基于灰色GM(1,n)模型的河北物流货运量预测
2015-09-06赵莉琴刘敬严
赵莉琴, 刘敬严
(石家庄铁道大学 经济管理学院,河北 石家庄 050043)
2009年以来,我国政府把物流产业作为十大重点产业之一,提出了一系列振兴规划,制定了区域物流协调和持续发展目标[1]。因此,基于区域经济发展的物流需求预测对区域物流规划设计、道路水路发展、配送节点设立、信息系统及网络配置等方面具有积极的现实意义。区域物流需求预测包括货运量、运输量、道路需求、物流企业及节点需求、车辆需求量等方面的预测[2],其中货运量指标具有综合性和辐射广泛性特点,可以作为区域物流需求预测的代表性指标。
目前预测研究中经常使用的方法主要集中在时间序列预测模型、回归预测模型和神经网络预测模型三类。时间序列模型在传统的指数平滑法和静态时间序列模型后,现在又根据非线性状态,提出混沌时序分析法,比如基于混沌预测的非线性自适应录滤波方法、遗传算法快速混沌预测法、小波网络预测模型等[3-7]。回归预测模型包括在传统的线性基础上发展起来的一元回归、多元回归、比例估算法和朗格系数法,到近期发展的非线性回归预测法,比如曲线直线化方法、非线性最小二乘法和近似非线性法等[8-10]。时间序列预测模型和回归预测模型一般都是基于数学理论和基本假设为前提进行数学建模,对于动态、非规律性、难以描述数据内在影响的事件很难演绎建立数学模型。神经网络法作为典型的非线性预测方法在近期应用比较广泛,但是神经网络预测模型采用误差导数梯度下降的方法进行迭代,难以避免出现局部误差较大的情况[11-12]。在近期研究中发现,将神经网络模型与其他方法的结合,比如回归神经网络、模糊算法、遗传算法等,可弥补局部极差问题的存在。
灰色GM(1,n)模型能够从非线性模型中找出规律,寻找数据的整体功能。灰色理论是建立在生产数据的建模上,而非原始数据模型,所以其预测结果精度相对比较高[13]。灰色 GM(1,n)模型可以依靠小样本进行原始数据重新生成数据计算,然后根据参数对非线性、复杂的数据进行预测。所以采用GM(1,n)模型能够适应区域货运量与影响因素复杂、非线性关系,能够依据比较少的数据进行更好的预测。
由于影响区域货运量因素比较多,如果直接把强相关和弱相关的全部影响因素数据输入GM(1,n)模型进行测算,不但导致输入工作量大,而且会造成模型结构复杂、运算量大、模拟时间长、精度不够等结果[14-16]。所以使用灰色关联分析法,对全部影响区域货运量因素进行筛选分析,对定量研究系统内多因素之间相互作用、相互影响进行发展态势的量化比较,有效减少GM(1,n)模型的变量数量。
一、基本原理
(一)灰色关联分析
灰色关联分析法是对一个系统发展变化态势的定量描述和比较的方法,通过确定参考数据列与若干个比较数据列的几何形状相似度来判断其联系是否紧密,反映了曲线之间的关联程度。与参考数列关联度越大的比较数列,其发展方向和速率与参考数列越接近,与参考数列的关系越紧密[17]。具体分析过程如下:
1.确定分析数列
确定反映系统行为特征的参考数列和影响系统行为的比较数列,参考数列为:
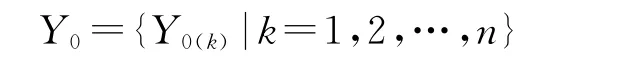
比较数列为:
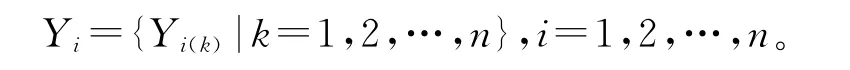
2.变量的无量纲化
由于系统中各因素数列的数据可能因纲量不同,不便于进行比较,或者不能得到正确结论,因此在进行灰色关联分析时先进行无量纲化。参考数列进行无量纲化后得到 X0={X0(k)=1,2,…,n};比较数列进行无量纲化得到Xi={Xi(k)|=1,2,…,n};i=1,2,…,n。
3.求灰色关联系数
计算参考数列X0与比较数列X1,X2,…,Xn的灰色关联系数。计算公式如下:
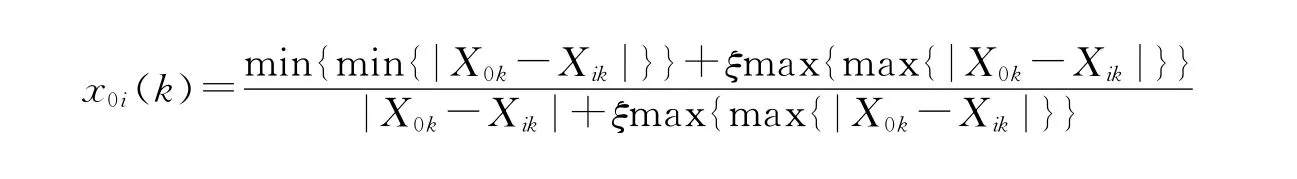
式中ξ∈[0,1]为分辨系数,一般取值为ξ=0.5。
4.求灰色关联度
计算参考数列Y0与比较数列Yi的灰色关联度。因为参考数列与比较数列在曲线各个点的关联程度值不是一个,而且过于分散,所以计算在曲线各个点的平均值,作为参考数列与比较数列的关联程度的表示,其计算公式如下:
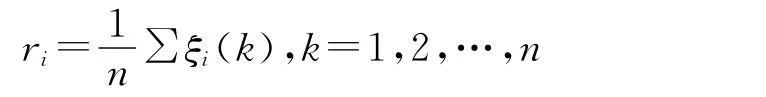
式中,ri代表参考数列Y0与比较数列Yi的灰色关联度。
5.排关联序
关联度排序是指各因素之间的关联度,主要使用关联度大小次序进行描述,而不仅仅是关联度的大小。将k个比较因素与参考因素的关联度按大小进行排序,便组成了关联序,反映了参考因素对各比较因素的“优劣”关系。
(二)灰色GM(1,n)模型测算分析
灰色GM(1,n)模型反映了n-1个变量对一个变量的一阶导数的影响,通过拟合效果的检验建立最优模型。
1.对原始数据做一次累加形成新生数列
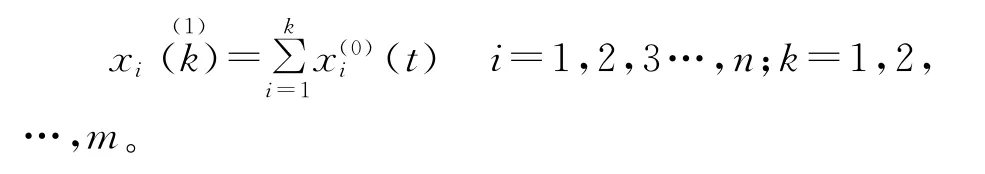
2.求参数向量
参数向量^α=[a,b1,b2,…,bn-1]T
根据yn=B^α=(BTB)-1BTyn,式中α为 GM(1,n)的发展系数;bi为xi的协调系数。
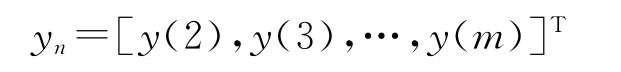
B值计算公式为:

3.建立时间响应函数

4.建立还原函数
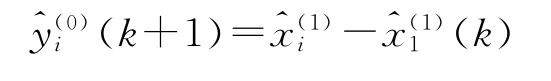
二、河北物流货运量影响因素灰色关联分析
区域物流货运量受多种因素影响,同时也带有明显的地域特征。相对于河北省来说,影响区域货运量的因素主要集中在6个方面[18],从国家统计局统计标准进行分类,可以分为国民经济、固定资产投资和房地产、对外经济贸易、能源、运输和邮电、社会消费。相对其他省份来说,河北省预测物流货运量必须考虑能源消费和社会消费两个指标。因为河北省能源结构相对来说集中化程度非常高,主要依托煤炭作为能源来源,但是河北省不是煤炭储存大省,需要从山西、内蒙古进行调运,无形中增加了货运量的值。同时,河北省与北京、天津的地缘关系,成为北方小商品集散地,社会消费品的批发功能对河北省货运量也有非常大的影响。
结合河北省特点,选取6个方面作为比较因素。其中国民经济指标中选取了GDP(X1)、第一产业增加值(X2)、第二产业增加值(X3)、第三产业增加值(X4)四个指标作为比较因素;在固定资产投资和房地产指标中选取了全社会固定资产投资额(X5)作为比较因素;在对外经济贸易指标中选取了经营单位所在地进出口额(X6)作为比较因素;在能源指标中选取了煤炭消耗量(X7)、原油消耗量(X8)作为比较因素;在社会消费品指标中采用批发业主营收入(X9)、零售业主营收入(X10)、社会零售品消费总额(X11)作为比较因素;在运输和邮电指标中选取交通运输、仓储和邮电业增加值(X12)、铁路营运里程(X13)、公路里程(X14)、高速等级里程(X15)、公路营运车辆拥有量(X16)、民用机动船净载重量(X17)、快递量(X18)七个指标作为比较因素。
在灰色关联分析中,采用河北省1993—2012年统计数据进行分析。因为影响河北省货运量各因素指标统计标准不一,数量级别差异很大,所以首先对20年数据Y0与Y1,Y2,Y3,…,Yn进行无纲量化处理,把预处理后的的数据转变成级别差异不大的无纲量化数据X0、X1,X1,…,Xn备用。然后根据灰色关联基本原理中的第三、第四步骤计算关联系数和关联度,然后根据关联度大小和关联程度进行关联序排序。
在计算过程中,设定分辨系数=0.5,然后在关联系数和关联度的基础上导出灰色关联序。最后多次改变分辨系数值,分别设为0.6、0.7、0.8、0.9,其计算结果表明,Y0与Y1,Y2,…,Yn的关联系数和关联度数值有所差异,而灰色关联序的排序没有变化。下面以ξ=0.9的值,计算Y0与Y1,Y2,…,Yn的关联度与关联序的数值,见表1。
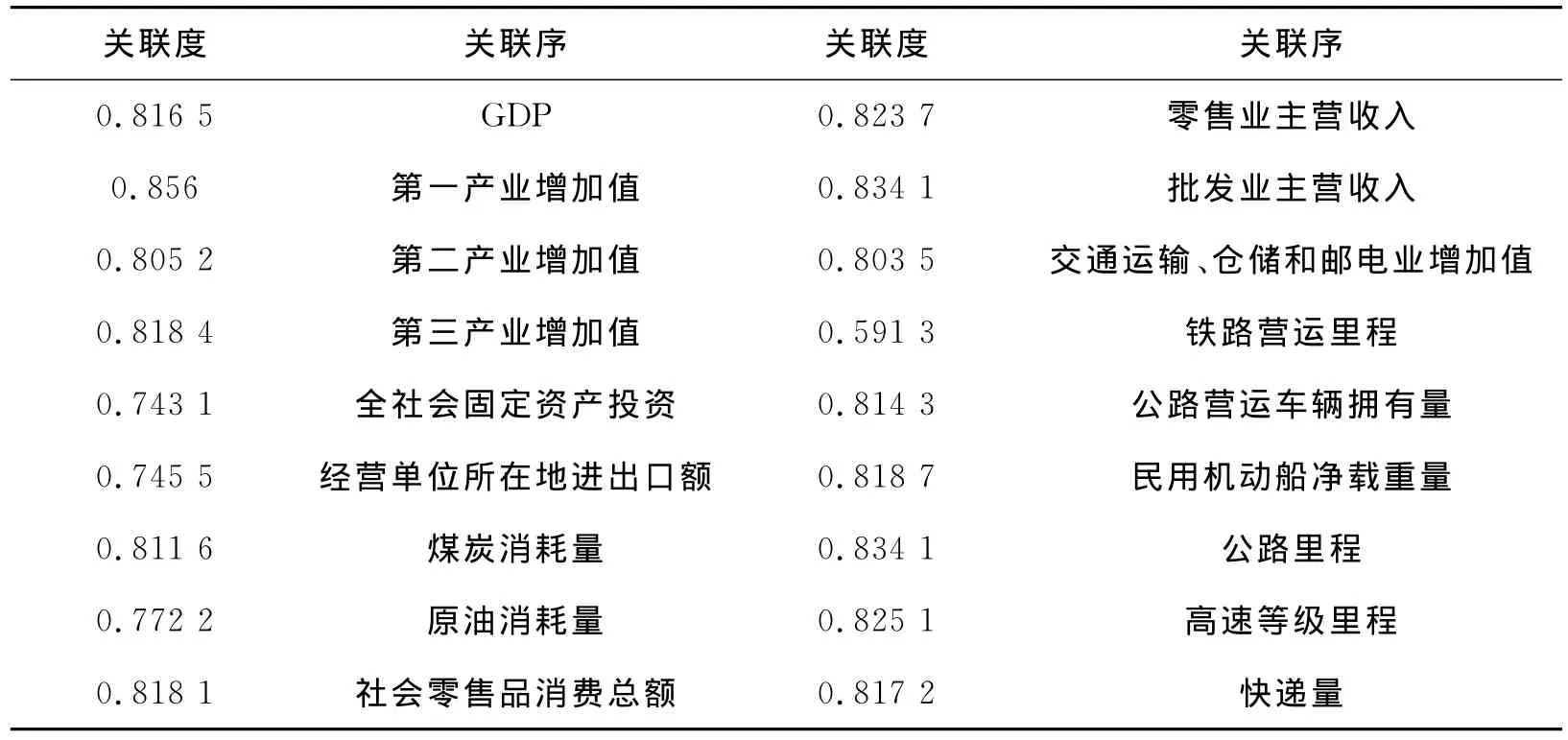
表1 影响河北省货运量各因素的灰色关联分析结果
根据选取影响主因素≥65%的原则,计划从18项指标中选取12个作为影响河北省物流货运量的主要指标。从表2子类划分结果中可以看出,与货运量指标灰色关联度指标从大到小排序中可知,12个主要影响指标包括GDP、第一产业增加值、第三产业增加值、煤炭消耗量、批发业主营收入、零售业主营收入、社会零售品消费总额、公路里程、高速等级公路里程、民用机动船净载重量、公路营运车辆拥有量、快递量。说明以上12个指标与河北省货运量指标曲线变化趋势明显吻合,灰色关联度比较紧密。下面把12指标分别进行子类归类。

表2 影响河北省货运量各因素子类划分结果
从表1和表2中可以看出,在国民经济子类中,河北省第一产业和第三产业对货运量影响都比较大,原因是河北省第一产业产值在国民经济中占有近30%份额,货运量与第一产业关系也比较大,同时河北省第三产业发展较快,反观第二产业优势并不明显,所以在国民经济子类中,选取河北省GDP、第一产业产值、第三产业产值作为影响因素。固定资产投资和房地产、对外经济贸易各子类指标对河北省货运量影响不大,直接扣除。在能源子类中,煤炭消耗量指标其关联度较紧密,选取煤炭消耗量作为影响因素。在运输和邮电子类中,公路里程、高速等级公路里程、民用机动船净载重量、公路营运车辆拥有量、快递量的关联度较大,选取该五项指标为影响因素。
三、河北省货运量灰色预测模型的建立与预测
(一)统计数据
根据河北省1993—2012年经济统计数据,分别得出预测指标货运量x1,影响因素GDP(亿元)x2、第一产业增加值(亿元)x3、第三产业增加值(亿元)x4、煤炭消耗量(万吨)x5、批发业主营收入(亿元)x6、零售业主营业务收入(亿元)x7、社会零售品消费总额(亿元)x8、公路里程(万公里)x9、高速等级里程(万公里)x10、民用驳船净载重量(万吨)x11、公路营运载货汽车拥有量(万辆)x12、快递量(件)x13。其中快递量数据(1993—2000年),是根据2000—2012年数据的线性规律进行推算得出。
(二)计算过程
根据河北省1993—2012年货运量及各经济指标统计数据进行各数列一次累加,形成货运量的相关因素数据列和另外13个影响因素的系统特征数据列。在此基础上求得参数:

根据参数计算结果构建yn和B矩阵,构建GM(1,n)河北省货运量预测模型。其中系统发展系数a和驱动项b分别为:a=1.777 7。b=6.564 9;-0.037 6;-0.048 5;0.822 9;7.998 9;-1.8175;-139.269 3;14 484.161 2;0.015 3;53.974 7;-0.002 6;-0.001 1。
表3为河北省货运量GM(1,12)预测结果,通过建模分析可知,其准确率为97%以上。
(三)结果分析
通过建模分析,河北省1993—2012年货运货量预测值准确率非常高,平均相对误差只有2.924%,相对误差除了2012年、2011年差距比较大以外,其他10个年份都在3%以下,还有7个年份在1%以下。从历史实际数据来看,预测值的准确度比较高,预测结果有较强的可信度。
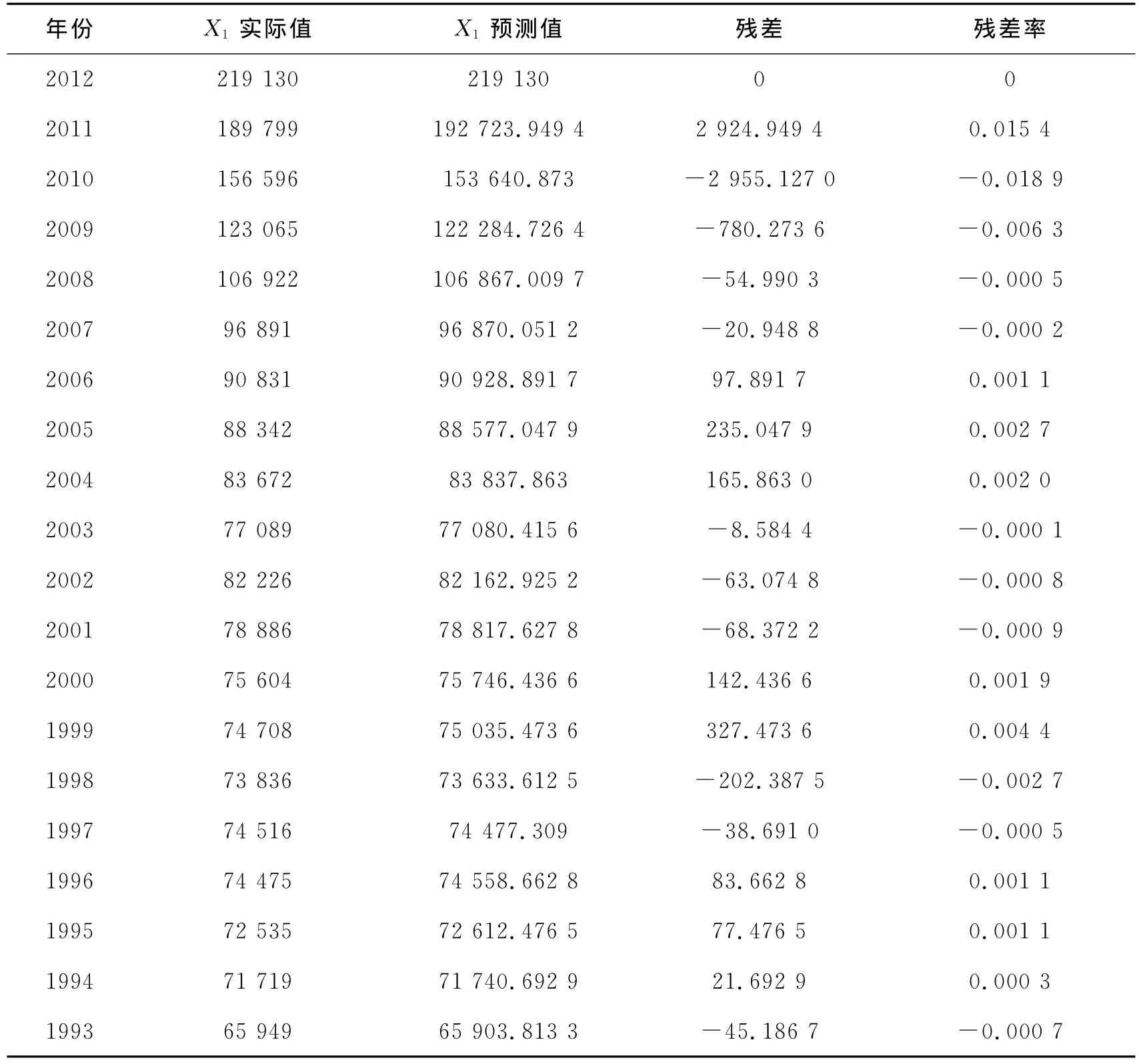
表3 河北省货运量GM(1,12)预测结果
四、结论
使用灰色关联分析,确定影响河北省货运量的主要因素,然后根据灰色GM(1,n)预测模型构建新生数据列矩阵,对河北省货运量进行预测。实例表明,基于灰色关联分析确定的影响变量合理可行,减少灰色GM(1,n)预测模型输入变量数目,可以简化预测模型结构,相对提高预测准确度,同时可以简化日常工作量,有利于方法的推广。
[1]赵莉琴,郭跃显.城市物流竞争力评价方法研究[J].地域研究与开发,2011(2):78-79.
[2]赵莉琴,刘敬严,訾红兵.京津冀区域物流与城市群物流功能建设分析[J].石家庄铁道大学学报:社会科学版,2014,8(3):13-15.
[3]Aloísio Carlos de pina,Bruno da Fonseca Monteiro.ANN and Wavelet network meta-models for the coupled analysis of floating production systems[J].Applied Ocean Research,2014,48(1):21-23.
[4]Takashi Kuremoto,Shinsuke Kimura.Time series forecasing using a deep belief network with restricted Boltzamn Machines[J].Neurocomputing,2014,137(11):47-54.
[5]Kulikova M V.Maximum likelihood estimation via the extend covariance and combined square-root filters[J].Mathematics and computers in Simulation,2009,79(2):1641-1657.
[6]王大鹏.灰色预测模型及中长期电力负荷预测应用[D].武汉:华中科技大学,2013.
[7]Vahid Faghihi,Kenneth F,Reinschmidt,Julian H kang.Construction scheduling using genetic Algorithm based on Building information mode[J].Expert Systems with Applications,2014,41(12):7565-7578.
[8]刘昆,刘向东.我国铁路集装箱专用平车需求量预测[J].铁道车辆,2014(1):28-31.
[9]邵峰晶,于忠清.数据挖掘原理与算法[M].北京:中国水利水电出版社,2003.
[10]段晓晨,郭兰英,张新宁.新建高铁工程非线性造价估算方法研究[J].铁道学报,2013(10):115-116.
[11]刘志杰,季令,叶玉玲.基于径向基神经网络的铁路货运量预测[J].铁道学报,2006,28(5):1-5.
[12]苏博,刘鲁,杨方廷.基于灰色关联分析的神经网络模型[J].系统工程理论与实践,2008,28(9):98-104.
[13]周伟,方志耕.非线性优化GM(1,N)模型及其应用研究[J].系统工程与电子技术,2010(2):34-39.
[14]张永军,石辉,梁锦照.基于 AHP灰关联及GM(1,N)建模的静态网损因素分析[J].华南理工大学学报,2011(3):63-65.
[15]樊爱宛,潘中强,王巍,等.灰色 GM(1,N)模型在河南省煤炭需求预测中的应用[J].煤炭技术,2011(10):7-10.
[16]鲁亚运,原峰,谭枝登.时滞 GM(1,N)模型及其应用[J].统计与决策,2014(14):72-73.
[17]耿立艳,张天伟,赵鹏.基于灰色关联分析的LS-SVM铁路货运量预测[J].铁道学报,2012(3):2-3.
[18]刘敬严,陈国勋.京津冀交通运输与区域经济复合系统协同发展分析[J].石家庄铁道大学学报:社会科学版,2014,8(4):23-27.
