基于MapReduce和分布式缓存的KNN分类算法研究
2015-08-18涂敬伟皮建勇贵州大学计算机科学与信息学院贵州贵阳550025贵州大学云计算与物联网研究中心贵州贵阳550025
涂敬伟,皮建勇(1.贵州大学 计算机科学与信息学院,贵州 贵阳 550025;2.贵州大学 云计算与物联网研究中心,贵州 贵阳 550025)
基于MapReduce和分布式缓存的KNN分类算法研究
涂敬伟1,2,皮建勇1,2
(1.贵州大学 计算机科学与信息学院,贵州 贵阳 550025;2.贵州大学云计算与物联网研究中心,贵州贵阳550025)
随着大数据时代的到来,K最近邻(KNN)算法较高的计算复杂度的弊端日益凸显。在深入研究了KNN算法的基础上,结合MapReduce编程模型,利用其开源实现Hadoop,提出了一种基于MapReduce和分布式缓存机制的KNN并行化方案。该方案只需要通过Mapper阶段就能完成分类任务,减少了TaskTracker与JobTracker之间的通信开销,同时也避免了Mapper的中间结果在集群任务节点之间的通信开销。通过在Hadoop集群上实验,验证了所提出的并行化KNN方案有着优良的加速比和扩展性。
KNN分类算法;并行化;MapReduce编程模型;Hadoop;分布式缓存
0 引言
在数据挖掘中,分类算法是基础和核心的研究内容,如何实现对事物的自动归档和分类是其主要的研究内容。经典的分类算法主要有决策树、贝叶斯分类器、最近邻、SVM、神经网络等。这些算法在电子商务、通信、互联网、医疗以及科学研究等领域起到了非常重要的决策支撑作用。其中,K最近邻(KNN)分类法是一种简洁、易实现、分类准确率较高的算法,在文本分类、图像及模式识别等方面有着广泛的应用。但是,随着大数据时代对分类任务要求的提高,传统的KNN分类算法已经不能满足人们的需求。
针对KNN算法的时间复杂度高、运算速度慢等不足,众多学者从不同的方向对算法进行了改进研究。比如参考文献[1]中所提到KD树,建立了一种对K维空间中的实例进行存储以便对其进行快速检索的数据结构,减少了计算距离的次数;参考文献[2]中,通过建立低维的特征向量空间来降低计算开销;参考文献[3]则是通过减少训练样本来降低计算开销。这些改进的算法或以牺牲算法的分类准确率为代价,或在降低样本相似度计算代价的同时,引入了新的计算代价,同时也降低了模型易读性。然而,Google分布式计算模型 MapReduce的提出,为KNN处理大数据集提供了一种新的可能。A-pache基金会的开源项目 Hadoop的发布,使得这种可能成为了现实。
本文简单介绍了MapReduce编程模型,对传统的KNN算法进行了简单扼要的介绍和分析;提出并实现了基于MapReduce模型的并行化方案。通过实验验证了并行化KNN方法的高效性,并分析了其不足与以后的研究方向。
1 MapReduce编程模型
简单地说,MapReduce[4]编程模型采用了“分而治之”的思想,将一个大而复杂的作业分割成众多小而简单的独立任务,然后将这些任务分发给集群中各节点独立执行。
在 Map和 Reduce中,数据通常以<key,value>键值对的形式存在。
MapReduce编程模型的执行过程如图1所示。具体流程大致可分为以下几个部分:
(1)用户提交任务后,MapReduce首先将 HDFS上的源数据块逻辑上划分为若干片。随后,将切片信息传送给 JobTacker,并通过 Fork创建主控进程(master)和工作进程(worker)。
(2)由主控进程负责任务调度,根据数据本地化策略,为空闲的worker分配任务。
(3)在 Mapper阶段,被分配到 Map任务的 worker读取输入数据的对应分片。Mapper与 Split是一一对应的。Mapper任务首先通过相关的函数,以行为单位,将 Split转化为 Map能够处理的<key,value>键值对的形式传递给Map,Map产生的中间键值对缓存在内存之中。
(4)当缓存溢出时,缓存的中间键值对根据用户定义的 Reducer的个数 R,分成 R个区,并写入本地磁盘。分区一一对应于 Reducer。Reducer会通过 master获得相对应的分区在本地磁盘上的位置信息。
(5)Reducer阶段,Reducer首先读取与之相对应的分区数据,随后根据键值对<key,value>的 key值对其进行排序,将具有相同 key值的排在一起。
(6)Reduce函数遍历排序后的中间键值对。对于每个唯一的键,根据用户重写的 Reduce,处理与之相关联的 value值。Reduce的输出结果以键值对的形式写入到该分区的输出文件中。
(7)当所有的Map和 Reduce任务都完成以后,master会唤醒用户程序,用户程序对MapReduce平台的调用由此返回。

图1 MapReduce编程模型
由此可见,MapReduce为用户提供了一个极其简单的分布式编程模型。用户只需关心与任务相关的Map和Reduce即可,其他的对用户而言都是透明的。
2 KNN算法描述
K近邻法[5]是在1968年由COVER T和HART P提出的,它没有显式的学习过程。分类时,对新的实例,根据其K个最近邻的训练实例的类别,通过多数表决等方式进行预测。所以,实际上K近邻法是利用训练集对特征向量空间进行划分,并作为其分类的“模型”[6]。具体算法描述如下:
输入数据:训练数据集 T={(x1,y1),(x2,y2),…,(xN,yN)}
其中,xi∈X⊆Rn为实例的特征向量,yi∈{c1,c2,…cK}为实例的类别,i=1,2,…N;实例特征向量x。
输出:实例x所属的类y
(1)计算实例x与每个训练实例的距离;
(2)令 K是最近邻数目,根据计算的距离度量,在训练集中找出与x最近邻的 K个点的集合Nk(x);
(3)在Nk(x)中根据分类决策规则(如多数表决)决定x的类别y:

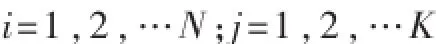
其中,I为指示函数,即当yi=cj时I为1,否则I为0。
从算法描述可以看到,算法的原理和实现非常简单。但是,由于每判定一个输入实例都要遍历一次所有的训练样本,并计算该输入实例到所有训练样本的距离,因此,对于具有海量和高维的训练数据集以及分类任务时,K近邻法的计算开销会以惊人的速度增加。总的分类任务所需时间将远远超出人们的预期,使得K近邻法失去了用武之地。
3 并行化KNN的分析与实现
3.1并行化KNN分析
单节点情况下,针对一个分类任务,训练样本和测试样本的大小一般情况下是固定的。所有的工作量由一台PC独立承担。在集群环境下,借鉴 MapReduce“分而治之”的思想,将海量的数据集进行分割,上传至Hadoop集群的分布式文件系统HDFS。然后将大的样本相似性计算和分类决策规则分割到存有训练样本的节点上进行并行处理。这是并行化KNN算法的基本思想。
一般情况下,MapReduce编程模型处理的是单一数据源的任务,比如WordCount任务。但是,KNN分类是有导师的学习,需要两个数据源:训练数据集和测试数据集,且要求在 Map任务开始前,能够读取到这两个数据集。为了解决双数据源的问题,本文采用了 Hadoop提供的分布式文件缓存拷贝机制[7],它能够在任务运行过程中及时地将文件复制到任务节点以供使用。当集群PC的内存有限、文件无法整个放入到内存中时,使用分布式缓存机制进行复试是最佳的选择。
将测试文件散布到集群的各个节点中,将训练数据作为边数据分发给存有测试集的节点。在 Mapper阶段,虽然每个测试样例仍要遍历整个训练数据集,但是,每个 Mapper只需要完成 1/n个测试集与整个训练集的相似性计算,如图2(b)所示。所以在 Mapper阶段,测试样本即可获得与训练数据集全局的相似性。从而在本地就能够得到测试样例的K个最近邻居,并根据投票选出测试样例的类别。不需要经过 Reducer阶段、集群间的数据传输、与 master进程之间的信息交互,进而节约任务运行的时间,提高了算法的效率。
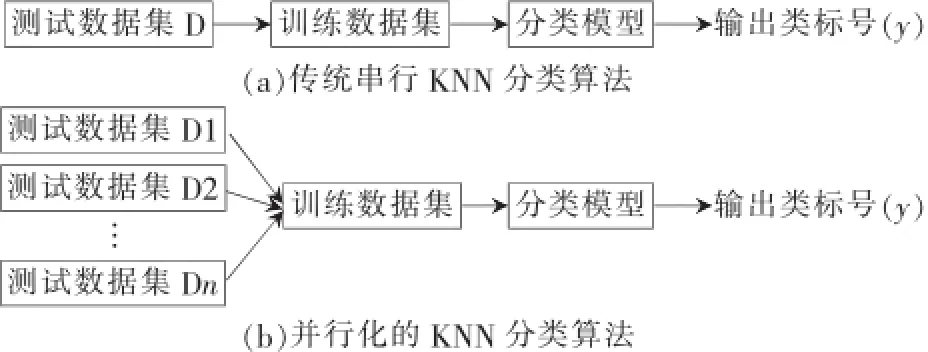
图2 串行和并行KNN流程对比图
3.2并行化KNN的实现
根据上一小节的分析,只通过 Mapper就能够完成分类任务。首先,Mapper读取到的分片数据由 InputFormat对象,生成<key,value>键值对。其中,key为测试样本在分片中的偏移量,value为每个样本的内容,数据类型为Text。同时,在运行Map之前,将训练数据上传至 HDFS或本地文件系统,借助分布式缓存机制,将训练集分发给每一个 slave节点,然后 Mapper通过一个静态的方法UseDistributedCache()实现对缓存数据的调用。之后,通过Map计算每一个测试样本与每一个训练样本的距离,获得每一个训练样本的类别标志;找出测试实例的K个最近邻,根据投票得到测试实例的类别;最后将结果以<key,value>的形式输出到指定的目录。具体伪代码如下:
输入:<key,value>
输出:<key,String>
ClassMapper{
使用 UseDistributedCache(),获得测试数据集Tests;
创建KNNnode对象 node,存储训练样本与测试样本的距离和训练样本的类别;
Map(key,value){
训练样本向量化,得到向量化的测试样本 test;
遍历本节点训练样本集 Trains,得到测试样本与每一个训练样本的距离 distanc以及相应训练样例的类标示 catalog,并赋值给node对象;
通过 PriorityQueue得到与测试样距离最近的 K个 node对象的队列 pq;
根据投票获得测试样本的类c;
输出结果output.collct(test,c);
}
}
4 实验结果与分析
4.1实验环境
并行化KNN实验是在Hadoop平台下完成的。硬件设备为6台X86架构的PC,主设备节点采用 Intel志强四核处理器,内存为 4 GB;从设备节点采用 AMD四核处理器,主频为2.7 GHz,内存为4 GB。
4.2实验数据集
实验采用标准数据集CoverType,它通过地质变量来预测森林植被覆盖类型,是54维的7分类数据集。共有58万个样本,选取其中的30万个为训练样本,其余的28万个为测试实例,数据集大小为 70 MB。
4.3结果分析
实验首先对传统的KNN算法和本文提出的并行化KNN的运行效率进行了验证。另外,为了验证采用分布式缓存机制带来的性能提升,还实现了另一种基于MapReduce的并行化 KNN方案[8],采用内存的机制传递边数据。这种方案由于受到单节点PC内存的限制,不能通过内存来传递训练数据,只能将测试数据作为边数据,由内存传递给 woker。因此,这种方法不仅需要经过Mapper阶段,还需要经过 Reducer阶段。理论上,这种方案的效率要低于采用分布式缓存机制的并行化KNN。
在分布式环境下,由于数据分布的不确定性,实验结果具有一定的颠簸,以下实验数据均为在多次实验后所取得的合理值。
图3显示了三种算法在处理相同任务时所需要的时间。从图中可以看到,在单台和双台PC的情况下,并行化 KNN方案一(采用分布式缓存机制)和方案二(采用内存机制)并没有表现出其高效性,反而因为需要启动JVM以及信息交互的原因,运行时间比传统KNN算法的时间更长。当集群的节点数大于3台时,随着节点数量的增加,并行化KNN的运行时间开始大幅度地减少,体现出并行化的KNN算法的高效性。
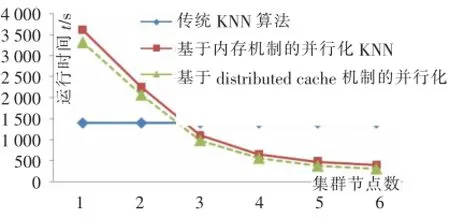
图3 运行时间对比图
图4为方案一和方案二的加速比对比图,从图中可以看到,随着节点数量的增加,方案二的加速比也迅速地增加,明显优于方案一。
通过实验得出,基于分布式缓存机制的并行化KNN算法在运行效率和扩展性上均要优于基于内存的并行化KNN。
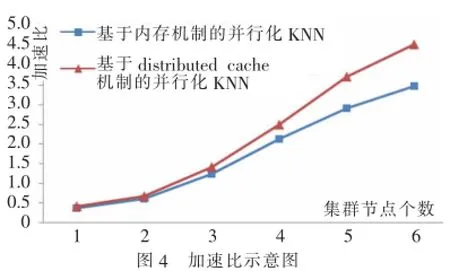
图4 加速比示意图
5 结论
本文根据传统KNN算法的特点,提出了一种基于Mapreduce和分布式缓存机制的并行化 KNN算法的实现。减少了任务执行过程中集群之间的信息交互以及中间数据的传输时延,从而使得本文提出并实现的并行化KNN算法在效率上有了进一步的提高。但是本文提出的并行化方案只是对传统KNN算法最基本的并行化的实现,效率提升受到KNN算法本身特性的约束。借鉴前人的研究成果,对算法本身的K近邻查找策略进行研究,在此基础上实现并行化,取得更理想的效果,将是接下来研究的主要工作和方向。
[1]SAMET H.The design and analysis of spatial data structures[M].MA:Addison-Wesley,1990.
[2]FRANKLIN M,HALEVY A,MAIER D.A first tutorial on dataspaces[J].Proceedings of the VLDB Endowment,2008,1(2):1516-1517.
[3]刘莉,郭艳艳,吴扬扬.一种基于基本信息单元的索引[J].计算机工程与科学,2011(9):117-122.
[4]DEANJ,GHENAWATS.MapReduce:simplifieddata processing on large clusters[J].Communications of the ADM-50th Anniversary Issue:1958-2008,2008,51(1):107-113.
[5]COVER T,HART P.Nearest neighbor pattern classification[J]. IEEE Transactions on Information Theory,1967,13(1):21-27.
[6]李航.统计学习方法[M].北京:清华大学出版社,2012.
[7]TOM W.Hadoop:the definitive guide(second editon)[M]. O′Reilly Media,Inc.,2011.
[8]闫永刚,马廷淮,王建.KNN分类算法的 MapReduce并行化实现[J].南京航空航天大学学报,2013,45(4):550-555.
Parallelized K-nearest neighbor algorithm based on MapReduce and distributed cache
Tu Jingwei1,2,Pi Jianyong1,2
(1.College of Computer Science and Information,Guizhou University,Guiyang 550025,China;(2.Research Centre of Cloud Computing and Internet of Things,Guizhou University,Guiyang 550025,China)
With the advent of the era of big data,K-nearest neighbor algorithm′s shortcoming which high computational complexity is become more and more seriously.Through the use of distributed cache mechanism and Hadoop programming ideas provided,thispaperproposedKNNparallelizationschemebasedontheMapReduce.Theprogramonlyneedstocomplete classification tasks by Mapper stage.It reduced the communication overhead between the TaskTracker and JobTracker;on the other hand,it avoided the intermediate results Mapper overhead communication and information transfer between nodes in the cluster task. Through experiments on a Hadoop cluster,the proposed parallel KNN has a better speedup and scalability.
K-nearest neighbor algorithm;parallelization;MapReduce;hadoop;distributed cache
TP399
A
1674-7720(2015)02-0018-04
(2014-09-30)
涂敬伟(1987-),男,硕士,主要研究方向:海量数据挖掘。
皮建勇(1973-),男,博士,副教授,主要研究方向:数据挖掘,人工智能,分布式并行计算。
