基于API接口的腾讯微博数据挖掘
2015-09-25陈向阳陈丽萍姜振国
陈向阳,陈丽萍,姜振国
(河北大学计算机科学与技术学院,保定 071000)
基于API接口的腾讯微博数据挖掘
陈向阳,陈丽萍,姜振国
(河北大学计算机科学与技术学院,保定071000)
0 引言
微博是近几年发展起来的一个信息交互平台,通过该平台可以接收或发送微博信息。用户可以通过关注感兴趣的人,接收关注人的信息,也可以在计算机或移动通信终端发送自己感兴趣的信息,其简单快捷的操作方式和发布信息的随时随地性,使这种互动形式的信息传播成为互联网的一大亮点,是Web 2.0时代下产生的一种新型社交网络。Twitter是美国最大的微博网站,自2006年创建以来[1],微博的使用者就增长迅猛,仅2009年Twitter的使用者就增长了25倍多,和其他社交网站Facebook以及LinkedIn相比,增长率是二者总和的10倍[2]。国内的新浪微博和腾讯微博在开通之初,用户数量也增长迅猛,均在不足一年半的时间内超过1亿用户。中国互联网信息中心(CNNIC)报告显示,至2011年底,中国微博用户达到2.5亿[3]。
1 微博的研究现状
微博的用户群基数巨大,信息传播迅速,而且微博平台上有大量的媒体和商家用户,这些用户之间的关系和信息的传播方式,对商品的推介和舆情的监控有重要意义,因此基于微博数据的分析和研究已成为一个非常有价值的研究方向。国外多以Twitter为对象来研究微博。Teutte等人[4]分析了Twitter的网络动态性,通过对出度和入度的增长和网络使用密度等的分析,研究其对微博网络变化的影响。Shen[5]等人研究了微博中Spam信息的传播方式,并通过文本挖掘对微博信息的内容进行了分析。近年来国内对微博的研究也越来越多,杨长春[6]等从用户是否活跃,博文是否被转载和评论设计了新的博主评价指标,并把该指标作为PageRank算法的因子提出来不同的核心用户发现算法。廉捷等[7]提出了采用新浪微博API来取得新浪微博数据的方法,并与传统的的网络爬虫技术相比较,二者结合可以高效完整地获取新浪微博数据。
近几年国内对微博的研究越来越深入,从定性研究逐渐进入定量分析,对数据的需求也就越来越多,但多数文章并无明确说明微博信息的提取方式,使得进行微博研究的第一项工作“信息获取”模糊不清。因此本文着重研究微博信息的获取方式。大多数微博信息挖掘以新浪微博数据为研究对象,但近期新浪微博提高的数据获取门槛,普通的研究者无法从其获取数据,所以本文以同样有代表性的腾讯微博平台为研究对象,研究其数据挖掘方式。
2 腾讯微博官方提供的API接口
腾讯微博开放平台为开发者提供了获取微博数据的接口。利用这些API接口,用户可以方便地获取需要的微博信息,或在微博中传播信息。
获取互联网的数据一般是通过网络爬虫实现的。但网络爬虫对计算机的配置和网速有较高的要求,运行效率较低。而腾讯微博开放API接口可以更加简洁地获取相应的数据,为程序高效获取微博数据提供保障。因此文中研究使用API接口获取微博信息的方法及限制。
腾讯微博官方提供的API接口共有22类,几乎涵盖了所有的微博信息操作方法,如表1所示。同时官方也对API的调用权限进行了限制,为了均衡服务器的负载,对用户进行分级。将用户权限分为三级:初级授权、高级授权和腾讯合作方授权。其中初级授权每个API的调用次数为不超过1000次/小时。

表1 腾讯微博接口
3 微博信息提取的前提
为了能够使用微博信息平台,获取需要的微博信息,用户需要获得信息平台的资源授权,过程如下:
(1)为了能够获得使用腾讯API的资格,我们必须向官方申请成为开发者。用户只需在腾讯微博开放平台网站上登录QQ账号并申请成为开发者,然后提交详细信息后即可。在1~2工作日内申请就会被通过,获得使用腾讯微博信息的许可权,成为腾讯微博的开发者。
(2)创建应用,获取使用API的权限,即得到API接口验证序号 (App Key)和API接口密钥 (App Secret),对用户发出的请求进行数字签名。
(3)获取OAUTH认证。所谓认证是指第三方软件不知道用户的用户名和密码,为用户申请获得提供方资源的授权。OAUTH认证是获取用户资源授权的一个安全、公开而又简单的标准。当前,腾讯微博对第三方授权采用的是OAUTH 2.0协议。获取认证就是获取访问令牌 (Access Token),是第三方获得资源授权的凭证,是第三方访问API资源的钥匙。其基本流程如图1所示:

图1 获取OAUTH认证的流程
其中,对于弹出的回调信息是如下的URL:
http://www.myurl.com/example?code=CODE&openid =O PENID&openkey=OPENKEY
其意义如下表2所示:
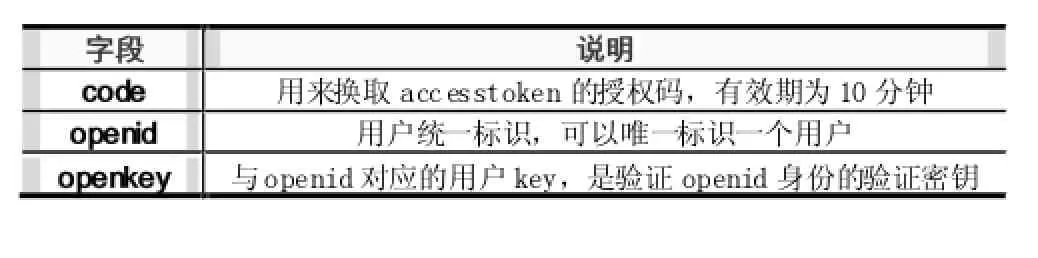
表2 回调信息字段意义
4 微博信息提取的方法
为方便微博API的调用,腾讯为用户提供了一个SDK,使用权限认证、数据采集和数据分析等各项功能都被打包在其中。SDK是以API为基础的,因此基于SDK开发的工程能极大地减少开发程序的工作量。但作为一种新的网络应用,微博的SDK开发并不完善,使用SDK时可能会出现一些功能性的错误,所以应区别对待,必要时进行代码修改和完善。
目前已开发并发布的SDK包括支持Java、C++等多种语言版本,本文采用Java语言作为开发工具。例如:在使用腾讯官方API提供的SDK包,抓取的数据在Eclipse下显示是乱码,所以必须对其进行修改。可将SDK中的 QHttpClient.java类的http请求方法中的以下部分代码进行修改


这样从服务器读来的数据才可使用。
由于腾讯微博的API对使用者的请求次数有限定,所以本文在获取数据时,一方面通过程序控制访问频率,另一方面在每一次访问中尽可能多地取得系统允许的信息量。程序需要通过线程控制访问频率,因为如果短时间内,程序运行中较频繁地调用API接口,虽然总的访问次数未超过每小时的1000次,但因为在这段时间内高度频繁地调用,系统会认为用户访问达到上限,所以通常每调用100次请求后,程序将暂停几分钟,从而避免超过腾讯API对于用户请求的限制。当请求访问次数达到API请求上限时就停下来,等下一个允许时间段再读取。而在每一次信息读取中,采用不同的函数方法效率也会不同。例如为了能得到一个人好友列表中所有的信息,如果使用info方法获取用户信息,每次只能得到一个用户的信息,而用fanslist可以得到30个用户信息。这样就减少了API的调用次数,从而能在相同调用次数下得到更多的用户信息。
5 微博信息的处理
获得OAUTH身份认证,并通过腾讯API可以根据请求返回特定的XML或JSON文件。微博中用户状态与信息,可能包含一些个性化字符格式,这些字符会导致整个XML文档无法被正确解析,因此返回方式采取JSON格式更具稳定性[7]。
JSON数据格式非常简单,文件没有明显的格式信息,用来传输信息简单灵活,如:
tweet:用户最近发的一条微博
{text:微博内容,from:来源,id:微博id,timestamp:微博时间戳}
和结构化的XML文件不同,复杂的JSON文件没有使用格式化标签来标记有意义的内容,对于人来说处理起来不太容易,但由于JSON文件结构简单,因此通过计算机强大的处理能力来分析JSON文件具有很强的优势。另外JSON文件中因为没有属性标签,所以和XML文件对比,同样内容的查询结果,返回的XML文件要比JSON文件更大,因此作为海量微博信息的媒介工具,JSON文件更合适。
例如腾讯FRIENDSAP中用户粉丝列表方法声明为:userFanslist(oAuth,format,reqnum,startindex,name,fo-penid,mode,install)。其中参数format需要设置成JSON,返回结果为JSON格式的字符串,然后通过解析程序对JSON格式的字符串进行解析获得用户需要的信息。将解析出来的信息存储到数据库,即可进行相关的数据分析和研究。
6 API接口提取信息的优缺点分析
基于API接口提取信息效率较高,方便迅捷。但普通用户无法自由地从微博服务商那里获得完整的API,因此使用API的方式只能获得部分微博数据。如在腾讯微博中,很多重要查询功能的API是不开放的,同时对于开放的API,每次查询的返回结果也有上限,所以每次查询需要记录查询位置,往往会出现重复查询结果,需要人工筛选。微博研究最关心的问题是那些具有大量信息的用户,而这些限制正好阻碍了研究信息的获取。同时对用户每小时的访问次数也有限制,所以为了获得足够的研究数据,用户往往需要较长的数据获取时间。因此用户在获取微博信息时应该结合其他的方法如爬虫等,来完善数据信息。
[1]Pieter N,Michiel H.Mining Twitter in the Cloud:A Case Study[C].Proceedings of the 2010 IEEE 3rd International Conference on Cloud Computing,2010:107~114
[2]Abraham R,Martinez T.Twitter:Network Properties Analysis[C].Proceedings of the CONIELECOMP 2010-20th International Conference on Electronics Communications and Computers,2010:180~184
[3]文坤梅,徐帅,李瑞轩等.微博及中文微博信息处理研究综述[J].中文信息学报,2012,26(6):27~37
[4]Teutte G,Kleinberg J,Watts D J.The Structure of Information Pathways in a Social Communication Network[C].Proceedings of SIGKDD,2008:435~443
[5]Shen Yang,Li Shu-chen,Ye Xiao-xiao,et al.Content Mining and Network Analysis of Microblog Spam[J].Journal of Convergence Information Technology,2010,5(1):135~140
[6]杨长春,俞克非,叶施仁等.一种新的中文微博社区博主影响力的评估方法[J].计算机工程与应用,2012,48(25):229~233
[7]廉捷,周欣,曹伟等.新浪微博数据挖掘方案[J].清华大学学报(自然科学版),2011,51(10):1300~1305
Microblog;API Interface;Information Extraction
Data Mining of Tencent Microblog Based on API Interface
CHEN Xiang-yang,CHEN Li-ping,JIANG Zhen-guo
(School of Computer Science and Technology,Hebei University,Baoding071000)
1007-1423(2015)09-0047-04
10.3969/j.issn.1007-1423.2015.09.011
陈向阳(1977-),女,河南三门峡人,硕士研究生,讲师,研究方向为数据挖掘
陈丽萍(1974-),女,河北保定人,硕士研究生,讲师,研究方向为数据挖掘
姜振国(1992-),男,河北保定人,本科,学生,研究方向为软件工程
2015-01-04
2015-02-10
以腾讯微博为对象,介绍它提供的API接口,以及如何成为授权用户和微博信息提取及处理的方法。利用API接口可以高效迅捷地获取微博信息,但微博服务商并不完全开放API接口,而且对单位时间内的访问次数也有限制,因此对于所需的关键微博信息如果无法通过API得到时,需要结合其他方法获取。
微博;API接口;信息挖掘
保定科技局计划项目(No.13ZG017)
Takes Tencent microblog as the research object,introduces the API interface of it,and the method of becoming an authorized user and microblog information extraction and processing.Microblog can access the information efficiently and quickly,Microblog API interface service doesn't completely open API interface,but also has a restriction on the access times of unit of time,so for the desired key microblog information if it can't get through API,then needs to combine with other methods to obtain.
