基于改进的TF-IDF方法的文本相似度算法研究
2015-07-28周丽杰于伟海
周丽杰,于伟海,郭 成
(1.烟台职业学院电教中心,山东烟台 264670;2.烟台市教育局,山东烟台 264003;
3.大连理工大学软件学院,辽宁大连 116620;4.烟台职业学院成教处,山东烟台 264670)
基于改进的TF-IDF方法的文本相似度算法研究
周丽杰1,于伟海2,4,郭 成3
(1.烟台职业学院电教中心,山东烟台 264670;2.烟台市教育局,山东烟台 264003;
3.大连理工大学软件学院,辽宁大连 116620;4.烟台职业学院成教处,山东烟台 264670)
传统的文本相似度算法采用关键词频率表示该关键词在文档中的重要程度,关键词在类别内不同文档中的频率波动使得关键词的权值产生不稳定性,导致文本之间的相似度运算不够准确.本文提出一种基于词语信息量的改进的TF-IDF算法计算关键词的权值,将得到的权值运用于向量空间模型和马尔可夫模型中,分别得到基于向量空间模型的基础相似度和基于马尔可夫模型的语义相似度,将语义相似度和基础相似度相结合,得到文本之间总体相似度.将改进的文本相似度算法运用于文本分类,实验结果表明,在搜狗文本分类语料库基础上,改进的算法相对于传统的文本相似度算法使得文本分类的准确率有了较大地提高.
文本相似度算法;TF-IDF方法;词语关联;马尔可夫模型;文本分类
1 TF-IDF方法
当前,对文本中关键词的权值计算主要采用TF-IDF方法[1],TF表示关键词在本文档中出现的频率,记为C;DF表示该文本在整个文档集中出现的频率,记为n;IDF表示的是反文档频率,记整个文档集中文档的数目是N,则IDF可表示为N/n.一般认为,关键词在文档中出现的次数越高,表明该关键词在文档中越重要;关键词在文档集出现的越频繁,表明该关键词对于文档区分能力越小,对于关键词i在文档j中的权值计算方法如公式1所示.

公式1中,Ci表示关键词i在文档j中出现的次数,nj表示文档j在文档集中出现的次数,0.01是为了数据平滑.由TF-IDF的定义可知,类别内不同文档内,关键词的频率不尽相同,会出现很大程度的波动现象,使得最终的关键词权值缺乏稳定性.
2 改进的文本相似度算法
对关键词频率波动进行改进,提出全局频率的概念,对多个文本中的关键词频率进行平均化.将新的关键词频率运用于TF-IDF算法,通过余弦相似度法和马尔可夫模型实现文本之间的相似度运算.
2.1 关键词权值计算
由于TF-IDF方法中关键词频率的波动并随之增大了文本特征选择复杂性.基于此,文献[5-6]提出对文档中关键词权值进行归一化操作,依据文档中所有关键词的数量修正文档中关键词的权重,本文在此基础上,综合考虑各个文档中关键词的频率以及文档的长度信息,对频率信息和长度信息进行平均化,提出一种词语信息量的度量方法,得到改进的TF权重计算方法如公式2所示.

公式2中,C1表示该关键词i在文档r1中出现的次数,lr1表示该文档r1的长度,t表示对应所属类别中包含关键词i的文档数目,lr2表示文档r2的长度,s表示该所属类别中所包含文档的数目.得到改进的关键词权重计算公式如公式3所示.

2.2 语义相似度
根据马尔可夫模型的理论基础,将这一理论运用于文本表示当中,通过马尔可夫链中各个状态之间的状态切换概率来表征文本中关键词之间的跳转概率,如图1所示.
图1中,S0→S12→S23→…→Sn4→SF表示的是一条马尔可夫链,该链中各个状态之间边上的权值表示的是状态之间的切换概率.文本相似度运算过程中,马尔可夫链中各个状态对应的是文本中各个关键词,链中状态之间的切换概率对应的是关键词之间的跳转概率.对于S0→S12→S23→…→Sn4→SF这条马尔可夫链,S12→S23表示状态S12所对应的关键词后是S23,所对应的关键词的概率是a13,计算方法为统计S23所对应的关键词出现在S12所对应的关键词之后的次数.因此,马尔可夫链中各个状态之间的跳转关系表示的是文本中关键词的排列顺序.
通过马尔可夫模型中节点之间的跳转概率以及模型中节点权值,得到文本之间语义相似度的计算方法如下所示.

图1 文本中关键词跳转概率图
Step1:基准文本采用马尔可夫模型表示为Tb,表示为向量形式为Tb=(t1Tb,t2Tb,…,tnTb).
Step2:对于待测文本T=(t1T,t2T,…,tnT),对任一关键词tiT∈T,匹配是否在Tb中出现,如果匹配成功,得到匹配节点,匹配节点的权值为WtiT,如果匹配不成功,置节点权值为ε(ε为很小的数),如公式4所示.

Step3:通过匹配节点的权值和跳转概率,得到文本之间语义相似度如公式5所示.

在公式4中,WtiT表示运用改进的TF-IDF方法获得的关键词tiT的权值.
在公式5中,WtiT表示关键词tiT的权值,atiTti+1T表示关键词tiT跳转到关键词t(i+1)T的概率,即关键词t(i+1)T紧随出现在关键词tiT后的次数.若没有出现,则置为1.
2.3 文本总体相似度
通过改进的关键词权重计算方法,对于待测文本T=(t1T,t2T,…,tnT)和基准文本Tb=(t1Tb,t2Tb,…,tnTb),运用余弦向量法得到文本之间基础相似度如公式6所示.

结合语义相似度和基础相似度,得到文本之间总体相似度如公式7所示.
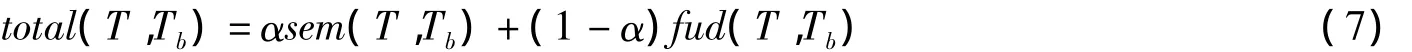
3 实验与讨论
将改进的文本相似度算法运用于文本分类,文本分类的语料库采用搜狗中文文本分类语料库,该语料库中共有17910篇文档,共分为9个类别,每个类别内文档数目为1990篇.采用中国科学院主持研发的ICTCLAS中文分词工具,文本分类算法使用贝叶斯算法,(公式7)中参数α设置为0.4.
使用改进的TF-IDF算法计算关键词权值,为每篇文本构建马尔可夫模型,统计出各个关键词之间的跳转概率.分别从每个类别中选取70%的文本作为训练数据,剩余30%文本作为测试数据[7-8],文本经过分词之后,选取文本中70%关键词用以表示文本,比较本文提出的算法与传统的文本相似度算法在文本分类时不同的分类准确率,如图2所示.
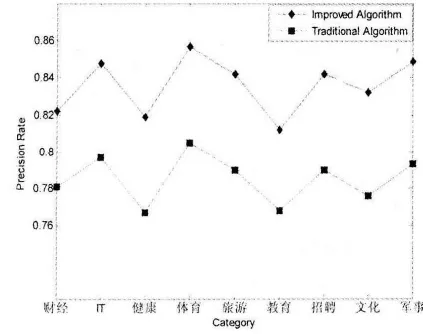
图2 本文算法和传统算法分类准确率比较图
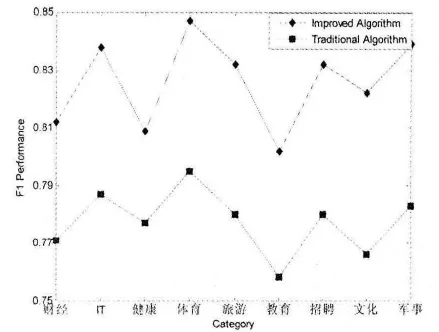
图3 本文算法和传统算法分类F1值比较图
由图2可知,相比于传统文本相似度算法,本文算法使得文本分类的准确率有了较大提高,分类的准确率平均值保持在83.6%左右,而采用传统算法在进行文本分类时,分类准确率平均值只有78.5%左右.
由图3可知,相比于传统文本相似度算法,本文算法使得文本分类的F1值有了较大提高,分类的F1平均值保持在82.5%左右,而采用传统算法在进行文本分类时,分类F1值的平均值只有77.4%左右.
依次选取文本分词之后文本中关键词总数的50%,70%和85%,分别比较本文算法和传统文本相似度算法在分类时的准确率,如图4所示.

图4 关键词总数50%,70%和85%在分类时准确率
由图4可知,当关键词数目较少,为文本中关键词总数50%时,传统文本相似度算法在进行文本分类时的分类准确率平均值只有67%左右,而本文算法使得分类准确率平均值保持在76%附近;当选取文本中70%关键词时,结果如图2所示,选取关键词数目从50%变成70%,传统算法在分类的准确率提高了11%左右,本文算法分类时准确率提高了7%左右;当关键词总数变成总数85%时,本文算法和传统算法在进行分类时的准确率分别是85.6%和85.4%.
对实验结果进行分析,当选取文本中关键词总数较少(50%关键词)时,传统算法在进行文本分类时分类准确率较低,因为文本中特征项选取较少,对文本的表征能力不高,相比于本文算法,本文算法将文本中关键词之间关联性加以提取,待测试文本中与基准文本关键词语义关联相符合特征信息加以权值放大,在选取关键词数目较少时,显著地提高了分类的准确率,比传统算法在分类时的准确率提高了9%左右;当选取关键词的数目达到平衡状态(70%关键词)时,本文算法的优越性显得并非十分明显,但是也使分类的准确率有了较大的提高,提高了5%左右;此时,接近饱和的关键词数目已经能够比较全面的反映文本的特征信息,最后的实验结果也说明了这一点,本文算法在分类时的准确率只比传统算法提高了0.2%.因此,本文算法在特征项的数目选取较少时,能够比较显著的提高文本分类的准确率.
4 结束语
文本特征选择有多种方式,TF-IDF方法是一种常用的方式,TF-IDF方法在计算关键词权重时由于关键词的频率波动导致关键词的权值出现不稳定性,本文提出一种词语信息量的方法,以全局频率为依托,避免关键词因在不同文档的频率不同而产生波动.将改进的关键词权值计算方法运用于向量空间模型和马尔可夫模型,有效地提高了文本相似度计算的准确率,从而提高了文本分类的准确率.下一步的工作应该是提高文本特征提取的效率、更准确的获取关键词之间的语义关联,并对本文构建的马尔可夫模型进行优化,减小马尔可夫模型的存储空间,提高在关键词匹配时的匹配效率.
[1]Yanhui Gu,Zhenglu Yang,Guandong Xu.Exploration on efficient similar sentences extraction[J].World WideWeb,2014,17(4):595-626.
[2]许文杰,陈庆奎.基于余弦向量法的web数据并行抓取系统[J].计算机工程,2009,35(7):64-68.
[3]Koby Crammer,Mark Dredze,Fernando Pereira.Confidence-Weighted Linear Classification for Text Categorization[J].Journal of Machine Learning Research,2012(13):1891-1926.
[4]华秀丽,朱巧明,李培峰.语义分析与词频统计相结合的中文文本相似度量方法研究[J].计算机应用研究,2012,29(3):833-837.
[5]廖一星,潘学增.面向不平衡文本的特征选择方法[J].电子科技大学学报,2012,41(4):592-596.
[6]褚蕾蕾,常文波,李秦.文本聚类中改进特征权重算法[J].工程数学学报,2012,29(4):523-529.
[7]李秦.文本聚类中改进特征权重算法[J].工程数学学报,2012,29(4):523-529.
[8]李侃,周世斌,刘玉树.统计流形扩散核的文本分类方法[J].模式识别与人工智能,2012,25(2):339-345.
Research on Text Sim ilarity Algorithm Based on Improved TF-IDF Strategy
ZHOU Li-jie1,YUWei-hai2,4,GUO Cheng3
(1.Electronic Teaching Center,Yantai Vocational College,Yantai,264670; 2.Yantai Bureau of Education,Yantai,264003; 3.School of Software Technology,Dalian University of Technology,Dalian,116620; 4.Department of Adult Education,Yantai Vocational College,Yantai,264670,China)
Traditional text similarity algorithm uses term's frequency to show the importance of the term in a document,the continuously changing frequency of a term in different documentswhich has common category makes the term'sweightunstable,causing a low precision rate of text similarity calculation.We propose an improved TF-IDF strategy based on term's information capacity to calculate the term'sweight,the obtained term'sweight is used in vector spacemodel and Markovmodel to acquire the fundamental similarity based on vector spacemodel and semantic similarity based on Markovmodel,combining similarity and semantic similarity,the overall similarity between texts is got by combining fundamental similarity and semantic similarity.The experimental results on an open benchmark datasets from Sogou show our proposed approach can improve the accuracy and F1 performance of classification compared to traditional approach.
text similarity algorithm;TF-IDF strategy;word-relation;Markovmodel;text categorization
TP391
A
1672-2590(2015)03-0018-05
文本相似度的研究已经运用于许多的自然语言处理应用当中[1],传统的文本相似度算法采用关键词频率表示关键词在文档中的重要程度,关键词在多个文本中频率的波动导致关键词的权值产生不稳定性,同时也增大了TF-IDF(term frequency-inverse document frequency)方法进行特征抽取时的开销;采用向量空间模型[2]来表示文本,割裂了文本中关键词之间的关联.因此,得到的文本之间的相似度不够准确.研究并发现一种文本的有效处理策略、提取出文本潜在的语义信息资源非常必要.
Koby Crammer等人将自然语言处理中的统计方法引入,提出一种置信度加权的学习策略,并利用高斯分布来更新文本向量中元素的权值因子,试图让向量空间模型能够更加准确的反映文本,然而,文本中关键词之间关联性依然被忽略[3];文献[4]提出根据表征文本特征的关键词的词频信息和语义特征来对文本之间的相似度进行度量,然而关键词的词频波动信息并未考虑,语义特征中也未包含关键词的词序关系;文献将文本中关键词组织成图的形式,通过文本之间共有关键词,建立文本中其它关键词之间的关联,这种方式导致很多完全无关的关键词通过共有关键词建立了联系.通过对大量文献的研究,关键词频率波动会对文本的特征选择产生较大影响,关键词之间的词序关系包含了文本中丰富的信息,对于进一步提高文本之间相似度运算的准确性至关重要.
本文提出一种改进的文本相似度计算方法,为了克服关键词频率的波动,提出一种全局关键词频率的方法,将类别内多个文档中的频率值做平均化,将获得的关键词频率值采用TF-IDF方法计算关键词权值.将得到的关键词权值分别作为向量空间模型中元素值和马尔可夫模型中的节点权值,向量空间模型采用余弦相似度法得到文本之间基础相似度,马尔可夫模型可以体现文本中关键词之间关联性,得到文本之间的语义相似度,将基础相似度和语义相似度相结合,得到文本之间总体相似度.
2015-03-23
国家自然科学基金资助项目(61401060;61272173);山东省高等学校科技计划基金资助项目(J12LN73)
周丽杰(1976-),女,山东龙口人,烟台职业学院电教中心实验师.
