基于张量递归神经网络的英文语义关系分类方法研究
2015-09-18周佳逸上海海事大学信息工程学院上海201306
周佳逸(上海海事大学信息工程学院,上海201306)
基于张量递归神经网络的英文语义关系分类方法研究
周佳逸
(上海海事大学信息工程学院,上海201306)
语义关系分类作为当前语义技术的一个基础领域,获得广泛的关注。提出基于张量空间的递归神经网络算法,利用张量(向量-矩阵对)表示单词,获得更准确的语义分类结果。通过无监督的结构化方式训练模型,大大简便分类过程,舍弃了人工手动标注。实验表明,该算法可以有效识别语义关系,比传统算法性能提高5%以上。
张量;神经网络;语义关系分类
0 引言
随着互联网的广泛使用,大量信息涌入人们的生活。如何在海量信息里寻找出自己需要的信息成为人们探究的一个新课题。在对英文信息的搜索过程中,若能以主题词及与主题词有特定关系的目标单词作为搜索依据,也就是说,将信息查询问题转换为语义关系识别问题,将大大增加搜索的效率。例如,某人需要搜索“search reasons that causes headache”,当存在工具可以自动搜索因果关系时,将减少大量搜索时间,增加搜索效率。除了作为信息搜索功能的基础,语义关系分类方法对于词库建设、各领域语料集建设、社交网络问答系统、文本翻译、词义消歧等都具有潜在的应用价值。词汇的语义关系是进行语义分析的重要基础,而语义关系技术是自然语言处理(Natural Language Processing, NLP)的关键步骤,因此,对于语义关系分类方法的研究是十分必要的,有利于推动相关领域的发展。
鉴于语义关系分类方法在实际应用中的广泛应用,中外学者对此课题已经有了较长时间的关注与研究。
目前,主要的语义关系分类方法包括以下几种:
基于模式识别的方法。此种方法主要是基于已经定义好的法则,在目标文本中进行匹配,搜索出相对应的语义关系。最早提出基于模式方法对语义关系进行分类的是Hearts[1]等人。他定义了“such a as b”和“a and other b”等模式,取得了一定成果。在这之后,越来越多的学者关注基于模式的方法并对此进行了改进。Brin[2]通过迭代的方法,根据构造好的关系实例对在已标注的文本内发现模式。
基于统计的方法。该方法根据所统计出两个词的同现信息大小来判断两个词是否具有语义关系[3]。Peter[4]提出将点间互信息与搜索引擎相结合,通过搜索引擎提交查询,分析返回结果。之后,也有学者提出了将聚类方法和基于模式的方法相结合来进行语义关系分类。
基于图的方法。该方法是通过构建图,并对图进行聚类切分,每一个子图就是语义关系集合。Philippe Muller和Vincent[5]等利用已有词典构建了一个相关的词典图用于分类语义关系。而Einat Minkov[6]等人通过句法分析,根据语义路径来建立图,分类语义关系。
在以上方法中,大多数方法都需要大量的手动标记的语义资源。相比之下,本文主要结合模式方法和统计方法,根据语义树结构对长句进行分词,利用基于张量递归神经网络算法对训练集进行训练,简化了语义关系分类的过程。
1 基于张量递归神经网络的英文语义关系分类方法
1.1基于张量的递归神经网络算法
(1)张量空间的单词表示
单词通过向量空间的表示在语义领域被广泛应用[7]。本文中,单词将不再只由一个向量表示。在张量空间中,单词由一阶张量(向量)和二阶张量(参数矩阵)组合表示。根据Collobert和Weston[8]提出的已经过无监督训练过的50维向量模型,将所有单词向量初始化为x,且x∈Rn。该模型可通过对Wikipedia的文本学习,预测到每个单词在上下文中出现的概率。和其他基于向量空间模型局部同现方法相似,由该方法表示的单词向量可以显示句法和语义信息。与此同时,每个单词也与一个矩阵X相联系。在实验中,矩阵初始化为X=I+ ε,ε为高斯噪声。如果每个向量的维度为n,则每个单词的矩阵为X∈Rn×n。由于表示单词的向量和矩阵通过对语义标签的学习,将不断修正以合成一个可以预测分布的向量序列,因此矩阵的初始化是随机的,通常由单位矩阵表示。
由上述可得,每个一个长度为m的短语或句子可以表示为向量矩阵对,诸如((a,A),...,(m,M))。
(2)单词的递归合成
基于张量的递归神经网络算法是在语义树的基础上进行递归计算,由神经网络算法对训练集进行训练,获得最终结果。
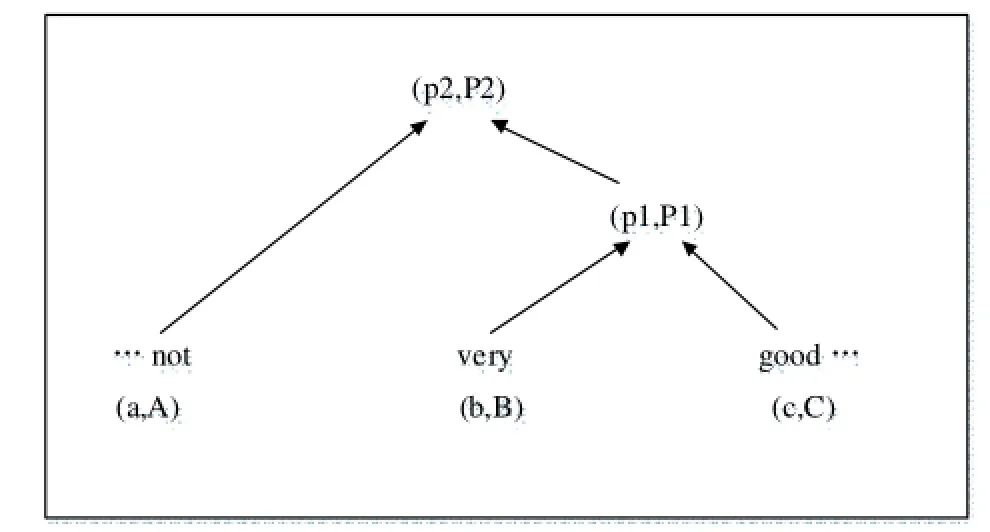
图1 基于张量的递归神经网络模型
父向量p是由两个连续单词的向量a和b计算而来,最常用是由Mitchell和Lapata[9]提出的函数p:p= f(a,b,R,K)。其中R为已知的先验语法,K为背景知识。目标函数f根据不同文本有不同的可能性。
Baroni和Zamparelli[10]在他们的基础上利用向量和矩阵空间的合成,提出针对形容词-名字组合对的函数p=Ab,其中矩阵A表示形容词,向量b表示名字。而Zanzotto[11]在M的基础上,提出了以矩阵空间模型为基础的针对词对的合成函数p=Ba+Ab,向量a,b分别表示两个单词,矩阵A,B则为单位矩阵。
后两种模型的优势在于彻底舍弃了手动标记语料库和明确的背景知识,无需再由人工完成语义标记。
在以上模型基础上进行泛化,获得如下合成函数:
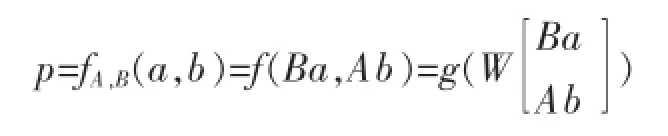
其中A,B为单词的参数矩阵,W为映射所有变形单词到相同维度n的矩阵,W∈Rn×2n。通常,g为一个恒等函数,但此处为了扩大函数范围,使得其不为简单的线性函数,将g设为非线性函数(例如:sigmoid,tanh)。在该模型中,单词的矩阵部分可以反映出具体每个单词带来的参数改变。Baroni等人和Zanzotto提出的模型都是本模型的特殊形式。
在多个单词和短语进行语义合成时,由基于张量空间的词对合成模型来合成长序列词的向量和矩阵。在本模型中,主要思想是利用经过学习的适应于二叉语义树的相同函数f,对单词对进行合成,并对每个非终结点进行矩阵计算。为了计算每个非终短语的矩阵,定义父矩阵为:

其中WM∈Rn×2n,由上式可以计算得P∈Rn×n,与输入矩阵维度相同。
当两个单词在语义树中合成为一个成分时,它可以通过目标函数f和fM计算,继续与其他单词进行下一步的语义合成。
举例来说,图1的张量计算过程为:
①合成向量b和c,以及对应的矩阵,得到(p1,P1),,需要注意的是,当一个单词由n维向量和n×n维矩阵对表示时,整个模型的维度将非常大。为了在计算中减少计算量,并提高计算速度,本模型根据张量分解算法,将矩阵进行如下分解:
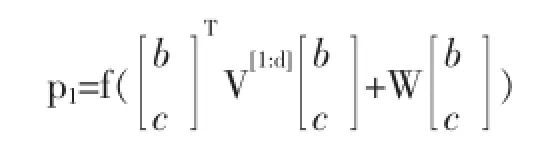
②合成的向量矩阵对(p1,P1)与a相结合,获得上层非终结点的向量矩阵对(p2,P2),
③重复①,②,应用函数f,fM自底向上递归计算各个节点,直至计算出顶层节点的向量和矩阵对,获得语义合成的最终结果。
(3)模型训练
递归神经网络的一大优势在于树的每个节点都可以由向量来表示。通常,通过训练每个节点的softmax分类器来预测各个类别的分布。语义关系分类通常表示为函数:
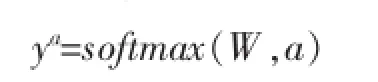
其中,Ws情感分类矩阵。若单词大小为|V|,则Ws∈R|V|×d。a表示分类器所在的单词。
在整个模型的训练过程中,定义θ=(W,WM,Wlabel,L,LM作为模型参数,λ为规范化的先验分布参数。L和LM为单词的向量集和矩阵集。由此得到梯度的求值公式为:

上式中,E(x,t,θ)为误差函数。为得到梯度值,需先自底向上计算每个节点的(pi,Pi),然后自顶向下采用softmax分类器进行计算。在此过程中,充分利用张量分解的优势,对计算过程进行简化,加快计算速度。
1.2基于张量神经网络的英文语义关系分类方法分析
通过语义树的建立和基于张量的神经网络算法,该模型可以获得语法分析中的语义关系,特别是名词间的关系。举例来说,英文文本“My[apartment]e1has a big[bathroom]e2.”中,通过深度学习,可分析出“bathroom”和“apartment”的关系为局部-整体的关系。语义关系分析方法对于信息提取有重要作用,同时也是词库建设的基础。
语义关系分类方法需要模型拥有处理两个任何类型的名词的能力。如图2,解释了本模型如何对名词关系进行分类。首先,找到需要分类的两个名词在二叉语义树中的路径。然后选择最高节点,以最高节点的向量为语义关系分类的特征向量。再由两个词组成的二叉树内使用基于张量的神经网络算法对数据进行处理,获得语义关系的分类结果,其中节点的参数矩阵将包含行列数、数据集跳过信息、正确分类关系信息等数据。
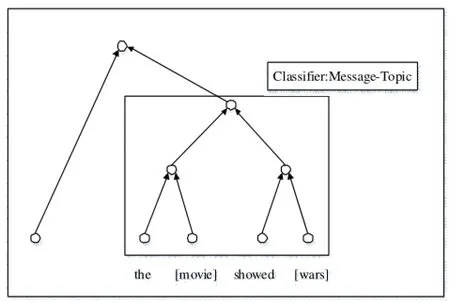
图2 语义关系分类原理图
2 实验
2.1评价标准
为了测试基于张量神经网络的英文语义关系分类方法与其他方法的效率,我们使用了NLP&CC语义关系抽取评测大纲中的指标,以F1值最为参考标准。F1值为正确率和召回率的调和平均数。
正确率为:
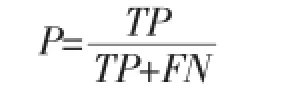
其中,TP为提取出正确信息条数,FP为提取出错误信息条数,TP+FP为提取出的信息总数。
召回率为:
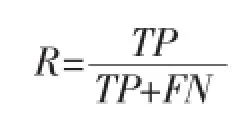
其中,TP为提取出正确信息条数,FN为未提取的正确信息条数,TP+FN为所有需要提取的信息数。
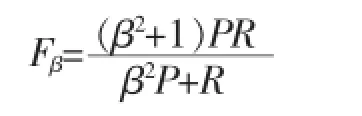
通常,F-measure设置β=1时,即:
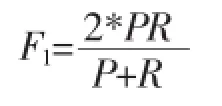
2.2实验坏境及步骤
本次实验将仿真环境架设在Linux系统中,版本为Ubuntu 14.04 64bit。编程语言版本为Python 2.6,JDK 1.7,配合MATLAB软件完成最后的训练及测试工作。
具体实验步骤如下:
(1)准备语料集,对语料库进行处理,去除多余的空格以及符号,规范化格式,转变为纯文本文件,为后续的分词做准备。
(2)使用Stanford-Parser自然语言处理工具包,调用其英文处理模块englishPCFG.ser.gz对文本进行分词,使用sst-light工具对词性进行标注,如NN(常用名词)、VV(动词)等,每一个句子都可以拆分成若干个带标注的词语组成的语义树,如图3所示。
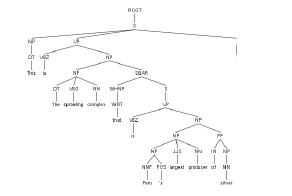
图3 经过分词处理的语义树
(3)步骤(2)生成了分词以及标记过的文本数据,得出每个单词的词性及含义。因此,可根据步骤(2)获得两个名词间的最小子树,对其进行处理分类。
(4)获取最小子树中两个名词的向量-矩阵对,加入特征集(POS,NER,WordNet)
(5)利用算法计算欧几里得距离并获得相关参数及F1值。
在数据集的选择上,本实验选择了SemEval提供的语料库。SemEval(Semantic Evaluation)作为致力于语义研究系统的国际机构,其提供的语料库具有一定的参考意义。在SemEval中,将数据集中的语义关系分为9种(Cause-Effect、Instrument-Agency、Product-Producer、Content-Container、Entity-Origin、Entity-Destination、Component-Whole、Member-Collection、Message-Topic),并额外增设一个other类(任何不属于这9类语义关系的类别将被分入other类中)。
将语料集按照上述步骤进行处理,放入训练好的模型中,得出F1值。为了对实验方法进行公证的评价,将本实验得出的F1值与基于张量的递归神经网络算法(Tensor Recursive Neural Network,TRNN)与支持向量机模型(Support Vector Machine,SVM)、递归神经网络算法(Recursive Neural Network,RNN)、线性向量-矩阵递归神经网络算法(Linear Vector-Matrix Recursive Neural Network,Lin.RNN)F1值的比较,获得算法性能的对比。
实验结果如表1所示。

表1 实验结果
3 结语
本文研究了一种用于语义关系分类的基于张量的递归神经网络算法。该算法中,以向量-矩阵对的形式表示一个单词,向量用于表示单词,而矩阵参数表示该单词与邻接单词的修饰作用。在计算过程中,通过对矩阵选择张量分解算法进行简化,明显提高了计算速度。与其他算法相比,该算法在经过非监督化的结构学习过程后,对语料库的语义关系分类效果较好。使得语义关系分类过程大大简化,无需大量人工对语料库进行标注。
然而,该算法在学习过程中,也存在所需时间较长的不足,我们下一步将致力于探寻更高效的训练方法,以进一步提高训练速度。
[1]Hearst,Marti A.Automatic Acquisition of Hyponyms from Large Text Corpora[C].Proceedings of the 14th International Conference on Computational Linguistics.New York:ACM.1992:539~545
[2]Sergey Brin,Rajeev Motwani,Lawrence Page,Terry Winograd.What Can You Do with a Web in Your Pocket[J].IEEE Data Engineering Bulletin,2008(21):37~47
[3]John Rupert Firth.A Synopsis of Linguistic Theory[J].Philological Society:Studies in Linguistic Analysis.1957(4):1930~1955
[4]Oren Etzioni,Michael Cafarella,Doug Downey,etc.Unsupervised Named-Entity Extraction from the Web:An Experimental Study[J]. Artificial Intelligence,2005,6(165):91~134
[5]Philippe Muller,Nabil Hathout,Bruno Gaume.Synonym Extraction Using a Semantic Distance on a Dictionary[C].Proceedings of the First Workshop on Graph Based Methods for Natural Language Processing,2006:65~72
[6]Einat Minkov,William Cohen.Graph Based Similarity Measures for Synonym Extraction from Parsed Text[C].Proceedings of the 7th Workshop on Graph Based Methods for Natural Language Processing,2012:20~24
[7]Richard Socher,Alex Perelygin,Jean Y.Wu,Jason Chuang,Christopher D.Manning.GloVe:Global Vectors for Word Representation,2014[J]
[8]Collobert and J.Weston.A Unified Architecture for Natural Language Processing:Deep Neural Networks with Multitask Learning[C]. In ICML,2008
[9]Mitchell and M.Lapata.2010.Composition in Distributional Models of Semantics[J].Cognitive Science,38(8):1388~1429
[10]Baroni,Robert Zamparelli.Nouns are vectors,adjectives are matrices:Representing adjective-noun Construction in Semantic Space [C].In EMNLP.2010:1183~1193
[11]M.Zanzotto,I.Korkontzelos,F.Fallucchi,S.Manandhar.Estimating Linear Models for Compositional Distributional Semantics. COLING,2012
Research on the Classification of English Semantic Relationships Based on Tensor Recursive Neural Network
ZHOU Jia-yi
(College of Information Engineering,Shanghai Maritime University,Shanghai 201306)
Classification of semantic relationships is a basic area of semantic technology and gains wide attention.Introduces a better approach to classify semantic relationships of words,tensor recursive neural network model which uses tensor(vector-matrix pairs)to represent a single words.The model trains the data by an unsupervised and structural way,which has no more need of hand-labeled corpus and simplify the process of classification.The experiment shows that the algorithm can classify semantic relationships effectively,and the outperform improves by 5 percent.
Tensor;Neural Network;Classification of Semantic Relationships
1007-1423(2015)11-0043-05
10.3969/j.issn.1007-1423.2015.11.008
周佳逸(1990-),女,上海人,硕士研究生,研究方向为神经网络、语义分析
2015-03-03
2015-03-31
