一种存储优化的多模式匹配算法*
2015-08-18段惠超韩建民浙江师范大学数理与信息工程学院浙江金华321004
段惠超,韩建民,邱 晟(浙江师范大学 数理与信息工程学院,浙江 金华 321004)
一种存储优化的多模式匹配算法*
段惠超,韩建民,邱晟
(浙江师范大学数理与信息工程学院,浙江金华 321004)
AC(Aho-Corasick)自动机是经典的多模式匹配算法,但在模式串字符集较大的情况下,AC自动机的存储开销较大。为降低存储开销提出了存储优化的多模式匹配算法SMMA,该算法在Trie树建立阶段利用正向表来存储每个状态的后续状态指针以及失配指针,而无需存储字符集所有字符的后继指针,从而压缩了每个状态的储存空间。实验表明,所提出的算法与AC自动机算法在时间效率上相近,但极大地降低了存储开销。
模式匹配;AC自动机;Trie树
0 引言
模式匹配算法一直是信息领域的研究热点,广泛应用于入侵检测、生物信息学、模式识别等领域[1]。模式匹配算法可以分为单模式匹配算法[2-3]和多模式匹配算法[4-8]。Aho-Corasick算法[4](以下简称 AC算法)是经典的多模式匹配算法,它把所有模式串构建成 Trie树,并进一步预处理得到有限状态自动机,对主串的一次扫描即可完成所有模式串的匹配。Commentz-Walter算法(CW算法)[5]建立反向自动机,在模式匹配阶段利用坏字规则和好后缀规则,在失配时滑动最大的距离,实现了模式串的跳跃匹配,减少了时间开销。Wu-Manber(WM)算法[6]对多模式串进行预处理,建立三张映射表进行部分匹配,最后进行全模式匹配,提高了效率。参考文献[7]提出了改进的多模式匹配算法,在DFSA算法的基础上,结合QS算法[8]思想,利用匹配过程中匹配失败信息,跳过尽可能多的字符。
AC算法的一个不足是需要为自动机每个状态分配空间,在模式串字符集比较大的情况下,算法空间复杂度比较大。极端情况下,需要使用外存来保存匹配过程的中间信息,严重影响算法效率。为此,参考文献[9]提出基于异构隐式存储的多模式匹配算法,从横向扇出压缩与纵向路径压缩入手,减少了空间开销,但算法的空间压缩率不高,且算法效率有所降低。参考文献[10]通过选择性分群减小匹配算法的空间复杂度,有效解决导致DFA状态膨胀的问题。参考文献[11]提出了对DFA进行高效存储的方法,从DFA状态数目和状态转移数目两方面进行压缩。在复合的FSM中,利用新的正则特征,进一步存储压缩,但是算法实现复杂、压缩性能不稳定、时间效率不高,实际工程应用不理想。为了减少自动机各结点的存储空间,TUCK N等人[12]在每个结点中增加一个位图数据,以记录当前结点所有的下一层结点的状态,压缩了存储空间。AC-bitmap[13]则将自动机的所有结点按模式树结构的层数进行划分,使得两种存储方式共存,以压缩算法的存储空间。但是,基于位图压缩自动机算法要求采用连续的地址空间存储,以加快转移时的查找速度,算法实现比较复杂,并且算法要求为每个结点存储一个位图信息,随着字母表的不断增大,其存储空间将迅速增大。
为更好地优化多模式匹配算法的空间复杂度,本文提出了基于存储优化的多模式匹配算法 (Storage-optimized Multi-pattern Matching Algorithm,SMMA)。该算法在建立 Trie树时,动态建立自动机上每个状态结点的字符集,只保留 Trie树上的有效路径信息,以保证用最小的空间代价存储模式串的所有信息,避免了无效字符路径的创建,压缩了储存空间。在模式匹配阶段,通过在自动机上的状态转移完成匹配。在保持算法时间复杂度不变的情况下,显著降低了算法的空间开销。
1 相关概念
定义1设p为Trie树的一个结点,则Trie树中从根结点到结点p的简单路径上所有字符组成的字符序列称为结点 p的路径,记为 path(p)。构成 path(p)中字符的个数称为结点 p的路径长度,记为 Len(p)。
定义2设p为Trie树的一个结点,若结点p的路径path(p)是一个模式串,则称结点p为匹配点,否则称为非匹配点。
定义 3自动机 M是一个五元组:M=(Q,∑,g,q0,F)。其中:Q是有穷状态集;∑是字母表;g是转移函数,转向下一个状态;q0是初始状态;F是自动机M上的终止状态集。
定义4设pa、p为自动机上的状态结点,c为字符集中的一个字符,若∃p,pa,c,path(p)=c+path(pa),p∈Q,pa∈Q,c∈(sigma),则称pa为p的后缀结点,记为S(p)。
定义5设p为Trie树的一个结点,当且仅当结点p或其后缀结点为匹配点,结点p具有匹配性。
定义6设p为自动机上的一个状态结点,则称Len (S(p))为结点p的匹配长度。
2 SMMA模式匹配算法
2.1SMMA算法的基本思想
SMMA算法包括三个阶段:建立 Trie树阶段、建立自动机阶段和模式匹配阶段。SMMA算法在建立 Trie树时,并不像传统的AC自动机那样为每一个结点开辟字符集大小的后继指针空间,而是根据具体的模式串信息动态地扩增Trie树结点的后继指针空间,因此只保留Trie树上的有效路径信息,避免了无效字符路径的创建,压缩了储存空间。在实现时,SMMA用正向表来存储Trie树。
建立自动机和模式匹配阶段都有查询当前结点cur的某个后继ch的操作goto(cur,ch)。若当前结点的后继结点不存在,则继续查询goto(fail[cur],ch)。为了快速求得所需的后继结点,本文用Next(cur,ch)函数获得后继结点编号,Next()函数的实现在2.3节介绍。
2.2正向表
正向表是一种边表,空间代价与邻接表相当,由于正向表没有使用指针而减少了一部分结构性开销,在存储树和稀疏图时具有巨大优势。将正向表应用于AC自动机多模式匹配算法,可以压缩所需的存储空间,减少算法空间开销。
2.3结点后继获得函数Next()
算法1结点后继获得函数Next(x,c)
输入:当前结点编号x,转移字符c
输出:当前结点x以字符c为转移条件的后继结点编号
①初始化边指针i←head[x];
②若边指针i为空,则转到⑤;
③若edge[i].ch==c,则返回 edge[i].to结点的编号;
④边指针i指向下一条边:i←edge[i].next,并转到②;
⑤若结点x为根结点,则返回0(根结点编号);
⑥递归调用结点后继获得函数,返回 Next(tree[x]. fail,c)。
2.4建立Trie树阶段
算法2模式串插入算法
输入:待插入字符串 arr[],待插入字符串的标号 index
输出:将字符串arr[]插入Trie树
①初始化字符指针 i←0,设置当前结点指针cur←0 (Trie树根结点),计算字符串长度len←strlen(arr);
③初始化边指针j←head[cur];
④若边指针j为空,则转到⑦;
⑤若edge[j].ch==arr[i],则转到⑦;
⑥边指针 j指向下一条边:j←edge[j].next,并转到④;
⑦若边指针j非空,则转到⑨;
⑧清空结点编号为nodeNo的结点,增加一条以cur为源点,以 nodeNo为终点,边上的字符为 arr[i]的有向边,并依次设置cur←nodeNo,nodeNo←nodeNo+1,转到⑩;
⑨将edge[j].to结点设置为当前结点:cur←edge[j].to;
2.5建立自动机阶段
建立自动机是实现SMMA算法的关键。建立自动机时,需要对 Trie树进行广度优先遍历(Breadth First Search,BFS),预处理 Trie树上每个结点的后缀结点、匹配性等信息,以便在模式匹配阶段快速转移状态,在失配时,能根据建立自动机阶段预处理出的信息快速确定所需要的后继状态。利用Next()函数快速返回其后缀结点的编号。
算法3自动机建立算法
输入:Trie树Tree[]
输出:建立自动机
①初始化队列Q的队头指针l和队尾指针h:l←0,h←0,并设置边指针 i←head[0];
②若边指针i为空,则转到⑤;
③将edge[i].to结点放入队尾:Q[h]←edge[i].to,h←h+1,并设置 edge[i].to结点的后缀结点为自动机的起始结点:tree[edge[i].to].fail←0;
④边指针i指向下一条边:i←edge[i].next,并转到②;
⑤若 l≥h,则转到⑩;
⑥设置当前结点指针 cur:cur←Q[l],l←l+1,并设置边指针i←head[cur];
⑦若边指针为空,则转到⑤;
⑧利用结点后继获得函数计算edge[i].to结点的后缀结点:tree[edge[i].to].fail←child(tree[cur].fail,edge[i]. ch),更新 edge[i].to结点的信息并将该结点放入队尾:tree[edge[i].to].isDanger←tree[edge[i].to].isDanger|tree[tree [edge[i].to].fail].isDanger,Q[h]←edge[i].to,h←h+1;
⑨边指针 i指向下一条边:i←edge[i].next,并转到⑦;
⑩自动机建立完成,返回。
2.6模式匹配阶段
从自动机的初始状态结点开始,以主串中各字符为转移条件,用Next()函数返回当前结点的后继结点,再将当前结点指针cur转移到该后继结点上。若该结点未被访问并且具有匹配性,则设置临时结点指针p,并赋初值为cur,同时标记该结点为已访问的结点,根据具体需要获取数据信息,再将结点指针p转移到结点p的后缀结点上。
3 算法的时空复杂度
设自动机的状态结点个数为N,字符集规模为∑,文本主串长度为L,模式串集合大小为P,模式串集合的总规模为其中,l(i)为第i个模式串的长度。
3.1空间复杂度分析
在建立自动机阶段,AC算法需要对每个状态结点建立字符集大小的空间,空间复杂度为O(N*∑)。SMMA算法对于自动机的每个状态结点只保留必要的结点信息,其所占用的存储空间大小与自动机的结点个数呈线性相关,因此SMMA算法存储自动机的空间复杂度为O (N)。AC算法和SMMA算法都需要存储待匹配的文本主串和各模式串的信息,存储待匹配的文本主串的空间复杂度为 O(L),存储模式串集合具体信息的空间复杂度为
3.2时间复杂度分析
在建立 Trie树阶段,在插入模式串的每个字符时都需要遍历当前结点的所有后继结点,该阶段最差时间复杂度为
在建立自动机阶段,SMMA算法需要通过BFS序遍历所有结点,预处理出每个状态结点的后缀结点、匹配性等重要信息,对于 Trie树上的每一条从根到叶的路径上的结点来说,它们的后缀结点离根的距离一般是逐层增长的,若不是,则进行多次回溯,而回溯的总次数不会大于路径上的结点个数,其平均时间复杂度为O(l(i)*∑),所以建立自动机阶段的最差时间复杂度为O(N*∑)。
在主串匹配阶段,SMMA算法转移所需的时间复杂度为O(∑)。由于可能出现主串失配的情况而需要多次回溯查找后继结点,但每次失配时,回溯查询的次数最多仅为当前结点所在层的深度。因此最坏情况下进行了主串长度次回溯,其平均时间复杂度为O(L*∑),而设立临时结点指针回溯查询具有相同后缀的模式串的次数不会超过自动机的状态结点数,其最差时间复杂度为O (N),因此主串匹配阶段的总时间复杂度为O(L*∑+N)。
4 实验仿真
实验部分测试了SMMA算法,同时比较SMMA算法和AC算法、AC_bitmap算法的时间开销和空间开销。本文随机产生 100 KB文本主串,并给出不同字符集大小的模式串集合,各模式串长度均为100 B,程序运行结果:处理模式串集合,给出每个模式串与主串的关系信息,例如模式串是否匹配、模式串在主串中的位置等。实验所得数据如图1~图6所示,其中P为模式串规模,∑为字符集大小。
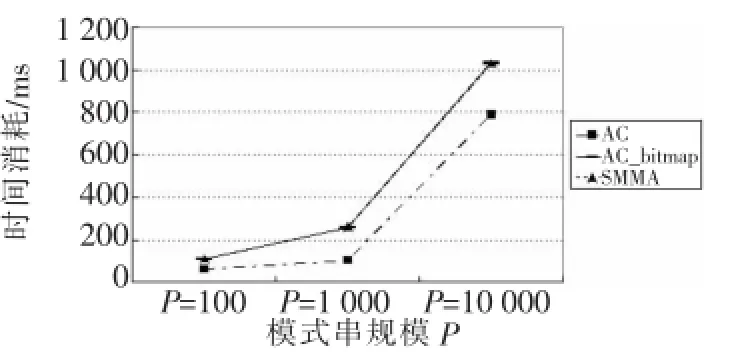
图1 实验结果(∑=10)
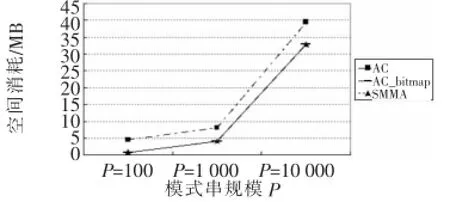
图2 实验结果(∑=10)
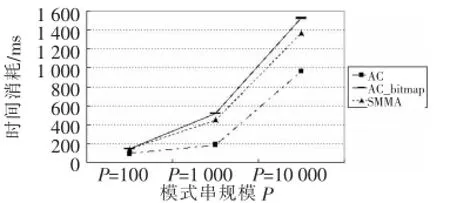
图3 实验结果(∑=100)

图4 实验结果(∑=100)
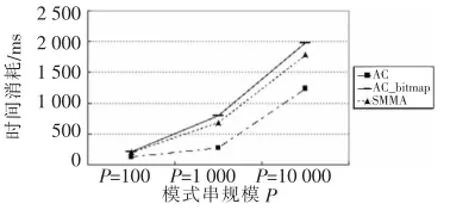
图5 实验结果(∑=1 000)
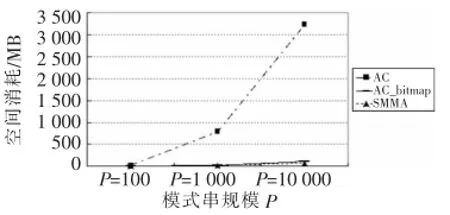
图6 实验结果(∑=1 000)
分析可见SMMA算法在渐近时间复杂度上与AC算法相同,仅在常数上有所增加,在模式串规模扩大、字符集大小增大的情况下,SMMA算法极大地减少了多模式匹配算法的空间消耗。SMMA算法与AC_bitmap算法的时空效率十分接近,平均情况下,SMMA算法的时间效率比AC_bitmap算法提升了 5.8%,空间消耗减少了 16.3%。但随着模式串规模和字符集大小的增加,SMMA算法的优势更加明显。
5 结论
本文提出的SMMA算法避免了无效字符路径的创建,压缩了多模式匹配算法的储存空间,优化了空间效率,有效地改进了AC算法在存储空间上的缺陷。实验结果表明,SMMA算法具有高效的时空效率,在模式串规模与字符集规模增大的情况下,优势更加明显。
[1]王培凤,李莉.基于 Aho-Corasick算法的多模式匹配算法研究[J].计算机应用研究,2011,28(4):1251-1259.
[2]KNUTH D E,MORRIS J H.Pattern matching in strings[J]. SIAM Journal on Computing,1977,6(2):323-350.
[3]BOYER R S,MOORE J S.A fast string searching algorithm[J].Communications of the ACM,1988,20(10):762-772.
[4]AHO A V,CORASICK M J.Efficient string matching:an aid to bibliographic search[J].Communications of the ACM,1975,18(6):330-340.
[5]COMMENTS W R.A string matching algorithm fast on the average[C].Proceedings of the 6th Colloquium on Automata,Language and Programming[S.1.]:Springer-Verlag,1979.
[6]Wu Sun,MANBER U.A fast algorithm for multi-pattern searching[Z].Taiwan,China:Department of Computer Science,Chung-Cheng University,1994.
[7]王永成,沈州,许一震.改进的多模式匹配算法[J].计算机研究与发展,2002,39(1):55-60.
[8]SUNDAY D M.A very fast substring search algorithm[J]. Communications of the ACM,1990,33(8):132-142.
[9]李志东,杨武,张汝波,等.基于异构隐式存储的多模式匹配算法[J].通信学报,2009,30(3):119-124.
[10]徐乾,鄂跃鹏,葛敬国,等.深度包检测中一种高效的正则表达式压缩算法[J].软件学报,2009,20(8):2214-2226.
[11]于强,霍红卫.一组提高存储效率的深度包检测算法[J].软件学报,2011,22(1):149-163.
[12]TUCK N,SHERWOOD T,CALDER T,et al.Deterministic memory efficient string matching algorithms for intrusion detection[C].Proceedings of the 23rd Annual Joint Conference of IEEE Computer and Communications Societies,New Jersey:IEEE Press,2004:2628-2639.
[13]张元竞,张伟哲.一种基于位图的多模式匹配算法[J].哈尔滨工业大学学报,2010,42(2):277-280.
A storage-optimized multi-pattern matching algorithm
Duan Huichao,Han Jianmin,Qiu Sheng
(College of Mathematics,Physics and Information Engineering,Zhejiang Normal University,Jinhua 321004,China)
Aho-Corasick automaton is a classic multi-pattern matching algorithm;however,when the character set of patterns becomes rather large,its storage overhead correspondingly will be much higher.To solve this problem,this paper proposes a storage-optimized multi-pattern matching algorithm(SMMA).In build-up phase of Trie,the subsequent state pointer and mismatching pointer of each state will be kept in storage based on the indexed table.The algorithm won′t store the subsequent state pointer for entire character set of each state,which contributes to the reduction of storage space.The experiments show that the SMMA can reduce the storage overhead greatly while maintaining its efficiency similar to that of AC automation algorithm.
pattern matching;AC automata;Trie tree
TP391.4
A
1674-7720(2015)02-0014-04
国家自然科学基金(61170108);国家级大学生创新创业训练计划项目(201310345005)
(2014-09-25)
段惠超(1993-),男,本科,主要研究方向:模式匹配算法。
韩建民(1969-),男,博士,教授,主要研究方向:信息安全、软件工程。
