.
5 结 论
随着闪存技术的发展,闪存数据库系统会越来越普及.已有的面向闪存数据库的索引结构,或者没有充分考虑到闪存的特性,或者对于缓冲区的利用不够高效,仍有很大的提升空间.本文首先提出了一种朴素的HNLBI索引,该索引大量减少了缓冲区中的冗余信息,提高了缓冲区的利用效率,同时通过头节点的使用更好地组织了缓冲区中的更新信息,减少了闪存写操作的次数.但是针对缓冲区替换算法,HNLBI索引并没有利用数据访问的局部性特点,因此本文提出了改进的索引结构,即CF-HNLBI索引,它将缓冲区分为冷区和热区,当缓冲区满时,替换操作仅发生在冷区,这使得被频繁访问的节点有更多的机会驻留在缓冲区中,提高了缓冲区的利用效率,也有效地减少了闪存写操作的次数.本文研究过程中,和其他已有索引结构(如BFTL、IBSF)进行了对比.然而,不同的闪存设备读写代价比是不一样的,我们将在未来的工作中,在不同的闪存设备上充分测试CF-HNLBI索引的不同性能表现,从而为不同读写代价比的设备确定最优的参数.
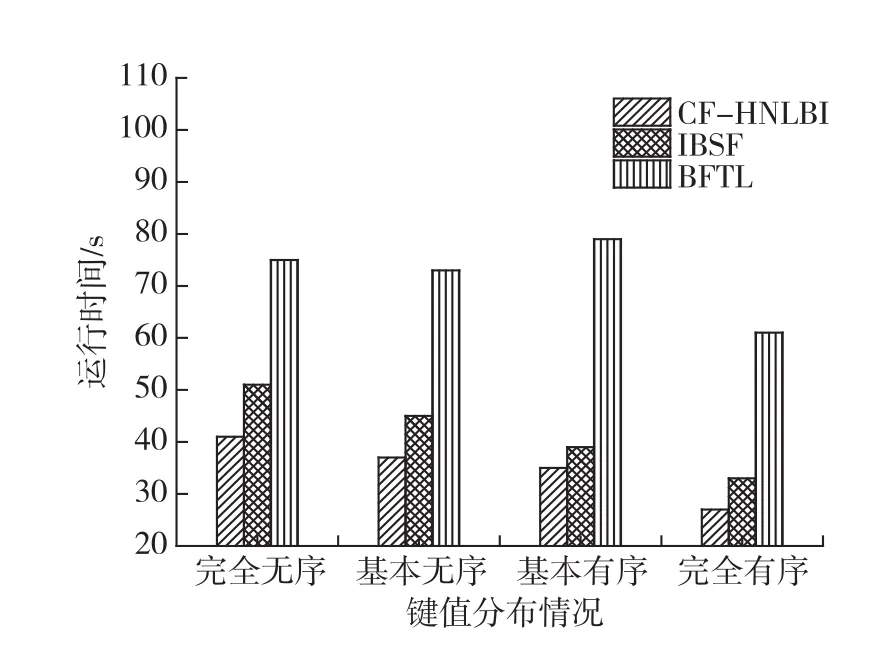
图7 构建索引时间对比Fig.7 The time cost for building an index
[1] Chiang M L,Lee P C H,Chang R C.Managing flash memory in personal communication devices[C]∥Consumer Electronics,Proceedings of 1997 IEEE International Symposium.[S.l.]:IEEE,1997:177-182.
[2] Canim M,Mihaila G A,Bhattacharjee B,et al.An object placement advisor for DB2 using solid state storage[J]. Proceedings of the VLDB Endowment,2009,2(2): 1318-1329.
[3] Nath S,Kansal A.FlashDB:dynamic self-tuning database for NAND flash[C]∥Proceedings of the 6th International Conference on Information Processing in Sensor Networks.New Xork:ACM,2007:410-419.
[4] Intel Corporation.Understanding the flash translation layer(FTL)specification[EB/OL].[1998-12-01].http:∥www.docin.com/p-730629258.html.
[5] Lee S W,Moon B.Design of flash-based DBMS:an in-page logging approach[C]∥Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data.New Xork:ACM,2007:55-66.
[6] Lee S W,Moon B,Park C,et al.A case for flash memory ssd in enterprise database applications[C]∥Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data.New Xork:ACM,2008:1075-1086.
[7] Wu C H,Kuo T W,Chang L P.An efficient B-tree layer implementation for flash-memory storage systems[J]. ACM Transactions on Embedded Computing Systems (TECS),2007,6(3):19.
[8] Lee H S,Lee D H.An efficient index buffer management scheme for implementing a B-tree on NAND flash memory [J].Data&Knowledge Engineering,2010,69(9):901-916.
[9] Agrawal D,Ganesan D,Sitaraman R,et al.Lazy-adaptive tree:an optimized index structure for flash devices[J]. Proceedings of the VLDB Endowment,2009,2(1): 361-372.
[10] On S T,Hu H,Li X,et al.Flash-optimized B+-tree[J]. Journal of Computer Science and Technology,2010,25 (3):509-522.
[11] Kang D,Jung D,Kang J U,et al.μ-tree:an ordered index structure for NAND flash memory[C]∥Proceedings of the 7th ACM&IEEE International Conference on Embedded Software.New Xork:ACM,2007:144-153.
[12] Zeinalipour-Xazti D,Lin S,Kalogeraki V,et al.Micro-Hash:an efficient index structure for flash-based sensor devices[J].FAST,2005,5:31-44.
[13] Xin S,Pucheral P,Meng X.PBFilter:indexing flash-resident data through partitioned summaries[C]∥Proceedings of the 17th ACM Conference on Information and Knowledge Management.New Xork:ACM,2008: 1333-1334.
[14] Nath S,Kansal A.FlashDB:dynamic self-tuning database for NAND flash[C]∥Proceedings of the 6th International Conference on Information Processing in Sensor Networks.New Xork:ACM,2007:410-419.
[15] Meng X,Jin P,Cao W,et al.Report on the first international workshop on flash-based database systems(FlashDB 2011)[J].ACM Sigmod Record,2011,40(2):40-44.
[16] Meng X,Xue L,Xu J.Flash-based database systems:experiences from the flashDB project[C]∥Proceedings of the 16th International Conference on Database Systems for Advanced Applications.Berlin:Springer-Verlag,2011:240-240.
[17] Jin P,Ou X,Härder T,et al.AD-LRU:an efficient buffer replacement algorithm for flash-based databases[J]. Data&Knowledge Engineering,2012,72:83-102.
[18] Lu Z,Qi X,Cao W,et al.LB-logging:a highly efficient recovery technique for flash-based database[M]∥Webage information management.Berlin:Springer-Verlag, 2012:375-386.
[19] Hardock S,Petrov I,Gottstein R,et al.Noftl:database systems on ftl-less flash storage[J].Proceedings of the VLDB Endowment,2013,6(12):1278-1281.
[20] Tang X,Meng X F,Liang Z H,et al.Cost-based buffer management algorithm for flash database systems[J]. Journal of Software,2011,22(12):2951-2964.
[21] Jin P Q,Ou X,Theo H,et al.AD-LRU:an efficient buffer replacement algorithm for flash-based databases [J].Data&Knowledge Engineering,2012,72:83-102.
[22] Zhou D,Liang Z C,Meng X F.HF-tree:an update-efficient index for flash memory[J].Journal of Computer Research and Development,2010,5:832-840.
[23] Su X,Jin P,Xiang X,et al.Flash-DBSim:a simulation tool for evaluating flash-based database algorithms[C]∥Computer Science and Information Technology,2009. 2nd IEEE International Conference.[S.l.]:IEEE,2009: 185-189.
CF-HNLBI:a New B-tree Indexing for Flash-based Databases
LIU Xing-jie1,LIN Zi-yu1*,LAI Xong-xuan2
(1.School of Information Science and Engineering,Xiamen University, 2.School of Software,Xiamen University,Xiamen 361005,China)
A new B-tree-based indexing,called CF-HNLBI,is proposed for flash-based database systems.In CF-HNLBI,indexing units are organized in the form of lists to reduce the time cost of traversal operations.The method involves less redundant information in the index buffer compared to other indexings schemes.It divides the buffer into two areas,i.e.,cold area and hot area,and adopts the buffer replacement algorithm based on updating information frequency to reduce the number of write operations.Extensive experimental results show that CF-HNLBI can achieve better performances than the state-of-the-art methods.
flash;database;index;B-tree
10.6043/j.issn.0438-0479.2015.02.017
TP 311
A
0438-0479(2015)02-0247-10
2014-06-18 录用日期:2014-11-19
国家自然科学基金(61303004,61370010,61102136,61202012);福建省自然科学基金(2013J05099,2011J05156,2011J05158);中央高校基本科研业务费专项(2011121049)
*通信作者:ziyulin@xmu.edu.cn
刘颖杰,林子雨,赖永炫.CF-HNLBI:一种新的闪存数据库B-树索引[J].厦门大学学报:自然科学版,2015,54(2): 247-256.
:Liu Xingjie,Lin Ziyu,Lai Xongxuan.CF-HNLBI:a new B-tree indexing for flash-based databases[J].Journal of Xiamen University:Natural Science,2015,54(2):247-256.(in Chinese)
