基于模糊C-means的多视角聚类算法
2015-10-13杨欣欣黄少滨
杨欣欣,黄少滨
基于模糊C-means的多视角聚类算法
杨欣欣,黄少滨
(哈尔滨工程大学计算机科学与技术学院,黑龙江哈尔滨,150001)
目前多数多视角聚类算法属于“刚性”划分算法,不适用于处理具有聚簇重叠结构的数据集,为此,提出一种基于模糊C-means的多视角聚类算法(简称FCM-MVC),该算法利用隶属度描述对象与类别的关系,能够更真实地描述具有聚簇重叠结构数据集的聚类结果。FCM-MVC算法同时利用多个视角信息,自动计算每个视角的权重。研究结果表明:FCM-MVC算法能够有效处理具有聚簇重叠结构的数据集;与已有的3种经典的多视角聚类算法相比,该算法获得的聚类精度更高。
多视角聚类;模糊C-means;数据挖掘
近年来,在许多实际应用中出现了大量由多种表示方法或多种视角描述的多视角数据(Multi- view)[1−2]。例如,同一则新闻可以由多个新闻机构以不同的描述方式报道,同一则新闻也可以翻译成多种不同的语言[1−2]。不同的表示方法从不同的视角更全面、更客观地描述数据集特性。多视角聚类方法充分利用多视角信息,考虑不同视角信息的区别,往往能够获得更加准确的数据划分结果,是近年来备受关注的学习范式。该学习范式主要包含2类算法[3]:集中式和分散式。目前大部分多视角聚类算法为集中式方 法[1−14]。集中式方法同时利用多个数据描述特征空间信息,探测数据中隐藏的模式;分散式算法首先使用单视角算法对每个视角分别进行独立聚类,然后结合每个视角的聚类结果,得到最终的划分结果[3]。基于奇异值分解的算法HC-MLSVD[1],将多视角数据表示为多维张量,利用奇异值方法将其映射到低维空降。
基于谱聚类的方法将多视角数据表示为多个特征空间的视图,然后寻找多视图的最小划分[2−5, 13−14]。基于k-means多视角聚类算法[6, 12],自动确定视角和特征的权值。Blaschko等[6]提出了一种基于核典型相关分析的双视角聚类算法,每个视角采用单独的相似性测量,适用于分析部分只有一种视角描述的数据。Chaudhuri等[8]提出了一种子空间多视角聚类算法,通过典型相关分析将多视角数据映射到低维子空间。Tzortzis等[10]提出基于核的方法,用核矩阵表示每个视角的对象,根据每个视角的信息量自动确定其核矩阵的权重。Long等[3]提出一种分散式多视角聚类模型,该模型通过引入映射函数,使得不同空间的模式具有可比性,从多个视角中学习最佳模式。Bruno等[11]提出一种后期融合方法,重新建立每个视角聚簇之间的关系。这些多视角聚类算法都是“刚性”划分方法。与刚性聚类方法相比,模糊聚类方法中样本不再完全属于或完全不属于某一类,而是以一定的隶属度隶属于每个类,即利用隶属度描述样本属于每个类别的不确定性程度,这样更能准确地反映现实世界。模糊聚类获得了广泛研究,并取得了较好的聚类效果[18−19]。本文作者基于模糊C-means算法提出一种多视角聚类算法FCM-MVC,利用隶属度描述对象与类别的关系,同时利用多个视角空间中的信息,自动计算每个视角的权重。
1 基于模糊C-means的多视角聚类算法
设具有个视角的多视角数据对象集合为{1,2,…,x},(i)表示多视角数据在第(1≤≤)个视角空间的特征矩阵,其中第(1≤≤)行向量表示数据对象在第个视角空间中的特征向量,其中n为第个视角的特征维度。FCM-MVC算法的最优化目标函数如下:

s.t
其中:为模糊指数,用于调节隶属度的模糊程度;为隶属度矩阵;表示对象隶属于第个聚簇的隶属度;,(1≤≤)表示第个聚类中心的向量;,其中w表示视角的权重;表示在第维空间上与之间的欧几里得距离,如果特征为连续值,则
若特征是离散值,则
运用朗格朗日乘子法,构造约束条件(2)下的目标函数(1)的Lagrange函数为
(5)
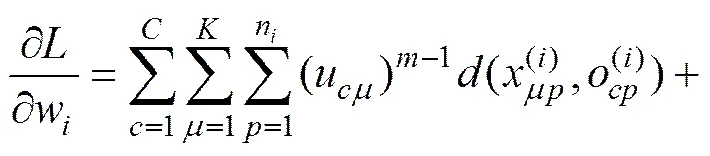
求解等式(6)~(10)构成的方程组,得到目标函数(1)在约束条件(2)下取到极小值时需满足的必要条件为:
其中:
综上所述,基于模糊C-means的多视聚类算法计算步骤描述如下。
输出:使目标函数(1)最小化的多视角数据集的隶属度矩阵。
1) 初始化:随机产生并归一化隶属度矩阵;
2) 重复以下计算过程,直到连续2次迭代目标函数的差值小于或迭代次数达到最大迭代数max;
For each
①根据式(11)计算第个视角空间的聚簇中心(=1,2,…,) 。
②根据(3)或(4)式计算第个视角的第维空间上数据与聚簇中心的距离。
③根据(13)和(14)式计算第个视角空间的权重。
End for
时间复杂度分析:步骤2为循环迭代过程,算法运行时间主要消耗在该步骤。以下主要分析步骤2消耗的时间复杂度。在1次循环中步骤①计算的时间复杂度为(),计算第个视角空间中个聚簇中心的时间复杂度为,计算个视角特征空间的聚簇中心消耗的时间复杂度为。同理分析知步骤②消耗的时间复杂度为。在1次循环中步骤③计算所有视角空间中的消耗的时间复杂度为,计算所有视角空间中的消耗的时间复杂度为,所以在1次循环中,步骤③消耗的时间复杂度为。同理分析知步骤④消耗的时间复杂度是。综上,FCM-MVC算法消耗的时间复杂度为,其中为所有视角特征维度之和,为算法达到收敛状态时的迭代次数。
2 实验分析
2.1 数据集介绍
本实验使用4个benchmark数据集分析多视角数据内部隐藏的重叠聚簇结构,测试FCM-MVC算法的聚类精度和收敛特性:
3-Sources 数据集是同时由3家新闻社报道的169条新闻组成,包括6个主题。将BBC新闻社报道的新闻作为第1视角,将Guardian和The Reuters新闻社报道的新闻分别作为第2和第3视角[15]。采用Grreene等[15]提出的方法构建多视角数据集Dataset1。
Reuters Multilingual 数据集由5种语言描述的6个主题的文本组成[16],从每个主题中随机选取200篇文本,将法语、德语和英语描述的文本作为3个视角。采用Amini等[16]的方法构建多视角数据集Dataset2。
Corel 数据集包含5 000 张图像,每个图像包含文字标注信息和图像分割块信息[22]。分别从cow,grass和horses 3个类别中选取100 张图像,将图像的文字描述信息作为第1视角,将图像分割组信息作为第2视角,采用文献[21]中的方法构建多视角数据集Dataset3。
MSRC 数据集包含23个类别图像[20], 分别从clouds和trees类别中随机选取400和200张图像组成数据集dataset4。采用整体视觉特征(GVF)、局部视觉特征(LVF)作为第1和第2视角。采用Shotton等[20]的方法构建多视角数据集Dataset3。
2.2 实验结果分析
图1所示为Dataset3数据集和Dataset4数据集中图像之间相似度可视化示意图,其中,灰度越深表示相应的图像之间的相似度越高。从图1可以发现Dataset3数据集和Dataset4数据集中存在明显的聚簇结构,并且不同的聚簇之间存在明显的重叠部分,而基于“刚性”划分的多视角聚类方法严格地将多视角数据对象集合划分到不同的聚簇中,不同聚簇之间不存在交集,难以表示聚类重叠部分多视角数据对象的聚簇结果。Dataset1数据集和Dataset2数据集具有类似的聚类结构,不再列举。图2所示为Dataset4数据集中多视角数据对象属于第1个聚类的隶属度值,400~460之间的多视角对象为第1个聚簇和第2个聚簇之间重叠的部分,相应的隶属度近似于0.5。表1所示为Dataset4中聚簇重叠部分多视角数据对象的隶属度值示例,这些数据对象既包含cloud又包含tree聚类,难以严格地将这些多视角数据对象划分到cloud聚类或于cloud聚类中,数据对象的隶属度在0.5左右。由此可见:FCM-MVC算法引入模糊隶属度概念,利用模糊隶属度描述数据对象与聚簇之间的隶属关系,能够更有效地挖掘和分析聚簇重叠部分数据对象内部隐藏的结构,更客观地描述现实世界数据对象的聚类结果。
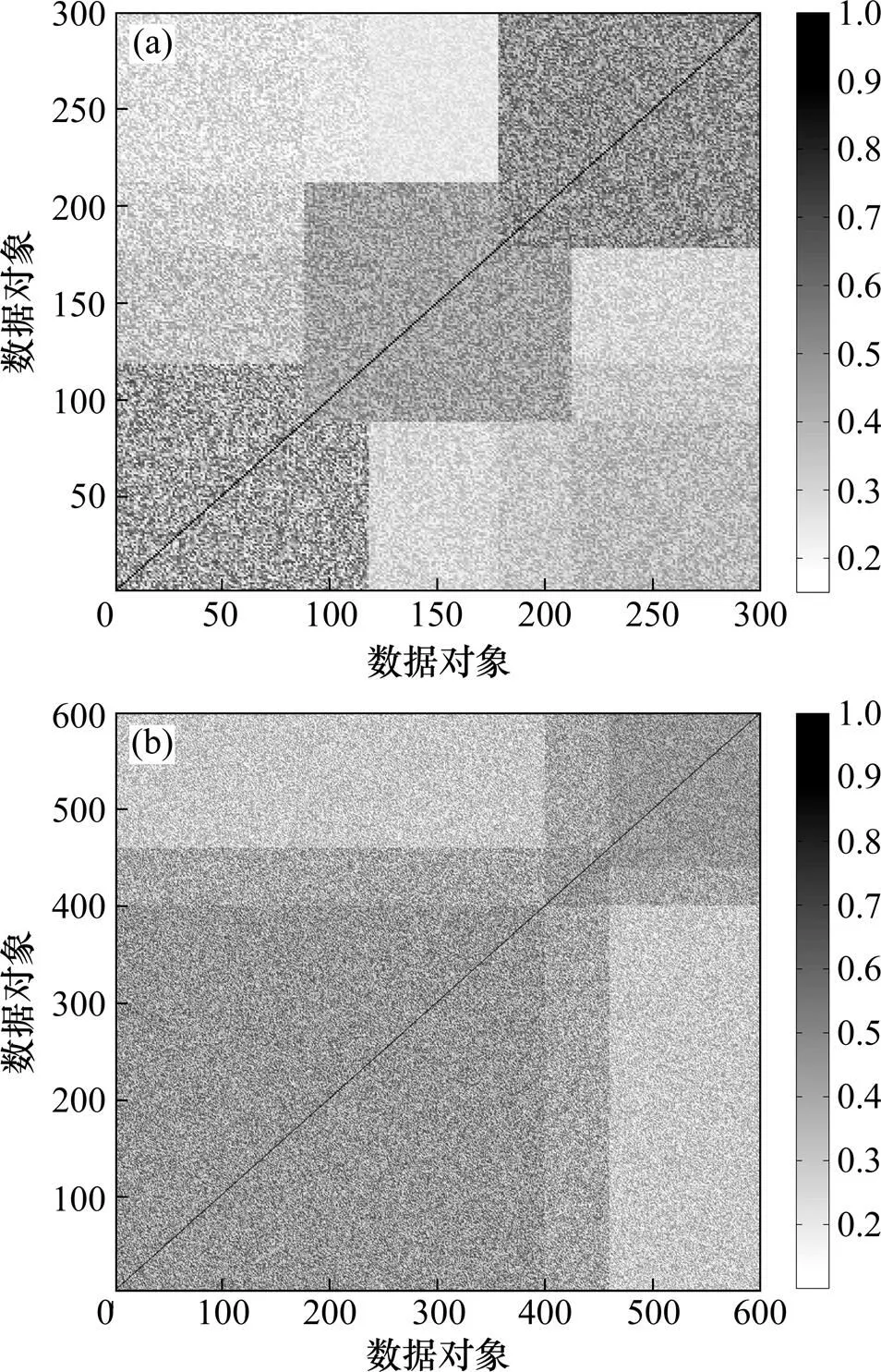
(a) Dataset3 数据集;(b) Dataset4 数据集
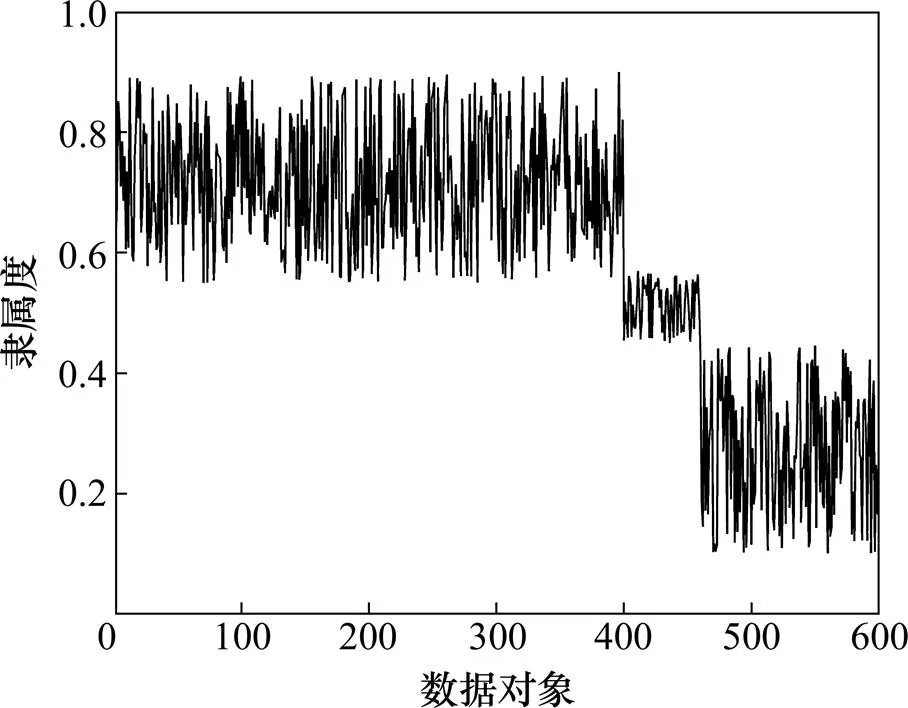
图2 图像隶属度值

表1 Dataset4数据集重叠聚簇部分数据隶属度示例
其次,FCM-MVC算法与目前已有的3种“刚性”划分多视角聚类算法进行准确率对比,包括基于典型相关性分析的方法KCCA[6]、协同回归的多视角谱聚类算法Co-reguSC[4]和基于核映射的多视角K-means算法MVKKM[9]。另外,单视角模糊C-means算法的在最优视角上的聚类用Best Single-view表示,将FCM-MVC算法与Best Single-view的聚类效果进行对比分析。利用NMI指标评估聚类效果,NMI越大表明聚类结果越准确。图3所示为KCCA,Co-reguSC,MVKKM,Best Single-view和FCM-MVC算法聚类结果NMI值比较。结果表明:FCM-MVC算法聚类结果明显优于目前已有的3种“刚性划分”多视角聚类算法,这在一定程度上是由于模糊方法利用隶属度,能够更客观、更精确地描述聚簇重叠部分数据对象的聚类结果;另外,FCM-MVC算法的聚类结果明显优于Best Single-view的聚类结果,主要原因在于FCM-MVC算法能够充分利用多种视角空间信息,进一步提高聚类精度。
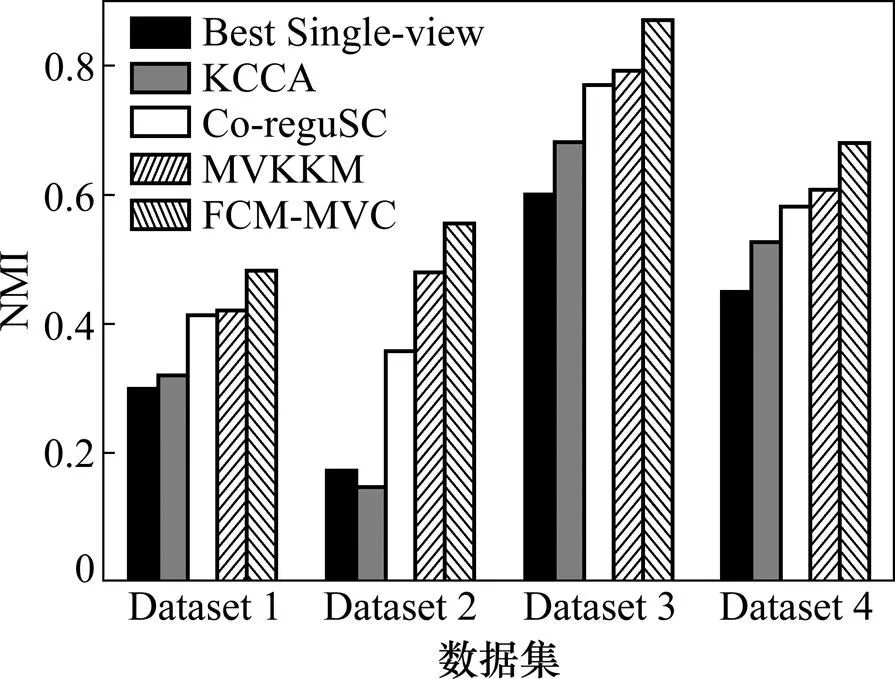
图3 聚类结果NMI值
最后,图4所示为FCM-MVC算法在Dataset1和Dataset3数据集上式(1)所示目标函数随算法迭代运行的变化情况。结果表明:FCM-MVC算法目标函数值逐渐下降,在迭代50次左右逐渐达到收敛状态。
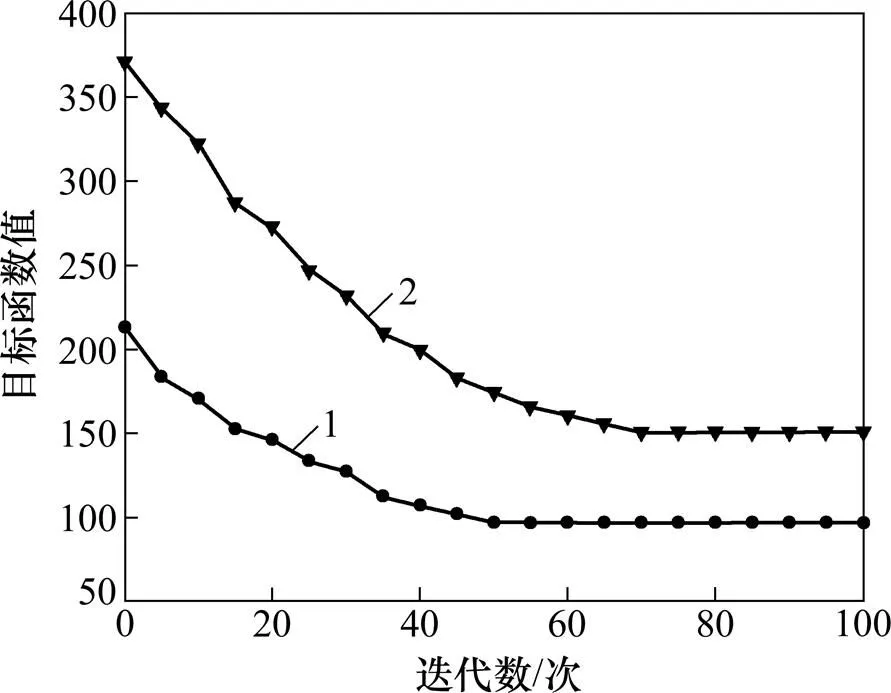
1—Dataset 1;2—Dataset 3
3 结论
1) 基于模糊C-means算法FCM提出了一种多视角聚类算法FCM-MVC,与已有的多视角聚类算法相比,FCM-MVC算法能够更有效地描述和挖掘具有重叠聚簇结构的多视角数据的聚类结果,并且能够有效提高聚类精度。
2) 目前已有的多视角聚类算法需要领域专家预先确定多视角数据的聚类数目,下一步的主要研究工作是考虑如何自动确定多视角数据的聚类数目。
[1] LIU Xinhai, Glänzel W, de Moor B. Hybrid clustering of multi-view data via Tucker-2 model and its application[J]. Scientometrics, 2011, 88(3): 819−839.
[2] WANG Xiang, QIAN Buyue, YE Jieping, et al. Multi-objective multi-view spectral clustering via pareto optimization[C]//Proc of the 13th SIAM International Conference on Data Mining. Philadelphia: SIAM, 2013: 234−242.
[3] LONG Bo, YU P S, ZHANG Zhongfei. A general model for multiple view unsupervised learning[C]//Proc of the 8th SIAM International Conference on Data Mining. Philadelphia: SIAM, 2008: 822−833.
[4] Kumar A, Hal Daumé III. A co-training approach for multi-view spectral clustering[C]//Proc of the 28th IEEE International Conference on Machine Learning. NJ: IEEE, 2011: 393−400.
[5] Kumar A, Rai P, Hal Daumé III. Co-regularized multi-view spectral clustering[C]//Proc of the 24th Annual Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2011: 1413−1421.
[6] CHEN Xiaojun, XU Xiaofei, HUANG Joshua, et al. TW-k-means: Automated two-level variable weighting clustering algorithm for multiview data[J]. IEEE Transactions on Knowledge and Data Engineering, 2013, 25(4): 932−944.
[7] Blaschko M B, Lampert C H. Correlational spectral clustering[C]//Proc of the 21st IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2008: 1−8.
[8] Chaudhuri K, Kakade S, Livescu K, et al. Multiview clustering via canonical correlation analysis[C]//Proc of the 26th Annual International Conference on Machine Learning. New York: ACM, 2009: 129−136.
[9] LIU Jialu, WANG Chi, GAO Jing, et al. Multi-view clustering via joint nonnegative matrix factorization[C]//Proc of the 13th SIAM International Conference on Data Mining. Piscataway: IEEE, 2013: 252−260.
[10] Tzortzis G, Likas A. Kernel-based weighted multi-view clustering[C]//Proc of the 12th IEEE international conference on Data Mining. Piscataway: IEEE, 2012: 675−684.
[11] Bruno E, Marchand-maillet S. Multiview clustering: a late fusion approach using latent models[C]//Proc of the 32nd international ACM SIGIR conference on Research and Development in Information Retrieval. New York: ACM, 2009: 736−737.
[12] Eaton E, DesJardins M, Jacob S. Multi-view clustering with constraint propagation for learning with an incomplete mapping between views[C]//Proc of the 19th ACM international conference on Information and knowledge management. New York: ACM, 2010: 389−398.
[13] Eaton E, DesJardins M, Jacob S. Multiview Spectral Embedding [J].IEEE Transactions on Systems, Man, and Cybernetics, Part B: Cybernetics, 2010, 40(6): 1438−1446.
[14] ZHOU Dengyong, Burges C J C. Spectral clustering and transductive learning with multiple views[C]//Proc of the 24th International Conference on Machine Learning. New York: ACM, 2007: 1159−1166.
[15] Greene D, Cunningham P. A matrix factorization approach for integrating multiple data views[C]//Proc of European Conference on Machine learning and Principles and Practice of Knowledge Discovery in Databases. Berlin: Springer, 2009: 423−438.
[16] Amini M, Usunier N, Goutte C. Learning from multiple partially observed views: An application to multilingual text categorization[C]//Proc of the 23rd Annual Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2009: 28−36.
[17] Strehl A, Ghosh J. Cluster ensembles-a knowledge reuse framework for combining multiple partitions[J]. Journal of Machine Learning Research, 2002, 3(3): 583−617.
[18] Miyamoto S, Mukaidono M. Fuzzy c-means as a regularization and maximum entropy approach[C]//Proc of the 7th International Fuzzy Systems Association Word Congress. Berlin: Springer, 1997: 86−92.
[19] Huang H C, CHUANG Yungyu, CHENChusongMultiple kernel fuzzy clustering[J]. IEEE Transactions on Fuzzy Systems, 2012, 20(1): 120−134.
[20] Shotton J, Winn J, Rother C, et al. Textonboost for image understanding: Multi-class object recognition and segmentation by jointly modeling texture, layout, and context[J]. International Journal of Computer Vision, 2009, 81(1): 2−23.
[21] 杜友田, 李谦, 周亚东, 等. 基于异质信息融合的网络图像半监督学习方法[J]. 自动化学报, 2012, 38(12): 1923−1932. DU Youtian, LI Qian, ZHOU Yadong, et al. Web image semi-supervised learning method based on heterogeneous information fusion[J]. Acta Automatica Sinica, 2012, 38(12):1923−1932.
[22] Duygulu P, Barnard K, de Freitas N, et al. Object recognition as machine translation: Learning a lexicon for a fixed image vocabulary[C]//Proceedings of European Conference on Computer Vision. Berlin: Springer, 2002: 97−112.
(编辑 陈爱华)
Multi-view clustering algorithm based on fuzzy C-means
YANG Xinxin, HUANG Shaobin
(College of Computer Science and Technology, Harbin Engineering University, Harbin 150001, China)
Considering that most exiting multi-view clustering algorithms focusing on hard-partition clustering methods, which are not suitable for analyzing dataset with overlapping clusters, a multi-view clustering algorithm based on fuzzy C-means (FCM-MVC) was developed. The membership degree was used to describe the relation between objects and clusters, so FCM-MVC algorithm could more truely describe clustering results of dataset with overlapping clusters. FCM-MVC algorithm simultaneously incorporated fearture information in multi-view space and automatically computes weight of each view. The results show that FCM-MVC can analyze overlapping clusters effectively and the precision of clustering results of FCM-MVCare superior to the three representative algorithms.
multi-view clustering; fuzzy C-means; data mining
10.11817/j.issn.1672-7207.2015.06.021
TP181
A
1672−7207(2015)06−2128−06
2014−08−14;
2014−10−25
国家科技支撑计划项目(2012BAH08B02);哈尔滨工程大学中央高校基本科研业务专项资金资助项目(HEUCFZ1212,HEUCF100603)(Project (2012BAH08B02) supported by the National Key Project of Scientific and Technical Supporting Programs; Project (HEUCFZ1212, HEUCF100603) supported by the Fundamental Research Funds of Harbin Engineering University for the Central Universities)
杨欣欣,博士研究生,从事数据挖掘、社会网络和复杂网络研究;E-mail:yangxinxin051131@126.com
