一种基于气泡流控的改进多播路由算法*
2015-07-10肖灿文董德尊庞征斌李存禄
娄 辉,肖灿文,董德尊, 庞征斌,李存禄
(国防科学技术大学计算机学院,湖南 长沙 410073)
1 引言
随着人们对芯片计算性能需求的不断提升,单纯依靠提高芯片时钟频率来提高整体计算性能的方法已经很难满足性能的需要,因此当前片上系统大多通过增加芯片上集成的处理器核的数目来进一步提升性能。片上网络通过通信链路连接多个处理器核,这种方式与基于总线的互连相比,能够实现更低的通信延迟、更高的吞吐量和更低的能耗。片上网络作为不同处理器核之间的通信部件,其性能对片上系统的整体性能会产生很大影响。当前片上多处理器系统研究大多致力于提升单播通信的性能,然而许多并行应用和程序模型都需要支持多播。例如,在基于目录的 Cache 一致性[1]协议中,大量依赖多播和广播通信特性去维持请求间的顺序,并通过广播作废不同Cache节点上的共享数据块;而在基于令牌的 Cache 一致性协议[2]中也需要使用多播收集令牌。在不同的Cache 一致性协议通信模型中,多播通信占网络总通信量的3.1%~12.4%[3]。因此,设计一种针对多播通信的高效的路由算法将会有效提升片上网络的通信性能。表1列出了不同协议下多播通信占系统总通信量的比例。从表1可以看出,多播通信在网络中所占的比例很大,这些聚合通信对多核系统的性能会产生显著的影响,即使网络中注入很少的多播包,网络吞吐量也会明显下降。为了避免这些重要的聚合通信成为整个片上系统性能提升的瓶颈,片上网络必须支持多播通信这种重要的通信模式。路由算法决定了网络中报文的通信形式,同时不同的路由算法对网络中带宽的利用、平均报文时延、饱和吞吐率以及能耗等都有很大的影响。对于多播也是一样,不同的多播路由算法也会显著影响网络资源的利用效率。因此,一个高效的多播路由算法对多处理器系统来说至关重要。

Table 1 Proportion of multicast in the network
多播和广播是一个源节点向一个目的节点集合发送同样的数据信息的通信模型。多播报文通信的主要目标是为多播报文选择一条最优路径,使得报文在该路径上传播所占用的通道带宽尽可能少,并使该报文的传播延迟尽可能短。报文死锁会明显降低多播通信的性能,因此在多播路由设计中应保证报文传播不会产生死锁。多播通信对网络的整体性能产生很大影响,因此当前的许多工作对如何设计高效的多播路由算法以提高片上网络整体性能进行了研究。
当前已有很多针对多播通信的路由算法,例如,基于树的多播路由算法[4]保证多播报文尽可能地沿着共同路径传输,当需要发往不同方向的目标节点时进行报文复制,从而使多播报文以树的形式发送到所有目标节点。该方法的一个明显缺陷是容易产生拥塞,当传播树中有一个分支拥塞时,其它的分支也会被阻塞,拥塞的产生使得该方法的网络吞吐率很低。基于路径的多播路由算法限制多播报文沿着同一路径依次通过各个目标节点,报文首先到达离源节点最近的目的节点,然后到达较远的节点,并在报文到达目的节点时进行复制。这种方法往往使得报文传播的路径很长,从而增加了报文的传输延迟。由于片上网络在面积、能耗和性能等方面都有严格的限制,因此这些方法不适合在片上网络使用。虚电路树多播路由VCTM(Virtual Circuit Tree Multicasting)[3]是片上网络中一种重要的多播路由算法。该算法只需要添加较少的存储空间就能够有效地支持多播与广播。但是,该算法有三个缺点:(1)为维持多播信息需要额外的存储空间,从而增加了芯片的面积;(2)传播过程中需要多播包的建立信号,从而增加了网络中的延时;(3)即使是同样的目的节点集,如果多播源节点改变,VCTM也必须重新建立多播树进行多播通信。这些缺陷使得VCTM不能很好地运用到大规模网络中。支持广播的逻辑划分路由BLBDR(Broadcast Logic-Based Distributed Routing)[5]通过划分工作区域来有效隔离有缺陷的区域,同时关闭不需要的网络区域,从而有效降低能耗。该方法确定了NOC中层虚拟化的概念,对网络的不同区域进行隔离通信。但是,如果目的节点集合散落到不同的网络部分,则该算法的性能会明显降低,这是因为该方法很难确定一个能够覆盖所有的目的节点的区域,因此该调度算法在片上网络多播通信中并不适用。递归划分多播路由算法RPM (Recursive Partitioning Multicast)[6]由于存在缓存资源利用的不均衡,其性能也受到了相应影响,本文后续部分将进行详细分析。均衡自适应多播路由算法BAM (Balanced Adaptive Multicast)[7]采用的死锁避免方法,影响了网络通道资源的利用率,本文就是针对RPM和BAM算法的不足提出了新的基于气泡流控的多播路由算法。
本文的主要贡献总结如下:
(1)改进了多播路由算法(RPM和BAM)的死锁避免方法。通过加入气泡(即空闲虚通道)的方法来避免死锁,该方法释放了为了防止死锁而预留的网络缓存资源,从而更有效地利用了网络的缓冲资源,提升了网络的性能。
(2)对该方法的无死锁性进行了论述。
(3)评估了不同流量模型下改进的RPM和BAM的性能,同时评估了改进的BAM在不同网络资源下的敏感性及可扩展性。
本文其余部分组织如下:第2节介绍了我们的多播路由算法的实现过程;第3节介绍路由器流水线和微体系结构;第4节评估了不同路由算法的性能,并与我们提出的方法进行了比较,同时总结了模拟结果;最后是本文的结论。
2 多播路由算法
本文针对RPM和BAM两种多播路由算法存在的不足,提出一种新的多播路由算法。RPM能够根据包当前所在的地址,将网络划分成八个区域。根据报文目的节点在这八个区域的位置,采用一系列的优先级规则计算出报文去每个区域的优先的输出端口。RPM尽可能多地使报文沿着同一条路径传输来减小网络带宽的使用,之后进行复制操作,将复制的包传输到各个目的节点。但是,为了防止多播路由的死锁,RPM采用了两个虚拟网络VN0和VN1,VN0只传输向上的报文,VN1只传输向下的报文。这种死锁避免的方法使水平方向的缓存成为了性能的瓶颈,它被VN0和VN1同时使用而垂直方向的只有一个方向使用。这种方法由于不同维度的缓存资源的使用不均衡影响了它的性能。BAM也是根据包当前所在的地址,将网络划分成八个区域,但它根据各输出端口的拥塞程度选择到达目的区域具有较低拥塞程度的输出端口,从而高效地使用链路带宽。BAM为了防止死锁,将Duato 的单播死锁避免理论[8]运用到多播路由算法上,将网络中的虚通道划分为适应性虚通道和逃逸虚通道。一旦多播包进入逃逸虚通道,后续路由算法就按维序路由进行报文复制。这种死锁避免的方法,当网络要发生死锁的时候才用逃逸虚通道,所以网络中的逃逸虚通道在网络使用的概率比较小。它使网络的虚通道的资源没有充分利用,造成资源浪费,导致网络性能不能充分发挥。当多播报文进入逃逸虚通道时报文只能够进行维序路由。这种路由方法是为了保证无死锁而牺牲了网络中的带宽,从而使带宽不能充分利用,网络延时增大。由于在逃逸虚网络中向北和向南传输的报文不能够转变方向,造成了网络不同维度间的资源的不均衡。
基于对RPM和BAM的观察与分析,本文提出了一种新的多播死锁避免方法。这种死锁避免方法是在网络的垂直方向注入气泡(Bubble),取消RPM和BAM的两个网络。以BAM为例简述新死锁避免方法,改进BAM简称BAM-B。
BAM-B是在BAM基础上提出来的,首先叙述BAM的均衡自适应多播路由算法。BAM首先根据报文的位置将网络划分成八个区域,分别为 0、1、2、3、4、5、6、7,如图1所示。位于 1、3、5 和 7 中的目标节点只有一个输出端口到达, 因此多播报文目标节点中有处于 1、3、5 或 7的,则对应的北、西、南或东输出端口一定会被选择使用,这些端口被称作必须输出端口。而处于区域0、2、4、6的多播报文目标节点,源节点有两个方向输出端口可以到达它们。网络中报文传输遵守如下规则:(1)如果目标节点只有一个必须端口,则沿着必须端口传输数据。(2)如果没有必须输出端口或有两个必须输出端口,则报文沿最低拥塞的输出端口方向传输。以上是BAM与BAM-B相同的地方,下面是本文提出的改进算法不同的地方。

Figure 1 Network regional division schematic diagram图1 网络区域划分示意图
不同的主要地方在于对死锁的处理方式。不失一般性,考虑多播源节点位于如图1所示的位置,考虑多播包向北输出端口传输,且目标节点集都在北向这一维的不转维的情况,即目的节点集中不带有0和2区域的节点,则不需要加入气泡(即空虚通道),虚通道全部分配给包进行虚通道VC(Virtual Channel)分配。当去目标节点存在一次路由转维时,此例子中即目的节点集中存在0或2区域的目的节点,则将VC中加入气泡,即留一个切片缓存区,其它的全部分配给包进行VC分配。
死锁发生的情况如图2所示,A包占据通道U请求通道V,B包占据通道V请求通道W,C包占据通道W请求通道X,D包占据通道X请求通道U。

Figure 2 Packet deadlock situation图2 报文发生死锁情况
文献[9]证明了在Mesh网络中通过注入气泡来提高单播完全自适应路由网络性能的方法是无死锁的。但是,它没有涉及网络中存在多播的情况。由于Cache 一致性协议的多播包大量用于传输网络中的控制信息,同时片上有大量的连线资源,所以可以将这些信息用单切片的多播包传输。在网络中传输的单切片的多播包,各个复制的切片相互独立,类似于单播包。
所以新的多播路由算法与网络中注入气泡的单播完全自适应路由算法有类似的性质且都是无死锁的。下面将描述新的多播路由算法是无死锁的:
(1)如果X中的虚通道中所有的报文都请求U,由改进新的路由算法知X通道中必然存在一个空闲VC。W中请求X虚通道的报文必有一个能够请求成功,则W中的报文可以继续向X通道传输。因此,W中将有空闲VC,V可以请求W,则这种情况下存在一个报文可以移动。
(2)如果X中的所有VC都被占用,由改进的新路由算法知X通道中必然存在一个报文到达目的节点(可以排出)或脱离该环(不请求U,向上传输),则将产生新的空闲VC。W中请求X虚通道的报文必有一个能够请求成功,W中的报文可以继续向X通道传输,则在这种情况下存在一个报文可以移动。
综上所述,这种新的多播路由算法是无死锁的。与RPM的死锁避免方法不同,新的多播死锁避免方法解决了RPM 为了防止死锁而采用两个虚拟网络造成的网络缓存资源使用不均衡的问题;与BAM的死锁避免方法也不同,解决了BAM为防止网络死锁采用逃逸虚通道而造成的虚通道的资源没有充分利用,和逃逸虚通道中带宽的不充分利用等问题。
3 路由器流水线和微体系结构
本文选择的基准路由器是交叉开关分配虚通道路由器[10,11]。路由器使用预先选择策略来提前选择拥塞比较小的输出端口,其原理是前一个时钟预先选择每个象限下一时钟的优先输出端口。多播报文和单播报文采用经典的五步流水线,单播报文流水线如图3a所示和多播报文流水线如图3b所示。
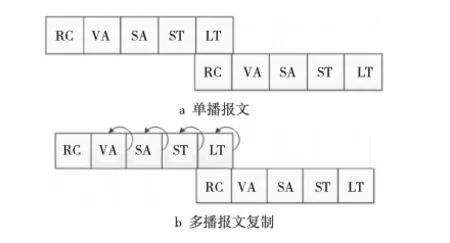
Figure 3 Packet pipeline图3 报文的流水线
在多播通信模式下,在中间路由器,一个包需要去复制几个拷贝的包。为了支持多播包的复制,路由器需要增加复制部件,修改在单播包情况下的虚通道分配器VA(Virtual Channel Allocator)和交叉开关分配器SA(Switch Allocator) 。由于Cache 一致性协议的多播报文一般传输的是控制信号,故网络上传输的多播报文都是单切片报文。路由器增加的复制部件仅仅是一些控制逻辑,多播包只有SA和VA分配成功才复制切片向下传输。这种情况下不需要等待所有的地址都分配成功才发送切片。满足一个输出端口则发送一个复制切片,只有当所有的请求输出端口都得到满足时 ,多播报文才能够从输入虚通道中移除。
图4描述了路由器微体系结构。Pre-selection 模块为每个象限预先选择了优先的输出端口,由于预先选择模块在报文进行路由计算之前已经预先选择了优先的输出端口,故不会影响路由器关键路径的延时,单播报文和多播报文路由计算都会使用该模块的预先选择输出信号来提前确定每个象限的优先方向。
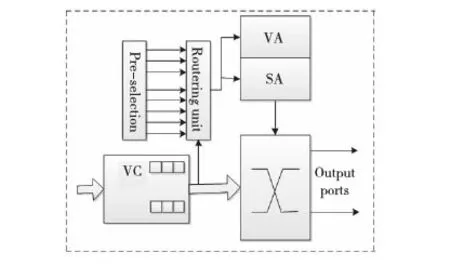
Figure 4 Router microarchitecture图4 路由器微体系结构
4 实验评估
本节评估所提出的死锁避免方法与RPM和BAM结合使用时网络性能的改进。实验中主要使用合成流量模式[11],使用时钟精确模拟器Booksim[11],对改进的多播路由器微体系结构进行了细粒度建模。合成流量模式下评估RPM、BAM和本文提出的基于气泡流控的RPM和BAM(分别记做RPM-B、BAM-B)。RPM需要将网络划分成两个虚拟网络(分别用于传输向上和向下的报文),故不需要配置逃逸虚通道,不会发生死锁;BAM 的多播虚拟网络也需要划分两个虚拟网络(自适应网络和逃逸虚网络),逃逸虚网络是为了防止死锁。而RPM-B和BAM-B只有一个网络,它通过向网络注入气泡来防止死锁。本实验在二维Mesh网络中进行评估。
多播报文与单播报文都包含一个切片,实验中使用多种合成流量模型[11],包括uniform random、transpose、bit rotation 和random permutation。网络拓扑结构使用4×4、8×8的Mesh网络,多播报文目的节点数目与位置在网络中均匀分布。表2给出了基准实验配置参数和用于算法敏感性分析和它的扩展性分析的参数。

Table 2 Configuration parameters in these experiments
4.1 性能
实验测试了RPM、RPM-B、BAM和BAM-B网络的整体性能。RPM:两个虚拟网络分别用于传输向上和向下的报文;RPM-B: RPM路由算法的改进,只有一个虚拟网络,在其网络加入气泡,即空VC避免死锁;BAM:两个虚拟网络分别是自适应网络;逃逸虚网络和BAM-B:BAM路由算法的改进,只有一个虚拟网络,在其网络加入气泡,即空VC。
4.1.1 网络的整体性能
图5给出了网络的路由算法在uniform random、transpose、bit rotation 和random permutation四种不同的合成流量模型下网络的整体性能。
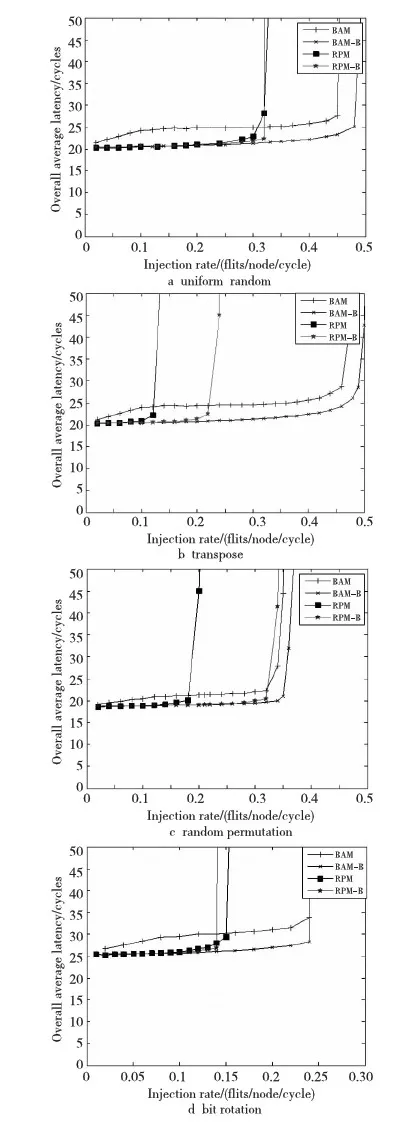
Figure 5 Performance of different synthetic loads图5 不同合成负载下的性能
将RPM-B和BAM-B与RPM和BAM 进行比较,从图5中看到取得了性能的提升,报文的平均延时都得到了降低,而网络的饱和吞吐量除了bit rotation合成流量负载下RPM-B的性能比RPM性能稍差外,其他的饱和吞吐率得到了提升。uniform random 合成流量模型下BAM-B饱和吞吐率提升了6.3%,网络平均延时下降了8.6%。而RPM-B相对于RPM来说,网络的平均延时在注入率比较高时得到了下降,而网络吞吐率没有明显提升。因为RPM分为两个网络,在流量比较低的时候资源和RPM-B基本上一样,对性能没有多大的影响,当网络流量比较高时,RPM不同维度间缓存资源的不均衡性显现,导致报文的延时增大。transpose和random permutation合成流量模型下BAM-B相对于BAM饱和吞吐率分别提升了4.1%、5.5%,平均网络延时降低了15.4%、15.0%;而RPM-B相对于RPM饱和吞吐率分别提升了71.4%、75%,网络平均延时降低了24.9%、12.7%。由于transpose和random permutation两种合成流量负载模型对于RPM将网络分成两个虚拟网络的算法,更容易造成网络中不同维度间缓存资源的不均衡,所以网络中的平均吞吐率提升和网络平均延时的下降都比较明显。BAM在不同维度缓存资源相对均衡,只有逃逸虚通道网络存在缓存资源不均衡问题,所以网络平均吞吐率相对增加较少,网络平均延时下降没有RPM-B的明显。而在bit rotation模型下,BAM-B相对于BAM饱和吞吐率没有得到提升,网络平均延时降低了12.2%;RPM-B相对于RPM饱和吞吐率和网络平均延时都没有得到很好的提升。
4.1.2 多播的性能
图6给出了网络中只有多播报文时网络的整体性能,BAM-B相对于BAM饱和吞吐率提升了16.7%,网络平均延时降低17.30%,网络中全都是多播报文相比网络中存在单播报文的流量模型,使网络中的报文更容易进入逃逸网络,更容易成为网络的瓶颈,从而改进后使网络饱和吞吐率提升最大,网络平均延时降低最大。RPM-B相对于RPM平均网络延时仅仅在网络注入率比较高的时候才有少许的性能提高,而网络饱和吞吐率提升了6.7%,由于网络中都是多播包,当网络注入率比较低时RPM和RPM-B都能够有效地使用网络的资源,性能基本相当,而当网络注入率比较高时由于RPM把网络分成向上和向下的网络,造成网络不同维度的通道使用率不同,导致相对于RPM-B更容易发生饱和。

Figure 6 Performance under 100% the proportion of multicast packets图6 100%多播报文比例下的性能
4.2 敏感性分析
为了分析本文方法对网络整体性能影响和可扩展性方面的影响,进一步开展敏感性分析实验。由于RPM与BAM有类似的性质,不再讨论RPM与它的改进算法对于各种资源的敏感性分析。我们主要以BAM与BAM-B为分析对象,图7对多播改进性能在虚通道数目、多播报文比例、多播报文的平均目标节点数、网络规模四个方面对网络性能与可扩展性进行分析。
4.2.1 虚通道数目
图7a给出了虚通道配置分别是8个VC、6个VC、4个VC时网络的性能。从图7a中可以看到,当虚通道数为8个VC、6个VC、4个VC时,网络吞吐量分别提升6.3%、8.8%、14.2%,延时分别下降8.6%、8.1%、14.2%。当配置较小的虚通道时,由加气泡的方法来避免死锁带来了性能的很大提升。
主要有两个方面因素影响了性能:(1)虚通道比较少时,缓存资源稀缺性增强,增加气泡的方法可以使逃逸虚通道的缓存资源释放,释放稀缺的缓存资源。随着虚通道数的增加,缓存资源的稀缺性逐渐降低,当8个VC时,网络饱和吞吐率只有6.3%的提升,而4个VC时,网络饱和吞吐率提升14.2%。
(2)由于BAM由自适应网络和逃逸虚网络组成,逃逸虚网络中采取维序路由的算法,使多播通道重用的概率降低,增加了网络延时;同时,由于逃逸虚通道只有符合维序路由的包才能够注入,使得垂直方向和水平方向的网络使用情况不均衡,这种不均衡性随着网络中虚通道的减小更加明显,所以虚通道少时,改进算法的延迟下降更明显。
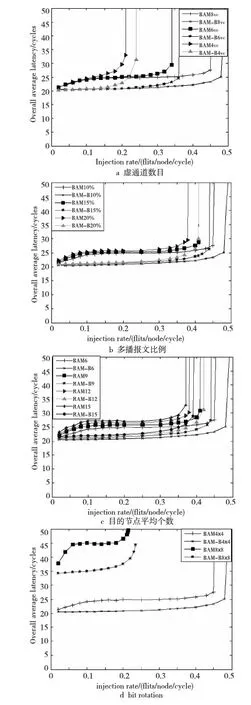
Figure 7 Performance under different network parameters图7 不同网络参数下的性能
4.2.2 多播报文比例
图7b给出了多播比例配置不同时网络的性能及可扩展性分析。从图7b中可以看,到多播比例分别是10%、15%、20%时,网络的平均延时降低分别为13.80%、14.40%、14.80%,网络的吞吐率提升分别为8.6%、7.3%、7.9%。改进的多播路由算法随着网络多播包比例的提高,平均延时降低越明显,因为随着网络中多播报文的增加,网络中总的报文数量也在大量增加。在BAM中进入逃逸虚通道的报文数量也增加,从而增加网络中报文的网络延时,降低了网络的吞吐率。多播比例增加时,加入气泡避免死锁的方法能够提供更多的网络资源,延时下降更为明显,使得延时下降比例从13.80% 提升到14.80%。
4.2.3 多播报文的平均目标节点数
图7c给出了多播目的节点数量配置不同时网络的性能及可扩展性分析。从图7c中可以看到,多播目的节点数量分别为6、9、12、15时,网络的平均延时分别降低13.80%、14.70%、15.30%、16.60%,网络的吞吐率分别提升8.6%、7.3%。10.50%、8.1%。可见,多播平均节点数目对网络延时与吞吐率的影响,与多播报文比例对网络性能的影响类似。
4.2.4 网络规模
图7d给出了4×4 Mesh、8×8 Mesh网络性能,本文方法的网络平均延时分别下降13.80%、18.1%,网络饱和吞吐率提升分别为8.6%、9.8%。由于8×8 Mesh网络中节点数目比4×4 Mesh网络中的节点数目多,报文需要走过更多的路径才能到达目的节点。所以,从图7d中可以看到,对于网络的延时,8×8网络比4×4网络延时明显增大,同时改进后的网络平均延时降低比率也从13.8%增加到18.1%,网络的饱和吞吐率提升比例从8.6%提升到9.8%。由于网络规模的增大对于BAM来说,包进入逃逸虚通道避免死锁的机会更大,更容易使逃逸虚通道成为网络性能提升的瓶颈,而BAM-B能够更好地利用网络的资源,去掉了逃逸虚通道,解除了网络性能提升的瓶颈,使网络平均延时明显降低,吞吐率明显增加。
5 结束语
在当前的众核系统中,支持多播的片上网络变得非常重要。它不仅可以提高网络的饱和吞吐率,也可以降低网络的平均延时,提高网络带宽的利用率。不同多播路由算法对网络资源的利用和网络中报文的分布至关重要,从而对网络的饱和吞吐率和平均网络延时有极大的影响。
本文提出的通过网络中加入气泡,即空闲虚通道的方式来避免网络中的死锁,充分释放了网络中的缓冲资源,提高了网络性能。我们提出的新多播路由算法,相对于最先进的多播路由算法,减少了网络的平均延时和提升了网络的饱和吞吐率。网络平均延时相对于最先进的多播路由算法降低了18.1%,饱和吞吐率相对于最先进的多播路由算法提升了16.7%。相对于RPM路由算法改进后的饱和吞吐率最大提升75%,平均延时最大下降24.9%。
[1] Chaiken D,Field C,Kurihara K,et al.Directory-based cache coherence in large scale multiprocessors[J]. Computer,1990, 23 (6):49-58.
[2] Martin M M K, Hill M D, Wood D A. Token coherence:Decoupling performance and correctness[C]∥Proc of the 30th International Symposium on Computer Architecture, 2003:182-193.
[3] Jerger N E, Peh L-S, Lipasti M, et al. Virtual circuit tree multicasting:A case for on-chip hardware multicast support[C]∥Proc of ISCA, 2008:229-240.
[4] Malumbres M P, Duato J, Torrellas J. An efficient implementation of tree-based multicast routing for distributed shared-memory multiprocessors[C]∥Proc of IPDPS,1996:186-189.
[5] Rodrigo S, Flich J, Duato J, et al. Efficient unicast and multicast support for CMPs[C]∥Proc of MICRO’08, 2008:364-375.
[6] Wang L, Jin Yu-hu, Kim H, et al. Recursive partitioning multicast:A bandwidth-efficient routing for networks-on-chip[C]∥Proc of NOCS’09, 2009:64-73.
[7] Ma S, Jerger N E, Wang Z Y. Supporting efficient collective communication in NoCs[C]∥Proc of HPCA’12, 2012:165-176.
[8] Duato J. A new theory of deadlock-free adaptive routing in wormhole networks [J].IEEE Transactions on Parallel and Distributed Systems, 1993,4(12):1320-1331.
[9] Xiao Can-wen, Zhang Min-xuan, Dou Yong, et al. Dimensional bubble flow control and fully adaptive routing in the 2-D mesh network on chip[C]∥Proc of EUC’08,2008:353-358.
[10] Jerger N E, Peh L. On-chip networks [M]. 1st ed. California:Morgan & Claypool Publishers, 2009.
[11] Dally W, Towles B. Principles and practices of interconnection networks [M]. San Francisco:Morgan Kaufmann Publishers Inc, 2003.
