空间关键词查询研究综述
2015-09-16李维丹
李维丹
空间关键词查询研究综述
李维丹
(同济大学计算机科学与技术系,上海201804)
随着定位服务技术的出现,越来越多的应用把现实对象与空间位置关联起来,衍生出应用广泛的空间关键词查询,即结合空间查询和文本查询以寻求最优结果的混合查询。对空间关键词查询领域的研究进展进行总结,特别对各种查询方法的索引机制、查询策略、性能评估、适用范围进行详细的分析与比较;同时,详细介绍一种分布式空间关键词查询系统,并指出空间关键词查询尚存的开放问题。
空间数据库;空间关键词查询;索引结构;分布式计算
0 引言
随着定位技术的发展,越来越多的对象(如行人)和空间位置紧密关联起来。此外,Web上包含的位置信息也越来越多。这些变化促进了空间关键词查询(Spatial Keyword Query,SKQ)[2~5]的发展。
空间关键词查询主要分为空间查询和关键字查询。目标是找出包含查询关键词且距离查询位置最近的若干对象。例如,用户通过手机查询距离当前位置最近的书店。
近年来,快速有效地返回空间关键词查询结果成为学术界的研究热点,并提出了各种解决方案。本文基于这些研究成果,对空间关键词查询的最新进展进行综述,分析和比较了空间关键词查询处理关键技术,包括索引结构、查询策略及结果排序与评估等。
1 问题定义与技术挑战
在一个空间关键词查询中,给定一个数据集P。设o是P中的一个对象,o=〈o.id,o.s,o.t〉,o.id用于唯一标识对象o;o.s是对象o的空间属性;o.t是对象o的文本描述。
用q=〈q.s,q.t,q.k〉表示一个空间关键词查询。其中,q.s是查询的位置,q.t是查询关键词,q.k是需要返回的结果数目。
空间关键词查询q的目标是从数据集P中找出q.k个最优对象。一般,评价函数f(o,q)定义为:

其中,δ(o.s,q.s)用于计算对象位置o.s和查询位置q.s之间的距离;θ(o.t,q.t)用于计算对象的文本描述o.t和查询的关键词q.t之间的相关度;α是一个权重因子,用于两种度量的权重分配。
下面给出了空间距离计算和文本相关度计算的主要公式:
(1)空间距离(δ)
在空间关键词查询中,δ一般是欧氏距离,计算公式为:

其中d(o.s,q.s)是o.s和q.s之间的距离,dmax是数据空间中距离的最大值,用于归一化处理。
(2)文本相关度(θ)
计算文本相关度的方法很多,应用较广泛的是计算两个文本向量的余弦值。使用这种方法,θ可表示为:
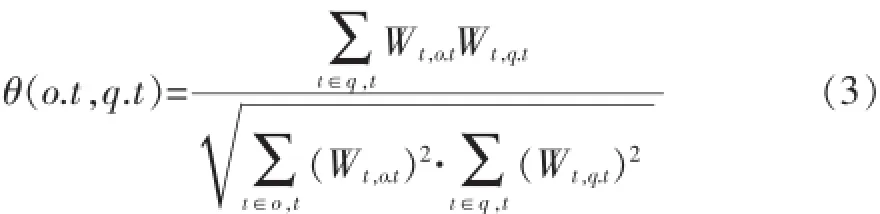
其中,Wt,o.t=q+ln(ft,o.t),ft,o.t表示关键词t在文本描述o.t中出现的频数;,其中|P|表示对象的个数,dft表示包含t的文档数。根据余弦性质可知计算结果在[0,1]内,这样就能和距离计算结果的范围保持一致。
2 空间关键词查询处理的基本技术
空间关键词查询主要研究如何提高查询效率并拓展其实际应用。其中的关键问题是如何构建合适的索引结构。此外,还需要对查询结果进行排序。以下将详述这些内容。
2.1索引技术
构建高性能的索引是实现高效查询的有效方法。下面,首先介绍基本的空间索引和文本索引技术,然后评述专门针对空间关键词查询的索引技术。
(1)空间索引技术
常见的空间索引技术大致可以分为四类,分别是:
①基于二叉树的索引:基于此索引结构的主要有KD树[9]、K-D-B树[10]、LSD树[11]等。这类空间索引结构适用于点状对象。
②基于B-树的索引:此类索引结构中比较典型的是R-树。R-树将空间对象及索引空间用最小边界矩形(Minimum Bounding Rectangle)来近似表示,将空间相邻的对象组织到同一结点或同一分支,并将一个结点对应成一个或者多个磁盘页。该索引策略大大减少了I/O访问。
③基于哈希的网格技术:这类索引将索引空间划为若干格子,并将每个格子相关联的空间目标存储在同一磁盘页,这样,查询时就能通过格子的标号来定位空间对象。具有代表性的便是Grid文件[13],多用于点状对象。
④空间目标排序法:此方法将多维对象映射到一维空间中,然后采用一维索引来实现。常见的映射方法有Z-排序、Hilbert曲线等。
(2)文本索引技术
文本索引主要是用于关键词查询。关键词查询中常用的索引结构主要是倒排索引(Inverted Index)[14]和签名文件(Signature File)[15]。
①倒排索引
倒排索引是一种简单高效的文本索引,它列出了每个关键词以及包含该关键词的所有对象,如表1所示。
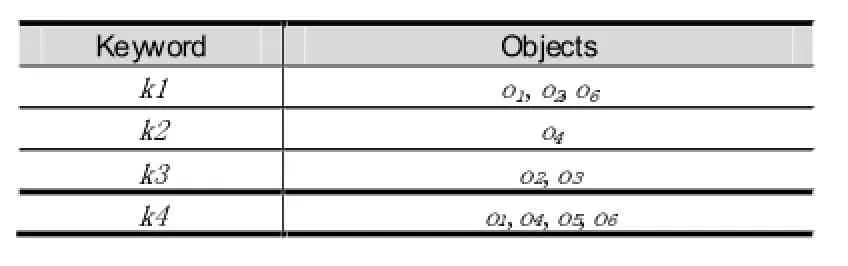
表1 倒排索引
当需查询包含关键词k1和k4的对象时,就相交这两个关键词的对象集合,得到的{o1,o6}即为结果。
(2)签名文件
签名文件也是一种常见的文本索引方式,它为每个关键词分配一个固定大小的向量,称为签名(signature)。对一个空间对象的所有关键词的签名进行OR运算,就形成了该对象的签名。
在查询时,首先生成查询关键词的签名,然后通过AND操作进行检索。
(3)基于空间关键词查询的索引技术
按照构建索引方式的不同,现有针对空间关键词查询的索引结构可分为两类,一类是独立索引[1,4];另一类是混合索引[2~3,5~6]。
①独立索引
针对空间关键词查询的独立索引将传统的文本索引技术和具有空间过滤功能的Quad树[16]、R树[12]、网格索引(grid index)[13]等空间索引独立地用于查询。
例如,文献[3]中采用倒排索引来索引关键词,用网格索引来索引空间位置;而文献[17]使用Quad树和R树来进行空间索引。
基于独立索引的空间关键词查询的效率很低,不适合数据规模较大、查询时间要求较高的情况。
②混合索引
目前,空间关键词查询处理大多采用混合索引,即将空间索引和文本索引结合成统一的索引结构。混合索引可以分为松散混合索引[19]和紧密混合索引[2~3,5~7]。
●松散混合索引
混合索引中使用的空间索引大多是R树[12]或其变体。例如,将空间索引和文本索引松散地结合,为每个关键词建立一棵R*树,查询过程中,首先根据查询关键词找出对应的R*树,然后遍历它查找结果。这种方法对单关键词查询非常有效。
本质上,松散混合索引还未摆脱空间索引和文本索引顺序检索的特点,查询效率波动较大。
●紧密混合索引
紧密混合索引结合了空间索引和文本索引,在查询过程中可同时访问空间索引和文本索引。
采用R-树作为空间索引的紧密混合索引本质上是在R树的结点中加入子结点的文本信息,从而尽早实现对不合理路径的剪枝。
同时进行空间和文本的索引,避免了过多的数据访问,基于此类索引结构的空间关键词查询可有效提高效率。
2.2查询算法
空间关键词查询处理已有多种算法。下面介绍几种代表性的算法。
(1)SK(Spatial Keyword)算法[7]
SK算法基于KR*树索引结构实现。该算法以查询Q和KR*树的根结点N为输入,Q=〈Q.r,Q.t,Q.k〉,给出查询区域、查询关键词和需返回的对象个数。首先,算法检查当前结点的所有子结点,若子结点包含所有的查询关键词,则加入列表。然后检测结点是否与查询区域相交,若相交,且该结点是叶子结点,则将满足条件的对象加入候选集;若相交,但其不是叶子结点,则重复以上计算;若不相交,则剪掉该结点及其子结点。最后,算法返回一个候选集,该候选集里的所有对象都与查询区域相交且包含查询关键词。若要进行top-k查询,则需对候选集进行排序,并取最优的k个对象。
该算法较早实现对空间数据和文本数据的同时处理,能大大减小I/O开销。由于需要在算法结束后进行排序,候选集较大时性能较差。
(2)距离优先IR2树算法[2]
距离优先IR2树算法基于IR2树索引结构实现。该算法中,查询关键词只用于过滤,即只考虑包含全部查询关键词的对象。最后,算法返回包含查询关键词的前k个距离查询点最近的对象,并按与查询点的距离排序。
该算法查询效率很高,I/O开销较少。缺点在于只能实现关键词的布尔查询。
(3)LkT(Location-aware Top-k Text Retrieval)算法[3]
LkT算法主要用于基于位置的top-k空间关键词查询,采用的索引结构是IR-树。
该算法采用最好优先遍历策略[23],依次取得k个查询结果。该算法的查询策略和距离优先IR2树算法基本一致。
(4)三种算法的比较分析
上述的三种算法中,SK查询算法是范围查询,返回的是与给定查询区域相交的对象;后两种是基于距离的查询,返回结果需要排序。三者均支持top-k查询,不过SK查询算法需要对算法的候选集进行排序,而后两种算法可以直接得出k个最优结果。表3给出了三者比较信息。

表2 空间关键词查询算法比较
2.3查询结果的排序与评估
空间关键词查询一般要返回多个对象。这就需要合适的排序策略。现有研究中,排序方式可分两类,一类是直接由查询算法返回排序好的结果;另一类是在查询算法结束后进行排序。
此外,还需评估查询结果的好坏。评估方法主要考虑返回的候选对象的数目和最终结果与查询要求的匹配程度。
2.4空间关键词查询的变体
还有空间关键词查询的变体,如移动空间关键词查询、多目标空间关键词查询等。
目前,针对移动查询的研究主要采用安全区域(safe zone)的思想,若用户在安全区域内,查询结果不变。若用户离开该区域,则重新提交查询,计算新的结果和新的安全区域。
针对多目标关键词查询[8]给出了一种基于贪心算法的方案,首先查找包含部分或者全部关键词的最近对象,然后用还未找到的关键词组成新的查询,直到所有关键词都已经找到或遍历结束。
除了上述两种外,还有其他形式的空间关键词查询。如文献[24]中的基于位置的近似关键词查询,及文献[25]中的联合空间关键词查询等。
3 空间关键词查询的分布式处理
随着实际应用越来越广,在集中式环境下处理空间关键词查询已不能满足对性能和效率的需求。
首先,实际的查询系统往往基于C/S或B/S架构,若用户规模极大,服务端将承担巨大的负荷;其次,移动终端的日益普及导致移动查询日益普及,对于移动查询,用户行进过程中不断向服务端提交查询,服务端不断进行繁重的计算;再次,实际的空间关键词查询往往并不基于欧氏距离,而是基于道路网络(以下简称路网),因为在现实中,从一个地方并不能通过直线路径抵达另一地方,而必须经过道路路径,相比欧氏空间,路网结构更复杂,数据量级更大,查询效率难免降低。
综上,在集中式环境下进行空间关键词查询已不能满足现实应用的需求。于是,在分布式环境中进行处理已逐渐成为空间关键词查询问题的研究方向。如文献[27]提出了一种基于多核平台的平行处理技术,能对SQL语句执行分布处理,文献[28]提出了一种分布式处理基于路网的空间关键词查询技术,文献[29]提出了一种分布式空间关键词查询系统,以下将介绍一个具有代表性的分布式系统。
3.1DISKs(Distribured Spatial Keyword Search)
文献[29]第一次提出基于分布式处理空间关键词查询问题,并提出了能有效处理基于路网的空间关键词查询的分布式系统,即DISKs。
DISKs的架构如图1所示。包含三个模块:分割器(Partitioner)、索引器(Indexer)和分布式查询处理器(Distributed Query Processor)。分割器和索引器用于预先构建索引模块。
(1)分割器和索引器
分割器以一个路网为输入,输出N个小的节点不相交的分区,并将连接各分区的边的终点作为后续步骤的入口节点。
索引器以分割器输出的分区及入口节点为参数,输出名为NPD-Index(Node Partition Distance Index)的索引结构。NPD-Index由N个部分组成,每部分与一个分区关联,并包含两个结构,分别为DL(Distance List)和SC(Short-Cut)。其中,DL是路网中基于节点的搜索树,它的每个叶节点被标记为该节点与其所在分区入口节点的距离。SC结构是一个附加边的集合,每条边连接该分区的两个入口节点。
经过分割器和索引器的处理,使用分区及其相关的DL和SC结构,能准确计算出路网中任何一个位置到该分区中任何一个位置的最短距离。此外,通过将各入口点作为输入,NPD-Index还能实现在整个路网上执行一组Dijkstra算法。
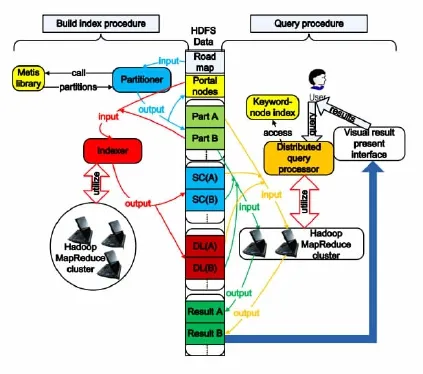
图1 DISKs系统架构
(2)分布式查询处理器
在NPD-Index被构建后,即能在集群中执行分布式查询。将每个分区索引分配给一台机器,从而计算出该分区的结果。分布式查询算法以一个参数r和若干关键词为输入。对于每个关键词K,节点集XK包含所有包含K的节点。对于每个分区P,查询算法执行如下操作:
①对每个包含关键词K的节点集XK,执行如下步骤:
Sub-step 1:查找树DL查找XK中包含的叶节点,并遍历与其距离最大为r的入口节点。
Sub-step 2:从已遍历到的入口节点开始,搜索P与SC的并集,并返回P中到XK中任何节点距离不超过r的节点。
②对所有节点集中的返回节点执行相交操作。①对每个关键词K计算了P中到XK的距离不大于r的节点集。②相交后,找出P中到所有节点集(即每个关键词的相关节点)距离不大于r的节点。
(3)基于Hadoop的DISKs实现
Hadoop工作阶段由map阶段和reduce阶段组成。在map阶段,任务被分配至不同的机器,在reduce阶段,标志相同的map阶段的输出被发送到一台机器上进行下一步操作。
如前所述,以入口节点为输入,NPD-Index结构可实现为一组Dijkstra实例。在map阶段,这些实例可方便地分布于不同机器上进行计算。在reduce阶段,将map阶段的结果汇总在一起。
综上即可完成一次分布式的查询操作。
4 结语
随着空间关键词查询应用的日渐广泛,需要研究的方面也逐渐增多,尚有一些有待深入研究的开放问题。例如,可以考虑将关键词映射到几何空间中,形成一个纯粹的空间索引;基于关键词重要程度进行查询等。
本文对空间关键词查询研究现状进行了综述,分别是从索引技术、查询算法及结果评估等三方面对已有研究成果进行了阐述,并详细介绍了一种分布式空间关键词查询系统。最后,指出了空间关键词查询研究的一些开放问题。
[1]K.S.McCurley.Geospatial Mapping and Navigation of the Web.WWW,2001:221~229
[2]I.D.Felipe,V.Hristidis,and N.Rishe.Keyword Search on Spatial Databases.ICDE,2008:656~665
[3]G.Cong,C.S.Jensen,and D.Wu.Efficient Retrieval of the Top-k Most Relevant Spatial Web Objects.PVLDB,2009:337~348
[4]Y.-Y.Chen,T.Suel,and A.Marowetz.Efficient Query Processing in Geographic Web Search Engines.SIGMOD,2006:277~288
[5]R.Hariharan,B.Hore,C.Li,and S.Mehrotra.Processing Spatial-Keyword(SK)Queries in Geographic Information Retrieval(GIR) Systems.SSDBM,2007:1-10
[6]D.Zhang,Y.M.Chee,A.Mondal,A.K.H.Tung,M.Kitsuregawa.Keyword Search in Spatial Databases:Towards Searching by Document.ICDE,2009:688-699
[7]D.Wu,M.L.Yiu,C.S.Jensen,G.Cong.Efficient Continuously Moving Top-k Spatial Keyword Query Processing.ICDE,2011:541~552
[8]X.Cao,G.Cong,C.S.Jensen,B.C.Ooi.Collective Spatial Keyword Querying.SIGMOD,2011:373~384
[9]J.L.Bentley.Multidimensional Binary Search Trees used for Associative Searching.Comm.ACM,1975,18(9):509~517
[10]J.T.Robinson.The K-D-B-Tree:A Search Structure for Large Multidimensional Dynamic Indexes.SIGMOD,1981:10~18
[11]A.Henrich,H.W.Six,P.Widmayer.The LSD Tree:Spatial Access to Multidimensional Point and Nonpoint Objects.VLDB,1989: 45-53
[12]A.Guttman.R-trees:A Dynamic Index Structure for Spatial Searching.SIGMOD,1984:47-57
[13]J.Nievergelt,and H.Hinterberger.The Grid File:An Adaptable,Symmetric Multi-Key File Structure.TODS,1984,9(1):38~71
[14]J.Zobel,and A.Moffat.Inverted Files for Text Search Engines.ACM Comput.Surv.,2006,38(2):6
[15]C.Faloutsos,and S.Christodoulakis.Signature Files:An Access Method for Documents and Its Analytical Performance Evaluation. ACM Transactions on Office Information Systems.1984,2(4):267-288
[16]R.Finkel,and J.L.Bentley.Quad Trees:A Data Structure for Retrieval on Composite Keys.Acta Informatica,1974,4(1):1-9
[17]R.Lee,H.Shiina,H.Takakura,Y.J.Kwon,and Y.Kambayashi.Optimization Range Query Processing.WISEW,2003:9-17
[18]Z.Li,K.C.K.Lee,B.Zheng,W.C.Lee,D.L.Lee,and X.Wang.IR-tree:An Efficient Index for Goegraphic Document Search.TKDE,2011:585-599
[19]W.Wu,F.Yang,C.-Y.Chan,and K.-L.Tan.Finch:Evaluating Reverse k-Nearest Neighbor Queries on Location Data.PVLDB, 2008:1056-1067
[20]Y.Zhou,X.Xie,C.Wang,Y.Gong,and W.Y.Ma.Hybrid Index Structures for Location-Based Web Search.CIKM,2005:155-162
[21]J.B.Rocha-Junior,A.Vlachou,C.Doulkeridis,and K.Norvag.Efficient Processing of Top-k Spatial Preference Queries.PVLDB, 2010:93-104
[22]D.Zhang,B.C.Ooi,A.K.H.Tung.Locating Mapped Resources in Web2.0.ICDE,2010:521~532
[23]G.R.Hjaltason,H.Samet.Distance Browsing in Spatial Databases.ACM Trans.Database Sys.,1999,24(2):265~318
[24]S.Alsubaiee,A.Behm,C.Li.Supporting Location-Based Approximate-Keyword Queries.ACM GIS,2010:61~70
[25]D.Wu,W.L.Yiu,G.Cong,and C.S.Jensen.Joint Top-k Spatial Keyword Query Processing.TKDE,2011:1~15
[26]B.Martins,M.Silva,L.Andrade.Indexing and Ranking in Geo-IR Systems.GIR,2005:31-34
[27]L.Qin,J.X.Yu,L.Chang.Ten Thousand SQLs:Parallel Keyword Queries Computing.In VLDB,volume 3,pages 58~69,2010
[28]Siqiang Luo,Yifeng Luo,Shuigeng Zhou,Gao Cong,Jihong Guan:Distributed Spatial Keyword Querying on Road Networks.EDBT 2014:235-246
[29]Siqiang Luo,Yifeng Luo,Shuigeng Zhou,Gao Cong,Jihong Guan:DISKs:A System for Distributed Spatial Group Keyword Search on !Road Networks.PVLDB 5(12):1966-1969(2012)
Spatial Database;Spatial Keyword Query;Indexing;Distributed Computing
Research on the Survey of Spatial Keyword Query
LI Wei-dan
(Department of Computer Science and Technology,Tongji University,Shanghai 201804)
With the emergence of positioning services,more and more applications associate the physical objects with spatial locations.This situation leads to the prevalence of spatial keyword queries in practice and research.Spatial keyword query processing involves techniques of both spatial query and keyword query processing,and the query results may be impacted by these two aspects.Surveys the state of the art techniques of spatial keyword query processing.Especially,focuses a comparative analysis on indexing mechanisms,query strategies,results ranking and evaluation.In addition,introduces a distributed spatial keyword query system.Highlights open research issues.
1007-1423(2015)12-0034-06
10.3969/j.issn.1007-1423.2015.12.008
李维丹(1991-),男,内蒙古自治区人,硕士研究生,研究方向为空间关键词查询
2015-03-27
2015-04-15
