PbRED:基于优先级的RED改进算法*
2015-07-10江明,刘锋
江 明,刘 锋
(1.北京航空航天大学电子信息工程学院,北京 100191;2.国家空管新航行系统技术重点实验室,北京 100191)
1 引言
随着互联网规模的不断增大,互联网上的用户和应用也都在快速增长,拥塞问题已经成为影响TCP传输性能的重大问题,对网络服务质量QoS(Quality of Service)提出了更高的要求。队列管理机制作为TCP/IP的拥塞控制手段,近年来得到研究者们的高度重视,在减轻拥塞、提升吞吐量方面起到了重要的作用[1~3]。
主动式队列管理AQM(Active Queue Management)是基于FIFO调度策略的队列管理机制[4],能够让路由器主动决定在什么时候丢多少包,以实现拥塞控制。AQM能减少丢弃包的数量,提供更优秀的服务性能。AQM算法中最为著名的是随机早期检测RED(Random Early Detection)[5]。RED能够有效控制队列长度,可以更好地支持实时应用;能够最少化全局同步的发生,使带宽利用率不致降低。然而,RED没有考虑业务流的优先级,不能支持服务质量区分,且对参数的敏感度较高。继RED算法之后,研究人员又提出了BLUE[6]、GREEN[7]等算法和SRED[8]、ARED[9]、PRED[10]等RED改进版本。但是,这些算法和改进版本都没有考虑优先级的问题。
在先前将RED应用于存在优先级的场景的研究中,研究者们提出的技术路线大致分为两类。一类是将路由器缓存队列拆分成多个具有不同优先级的虚拟队列,对每个虚拟队列赋予优先级。文献[11]提出了队列实时优先级的概念,将缓存队列分成多个具有不同实时优先级的队列,每当分组到达时按照拥塞程度计算各个队列的实时优先级,并将分组存入优先级最高的队列中;文献[12]按照分组优先级的不同分成多个虚拟子队列,并使用状态方程计算队列长度和丢弃概率;文献[13]提出的算法思想与文献[11]类似,但在计算丢弃概率时使用ARED算法来更新最大丢弃概率。这类算法需要维持多个虚拟队列,会增加分组乱序的问题,从而导致TCP性能降低或者增加延迟抖动。
另一类则是将到来的分组按业务流的不同赋予优先级。最典型的是RIO算法及其改进算法RIO-C[14]。RIO在一个队列中管理in分组和out分组而不需要维持两个队列;RIO-C在RIO的基础上将丢弃优先级扩展为三类,然而会对高丢弃优先级的分组过量丢弃;文献[15]提出PFRIO算法,为每类丢弃优先级设置一组参数并分别计算平均队列长度和丢弃概率,但各优先级丢弃概率的差异仍然较大;文献[16]的基本思想与文献[11]类似,而使用IPv6包头的流标签域来标记优先级包和非优先级包。这类算法大多关注各优先级之间的丢包率比较和平均队列长度,对吞吐量等性能没有提升。在计算丢弃概率时往往使高丢弃优先级分组的丢弃概率急剧增加,有失公平性[14~17]。同时,还要维持多组参数,不仅需要消耗较多存储资源,具有相当的计算复杂度,而且依然存在对参数敏感度的问题,由于参数众多,参数敏感性问题甚至比RED更甚。
近年来,研究者们仍然对有优先级的RED有较高的关注,相关研究仍在继续。文献[18,19]针对AQM与VoIP相容的问题,提出了新的架构BOUDICCA,用基于AF-PHB和WRED配置的方法来降低成本并划分优先级。BOUDICCA对VoIP网络针对性较强,结合使用了OSPF路由选择与RED的拥塞控制。它是几种不同领域的算法结合起来的整体架构,并没有对RED算法本身进行有效的改进,只是通过设置不同的Pmax来调整“金、银、铜”三种不同优先级的丢弃概率,以保证“金”数据流的高QoS。文献[20]提出DF-RED算法,用优先级来保护适应流。当适应流与非适应流同时存在且非适应流大量攫取资源时,DF-RED增大非适应流的丢弃概率,从而起到保护适应流的作用。DF-RED的优先级是在网络运行中动态确定的,因此其计算成本较高,而且从仿真结果看,其队列长度变化比RED更剧烈。文献[21]提出的算法使用反馈的方式,把拥塞检测信号通知给tcp流,能更快地探知到早期拥塞。其只在入口节点对分组进行优先级的划分,对适应流和非适应流的性能保障有明显区分度,但同种流之间则无明显区分。
本文提出一种新的RED改进机制—基于优先级的RED PbRED(Priority based RED),针对RED没有考虑到业务流存在优先级从而无法区分服务质量的情况,对业务流赋予优先级,使用优先级信息调整丢弃概率,优先级越高,丢弃概率越小,反之亦然。不同于现有的算法,PbRED可以通过调节可调参数,自由调整不同优先级业务流的丢弃概率,从而使不同优先级服务质量的线性区分度具有可控性,保证高优先级业务流获得更好的吞吐量性能,并且提高tcp流对cbr流的竞争力。在得到较好性能的同时,几乎不会损失公平性。
2 随机早期检测算法RED
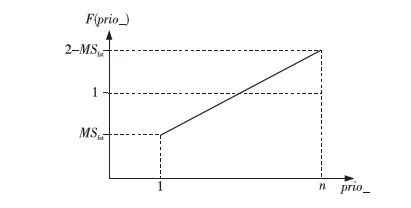
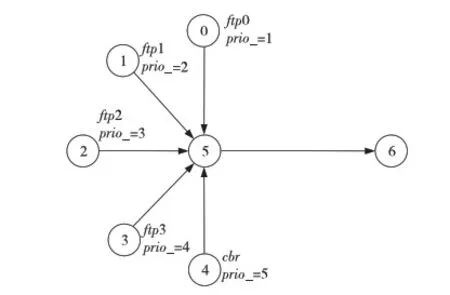
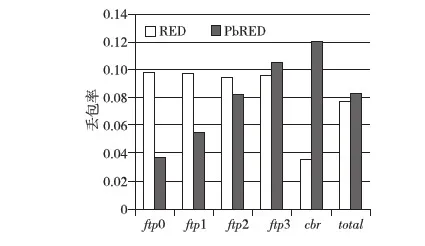
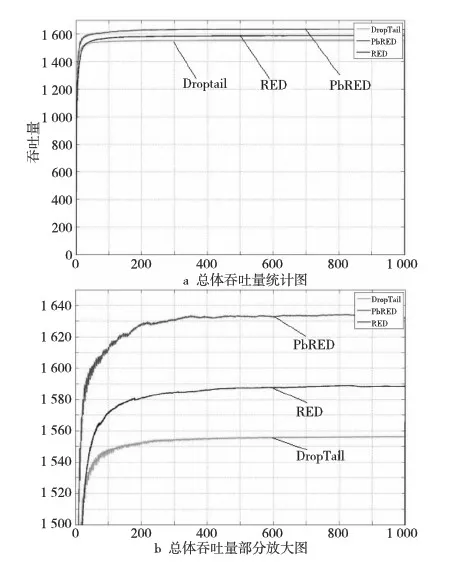
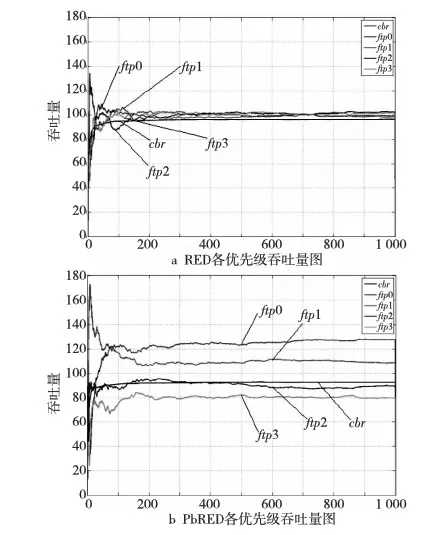
RED的基本思想是通过监控路由器输出端口队列的平均长度来探测拥塞,一旦发现拥塞逼近,就随机地选择连接来通知拥塞,使它们在队列溢出导致丢包之前减小发送窗口,降低发送数据的速率,从而缓解网络拥塞。每当有分组到达时,RED算法首先计算此时的平均队列长度Lave,并将之与队列长度最小门限THmin和最大门限THmax比较。若Lave RED算法能够准确地辨别拥塞,有效缓解全局同步现象,提高网络资源的利用率;能够有效地将平均队列长度控制在较低的长度,缓解早期拥塞现象;同时,RED算法的控制原理简单,计算复杂度低,实现简便。 RED算法没有考虑到不同业务流存在不同优先级的情况,因而不能较好地区分服务。在实际应用中,很多时候希望不同的业务流得到不同的服务质量。当带宽资源有限时,应当优先保证实时性业务的服务质量,例如视频流、音频流和文本流同时存在时,我们希望视频流能够得到高于其他两个流的服务质量,而音频流的服务质量又应当高于文本流。又如付费用户的业务流理应比非付费用户的业务流得到更好的服务。 另外,RED虽然能够在ftp流之间较为公平地分配带宽,但当ftp流和非ftp流(例如cbr流)同时存在时,RED就不能有效地保护ftp流。因为RED本质上还是通过丢弃数据包来通知ftp源减小发送窗口来控制拥塞,而cbr流没有拥塞控制机制,不会由于丢包而降低发送速率。因此,当发生拥塞时,cbr流能够比ftp攫取到更多的网络带宽,这是我们不希望看到的。 在RED计算丢弃概率Pdrop时,对所有的业务流的计算都是相同的,在所有的流之间随机挑选要丢弃的分组。这样的做法对不同优先级的业务流没有区分度,高优先级的业务流与低优先级的业务流得到的服务质量是大致相同的。 本文提出的PbRED算法,使用优先级信息来计算丢弃概率Pdrop,使高优先级业务流的Pdrop减小,低优先级业务流的Pdrop增大,进而使高优先级业务流获得相对较多的资源。同时,由于cbr流的优先级最低,能够通过大量丢弃cbr流的包,把cbr流攫取的带宽提供给tcp流,从而提高tcp流对cbr流的竞争力,保护tcp流。 在实际的应用中,应当根据不同业务流类型、业务流的紧急程度等信息来确定业务流的优先级。而在本文理论分析及仿真实验中,为简化起见,直接对每个业务流分配优先级。本文规定,用从1开始的自然数来代表每个业务流的优先级,并用prio_表示优先级这个变量。优先级最高的业务流,其prio_值为1;优先级第二高的业务流,其prio_值为2,以此类推。在本文的分析中,假设网络中共有n条业务流,且优先级互不相同,优先级最低为n。 在PbRED算法中,丢弃概率Pdrop对所有业务流不再是相同的,而是与每个业务流的优先级相关。优先级越高,丢弃概率越小。新的丢弃概率计算方法为: Pdrop=Pdrop-old×F(prio_) (1) 其中,Pdrop-old是改进前的丢弃概率,即RED算法中的丢弃概率。F(prio_)是不同优先级对应的缩减系数,F(prio_)∈[0,1]。F(prio_)的计算方法为: (2) 其中,n表示优先级的个数;MDfst(即Min-Drop-first)代表优先级为1的缩减系数值,它是所有优先级的缩减系数中的最小值;第n个优先级的缩减系数为2-MDfst。由于所有优先级的缩减系数是线性变化的,这就保证了在正常情况下,所有缩减系数的数学期望是1,即从统计的角度来讲,丢弃概率的期望值与RED是相同的。 F(prio_)函数如图1所示。低优先级业务流的丢弃概率在乘以缩减系数之后有可能增大至超过1,对于超过1的丢弃概率,都以1计算。 Figure 1 F(prio_) function图1 F(prio_)函数 PbRED算法中的优先级与IP协议中规定的优先级物理意义相同,但为了理论研究和仿真实验的简化,使用的是IPv6数据报首部中的“Flow Label(流标号)”域。由于使用已有的域,不必另行增加报头的开销,也不会增加计算复杂度。 MDfst是PbRED算法中一个很重要的可调参数,它的取值会影响到PbRED算法的性能。PbRED通过调节参数MDfst来调整不同优先级业务流的丢弃概率。从图1中能够看出,MDfst的取值越小,各优先级的缩减系数之间的差值越大。MDfst的两个极限值分别是0和1。当MDfst=0时,优先级为1的流的分组的Pdrop=0,即不会被丢弃。当MDfst=1时,所有优先级的丢弃概率都是Pdrop-old,即此时就是RED。从这个角度,可以把RED算法看成是PbRED算法的一个特例。MDfst的取值在0.3~0.6时,能够取得较好的性能,本文中取MDfst=0.5。 PbRED既不必维持多个虚拟队列,也不需要多组参数,因此不存在分组乱序和参数敏感性的问题。 由以上对PbRED算法的介绍和分析,最终总结PbRED算法的伪代码如算法1所述。 算法1PbRED算法 输入: p//新近到达的分组; n//优先级数量; MDfst//第1优先级的缩减系数。 输出: Pdrop//分组p的丢弃概率 /*首先由RED算法进行处理,若此时平均队长在上下门限之间,则得到RED算法的丢弃概率*/ 1:if(Lave>THmin&&Lave 2:{ 3: 由RED算法计算丢弃概率Pdrop-old; 4:} //获取分组p的优先级信息 5:获取p→prio_; //计算p的缩减系数及丢弃概率 6:计算p的缩减系数;//由式(2) 7:计算丢弃概率;//由式(1) 8:if(Pdrop>1) 9:{ 10:Pdrop=1;/*针对低优先级丢弃概率可能大于1的情况进行调整*/ 11:} 12:返回Pdrop; PbRED流程图如图2所示。 Figure 2 Flow chart of PbRED图2 PbRED流程图 仿真使用NS2模拟实验平台[22~25]对RED和PbRED两种算法进行了实现和性能评估。仿真采用的性能指标有三项,分别是: (1)丢包率:在传输过程中丢失的数据分组数与信源总共发送的数据分组数的比率。 (2)队列长度:包括瞬时队列长度和平均队列长度,以字节为单位,除以分组大小即得包的个数。 (3)吞吐量:单位时间内信宿接收到的数据量。 仿真使用的场景是队列管理实验典型的单边哑铃型结构,如图3所示。 Figure 3 Simulation script图3 仿真场景 节点0、1、2、3、4为五个信源,业务流类型分别为四个ftp源和一个cbr源,代号分别为ftp0~ftp3和cbr,优先级依次为1、2、3、4、5。节点5和6之间的链路为瓶颈链路5-6,其带宽为0.5 Mb,延时为20 ms。五条信源链路0-5、1-5、2-5、3-5、4-5的参数相同,带宽为2 Mb,延时为10 ms。所有tcp源的发送窗口均为10 000,cbr源的发送速率为0.1 Mb,所有数据源的分组大小均为500。实验中取MDfst=0.5,RED算法的各参数均为NS2下的默认参数,即THmin=5,THmax=15。仿真时间为1 000 s。 4.2.1 丢包率 表1为仿真的丢包率的统计结果。从表1中可以看出,由于cbr流不受拥塞控制,在发生拥塞时不会降低发送速率(即两种算法下,发送包数不变)。RED算法对各业务流的丢弃概率大致相同,但由于cbr流发送速率大于ftp流,故丢包率相对较小,因此能够攫取到更多资源,其丢包率远远小于ftp流。而PbRED算法在区分各优先级的丢包率的同时,能够大幅提升cbr流的丢包率(因为其优先级最低),使得ftp流能够获得更多资源,从而达到保护ftp流的目的。 Table 1 Statistics of loss rate 根据表1中的丢包率数据,绘制丢包率柱状图如图4所示,图中每个数据源的左侧柱为RED的数据,右侧柱为PbRED的数据。从图4中可以形象地看出,PbRED使得各优先级的丢弃概率呈现出区分度,并且大大提升了cbr流的丢弃概率,从而保护了tcp流。 Figure 4 Statistical histogram of loss rate图4 丢包率统计柱状图 4.2.2 队列长度 图5为仿真的队列长度的统计结果。从图5中可以看出,虽然瞬时队列长度变化非常剧烈,但RED算法和PbRED算法都能够使得平均队列长度维持在12~13个左右,即PbRED算法不会增加队列的平均长度。 Figure 5 Statistical chart of queue length图5 队列长度统计图 4.2.3 吞吐量 图6和图7为仿真的吞吐量的统计结果。图6a为总体的吞吐量统计图,将DropTail、RED和PbRED三种算法进行比较;图6b是部分放大图。从图中可以清楚地看到,RED算法的吞吐量相比于DropTail有一定的提升,而PbRED算法又能够在RED算法的基础上进一步较大幅度地提升总体吞吐量。 Figure 6 Statistical chart of total throughput图6 总体吞吐量图 图7为各优先级的吞吐量统计图,从图7a中能够看出,RED算法没有考虑优先级的影响,故各业务流的吞吐量非常接近,各ftp流的吞吐量没有区分度,而cbr流的吞吐量也与ftp流相接近。而图7b中,PbRED能够合理地区分各优先级的服务质量,各优先级的吞吐量水平呈现显著差异,高优先级的业务流的吞吐量得到较大提升,ftp0的吞吐量上升幅度最大。同时,cbr流的吞吐量有明显下降,把一部分带宽资源让给了ftp流,从而达到了保护tcp流的目的。 Figure 7 Statistical chart of each priority’s throughput图7 各优先级吞吐量图 4.2.4 公平性 为了评估PbRED的公平性能,利用文献[17]中对算法公平性指标的定义: (3) 其中,xi表示每个优先级数据源所发送的数据包数量,n表示数据源的数目。公平性指数FI在[0,1],且FI越大,算法的公平性越好。 根据表1中的发送包数据,由式(3)计算得到RED的公平性指数为0.919 6,而PbRED算法的公平性指数为0.909 6。按照文献[14~16]的仿真结果,由式(3)计算得到RIO-C、PFRIO和文献[16]算法的公平性指数分别为0.668 0、0.800 6和0.500 0。比较结果可以看出,文献[14~16]的三种算法的公平性均有不同程度的牺牲,RED算法的公平性最好,本文的PbRED算法的公平性与RED算法接近。 4.2.5 实验小结 多次仿真实验得到的结果与理论分析得出的结论相吻合,表明了PbRED算法的合理性和正确性。当各业务流有不同优先级时,PbRED能够在略微提升整体吞吐量、有效控制平均队列长度的前提下,合理区分不同优先级业务流的服务质量,保证高优先级业务流得到更好的服务质量。同时,能够增大低优先级cbr流的丢包率,降低cbr流的吞吐量,将带宽资源更多地分配给ftp流,从而提高ftp对cbr流的资源竞争力,有效保护ftp流。 本文提出了一种新的基于优先级的RED改进算法—PbRED,针对RED没有考虑到业务流优先级、不能区分服务质量的情况进行了改进,使用优先级信息计算丢弃概率,使不同优先级业务流的服务质量存在线性区分度,优先级越高,丢弃概率越小,反之亦然。通过调节可调参数,可以自由调整不同优先级业务流的丢弃概率,从而控制不同优先级服务质量的区分度。在保证高优先级业务流能得到更好的服务质量的同时,提高tcp流对cbr流的竞争力,有效保护tcp流。仿真实验表明,在保证不降低整体吞吐量、平均队列长度不变、公平性较好的前提下,PbRED算法能够合理区分不同优先级业务流的服务质量,并保证高优先级业务流得到更好的吞吐量性能。同时,能够增大低优先级cbr流的丢包率,降低cbr流的吞吐量,将带宽资源更多地分配给ftp流,从而提高ftp对cbr流的资源竞争力,有效保护ftp流。 随着RED算法在网络中的广泛应用,研究者们一直在寻求对它进行各个方向的改进。未来的工作将对PbRED的参数进行深入探讨,确定各参数的最佳值,如如何取值能够得到最佳折衷和最优性能、上下门限应如何取值才可以得到最好的性能、是否需要调整其它参数等;同时要考虑如何减少低优先级付出的代价,使得整体的性能进一步优化。这些都是很有价值的研究方向。 [1] Wu Chun-ming,Jiang Ming,Zhu Miao-liang.Research on some active queue management algorithms[J].Chinese Journal of Electronics,2004,32(3):429-434.(in Chinese) [2] Xu Yan,Wang Zheng-hong.Comparative study of several active queue management algorithms[J].Journal of Jiangsu Polytechnic University,2004,16(4):52-55.(in Chinese) [3] Xie Xi-ren.Computer networks[M].Beijing:Publishing House of Electronics Industry,2011.(in Chinese) [4] Braden B,Clark D,Crowcroft J, et al. IETF RFC2309 . Recommendations on queue management and congestion avoidance in the Internet[S].The Internet Society,1998. [5] FIoyd S,Jacobson V.Random early detection gateway for congestion avoidance[J]. IEEE/ ACM Transactions on Networking,1993,1(4):397-413. [6] Feng W C,Kandlur D D,Saha D.Blue:A new class of active queue management algorithm[R].Michigan:University of Michigan Technical Reports,1999. [7] Wydrowski B, Zukerman M. GREEN:An active queue management algorithm for a self managed internet[C]∥Proc of ICC’02, 2002:2368-2372. [8] Ott T J,Lakshman T V,Wong L. SRED:Stabilized RED[C]∥Proc of IEEE INFOCOM’99,1999:1346-1355. [9] Floyd S,Gummadi R,Shenker S. Adaptive RED:An algorithm for increasing the robustness of RED’s active queue management[EB/OL].[2013-05-10].http://www.icir.org/floyd/papers.html. [10] Shi Pei-xin,Lei Zhen-ming.PRED:An active queue management for SPFQ[J].Computer Engineering and Applications,2003,39(26):1-5.(in Chinese) [11] Zhang Ke-ping,Tian Liao,Li Zeng-zhi.PRED:A new queue management algorithm with priority and self-adaption[J].Chinese Journal of Electronics,2004,32(6):1039-1043.(in Chinese) [12] Yang Qing-xiang,Li An-fu.Packet priority-based queue management and adaptive packet drop mechanism[J].Electric Power Automation Equipment,2006,26(4):18-20.(in Chinese) [13] Zhu Guo-hui.An algorithm with priority improved on RED[J].Journal of Shaanxi University of Science&Technology,2010,28(5):146-150.(in Chinese) [14] Clark D,Wang W J. Explicit allocation of best-effort packet delivery service[J]. IEEE/ACM Transactions on Networking, 1998,6(4):362-373. [15] Kang Ya-nan,Zhang Cai-yun,Cheng Ru-zhen.Active queue management research for DiffServ model[J].Computer Engineering and Applications,2009,45(5):125-128.(in Chinese) [16] Zhang Li-li.Research of priority detection RED based on IPv6[D].Jilin:Jilin University,2012.(in Chinese) [17] Jain R,Chiu D M,Hawe W. A quantitative measure of fairness and discrimination for resource allocation in shared systems[R]. Technical Report TR301. Maynard:Digital Equipment Corp,1984. [18] Pitts J M, Yang Qiang, Schormans J A. Using AF-PHB BOUDICCA configuration for reliable real-time precedence-based SLAs in degraded IP networks[C]∥Proc of IEEE Military Communication Conference,2007:495-501. [19] Pitts J M, Wang X, Yang Qiang, et al. Excess-rate queueing theory for M/M/1/RED with application to VoIP QoS[J]. IEEE Electronics Letters, 2006,42(20):1188-1189. [20] Yu Guan-wei,Xing Wei,Lu Dong-ming.DF-RED:A dynamic fairness based RED algorithm[J].Manufacturing Automation,2010,32(9):7-13.(in Chinese) [21] Li Xin,Chen Hao,Chen Jian.Scheme research of congestion management in DiffServ networks based on feedback[J].Application Research of Computers,2013,29(8):3088-3090.(in Chinese) [22] Sanjeev P, Gupta P K, Garg A.Comparative analysis of congestion control algorithms using ns2[J].IJCSI International Journal of Computer Science Issues, 2011,8(1):1-4. [23] Huang Hua-ji,Feng Sui-li,Qin Li-jiao,et al.NS network simulation and protocol emulation[M].Beijing:Posts&Telecom Press,2010.(in Chinese) [24] Fang Lu-ping,Liu Shi-hua,Chen Pan,et al.NS-2 network simulation basis and application[M].Beijing:National Defense Industry Press,2008.(in Chinese) [25] NS2[EB/OL].[2013-05-10].http://www.isi.edu/nsnam/ns/. 附中文参考文献 [1] 吴春明,姜明,朱淼良.几种主动式队列管理算法的比较研究[J].电子学报,2004, 32(3):429-434. [2] 徐燕,王正洪.几种主动队列管理拥塞控制算法的比较研究[J].江苏工业学院学报,2004, 16(4):52-55. [3] 谢希仁.计算机网络[M].北京:电子工业出版社,2011. [10] 时培昕,雷振明.PRED:一种配合队列调度的RED算法[J].计算机工程与应用,2003,39(26):1-5. [11] 张克平,田辽,李增智.PRED:一种具有优先级自适应的队列管理新算法[J].电子学报,2004,32(6):1039-1043. [12] 杨庆祥,李安伏.基于分组优先级的队列管理与自适应丢包机制[J].电力自动化设备,2006,26(4):18-20. [13] 朱国晖.带有进出优先级的RED改进算法[J].陕西科技大学学报,2010,28(5):146-150. [15] 康亚男,张彩云,成汝震.DiffServ模型中主动队列管理研究[J].计算机工程与应用,2009,45(5):125-128. [16] 张黎丽.基于IPv6网络的优先级检测RED算法的研究[D].吉林:吉林大学,2012. [20] 余冠玮,邢卫,鲁东明.DF-RED:一种基于动态公平性的RED算法[J].制造业自动化,2010,32(9):7-13. [21] 李昕,陈浩,陈坚.基于反馈的区分服务网络拥塞管理方案研究[J].计算机应用研究,2012,29(8):3088-3090. [23] 黄化吉,冯穗力,秦丽姣,等.NS网络模拟和协议仿真[M].北京:人民邮电出版社,2010. [24] 方路平,刘世华,陈盼,等. NS-2网络模拟基础与应用[M].北京:国防工业出版社,2008.3 PbRED算法
3.1 PbRED改进算法的基本思想
3.2 PbRED算法
3.3 PbRED的分析
3.4 PbRED算法细节

4 仿真结果及分析
4.1 仿真场景
4.2 实验结果


5 结束语
