利用互信息和聚类抽样的文本情感分类
2015-09-18陈智,李鹏,2
陈 智,李 鹏,2
(1.武汉科技大学计算机科学与技术学院,武汉430065 2.智能信息处理与实时工业系统湖北省重点实验室,武汉430065)
CHEN Zhi1,LI Peng1,2
(1.College of Computer Scienceand Technology,Wuhan University of Science and Technology,Wuhan 430065;2.Hubei Province Key Laboratory of Intelligent Information Processing and Real-time Industrial System,Wuhan 430065)
利用互信息和聚类抽样的文本情感分类
陈智1,李鹏1,2
(1.武汉科技大学计算机科学与技术学院,武汉430065 2.智能信息处理与实时工业系统湖北省重点实验室,武汉430065)
为了将文本情感划分更细的类别,提出一种利用互信息和聚类抽样的文本情感分类方法,对文本进行分词和特征提取的预处理,通过聚类抽样得到的情感标签之间的互信息,组合情感标签的互信息得到情感类别,并根据互信息调整特征词库的权重,最后利用中心性度量综合得出该文本情感的类别。实验通过不同的文本情感分类方式对分类结果进行比较,实验表明,该分类方法优于其他分类方法,从而验证该方法的有效性。
互信息;聚类抽样;情感标签;文本情感分类
0 引言
文本的情感分类研究已久[1],经常被用在新闻、产品的评论的分析上面,对新闻评论的分析可以了解观点持有者对一个观点的立场,产品情感分析可以帮助用户了解某一产品在大众心目中的口碑。传统的情感分类仅仅对情感倾向做出一个分类,即将情感分为3类:正向、负向和中性的,或者是更简单的正负两类。这样的分类被广泛应用到商业智能中,但是对于更复杂的分析,我们需要更详细的分类,例如站在用户心理的角度分析当时用户的情感状态。
文本情感分类的方式主要有两种:非监督和监督的方式。非监督的方式是通过一些先验情感知识结合一定的方法获取情感规则进行分类;监督的方式是通过机器学习里面的几种经典的分类方式(朴素贝叶斯、最大熵分类、支持向量机)进行训练、分类。文献[2]是利用微博(Twitter、Blogs)文本建立语料库,然后通过机器学习的方式训练,对文本情感进行分类分析的。文献[3]结合了两种机器学习的方式(生成方式和判别方式),消除了两种分类方式的不足。而对于多种类别的分类,文献[4]描述了一种通过监督训练的方式对6种基本的情感类别进行分类,该方法发现对于某些情感比较合适,而其他情感则分类并不明显。在中文信息处理方面,中文词汇要远多于英文词汇,而且中文文本的分词存在许多歧义问题,因此对于学习的过程就需要大量的训练文本,造成了分类的困难。文献[5]提出了一种利用非监督的方式进行文本分类而且获得了较高的准确度。
本文提出了一种利用互信息和聚类抽样的文本情感分类方法。首先考虑无情感标签的方式对文本进行分类,发现仅仅利用情感类别词汇并不对情感类别具有一个较好的表达作用。然后引入了情感标签,但考虑到情感标签数量较多,需要对其进行抽样,利用随机抽样的方式不理想,随机抽取标签并不具备较好的代表性,最终本文利用互信息对文本情感标签进行分类,然后对标签的抽取采用了聚类抽样的方式,在先验情感词库的基础之上,通过分析文本里面词汇具有的一些情感含义,综合特征词汇得出文本的情感分类,取得了较好的效果。
1 分类方法
1.1先验知识库
对于情感的分类,我们利用《中文情感词汇本体说明文档V1.0》的情感分类作为分类类别标注。该标准将情感分为7大类:乐、好、怒、哀、惧、恶、惊;21小类:快乐、安心、尊敬、赞扬、相信、喜爱、祝愿、愤怒、悲伤、失望、疚、思、慌、恐惧、羞、烦闷、憎恶、贬责、妒忌、怀疑、惊奇。实验利用这21小类的情感作为情感分类的基本情感。另外引用的是针对这个情感分类的标准的一个情感词汇的词库,对于每个情感词汇,包含这样一些信息:词语、词性种类、词义数、词义序号、情感分类、强度、极性、辅助情感分类、强度、极性,本文将引入这些情感的词汇作为情感标签。
1.2系统的整体思想
利用互信息和聚类抽样的文本情感分类是通过分析情感标签与情感类别之间的互信息关系进行的,可以分为如下几个阶段:
(1)预处理阶段
(2)互信息评价阶段
(3)综合评价阶段
预处理阶段是对分本进行分词和特征提取得到特征词的处理过程;互信息评价阶段是针对每个词求取它们与选取的情感标签的互信息,对词汇进行权重调整,然后综合情感标签的互信息到情感类别,得出情感词汇与情感类别之间的互信息关系的过程;综合评价阶段是对所有分析之后的词汇进行一个总体上的评估,得出文本的情感分类。
2 算法描述
2.1词汇预处理
对于文本的分析,首先都需要经过预处理的阶段。将文本用一种形式表现出来。词是表达文本信息的一种简单又合理的方式,每个词有自己的意思,词的组合就成了句子,而句子的组合就成了一段文本。对一段文本进行表示,常用的方法是利用一组特征向量进行表示。对此,我们就需要对文本进行分词、特征提取。
(1)分词
分词的方法被分为三类:基于字符串匹配的分词、基于理解的分词和基于统计的分词。字符串匹配的方式是最常用的一种分词的方式,也是目前准确度最高的分词方法。文献[6]采用的是二字Hash索引的分词方法,这是分词最基本最传统的基于词典的分词方式。该方法的缺点是对词典的依赖过高,因此,常常需要对未登录词、人名、地名进行识别,常用的识别方法是基于统计学的一些方法。近些年研究得比较多的是通过统计的方式进行分词。
本文利用的是字符串匹配的方式,通过对分词词典建立二字Hash索引,可以快速地进行分词。
(2)特征提取
文本特征向量进行提取,常常需要进行一些筛选,不然文本特征就不具备代表性。文本特征提取的方式有很多,主要是针对多文本之间词汇的信息量进行提取,如:比较常用的TDIDF的特征提取是根据词汇的频率和它的反文档频率进行权重评价的。文献[7]在研究文本情感分类的基础上,比较了多种特征提取的方式,然后通过传统的分类方式验证特征提取的有效性。在本实验中,由于只是对单文本进行特征提取,因此需要利用先验权重和词频进行权重评价。先验权重在实验第二阶段通过互信息进行调整。
由于事先没有通过大量文本反应的权重的特征来计算词汇的权重,因此第一步只是简单地选择词汇在本文本中出现的次数作为权重,而对于数据库里面已有的词汇权重的就利用词汇出现次数乘上权重,即:

其中,Freq(c)表示词汇c在本文本中出现的次数,w*表示词汇c在数据库中保存的权重,这一阶段的输出数据应该是c1w1,c2w2,…,cnwn,其中wi表示第i个特征词汇,其中ci表示第i个特征词汇的权重信息。
2.2互信息评价
(1)互信息概念模型
互信息是计算语言学模型分析的常用方法,它度量两个对象之间的相互性。互信息在非监督的情感分析上也经常被用到,作为词汇情感衡量的规则,文献[8]很简单却十分巧妙地利用了互信息,通过计算给定短语与“优”的互信息减去给定短语与“差”的互信息而对其进行的分类。文献[9]采用了互信息的方式,并在互信息上进行了相关小的改进而达到了一个不错的分类效果。基于此,本文采用互信息评价两个特征词和情感类别之间的相关性质。它的计算公式为:

其中p(x,y)表示特征词x和情感类别y共同出现的概率,p(x)、p(x)表示x、y单独出现的概率。
为了弥补直接通过情感类别词汇的稀疏性质,本文在度量词汇与情感类别的互信息的基础上,间接引入了一组中间的情感标签,通过分析词汇与情感标签之间的互信息,然后通过情感标签与情感类别之间统计关系,来间接地得到词汇与情感类别之间的互信息。这里借助于一个情感标签的词库,这个词库中每个情感词汇都作为一个情感标签,每个情感标签都属于一个情感类别,以及包含这个情感强度。在这个中间情感标签的作用下,就可以将特征词汇映射到情感的类别。互信息评价模型具体见图1,在该模型中,首先求特征词汇与情感标签之间的关系,然后利用情感标签与情感类别之间的关系将特征词汇与情感类别之间的关系映射起来。最后就可以利用这个对应关系对文本情感进行分类。
(2)文本互信息的计算
在文本互信息的计算过程中,首先仅考虑特征词汇与情感类别词汇之间的互信息的计算。对于每个特征词与情感类别词汇之间的互信息,乘上特征词汇的权重就可以表示两者对于本文本的互信息的度量,计算公式如下:
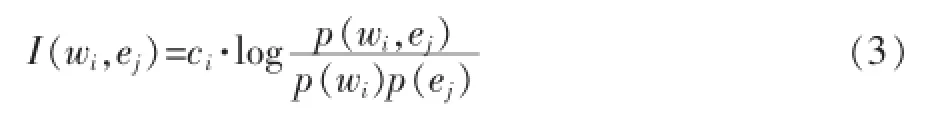
其中wi表示第i个特征词汇,其中ci表示第i个特征词汇的权重,ej表示第j类情感。该值越大,说明这个特征词与这一类情感联系更为紧密,即这个词更一般地表现这类情感。
对于互信息的频数统计,我们首先通过对微博建立索引,然后对需要统计的词汇进行查询,即可以得到两个词共现和它们单独出现的频数。我们通过Lucence提供的开源工具对微博数据建立索引。对于特征词与情感类别词汇在本文本的互信息度量的统计模型为:
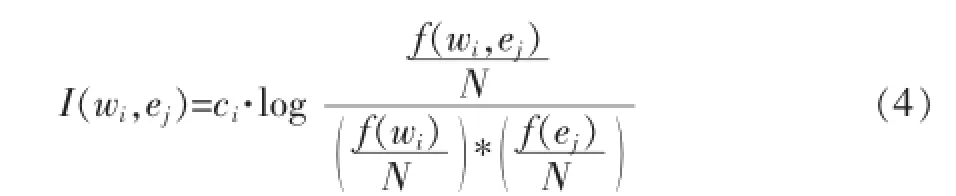
其中,f(wi,ej)是特征词汇wi与情感类别词汇ei共现的频数,f(wi)是wi单独出现的次数,f(ej)是ei单独出现的次数,N是文档即微博的总数。这个公式引入了词汇的权重,对于词权较高的特征词,表示了其对文本的情感贡献度较高,因此情感的关联度应该更大。
然后我们引入情感标签。由于情感类别的词汇覆盖的范围窄,这里为了对情感做一个更好的估计,我们引入一个情感词库,每个词作为一个情感标签,用集合E={et1,et2,…,etn},在计算词汇与情感类别的互信息时,首先计算特征词汇与情感标签的互信息,即I(wi,etj),然后通过情感标签的情感类别以及情感强度计算词汇与情感类别的互信息。
情感标签的情感强度是对这个标签与对应的情感类别的一个频数的统计,它与总体的情感强度的比值就是这个标签对这个情感类别贡献的概率。因此,在得到特征词汇与情感标签的互信息之后,对第i个特征词汇与第j个情感类别之间的互信息度量如下:

其中Iikj是情感j下的第k个标签与特征词汇i对应的互信息,nj是属于情感j的情感标签的数量,wjk是第j类情感的第k个情感标签的权重,分数表示属于情感j的第k个情感标签强度与情感j的总强度的比值。因此,上面的公式表示的就是特征词汇i对应情感类别j的互信息的一个期望值。
(3)情感标签的抽样
由于一个情感类别包含较多的情感标签,因此需要对情感标签进行一个抽样。抽样的方式主要有随机抽样、分层抽样、系统抽样、聚类抽样等方法。随机抽样即随机地选取一定数量的样本,但随着样本的数量过大,随机抽样将变得不那么准确;聚类抽样是将总体中各单位归并成若干个互不交叉、互不重复的集合,称之为群;然后以群为抽样单位抽取样本的一种抽样方式。系统抽样,当总体中的个体数较多时,采用简单随机抽样显得较为费事。这时,可将总体分成均衡的几个部分,然后按照预先定出的规则,从每一部分抽取一个个体,得到所需要的样本。
本文所利用的抽样是聚类抽样,本文使用的情感标签先前就已经有了一个类别属性,基于如下假设:每个情感类别下的情感标签都存在一定的分布,即同一个类别的情感标签也会形成簇。本文的聚类抽样是在这个类别下面进一步进行聚类。具体过程如下:
①对所有类别的情感标签进行分类;
②对每一个情感类别下的情感标签求两两之间的相似度,以此相似度矩阵作为聚类的方式,相似性的度量是:

其中dist(eti,etj)表示两个标签之间的距离,p(eti)是标签eti的单独出现的概率,p(eti,etj)是标签eti,etj共现的概率,公式取互信息的倒数作为距离的度量,表示两个标签的不相关程度,即两者之间的距离;
③通过AP聚类算法[10]进行聚类,最后选取聚类中心点作为聚类抽样的样本。
(4)词汇权重调整
求出每个词对应情感的互信息后,接着需要根据这些互信息调整特征词库的权重。互信息理论进行特征抽取是基于如下假设:在某个特定类别中出现频率高、但在其他类别中出现频率低的特征词,与该类的互信息比较大。这条假设也说明了这样一个性质,即:在一个特征词与所有的情感类别的互信息中,应该有一类或少数几类相比其他类别具有较高的互信息。所以,这里的权重调整的思想是:赋予那些情感相关性高,而且区分度大的词汇一个较高的权重。
因此,在本文的权重计算中,利用方差这一属性表示词汇对情感类别的区分度,而利用词汇向量中的最大的互信息值与总体平均互信息值的差来表示情感的相关性强度。利用二者的乘积进行权重衡量的参数,它们的计算公式如下:
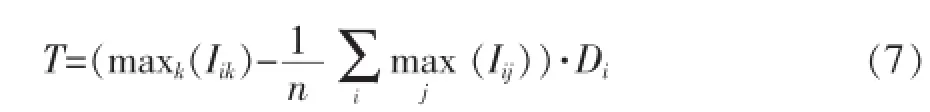
其中,Iik表示第i个词汇的与第k个情感的互信息值,maxk(Iij)即表示这个特征词的互信息向量中的最大互信息值。就是对所有特征词汇的互信息向量中的最大值取一个平均值,它们之间的差值就表示了这个特征词汇情感相关性强度,当值为正时就表明特征词与至少其中一个类别的相关性强,为负则表明这个特征词不与任何一个情感类别强相关。Di是第i个特征词汇对应的互信息向量的方差,即:

其中,Iik是第i个特征词汇与第k个情感类别的互信息。它表示的意义是一个权重较高的特征词应该对于不同的情感类别具有较高的区分度。
为了让权重增减的迭代过程能够有一个收敛,利用sigmoid函数,乘上系数2,将其变化倍数控制在(0,2)的区间内,当函数的参数值为0的话,权重调整函数值为1,即表示权重调整不变。具体如下:

其中Ci是第i次迭代的结果,k是收敛系数,表示调整权值的速度的快慢。当k较大时权值收敛得比较快。需要将将权值的调整范围控制在设置一个收敛区间(a,b),然后设定收敛系数k控制收敛的速度。
在这个过程结束后,会形成一个量化的特征词——情感词的矩阵U。
2.3综合评价
进行了上述工作以后,得到每个词汇在这个文本所属情感类别的一个判断,现在还需要根据文本的特征词的情感互信息属性来进行一个综合的度量,分出这个文本所属的情感类别。对于这个特征-情感的矩阵,对情感构成的列空间进行分析,每个情感在这个文本中都维持一个词汇相关度的矩阵E={e1,e2,…,en},第i个情感用向量表示为:ei=(Ii1,Ii2,…,Iin),因此可以对这些向量进行评估,找出一个最适合成为中心的情感向量来代表整个文本的情感属性。
对于中心点的度量,是通过情感向量之间的相似度进行度量的。因此,首先形成一个相似度矩阵S表示情感与情感之间的距离度量,当然这个距离度量是建立在当前文本的基础上的,相似度的求法采用余弦值得方式进行求解:

其中,x、y分别是两个向量,即x=(x1,x2,…,xn)。在得到情感之间的距离矩阵之后,就可以通过情感之间的距离综合选择一个中心的情感。每个情感与情感之间都构成一段距离,用图的方式去解决这个问题就是寻找全图中的中心点。中心点的度量有多种方式,本文采用的中心点度量的方式是度中心性。度中心性是将这一点与其他点之间的权重进行累加:

其中wij表示(i,j)的权值,即可以取距离的倒数,对每个点计算其度中心性,选取最大中心性的点作为中心。
3 实验结果及分析
3.1实验相关参数
实验通过随机地从微薄上获取的一些文本进行处理分析。选取100条需要评测的微博,首先人工进行评测,对每条微薄都进行人工分类,然后对这100条文本分别采用的方式进行分类。为了能够对实验结果有一个更加客观的评价,对标签的选取这一变量进行,对3种分类方式进行对比:
(1)利用互信息和聚类抽样的分类(Our):这是本文采用的方式,采用情感标签,通过聚类抽样对情感标签进行抽取,然后求互信息对文本情感进行分类。
(2)利用互信息和随机抽样分类(Random):利用互信息方式,但是抽样的方式采用随机抽样的形式。
(3)无情感标签的分类(None):直接求特征词汇与情感类别词汇的互信息,利用情感类别词汇代表情感类别。
3.2实验评价指标
本实验采用了如下的评价指标:对于每个要被分类的文本,它所包含的情感。因此在人工进行情感评测时应该对一个文本评测多种情感。这里对每一个文本分别评测两类情感:主要情感和次要情感。如果分类情感符合主要情感,则准确率取1;如果分类情感符合次要情感,则准确率取0.5;其他的都属于错误分类的,准确率取0。因此,这里针对存在正交的情感类别,定义准确度评价公式为:

其中,PN表示正确分类为主要情感的微博条数,SN表示被分类为次要情感的微博条数,MN表示被错误分类的微博条数。
同时,本文还比较了聚类抽样分类和随机抽样分类的运行时间,即平均每条文本分类的全过程所花费的时间。由于无标签分类相当于每次只使用了一个标签,用时很少,故不对其时间比较。
3.3结果分析
本文首先比较不同标签数目下各种算法的准确度。图2选取的标签数目为3、5、8、10、15,在这5种标签数目下对数据进行分类,然后统计分类的准确度,由图2可以看出,使用本文利用互信息和聚类抽样的文本情感分类效果要明显好于其他两种方式,随着聚类簇的增多,准确度的表现是先增高后降低,说明了在选取合适的簇数目下面可以得到一个比较好的分类效果。而随机抽样方式的准确度随着标签的个数增加而增加,在标签数目较少的情况下,随机抽样方式的效果比不使用标签的效果更低,只有当足够数目的标签时,才能获得一个相对可观的准确度。
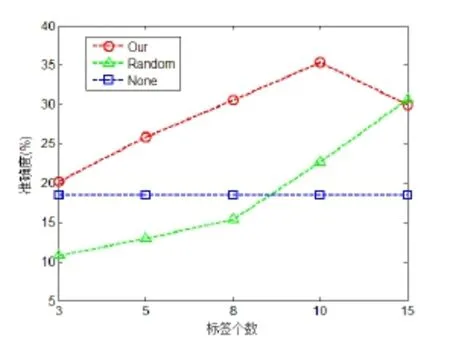
图2不同个数标签的3种分类方式比较
图3给出了在不同数目的情感分类下面3种方法的准确度,分别选择情感类别个数为2、5、7、10、21。由图3可以看出,随着分类类别的数目的增加,分类的准确度降低,但仍可以看到本文提出的利用互信息和聚类抽样的分类效果要好于其他两种。
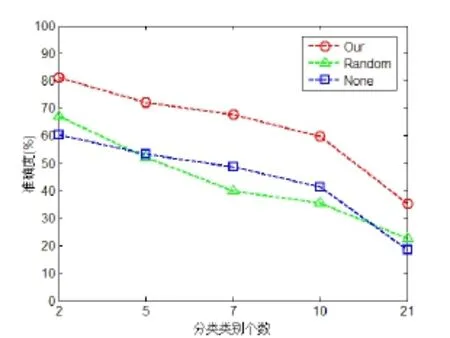
图3 不同类别数目的3种分类方式比较
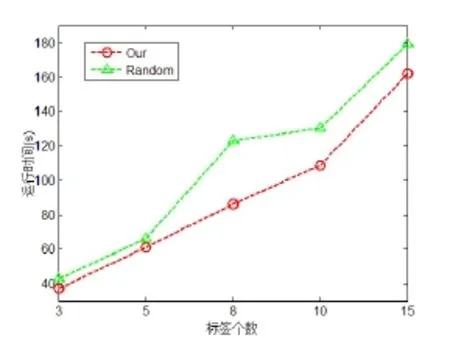
图4 两种标签抽样分类方式的时间比较
最后,我们对比了不同分类方式下的平均时间,具体如图4所示。由图4可以看出,随机抽样方式与本文所提方式的时间大致相等,由于随机抽样里每次都需要对重新抽取的标签计算一下其频数,因此在时间上要稍微高于本文中所用的聚类抽样。而且,随机抽样存在一个不稳定性,对于标签的抽取,不同时间抽取到的标签在频数上面存在很大差异性,因此,分类所用的时间随着标签数的增长也存在一些波动,而本文所提的聚类抽样是相对比较稳定的。
4 结语
本文提出了一种新的对文本情感进行分类的方法,站在更细的情感类别粒度下,采用互信息和聚类抽样的方式,从文本情感类别的概率分布考虑一段文本的情感。实验表明,本文提出的利用互信息和聚类抽样的文本情感分类方法优于其他分类方法,从而验证了该方法的有效性。
[1]Pang B,Lee L,Vaithyanathan S.Thumbs up:Sentiment Classification Using Machine Learning Techniques[C].Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing-Volume 10.Association for Computational Linguistics,2002:79~86
[2]Yang C,Lin K H,Chen H H.Emotion Classification Using Web Blog Corpora[C].Web Intelligence.IEEE/WIC/ACM International Conference on.IEEE,2007:275~278
[3]夏睿,宗成庆.情感文本分类混合模型及特征扩展策略[J].智能系统学报,2011,6:1673~4785
[4]Purver M,Battersby S.Experimenting with Distant Supervision for Emotion Classification[C].Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics.Association for Computational Linguistics,2012:482~491
[5]Zagibalov T,Carroll J.Automatic Seed Word Selection for Unsupervised Sentiment Classification of Chinese Text[C]Proceedings of the 22nd International Conference on Computational Linguistics-Volume 1.Association for Computational Linguistics,2008:1073~1080
[6]李庆虎,陈玉健,孙家广.一种中文分词词典新机制——双字哈希机制[J].中文信息学报,2003,17(4):1003-0077
[7]周茜,赵明生,扈曼.中文文本分类中的特征选择研究[J].中文信息学报,2004,18(3):17~23
[8]Turney P D.Thumbs up or Thumbs Down:Semantic Orientation Applied to Unsupervised Classification of Reviews[C].Proceedings of the 40th Annual Meeting on Association for Computational Linguistics.Association for Computational Linguistics,2002:417~424
[9]Farag Saad and Brigitte Mathiak.2013.Revised Mutual Information Approach for German Text Sentiment Classification.In Proceedings of the 22nd International Conference on World Wide Web Companion(WWW'13 Companion).International World Wide Web Conferences Steering Committee,Republic and Canton of Geneva,Switzerland,579~586
[10]Frey B J,Dueck D.Clustering by Passing Messages Between Data Points[J].Science,2007,315(5814):972-976
CHEN Zhi1,LI Peng1,2
(1.College of Computer Scienceand Technology,Wuhan University of Science and Technology,Wuhan 430065;2.Hubei Province Key Laboratory of Intelligent Information Processing and Real-time Industrial System,Wuhan 430065)
To divide the text sentiment into finer categories,proposes a text sentiment classification method by using mutual information and cluster sampling.Uses the text pre-processing for text segmentation and feature extraction,and calculates the mutual information of each sentiment tag by cluster sampling.Obtains sentiment categories by combination of sentiment tags,and adjusts the weight of key word by mutual information.Derives the text sentiment classification by using center metric.Compares different text sentiment classification in the experiment.The results show that the proposed classification method outperforms other classification methods and verify the effectiveness of the proposed method.
Mutual Information;Cluster Sampling;Sentiment Tag;Text Sentiment Classification
Text Sentiment Classification Based on Mutual Information and Cluster Sampling
武汉科技大学大学生科技创新基金项目(No.13ZRC071)
1007-1423(2015)11-0014-07
10.3969/j.issn.1007-1423.2015.11.003
陈智(1992-),男,湖北荆州人,在读本科
李鹏(1981-),男,湖北武汉人,讲师,硕士,研究方向为分布式计算、移动计算
2015-03-25
2015-04-08
